
Abstract
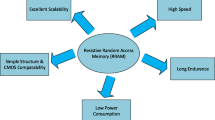
This paper surveys domain-specific architectures (DSAs) built from two emerging memory technologies. Hybrid memory cube (HMC) and high bandwidth memory (HBM) can reduce data movement between memory and computation by placing computing logic inside memory dies. On the other hand, the emerging non-volatile memory, metal-oxide resistive random access memory (ReRAM) has been considered as a promising candidate for future memory architecture due to its high density, fast read access and low leakage power. The key feature is ReRAM’s capability to perform the inherently parallel in-situ matrix-vector multiplication in the analog domain. We focus on the DSAs for two important applications—graph processing and machine learning acceleration. Based on the understanding of the recent architectures and our research experience, we also discuss several potential research directions.
Similar content being viewed by others


References
Hennessy J L, Patterson D A. A new golden age for computer architecture. Commun ACM, 2019, 62: 48–60
Krizhevsky A, Sutskever I, Hinton G E. Imagenet classification with deep convolutional neural networks. In: Proceedings of the 25th International Conference on Neural Information Processing Systems, 2012. 1097–1105
Farmahini-Farahani A, Ahn J H, Morrow K, et al. NDA: near-DRAM acceleration architecture leveraging commodity DRAM devices and standard memory modules. In: Proceedings of High-Performance Computer Architecture, 2015
Hybrid Memory Cube Consortium. Hybrid Memory Cube Specification Version 2.1. Technical Report. 2015
Lee D U, Kim K W, Kim K W, et al. A 1.2 V 8 Gb 8-channel 128 GB/s high-bandwidth memory (HBM) stacked DRAM with effective microbump I/O test methods using 29 nm process and TSV. In: Proceedings of IEEE International Solid-State Circuits Conference Digest of Technical Papers (ISSCC), 2014. 432–433
Wong H S P, Lee H Y, Yu S, et al. Metal-oxide RRAM. Proc IEEE, 2012, 100: 1951–1970
Xia L, Li B, Tang T, et al. MNSIM: simulation platform for memristor-based neuromorphic computing system. IEEE Trans Comput-Aided Des Integr Circuits Syst, 2017, 37: 1009–1022
Prezioso M, Merrikh-Bayat F, Hoskins B D, et al. Training and operation of an integrated neuromorphic network based on metal-oxide memristors. Nature, 2015, 521: 61–64
Thomas A. Memristor-based neural networks. J Phys D-Appl Phys, 2013, 46: 093001
Xiao W, Xue J, Miao Y, et al. TUX2: distributed graph computation for machine learning. In: Proceedings of the 14th USENIX Symposium on Networked Systems Design and Implementation, 2017
Alexandrescu A, Kirchhoff K. Data-driven graph construction for semi-supervised graph-based learning in NLP. In: Proceedings of Human Language Technology Conference of the North American Chapter of the Association of Computational Linguistics, 2007. 204–211
Goyal A, Daumé III H, Guerra R. Fast large-scale approximate graph construction for NLP. In: Proceedings of the 2012 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning, 2012. 1069–1080
Zesch T, Gurevych I. Analysis of the wikipedia category graph for NLP applications. In: Proceedings of the TextGraphs-2 Workshop (NAACL-HLT 2007), 2007. 1–8
Qiu M, Zhang L, Ming Z, et al. Security-aware optimization for ubiquitous computing systems with SEAT graph approach. J Comput Syst Sci, 2013, 79: 518–529
Stankovic A M, Calovic M S. Graph oriented algorithm for the steady-state security enhancement in distribution networks. IEEE Trans Power Deliver, 1989, 4: 539–544
Wang Y J, Xian M, Liu J, et al. Study of network security evaluation based on attack graph model (in Chinese). J Commun, 2007, 28: 29–34
