
Abstract
In this paper, we develop a fault tolerant job scheduling strategy in order to tolerate faults gracefully in an economy based grid environment. We propose a novel adaptive task checkpointing based fault tolerant job scheduling strategy for an economy based grid. The proposed strategy maintains a fault index of grid resources. It dynamically updates the fault index based on successful or unsuccessful completion of an assigned task. Whenever a grid resource broker has tasks to schedule on grid resources, it makes use of the fault index from the fault tolerant schedule manager in addition to using a time optimization heuristic. While scheduling a grid job on a grid resource, the resource broker uses fault index to apply different intensity of task checkpointing (inserting checkpoints in a task at different intervals).
To simulate and evaluate the performance of the proposed strategy, this paper enhances the GridSim Toolkit-4.0 to exhibit fault tolerance related behavior. We also compare “checkpointing fault tolerant job scheduling strategy” with the well-known time optimization heuristic in an economy based grid environment. From the measured results, we conclude that even in the presence of faults, the proposed strategy effectively schedules grid jobs tolerating faults gracefully and executes more jobs successfully within the specified deadline and allotted budget. It also improves the overall execution time and minimizes the execution cost of grid jobs.
Similar content being viewed by others


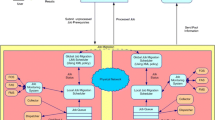
References
Abawajy JH (2004) Fault-tolerant scheduling policy for grid computing systems. In: 18th International parallel and distributed processing symposium (IPDPS’04)—Workshop 13, 2004, p 238b
Burchard L-O, De Rose CAF, Heiss H-U, Linnert B, Schneider J (2005) VRM: a failure-aware grid resource management system. In: Proceedings of the 17th international symposium on computer architecture and high performance computing (SBAC-PAD’05), IEEE, 24–27 October 2005, pp 218–225
Buyya R (2002) Economic-based distributed resource management and scheduling for grid computing. Ph.D. Paper, Monash University, Melbourne, Australia, 12 April 2002
Buyya R, Murshed M (2002) GridSim: a toolkit for the modeling and simulation of distributed resource management and scheduling for grid computing. Concurr Comput Pract Exp (CCPE) 14(13–15):1175–1220
Buyya R, Abramson D, Giddy J, Nimrod G (2000) An architecture for a resource management and scheduling system in a global computational grid. In: The 4th international conference on high performance computing in Asia-Pacific region (HPC Asia 2000), Beijing, China, vol 1. IEEE Computer Society Press, Los Alamitos, pp 283–290
Buyya R, Abramson D, Giddy J, Stockinger H (2002) Economic models for resource management and scheduling in grid computing. Concurr Comput Pract Exp (CCPE) 14(13–15):1507–1542
Buyya R, Murshed M, Abramson D (2002) A deadline and budget constrained cost-time optimization algorithm for scheduling task farming applications on global grids. In: Proceedings of the 2002 international conference on parallel and distributed processing techniques and applications (PDPTA’02), Las Vegas, USA, 24–27 June 2002
Buyya R, Abramson D, Venugopal S (2005) The grid economy, special issue on grid computing. Proc IEEE 93(3):698–714
Buyya R, Murshed M, Abramson D, Venugopal S (2005) Scheduling parameter sweep applications on global grids: a deadline and budget constrained cost-time optimization algorithm. Softw Pract Exp (SPE) 35(5):491–512
Chetty M, Buyya R (2002) Weaving computational grids: how analogous are they with electrical grids? Comput Sci Eng (CiSE) 4(4):61–71
Foster I (2002) What is the grid? A three point checklist. GRID Today, 20 July 2002
Foster I, Kesselman C (1999) The Grid: blueprint for a new computing infrastructure. Morgan Kaufmann, San Mateo
Foster I, Kesselman C (2004) The Grid 2: blueprint for a new computing infrastructure. Morgan Kaufman, San Mateo
Foster I, Kesselman C, Tueke S (2001) The anatomy of the grid: enabling scalable virtual organizations. Int J Supercomput Appl
Foster I, Kesselman C, Nick J, Tuecke S (2002) The physiology of the grid: an open grid services architecture for distributed systems integration. 22 June 2002
