
Abstract
Facial action unit (AU) detection and face alignment are two highly correlated tasks, since facial landmarks can provide precise AU locations to facilitate the extraction of meaningful local features for AU detection. However, most existing AU detection works handle the two tasks independently by treating face alignment as a preprocessing, and often use landmarks to predefine a fixed region or attention for each AU. In this paper, we propose a novel end-to-end deep learning framework for joint AU detection and face alignment, which has not been explored before. In particular, multi-scale shared feature is learned firstly, and high-level feature of face alignment is fed into AU detection. Moreover, to extract precise local features, we propose an adaptive attention learning module to refine the attention map of each AU adaptively. Finally, the assembled local features are integrated with face alignment feature and global feature for AU detection. Extensive experiments demonstrate that our framework (i) significantly outperforms the state-of-the-art AU detection methods on the challenging BP4D, DISFA, GFT and BP4D+ benchmarks, (ii) can adaptively capture the irregular region of each AU, (iii) achieves competitive performance for face alignment, and (iv) also works well under partial occlusions and non-frontal poses. The code for our method is available at https://github.com/ZhiwenShao/PyTorch-JAANet.








Similar content being viewed by others


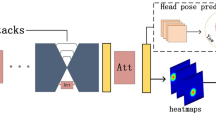
References
Batista, J. C., Albiero, V., Bellon, O. R., & Silva, L. (2017). Aumpnet: Simultaneous action units detection and intensity estimation on multipose facial images using a single convolutional neural network. In: IEEE international conference on automatic face & gesture recognition (pp. 866–871). IEEE
Benitez-Quiroz, C. F., Srinivasan, R., Martinez, A. M., et al. (2016). Emotionet: An accurate, real-time algorithm for the automatic annotation of a million facial expressions in the wild. In: IEEE conference on computer vision and pattern recognition (pp. 5562–5570). IEEE.
Cao, Z., Hidalgo, G., Simon, T., Wei, S. E., & Sheikh, Y. (2019). Openpose: Realtime multi-person 2d pose estimation using part affinity fields. In: IEEE transactions on pattern analysis and machine intelligence.
Chu, W. S., De la Torre, F., & Cohn, J. F. (2017). Learning spatial and temporal cues for multi-label facial action unit detection. In: IEEE international conference on automatic face & gesture recognition (pp. 25–32). IEEE
Cootes, T. F., Edwards, G. J., & Taylor, C. J. (2001). Active appearance models. IEEE Transactions on Pattern Analysis and Machine Intelligence, 23(6), 681–685.
Corneanu, C. A., Simón, M. O., Cohn, J. F., & Guerrero, S. E. (2016). Survey on rgb, 3d, thermal, and multimodal approaches for facial expression recognition: History, trends, and affect-related applications. IEEE Transactions on Pattern Analysis and Machine Intelligence, 38(8), 1548–1568.
Corneanu, C. A., Madadi, M., & Escalera, S. (2018). Deep structure inference network for facial action unit recognition. In European conference on computer vision (pp. 309–324). Springer
Ekman, P., & Friesen, W. V. (1978). Facial action coding system: A technique for the measurement of facial movement. London: Consulting Psychologists Press.
Ekman, P., Friesen, W. V., & Hager, J. C. (2002). Facial action coding system. Atlanta: Research Nexus.
Ertugrul, I. O., Cohn, J. F., Jeni, L. A., Zhang, Z., Yin, L., & Ji, Q. (2020). Crossing domains for au coding: Perspectives, approaches, and measures. IEEE Transactions on Biometrics, Behavior, and Identity Science, 2(2), 158–171.
Fan, R. E., Chang, K. W., Hsieh, C. J., Wang, X. R., & Lin, C. J. (2008). Liblinear: A library for large linear classification. Journal of Machine Learning Research, 9(Aug), 1871–1874.
Girard, J. M., Chu, W. S., Jeni, L. A., & Cohn, J. F. (2017). Sayette group formation task (gft) spontaneous facial expression database. In IEEE international conference on automatic face & gesture recognition (pp. 581–588). IEEE.
Gudi, A., Tasli, H. E., Den Uyl, T. M., & Maroulis, A. (2015). Deep learning based facs action unit occurrence and intensity estimation. In IEEE international conference and workshops on automatic face and gesture recognition (Vol. 6, pp. 1–5). IEEE
He, J., Li, D., Yang, B., Cao, S., Sun, B., & Yu, L. (2017). Multi view facial action unit detection based on cnn and blstm-rnn. In IEEE international conference on automatic face & gesture recognition (pp. 848–853). IEEE
He, K., Zhang, X., Ren, S., & Sun, J. (2016). Deep residual learning for image recognition. In IEEE conference on computer vision and pattern recognition (pp. 770–778). IEEE
Ioffe, S., & Szegedy, C. (2015). Batch normalization: Accelerating deep network training by reducing internal covariate shift. In International conference on machine learning (pp. 448–456).
