
Abstract
This paper presents a new Metropolis-adjusted Langevin algorithm (MALA) that uses convex analysis to simulate efficiently from high-dimensional densities that are log-concave, a class of probability distributions that is widely used in modern high-dimensional statistics and data analysis. The method is based on a new first-order approximation for Langevin diffusions that exploits log-concavity to construct Markov chains with favourable convergence properties. This approximation is closely related to Moreau–Yoshida regularisations for convex functions and uses proximity mappings instead of gradient mappings to approximate the continuous-time process. The proposed method complements existing MALA methods in two ways. First, the method is shown to have very robust stability properties and to converge geometrically for many target densities for which other MALA are not geometric, or only if the step size is sufficiently small. Second, the method can be applied to high-dimensional target densities that are not continuously differentiable, a class of distributions that is increasingly used in image processing and machine learning and that is beyond the scope of existing MALA and HMC algorithms. To use this method it is necessary to compute or to approximate efficiently the proximity mappings of the logarithm of the target density. For several popular models, including many Bayesian models used in modern signal and image processing and machine learning, this can be achieved with convex optimisation algorithms and with approximations based on proximal splitting techniques, which can be implemented in parallel. The proposed method is demonstrated on two challenging high-dimensional and non-differentiable models related to image resolution enhancement and low-rank matrix estimation that are not well addressed by existing MCMC methodology.
Similar content being viewed by others
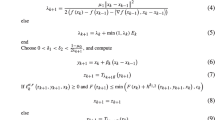


1 Introduction
With ever-increasing computational resources Monte Carlo sampling methods have become fundamental to modern statistical science and many of the disciplines it underpins. In particular, Markov chain Monte Carlo (MCMC) algorithms have emerged as a flexible and general purpose methodology that is now routinely applied in diverse areas ranging from statistical signal processing and machine learning to biology and social sciences. Monte Carlo sampling in high dimensions is generally challenging, especially in cases where standard techniques such as Gibbs sampling are not possible or ineffective. The most effective general purpose Monte Carlo methods for high-dimensional models are arguably the Metropolis-adjusted Langevin algorithms (MALA) (Robert and Casella 2004, p. 371) and Hamiltonian Monte Carlo (HMC) (Neal 2012), two classes of MCMC methods that use gradient mappings to capture local properties of the target density and explore the parameter space efficiently.
Advanced versions of MALA and HMC use other elements of differential calculus to achieve higher efficiency. For example, Yuan and Minka (2002) and Zhang and Sutton (2011) use Hessian matrices of the target density to capture higher-order information related to scale and correlation structure. Similarly, Girolami and Calderhead (2011) use differential geometry to lift these methods from Euclidean spaces to Riemannian manifolds where the target density is isotropic. In this paper we move away from differential calculus and explore the potential of convex analysis for MCMC sampling from distributions that are log-concave.
Log-concave distributions, also known as “convex models” outside the statistical literature, are widely used in high-dimensional statistics and data analysis and, among other things, play a central role in revolutionary techniques such as compressive sensing and image super-resolution (see Candès and Tao 2009; Candès and Wakin 2008; Chandrasekaran et al. 2012 for examples in machine learning, signal and image processing, and high-dimensional statistics). Performing inference in these models is a challenging problem that currently receives a lot of attention. A major breakthrough on this topic has been the adoption of convex analysis in high-dimensional optimisation, which led to the development of the so-called “proximal algorithms” that use proximity mappings of concave functions, instead of gradient mappings, to construct fixed point schemes and compute function maxima (see Combettes and Pesquet 2011; Parikh and Boyd 2014 for two recent tutorials on this topic). These algorithms are now routinely used to find the maximisers of posterior distributions that are log-concave and often non-smooth and very high dimensional (Afonso et al. 2011; Agarwal et al. 2012; Candès and Tao 2009; Candès et al. 2011; Chandrasekaran and Jordan 2013; Chandrasekaran et al. 2011; Pesquet and Pustelnik 2012).
In this paper we use convex analysis and proximal techniques to construct a new Langevin MCMC method for high-dimensional distributions that are log-concave and possibly not continuously differentiable. Our experiments show that the method is potentially useful for performing Bayesian inference in many models related to signal and image processing that are not well addressed by existing MCMC methodology, for example, non-differentiable models with synthesis and analysis Laplace priors, priors related to total-variation, nuclear and elastic-net norms or with constraints to convex sets, such as norm balls and the positive semidefinite cone.
The remainder of the paper is structured as follows: Section 2 specifies the class of distributions considered, defines some elements of convex analysis which are essential for our methods, and briefly recalls the unadjusted Langevin algorithm (ULA) and its Metropolised version MALA. In Sect. 3.1 we present a proximal ULA for log-concave distributions and study its geometric convergence properties. Following on from this, Section 3.2 presents a proximal MALA which inherits the favourable convergence properties of the unadjusted algorithm while guaranteeing convergence to the desired target density. Section 4 demonstrates the proposed methodology on two challenging high-dimensional applications related to image resolution enhancement and low-rank matrix estimation. Conclusions and potential extensions are finally discussed in Section 5. A MATLAB implementation of the proposed methods is available at http://www.maths.bris.ac.uk/~mp12320/code/ProxMCMC.zip.
