
Abstract
In this paper we propose a simple estimator for unbalanced repeated measures design models where each unit is observed at least once in each cell of the experimental design. The estimator does not require a model of the error covariance structure. Thus, circularity of the error covariance matrix and estimation of correlation parameters and variances are not necessary. Together with a weak assumption about the reason for the varying number of observations, the proposed estimator and its variance estimator are unbiased. As an alternative to confidence intervals based on the normality assumption, a bias-corrected and accelerated bootstrap technique is considered. We also propose the naive percentile bootstrap for Wald-type tests where the standard Wald test may break down when the number of observations is small relative to the number of parameters to be estimated. In a simulation study we illustrate the properties of the estimator and the bootstrap techniques to calculate confidence intervals and conduct hypothesis tests in small and large samples under normality and non-normality of the errors. The results imply that the simple estimator is only slightly less efficient than an estimator that correctly assumes a block structure of the error correlation matrix, a special case of which is an equi-correlation matrix. Application of the estimator and the bootstrap technique is illustrated using data from a task switch experiment based on an experimental within design with 32 cells and 33 participants.
Similar content being viewed by others

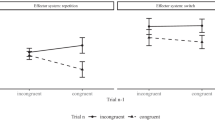

Notes
Although the effect of Task was not included in our hypotheses, the significant effect is not surprising: Responding to the location of a stimulus by hitting a spatially corresponding key is known to yield particularly fast responses (e.g., Fitts & Deininger, 1954; overview in Proctor & Vu, 2006), widely regarded as constituting a special kind of facilitated (“compatible” or “automatic”) processing.
References
Allport, D. A., Styles, E. A., & Hsieh, S. (1994). Shifting intentional set: Exploring the dynamic control of tasks. In C. Umilta & M. Moscovitch (Eds.), Attention and performance XV: Conscious and nonconscious information processing (pp. 421–452). Cambridge, MA: MIT Press.
Bond, S., & Windmeijer, F. (2005). Reliable inference for GMM estimators? Finite sample properties of alternative test procedures in linear panel models. Econometric Reviews, 24(1), 1–37.
Bradley, R. C. (1981). Central limit theorems under weak dependence. Journal of Multivariate Analysis, 11, 1–16.
Cheng, G., Yu, Z., & Huang, J. Z. (2013). The cluster bootstrap consistency in generalized estimating equations. Journal of Multivariate Analysis, 115, 33–47.
Chung, K. L. (2001). A course in probability theory (3rd ed.). San Diego: Academic Press.
Efron, B., & Tibshirani, R. J. (1993). An introduction to the bootstrap. New York: Chapman & Hall.
Fitts, P. M., & Deininger, R. L. (1954). S-R compatibility: Correspondence among paired elements within stimulus and response codes. Journal of Experimental Psychology, 48, 483–492.
Greenhouse, S. W., & Geisser, S. (1959). On methods in the analysis of profile data. Psychometrika, 24(2), 95–112.
Hall, P., & Horowitz, J. L. (1996). Bootstrap critical values for tests based on generalized-method-of-moments estimators. Econometrica, 64(4), 891–916.
Huynh, H., & Feldt, L. S. (1976). Estimation of the Box correction for degrees of freedom from sample data in randomized block and split-plot designs. Journal of Educational Statistics, 1(1), 69–82.
Kiesel, A., Steinhauser, M., Wendt, M., Falkenstein, M., Jost, K., Philipp, A. M., et al. (2010). Control and interference in task switching—A review. Psychological Bulletin, 136, 849–874.
Klass, M., & Teicher, H. (1987). The central limit theorem for exchangeable random variables without moments. The Annals of Probability, 15, 138–151.
Liang, K.-Y., & Zeger, S. L. (1986). Longitudinal data analysis using generalized linear models. Biometrika, 73(1), 13–22.
MacKinnon, J. G. (2002). Bootstrap inference in econometrics. Canadian Journal of Economics, 35, 615–645.
Mauchly, J. W. (1940). Significance test for sphericity of a normal \(n\)-variate distribution. Annals of Mathematical Statistics, 11, 204–209.
McDonald, R. P. (1976). The McDonald–Swaminathan matrix calculus: Clarifications, extensions, and illustrations. General Systems, 21, 87–94.
McDonald, R. P., & Swaminathan, H. (1973). A simple calculus with applications to multivariate analysis. General Systems, 18, 37–54.
Meiran, N. (1996). Reconfiguration of processing mode prior to task performance. Journal of Experimental Psychology: Learning, Memory, and Cognition, 22, 1423–1442.
Newey, W. H., & McFadden, D. (1994). Large sample estimation and hypothesis testing. In R. F. Engle & D. L. McFadden (Eds.), Handbook of econometrics (Vol. IV, pp. 2111–2245). Amsterdam: Elsevier.
