
Abstract
Markov chain Monte Carlo (MCMC) is a powerful methodology for the approximation of posterior distributions. However, the iterative nature of MCMC does not naturally facilitate its use with modern highly parallel computation on HPC and cloud environments. Another concern is the identification of the bias and Monte Carlo error of produced averages. The above have prompted the recent development of fully (‘embarrassingly’) parallel unbiased Monte Carlo methodology based on coupling of MCMC algorithms. A caveat is that formulation of effective coupling is typically not trivial and requires model-specific technical effort. We propose coupling of MCMC chains deriving from sequential Monte Carlo (SMC) by considering adaptive SMC methods in combination with recent advances in unbiased estimation for state-space models. Coupling is then achieved at the SMC level and is, in principle, not problem-specific. The resulting methodology enjoys desirable theoretical properties. A central motivation is to extend unbiased MCMC to more challenging targets compared to the ones typically considered in the relevant literature. We illustrate the effectiveness of the algorithm via application to two complex statistical models: (i) horseshoe regression; (ii) Gaussian graphical models.




Similar content being viewed by others


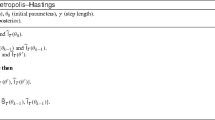
Availability of data and material
The data are confidential human subject data, thus are not available.
References
Andrieu, C., Doucet, A., Holenstein, R.: Particle Markov chain Monte Carlo methods. J. R. Stat. Soc. Ser. B (Stat. Methodol.) 72(3), 269–342 (2010)
Andrieu, C., Lee, A., Vihola, M.: Uniform ergodicity of the iterated conditional SMC and geometric ergodicity of particle Gibbs samplers. Bernoulli 24(2), 842–872 (2018)
Armstrong, H., Carter, C.K., Wong, K.F.K., Kohn, R.: Bayesian covariance matrix estimation using a mixture of decomposable graphical models. Stat. Comput. 19(3), 303–316 (2009)
Atay-Kayis, A., Massam, H.: A Monte Carlo method for computing the marginal likelihood in nondecomposable Gaussian graphical models. Biometrika 92(2), 317–335 (2005)
Bhadra, A., Datta, J., Polson, N.G., Willard, B.: Lasso meets horseshoe: a survey. Stat. Sci. 34(3), 405–427 (2019)
Biswas, N., Bhattacharya, A., Jacob, P.E., Johndrow, J.E.: Coupled Markov chain Monte Carlo for high-dimensional regression with Half-t priors. (2021). arXiv:2012.04798v2
Carvalho, C.M., Polson, N.G., Scott, J.G.: Handling sparsity via the horseshoe. In: van Dyk D, Welling M (eds) Proceedings of the Twelth International Conference on Artificial Intelligence and Statistics, PMLR, Hilton Clearwater Beach Resort, Clearwater Beach, Florida USA, Proceedings of Machine Learning Research, vol 5, pp 73–80 (2009)
Cheng, Y., Lenkoski, A.: Hierarchical Gaussian graphical models: beyond reversible jump. Electron. J. Stat. 6, 2309–2331 (2012)
Chopin, N., Papaspiliopoulos, O.: An Introduction to Sequential Monte Carlo. Springer, Berlin (2020)
Chopin, N., Singh, S.S.: On particle Gibbs sampling. Bernoulli 21(3), 1855–1883 (2015)
Del Moral, P.: Feynman-Kac Formulae: Genealogical and Interacting Particle Systems with Applications. Springer, New York (2004)
Del Moral, P., Doucet, A., Jasra, A.: Sequential Monte Carlo samplers. J. R. Stat. Soc. Ser. B (Stat. Methodol.) 68(3), 411–436 (2006)
