
Abstract
Controversy measurement on social media plays an important part in understanding public opinion. Various topics are frequently hotly debated on social media platforms including Twitter and Sina Weibo. People sometimes use offensive or sarcastic language to convey their opinions about a topic or a source post, which might spark heated discussions and controversy towards related topics. Recent researches take controversy detection as a binary classification problem with two labels: controversy or non-controversy. The reason might be lacking a comprehensive understanding of why the controversy happened and a specific imagination of how it will be used in the downstream tasks. However, we believe that the degree of controversy courted by posts or topics in a real scenario varied. And fine-grained measurement of controversy will be beneficial to public sentiment identification, influence assessment and other social network analysis tasks. We also notice that the existing benchmarks of controversy detection are not applicable for fine-grained topic-level controversy measurement. In this paper, we present ProsCons, a large-scale comprehensive Chinese dataset that includes 245 topics and 32,667 posts with pro, con or neutral stances. Based on that, we design a controversy measurement framework for measuring the controversy intensity that topics sparked. This framework considers the degree of antagonism in terms of stance and sentiment, as well as the irrational degree (offensive or sarcasm) of a post to compute a controversy intensity. ProsCons provides a new benchmark for Chinese stance detection, offensive language and sarcasm detection, contributing to the multi-task learning of them. We conduct extensive experiments on ProsCons and provide baselines for these tasks. The experimental results highlight the challenges of the aforementioned tasks based on the ProsCons.






Similar content being viewed by others
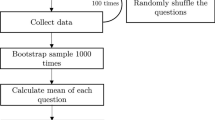


Availability of data and materials
Please request the ProsCons dataset at wanghaiyang19@nudt.edu.cn. X-stance can be accessed in http://doi.org/10.5281/zenodo.3831317. COVID-19-Stance can be accessed in https://github.com/kglandt/stance-detection-in-covid-19-tweets.
Notes
Please request the ProsCons dataset at wanghaiyang19@nudt.edu.cn.
The analysis in this section is limited and the heuristic inference based on the ProsCons dataset only.
References
Zhong, L., Cao, J., Sheng, Q., Guo, J., Wang, Z.: Integrating semantic and structural information with graph convolutional network for controversy detection. In: Jurafsky, D., Chai, J., Schluter, N., Tetreault, J.R. (eds.) Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, ACL 2020, Online, July 5-10, 2020, pp. 515–526 (2020). https://doi.org/10.18653/v1/2020.acl-main.49
Dori-Hacohen, S.: Controversy analysis and detection (2017)
Rethmeier, N., Hübner, M., Hennig, L.: Learning comment controversy prediction in web discussions using incidentally supervised multi-task cnns. In: Balahur, A., Mohammad, S.M., Hoste, V., Klinger, R. (eds.) Proceedings of the 9th Workshop on Computational Approaches to Subjectivity, Sentiment and Social Media Analysis, WASSA@EMNLP 2018, Brussels, Belgium, October 31, 2018, pp. 316–321 (2018). https://doi.org/10.18653/v1/w18-6246
