
Abstract
Purpose
Accurate estimation of the position and orientation (pose) of surgical instruments is crucial for delicate minimally invasive temporal bone surgery. Current techniques lack in accuracy and/or line-of-sight constraints (conventional tracking systems) or expose the patient to prohibitive ionizing radiation (intra-operative CT). A possible solution is to capture the instrument with a c-arm at irregular intervals and recover the pose from the image.
Methods
i3PosNet infers the position and orientation of instruments from images using a pose estimation network. Said framework considers localized patches and outputs pseudo-landmarks. The pose is reconstructed from pseudo-landmarks by geometric considerations.
Results
We show i3PosNet reaches errors \(<\,0.05\) mm. It outperforms conventional image registration-based approaches reducing average and maximum errors by at least two thirds. i3PosNet trained on synthetic images generalizes to real X-rays without any further adaptation.
Conclusion
The translation of deep learning-based methods to surgical applications is difficult, because large representative datasets for training and testing are not available. This work empirically shows sub-millimeter pose estimation trained solely based on synthetic training data.
Similar content being viewed by others

Introduction
Current clinical practice in temporal bone surgery for cochlear implantation (CI) and vestibular schwannoma removal is still centered on a conventional and open operation setting. One fundamental challenge in moving to less traumatic minimally invasive procedures is to satisfy the required navigation accuracy. To ensure delicate risk structures such as the facial nerve and chorda tympani are not damaged by surgical tools, the clinical navigation accuracy must exceed 0.5 mm [15, 19]. Recent efforts have used force-feedback [28], optical tracking systems (OTSs) [5] and neuro-monitoring for CI [1], but each one of these strategies have drawbacks in the minimally invasive setting. For example, OTSs require line-of-sight and a registration between patient and tracking system. Electromagnetic tracking [13], force-feedback or neuro-monitoring, on the other hand, feature-limited accuracy. None of these methods can be used to navigate next-generation flexible instruments that follow nonlinear paths [7]. X-ray imaging, on the other hand, is precise and not constrained by line-of-sight. However, similar to OTS, fiducials used for patient registration significantly impact tracking accuracy of surgical instruments. The small size of fiducials, low contrast to anatomy alongside high anatomy-to-anatomy contrast and rotational symmetry characterize challenges specific to pose estimation of surgical tools in temporal bone surgery.
Unlike previous methods, deep learning allows instrument pose estimation to break into submillimeter accuracy at acceptable execution times [6, 16]. Previous non-deep learning pipelines based on 2D/3D registration [12] and template matching [26] achieve submillimeter accuracy for simple geometries. However, such techniques do not scale, do not generalize to more complex instruments and/or require full-head preoperative CT scans. In addition, these solutions are usually customized to a specific application, e.g., screws in pedicle screw placement [6], fiducials [11] or guide wires and instruments [26]. The recent shift to deep neural networks offers better accuracy at near real-time execution speed for implants and instruments [6, 16]. However, no such solution has been proposed for temporal bone surgery.
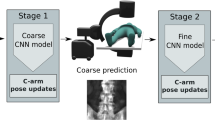
We propose i3PosNet, a deep learning-powered iterative image-guided instrument pose estimation method to provide high-precision estimation of poses. We focus on pose estimation from X-ray images showing a fiducial (screw) placed on the skull close to the temporal bone, because screws are commonly used as fiducials in robotic CI [5]. For optimum performance, i3PosNet implements a modular pipeline consisting of (1) region of interest normalization, (2) 2D pose estimation and (3) 3D pose reconstruction to determine the pose. To this effect, we patchify and normalize a small region around the expected fiducial position. We design a convolutional neural network (CNN) to predict six pseudo-landmarks on two axes with subpixel accuracy. A geometric model reconstructs 3D poses from their landmark coordinates. The division of the pipeline into three modular steps reduces complexity, increases performance and significantly boosts the angle estimation performance of i3PosNet (Fig. 1).