Newman, C. H. (1984). Asymptotic independence and limit theorems for positively and negatively dependent random variables. Inequalities in Statistics and Probability, IMS Lecture Notes-Monograph Series, 5, 127–140.
Proctor, R. W., & Vu, K.-P. L. (2006). Stimulus-response compatibility principles: Data, theory, and application. Boca Raton, FL: CRC Press.
R Core Team. (2018). R: A language and environment for statistical computing. Vienna: R Foundation for Statistical Computing.
Robins, J. M., Rotnitzky, A., & Zhao, L. P. (1995). Analysis of semiparametric regression models for repeated outcomes in the presence of missing data. Journal of the American Statistical Association, 90(429), 106–121.
Rogers, R. D., & Monsell, S. (1995). Costs of a predictable switch between simple cognitive tasks. Journal of Experimental Psychology: General, 124, 207–231.
Rotnitzky, A., & Jewell, N. P. (1990). Hypothesis testing of regression parameters in semiparametric generalized linear models for cluster correlated data. Biometrika, 77(3), 485–497.
Schneider, D. (2015). Attentional control of response selection in task switching. Journal of Experimental Psychology: Human Perception and Performance, 41, 1315–1324.
Spiess, M. (2006). Estimation of a two-equation panel model with mixed continuous and ordered categorical outcomes and missing data. Applied Statistics, 55(4), 525–538.
Spiess, M., & Hamerle, A. (1996). On the properties of GEE estimators in the presence of invariant covariates. Biometrical Journal, 38(8), 931–940.
Swaminathan, H. (1976). Matrix calculus for functions of partitioned matrices. General Systems, 21, 95–98.
Vandierendonck, A., Liefooghe, B., & Verbruggen, F. (2010). Task switching: Interplay of reconfiguration and interference control. Psychological Bulletin, 136, 601–626.
Wilcox, R. R. (2017). Introduction to robust estimation and hypothesis testing (4th ed.). San Diego: Academic Press.
Winer, B. J., Brown, D. R., & Michels, K. M. (1991). Statistical principles in experimental design (3rd ed.). New York: McGraw-Hill.
Zyskind, G. (1967). On canonical forms, non-negative covariance matrices and best and simple least squares linear estimators in linear models. The Annals of Mathematical Statistics, 38, 1092–1109.
Author information
Authors and Affiliations
Corresponding author
Additional information
The authors thank Aquiles Luna-Rodriguez for programming the experimental software and Marvin Gensicke for collecting the data.
Electronic supplementary material
Below is the link to the electronic supplementary material.
Appendices
A Simplifications
Given \(\mathbf{X }_i = \mathbf{D }_i \mathbf{Z }\) and \(\mathbf{D }^T_i \widetilde{\mathbf{V }}^{-1/2}_i = \mathbf{V }^{-1/2} \mathbf{D }^T_i \), (5) simplifies to
The inverse of \(\mathbf{R }_i\) is given by the following
Theorem 1
Let \(0 \le \rho _1 \le \rho _2 < 1\) and \(T_{i,k}>0\), then the inverse of
is
where \(\mathbf{I }_{T_i}\) is the \((T_i \times T_i)\) identity matrix, \(\mathbf{D }_i = \mathrm {bdiag}(\mathbf{1 }_{T_{i,1}}, \ldots , \mathbf{1 }_{T_{i,K}})\), \(\mathbf{J }_{T_{i}}\) is a \((T_i \times T_i)\) matrix of ones, \(\mathbf{a }_i = (a_{i,1} , \ldots , a_{i,K})^T\) and \(a_{i,k} = 1/(1-\rho _2 + (\rho _2 - \rho _1) T_{i,k})\).
Proof
Note that for \(0 \le \rho _1 \le \rho _2 < 1\) and \(T_{i,k}>0\) we have \(1-\rho _2 + (\rho _2 - \rho _1) T_{i,k} \ne 0\): Let \(\rho _2 = \rho _1 +\delta \), where \(\delta \ge 0\). Then \(1-\rho _2 + (\rho _2 - \rho _1) T_{i,k} = 1 - \rho _1 + \delta ( T_{i,k}-1) > 0\).
