
Abstract
Image-to-image translation aims to learn the mapping between two visual domains. There are two main challenges for this task: (1) lack of aligned training pairs and (2) multiple possible outputs from a single input image. In this work, we present an approach based on disentangled representation for generating diverse outputs without paired training images. To synthesize diverse outputs, we propose to embed images onto two spaces: a domain-invariant content space capturing shared information across domains and a domain-specific attribute space. Our model takes the encoded content features extracted from a given input and attribute vectors sampled from the attribute space to synthesize diverse outputs at test time. To handle unpaired training data, we introduce a cross-cycle consistency loss based on disentangled representations. Qualitative results show that our model can generate diverse and realistic images on a wide range of tasks without paired training data. For quantitative evaluations, we measure realism with user study and Fréchet inception distance, and measure diversity with the perceptual distance metric, Jensen–Shannon divergence, and number of statistically-different bins.

















Similar content being viewed by others

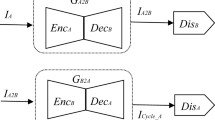
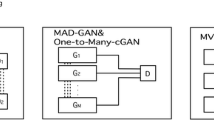
References
AlBahar, B., & Huang, J. B. (2019). Guided image-to-image translation with bi-directional feature transformation. In ICCV.
Almahairi, A., Rajeswar, S., Sordoni, A., Bachman, P., & Courville, A. (2018). Augmented cyclegan: Learning many-to-many mappings from unpaired data. In ICML.
Arjovsky, M., Chintala, S., & Bottou, L. (2017). Wasserstein GAN. In ICML.
Bousmalis, K., Silberman, N., Dohan, D., Erhan, D., & Krishnan, D. (2017). Unsupervised pixel-level domain adaptation with generative adversarial networks. In CVPR.
Cao, J., Katzir, O., Jiang, P., Lischinski, D., Cohen-Or, D., Tu, C., et al. (2018). Dida: Disentangled synthesis for domain adaptation. arXiv preprint arXiv:1805.08019.
Chen, Q., & Koltun, V. (2017). Photographic image synthesis with cascaded refinement networks. In ICCV.
Chen, X., Duan, Y., Houthooft, R., Schulman, J., Sutskever, I., & Abbeel, P. (2016). InfoGAN: Interpretable representation learning by information maximizing generative adversarial nets. In NIPS.
Chen, Y. C., Lin, Y. Y., Yang, M. H., & Huang, J. B. (2019). Crdoco: Pixel-level domain transfer with cross-domain consistency. In CVPR.
Cheung, B., Livezey, J. A., Bansal, A. K., & Olshausen, B. A. (2015). Discovering hidden factors of variation in deep networks. In ICLR workshop.
Choi, Y., Choi, M., Kim, M., Ha, J. W., Kim, S., & Choo, J. (2018). Stargan: Unified generative adversarial networks for multi-domain image-to-image translation. In CVPR (Vol. 1711).
Cordts, M., Omran, M., Ramos, S., Rehfeld, T., Enzweiler, M., Benenson, R., et al. (2016). The cityscapes dataset for semantic urban scene understanding. In CVPR.
Denton, E. L., & Birodkar, V. (2017). Unsupervised learning of disentangled representations from video. In NIPS.
Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., et al. (2014). Generative adversarial nets. In NIPS.
Heusel, M., Ramsauer, H., Unterthiner, T., Nessler, B., & Hochreiter, S. (2017). GANs trained by a two time-scale update rule converge to a local nash equilibrium. In NIPS.
Hoffman, J., Tzeng, E., Park, T., Zhu, J. Y., Isola, P., Saenko, K., et al. (2018). Cycada: Cycle-consistent adversarial domain adaptation. In ICML.
Huang, X., Liu, M. Y., Belongie, S., & Kautz, J. (2018). Multimodal unsupervised image-to-image translation. In ECCV.
Isola, P., Zhu, J. Y., Zhou, T., & Efros, A. A. (2017). Image-to-image translation with conditional adversarial networks. In CVPR.
Kim, T., Cha, M., Kim, H., Lee, J., & Kim, J. (2017). Learning to discover cross-domain relations with generative adversarial networks. In ICML.
Kinga, D., & Adam, J. B. (2015). A method for stochastic optimization. In ICLR.
Kingma, D. P., Rezende, D., Mohamed, S. J., & Welling, M. (2014). Semi-supervised learning with deep generative models. In NIPS.
Lai, W. S., Huang, J. B., Ahuja, N., & Yang, M. H. (2017). Deep laplacian pyramid networks for fast and accurate superresolution. In CVPR.
Larsson, G., Maire, M., & Shakhnarovich, G. (2016). Learning representations for automatic colorization. In ECCV.
Ledig, C., Theis, L., Huszár, F., Caballero, J., Cunningham, A., Acosta, A., et al. (2017). Photo-realistic single image super-resolution using a generative adversarial network. In CVPR.
Lee, H. Y., Tseng, H. Y., Huang, J. B., Singh, M. K., & Yang, M. H. (2018) Diverse image-to-image translation via disentangled representations. In ECCV.
Lee, H. Y., Yang, X., Liu, M. Y., Wang, T. C., Lu, Y. D., Yang, M. H., et al. (2019). Dancing to music. In NeurIPS.
Li, Y., Huang, J. B., Ahuja, N., & Yang, M. H. (2016). Deep joint image filtering. In ECCV.