2 Definitions and notations
2.1 Convex analysis
Let \(\varvec{x}\in {\mathbb {R}}^n\) and let \(\pi (\text {d}\varvec{x})\) be a probability distribution which admits a density \(\pi (\varvec{x})\) with respect to the usual \(n\)-dimensional Lebesgue measure. We consider the problem of simulating from target densities of the form
where \(g\,{:}\,{\mathbb {R}}^n \rightarrow [0,\infty )\) is a concave upper semicontinuous function satisfying \(\lim _{\Vert \varvec{x}\Vert \rightarrow \infty } g(\varvec{x}) = -\infty \). It is assumed that \(g(\varvec{x})\) can be evaluated point-wise and that the normalising constant \(\kappa \) may be unknown. Although not denoted explicitly, \(g\) may depend on the value of an observation vector, for instance in Bayesian inference problems. The methods presented in this paper will require \(g\) to have a proximity mapping that is inexpensive to evaluate or to approximate.
Definition 2.1
(Proximity mappings) The \(\lambda \)-proximity mapping or proximal operator of a concave function \(g\) is defined for any \(\lambda > 0\) as (Moreau 1962)
In order to gain intuition about this mapping it is useful to analyse its behaviour when the regularisation parameter \(\lambda \in {\mathbb {R}}^+\) is either very small or very large. In the limit \(\lambda \rightarrow \infty \), the quadratic penalty term vanishes and (2) maps all points to the set of maximisers of \(g\). In the opposite limit \(\lambda \rightarrow 0\), the quadratic penalty dominates (2) and the proximity mapping coincides with the identity operator, i.e. \(\hbox {prox}^\lambda _{g}(\varvec{x}) = \varvec{x}\). For finite values of \(\lambda \), \(\hbox {prox}^\lambda _{g}(\varvec{x})\) behaves similarly to a gradient mapping and moves points in the direction of the maximisers of \(g\). Indeed, proximity mappings share many important properties with gradient mappings that are useful for devising fixed point methods, such as being firmly non-expansive, i.e. \(\Vert \hbox {prox}^\lambda _{g}(\varvec{x})-\hbox {prox}^\lambda _{g}(\varvec{y})\Vert ^2 \le (\varvec{x}-\varvec{y})^T\{\hbox {prox}^\lambda _{g}(\varvec{x})-\hbox {prox}^\lambda _{g}(\varvec{y})\}, \forall \varvec{x},\varvec{y}\in {\mathbb {R}}^n\) (Bauschke and Combettes 2011, Chap. 12), and having the set of maximisers of \(g\) as fixed points. These mappings were originally studied by Moreau (1962), Martinet (1970) and Rockafellar (1976) several decades ago. They have recently regained very significant attention in the convex optimisation community because of their capacity to move efficiently in high-dimensional and possibly non-differentiable scenarios, and are now used extensively in the proximal optimisation algorithms that underpin modern high-dimensional statistics, signal and image processing, and machine learning (Agarwal et al. 2012; Chandrasekaran and Jordan 2013; Combettes and Pesquet 2011; Parikh and Boyd 2014). Section 3 shows that proximity mappings are not only useful for optimisation, they also hold great potential for stochastic simulation.
Definition 2.2
(Moreau approximations) For any \(\lambda > 0\), define the \(\lambda \)-Moreau approximation of \(\pi \) as the following density
with normalising constant \(\kappa ^\prime \in {\mathbb {R}}^+\). Moreau approximations (3) are closely related to Moreau–Yoshida envelope functions from convex analysis (Bauschke and Combettes 2011). Precisely, \(\log \pi _\lambda (\varvec{x})\) is equal to the \(\lambda \)-Moreau–Yoshida envelope of \(\log \pi (\varvec{x})\) up to the additive constant \(\log \kappa ^\prime \). Note that \(\pi _\lambda (\varvec{x})\) can be efficiently evaluated (up to a constant) by using \(\hbox {prox}^\lambda _g(\varvec{x})\), i.e. \(\pi _\lambda (\varvec{x}) \propto \exp {\left[ g\{\hbox {prox}^\lambda _{g}(\varvec{x})\}\right] } \exp {\{-\Vert \hbox {prox}^\lambda _{g}(\varvec{x}) - \varvec{x}\Vert ^2/2\lambda \}}\).
Definition 2.3
(Class of distributions \(\mathcal {E}(\beta ,\gamma )\)) We say that \(\pi \) belongs to the one-dimensional class of distributions with exponential tails \(\mathcal {E}(\beta ,\gamma )\) if for some \(u\), and some constants \(\gamma > 0\) and \(\beta > 0\), \(\pi \) takes the form
Moreau approximations have several properties that will be useful for constructing algorithms to simulate from \(\pi \).
-
1.
Convergence to \(\pi \) The approximation \(\pi _\lambda (\varvec{x})\) converges point-wise to \(\pi (\varvec{x})\) as \(\lambda \rightarrow 0\).
-
2.
Differentiability \(\pi _\lambda (\varvec{x})\) is continuously differentiable even if \(\pi \) is not, and its log-gradient is \(\nabla \log \pi _\lambda (\varvec{x}) = \{\hbox {prox}^\lambda _{g}(\varvec{x})-\varvec{x}\}/\lambda \).
-
3.