As part of this work, we publish three datasets in addition to the source code.Footnote 1 Based on these three datasets, we show i3PosNet (i) generalizes to real X-ray while only training on synthetic images, (ii) generalizes to two surgical instruments in pilot evaluations, and (iii) outperforms state-of-the-art registration methods as well as the end-to-end variation of i3PosNet. As no public datasets with ground truth poses are available for training and evaluation of novel pose estimation methods, we believe these new datasets will foster further developments in this area. Dataset A consists of synthetic radiographs with a medical screw for training and evaluation. In Dataset B, the screw is replaced by either a drill or a robot. Dataset C features real images of micro-screws placed on a head phantom. Images are acquired with a c-arm and manually annotated in 2D.

Instrument pose estimation from single X-ray: three instruments
Related work
Pose estimation using radiographs of instruments in the temporal bone has received little scientific attention. Most published research uses other tracking paradigms, most notably optical tracking [5]. While some deep learning-based approaches directly [4, 16] or indirectly [6] extract instrument poses from X-ray images, neither address temporal bone surgery. In this section, we give a brief overview of instrument tracking for temporal bone surgery.
Robotic solutions for minimally invasive cochlear implantation demand accurate tracking solutions. The small size of critical risk structures limits the acceptable navigation accuracy to which the tracking accuracy is a significant contributor [19]. In response, robotic cochlear implantation solutions rely on high precision optical [2, 5, 15] and electromagentic tracking [17]. However, electromagnetic tracking is not suitable to guide a robot because of accuracy and metal-distortion constraints [13]. Optical tracking cannot directly measure the instrument pose due to the occluded line-of-sight. Instead, the tool base is tracked adding the base-to-tip registration as a significant error source [5]. Adding additional, redundant approaches based on pose reconstruction from bone density and drill forces [28] as well as a neuro-monitoring-based fail-safe [1] Rathgeb et.al.[18] report a navigation accuracy of \(0.22 \pm 0.1\) mm at the critical facial nerve / \(0.11\pm 0.08\) mm at the target.
Earlier work on X-ray-imaging-based instrument pose estimation centers on traditional registration [8, 10,11,12, 24, 29], segmentation [11] and template-matching [26]. These methods are employed for various applications from pedicle screw placement to implant and guide wire localization. Temporal bone surgery has only been addressed by Kügler et.al.[12]. Recent work introduces deep learning methods for instrument pose estimation using segmentation as intermediate representations [6] and directly estimating the 3D pose [4, 16]. While Miao et.al.[16] employ 974 specialized neural networks, Bui et.al.’s work [4] extends the PoseNet architecture, but does not feature anatomy. Bier et.al.[3] proposed an anatomical landmark localization method. However, instruments sizes are significantly smaller in temporal bone surgery impacting X-ray attenuation and therefore image contrast. For the pose estimation of surgical instruments on endoscopic images [9, 14], deep learning is prevalent technique, but sub-pixel accuracy is not achieved—in part because the manual ground truth annotation does not allow it.
No deep learning-based pose estimation method addresses temporal bone surgery or its challenges such as very small instruments and low contrast.
Datasets
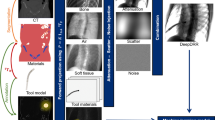
This paper introduces three new datasets: two synthetic digitally rendered radiograph (DRR) datasets (Dataset A for a screw and Dataset B for two surgical instruments), and a real X-ray dataset (Dataset C for manually labeled screws). All datasets include annotations for the pose with a unified file format (Table 1).
Dataset A: synthetic
This dataset shows a CT scan of a head and a screw rendered as X-ray. We balance it w.r.t. anatomical variation and projection geometry by implementing a statistical sampling method, which we describe here. In consequence, the dataset is ideal for method development and the exploration of design choices (Fig. 2a).
Anatomy and fiducial
To account for the variation of patient-specific anatomy, we consider three different conserved human cadaver heads captured by a SIEMENS SOMATOM Definition AS+. The slices of the transverse plane are centered around the otobasis and include the full cross section of the skull. A small medical screw is virtually implanted near the temporal bone similar to the use for tool registration of the pre-operative CT in robotic cochlear surgery [5]. The screw geometry is defined by a CAD mesh provided by the screw manufacturer (c.f. Dataset C). Its bounding box diagonal is 6.5 mm.