Garimella, K., Morales, G.D.F., Gionis, A., Mathioudakis, M.: Quantifying controversy on social media. ACM Transactions on Social Computing 1(1), 1–27 (2018)
Hessel, J., Lee, L.: Something’s brewing! early prediction of controversy-causing posts from discussion features. In: Burstein, J., Doran, C., Solorio, T. (eds.) Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2019, Minneapolis, MN, USA, June 2-7, 2019, Volume 1 (Long and Short Papers), pp. 1648–1659 (2019). https://doi.org/10.18653/v1/n19-1166
Addawood, A., Rezapour, R., Abdar, O., Diesner, J.: Telling apart tweets associated with controversial versus non-controversial topics. In: Hovy, D., Volkova, S., Bamman, D., Jurgens, D., O’Connor, B., Tsur, O., Dogruöz, A.S. (eds.) Proceedings of the Second Workshop on NLP and Computational Social Science, NLP+CSS@ACL 2017, Vancouver, Canada, August 3, 2017, pp. 32–41 (2017). https://doi.org/10.18653/v1/w17-2905
Wang, Z., Wang, J., Guo, Y., Gong, Z.: Zero-shot node classification with decomposed graph prototype network. In: Zhu, F., Ooi, B.C., Miao, C. (eds.) KDD ’21: The 27th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Virtual Event, Singapore, August 14-18, 2021, pp. 1769–1779 (2021). https://doi.org/10.1145/3447548.3467230
Wang, C., Wang, C., Wang, Z., Ye, X., Yu, P.S.: Edge2vec: Edge-based social network embedding. ACM Trans. Knowl. Discov. Data 14(4), 45–14524 (2020). DOI: 10.1145/3391298
Mohammad, S.M., Kiritchenko, S., Sobhani, P., Zhu, X., Cherry, C.: Semeval-2016 task 6: Detecting stance in tweets. In: Bethard, S., Cer, D.M., Carpuat, M., Jurgens, D., Nakov, P., Zesch, T. (eds.) Proceedings of the 10th International Workshop on Semantic Evaluation, SemEval@NAACL-HLT 2016, San Diego, CA, USA, June 16-17, 2016, pp. 31–41 (2016). https://doi.org/10.18653/v1/s16-1003
Sobhani, P., Inkpen, D., Zhu, X.: A dataset for multi-target stance detection. In: Lapata, M., Blunsom, P., Koller, A. (eds.) Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics, EACL 2017, Valencia, Spain, April 3-7, 2017, Volume 2: Short Papers, pp. 551–557 (2017). https://doi.org/10.18653/v1/e17-2088
Allaway, E., McKeown, K.R.: Zero-shot stance detection: A dataset and model using generalized topic representations. In: Webber, B., Cohn, T., He, Y., Liu, Y. (eds.) Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing, EMNLP 2020, Online, November 16-20, 2020, pp. 8913–8931 (2020). https://doi.org/10.18653/v1/2020.emnlp-main.717
Küçük, D., Can, F.: Stance detection: A survey. ACM Comput. Surv. 53(1), 12–11237 (2020). DOI: 10.1145/3369026
Liang, B., Chen, Z., Gui, L., He, Y., Yang, M., Xu, R.: Zero-shot stance detection via contrastive learning. In: Laforest, F., Troncy, R., Simperl, E., Agarwal, D., Gionis, A., Herman, I., Médini, L. (eds.) WWW ’22: The ACM Web Conference 2022, Virtual Event, Lyon, France, April 25 - 29, 2022, pp. 2738–2747 (2022). https://doi.org/10.1145/3485447.3511994
Allaway, E., Srikanth, M., McKeown, K.R.: Adversarial learning for zero-shot stance detection on social media. In: Toutanova, K., Rumshisky, A., Zettlemoyer, L., Hakkani-Tür, D., Beltagy, I., Bethard, S., Cotterell, R., Chakraborty, T., Zhou, Y. (eds.) Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2021, Online, June 6-11, 2021, pp. 4756–4767 (2021). https://doi.org/10.18653/v1/2021.naacl-main.379