Subdifferential The point \(\{\hbox {prox}^\lambda _{g}(\varvec{x})-\varvec{x}\}/\lambda \) belongs to the subdifferentialFootnote 1 set of \(\log \pi \) at \(\hbox {prox}^\lambda _{g}(\varvec{x})\), i.e. \(\{\hbox {prox}^\lambda _{g}(\varvec{x})-\varvec{x}\}/\lambda \in \partial \log \pi \{\hbox {prox}^\lambda _{g}(\varvec{x})\}\) (Bauschke and Combettes 2011, Chap. 16). In addition, if \(\log \pi \) is differentiable at \(\hbox {prox}^\lambda _{g}(\varvec{x})\) then its subdifferential collapses to a single point, i.e. \(\{\hbox {prox}^\lambda _{g}(\varvec{x})-\varvec{x}\}/\lambda = \nabla \log \pi \{\hbox {prox}^\lambda _{g}(\varvec{x})\}\).
-
4.
Maximizers The set of maximizers of \(\pi _\lambda \) is equal to that of \(\pi \). Also, because \(\pi _\lambda \) is continuously differentiable, \(\nabla \log \pi _\lambda (\varvec{x}^*) = 0 \) implies that \(\varvec{x}^*\) is a maximizer of \(\pi \).
-
5.
Separability Assume that \(\pi (\varvec{x}) = \prod _{i=1}^n f_i(x_i)\) and let \({f_i}_\lambda \) be the \(\lambda \)-Moreau approximation of the marginal density \(f_i\). Then \(\pi _\lambda (\varvec{x}) = \prod _{i=1}^n {f_i}_\lambda (x_i)\).
-
6.
Exponential tails Assume that \(\pi \in \mathcal {E}(\beta ,\gamma )\) with \(\beta \ge 1\). Then \(\pi _\lambda \in \mathcal {E}(\beta ^\prime ,\gamma ^\prime )\) with \(\beta ^\prime = \min (\beta ,2)\).
Properties 1–5 are extensions of well known results for Moreau–Yoshida envelope functions first established in Moreau (1962). Property 1 results from the fact that in the limit \(\lambda \rightarrow 0\) the term \(\exp {\left( -\Vert \varvec{u}- \varvec{x}\Vert ^2/2\lambda \right) }\) tends to a Dirac delta function at \(\varvec{x}\). Property 2 can be easily established by using the results of Section 2.3 of Combettes and Wajs (2005). Property 3 follows from the fact that \(\hbox {prox}^\lambda _{g}(\varvec{x})\) is the maximiser of \(h(\varvec{u}) = \log \pi (\varvec{u}) - \Vert \varvec{u}- \varvec{x}\Vert ^2/2\lambda \) and therefore \(0 \in \partial h\{\hbox {prox}^\lambda _{g}(\varvec{x})\}\) (Combettes and Wajs 2005, Lemma 2.5). Property 4 follows from Properties 2 and 3: if \(\varvec{x}^*\) is a maximizer of \(\pi _\lambda \) then from Property 2, \(\hbox {prox}^\lambda _{\pi }(\varvec{x}^*) = \varvec{x}^*\), and from Property 3, \(0 \in \partial \log \pi (\varvec{x}^*)\). Then, Fermat’s rule, generalised to subdifferentials, together with the fact that \(\pi \) is log-concave implies that \(\varvec{x}^*\) is a maximizer of \(\pi \). Property 5 results from the fact that the proximity mapping of the separable sum \(g(\varvec{x}) = \sum _{i=1}^n \log f_i(x_i)\) is given by \(\{\hbox {prox}^\lambda _{\log f_1}(x_1),\ldots ,\hbox {prox}^\lambda _{\log f_n}(x_n)\}\) (Parikh and Boyd 2014, Chap. 2). Finally, to establish Property 6 we use (3) and (4) and note that for \(\varvec{x}\) sufficiently large, \(\pi _\lambda \) has exponentially decreasing tails with exponent \(\beta ^\prime = \beta \) if \(\beta \in [1,2]\) and \(\beta ^\prime = 2\) if \(\beta > 2\) (distributions with \(\beta < 1\) are not log-concave).
To illustrate these definitions, Fig. 1 depicts the Moreau approximations of four distributions that are log-concave: the Laplace distribution \(\pi (x) \propto \exp {\left( -|x|\right) }\), the Gaussian distribution \(\pi (x) \propto \exp {\left( -x^2\right) }\), the quartic or fourth-order polynomial distribution \(\pi (x) \propto \exp {\left( -x^4\right) }\), and the uniform distribution \(\pi (x) \propto \varvec{1}(\varvec{x})_{[-1,1]}\). We observe that the approximations are smooth, converge to \(\pi \) as \(\lambda \) decreases, and have the same maximisers as the true densities, as described by Properties 1, 2 and 4. We also observe that for densities with lighter-than-Gaussian tails, the Moreau approximation mimics the true density around the mode but has Gaussian tails, as described by Property 6.