Dempster, A.P.: Covariance selection. Biometrics 28(1), 157 (1972)
Dobra, A., Lenkoski, A., Rodriguez, A.: Bayesian inference for general Gaussian graphical models with application to multivariate lattice data. J. Am. Stat. Assoc. 106(496), 1418–1433 (2011)
Glynn, P.W., Rhee, C.H.: Exact estimation for Markov chain equilibrium expectations. J. Appl. Probab. 51, 377–389 (2014)
Godsill, S.J.: On the relationship between Markov chain Monte Carlo methods for model uncertainty. J. Comput. Graph. Stat. 10(2), 230–248 (2001)
Heng, J., Jacob, P.E.: Unbiased Hamiltonian Monte Carlo with couplings. Biometrika 106(2), 287–302 (2019)
Hinne, M., Lenkoski, A., Heskes, T., van Gerven, M.: Efficient sampling of Gaussian graphical models using conditional Bayes factors. Stat 3(1), 326–336 (2014)
Jacob, P.E., Lindsten, F., Schön, T.B.: Smoothing with couplings of conditional particle filters. J. Am. Stat. Assoc. 115(530), 721–729 (2020)
Jacob, P.E., O’Leary, J., Atchadé, Y.F.: Unbiased Markov chain Monte Carlo methods with couplings. J. R. Stat. Soc. Ser. B (Stat. Methodol.) 82(3), 543–600 (2020)
Jasra, A., Stephens, D.A., Doucet, A., Tsagaris, T.: Inference for Lévy-driven stochastic volatility models via adaptive sequential Monte Carlo. Scand. J. Stat. 38(1), 1–22 (2010)
Jasra, A., Kamatani, K., Law, K.J.H., Zhou, Y.: Multilevel particle filters. SIAM J. Numer. Anal. 55(6), 3068–3096 (2017)
Jones, B., Carvalho, C., Dobra, A., Hans, C., Carter, C., West, M.: Experiments in stochastic computation for high-dimensional graphical models. Stat. Sci. 20(4), 388–400 (2005)
Kantas, N., Beskos, A., Jasra, A.: Sequential Monte Carlo methods for high-dimensional inverse problems: a case study for the Navier-Stokes equations. SIAM/ASA J. Uncertainty Quant. 2(1), 464–489 (2014)
Lauritzen, S.L.: Graphical Models. Oxford Statistical Science Series, The Clarendon Press, New York (1996)
Lee, A., Singh, S.S., Vihola, M.: Coupled conditional backward sampling particle filter. Ann. Stat. 48(5), 3066–3089 (2020)
Lenkoski, A.: A direct sampler for G-Wishart variates. Stat 2(1), 119–128 (2013)
Middleton, L., Deligiannidis, G., Doucet, A., Jacob, P.E. Unbiased smoothing using particle independent Metropolis-Hastings. In: Chaudhuri K, Sugiyama M (eds) Proceedings of Machine Learning Research, PMLR, Proceedings of Machine Learning Research, vol 89, pp 2378–2387 (2019)
Murray, I., Ghahramani, Z., MacKay, D.J.C.: MCMC for doubly-intractable distributions. In: Proceedings of the Twenty-Second Conference on Uncertainty in Artificial Intelligence, AUAI Press, Arlington, Virginia, USA, UAI’06, pp. 359–366 (2006)
Rosenthal, J.S.: Faithful couplings of Markov chains: now equals forever. Adv. Appl. Math. 18(3), 372–381 (1997)
Roverato, A.: Hyper inverse Wishart distribution for non-decomposable graphs and its application to Bayesian inference for Gaussian graphical models. Scand. J. Stat. 29(3), 391–411 (2002)
Soh, S.E., Tint, M.T., Gluckman, P.D., Godfrey, K.M., Rifkin-Graboi, A., Chan, Y.H., Stünkel, W., Holbrook, J.D., Kwek, K., Chong, Y.S., Saw, S.M.: the GUSTO Study Group: Cohort profile: Growing up in Singapore towards healthy outcomes (GUSTO) birth cohort study. Int. J. Epidemiol. 43(5), 1401–1409 (2014)