Zhu, Q., Liang, B., Sun, J., Du, J., Zhou, L., Xu, R.: Enhancing zero-shot stance detection via targeted background knowledge. In: Amigó, E., Castells, P., Gonzalo, J., Carterette, B., Culpepper, J.S., Kazai, G. (eds.) SIGIR ’22: The 45th International ACM SIGIR Conference on Research and Development in Information Retrieval, Madrid, Spain, July 11 - 15, 2022, pp. 2070–2075 (2022). https://doi.org/10.1145/3477495.3531807
Zhou, X., Yong, Y., Fan, X., Ren, G., Song, Y., Diao, Y., Yang, L., Lin, H.: Hate speech detection based on sentiment knowledge sharing. In: Zong, C., Xia, F., Li, W., Navigli, R. (eds.) Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, ACL/IJCNLP 2021, (Volume 1: Long Papers), Virtual Event, August 1-6, 2021, pp. 7158–7166 (2021). https://doi.org/10.18653/v1/2021.acl-long.556
Xu, R., Zhou, Y., Wu, D., Gui, L., Du, J., Xue, Y.: Overview of NLPCC shared task 4: Stance detection in chinese microblogs. In: Lin, C., Xue, N., Zhao, D., Huang, X., Feng, Y. (eds.) Natural Language Understanding and Intelligent Applications - 5th CCF Conference on Natural Language Processing and Chinese Computing, NLPCC 2016, and 24th International Conference on Computer Processing of Oriental Languages, ICCPOL 2016, Kunming, China, December 2-6, 2016, Proceedings. Lecture Notes in Computer Science, vol. 10102, pp. 907–916 (2016). https://doi.org/10.1007/978-3-319-50496-4_85
Murakami, A., Raymond, R.: Support or oppose? classifying positions in online debates from reply activities and opinion expressions. In: Huang, C., Jurafsky, D. (eds.) COLING 2010, 23rd International Conference on Computational Linguistics, Posters Volume, 23-27 August 2010, Beijing, China, pp. 869–875 (2010). https://aclanthology.org/C10-2100/
Vamvas, J., Sennrich, R.: X -stance: A multilingual multi-target dataset for stance detection. In: Ebling, S., Tuggener, D., Hürlimann, M., Cieliebak, M., Volk, M. (eds.) Proceedings of the 5th Swiss Text Analytics Conference and the 16th Conference on Natural Language Processing, SwissText/KONVENS 2020, Zurich, Switzerland, June 23-25, 2020 [online Only]. CEUR Workshop Proceedings, vol. 2624 (2020). http://ceur-ws.org/Vol-2624/paper9.pdf
Glandt, K., Khanal, S., Li, Y., Caragea, D., Caragea, C.: Stance detection in COVID-19 tweets. In: Zong, C., Xia, F., Li, W., Navigli, R. (eds.) Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, ACL/IJCNLP 2021, (Volume 1: Long Papers), Virtual Event, August 1-6, 2021, pp. 1596–1611 (2021). https://doi.org/10.18653/v1/2021.acl-long.127
Conforti, C., Berndt, J., Pilehvar, M.T., Giannitsarou, C., Toxvaerd, F., Collier, N.: Will-they-won’t-they: A very large dataset for stance detection on twitter. In: Jurafsky, D., Chai, J., Schluter, N., Tetreault, J.R. (eds.) Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, ACL 2020, Online, July 5-10, 2020, pp. 1715–1724 (2020). https://doi.org/10.18653/v1/2020.acl-main.157
Deng, J., Zhou, J., Sun, H., Zheng, C., Mi, F., Meng, H., Huang, M.: COLD: A benchmark for chinese offensive language detection. In: Goldberg, Y., Kozareva, Z., Zhang, Y. (eds.) Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, EMNLP 2022, Abu Dhabi, United Arab Emirates, December 7-11, 2022, pp. 11580–11599 (2022). https://aclanthology.org/2022.emnlp-main.796
Warner, W., Hirschberg, J.: Detecting hate speech on the world wide web. (2012)