Density plots for the Laplace (a), Gaussian (b), quartic (c) and uniform (d) distributions (solid black), and their Moreau approximations (3) for \(\lambda = 1, 0.1, 0.01\) (dashed blue and green, and solid red). (Color figure online)
As mentioned previously, the methods proposed in this paper are useful for models that have proximity mappings which are easy to evaluate or to approximate numerically (see Sect. 3.2.3 for more details). This is the case for many statistical models used in high-dimensional data analysis, where statistical inference is often conducted using convex optimisation algorithms that also require computing proximity mappings (see Afonso et al. 2011; Becker et al. 2009; Chandrasekaran et al. 2012; Recht et al. 2010 for examples in image restoration, compressive sensing, low-rank matrix recovery and graphical model selection). For more details about the evaluation of these mappings, their properties, and lists of functions with known mappings please see Bauschke and Combettes (2011), Combettes and Pesquet (2011) and (Parikh and Boyd (2014), Chap. 6). A library with MATLAB implementations of frequently used proximity mappings is available on https://github.com/cvxgrp/proximal.
2.2 Langevin Markov chain Monte Carlo
The sampling method presented in this paper is derived from the Langevin diffusion process and is related to other Langevin MCMC algorithms that we briefly recall below.
Suppose that \(\pi \) is everywhere non-zero and differentiable so that \(\nabla \log \pi \) is well defined. Then let \(W\) be the \(n\)-dimensional Brownian motion and consider a Langevin diffusion process \(\{Y(t): 0 \le t \le T\}\) on \({\mathbb {R}}^n\) that has \(\pi \) as stationary distribution. Such process is defined as the solution to the stochastic differential equation
Under appropriate stability conditions, \(Y(t)\) converges in distribution to \(\pi \) and is therefore potentially interesting for simulating from \(\pi \). Unfortunately, direct simulation from \(Y(t)\) is only possible in very specific cases. A more general solution is to consider a discrete-time approximation of the Langevin diffusion process with step-size \(\delta \). For computational reasons a forward Euler approximation is typically used, resulting in the so-called ULA
where the parameter \(\delta \) controls the discrete-time increment as well as the variance of the Gaussian perturbation \(Z^{(m)}\). Under certain conditions on \(\pi \) and \(\delta \), ULA produces a good approximation of \(Y(t)\) and converges to an ergodic measure which is close to \(\pi \). In MALA this approximation error is corrected by introducing a Metropolis-Hastings rejection step that guarantees convergence to the correct target density \(\pi \) (Roberts and Tweedie 1996).
It is well known that MALA can be a very efficient sampling method, particularly in high-dimensional problems. However, it is also known that for certain classes of target densities ULA is transient and as a result MALA is not geometrically ergodic (Roberts and Tweedie 1996). Geometric ergodicity is important theoretically to guarantee the existence of a central limit theorem for the chains and practically because sub-geometric algorithms often fail to explore the parameter space properly. Another limitation of MALA and HMC methods is that they require \(\pi \in \mathcal {C}^1\). This limits their applicability in many popular image processing and machine models that are not smooth.
In the following section we present a new MALA method that use proximity mappings and Moreau approximations to capture the log-concavity of the target density and construct chains with significantly better geometric convergence properties. We emphasise at this point that this is not the first work to consider modifications of MALA with better geometric convergence properties. For example, Roberts and Tweedie (1996) suggested using MALA with a truncated gradient to retain the efficiency of the Langevin proposal near the density’s mode and add robustness in the tails, though we have found this approach to be difficult to implement practically (this is illustrated in Sect. 3.2.4). Also, Casella et al. (2011) recently proposed three variations of MALA based on implicit discretisation schemes that are geometrically ergodic for one-dimensional distributions with super-exponential tails. For certain one-dimensional densities the methods presented in this paper are closely related to the partially implicit schemes of Casella et al. (2011). Manifold MALA (Girolami and Calderhead 2011) is also geometrically ergodic for a wide range of tail behaviours if \(\delta \) is sufficiently small (Łatuszyński et al. 2011).
3 Proximal MCMC
3.1 Proximal unadjusted Langevin algorithm
This section presents a proximal Metropolis-adjusted Langevin algorithm (P-MALA) that exploits convex analysis to sample efficiently from log-concave densities \(\pi \) of the form (1). In order to define this algorithm we first introduce the proximal unadjusted Langevin algorithm (P-ULA) that generates samples approximately distributed according to \(\pi \), and that will be used as proposal mechanism in P-MALA. We establish that P-ULA is geometrically ergodic in many cases for which ULA is transient or explosive and that P-MALA inherits these favourable properties, converging geometrically fast in many cases in which MALA does not.