Gupta I, Chandra T, Goldszmidt G (2001) On scalable and efficient distributed failure detectors. In: Proceedings of 20th annual ACM symposium on principles of distributed computing, August 2001. ACM Press, New York, pp 170–179
Hayashibara N, Cherif A, Katayama T (2002) Failure detectors for large-scale distributed systems. In: Proceedings of the 21st IEEE symposium on reliable distributed systems (SRDS’02), October 2002, pp 404–409
Huda MT, Schmidt HW, Peake ID (2005) An agent oriented proactive fault-tolerant framework for grid computing. In: First international conference on e-science and grid computing (e-science’05), IEEE, 5–8 December 2005, pp 78–85
Keat NW, Fong AT, Ling TC, Sun LC (2006) Scheduling framework for bandwidth-aware job grouping-based scheduling in grid computing. Malays J Comput Sci 19(2):117–126
Lee HM, Chung KS, Chin SH, Lee JH, Lee DW, Park S, Yu HC (2005) A resource management and fault tolerance services in grid computing. J Parallel Distrib Comput 65(11):1305–1317
Li Y, Lan Z (2006) Exploit failure prediction for adaptive fault-tolerance in cluster. In: Proceedings of the sixth IEEE international symposium on cluster computing and the grid (CCGRID’06), ISBN 0-7695-2585-7, vol 1, 16–19 May 2006, p 8
Fernandes Lopes R, da Silva FJ (2006) Fault tolerance in a mobile agent based computational grid. In: Proceedings of the sixth IEEE international symposium on cluster computing and the grid workshops (CCGRIDW’06), vol 2, 16–19 May 2006, pp 8–22
Medeiros R, Cirne W, Brasileiro F, Sauv’e J (2003) Faults in grids: why are they so bad and what can be done about it? In: Grid computing, 2003, proceedings. Fourth international workshop, ISBN 1-59593-414-6, November 2003, pp 18–24
Muthuvelu N, Liu J, Soe NL, Venugopal S, Sulistio A, Buyya R (2005) A dynamic job grouping-based scheduling for deploying applications with fine-grained tasks on global grids. In: Proceedings of the 3rd Australasian workshop on grid computing and e-research, Newcastle, Australia, ISSN 1445-1336 1-920-68226-0, vol 44, 30 January–4 February 2005, pp 41–48
Nainwal KC, Lakshmi J, Nandy SK, Narayan R, Varadarajan K (2005) A framework for QoS adaptive grid meta scheduling. In: Proceedings sixteenth international workshop on database and expert systems applications, August 2005, pp 292–296
Nazir B, Khan T (2006) Fault tolerant job scheduling in computational grid. In: Proceedings of 2nd IEEE international conference on emerging technologies (ICET’06), Peshawar, Pakistan, 13–14 November 2006, pp 708–713
Reddy SR (2006) Market economy based resource allocation in grids. Master Thesis, Indian Institute of Technology, Kharagpur, India, May 2006
Sherwani J, Ali N, Lotia N, Hayat Z, Buyya R (2004) Libra: a computational economy based job scheduling system for clusters. Int J Softw Pract Exp 34(6):573–590
Singh G, Kesselman C, Deelman E (2007) A provisioning model and its comparison with best effort for performance-cost optimization in grids. In: Proceedings of the sixteenth IEEE international symposium on high-performance distributed computing (HPDC 2007), Monterey, California, USA, ISBN:978-1-59593-673-8, 25–29 June 2007, pp 117–126
Soysa M, Buyya R, Nath B (2006) GridEmail: economically regulated Internet-based interpersonal communications. In: Dai Y, Pan Y, Raje R (eds) Advanced parallel and distributed computing: evaluation, improvement and practice. Nova Science, New York, pp 279–295
Sulistio A, Yeo CS, Buyya R (2004) A taxonomy of computer-based simulations and its mapping to parallel and distributed systems simulation tools. Int J Softw Pract Exp 34(7):653–673
Tu M, Li P, Ma Q, Yen I-L, Bastani FB (2005) On the optimal placement of secure data objects over Internet. In: IPDPS 2005
Yeo CS, Buyya R (2005) Service level agreement based allocation of cluster resources: handling penalty to enhance utility. In: Proceedings of the 7th IEEE international conference on cluster computing, Cluster 2005, Boston, Massachusetts, 27–30 September 2005. IEEE CS Press, Los Alamitos
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Nazir, B., Qureshi, K. & Manuel, P. Adaptive checkpointing strategy to tolerate faults in economy based grid. J Supercomput 50, 1–18 (2009). https://doi.org/10.1007/s11227-008-0245-6
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11227-008-0245-6