Shun J, Roosta-Khorasani F, Fountoulakis K, et al. Parallel local graph clustering. Proc VLDB Endow, 2016, 9: 1041–1052
Schaeffer S E. Survey: graph clustering. Comput Sci Rev, 2007, 1: 27–64
Fouss F, Pirotte A, Renders J M, et al. Random-walk computation of similarities between nodes of a graph with application to collaborative recommendation. IEEE Trans Knowl Data Eng, 2007, 19: 355–369
Guan Z, Bu J, Mei Q, et al. Personalized tag recommendation using graph-based ranking on multi-type interrelated objects. In: Proceedings of the 32nd International ACM SIGIR Conference on Research and Development in Information Retrieval, 2009. 540–547
Lo S, Lin C. WMR—a graph-based algorithm for friend recommendation. In: Proceedings of the 2006 IEEE/WIC/ACM International Conference on Web Intelligence, 2006. 121–128
Mirza B J, Keller B J, Ramakrishnan N. Studying recommendation algorithms by graph analysis. J Intell Inf Syst, 2003, 20: 131–160
Campbell W M, Dagli C K, Weinstein C J. Social network analysis with content and graphs. Lincoln Laboratory J, 2013, 20: 61–81
Tang L, Liu H. Graph mining applications to social network analysis. In: Managing and Mining Graph Data. Berlin: Springer, 2010. 487–513
Wang T, Chen Y, Zhang Z, et al. Understanding graph sampling algorithms for social network analysis. In: Proceedings of the 31st International Conference on Distributed Computing Systems Workshops, 2011. 123–128
Aittokallio T, Schwikowski B. Graph-based methods for analysing networks in cell biology. Briefings Bioinf, 2006, 7: 243–255
Enright A J, Ouzounis C A. BioLayout—an automatic graph layout algorithm for similarity visualization. Bioinformatics, 2001, 17: 853–854
Novére N L, Hucka M, Mi H, et al. The systems biology graphical notation. Nat Biotechnol, 2009, 27: 735–741
Goodfellow I, Bengio Y, Courville A. Deep Learning. Cambridge: MIT Press, 2016
Han S, Pool J, Tran J, et al. Learning both weights and connections for efficient neural network. In: Proceedings of the 28th International Conference on Neural Information Processing Systems, 2015. 1135–1143
Wen W, Wu C, Wang Y, et al. Learning structured sparsity in deep neural networks. In: Proceedings of the 30th International Conference on Neural Information Processing Systems, 2016. 2074–2082
Park E, Ahn J, Yoo S. Weighted-entropy-based quantization for deep neural networks. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017. 5456–5464
Wu J, Leng C, Wang Y, et al. Quantized convolutional neural networks for mobile devices. In: Proceedings of IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016
Alwani M, Chen H, Ferdman M, et al. Fused-layer CNN accelerators. In: Proceedings of the 49th Annual IEEE/ACM International Symposium on Microarchitecture (MICRO), 2016. 1–12
Shen Y, Ferdman M, Milder P. Maximizing CNN accelerator efficiency through resource partitioning. In: Proceedings of the 44th Annual International Symposium on Computer Architecture, 2017. 535–547
Chen T, Du Z D, Sun N H, et al. DianNao: a small-footprint high-throughput accelerator for ubiquitous machine-learning. In: Proceedings of ACM SIGARCH Computer Architecture News, 2014. 269–284
Merolla P A, Arthur J V, Alvarez-Icaza R, et al. A million spiking-neuron integrated circuit with a scalable communication network and interface. Science, 2014, 345: 668–673
Sharma H, Park J, Mahajan D, et al. From high-level deep neural models to FPGAs. In: Proceedings of the 49th Annual IEEE/ACM International Symposium on Microarchitecture (MICRO), 2016. 1–12