Jeni, L. A., Cohn, J. F., & Kanade, T. (2017). Dense 3d face alignment from 2d video for real-time use. Image and Vision Computing, 58, 13–24.
Kazemi, V., Sullivan, J. (2014). One millisecond face alignment with an ensemble of regression trees. In IEEE conference on computer vision and pattern recognition (pp. 1867–1874). IEEE
Krizhevsky, A., Sutskever, I., & Hinton, G. E. (2012). Imagenet classification with deep convolutional neural networks. In Advances in neural information processing systems (pp. 1097–1105). Curran Associates, Inc.
Lafferty, J., McCallum, A., & Pereira, F. C. (2001). Conditional random fields: Probabilistic models for segmenting and labeling sequence data. In International conference on machine learning (pp 282–289).
Li, W., Abtahi, F., & Zhu, Z. (2017a). Action unit detection with region adaptation, multi-labeling learning and optimal temporal fusing. In IEEE conference on computer vision and pattern recognition (pp. 6766–6775). IEEE
Li, W., Abtahi, F., Zhu, Z., & Yin, L. (2018). Eac-net: Deep nets with enhancing and cropping for facial action unit detection. IEEE Transactions on Pattern Analysis and Machine Intelligence, 40(11), 2583–2596.
Li, X., Chen, S., & Jin, Q. (2017b). Facial action units detection with multi-features and -aus fusion. In IEEE international conference on automatic face & gesture recognition (pp. 860–865). IEEE
Li, Y., Wang, S., Zhao, Y., & Ji, Q. (2013). Simultaneous facial feature tracking and facial expression recognition. IEEE Transactions on Image Processing, 22(7), 2559–2573.
Li, Y., Zeng, J., Shan, S., & Chen, X. (2019). Self-supervised representation learning from videos for facial action unit detection. In IEEE conference on computer vision and pattern recognition (pp. 10924–10933). IEEE.
Martinez, B., Valstar, M. F., Jiang, B., & Pantic, M. (2019). Automatic analysis of facial actions: A survey. IEEE Transactions on Affective Computing, 10(3), 325–347.
Mavadati, S. M., Mahoor, M. H., Bartlett, K., Trinh, P., & Cohn, J. F. (2013). Disfa: A spontaneous facial action intensity database. IEEE Transactions on Affective Computing, 4(2), 151–160.
Milletari, F., Navab, N., & Ahmadi, S. A. (2016). V-net: Fully convolutional neural networks for volumetric medical image segmentation. In International conference on 3D vision (pp. 568–571). IEEE
Nair, V., & Hinton, G. E. (2010). Rectified linear units improve restricted boltzmann machines. In International conference on machine learning (pp. 807–814).
Niu, X., Han, H., Yang, S., Huang, Y., & Shan, S. (2019). Local relationship learning with person-specific shape regularization for facial action unit detection. In IEEE conference on computer vision and pattern recognition (pp. 11917–11926).
Paszke, A., Gross, S., Massa, F., Lerer, A., Bradbury, J., Chanan, G., et al. (2019). Pytorch: An imperative style, high-performance deep learning library. In Advances in neural information processing systems (pp. 8024–8035). Curran Associates, Inc.
Ranjan, R., Patel, V. M., & Chellappa, R. (2019). Hyperface: A deep multi-task learning framework for face detection, landmark localization, pose estimation, and gender recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence, 41(1), 121–135.
Sanchez, E., Tzimiropoulos, G., & Valstar, M. (2018). Joint action unit localisation and intensity estimation through heatmap regression. In British machine vision conference (p 233). BMVA Press.
Sankaran, N., Mohan, D. D., Setlur, S., Govindaraju, V., & Fedorishin, D. (2019). Representation learning through cross-modality supervision. In IEEE international conference on automatic face & gesture recognition (pp. 1–8). IEEE
Shao, Z., Ding, S., Zhao, Y., Zhang, Q., & Ma, L. (2016). Learning deep representation from coarse to fine for face alignment. In IEEE international conference on multimedia and expo (pp. 1–6). IEEE.
Shao, Z., Liu, Z., Cai, J., & Ma, L. (2018). Deep adaptive attention for joint facial action unit detection and face alignment. In European conference on computer vision (pp. 725–740). Springer
Shao, Z., Liu, Z., Cai, J., Wu, Y., & Ma, L. (2019). Facial action unit detection using attention and relation learning. In IEEE transactions on affective computing.
Shao, Z., Zhu, H., Tan, X., Hao, Y., & Ma, L. (2020). Deep multi-center learning for face alignment. Neurocomputing, 396, 477–486.
Simon, T., Joo, H., Matthews, I., & Sheikh, Y. (2017). Hand keypoint detection in single images using multiview bootstrapping. In IEEE conference on computer vision and pattern recognition (pp. 4645–4653). IEEE.