A key element of this paper is to first approximate the Langevin diffusion \(Y(t)\) with an auxiliary diffusion \(Y_\lambda (t)\) that has invariant measure \(\pi _\lambda \), defined by the stochastic differential equation (5) with \(\pi \) replaced by its \(\lambda \)-Moreau approximation (3). The regularity properties of \(\pi _\lambda \) will lead to discrete approximations with favourable stability and convergence qualities. We wish to use \(Y_\lambda (t)\) to simulate from \(\pi _\lambda \), which we can make arbitrarily close to \(\pi \) by selecting a small value of \(\lambda \). Direct simulation from \(Y_\lambda (t)\) is typically infeasible and we thus consider the forward Euler approximation (6) for \(Y_\lambda (t)\),
From Property 2 we obtain that (7) is equal to
This Markov chain has two interpretations that provide insight on how to select an optimal value for \(\lambda \). First, (8) is a discrete approximation of a Langevin diffusion with invariant measure \(\pi _\lambda \), and since we are interested is simulating from \(\pi \), we should set \(\lambda \) to a small value as possible to bring \(\pi _\lambda \) close to \(\pi \). Second, from a convex optimisation viewpoint, (8) coincides with a relaxed proximal point iteration to maximise \(\log \pi \) with relaxation parameter \(\delta /2\lambda \), plus a stochastic perturbation given by \(\sqrt{\delta }Z\) (Rockafellar 1976). According to this second interpretation \(\lambda \) should not be smaller than \(\delta /2\), as this could lead to an unstable proximal point update that is expansive and therefore to an explosive Markov chain. We therefore define the optimal \(\lambda \) as the smallest value within the range of stable values \([\delta /2,\infty )\). Setting \(\lambda = \delta /2\) we obtain the P-ULA Markov chain
We now study the convergence properties of P-ULA. In a manner akin to Roberts and Tweedie (1996), we study geometric convergence for the case where \(\pi \) is one-dimensional and we illustrate our results on the class \(\mathcal {E}(\beta ,\gamma )\). Extensions to high-dimensional models of the form \(\pi (\varvec{x}) = \prod _{i=1}^n f_i(x_i)\) are possible by using Property 5, and to high-dimensional densities \(\pi \in \mathcal {C}^\infty \) with Lipschitz gradients by using Theorem 7.1 of Mattingly et al. (2002).
Theorem 3.1
Suppose that \(\pi \) is one-dimensional and that (1) holds. For some fixed \(d >0\), let
Then \(\text {P-ULA}\) is geometrically ergodic if for some \(d \in [0,1]\) both \(S_d^+ < 0\) and \(S_d^- > 0\) exist.
Proof
The proof follows from the fact that \(\nabla \log \pi _{\delta /2}\) is continuous and \(\text {P-ULA}\) is \(\mu ^{Leb}\)-irreducible and weak Feller, and hence all compact sets are small (Meyn and Tweedie 1993, Chap. 6). Then, using Property 2, the conditions on \(S_d^+\) and \(S_d^-\) are equivalent to the conditions of part (a) of Theorem 3.1 of Roberts and Tweedie (1996) establishing that \(\text {P-ULA}\) is geometrically ergodic for \(d \in [0,1)\). For \(d = 1\) we proceed similarly to Property 6 and note that for approximations \(\pi _{\delta /2}\) with Gaussian tails we have that \(S_1^+ \in (-1,0)\) and \(S_1^- \in (0,1)\), thus part (b) of Theorem 3.1 of Roberts and Tweedie (1996) applies. Finally, notice from Property 2 that the values of \(d\), \(S_d^+\) and \(S_d^-\) are closely related to the tails of the approximation \(\pi _{\delta /2}\), i.e. \(\lim _{x\rightarrow \infty } \frac{\text {d}}{\text {d}x} \log \pi _{\delta /2}(x) = S_d^+ x^d + o(|x|^d)\) and \(\lim _{x\rightarrow -\infty } \frac{\text {d}}{\text {d}x}\log \pi _{\delta /2}(x) = S_d^- x^d + o(|x|^d)\). \(\square \)
Theorem 3.1 is most clearly illustrated when \(\pi \) belongs to the class \(\mathcal {E}(\beta ,\gamma )\). Recall that ULA is not ergodic for if \(\beta >2\) and only for \(\delta \) sufficiently small if \(\beta = 2\) (Roberts and Tweedie 1996).
Corollary 3.1
Assume that \(\pi \in \mathcal {E}(\beta ,\gamma )\) and that (1) holds. Then \(\text {P-ULA}\) is geometrically ergodic for all \(\delta > 0\).
This result follows from the fact that (1) implies \(\beta \ge 1\) (distributions belonging to \(\mathcal {E}(\beta ,\gamma )\) with \(\beta < 1\) are not log-concave), which in turn implies that \(\pi _{\delta /2} \in \mathcal {E}(\beta ^\prime ,\gamma ^\prime )\) with \(\beta ^\prime = \min (\beta ,2)\) and some \(\gamma ^\prime > 0\). The geometric convergence of \(\text {P-ULA}\) is then established by checking that for \(d = \beta ^\prime - 1\) the limits \(S_d^+\) and \(S_d\) exist and verify the conditions of Theorem 3.1 for all \(\delta >0\).
The results presented above establish that under certain conditions on \(\pi \) \(\text {P-ULA}\) converges geometrically to some unknown ergodic measure. To determine if this stationary measure is a good approximation of \(\pi \), and thus if P-ULA is a good proposal for a Metropolis–Hastings algorithm, we consider the more general question of how well \(\text {P-ULA}\) approximates the time-continuous diffusion \(Y(t)\) as a function of \(\delta \) [we consider strong mean-square convergence to \(Y(t)\) in the sense of Higham et al. (2003), which also implies the convergence of P-ULA’s ergodic measure to \(\pi \)].