Method for radiograph generation
Our DRR generation pipeline is fully parameterizable and tailored to the surgical pose estimation use-case. We use the Insight Segmentation and Reconstruction Toolkit and the Registration Toolkit to modify and project the CT anatomy and the fiducial into 2D images. The pipeline generates projections and corresponding ground truth poses from a CT anatomy, a mesh of the fiducial and a parameter definition, where most parameters can be defined statistically. Since the CT data only includes limited sagittal height, we require all projection rays that pass through an approx. 5 mm sphere around the fiducial to be uncorrupted by regions of missing CT data. For this, missing data are delineated by polygons. We export the pose \(\varvec{\theta }\) (Eq. 1) of the instrument for later use in training and evaluation.

Sample images from Dataset A (left), Dataset B (center) and Dataset C (right, the normalized detail illustrates low contrast)
Parameters of generation
The generation process is dependent on the projection geometry and the relative position and orientation of the fiducial w.r.t. the anatomy. In specific, we manually choose ten realistic fiducial poses w.r.t. the anatomy per subject and side. To increase variety, we add noise to these poses (position \(\mathbf {x}_\mathrm{instr}\) and orientation \(\mathbf {n}_\mathrm{instr}\)): The noise magnitude for testing is lower than for training to preserve realism and increase generalization. The projection geometry on the other hand describes the configuration of the mesh w.r.t. X-ray source and detector. These parameters are encoded in the Source-Object-Distance, the displacement orthogonal to the projection direction and the rotations around the object. We derive these from the specification of the c-arm, which we also use for the acquisition of real X-ray images.
In total, the dataset contains 18,000 images across three anatomies. Three thousand of them are generated with the less noise setting for testing.
Dataset B: surgical tools
To show generalization to other instruments, we introduce a second synthetic dataset. This dataset differs from the first twofold: instead of a screw, we use a medical drill or a prototype robot (see Fig. 1); these are placed at realistic positions inside of the temporal bone instead of on the bone surface. This dataset includes the same number of images per instrument as Dataset A (Fig. 2b).
Drill
Despite the drill’s length (drill diameter 3 mm), for the estimation of the tip’s pose, only the tip is considered to limit the influence of drill bending.
Prototype robot
The non-rigid drilling robot consists of a spherical drilling head and two cylinders connected by a flexible joint. By flexing and expanding the joint in coordination with cushions on the cylinders, the drill-head creates nonlinear access paths. With a bounding box diagonal of the robot up to the joint of 13.15 mm, its dimensions are in line with typical MIS and temporal bone surgery applications.
Dataset C: real X-rays
For Dataset C, we acquire real X-ray images and annotations. The dataset includes 540 images with diverse acquisition angles, distances and positions (Fig. 2c).
Preparation
The experimental setup is based on a realistic X-ray head phantom featuring a human skull embedded in tissue equivalent material. To not damage the head phantom for the placement of the fiducial (screw), we attach the medical titanium micro-screw with modeling clay as the best non-destructive alternative. The setup is then placed on the carbon fiber table and supported by X-ray-translucent foam blocks.

Definition of pose; length not to scale
Image acquisition
We capture multiple X-ray images with a Ziehm c-arm certified for clinical use before repositioning the screw on the skull. These images are collected from multiple directions per placement.
Manual annotation
In a custom annotation tool, we recreate the projection geometry from c-arm specifications replacing X-ray source and detector with camera and X-ray, respectively. The screw is rendered as an outline and interactively translated and rotated to match the X-ray. We remove images, where the screw is not visible to the annotater (approx. 1% of images). Finally, the projected screw position is calculated to fit the projection geometry.
Methods
Our approach breaks the task of surgical pose estimation down into three steps: reduction in image variety (region of interest appearance normalization), a convolutional neural network for information extraction and finally pose reconstruction from pseudo-landmarks. We describe a formalized problem definition in addition to these individual three steps in this section.
Problem definition
Surgical pose estimation is the task of extracting the pose from a X-ray image. We define the pose\(\varvec{\theta }\) to be the set of coordinates, forward angle, projection angle and distance to the X-ray source (depth). It is defined w.r.t. the detector and the projection geometry (see Fig. 3).