Soininen, P., Kangas, A.J., Würtz, P., Tukiainen, T., Tynkkynen, T., Laatikainen, R., Järvelin, M.R., Kähönen, M., Lehtimäki, T., Viikari, J., Raitakari, O.T., Savolainen, M.J., Ala-Korpela, M.: High-throughput serum NMR metabonomics for cost-effective holistic studies on systemic metabolism. Analyst 134(9), 1781 (2009)
Statisticat, L.L.C.: LaplacesDemon: complete environment for Bayesian inference. R Package Vers. 16(1), 4 (2020)
Tan, L.S.L., Jasra, A., De Iorio, M., Ebbels, T.M.D.: Bayesian inference for multiple Gaussian graphical models with application to metabolic association networks. Ann. Appl. Stat. 11(4), 2222–2251 (2017)
Uhler, C., Lenkoski, A., Richards, D.: Exact formulas for the normalizing constants of Wishart distributions for graphical models. Ann. Stat. 46(1), 90–118 (2018)
Wang, H., Li, S.Z.: Efficient Gaussian graphical model determination under G-Wishart prior distributions. Electron. J. Stat. 6, 168–198 (2012)
Acknowledgements
We thank the referees for many useful suggestions that helped to greatly improve the content of the paper.
Funding
This work is supported by the Singapore Ministry of Education Academic Research Fund Tier 2 (grant number MOE2019-T2-2-100) and the Singapore National Research Foundation under its Translational and Clinical Research Flagship Programme and administered by the Singapore Ministry of Health’s National Medical Research Council (grant number NMRC/TCR/004-NUS/2008; NMRC/TCR/012-NUHS/2014). Additional funding is provided by the Singapore Institute for Clinical Sciences, Agency for Science, Technology and Research.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflicts of interest/Competing interests
The authors have no conflicts of interest to declare that relate to the content of this article.
Code availability
The scripts that produced the empirical results are available on https://github.com/willemvandenboom/cpmcmc.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
A Systematic resampling
Algorithms 7 through 9 detail the systematic resampling methods used for the empirical results derived from Algorithm 6. They involve the floor function denoted by \(\lfloor x\rfloor \), i.e., \(\lfloor x\rfloor \) is the largest integer for which \(\lfloor x\rfloor \le x\).



B Proofs for Section 4
Our results derive from Lee et al. (2020). They consider a smoothing set-up which maps to our context of approximating a general posterior \(\pi (x)\) using adaptive SMC. Specifically, their target density is (Lee et al. 2020, Equation 1)
In our context, the term \(M_0(x)=\pi _{\alpha _0}(x)\) is a tempered posterior, the term \(G_0(x) = {p(y\mid x)}^{\alpha _1 - \alpha _{0}}\) a tempered likelihood, \(M_s(x_{s-1}, x_s)\) the density of the Markov transition starting at \(x_{s-1}\) resulting from the \(m_s\) MCMC steps which are invariant w.r.t. \(\pi _{\alpha _s}(x)\) in Step 2c of Algorithm 2 for \(s=1,\dots ,S\), \(G_s(x_{s-1}, x_s) = {p(y\mid x_s)}^{\alpha _{s+1} - \alpha _{s}}\) a tempered likelihood for \(s=1,\dots ,S-1\), and \(G_S(x_{S-1}, x_S) = {p(y\mid x_S)}^{1 - \alpha _{S}}\) a tempered likelihood. Then, the coupled conditional particle filter in Algorithm 2 of Lee et al. (2020) reduces to the coupled conditional SMC in our Algorithm 4. Thus, the results in Lee et al. (2020) apply to Algorithm 4.