Li, Y., Huang, J. B., Ahuja, N., & Yang, M. H. (2019). Joint image filtering with deep convolutional networks. IEEE Transactions on Pattern Analysis and Machine Intelligence, 41(8), 1909–1923.
Lin, J., Xia, Y., Liu, S., Qin, T., Chen, Z., & Luo, J. (2018a). Exploring explicit domain supervision for latentspace disentanglement in unpaired image-to-image translation. arXiv preprint arXiv:1902.03782.
Lin, J., Xia, Y., Qin, T., Chen, Z., & Liu, T. Y. (2018b). Conditional image-to-image translation. In CVPR.
Liu, A., Liu, Y. C., & Wang, F. Y. C. (2018). A unified feature disentangler for multi-domain image translation and manipulation. In NIPS.
Liu, M. Y., Breuel, T., & Kautz, J. (2017). Unsupervised image-to-image translation networks. In NIPS.
Liu, Z., Luo, P., Wang, X., & Tang, X. (2015). Deep learning face attributes in the wild. In ICCV.
Ma, L., Jia, X., Georgoulis, S., Tuytelaars, T., & Van Gool, L. (2018). Exemplar guided unsupervised image-to-image translation. In ICLR.
Ma, L., Jia, X., Sun, Q., Schiele, B., Tuytelaars, T., & Van Gool, L. (2017). Pose guided person image generation. In NIPS.
Makhzani, A., Shlens, J., Jaitly, N., Goodfellow, I., & Frey, B. (2016). Adversarial autoencoders. In ICLR workshop.
Mao, Q., Lee, H. Y., Tseng, H. Y., Ma, S., & Yang, M. H. (2019). Mode seeking generative adversarial networks for diverse image synthesis. In CVPR.
Mathieu, M., Zhao, J., Sprechmann, P., Ramesh, A., & LeCun, Y. (2016). Disentangling factors of variation in deep representation using adversarial training. In NIPS.
Murez, Z., Kolouri, S., Kriegman, D., Ramamoorthi, R., & Kim, K. (2018). Image to image translation for domain adaptation. In CVPR.
Park, T., Liu, M. Y., Wang, T. C., & Zhu, J. Y. (2019). Semantic image synthesis with spatially-adaptive normalization.
Paszke, A., Gross, S., Chintala, S., Chanan, G., Yang, E., DeVito, Z., et al. (2017). Automatic differentiation in pytorch. In NIPS workshop.
Radford, A., Metz, L., & Chintala, S. (2016). Unsupervised representation learning with deep convolutional generative adversarial networks. In ICLR.
Reed, S., Akata, Z., Yan, X., Logeswaran, L., Schiele, B., & Lee, H. (2016). Generative adversarial text to image synthesis. In ICML.
Richardson, E., & Weiss, Y. (2018). On GANs and GMMs. In NIPS.
Richter, S. R., Vineet, V., Roth, S., & Koltun, V. (2016). Playing for data: Ground truth from computer games. In ECCV.
Shrivastava, A., Pfister, T., Tuzel, O., Susskind, J., Wang, W., & Webb, R. (2017). Learning from simulated and unsupervised images through adversarial training. In CVPR.
Szegedy, C., Liu, W., Jia, Y., Sermanet, P., Reed, S., Anguelov, D., et al. (2015). Going deeper with convolutions. In CVPR.
Taigman, Y., Polyak, A., & Wolf, L. (2017). Unsupervised cross-domain image generation. In ICLR.
Vondrick, C., Pirsiavash, H., & Torralba, A. (2016). Generating videos with scene dynamics. In NIPS.
Wang, T. C., Liu, M. Y., Zhu, J. Y., Tao, A., Kautz, J., & Catanzaro, B. (2018). High-resolution image synthesis and semantic manipulation with conditional gans. In CVPR.
Yi, Z., Zhang, H. R., Tan, P., & Gong, M. (2017). Dualgan: Unsupervised dual learning for image-to-image translation. In ICCV.
Zhang, H., Xu, T., Li, H., Zhang, S., Wang, X., Huang, X., et al. (2018a). Stackgan++: Realistic image synthesis with stacked generative adversarial networks. In TPAMI.
Zhang, R., Isola, P., & Efros, A. A. (2016). Colorful image colorization. In ECCV.
Zhang, R., Isola, P., Efros, A. A., Shechtman, E., & Wang, O. (2018b). The unreasonable effectiveness of deep networks as a perceptual metric. In CVPR.
Zhu, J. Y., Park, T., Isola, P., & Efros, A. A. (2017a). Unpaired image-to-image translation using cycle-consistent adversarial networks. In ICCV.
Zhu, J. Y., Zhang, R., Pathak, D., Darrell, T., Efros, A. A., Wang, O., et al. (2017b). Toward multimodal image-to-image translation. In NIPS.
Acknowledgements
This work is supported in part by the NSF CAREER Grant #1149783, the NSF Grant #1755785, and gifts from Verisk, Adobe and Google.
Author information
Authors and Affiliations
Corresponding author
Additional information
Communicated by Jun-Yan Zhu, Hongsheng Li, Eli Shechtman, Ming-Yu Liu, Jan Kautz, Antonio Torralba.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Lee, HY., Tseng, HY., Mao, Q. et al. DRIT++: Diverse Image-to-Image Translation via Disentangled Representations. Int J Comput Vis 128, 2402–2417 (2020). https://doi.org/10.1007/s11263-019-01284-z
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11263-019-01284-z