The forward angle\(\alpha \) indicates the angle between the instrument’s main rotational axis projected onto the image plane and the horizontal axis of the image. The projection angle\(\tau \) quantifies the tilt of the instrument w.r.t. the detector plane. The depth\(d\) represents the distance on the projection normal from the source (focal point) to the instrument (c.f. Source-Object-Distance).
We assume an initial pose with accuracy \(\Delta x_\text {initial} \le 2.5\) mm and \(\Delta \alpha _\text {initial} \le 30^{\circ }\) is available. The initial pose can be manually identified, adopted from an independent low-precision tracking system, previous time points or determined from the image by a localization U-Net [14].
Given a new predicted pose, the initial guess is updated and the steps described in “Appearance normalization”– “Pose reconstruction” section iteratively repeated.
Appearance normalization
Since megapixel X-ray images (\(1024\times 1024\) pixels) are dominated by regions unimportant to the pose estimation, the direct extraction of subpixel accuracy from megapixel images oversaturates the deep learning strategy with data. It is therefore crucial to reduce the size of the image and the image variety based on prior knowledge (Fig. 2).
To reduce image variety, the appearance normalization creates an image patch that is rotated, translated and cut to the estimated object position. Additionally, we normalize the intensity in the patch of \(92\times 48\) pixels. Based on this normalization step and given perfect knowledge of the pose, the object will always appear similar w.r.t. the in-plane pose components (position and forward angle). We define this as standard pose—the object positioned at a central location and oriented in the direction of the x-axis of the patch.
Pseudo-landmarks are generated from the pose annotation. Their geometric placement w.r.t. the fiducial is described by the pair of x- and y-coordinates \((x_i, y_i)\). The independence from the fiducial’s appearance motivates the term “pseudo-landmark”. They are placed 15 mm apart in a cross-shape centered on the instrument (see Fig. 4). Two normalized support vectors define the legs of the cross: instruments rotational axis (x-direction, \(3+1\) landmarks), and its cross-product with the projection direction (y-direction, \(2+1\) landmarks). Equation 2 formalizes the transformation of the pose to point coordinates in the image plane dependent on the projection geometry (\(c_{\text {d2p}} = {\Delta _\text {ds} / d_\text {SDD}}\) with Source-Detector-Distance \(d_{SDD}\) and Detector-Pixel-Spacing \(\Delta _{ds}\)). \(\left\{ (x^\text {LP}_i , y^\text {LP}_i)\right\} _{i=1}^6\) describe the local placement (LP) of pseudo-landmarks w.r.t. the support vectors. Finally, landmark positions are normalized w.r.t. maximum values.
To construct prior knowledge for training, we generate random variations of the in-plane components of the pose effecting both image and annotation:
By drawing the variation of the position \(\mathbf {x}_\mathrm{instr}\) in polar coordinates \((R, \beta )\) (\(\mathcal {U}\): uniform distribution) and the forward angle \(\Delta \alpha \) from a normal distribution (\(\mathcal {N}\)), we skew the training samples toward configurations similar to the standard pose. This skew favors accuracy based on good estimates over more distant cases, similar to class imbalance. In effect, this appearance normalization increases the effectiveness (performance per network complexity) of the Deep Neural Network through the utilization of data similarity.
The patch appearance is dominated by the difference between the actual and the standard pose, i.e. the error of the prior knowledge.
Pseudo-landmark prediction
Based on the \(92\times 48\)-normalized greyscale patch, a convolutional neural network (CNN) extracts the pose information. Our analysis shows pseudo-landmarks outperform direct pose prediction. While we explain the design of the pseudo-landmark estimation here, the direct pose estimation follows a similar strategy.

Pseudo-landmark placement: initial (blue), estimation (yellow) and central landmark (red), ground truth (green)
The CNN is designed after a VGG-fashion [20] with 13 weight layers. We benchmark the CNN on multiple design dimensions including the number of convolutional layers and blocks, the pooling layer type, the number of fully connected layers and the regularization strategy. In this context, we assume a block consists of multiple convolutional layers and ends in a pooling layer shrinking the layer size by a factor of \(2\times 2\).