Sutskever, I., Martens, J., Dahl, G., & Hinton, G. (2013). On the importance of initialization and momentum in deep learning. In International conference on machine learning (pp. 1139–1147).
De la Torre, F., Chu, W. S., Xiong, X., Vicente, F., Ding, X., & Cohn, J. F. (2015). Intraface. In IEEE international conference and workshops on automatic face and gesture recognition (pp. 1–8). IEEE.
Valstar, M., & Pantic, M. (2006). Fully automatic facial action unit detection and temporal analysis. In IEEE conference on computer vision and pattern recognition workshop (pp. 149–149). IEEE.
Valstar, M. F., Sánchez-Lozano, E., Cohn, J. F., Jeni, L. A., Girard, J. M., Zhang, Z., et al. (2017). Fera 2017-addressing head pose in the third facial expression recognition and analysis challenge. In IEEE international conference on automatic face & gesture recognition (pp. 839–847). IEEE.
Wang, J., Sun, K., Cheng, T., Jiang, B., Deng, C., Zhao, Y., et al. (2020). Deep high-resolution representation learning for visual recognition. In IEEE transactions on pattern analysis and machine intelligence.
Wu, W., Qian, C., Yang, S., Wang, Q., Cai, Y., & Zhou, Q. (2018). Look at boundary: A boundary-aware face alignment algorithm. In: IEEE conference on computer vision and pattern recognition (pp. 2129–2138). IEEE.
Wu, Y., & Ji, Q. (2016). Constrained joint cascade regression framework for simultaneous facial action unit recognition and facial landmark detection. In IEEE conference on computer vision and pattern recognition (pp. 3400–3408). IEEE.
Wu, Y., Gou, C., & Ji, Q. (2017). Simultaneous facial landmark detection, pose and deformation estimation under facial occlusion. In IEEE conference on computer vision and pattern recognition (pp. 3471–3480). IEEE.
Xiong, X., & De la Torre, F. (2013). Supervised descent method and its applications to face alignment. In IEEE conference on computer vision and pattern recognition (pp. 532–539). IEEE.
Zeng, J., Chu, W. S., De la Torre, F., Cohn, J.F., & Xiong, Z. (2015). Confidence preserving machine for facial action unit detection. In IEEE international conference on computer vision (pp. 3622–3630) . IEEE.
Zhang, X., Yin, L., Cohn, J. F., Canavan, S., Reale, M., Horowitz, A., et al. (2014a). Bp4d-spontaneous: A high-resolution spontaneous 3d dynamic facial expression database. Image and Vision Computing, 32(10), 692–706.
Zhang, Z., Luo, P., Loy, C. C., & Tang, X. (2014b). Facial landmark detection by deep multi-task learning. In European conference on computer vision (pp. 94–108). Springer.
Zhang, Z., Girard, J. M., Wu, Y., Zhang, X., Liu, P., Ciftci, U., et al. (2016a). Multimodal spontaneous emotion corpus for human behavior analysis. In IEEE conference on computer vision and pattern recognition (pp. 3438–3446). IEEE.
Zhang, Z., Luo, P., Loy, C. C., & Tang, X. (2016b). Learning deep representation for face alignment with auxiliary attributes. IEEE Transactions on Pattern Analysis and Machine Intelligence, 38(5), 918–930.
Zhao, K., Chu, W. S., De la Torre, F., Cohn, J. F., & Zhang, H. (2015). Joint patch and multi-label learning for facial action unit detection. In IEEE conference on computer vision and pattern recognition (pp. 2207–2216). IEEE
Zhao, K., Chu, W. S., De la Torre, F., Cohn, J. F., & Zhang, H. (2016a). Joint patch and multi-label learning for facial action unit and holistic expression recognition. IEEE Transactions on Image Processing, 25(8), 3931–3946.
Zhao, K., Chu, W. S., & Zhang, H. (2016b). Deep region and multi-label learning for facial action unit detection. In IEEE conference on computer vision and pattern recognition. IEEE. pp 3391–3399.
Zhong, L., Liu, Q., Yang, P., Huang, J., & Metaxas, D. N. (2015). Learning multiscale active facial patches for expression analysis. IEEE Transactions on Cybernetics, 45(8), 1499–1510.
Acknowledgements
This work is supported by the Start-up Grant, School of Computer Science and Technology, China University of Mining and Technology. It is also partially supported by the National Key R&D Program of China (No. 2019YFC1521104), the National Natural Science Foundation of China (No. 61972157 and No. 61503277), the Zhejiang Lab (No. 2020NB0AB01), the Data Science & Artificial Intelligence Research Centre@NTU (DSAIR), and the Monash FIT Start-up Grant.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Shao, Z., Liu, Z., Cai, J. et al. JÂA-Net: Joint Facial Action Unit Detection and Face Alignment Via Adaptive Attention. Int J Comput Vis 129, 321–340 (2021). https://doi.org/10.1007/s11263-020-01378-z
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11263-020-01378-z