Shen Y, Ferdman M, Milder P. Escher: a CNN accelerator with flexible buffering to minimize off-chip transfer. In: Proceedings of the 25th IEEE International Symposium on Field-Programmable Custom Computing Machines (FCCM17). Los Alamitos: IEEE Computer Society, 2017
Ovtcharov K, Ruwase O, Kim J Y, et al. Toward accelerating deep learning at scale using specialized hardware in the datacenter. In: Proceedings of IEEE Hot Chips 27 Symposium (HCS), 2015. 1–38
Ovtcharov K, Ruwase O, Kim J Y, et al. Accelerating deep convolutional neural networks using specialized hardware. Microsoft Research Whitepaper, 2015, 2: 1–4
Sharma H, Park J, Amaro E, et al. Dnnweaver: from high-level deep network models to FPGA acceleration. In: Proceedings of the Workshop on Cognitive Architectures, 2016
Waldrop M M. The chips are down for Moore’s law. Nature, 2016, 530: 144–147
Black B, Annavaram M, Brekelbaum N, et al. Die stacking (3D) microarchitecture. In: Proceedings of the 39th Annual IEEE/ACM International Symposium on Microarchitecture (MICRO’06), 2006. 469–479
Hybrid Memory Cube Consortium. Hybrid Memory Cube Specification 2.1, 2015
OĆonnor M. Highlights of the high-bandwidth memory (HBM) standard. In: Proceedings of Memory Forum Workshop, 2014
Ahn J, Hong S, Yoo S, et al. A scalable processing-in-memory accelerator for parallel graph processing. In: Proceedings of ACM SIGARCH Computer Architecture News, 2015. 105–117
Shevgoor M, Kim J S, Chatterjee N, et al. Quantifying the relationship between the power delivery network and architectural policies in a 3D-stacked memory device. In: Proceedings of the 46th Annual IEEE/ACM International Symposium on Microarchitecture, 2013. 198–209
Kim G, Kim J, Ahn J H, et al. Memory-centric system interconnect design with hybrid memory cubes. In: Proceedings of the 22nd International Conference on Parallel Architectures and Compilation Techniques. Piscataway: IEEE Press, 2013. 145–156
Kim J, Dally W, Scott S, et al. Cost-efficient dragonfly topology for large-scale systems. IEEE Micro, 2009, 29: 33–40
Kim J, Dally W J, Abts D. Flattened butterfly: a cost-efficient topology for high-radix networks. In: Proceedings of ACM SIGARCH Computer Architecture News, 2007. 126–137
Izraelevitz J, Yang J, Zhang L, et al. Basic performance measurements of the Intel Optane DC persistent memory module. 2019. ArXiv:1903.05714
Hady F T, Foong A, Veal B, et al. Platform storage performance with 3D XPoint technology. Proc IEEE, 2017, 105: 1822–1833
Akinaga H, Shima H. Resistive random access memory (ReRAM) based on metal oxides. Proc IEEE, 2010, 98: 2237–2251
Liu W, Pey K L, Raghavan N, et al. Fabrication of RRAM cell using CMOS compatible processes. US Patent App. 13/052,864, 2012
Trinh H D, Tsai C Y, Lin H L. Resistive RAM structure and method of fabrication thereof. US Patent 9,978,938, 2018
Adam G C, Chrakrabarti B, Nili H, et al. 3D ReRAM arrays and crossbars: fabrication, characterization and applications. In: Proceedings of IEEE 17th International Conference on Nanotechnology (IEEE-NANO), 2017. 844–849
Chen W H, Lin W J, Lai L Y, et al. A 16 Mb dual-mode ReRAM macro with sub-14 ns computing-in-memory and memory functions enabled by self-write termination scheme. In: Proceedings of IEEE International Electron Devices Meeting (IEDM), 2017
Chang M F, Lin C C, Lee A, et al. A 3T1R nonvolatile TCAM using MLC ReRAM with sub-1 ns search time. In: Proceedings of IEEE International Solid-State Circuits Conference-(ISSCC) Digest of Technical Papers, 2015. 1–3
Han R, Huang P, Zhao Y, et al. Demonstration of logic operations in high-performance RRAM crossbar array fabricated by atomic layer deposition technique. Nanoscale Res Lett, 2017, 12: 1–6