All layers use ReLU activation. We double the number of channels after every block, starting with 32 for the first block. We use the mean squared error as loss function. For optimizers, we evaluated both Stochastic Gradient Descent with Nesterov Momentum update and Adam including different parameter combinations.
Pose reconstruction
We reconstruct the pose from the pseudo-landmarks based on their placement in a cross-shape (\(x^\text {LP}_i = 0\) or \(y^\text {LP}_i = 0\)). It enables us to invert Eq. 2 geometrically by fitting lines through two subsets of landmarks. The intersection yields the position \(\varvec{x}= (x,y)^\mathrm{T}\) and the slope the forward angle \(\alpha \). The depth \(d\) and projection angle \(\tau \) are determined by using Eqs. 4 and 5 on the same landmark subsets.
Experiments and results
We performed a large number of different experiments with independent analysis of the position \(\varvec{x}\), forward angle \(\alpha \), projection angle \(\tau \) and depth \(d\). In this section, we present the common experimental setup, evaluation metrics and multiple evaluations of i3PosNet. We group in-depth evaluations in three blocks: a general “Evaluation” section, and the analysis of the modular design and limitations in “Evaluation of design decisions” and “Limitations to projection parameters”. To streamline the description of the training and evaluation pipeline, we only present differences to the initially described common experimental setup.
Common experimental setup
Generalization to unseen anatomies is a basic requirement to any CAI methodology, therefore we always evaluate on an unseen anatomy. Following this leave-one-anatomy-out evaluation strategy, individual training runs only include 10 k images, since 5 k images are available for training per anatomy.
Training
Based on the training dataset (from Dataset A), we create 20 variations of the prior pose knowledge (see “Appearance Normalization”). In consequence, training uses 20 different image patches per \(1024\times 1024\) image for all experiments (200 k patches for training). We train the convolutional neural network to minimize the mean squared error of the pseudo-landmark regression with the Adam optimizer and standard parameters. Instead of decay, we use a learning rate schedule that uses fixed learning rates for different training stages of \(5 \times 10^{-3}\) initially and decrease the exponent by one every 35 epochs. We stop the training after 80 epochs and choose the best-performing checkpoint by monitoring the loss on the validation set.
Testing
The testing dataset (from Dataset A) features the unseen third anatomy, which we combine with ten randomly drawn initial poses per image. We use the strategy presented in “Appearance Normalization” to draw initial in-plane poses. For testing, no out-of-plane components are required a priori. The prediction is iterated three times, where the prior knowledge is updated with pose predictions each iteration (Fig. 5). Images with projection angles \(|\tau | > 80^{\circ }\) are filtered out, because the performance significantly degrades biasing results. This leads to on average 7864 tests per trained model. This degradation is obvious given the ambiguity that arises, if projection direction and fiducial main axis (almost) align. We provide an in-depth analysis of this limitation in “Limitations to projection parameters”.

Iterative refinement scheme (“recon&crop”: reconstruct pose and crop according to estimation)
Metrics
We evaluated the in-plane and out-of-plane components of the predicted pose independently using five error measures. During annotation, we experienced, out-of-plane components are much harder to recover from single images so we expect it much harder to recover for neural networks as well.
In-plane components
The Position Error (also reprojection distance [25]) is the Euclidean Distance in a plane through the fiducial and orthogonal to the projection normal. It is measured in pixel (in the image) or millimeter (in the world coordinate system). The relationship between pixel and millimeter position error is image-dependent because of varying distances between source and object. The Forward Angle Error is the angle between estimated and ground truth orientation projected into the image plane in degrees, i.e., the in-plane angle error.
Out-of-plane components
For the Projection Angle Error, we consider the tilt of the fiducial out of the image plane in degrees. Since the sign of the projection angle is not recoverable for small fiducials (\(\cos (\tau ) = \cos (-\tau )\)), we only compare absolute values for this out-of-plane angle error. The rotation angle is not recoverable at all for rotationally symmetric fiducials specifically at this size. Finally, the Depth Error (millimeter) considers the distance between X-ray source and fiducial (also known as the target registration error in the projection direction [25]).

