
Abstract
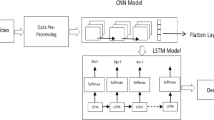
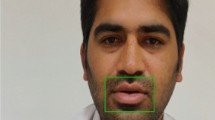
This paper is to propose a highly efficient and reliable real time communication system for speech impaired people to communicate and converse in an effective manner. The main idea deals with an algorithm to identify the word from a visual speech input disregard with its acoustic property. The non-acoustic speech is captured through a source and given as an input in the form of image frames then classified to obtain the desired form of output. The input given in the visual form deals with mouth postures. The network is structured to identify the speech in form of syllables. Convolution Neural Network, a deep learning technique is used as its classifier. A database is created especially for this algorithm and are aligned within in the form of class and subsets.






Similar content being viewed by others

References
Li, T., & Shen, F. (2015). Automatic segmentation of Chinese mandarin speech into syllable-like. In International conference on Asian language processing (IALP) (pp. 57–60).
Pradhan, A., Shanmugam, A., Prakash, A., Veezhinathan, K., & Murthy, H. (2014). A syllable based statistical text to speech system. In 21st European signal processing conference (EUSIPCO 2013) (pp. 1–5).
Devi, V. A. (2017). Conversion of speech to braille: Interaction device for visual and hearing impaired. In Fourth international conference on signal processing, communication and networking (ICSCN) (pp. 1–6).
Lu, L., Zhang, X., & Xu, X. (2018). Fusion of face and visual speech information for identity verification. In International symposium on intelligent signal processing and communication systems (ISPACS) (pp. 502–506).
Spyrou, E., Giannakopoulos, T., Sgouropoulos, D., & Papakostas, M. (2017). Extracting emotions from speech using a bag-of-visual-words approach. In 12th international workshop on semantic and social media adaptation and personalization (SMAP) (pp. 80–83).
Alcazar, V. J. L. L., Maulana, A. N. M., Mortega II, R. O., & Samonte, M. J. C. (2017). Speech-to-visual approach e-learning systems for the deaf. In 11th international conference on computer science and education (ICCSE) (pp. 239–243).
Petridis, S., Li, Z., & Pantie, M. (2017). End-to-end visual speech recognition with LSTMS. In IEEE international conference on acoustics, speech and signal processing (ICASSP) (pp. 2592–2596).
Mroueh, Y., Marcheret, E., & Goel, V. (2015). Deep multimodal learning for audio-visual speech recognition. In IEEE international conference on acoustics, speech and signal processing (ICASSP) (pp. 2130–2134).
Hou, J.-C., Wang, S.-S., Lai, Y.-H., Lin, J.-C., Tsao, Y., Chang, H.-W., & Wang, H.-M. (2017). Audio-visual speech enhancement using deep neural networks. In Asia-Pacific signal and information processing association annual summit and conference (APSIPA) (pp. 1–6).
Feng, W., Guan, N., Li, Y., Zhang, X., & Luo, Z. (2017). Audio visual speech recognition with multimodal recurrent neural networks. In International joint conference on neural networks (IJCNN) (pp. 681–688).
Karthikadevi, M., & Srinivasagan, K. G. (2014). The development of syllable-based test to speech system for Tamil language. In International conference on recent trends in information technology (pp. 1–6).
Stenzel, H., Jackson, P. J. B., & Francombe, J. (2017). Speech reaction time measurements for the evaluation of audio-visual spatial coherence. In Ninth international conference on quality of multimedia experience (QoMEX) (pp. 1–6).
Frisky, A. Z. K., Wang, C.-Y., Santoso, A., & Wang, J.-C. (2016). Lip-based visual speech recognition system. In International carnahan conference on security technology (ICCST) (pp. 315–319).
Fernandez-Lopez, A., Martinez, O., & Sukno, F. M. (2017). Towards estimating the upper bound of visual-speech recognition: the visual Lip-reading feasibility database. In 12th IEEE international conference on automatic face and gesture recognition (FG 2017) (pp. 208–215).
Jarraya, I., Werda, S., & Mahdi, W. (2016). Lip tracking using particle filter and geometric model for visual speech recognition. In 2014 international conference on signal processing and multimedia applications (SIGMAP) (pp. 172–179).
Luo, R., Fang, Q., Wei, J., Lu, W., Xu, W., & Yang, Y. (2017). Acoustic VR in the mouth: A real-time speech-driven visual tongue system. In IEEE virtual reality (VR) (pp. 112–121).
Bratoszewski, P., Szwoch, G., & Czyzewski, A. (2016). Comparison of acoustic and visual voice activity detection for noisy speech recognition. In Signal processing: Algorithms, architectures, arrangements, and applications (SPA) (pp. 287–291).
Georgakis, C., Petridis, S., & Pantic, M. (2015). Discrimination between native and non-native speech using visual features only. IEEE Transactions on Cybernetics, 46(12), 2758–2771.
Gupta, A., Miao, Y., Neves, L., & Metze, F. (2017). Visual features for context-aware speech recognition. In IEEE international conference on acoustics, speech and signal processing (ICASSP) (pp. 5020–5024).
Le Cornu, T., & Milner, B. (2017). Generating intelligible audio speech from visual speech. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 25(9), 1751–1761.
Yuan, Y., Tian, C., & Lu, X. (2018). Auxiliary loss multimodal GRU model in audio-visual speech recognition. IEEE Access, 6, 5573–5583.
Pahuja, H., Ranjan, P., & Ujlayan, A. (2018). Audio visual automatic speech recognition using multi-tasking learning of deep neural networks. In International conference on infocom technologies and unmanned systems (trends and future directions) (ICTUS) (pp. 455–458).
Matthews, I., Bangham, J. A., Cox, S., & Harvey, R. (2002). Extraction of visual features for lipreading. IEEE Transaction on Pattern Analysis and Machine Intelligence, 24(2), 198–213.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Subhashini, J., Kumar, C.M. An Algorithm to Identify Syllable from a Visual Speech Recognition System. Wireless Pers Commun 107, 2105–2121 (2019). https://doi.org/10.1007/s11277-019-06374-2
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11277-019-06374-2