MacAvaney, S., Yao, H.-R., Yang, E., Russell, K., Goharian, N., Frieder, O.: Hate speech detection: Challenges and solutions. PLoS ONE 14 (2019)
del Arco, F.M.P., Molina-González, M.D., Martín-Valdivia, M., López, L.A.U.: SINAI at semeval-2019 task 6: Incorporating lexicon knowledge into SVM learning to identify and categorize offensive language in social media. In: May, J., Shutova, E., Herbelot, A., Zhu, X., Apidianaki, M., Mohammad, S.M. (eds.) Proceedings of the 13th International Workshop on Semantic Evaluation, SemEval@NAACL-HLT 2019, Minneapolis, MN, USA, June 6-7, 2019, pp. 735–738 (2019). https://doi.org/10.18653/v1/s19-2129
Zhu, J., Tian, Z., Kübler, S.: Um-iu@ling at semeval-2019 task 6: Identifying offensive tweets using BERT and svms. In: May, J., Shutova, E., Herbelot, A., Zhu, X., Apidianaki, M., Mohammad, S.M. (eds.) Proceedings of the 13th International Workshop on Semantic Evaluation, SemEval@NAACL-HLT 2019, Minneapolis, MN, USA, June 6-7, 2019, pp. 788–795 (2019). https://doi.org/10.18653/v1/s19-2138
Rozental, A., Biton, D.: Amobee at semeval-2019 tasks 5 and 6: Multiple choice CNN over contextual embedding. In: May, J., Shutova, E., Herbelot, A., Zhu, X., Apidianaki, M., Mohammad, S.M. (eds.) Proceedings of the 13th International Workshop on Semantic Evaluation, SemEval@NAACL-HLT 2019, Minneapolis, MN, USA, June 6-7, 2019, pp. 377–381 (2019). https://doi.org/10.18653/v1/s19-2066
Zampieri, M., Malmasi, S., Nakov, P., Rosenthal, S., Farra, N., Kumar, R.: Semeval-2019 task 6: Identifying and categorizing offensive language in social media (offenseval). CoRR abs/1903.08983 (2019) 1903.08983
Zhang, Y., Xu, B., Zhao, T.: CN-HIT-MI.T at semeval-2019 task 6: Offensive language identification based on bilstm with double attention. In: May, J., Shutova, E., Herbelot, A., Zhu, X., Apidianaki, M., Mohammad, S.M. (eds.) Proceedings of the 13th International Workshop on Semantic Evaluation, SemEval@NAACL-HLT 2019, Minneapolis, MN, USA, June 6-7, 2019, pp. 564–570 (2019). https://doi.org/10.18653/v1/s19-2101
Rajendran, A., Zhang, C., Abdul-Mageed, M.: UBC-NLP at semeval-2019 task 6: Ensemble learning of offensive content with enhanced training data. In: May, J., Shutova, E., Herbelot, A., Zhu, X., Apidianaki, M., Mohammad, S.M. (eds.) Proceedings of the 13th International Workshop on Semantic Evaluation, SemEval@NAACL-HLT 2019, Minneapolis, MN, USA, June 6-7, 2019, pp. 775–781 (2019). https://doi.org/10.18653/v1/s19-2136
Nikolov, A., Radivchev, V.: Nikolov-radivchev at semeval-2019 task 6: Offensive tweet classification with BERT and ensembles. In: May, J., Shutova, E., Herbelot, A., Zhu, X., Apidianaki, M., Mohammad, S.M. (eds.) Proceedings of the 13th International Workshop on Semantic Evaluation, SemEval@NAACL-HLT 2019, Minneapolis, MN, USA, June 6-7, 2019, pp. 691–695 (2019). https://doi.org/10.18653/v1/s19-2123
Nguyen, D.Q., Vu, T., Nguyen, A.T.: Bertweet: A pre-trained language model for english tweets. In: Liu, Q., Schlangen, D. (eds.) Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, EMNLP 2020 - Demos, Online, November 16-20, 2020, pp. 9–14 (2020). https://doi.org/10.18653/v1/2020.emnlp-demos.2