Kataeva I, Ohtsuka S, Nili H, et al. Towards the development of analog neuromorphic chip prototype with 2.4 m integrated memristors. In: Proceedings of 2019 IEEE International Symposium on Circuits and Systems (ISCAS), 2019. 1–5
Bayat F M, Prezioso M, Chakrabarti B, et al. Implementation of multilayer perceptron network with highly uniform passive memristive crossbar circuits. Nature Commun, 2018, 9: 1–7
Cai F, Correll J M, Lee S H, et al. A fully integrated reprogrammable memristor-CMOS system for efficient multiply-accumulate operations. Nat Electron, 2019, 2: 290–299
Xu C, Niu D, Muralimanohar N, et al. Overcoming the challenges of crossbar resistive memory architectures. In: Proceedings of IEEE 21st International Symposium on High Performance Computer Architecture (HPCA), 2015. 476–488
Liu T, Yan T H, Scheuerlein R, et al. A 130.7-mm2 2-layer 32-Gb ReRAM memory device in 24-nm technology. IEEE J Solid-State Circ, 2014, 49: 140–153
Fackenthal R, Kitagawa M, Otsuka W, et al. 19.7 a 16 Gb ReRAM with 200 MB/s write and 1 GB/s read in 27 nm technology. In: Proceedings of IEEE International Solid-State Circuits Conference Digest of Technical Papers (ISSCC), 2014. 338–339
Qureshi M K, Karidis J, Franceschini M, et al. Enhancing lifetime and security of PCM-based main memory with start-gap wear leveling. In: Proceedings of the 42nd Annual IEEE/ACM International Symposium on Microarchitecture, 2009. 14–23
Lee M J, Lee C B, Lee D, et al. A fast, high-endurance and scalable non-volatile memory device made from asymmetric Ta2O5−x/TaO2−x bilayer structures. Nat Mater, 2011, 10: 625–630
Hsu C, Wang I, Lo C, et al. Self-rectifying bipolar TaOx/TiO2 RRAM with superior endurance over 1012 cycles for 3D high-density storage-class memory VLSI tech. In: Proceedings of Symposium on VLSI Technology, 2013. 166–167
Hu M, Strachan J P, Li Z, et al. Dot-product engine for neuromorphic computing: programming 1T1M crossbar to accelerate matrix-vector multiplication. In: Proceedings of the 53rd ACM/EDAC/IEEE Design Automation Conference (DAC), 2016
Hu M, Li H, Wu Q, et al. Hardware realization of BSB recall function using memristor crossbar arrays. In: Proceedings of the 49th Annual Design Automation Conference, 2012. 498–503
Chen Y, Luo T, Liu S, et al. DaDianNao: a machine-learning supercomputer. In: Proceedings of the 47th Annual IEEE/ACM International Symposium on Microarchitecture, Cambridge, 2014. 609–622
Mahajan D, Park J, Amaro E, et al. TABLA: a unified template-based framework for accelerating statistical machine learning. In: Proceedings of IEEE International Symposium on High Performance Computer Architecture (HPCA), 2016. 14–26
Albericio J, Judd P, Hetherington T, et al. Cnvlutin: ineffectual-neuron-free deep neural network computing. In: Proceedings of ACM/IEEE 43rd Annual International Symposium on Computer Architecture (ISCA), 2016. 1–13
Shafiee A, Nag A, Muralimanohar N, et al. ISAAC: a convolutional neural network accelerator with in-situ analog arithmetic in crossbars. In: Proceedings of ACM/IEEE 43rd Annual International Symposium on Computer Architecture (ISCA), 2016
Chi P, Li S, Xu C, et al. PRIME: a novel processing-in-memory architecture for neural network computation in ReRAM-based main memory. In: Proceedings of ACM/IEEE 43rd Annual International Symposium on Computer Architecture (ISCA), 2016
Song L, Qian X, Li H, et al. PipeLayer: a pipelined ReRAM-based accelerator for deep learning. In: Proceedings of IEEE 23rd International Symposium on High Performance Computer Architecture (HPCA), 2017