Theorem 3.2
Suppose that \(\pi \in \mathcal {C}^2\) and that (1) holds. Then there exists a continuous-extension \(\bar{Y}(t)\) of the \(\text {P-ULA}\) chain for which
where \(Y(t)\) is the Langevin diffusion (5) with ergodic measure \(\pi \). Moreover, if \(\nabla \log \pi \) is polynomial in \(\varvec{x}\), then \(\text {P-ULA}\) converges strongly to \(Y(t)\) at optimal rate; that is,
Proof
To prove the first result we use Property 3 to express P-ULA as a split-step backward Euler approximation of \(Y(t)\) (i.e. \(Y^{(m+1)} = Y^{+} + \sqrt{\delta } W^{(m)}\) with \(Y^{+} = \frac{\delta }{2}\nabla \log \pi \left( Y^{+}\right) + Y^{(m)}\)), and apply Theorem 3.3 of Higham et al. (2003), where we note that assumption (1) implies condition 3.1 of Higham et al. (2003). The second result follows from Theorem 4.7 of Higham et al. (2003). \(\square \)
3.2 Proximal Metropolis-adjusted Langevin algorithm
3.2.1 Metropolis–Hastings correction
As explained previously, P-ULA simulates samples from an approximation of \(\pi \). A natural strategy to correct this approximation error is to supplement P-ULA with a Metropolis–Hasting accept–reject step guaranteeing convergence to \(\pi \), leading to a P-MALA. This is a Metropolis–Hastings chain \(X^{(m)}\) that uses \(\text {P-ULA}\) as proposal. Precisely, given \(X^{(m)}\), a candidate \(Y^{*}\) is generated by using one \(\text {P-ULA}\) transition
We accept this candidate and set \(X^{(m)} = Y^{*}\) with probability
where \(q\{Y^*|X^{(m)}\} = p_{\mathcal {N}}\left[ Y^*|\hbox {prox}^\lambda _g\{X^{(m)}\},\delta \mathbb {I}_n\right] \) is the \(\text {P-ULA}\) transition kernel given by (9). Otherwise, with probability \(1-\text {r}\{X^{(m)},Y^*\}\), we reject the proposition and set \(X^{(m+1)} = X^{(m)}\). By the Hastings construction, the P-MALA chain converges to \(\pi \) in the total-variation norm [this follows from the facts that the chain is irreducible, aperiodic and \(\pi \)-invariant (Robert and Casella 2004, Chap. 7)]. Note that though (11) involves two proximity mappings, we only need to evaluate \(\hbox {prox}^{\delta /2}_{g}(X^{*})\) at each iteration since \(\hbox {prox}^{\delta /2}_{g}\{X^{(m)}\}\) is known from the algorithm’s previous iteration.
3.2.2 Convergence properties
We provide two alternative sets of conditions for the geometric ergodicity of \(\text {P-MALA}\) and illustrate our results on the case where \(\pi \) belongs to the class \(\mathcal {E}(\beta ,\gamma )\), which we use as benchmark for comparison with other MALAs.
Theorem 3.3
Suppose that (1) holds. Let \(A(\varvec{x}) = \{\varvec{u}: \text {r}(\varvec{x},\varvec{u}) = 1 \}\) be the acceptance region of \(\text {P-MALA}\) from point \(\varvec{x}\), and \(I(\varvec{x}) = \{\varvec{u}: \Vert \varvec{x}\Vert \ge \Vert \varvec{u}\Vert \}\) the region of points interior to \(\varvec{x}\). Suppose that \(A\) converges inwards in \(q\), i.e.
where \(A(\varvec{x})\Delta I(\varvec{x})\) denotes the symmetric difference \(A(\varvec{x}) \cup I(\varvec{x}) \setminus A(\varvec{x}) \cap I(\varvec{x})\). Then \(\text {P-MALA}\) is geometrically ergodic.
Proof
To prove this result we use Theorem 5.14 of Bauschke and Combettes (2011) to show that if (1) holds then, for any \(\varvec{x}\), the mean candidate position \(\hbox {prox}^\lambda _g(\varvec{x})\) verifies the inequality \(\Vert \hbox {prox}^\lambda _g(\varvec{x})\Vert < \Vert \varvec{x}\Vert \). This result, together with the condition that \(A\) converges inwards in \(q\), implies that \(\text {P-MALA}\) is geometrically ergodic (Roberts and Tweedie 1996, Theorem 4.1). \(\square \)
Corollary 3.2
Suppose that \(\pi \in {\mathcal {E}}(\beta ,\gamma )\) and that (1) holds. Then P-MALA is geometrically ergodic for all \(\delta > 0\).
Proving this result simply consists of checking that if \(\pi \in {\mathcal {E}}(\beta ,\gamma )\) and (1) holds then \(A\) converges inwards in \(q\) and therefore Theorem 3.3 applies, where we note that (1) implies that \(\beta \ge 1\).
Notice from Corollary 3.2 that P-MALA has very robust stability and converge properties. For comparison, MALA is not geometrically ergodic for any \(\pi \in {\mathcal {E}}(\beta ,\gamma )\) with \(\beta > 2\) (Roberts and Tweedie 1996) and manifold MALA is geometrically ergodic for \(\pi \in {\mathcal {E}}(\beta ,\gamma )\) with \(\beta \ne 1\) only if \(\delta \) is sufficiently small (Łatuszyński et al. 2011). P-MALA inherits these robust convergence properties from P-ULA, or more precisely from the regularity properties of \(\pi _{\delta /2}\) that guarantee that P-ULA is always stable and geometrically ergodic. In particular, that \(\log \pi _{\delta /2}\) decays at mostly quadratically, that \(\nabla \log \pi _{\delta /2}\) always exists and is Lipchitz continuous, and that the tails of \(\pi _{\delta /2}\) broaden with \(\delta \) such that \(Y_{\delta /2}(t)\) is always within the stability range of a forward Euler approximation with time step \(\delta \).