1.1 B.1 Proof of Proposition 1
Since \(G_s(x_{s-1}, x_s)\) does not depend on \(x_{s-1}\), we can write \(G_s(x_{s-1}, x_s) = G(x_s)\) for \(s=1,\dots ,S\) as in Section 2 of Lee et al. (2020). Assumption 1, that \({p(y\mid x)}\) is bounded, implies that \(G_s(x_s)\) is bounded for \(s=0,\dots ,S\), which is Assumption 1 in Lee et al. (2020). Therefore, Theorem 8 of Lee et al. (2020) provides \( \mathrm {Pr}(x_{0:S}' = {\bar{x}}_{0:S}') \ge N/(N+c). \)
Part (iii) follows similarly to the proof for Theorem 10(iii) of Lee et al. (2020): We have \(\mathrm {Pr}(\tau > t) \le \{1 - N/(N+c)\}^{t-1}\) for \(t\ge 1\). Therefore,
where the last equality follows from the geometric series formula \(\sum _{t=0}^\infty (1 - r)^t = 1/r\) for \(|r|<1\). Part (iii) implies Part (ii). \(\square \)
1.2 Proof of Proposition 2
Theorem 10 of Lee et al. (2020) provides results for a statistic that we denote by \(h_{0:S}: {\mathcal {X}}^{S+1}\rightarrow {\mathbb {R}}\). Consider \(h_{0:S}\) defined by \(h_{0:S}(x_{0:S})=h(x_S)\) where \(h:{\mathcal {X}}\rightarrow {\mathbb {R}}\) is our statistic of interest. Then, \(h_{0:S}\) is bounded by Assumption 2. The marginal distribution of \(x_S\) under the density on \(x_{0:S}\) in (4) is our posterior of interest \(\pi (x)\). Consequently, the results for \(h_{0:S}\) in Theorem 10 of Lee et al. (2020) provide the required results for h. \(\square \)
C Comparison with coupled HMC
The coupled HMC method of Heng and Jacob (2019) provides an alternative to coupled particle MCMC for unbiased posterior approximation if the posterior is amenable to HMC. The latter typically requires \({\mathcal {X}} = {\mathbb {R}}^{d_x}\) and that the posterior is continuously differentiable. Here, we apply coupled HMC to the posterior considered in Sect. 5.1 with a slight modification to make it suitable for HMC: the uniform prior over the hypercube \([-10, 10]^{d_x}\) is replaced by the improper prior \(p(x)\propto 1\) for \(x\in {\mathbb {R}}^{d_x}\) to ensure differentiability. The set-up of coupled HMC follows Section 5.2 of Heng and Jacob (2019) with the following differences. The leap-frog step size is set to 0.1 instead of 1 as the resulting MCMC failed to accept with the latter. We do not initialize both chains independently but instead set \({\bar{x}}(1)= x(0)\) as in Algorithm 6 since we found that this change reduces meeting times. We use code from https://github.com/pierrejacob/debiasedhmc to implement the method from Heng and Jacob (2019).

Results from execution of coupled HMC from Heng and Jacob (2019) for the case of the mixture of Gaussians, under the adjustments described in Appendix C. The top row contains a violin plot of \(\log (\tau )\). The bottom two rows show the integrated autocorrelation time and \({\hat{{{\,\mathrm{var}\,}}}}({\bar{h}}_k^l)\times \text {time}\) as a function of l, with their means and 95% bootstrapped confidence intervals in black and gray, respectively
Figure 5 presents the results analogously to Fig. 1. In terms of number of iterations, coupled HMC mixes worse and takes longer to meet than coupled particle MCMC. These increases are not offset by a lower computational cost per iteration. An important caveat here is that computation time depends on the implementation, and here coupled HMC is implemented using an R package and coupled particle MCMC in Python.
