
Abstract
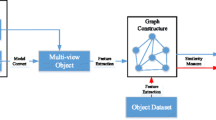
The rapid development of computer vision has led to an increasing amount of 3D data, such as multiple views and point clouds, which are widely used in 3D object recognition and retrieval. Intuitively, the quality of 3D data is the most crucial factor that directly affects the performance of 3D applications. However, how to evaluate the 3D data quality, especially the multi-view data quality, is still an open question. To tackle this issue, we propose an entropy-based multi-view information quantification model (MV-Info model) to quantitatively evaluate the multi-view data information. Our proposed MV-Info model consists of hierarchical data module, feature generation module, and quantitative calculation module. Besides, it considers the information entropy theory for more reasonable quantification results. In our method, how much information we can observe from a group of views can be quantified, which can be used to support 3D recognition and retrieval. We also designed a series of experiments to evaluate the effectiveness of the proposed model. The experimental results demonstrate the rationality and validity of the proposed model.
Similar content being viewed by others

References
Anderson R, Gallup D, Barron J T, et al. Jump: Virtual reality video. ACM Trans Graph, 2016, 35: 1–13
Xu X B, Wang Z, Deng Y M. A software platform for vision-based UAV autonomous landing guidance based on markers estimation. Sci China Tech Sci, 2019, 62: 1825–1836
Wang G, Shi Z C, Shang Y, et al. Precise monocular vision-based pose measurement system for lunar surface sampling manipulator. Sci China Tech Sci, 2019, 62: 1783–1794
Jaderberg M, Czarnecki W M, Dunning I, et al. Human-level performance in 3D multiplayer games with population-based reinforcement learning. Science, 2019, 364: 859–865
Bustos B, Keim D A, Saupe D, et al. Feature-based similarity search in 3D object databases. ACM Comput Surv, 2005, 37: 345–387
Maturana D, Scherer S. Voxnet: A 3D convolutional neural network for real-time object recognition. In: Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems. Hamburg, 2015. 922–928
Wu Z R, Song S, Khosla A, et al. 3D shapenets: A deep representation for volumetric shapes. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Boston, 2015. 1912–1920
Garcia-Garcia A, Gomez-Donoso F, Garcia-Rodriguez J, et al. Pointnet: A 3D convolutional neural network for real-time object class recognition. In: Proceedings of the International Joint Conference on Neural Networks. Vancouver, 2016. 1578–1584
Wu Z Z, Chen H C, Du S Y, et al. Correntropy based scale ICP algorithm for robust point set registration. Pattern Recogn, 2019, 93: 14–24
Li W J, Bebis G, Bourbakis N G. 3-D object recognition using 2-D views. IEEE Trans Image Process, 2008, 17: 2236–2255
Deng J, Dong W, Socher R, et al. Imagenet: A large-scale hierarchical image database. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Miami, 2009. 248–255
Shilane P, Min P, Kazhdan M, et al. The princeton shape benchmark. In: Proceedings of the Shape Modeling Applications. Genova, 2004. 167–178
Daras P, Axenopoulos A. A 3D shape retrieval framework supporting multimodal queries. Int J Comput Vis, 2010, 89: 229–247
Feng Y F, Zhang Z Z, Zhao X B, et al. Gvcnn: Group-view convolutional neural networks for 3D shape recognition. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, 2018. 264–272
Kanezaki A, Matsushita Y, Nishida Y. Rotationnet: Joint object categorization and pose estimation using multiviews from unsupervised viewpoints. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, 2018. 5010–5019
Ohbuchi R, Osada K, Furuya T, et al. Salient local visual features for shape-based 3D model retrieval. In: Proceedings of the IEEE International Conference on Shape Modeling and Applications. Stony Brook, 2008. 93–102
Ansary T F, Daoudi M, Vandeborre J P. A Bayesian 3-D search engine using adaptive views clustering. IEEE Trans Multimedia, 2007, 9: 78–88
Gao Y, Zhang Z Z, Lin H J, et al. Hypergraph learning: Methods and practices. IEEE Trans Pattern Anal Mach Intell, 2020, doi: https://doi.org/10.1109/TPAMI.2020.3039374
Zhang Z Z, Lin H J, Zhao X B, et al. Inductive multi-hypergraph learning and its application on view-based 3D object classification. IEEE Trans Image Process, 2018, 27: 5957–5968
Shannon C E. A mathematical theory of communication. Bell Syst Tech J, 1948, 27: 379–423
Vazquez P P, Feixas M, Sbert M, et al. Viewpoint selection using viewpoint entropy. Vision Model Vis, 2001, 1: 273–280
Gao Y, Dai Q H. View-Based 3D Object Retrieval. San Francisco: Morgan Kaufmann, 2014
Ansary T F, Vandeborre J P, Mahmoudi S, et al. A bayesian framework for 3D models retrieval based on characteristic views. In: Proceedings of the 2nd International Symposium on 3D Data Processing, Visualization, and Transmission. Washington, 2004. 139–146
Ohbuchi R, Furuya T. Scale-weighted dense bag of visual features for 3D model retrieval from a partial view 3D model. In: Proceedings of the 12th International Conference on Computer Vision Workshops. Kyoto, 2009. 63–70
Furuya T, Ohbuchi R. Dense sampling and fast encoding for 3D model retrieval using bag-of-visual features. In: Proceedings of the ACM International Conference on Image and Video Retrieval. Santorini, 2009. 1–8
Chen D Y, Tian X P, Shen Y T, et al. On visual similarity based 3D model retrieval. Comput Graph Forum, 2003, 22: 223–232
Shih J L, Lee C H, Wang J T. A new 3D model retrieval approach based on the elevation descriptor. Pattern Recogn, 2007, 40: 283–295
Su H, Maji S, Kalogerakis E, et al. Multi-view convolutional neural networks for 3D shape recognition. In: Proceedings of the IEEE International Conference on Computer Vision. Santiago, 2015. 945–953
Khotanzad A, Hong Y H. Invariant image recognition by Zernike moments. IEEE Trans Pattern Anal Mach Intell, 1990, 12: 489–497
Bracewell R N. The Fourier Transform and Its Applications. New York: McGraw-Hill, 1986
Krizhevsky A, Sutskever I, Hinton G. Imagenet classification with deep convolutional neural networks. In: Proceedings of the 25th International Conference on Neural Information Processing Systems. Lake Tahoe, 2012. 1097–1105
Cheng X, Rao Z F, Chen Y L, et al. Explaining knowledge distillation by quantifying the knowledge. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020. 12925–12935
Phong B T. Illumination for computer generated pictures. Commun ACM, 1975, 18: 311–317
Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition. 2014, ArXiv: 1409.1556
Author information
Authors and Affiliations
Corresponding author
Additional information
This work was supported by the SGCC Science and Technology Project (Grant No. 52020119000A).
Rights and permissions
About this article

Cite this article
Cheng, J., Bie, L., Zhao, X. et al. Visual information quantification for object recognition and retrieval. Sci. China Technol. Sci. 64, 2618–2626 (2021). https://doi.org/10.1007/s11431-021-1930-8
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11431-021-1930-8