Moreover, the convergence properties of \(\text {P-MALA}\) can also be studied in the framework of Random walk Metropolis–Hastings algorithms with bounded drift (Atchade 2006).
Theorem 3.4
Suppose that \(\pi \in \mathcal {C}^1\) and that (1) holds. Assume that there exists \(R > 0\) such that \(\forall \varvec{x}\in {\mathbb {R}}^n, \Vert \varvec{x}- \hbox {prox}^{\delta /2}{g}(\varvec{x})\Vert < R \), and that \(\pi \) verifies the conditions
Then \(\text {P-MALA}\) is geometrically ergodic.
Proof
The proof of this result follows from the proof of geometric ergodicity for the Shrinkage-thresholding MALA (Schreck et al. 2013), which is general to all Metropolis–Hastings algorithms with bounded drift, and where we note that the conditions on \(\pi \), together with the bounded drift condition \(\Vert \varvec{x}- \hbox {prox}^\lambda _{g}(\varvec{x})\Vert < R\), satisfy the assumptions of Theorem 4.1 of Schreck et al. (2013). \(\square \)
Notice that it is always possible to enforce the bounded drift condition by composing \(\hbox {prox}^\lambda _{g}(\varvec{x})\) with a projection onto an \(\ell _2\)-ball centred at \(\varvec{x}\) (this is equivalent to using a truncated gradient as proposed in (Roberts and Tweedie 1996)). Also, it is possible to relax the smoothness assumption to \(\pi \in \mathcal {C}^0\) by adding assumptions A3 and A4 from Schreck et al. (2013).
Finally, similarly to other MH algorithms based on local proposals, P-MALA may be geometrically ergodic yet perform poorly if the proposal variance \(\delta \) is either too small or very large. Theoretical and experimental studies of MALA show that for many high-dimensional target densities the value of \(\delta \) should be set to achieve an acceptance rate of approximately 40–70 % (Pillai et al. 2012). These results do not apply directly to P-MALA. However, given the similarities between MALA and P-MALA, it is reasonable to assume that the values of \(\delta \) that are appropriate for MALA will generally also produce good results for P-MALA. In our experiments we have found that P-MALA performs well when \(\delta \) is set to achieve an acceptance rate of 40–60 %.
3.2.3 Computation of the proximity mapping \(\hbox {prox}^{\delta /2}_{g}(\varvec{x})\)
The computational performance of P-MALA depends strongly on the capacity to evaluate efficiently \({\hbox {prox}}^{\delta /2}_{g}(\varvec{x}) = \mathop {\hbox {argmax}}_{\varvec{u}\in {\mathbb {R}}^n}\, g(\varvec{u}) -\Vert \varvec{u}- \varvec{x}\Vert ^2/\delta \). As mentioned previously, the computation of proximity mappings is the focus of significant research efforts because these operators are key to modern convex and non-convex optimisation. As a result, for many important models used in high-dimensional data analysis, signal and image processing, and statistical machine learning, there are now clever analytical or numerical techniques to evaluate these mappings efficiently (two examples of this are the total-variation and the nuclear-norm priors used in the experiments of Sect. 4). For a survey on the evaluation of proximity mappings and lists of some functions with known mappings please see (Parikh and Boyd (2014), Chap. 6) and Combettes and Pesquet (2011).
The most general strategy for computing \(\hbox {prox}^{\delta /2}_{g}(\varvec{x})\) is to note that (2) is a convex optimisation problem that can frequently be solved or approximated quickly with state-of-the-art convex optimisation algorithms. Komodakis and Pesquet (2014) presents these algorithms in the primal-dual framework and provides clear guidelines for parallel and distributed implementations. When applying these techniques within P-MALA it is important to use \(\varvec{x}\) to hot-start the optimisation, particularly in high-dimensional models where \({\hbox {prox}}^{\delta /2}_{g}(\varvec{x})\) is close to \(\varvec{x}\) because \(\delta \) has been set to a small value to achieve a good acceptance probability (recall that \({\hbox {prox}}^{\delta /2}_{g}(\varvec{x}) \rightarrow \varvec{x}\) when \(\delta \rightarrow 0\)).
