
Abstract
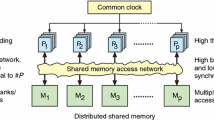
Moving threads is a new kind of approach for multicore processor architectures. Traditionally, each thread stays in the core where it is created, and data is moved from the main memory via caches to each core and thread. In the moving threads approach, each core can access only a certain portion of the main memory via its local memory block, and thus extremely lightweight threads are moved between the cores. As a consequence, all kinds of cache coherence problems and need for read reply messages are eliminated. Also Lamport’s sequential consistency of shared memory multiprocessor systems is achieved for free. In this paper, we propose a processor architecture (MTPA) for the moving threads paradigm. We describe the overall structure, operation, instruction set, and thread management mechanism as well as evaluate the proposed architecture with different functional unit settings with simulations and give early silicon area and power consumption estimates.
Similar content being viewed by others


References
Forsell M, Leppänen V (2007) Moving threads: a non-conventional approach for mapping computation to MP-SOC. In: Proc PDPTA’07, Las Vegas, USA, June 25–28, 2007, pp 232–238
International Technology Roadmap for Semiconductors (2009) Semiconductor Industry Association. http://public.itrs.net/
Philbin J, Edler J, Anshus OJ, Douglas CC, Li K (1996) Thread scheduling for cache locality. In: Proceedings of ASPLOS VII, Boston, October 1996
Keller J, Keßler C, Träff J (2001) Practical PRAM programming. Wiley, New York
von Eicken T, Culler D, Goldstein S, Schauser K (1992) Active messages: a mechanism for integrated communication and computation. In: Proc ISCA’92, Gold Coast, Australia, pp 256–266
Wallach D, Hsieh W, Johnson K, Kaashoek M, Weihl W (1995) Optimistic active messages: a mechanism for scheduling communication with computation. In: Proc PPoPP’95, Santa Barbara, CA, pp 217–226
Jenks S (2004) Multithreading and thread migration using MPI and myrinet. In: Proc parallel and distributed computing and systems conference, Cambridge, MA
Bhandarkar M, Kale LV, de Sturler E, Hoeflinger J (2001) Adaptive load balancing for MPI programs. In: Proc international conference on computational science-part II, ICCS. LNCS, vol 2074. Springer, Berlin, pp 108–117
Bougé L, Hatcher Ph, Namyst R, Perez C (1998) A multithreaded runtime environment with thread migration for a HPF data-parallel compiler. In: Proc PACT’98, Paris, France, October 1998, pp 418–425
Jenks S, Gaudiot J-L (2003) A multithreaded runtime system with thread migration for distributed memory parallel computing. In: Proc high performance computing symposium, Advanced simulation technologies conference, Orlando, FL, 2003
Thitikamol K, Keleher P (1999) Thread migration and communication minimization in DSM systems. In: Proc IEEE, Special issue on distributed shared memory, Spring 1999, pp 487–497
Weissman B, Gomes B, Quittek JW, Holtkamp M (1998) Efficient fine-grain thread migration with active threads. In: Proc IPPS/SPDP’98, pp 410–414
Chen J, Juang P, Ko K, Contreras G, Penry D, Rangan R, Stoler A, Peh L, Martonosi M (2005) Hardware-modulated parallelism in chip multiprocessors. SIGARCH Comput Archit News, 33(4):54–63
Kumar S, Hughes CJ, Nguyen A (2007) Carbon: architectural support for fine-grained parallelism on chip multiprocessors. In: Proc ISCA’07
Chaudhary V, Jiang H (2006) Techniques for migrating computations on the grid. In: Di Martino B, Dongarra J, Hoisie A, Zima H, Yang LT (eds) Engineering the grid: status and perspective, January 2006 American Scientific, pp 399–415.
Jiang H, Chaudhary V, Walters JP (2006) Data conversion for heterogeneous migration/checkpointing. In: Yang LT, Guo M (eds) High performance computing: paradigm and infrastructure. Wiley, New York, pp 241–260
Leppänen V (1998) Balanced PRAM simulations via moving threads and hashing. J. Univers. Comput. Sci. 4(8):675–689
Shaw KA, Dally WJ (2002) Migration in single chip multiprocessors. Comput Archit Lett 1(3):2–5
Constantinou T, Sazeides Y, Michaud P, Fetis D, Seznec A (2005) Performance implications of single thread migration on a chip multi-core. SIGARCH Comput Archit News 33(4):80–91
Forsell M (1997) MTAC—a multithreaded VLIW architecture for PRAM simulation. J. Univers. Comput. Sci. 33(9):1037–1055
Forsell M, Roivainen J (2008) Performance, area and power trade-offs in mesh-based emulated shared memory CMP architectures. In: Proc PDPTA’08, Las Vegas, USA, July 14–17, 2008, pp 471–477
Leppänen V (1996) Studies on the realization of PRAM. Dissertation 3, Turku Centre for Computer Science, University of Turku, Turku
Author information
Authors and Affiliations
Corresponding author
Additional information
This work was supported by the grants 122462 and 128733 of the Academy of Finland.
Rights and permissions
About this article
Cite this article
Forsell, M., Leppänen, V. A moving threads processor architecture MTPA. J Supercomput 57, 5–19 (2011). https://doi.org/10.1007/s11227-011-0573-9
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11227-011-0573-9