It is shown that \(\mathbf{F }_i \mathbf{R }_i = \mathbf{R }_i\mathbf{F }_i= \mathbf{I }_{T,i}\). Let \(d_{i,k} = T_{i,k} a_{i,k}\), \(\mathbf{d } = (d_{i,1}, \ldots , d_{i,K})^T\) and note that \(\mathbf{D }^T_i \mathbf{D }_i = \text {diag}(T_{i,1}, \ldots ,T_{i,K})\), \(\mathbf{D }^T_i \mathbf{J }_{T_i} = \text {diag}(T_{i,1}, \ldots , T_{i,K})\mathbf{J }_{K, T_i}\), \((1-\rho _2) \mathbf{a }^T_i + (\rho _2-\rho _1)\mathbf{d }^T_i = \mathbf{1 }^T_{K}\) and \(\mathbf{D }_i \mathbf{J }_{K, T_i} = \mathbf{J }_{T_i}\). Then
Further, using the results from above,
and
Thus, \(\mathbf{F }_i\mathbf{R }_i = \mathbf{I }_{T,i}\). \(\mathbf{R }_i \mathbf{F }_i = \mathbf{I }_{T,i}\) follows from the symmetry of \(\mathbf{R }_i\). \(\square \)
Further note that
If \(\mathbf{Z }\) is regular, then its inverse exists and simplification of (7) and (8) leads to (10) and (11). On the other hand, we may write (5) as
Taking the mean of \(\hat{\varvec{\theta }}^{(0)}\) with respect to \(\mathbf{y }\) conditional on \(\mathbf{Z }\), noting that \(E(\bar{\mathbf{y }}_i | \mathbf{Z }, \mathbf{r }_i) = E ( \bar{\mathbf{y }}_i | \mathbf{Z } )\) for all i, which follows from assuming that \(\Pr (\mathbf{r } | \mathbf{Z }) = \Pr (\mathbf{r }| \mathbf{Z } , \tilde{\mathbf{y }})\) for all possible \(\tilde{\mathbf{y }}\) and \(\mathbf{r }\), and \( E(\bar{\mathbf{y }}_i | \mathbf{Z }) = \mathbf{Z }\varvec{\theta }_0\) for all i [see model (1)],
Therefore, replacing \(E(\bar{\mathbf{y }}_i | \mathbf{Z })\) by \(\bar{\mathbf{y }} = \sum _i \bar{\mathbf{y }}_i / n\), we can estimate \(\varvec{\theta }\) as given by (12) in Sect. 3. Note that \(\hat{\varvec{\theta }}_{\text {m}}\) is unbiased. From \(\text {Var}(\hat{\varvec{\theta }}_{\text {m}}|\mathbf{Z }) = E(\text {Var}(\hat{\varvec{\theta }}_{\text {m}}|\mathbf{Z },\mathbf{r })) + \text {Var}(E(\hat{\varvec{\theta }}_{\text {m}}|\mathbf{Z },\mathbf{r }))\) and \(\text {Var}(E(\hat{\varvec{\theta }}_{\text {m}}|\mathbf{Z },\mathbf{r })) = \mathbf{0 }\), we have \(\text {Var}(\hat{\varvec{\theta }}_{\text {m}}|\mathbf{Z }) = E(\text {Var}(\hat{\varvec{\theta }}_{\text {m}}|\mathbf{Z },\mathbf{r }))\). Thus, the variance can be written as
estimated by (13). From (14) and (15) it follows that \(\hat{\varvec{\theta }}_{\text {m}}\) is consistent.
For a comparison of linear combinations of \(\hat{\varvec{\theta }}_{\text {m}}\) with linear combinations of other unbiased estimators linear in \(\bar{\mathbf{y }} = n^{-1} \sum _i \mathbf{y }_i\) and marginal with respect to \(\mathbf{r }\), consider \(\hat{\varvec{\vartheta }}=\mathbf{A }^T \bar{\mathbf{y }}\). The matrix \(\mathbf{A }\) may account for dependencies within \(\bar{\mathbf{y }}\). Unbiasedness of \(\hat{\varvec{\vartheta }}\) implies \(E(\hat{\varvec{\vartheta }} | \mathbf{Z }) = \mathbf{A }^T E(\bar{\mathbf{y }} | \mathbf{Z }) = \mathbf{A }^T \mathbf{Z } \varvec{\theta }_0 = \varvec{\theta }_0\) and thus \( \mathbf{A }^{T} = \mathbf{Z }^{-1}\). Hence, there is no other unbiased estimator which is linear in \(\bar{\mathbf{y }}\) than \(\hat{\varvec{\theta }}_{\text {m}}\) that could be more efficient.
Another interesting point is a comparison of the variances of two estimators (7) and (12) if the “working” covariance matrix is correctly specified, i.e., \(\mathbf{W }_i =\varvec{\Sigma }_i\) for all i. Defining random variables
and noting that the difference
is positive semi-definite, implies that (7) is asymptotically at least as efficient as (12).