Quantative comparison of i3PosNet, i2PosNet (no iter.), Registration with Covariance Matrix Adaptation Evolution and Gradient Correlation or Mutual Information
Evaluation
Comparison to registration
Due to long execution times of the registration (>30 min per image), the evaluation was performed on a 25-image subset of one (unseen) anatomy with two independent estimates image. We limited the number of DRRs generated online to 400. At that point the registration was always converged. Both i3PosNet and i2PosNet metrics represent distributions from four independent trainings to cover statistical training differences. Comparing i3PosNet to two previously validated registration methods [12], i3PosNet outperforms these by a factor of 5 (see Fig. 6). The errors for i3PosNet and i2PosNet are below 0.5 Pixel (0.1 mm) for all images. At the same time, i3PosNet reduces the single-image prediction time to 57.6 ms on one GTX 1080 at 6% utilization.
Real X-ray image evaluation
Because of the significant computation overhead (projection), we randomly choose 25 images from anatomy 1 in Dataset A and performed two pose estimations from randomly sampled deviations from the initial estimate. Four i3PosNet-models were independently trained for 80 epochs and evaluated for three iterations (see Table 2).
Generalization
i3PosNet also generalizes well to other instruments. Training and evaluating i3PosNet with corresponding images from Dataset B (drill and robot) shows consistent results across all metrics.
Evaluation of design decisions
To emphasize our reliance on geometric considerations and our central design decision, we evaluated the prediction of forward angles (end-to-end) in comparison with the usage of pseudo-landmarks and 2D pose reconstruction (modular). Comparing our modular solution to the end-to-end setup, we found the latter to display significantly larger errors for the forward angle, especially for relevant cases of bad initialization (see Fig. 7).
Limitations to projection parameters
We evaluate the dependence on projection angles \(\tau \) imposed especially for drill-like instruments (strong rotational symmetry) (see Fig. 8). We observe a decreasing quality starting at 60\(^{\circ }\) with instabilities around 90\(^{\circ }\) motivating the exclusion of images with \(|\tau | > 80^{\circ }\) from the general experiments.

The addition of virtual landmarks (modular, a) improves forward angle errors for inaccurate initial angles in comparison to regressing the angle directly (end-to-end, b)

Evaluation of the forward angle dependent on the projection angle; examples showing different instruments for different projection angles
Discussion and conclusion
We estimate the pose of three surgical instruments using a deep learning-based approach. By including geometric considerations into our method, we are able to approximate the nonlinear properties of rotation and projection.
The accuracy provided by i3PosNet improves the ability of surgeons to accurately determine the pose of instruments, even when the line of sight is obstructed. However, the transfer of the model trained solely based on synthetic data significantly reduces the accuracy, a problem widely observed in learning for CAI [21, 23, 27, 30]. As a consequence, while promising on synthetic results, i3PosNet closely misses the required tracking accuracy for temporal bone surgery on real X-ray data. Solving this issue is a significant CAI challenge and requires large annotated datasets mixed into the training [4] or novel methods for generation [22].
In the future, we also want to embed i3PosNet in a multi-tool localization scheme, where fiducials, instruments, etc., are localized and their pose estimated without the knowledge of the projection matrix. To increase the 3D accuracy, multiple orthogonal X-rays and a proposal scheme for the projection direction may be used. Through this novel navigation method, surgeries previously barred from minimally invasive approaches are opened to new possibilities with an outlook of higher precision and reduced patient surgery trauma.