Liu X, Mao M, Liu B, et al. Reno: a high-efficient reconfigurable neuromorphic computing accelerator design. In: Proceedings of the 52nd ACM/EDAC/IEEE Design Automation Conference (DAC), 2015. 1–6
Pingali K, Nguyen D, Kulkarni M, et al. The tao of parallelism in algorithms. In: Proceedings of ACM Sigplan Notices, 2011. 12–25
Gonzalez J E, Low Y, Gu H, et al. Powergraph: distributed graph-parallel computation on natural graphs. In: Proceedings of the 10th USENIX Conference on Operating Systems Design and Implementation, 2012. 17–30
Malewicz G, Austern M H, Bik A J, et al. Pregel: a system for large-scale graph processing. In: Proceedings of the 2010 ACM SIGMOD International Conference on Management of Data, 2010
Shun J, Blelloch G E. Ligra: a lightweight graph processing framework for shared memory. In: ACM Sigplan Notices, 2013. 135–146
Low Y, Bickson D, Gonzalez J, et al. Distributed GraphLab: a framework for machine learning and data mining in the cloud. Proc VLDB Endow, 2012, 5: 716–727
Ham T J, Wu L, Sundaram N, et al. Graphicionado: a high-performance and energy-efficient accelerator for graph analytics. In: Proceedings of the 49th Annual IEEE/ACM International Symposium on Microarchitecture (MICRO), 2016. 1–13
Lee H, Grosse R, Ranganath R, et al. Convolutional deep belief networks for scalable unsupervised learning of hierarchical representations. In: Proceedings of the 26th Annual International Conference on Machine Learning, 2009
Ciresan D, Meier U, Schmidhuber J, et al. Multi-column deep neural networks for image classification. In: Proceedings of IEEE Conference on Computer Vision and Pattern Recognition, 2012
Ciresan D C, Meier U, Masci J, et al. Flexible, high performance convolutional neural networks for image classification. In: Proceedings of the 22nd International Joint Conference on Artificial Intelligence, 2011
Sermanet P, Chintala S, LeCun Y, et al. Convolutional neural networks applied to house numbers digit classification. In: Proceedings of the 21st International Conference on Pattern Recognition (ICPR2012), 2012
Oquab M, Bottou L, Laptev I, et al. Learning and transferring mid-level image representations using convolutional neural networks. In: Proceedings of IEEE Conference on Computer Vision and Pattern Recognition, 2014
LeCun Y, Boser B, Denker J S, et al. Backpropagation applied to handwritten zip code recognition. Neural Comput, 1989, 1: 541–551
Kim Y. Convolutional neural networks for sentence classification. 2014. ArXiv:1408.5882
Howard A G. Some improvements on deep convolutional neural network based image classification. 2013. ArXiv:1312.5402
Gong Y, Jia Y Q, Leung T, et al. Deep convolutional ranking for multilabel image annotation. 2013. ArXiv:1312.4894
Collobert R, Weston J. A unified architecture for natural language processing: deep neural networks with multitask learning. In: Proceedings of the 25th International Conference on Machine Learning, 2008. 160–167
Abdel-Hamid O, Mohamed A, Jiang H, et al. Applying convolutional neural networks concepts to hybrid NN-HMM model for speech recognition. In: Proceedings of IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2012
Kalchbrenner N, Grefenstette E, Blunsom P, et al. A convolutional neural network for modelling sentences. 2014. ArXiv:1404.2188
Deng L, Hinton G, Kingsbury B. New types of deep neural network learning for speech recognition and related applications: an overview. In: Proceedings of IEEE International Conference on Acoustics, Speech and Signal Processing, 2013