D Additional simulations studies
Here, we provide some further simulation studies where the set-up is the same as in Sect. 5.1 except for the following. We consider a probability of PIMH of \(\rho = 0.05\) in addition to the other values of \(\rho \), the maximum l is \(l_{\max }=2\cdot 10^3\) and the number of repetitions is \(R=128\). Figure 8 considers different number of particles of N. Figure 9 varies the dimensionality of the parameter \(d_x\) where we use the true values \(x^* = (-3, 0, 3)^\top \) and \(x^* = (-3, 0, 3, 6)^\top \) for \(d_x=3\) and \(d_x=4\), respectively, based on the set-up in Middleton et al. (2019, Appendix B.2). Additionally, Fig. 9b uses independent inner MCMC steps across both chains except for that the MCMC step is faithful to any coupling. This contrasts with Sect. 5.1 which uses a common random number coupling for the Metropolis-Hastings inner MCMC step.
A higher number of particles N results in shorter meeting times. Criterion ‘\({\hat{{{\,\mathrm{var}\,}}}}({\bar{h}}_k^l)\times \text {time}\)’ is lowest for larger N, though beyond a certain N, not much improvement is gained. Jacob et al. (2020a) reach a similar conclusion when varying N for coupled conditional particle filters.
Performance deteriorates with increasing dimensionality \(d_x\), especially for smaller values of \(\rho \). For \(d_x=4\) (Fig. 9d), the chains even often fail to meet within the maximum number of iterations of 2000 considered for \(\rho =0,0.05\). We also see such lack of coupling in Fig. 9b for \(\rho =0\), suggesting that the coupling of the inner MCMC is important for good performance when working with coupled conditional SMC. This is despite the fact that the theoretical results in Sect. 4 do not depend on the quality of the coupling of the inner MCMC.
For certain values of l, using \(\rho \) away from 0 or 1 is competitive with conditional SMC or PIMH in terms of ‘\({\hat{{{\,\mathrm{var}\,}}}}({\bar{h}}_k^l)\times \text {time}\)’ although not notably better than using just one of them. The benefit of a mixture versus using only conditional SMC in terms of coupling is highlighted in Fig. 9b where the inner MCMC is uncoupled.
E Inner MCMC step for Gaussian graphical models
We set up an MCMC step with \(p(x\mid y) = p(K,G\mid Y)\) as invariant distribution. The corresponding MCMC step for the tempered density \({p_\alpha (x\mid y)}\), \(\alpha \in (0,1]\), required for Algorithm 6, follows by replacing n and U by \(\alpha n\) and \(\alpha U\), respectively, as \(p(y\mid x)^\alpha =\)
\((2\pi )^{-\alpha np/2}|K|^{\alpha n/2} \exp (-\frac{1}{2}\left<K, \alpha U\right>)\). We make use of the algorithm for sampling from a G-Wishart law introduced in Lenkoski (2013, Section 2.4). Thus, we can sample from \({K\mid G, Y} \sim {\mathcal {W}}_G(\delta +n,\, D^*)\). It remains to derive an MCMC transition that preserves \(p(G\mid Y)\), as samples of G can be extended to \(x=(K,G)\) by generating \(K\mid G, Y\).
We consider the double reversible jump approach from Lenkoski (2013) and apply the node reordering from Cheng and Lenkoski (2012, Section 2.2) to obtain an MCMC step with no tuning parameters. The MCMC step is a Metropolis-Hastings algorithm on an enlarged space that bypasses the evaluation of the intractable normalisation constants \(I_G(\delta , D)\) and \(I_G(\delta +n,\, D^*)\) in the target distribution (3). It is a combination of ideas from the PAS algorithm of Godsill (2001), which avoids the evaluation of \(I_G(\delta +n,\, D^*)\), and the exchange algorithm of Murray et al. (2006), which sidesteps evaluation of \(I_G(\delta , D)\). We will give a brief presentation of the MCMC kernel that we are using as it does not coincide with approaches that have appeared in the literature.