Notes
Find additional information at https://i3posnet.david-kuegler.de/
References
Ansó J, Dür C, Gavaghan K, Rohrbach H, Gerber N, Williamson T, Calvo EM, Balmer TW, Precht C, Ferrario D, Dettmer MS, Rösler KM, Caversaccio MD, Bell B, Weber S (2016) A neuromonitoring approach to facial nerve preservation during image-guided robotic cochlear implantation. Otol Neurotol 37(1):89–98
Balachandran R, Mitchell JE, Blachon G, Noble JH, Dawant BM, Fitzpatrick JM, Labadie RF (2010) Percutaneous cochlear implant drilling via customized frames: an in vitro study. Otolaryngol Head Neck Surg 142(3):421–426
Bier B, Unberath M, Zaech JN, Fotouhi J, Armand M, Osgood G, Navab N, Maier A (2018) X-ray-transform invariant anatomical landmark detection for Pelvic trauma surgery. In: MICCAI 2018. Springer
Bui M, Albarqouni S, Schrapp M, Navab N, Ilic S (2017) X-Ray PoseNet: 6 DoF pose estimation for mobile x-ray devices. In: WACV 2017
Caversaccio M, Gavaghan K, Wimmer W, Williamson T, Ansò J, Mantokoudis G, Gerber N, Rathgeb C, Feldmann A, Wagner F, Scheidegger O, Kompis M, Weisstanner C, Zoka-Assadi M, Roesler K, Anschuetz L, Huth M, Weber S (2017) Robotic cochlear implantation: surgical procedure and first clinical experience. Acta Oto-laryngol 137(4):447–454
Esfandiari H, Newell R, Anglin C, Street J, Hodgson AJ (2018) A deep learning framework for segmentation and pose estimation of pedicle screw implants based on C-arm fluoroscopy. IJCARS 13(8):1269–1282
Fauser J, Sakas G, Mukhopadhyay A (2018) Planning nonlinear access paths for temporal bone surgery. IJCARS 13(5):637–646
Gao G, Penney G, Gogin N, Cathier P, Arujuna A, Wright M, Caulfield D, Rinaldi A, Razavi R, Rhode K (2010) Rapid image registration of three-dimensional transesophageal echocardiography and x-ray fluoroscopy for the guidance of cardiac interventions. Lecture Notes in Computer Science. IPCAI. Springer, Berlin, pp 124–134
Hajj HA, Lamard M, Conze PH, Roychowdhury S, Hu X, Maršalkaite G, Zisimopoulos O, Dedmari MA, Zhao F, Prellberg J, Sahu M, Galdran A, Araújo T, Vo DM, Panda C, Dahiya N, Kondo S, Bian Z, Vahdat A, Bialopetravičius J, Flouty E, Qiu C, Dill S, Mukhopadhyay A, Costa P, Aresta G, Ramamurthy S, Lee SW, Campilho A, Zachow S, Xia S, Conjeti S, Stoyanov D, Armaitis J, Heng PA, Macready WG, Cochener B, Quellec G (2018) Cataracts: challenge on automatic tool annotation for cataract surgery. Medical image analysis
Hatt CR, Speidel MA, Raval AN (2016) Real-time pose estimation of devices from x-ray images: application to x-ray/echo registration for cardiac interventions. Med Image Anal 34:101–108
Jain AK, Mustafa T, Zhou Y, Burdette C, Chirikjian GS, Fichtinger G (2005) FTRAC-robust fluoroscope tracking fiducial. Med Phys 32(10):3185–3198
Kügler D, Jastrzebski M, Mukhopadhyay A (2018) Instrument Pose estimation using registration for otobasis surgery. In: WBIR2018. Springer
Kügler D, Krumb H, Bredemann J, Stenin I, Kristin J, Klenzner T, Schipper J, Schmitt R, Sakas G, Mukhopadhyay A (2019) High-precision evaluation of electromagnetic tracking. IJCARS
Kurmann T, Marquez Neila P, Du X, Fua P, Stoyanov D, Wolf S, Sznitman R (2017) Simultaneous recognition and pose estimation of instruments in minimally invasive surgery. In: MICCAI 2017. Springer, pp 505–513
Labadie RF, Balachandran R, Noble JH, Blachon GS, Mitchell JE, Reda FA, Dawant BM, Fitzpatrick JM (2014) Minimally invasive image-guided cochlear implantation surgery: first report of clinical implementation. The Laryngoscope 124(8):1915–1922
Miao S, Wang ZJ, Liao R (2016) A CNN regression approach for real-time 2D/3D registration. IEEE TMI 35(5):1352–1363
Nguyen Y, Miroir M, Vellin JF, Mazalaigue S, Bensimon JL, Bernardeschi D, Ferrary E, Sterkers O, Grayeli AB (2011) Minimally invasive computer-assisted approach for cochlear implantation: a human temporal bone study. Surg Innov 18(3):259–267