Koufakou, A., Pamungkas, E.W., Basile, V., Patti, V.: Hurtbert: Incorporating lexical features with BERT for the detection of abusive language. In: Akiwowo, S., Vidgen, B., Prabhakaran, V., Waseem, Z. (eds.) Proceedings of the Fourth Workshop on Online Abuse and Harms, WOAH 2020, Online, November 20, 2020, pp. 34–43 (2020). https://doi.org/10.18653/v1/2020.alw-1.5
Caselli, T., Basile, V., Mitrovic, J., Granitzer, M.: Hatebert: Retraining BERT for abusive language detection in english. CoRR abs/2010.12472 (2020) 2010.12472
Zampieri, M., Malmasi, S., Nakov, P., Rosenthal, S., Farra, N., Kumar, R.: Predicting the type and target of offensive posts in social media. In: Burstein, J., Doran, C., Solorio, T. (eds.) Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2019, Minneapolis, MN, USA, June 2-7, 2019, Volume 1 (Long and Short Papers), pp. 1415–1420 (2019). https://doi.org/10.18653/v1/n19-1144
Gehman, S., Gururangan, S., Sap, M., Choi, Y., Smith, N.A.: Realtoxicityprompts: Evaluating neural toxic degeneration in language models. In: Cohn, T., He, Y., Liu, Y. (eds.) Findings of the Association for Computational Linguistics: EMNLP 2020, Online Event, 16-20 November 2020. Findings of ACL, vol. EMNLP 2020, pp. 3356–3369 (2020). https://doi.org/10.18653/v1/2020.findings-emnlp.301
Oprea, S., Magdy, W.: isarcasm: A dataset of intended sarcasm. In: Jurafsky, D., Chai, J., Schluter, N., Tetreault, J.R. (eds.) Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, ACL 2020, Online, July 5-10, 2020, pp. 1279–1289 (2020). https://doi.org/10.18653/v1/2020.acl-main.118
Maynard, D., Greenwood, M.A.: Who cares about sarcastic tweets? investigating the impact of sarcasm on sentiment analysis. In: Calzolari, N., Choukri, K., Declerck, T., Loftsson, H., Maegaard, B., Mariani, J., Moreno, A., Odijk, J., Piperidis, S. (eds.) Proceedings of the Ninth International Conference on Language Resources and Evaluation, LREC 2014, Reykjavik, Iceland, May 26-31, 2014, pp. 4238–4243 (2014). http://www.lrec-conf.org/proceedings/lrec2014/summaries/67.html
Joshi, A., Tripathi, V., Patel, K., Bhattacharyya, P., Carman, M.J.: Are word embedding-based features useful for sarcasm detection? In: Su, J., Carreras, X., Duh, K. (eds.) Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, EMNLP 2016, Austin, Texas, USA, November 1-4, 2016, pp. 1006–1011 (2016). https://doi.org/10.18653/v1/d16-1104
Tay, Y., Luu, A.T., Hui, S.C., Su, J.: Reasoning with sarcasm by reading in-between. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, ACL 2018, Melbourne, Australia, July 15-20, 2018, Volume 1: Long Papers, pp. 1010–1020 (2018). https://doi.org/10.18653/v1/P18-1093. https://aclanthology.org/P18-1093/
Hazarika, D., Poria, S., Gorantla, S., Cambria, E., Zimmermann, R., Mihalcea, R.: CASCADE: contextual sarcasm detection in online discussion forums. In: Bender, E.M., Derczynski, L., Isabelle, P. (eds.) Proceedings of the 27th International Conference on Computational Linguistics, COLING 2018, Santa Fe, New Mexico, USA, August 20-26, 2018, pp. 1837–1848 (2018). https://aclanthology.org/C18-1156/
Oprea, S., Magdy, W.: Exploring author context for detecting intended vs perceived sarcasm. In: Korhonen, A., Traum, D.R., Màrquez, L. (eds.) Proceedings of the 57th Conference of the Association for Computational Linguistics, ACL 2019, Florence, Italy, July 28- August 2, 2019, Volume 1: Long Papers, pp. 2854–2859 (2019). https://doi.org/10.18653/v1/p19-1275