Graves A, Mohamed A, Hinton G. Speech recognition with deep recurrent neural networks. In: Proceedings of IEEE International Conference on Acoustics, Speech and Signal Processing, 2013
LeCun Y, Bottou L, Bengio Y, et al. Gradient-based learning applied to document recognition. Proc IEEE, 1998, 86: 2278–2324
Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition. 2014. ArXiv:1409.1556
Song L, Zhuo Y, Qian X H, et al. GraphR: accelerating graph processing using ReRAM. In: Proceedings of the 24th International Symposium on High-Performance Computer Architecture, 2018
Zheng L, Zhao J, Huang Y, et al. Spara: an energy-efficient ReRAM-based accelerator for sparse graph analytics applications. In: Proceedings of 2020 IEEE International Parallel and Distributed Processing Symposium (IPDPS), 2020. 696–707
Zhu X, Han W, Chen W. Gridgraph: large-scale graph processing on a single machine using 2-level hierarchical partitioning. In: Proceedings of 2015 USENIX Annual Technical Conference (USENIX ATC 15), 2015. 375–386
Zhang M, Zhuo Y, Wang C, et al. Graphp: reducing communication for PIM-based graph processing with efficient data partition. In: Proceedings of IEEE International Symposium on High Performance Computer Architecture (HPCA), 2018. 544–557
Ozdal M M, Yesil S, Kim T, et al. Energy efficient architecture for graph analytics accelerators. In: Proceedings of ACM/IEEE 43rd Annual International Symposium on Computer Architecture (ISCA), 2016. 166–177
Zhuo Y, Wang C, Zhang M, et al. GraphQ: scalable PIM-based graph processing. In: Proceedings of the 52nd International Symposium on Microarchitecture, 2019
Nag A, Balasubramonian R, Srikumar V, et al. Newton: gravitating towards the physical limits of crossbar acceleration. IEEE Micro, 2018, 38: 41–49
Choi S, Jang S, Moon J H, et al. A self-rectifying TaOy/nanoporous TaOx memristor synaptic array for learning and energy-efficient neuromorphic systems. NPG Asia Mater, 2018, 10: 1097–1106
Li C, Belkin D, Li Y, et al. Efficient and self-adaptive in-situ learning in multilayer memristor neural networks. Nat Commun, 2018, 9: 2385
Liu Z, Tang J, Gao B, et al. Neural signal analysis with memristor arrays towards high-efficiency brain-machine interfaces. Nature Commun, 2020, 11: 1–9
Krestinskaya O, Choubey B, James A. Memristive GAN in analog. Sci Report, 2020, 10: 1–14
Song L, Wu Y, Qian X, et al. ReBNN: in-situ acceleration of binarized neural networks in ReRAM using complementary resistive cell. CCF Trans HPC, 2019, 1: 196–208
Bahou A A, Karunaratne G, Andri R, et al. XNORBIN: a 95 TOp/s/W hardware accelerator for binary convolutional neural networks. In: Proceedings of IEEE Symposium in Low-Power and High Speed Chips (COOL CHIPS), 2018
Conti F, Schiavone P D, Benini L. XNOR neural engine: a hardware accelerator IP for 21.6-fJ/op binary neural network inference. IEEE Trans Comput-Aided Des Integr Circ Syst, 2018, 37: 2940–2951
Jafari A, Hosseini M, Kulkarni A, et al. BiNMAC: binarized neural network manycore accelerator. In: Proceedings of Great Lakes Symposium on VLSI, 2018. 443–446
Andri R, Karunaratne G, Cavigelli L, et al. ChewBaccaNN: a flexible 223 TOPS/W BNN accelerator. 2020. arXiv:2005.07137
Kim D, Kung J, Chai S, et al. Neurocube: a programmable digital neuromorphic architecture with high-density 3D memory. In: Proceedings of ACM/IEEE 43rd Annual International Symposium on Computer Architecture (ISCA), 2016. 380–392
Zhuo Y, Chen J, Luo Q, et al. SympleGraph: distributed graph processing with precise loop-carried dependency guarantee. In: Proceedings of the 41st ACM SIGPLAN Conference on Programming Language Design and Implementation, 2020