The enlarged hierarchical model giving rise to a posterior on an extended space that will be preserved by our MCMC kernel. The construction aims at: (i) removing the requirement for calculation of intractable normalising constants; (ii) avoiding introducing tuning parameters. The main text defines \(\Phi =(\Phi _{-f}, \Phi _{p-1,p})\) and \({\tilde{\Phi }}=({\tilde{\Phi }}_{-f}, {\tilde{\Phi }}_{p-1,p})\)
To attain the objective of suppressing the normalising constants in the method, one works with a posterior on an extended space, defined via the directed acyclic graph in Fig. 6. The left side of the graph gives rise to the original posterior \(p(G)\, p(K\mid G)\, p(Y\mid K)\). Denote by \({\tilde{G}}\) the proposed graph, with law \(q({\tilde{G}}\mid G)\). Lenkoski (2013) chooses a pair of vertices (i, j) in G, \(i<j\), at random and applies a reversal, i.e. \((i,j)\in {\tilde{G}}\) if and only if \((i,j)\notin G\). The downside is that the probability of removing an edge is proportional to the number of edges in G, which is typically small. Instead, we consider the method in Dobra et al. (2011, Equation A.1) that also applies the reversal, but chooses (i, j) so that the probabilities of adding and removing an edge are equal.
We reorder the nodes of G and \({\tilde{G}}\) so that the edge that has been altered is \((p-1,p)\), similarly to Cheng and Lenkoski (2012, Section 2.2). Given \({\tilde{G}}\), the graph in Fig. 6 contains a final node that refers to the conditional distribution of \(p({\tilde{K}}\mid {\tilde{G}})\) which coincides with the G-Wishart prior \(p(K\mid G)\). Consider the upper triangular Cholesky decomposition \(\Phi \) of K so that \(\Phi ^\top \Phi = K\). Let \(\Phi _{-f} = \Phi \setminus \Phi _{p-1,p}\). We work with the map \(K \leftrightarrow \Phi =(\Phi _{-f}, \Phi _{p-1,p})\). We apply a similar decomposition for \({\tilde{K}}\), and obtain the map \({\tilde{K}} \leftrightarrow {\tilde{\Phi }}=({\tilde{\Phi }}_{-f}, {\tilde{\Phi }}_{p-1,p})\).
We can now define the target posterior on the extended space as
Given a graph G, the current state on the extended space comprises of
with \({\tilde{G}}\sim q({\tilde{G}}\mid G)\), and \(\Phi \), \({\tilde{\Phi }}\) obtained from the Cholesky decomposition of the precision matrices \(K\sim {\mathcal {W}}_G(\delta +n, D^{*})\), \({\tilde{K}} \sim {\mathcal {W}}_{{\tilde{G}}}(\delta , D)\), respectively. Note that the rows and columns of D, \(D^{*}\) have been accordingly reordered to agree with the re-arrangement of the nodes we describe above. Consider the scenario with the proposed graph \({\tilde{G}}\) having one more edge than G. Given the current state in (6), the algorithm proposes a move to the state
The value \(\Phi ^\text {pr}_{p-1,p}\) is sampled from the conditional law of \({\Phi }_{p-1,p}\mid {\Phi }_{-f}, Y\).
We provide here some justification for the above construction. The main points are the following: (i) the proposal corresponds to an exchange of \(G\leftrightarrow {\tilde{G}}\), coupled with a suggested value for the newly ‘freed’ matrix element \(\Phi ^\text {pr}_{p-1,p}\); (ii) from standard properties of the general exchange algorithm, switching the position of \(G, {\tilde{G}}\) will cancel out the normalising constants of the G-Wishart prior from the acceptance probability; (iii) the normalising constants of the G-Wishart posterior never appear, as the precision matrices are not integrated out.