Tang, Y.-j., Chen, H.-H.: Chinese irony corpus construction and ironic structure analysis. In: International Conference on Computational Linguistics (2014)
Gong, X., Zhao, Q., Zhang, J., Mao, R., Xu, R.: The design and construction of a chinese sarcasm dataset. In: Calzolari, N., Béchet, F., Blache, P., Choukri, K., Cieri, C., Declerck, T., Goggi, S., Isahara, H., Maegaard, B., Mariani, J., Mazo, H., Moreno, A., Odijk, J., Piperidis, S. (eds.) Proceedings of The 12th Language Resources and Evaluation Conference, LREC 2020, Marseille, France, May 11-16, 2020, pp. 5034–5039 (2020). https://aclanthology.org/2020.lrec-1.619/
Xing, L., Ying, L., Sing, W.: Linguistic features enhanced convolutional neural networks for irony recognition. Journal of Chinese Information Processing 33(5):31 (2019)
OpenAI: GPT-4 technical report. CoRR abs/2303.08774 (2023) 2303.08774. https://doi.org/10.48550/arXiv.2303.08774
Huang, F., Kwak, H., An, J.: Is chatgpt better than human annotators? potential and limitations of chatgpt in explaining implicit hate speech. In: Ding, Y., Tang, J., Sequeda, J.F., Aroyo, L., Castillo, C., Houben, G. (eds.) Companion Proceedings of the ACM Web Conference 2023, WWW 2023, Austin, TX, USA, 30 April 2023 - 4 May 2023, pp. 294–297 (2023). https://doi.org/10.1145/3543873.3587368
Li, Y., Sosea, T., Sawant, A., Nair, A.J., Inkpen, D., Caragea, C.: P-stance: A large dataset for stance detection in political domain. In: Zong, C., Xia, F., Li, W., Navigli, R. (eds.) Findings of the Association for Computational Linguistics: ACL/IJCNLP 2021, Online Event, August 1-6, 2021. Findings of ACL, vol. ACL/IJCNLP 2021, pp. 2355–2365 (2021). https://doi.org/10.18653/v1/2021.findings-acl.208
Gorrell, G., Aker, A., Bontcheva, K., Derczynski, L., Kochkina, E., Liakata, M., Zubiaga, A.: Semeval-2019 task 7: Rumoureval, determining rumour veracity and support for rumours. In: May, J., Shutova, E., Herbelot, A., Zhu, X., Apidianaki, M., Mohammad, S.M. (eds.) Proceedings of the 13th International Workshop on Semantic Evaluation, 2019, Minneapolis, MN, USA, June 6-7, 2019, pp. 845–854 (2019). https://doi.org/10.18653/v1/s19-2147
Jeong, Y., Oh, J., Lee, J., Ahn, J., Moon, J., Park, S., Oh, A.: KOLD: korean offensive language dataset. In: Goldberg, Y., Kozareva, Z., Zhang, Y. (eds.) Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, EMNLP 2022, Abu Dhabi, United Arab Emirates, December 7-11, 2022, pp. 10818–10833 (2022). https://aclanthology.org/2022.emnlp-main.744
Jiang, A., Yang, X., Liu, Y., Zubiaga, A.: SWSR: A chinese dataset and lexicon for online sexism detection. Online Soc. Networks Media 27, 100182 (2022). DOI: 10.1016/j.osnem.2021.100182
Tang, X., Shen, X., Wang, Y., Yang, Y.: Categorizing offensive language in social networks: A chinese corpus, systems and an explanation tool. In: Sun, M., Li, S., Zhang, Y., Liu, Y., He, S., Rao, G. (eds.) Chinese Computational Linguistics - 19th China National Conference, CCL 2020, Hainan, China, October 30 - November 1, 2020, Proceedings. Lecture Notes in Computer Science, vol. 12522 (2020). https://doi.org/10.1007/978-3-030-63031-7_22
Hee, C.V., Lefever, E., Hoste, V.: Semeval-2018 task 3: Irony detection in english tweets. In: Apidianaki, M., Mohammad, S.M., May, J., Shutova, E., Bethard, S., Carpuat, M. (eds.) Proceedings of The 12th International Workshop on Semantic Evaluation, SemEval@NAACL-HLT 2018, New Orleans, Louisiana, USA, June 5-6, 2018, pp. 39–50 (2018). https://doi.org/10.18653/v1/s18-1005