B Estimators for Variances and Correlations
The variances as well as the correlations in \(\mathbf{W }_i\) are unknown. To calculate \(\hat{\varvec{\theta }}\) and \(\widehat{\text {Var}}(\hat{\varvec{\theta }})\) we therefore have to estimate \(\sigma ^2_{k}\), \(k=1,\ldots ,K\) , \(\rho _1\) and \(\rho _2\). This can be done by solving moment conditions as well, i.e., solving
\(\sigma _{k,k'}\) are the covariances of observations in the k and \(k'\)th cells, \(\mathbf{G }_i = \text {bdiag}(\mathbf{I }_K,\mathbf{Q }_i)\)
and \(\text {vec}(\mathbf{A })\) stacks the m rows of the \((m \times p)\) matrix \(\mathbf{A }\) as \((p \times 1)\) column vectors over each other to form an \((mp \times 1)\) column vector (Swaminathan, 1976). For the derivations we use the calculus of McDonald (1976), McDonald & Swaminathan (1973) and Swaminathan (1976). These estimating equations are based on the assumption that the differences \(((y_{i,k,t}-\mathbf{z }^T_k \hat{\varvec{\theta }})(y_{i,k',t'}-\mathbf{z }^T_k \hat{\varvec{\theta }}) - \hat{\zeta })\), where \(\hat{\zeta }\) is one of \(\hat{\sigma }^2_{k}\), \(\hat{\rho }_1\) and \(\hat{\rho }_2\), are linearly independent. If this is not true, then the estimators for variances and correlations are not (asymptotically) efficient. However this is not necessary for \(\hat{\varvec{\theta }}\) to be (asymptotically) efficient (Newey & McFadden, 1994). Solving these estimating equations gives the explicit solutions for \(\sigma ^2_k\), \(\rho _1\) and \(\rho _2\) presented in Sect. 3.
C Counter Example
One of the necessary and sufficient conditions in Theorem 2 of Zyskind (1967) under which the simple linear least squares estimator is also a best linear unbiased estimator is that \(\varvec{\Sigma }\mathbf{P }=\mathbf{P }\varvec{\Sigma }\) is symmetric, where \(\varvec{\Sigma }=\text {bdiag}(\varvec{\Sigma }_1,\ldots ,\varvec{\Sigma }_n)\), \(\mathbf{P }= \mathbf{X }(\mathbf{X }^T \mathbf{X })^{-1} \mathbf{X }^T\) and \(\mathbf{X } = (\mathbf{X }^T_1,\ldots ,\mathbf{X }^T_n)^T\).
In the following, we will show that this does not hold for the design and the covariance matrix given in Sect. 2. Let \(\mathbf{D } = (\mathbf{D }^T_1, \ldots ,\mathbf{D }^T_n)^T\). Then \(\mathbf{X } = \mathbf{D } \mathbf{Z }\) and \(\mathbf{P } = \mathbf{D }\mathbf{Z } (\mathbf{Z }^T \mathbf{D }^T \mathbf{D } \mathbf{Z })^{-1} \mathbf{Z }^T \mathbf{D }^T\). However, \(\mathbf{D }^T \mathbf{D } = \sum _i \mathbf{D }^T_i \mathbf{D }_i = \sum _i \text {diag}(T_{i,1}, \ldots , T_{i,K})\) and therefore \(\mathbf{P } = \mathbf{D } (\sum _i \mathbf{D }^T_i \mathbf{D }_i)^{-1} \mathbf{D }^T\), since \(\mathbf{Z }\) is regular. \(\mathbf{P }\) is a partitioned matrix with matrices \(\mathbf{P }_{i,j}=\text {bdiag}(T^{-1}_1 \mathbf{J }_{T_{i,1},T_{j,1}}, \ldots , T^{-1}_K \mathbf{J }_{T_{i,K},T_{j,K}})\), where \(i,j=1,\ldots ,n\).
On the other hand, \(\varvec{\Sigma } = \text {bdiag}( \varvec{\Sigma }_1 , \ldots , \varvec{\Sigma }_n )\), where \(\varvec{\Sigma }_i = \widetilde{\mathbf{V }}^{1/2}_i \mathbf{R }_i \widetilde{\mathbf{V }}^{1/2}_i\), see Sect. 2. Thus, \(\varvec{\Sigma }\mathbf{P } \) is a partitioned matrix as well, with matrices
which are again partitioned matrices with entries
For symmetry of \(\varvec{\Sigma }\mathbf{P }\) to hold, \(\mathbf{A }_{i,j}=\mathbf{A }_{j,i}^T\) and thus \(\mathbf{B }_{k,l}^{i,j} = (\mathbf{B }_{l,k}^{j,i})^T \) must hold for all i, j, k, l. Although this obviously holds if \(T_{i,k}=T_{j,k}\) for all i, j, k, l, it does not hold if the number of observations varies.
Rights and permissions
About this article

Cite this article
Spiess, M., Jordan, P. & Wendt, M. Simplified Estimation and Testing in Unbalanced Repeated Measures Designs. Psychometrika 84, 212–235 (2019). https://doi.org/10.1007/s11336-018-9620-2
Received:
Revised:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11336-018-9620-2