Posterior edge inclusion probabilities for the Gaussian graphical model fit on the metabolite data from SMC with \(N=10^5\) particles (upper triangle) and their absolute difference from the estimates from coupled particle MCMC in Fig. 3 (lower triangle). LDL, HDL and FA stand for low-density lipoprotein, high-density lipoprotein and fatty acids, respectively

Results from execution of Algorithm 6 with \(\rho =0\) (conditional SMC), \(\rho = 0.05\), \(\rho = 0.5\) and \(\rho = 1\) (PIMH), for the case of the mixture of Gaussians for various number of particles N. The top row contains violin plots of \(\log (\tau )\). The bottom two rows show the integrated autocorrelation time and \({\hat{{{\,\mathrm{var}\,}}}}({\bar{h}}_k^l)\times \text {time}\) as a function of l, with their means and 95% bootstrapped confidence intervals in black and gray, respectively

Results from execution of Algorithm 6 with \(\rho =0\) (conditional SMC), \(\rho = 0.05\), \(\rho = 0.5\) and \(\rho = 1\) (PIMH), for the case of the mixture of Gaussians for various parameter dimensionalities \(d_x\) and, in (b), for when the inner MCMC steps are not coupled beyond being faithful. The top row contains violin plots of \(\log (\tau )\). The bottom two rows show the integrated autocorrelation time and \({\hat{{{\,\mathrm{var}\,}}}}({\bar{h}}_k^l)\times \text {time}\) as a function of l, with their means and 95% bootstrapped confidence intervals in black and gray, respectively
Appendix F derives that
This avoids the tuning of a step-size parameter arising in the Gaussian proposal of Lenkoski (2013, Section 3.2). The variable \({\tilde{\Phi }}^\text {pr}_{p-1,p}\) is not free, due to the edge \((p-1,p)\) assumed being removed, and is given as (Roverato 2002, Equation 10)
The acceptance probability of the proposal is given in Step 6 of the complete MCMC transition shown in Algorithm 10 for exponent \(\epsilon =1\). In the opposite scenario when an edge is removed from G, then, after again re-ordering the nodes, the proposal \({\tilde{\Phi }}^\text {pr}_{p-1,p}\) is sampled from
whereas we fix \(\Phi _{p-1,p}^\text {pr} = - \sum _{i=1}^{p-2} \Phi _{i,p-1}\Phi _{ip} /\Phi _{p-1,p-1}\). The corresponding acceptance probability for the proposed move is again as in Step 6 of Algorithm 10, but now for \(\epsilon =-1\).

F Proposal for precision matrices
This derivation is similar to Appendix A of Cheng and Lenkoski (2012). Assume that the edge \((p-1,p)\) is in the proposed graph \({\tilde{G}}\) but not in G. The prior on \({\tilde{\Phi }}_{p-1,p}\mid {\tilde{\Phi }}_{-f}\) follows from Equation 2 of Cheng and Lenkoski (2012) as
The likelihood is
Here, \(|{\tilde{K}}|\) does not depend on \({\tilde{\Phi }}_{p-1,p}\) since \(|{\tilde{K}}| = |{\tilde{\Phi }}|^2 = (\prod _{i=1}^p {\tilde{\Phi }}_{ii})^2\). Combining the previous two displays thus yields \(p({\tilde{\Phi }}_{p-1,p}\mid {\tilde{\Phi }}_{-f},Y) \propto \exp ( -\langle {\tilde{\Phi }}^\top {\tilde{\Phi }}, D^*\rangle / 2)\). Dropping terms not involving \({\tilde{\Phi }}_{p-1,p}\) yields (8).
G Comparison with SMC for the metabolite application
We compare the results in Fig. 3 with those from running the SMC in Algorithm 2 with a large number of particles \(N=10^5\). Comparing Figs. 3 and 7 shows that the results are largely the same. The edge probabilities for which they differ substantially are harder to estimate according to the Monte Carlo standard errors from coupled particle SMC in Fig. 3.
Rights and permissions
About this article

Cite this article
van den Boom, W., Jasra, A., De Iorio, M. et al. Unbiased approximation of posteriors via coupled particle Markov chain Monte Carlo. Stat Comput 32, 36 (2022). https://doi.org/10.1007/s11222-022-10093-3
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s11222-022-10093-3