Lippmann, W., Curtis, M.: Public Opinion, (2017)
Tian, H., Gao, C., Xiao, X., Liu, H., He, B., Wu, H., Wang, H., Wu, F.: SKEP: sentiment knowledge enhanced pre-training for sentiment analysis. In: Jurafsky, D., Chai, J., Schluter, N., Tetreault, J.R. (eds.) Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, ACL 2020, Online, July 5-10, 2020, pp. 4067–4076 (2020). https://doi.org/10.18653/v1/2020.acl-main.374
Pérez, J.M., Giudici, J.C., Luque, F.M.: pysentimiento: A python toolkit for sentiment analysis and socialnlp tasks. CoRR abs/2106.09462 (2021) 2106.09462
Devlin, J., Chang, M., Lee, K., Toutanova, K.: BERT: pre-training of deep bidirectional transformers for language understanding. In: Burstein, J., Doran, C., Solorio, T. (eds.) Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2019, Minneapolis, MN, USA, June 2-7, 2019, Volume 1 (Long and Short Papers), pp. 4171–4186 (2019). https://doi.org/10.18653/v1/n19-1423
Cui, Y., Che, W., Liu, T., Qin, B., Yang, Z.: Pre-training with whole word masking for chinese BERT. IEEE ACM Trans. Audio Speech Lang. Process. 29, 3504–3514 (2021). https://doi.org/10.1109/TASLP.2021.3124365
Clark, K., Luong, M., Le, Q.V., Manning, C.D.: ELECTRA: pre-training text encoders as discriminators rather than generators. In: 8th International Conference on Learning Representations, ICLR 2020, Addis Ababa, Ethiopia, April 26-30, 2020 (2020). https://openreview.net/forum?id=r1xMH1BtvB
Yang, Z., Dai, Z., Yang, Y., Carbonell, J.G., Salakhutdinov, R., Le, Q.V.: Xlnet: Generalized autoregressive pretraining for language understanding. In: Wallach, H.M., Larochelle, H., Beygelzimer, A., d’Alché-Buc, F., Fox, E.B., Garnett, R. (eds.) Advances in Neural Information Processing Systems 32: Annual Conference on Neural Information Processing Systems 2019, NeurIPS 2019, December 8-14, 2019, Vancouver, BC, Canada, pp. 5754–5764 (2019). https://proceedings.neurips.cc/paper/2019/hash/dc6a7e655d7e5840e66733e9ee67cc69-Abstract.html
Liu, Y., Ott, M., Goyal, N., Du, J., Joshi, M., Chen, D., Levy, O., Lewis, M., Zettlemoyer, L., Stoyanov, V.: Roberta: A robustly optimized BERT pretraining approach. CoRR abs/1907.11692 (2019) 1907.11692
Funding
This work was supported by the National Natural Science Foundation of China (62172428).
Author information
Authors and Affiliations
Contributions
Bin Zhou raised the need of this work and provided funding. Haiyang Wang was responsible for data collection, annotation, experiment and completed the initial version of the manuscript. Ye Wang revised the manuscript and enriched the experiments. Xin Song, Xuechen Zhao and Xie Feng analysed the data and experiment results.
Corresponding author
Ethics declarations
Ethical Approval
Not applicable.
Competing Interests
No potential conflict of interest was reported by the authors.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Wang, H., Wang, Y., Song, X. et al. Quantifying controversy from stance, sentiment, offensiveness and sarcasm: a fine-grained controversy intensity measurement framework on a Chinese dataset. World Wide Web 26, 3607–3632 (2023). https://doi.org/10.1007/s11280-023-01191-x
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11280-023-01191-x