Teixeira C H, Fonseca A J, Serafini M, et al. Arabesque: a system for distributed graph mining. In: Proceedings of the 25th Symposium on Operating Systems Principles, 2015. 425–440
Wang K, Zuo Z, Thorpe J, et al. RStream: marrying relational algebra with streaming for efficient graph mining on a single machine. In: Proceedings of the 13th USENIX Symposium on Operating Systems Design and Implementation, 2018. 763–782
Mawhirter D, Wu B. Automine: harmonizing high-level abstraction and high performance for graph mining. In: Proceedings of the 27th ACM Symposium on Operating Systems Principles, 2019. 509–523
Jamshidi K, Mahadasa R, Vora K. Peregrine: a pattern-aware graph mining system. In: Proceedings of the 15th European Conference on Computer Systems, 2020. 1–16
Chen X, Dathathri R, Gill G, et al. Pangolin: an efficient and flexible graph mining system on CPU and GPU. 2019. ArXiv:1911.06969
Iyer A P, Liu Z, Jin X, et al. ASAP: fast, approximate graph pattern mining at scale. In: Proceedings of the 13th USENIX Symposium on Operating Systems Design and Implementation, 2018. 745–761
Boyd S. Distributed optimization and statistical learning via the alternating direction method of multipliers. FNT Mach Learn, 2010, 3: 1–122
Ren A, Zhang T, Ye S, et al. ADMM-NN: an algorithm-hardware co-design framework of DNNs using alternating direction methods of multipliers. In: Proceedings of the 24th International Conference on Architectural Support for Programming Languages and Operating Systems, 2019. 925–938
Niu W, Ma X, Lin S, et al. PatDNN: achieving real-time DNN execution on mobile devices with pattern-based weight pruning. In: Proceedings of the 25th International Conference on Architectural Support for Programming Languages and Operating Systems, 2020
Song L, Mao J, Zhuo Y, et al. HyPar: towards hybrid parallelism for deep learning accelerator array. In: Proceedings of the 25th IEEE International Symposium on High-Performance Computer Architecture, 2019
Song L, Chen F, Zhuo Y, et al. AccPar: tensor partitioning for heterogeneous deep learning accelerators. In: Proceedings of the 26th IEEE International Symposium on High-Performance Computer Architecture, 2020
Harrison P, Valavanis A. Quantum Wells, Wires and Dots: Theoretical and Computational Physics of Semiconductor Nanostructures. Hoboken: John Wiley & Sons, 2016
Jensen F. Introduction to Computational Chemistry. Hoboken: John Wiley & Sons, 2017
Chapman T, Avery P, Collins P, et al. Accelerated mesh sampling for the hyper reduction of nonlinear computational models. Int J Numer Meth Engng, 2017, 109: 1623–1654
Nobile M S, Cazzaniga P, Tangherloni A, et al. Graphics processing units in bioinformatics, computational biology and systems biology. Brief Bioinform, 201, 18: 870–885
Arioli M, Demmel J W, Duff I S. Solving sparse linear systems with sparse backward error. SIAM J Matrix Anal Appl, 1989, 10: 165–190
Saad Y. Iterative methods for sparse linear systems. SIAM, 2003, 82
Fan Z, Qiu F, Kaufman A, et al. GPU cluster for high performance computing. In: Proceedings of the 2004 ACM/IEEE Conference on Supercomputing, 2004. 47
Song F, Tomov S, Dongarra J. Enabling and scaling matrix computations on heterogeneous multi-core and multi-GPU systems. In: Proceedings of the 26th ACM International Conference on Supercomputing, 2012. 365–376
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Qian, X. Graph processing and machine learning architectures with emerging memory technologies: a survey. Sci. China Inf. Sci. 64, 160401 (2021). https://doi.org/10.1007/s11432-020-3219-6
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1007/s11432-020-3219-6