Rathgeb C, Anschuetz L, Schneider D, Dür C, Caversaccio M, Weber S, Williamson T (2018) Accuracy and feasibility of a dedicated image guidance solution for endoscopic lateral skull base surgery. Eur Arch Oto-Rhino-Laryngol 275(4):905–911
Schipper J, Aschendorff A, Arapakis I, Klenzner T, Teszler CB, Ridder GJ, Laszig R (2004) Navigation as a quality management tool in cochlear implant surgery. Laryngol Otol 118(10):764–770
Simonyan K, Zisserman A (2014) Very deep convolutional networks for large-scale image recognition. http://arxiv.org/pdf/1409.1556
Terunuma T, Tokui A, Sakae T (2018) Novel real-time tumor-contouring method using deep learning to prevent mistracking in x-ray fluoroscopy. Radiol Phys Technol 11(1):43–53
Unberath M, Zaech JN, Lee SC, Bier B, Fotouhi J, Armand M, Navab N (2018) Deepdrr–a catalyst for machine learning in fluoroscopy-guided procedures. In: Frangi A, Schnabel J, Davatsikos C, Alberola-López C, Fichtinger G, Frangi AF, Schnabel JA, Davatzikos C (eds) Medical image computing and computer assisted intervention–MICCAI 2018, Image processing, computer vision, pattern recognition, and graphics. Springer, Cham, pp 98–106. https://doi.org/10.1007/978-3-030-00937-3_12, http://arxiv.org/pdf/1803.08606
Unberath M, Zaech JN, Gao C, Bier B, Goldmann F, Lee SC, Fotouhi J, Taylor R, Armand M, Navab N (2019) Enabling machine learning in x-ray-based procedures via realistic simulation of image formation. Int J Comput Assist Radiol Surg 14(9):1517–1528. https://doi.org/10.1007/s11548-019-02011-2
Uneri A, Stayman JW, de Silva T, Wang AS, Kleinszig G, Vogt S, Khanna AJ, Wolinsky JP, Gokaslan ZL, Siewerdsen JH (2015) Known-component 3d–2d registration for image guidance and quality assurance in spine surgery pedicle screw placement. In: Proceedings of SPIE 9415
van de Kraats EB, Penney GP, Tomazevic D, van Walsum T, Niessen WJ (2005) Standardized evaluation methodology for 2-D-3-D registration. IEEE TMI 24(9):1177–1189
Vandini A, Glocker B, Hamady M, Yang GZ (2017) Robust guidewire tracking under large deformations combining segment-like features (SEGlets). Med Image Anal 38:150–164
Vercauteren T, Unberath M, Padoy N, Navab N (2020) Cai4cai: the rise of contextual artificial intelligence in computer assisted interventions. Proc IEEE 108(1):198–214
Williamson TM, Bell BJ, Gerber N, Salas L, Zysset P, Caversaccio M, Weber S (2013) Estimation of tool pose based on force-density correlation during robotic drilling. IEEE TBME 60(4):969–976
Zhang L, Ye M, Chan PL, Yang GZ (2017) Real-time surgical tool tracking and pose estimation using a hybrid cylindrical marker. Int J Comput Assist Radiol Surg 12(6):921–930
Zhang Y, Miao S, Mansi T, Liao R (2018) Task driven generative modeling for unsupervised domain adaptation: application to x-ray image segmentation. Medical image computing and computer assisted intervention—MICCAI 2018. Springer, Cham, pp 599–607
Acknowledgements
Open Access funding provided by Projekt DEAL.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
This research was partially funded by the German Research Foundation under Grant FOR 1585.
Research involving human participants and/or animals
This article does not contain any studies with human participants or animals.
Informed consent
This articles does not contain patient data.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Work done at Department of Computer Science, Technischer Universität Darmstadt, Darmstadt, Germany.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Kügler, D., Sehring, J., Stefanov, A. et al. i3PosNet: instrument pose estimation from X-ray in temporal bone surgery. Int J CARS 15, 1137–1145 (2020). https://doi.org/10.1007/s11548-020-02157-4
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11548-020-02157-4