Alternatively, for many popular models it possible to approximate \(\hbox {prox}^{\delta /2}_{g}(\varvec{x})\) very efficiently by using a decomposition \(g(\varvec{x}) = g_1(\varvec{x}) + g_2(\varvec{x})\) where \(g_1 \in \mathcal {C}^1\) is concave with \(\nabla g_1\) Lipschitz continuous and where \({\hbox {prox}}^{\delta /2}_{g_2}\) can be evaluated efficiently. This enables the approximation
that is used in the forward-backward or proximal gradient algorithm (Combettes and Pesquet 2011). We found this approximation to be very accurate for high-dimensional models because, again, \(\delta \) is set to a small value and \(\hbox {prox}^{\delta /2}_{g}(\varvec{x})\) is close to \(\varvec{x}\), and as a result the approximation \(g_1(\varvec{u}) \approx g_1(\varvec{x}) + (\varvec{u}-\varvec{x})^T\nabla g_1(\varvec{x})\) is generally accurate. Approximation (12) is useful for instance in linear inverse problems of the form \(g(\varvec{x}) = -(\varvec{y}-H\varvec{x})^T \Sigma ^{-1}(\varvec{y}-H\varvec{x})/2 -\alpha \phi (\varvec{x})\) involving a Gaussian likelihood and a convex regulariser \(\phi (\varvec{x})\) with a tractable proximity mapping [\(\phi (\varvec{x})\) is often some norm, which generally have known and fast proximity mappings (Parikh and Boyd 2014, Chap. 6.5)]. Notice that many signal and image processing problems can be formulated in this way (Combettes and Pesquet 2011). Moreover, if \(g_1 \in \mathcal {C}^2\) it is also possible to use a second-order approximation
where \(H_{i,j}(\varvec{x}) = \partial ^2 g_1/\partial x_i \partial x_j\) or an approximation that simplifies the computation of (13) (for example, if \(\hbox {prox}^{\delta /2}_{g_2}\) is separable, then using a diagonal approximation of the Hessian matrix of \(g_1\) leads to an approximation (13) that can be computed in parallel for each element of \(\varvec{x}\), and that has the same computational complexity as (12)). Again, many signal and image processing models it is possible to solve (13) efficiently with a few iterations of the ADMM algorithm of Afonso et al. (2011), which exploits the second-order information from \(H(\varvec{x})\) to improve convergence speed.
Finally, it is worth noting that although using an approximation of \(\hbox {prox}^{\delta /2}_{g}(\varvec{x})\) can potentially reduce P-MALA’s mixing speed, if the conditions for geometric ergodicity of Theorem 3.4 hold when \(\hbox {prox}^{\delta /2}_{g}(\varvec{x})\) is evaluated exactly, then P-MALA implemented with an approximate mapping also converges geometrically to \(\pi \) if the approximation error can be bounded by some \(R^\prime > 0\) or if \(\hbox {prox}^\lambda _{g}(\varvec{x})\) is followed by a projection to guarantee a bounded drift.
3.2.4 Illustrative example
For illustration we show an application of P-MALA to the density \(\pi (x) \propto \exp (-x^4)\) depicted in Fig. 1c. We compare our results with MALA, with the truncated gradient MALA (MALTA) (Roberts and Tweedie 1996), and with the simplified manifold MALA (SMMALA) (Girolami and Calderhead 2011). As explained previously, MALA is not geometrically ergodic for this target density due to the lighter-than-Gaussian tails. This can be cured by using MALTA, which is a bounded drift random walk Metropolis–Hastings algorithm constructed by replacing \(h(x) = \nabla \log \pi (x)\) in the MALA proposal with \(h_{\epsilon _1}(x) = \epsilon _1 h(x) / \max (\epsilon _1,\Vert h(x)\Vert )\) for some \(\epsilon _1 > 0\) (Atchade 2006). Although geometrically ergodic, MALTA can converge very slowly if the truncation threshold \(\epsilon _1\) is not set correctly. Setting good values for \(\epsilon _1\) can be difficult in practice, particularly because values that appear suitable in certain regions of the state space are unsuitable in others. Alternatively, manifold MALA implemented using the (regularised) inverse Hessian \(H^{-1}_{\epsilon _2}(x) = (12x^{2} + \epsilon _2)^{-1}\) is also geometrically ergodic if \(\delta \) is sufficiently small (for this example \(\delta \le 6\)) (Łatuszyński et al. 2011), however this algorithm can also converge slowly if the value of \(\epsilon _2\) is not set properly.
Figure 2a–d displays the first \(250\) samples of the chains generated with P-MALA, MALA, MALTA and SMMALA with initial state \(X^{(0)} = 10\) and \(\delta = 1\). We implemented MALTA and SMMALA using the values \(\epsilon _1 = 20\) and \(\epsilon _2 = 0.1\) that we adjusted during a series of pilot runs. We found that MALTA behaves like a Random walk Metropolis–Hastings algorithm for smaller values of \(\epsilon _1\), and that for larger values it rejects the proposed moves with very high probability and gets “stuck”. Similarly, we found that SMMALA is very sensitive to the value of \(\epsilon _2\), with too small values leading to poor mixing around the mode and larger values to poor mixing in the tails.

Comparison between P-MALA, MALA, the truncated gradient MALA (MALTA), and simplified manifold MALA (SMMALA) using the one-dimensional density \(\pi (x) \propto \exp \{-x^4\}\) and algorithm parameters \(\delta = 1, \epsilon _1 = 20, \epsilon _2 = 0.1\). Initial state \(X^{(0)} = 10\) (a–d) and \(X^{(0)} = 5\) (e–h)
We observe in Fig. 2a–d that the chains generated with P-MALA and MALTA exhibit good mixing, that SMMALA has slower mixing, and that MALA has rejected all the proposed moves and failed to converge. We repeated this experiment using the initial state \(X^{(0)} = 5\) and the same values for \(\delta \), \(\epsilon _1\) and \(\epsilon _2\). The first \(250\) samples of each chain are displayed in Fig. 2e–h. Again, we observe the good mixing of P-MALA, the slower mixing of SMMALA, and the lack of ergodicity of MALA. However, we also observe that in this occasion MALTA got “stuck” at states where its mixing properties are very poor and failed to converge. We also repeated this experiment with HMC (not shown) and observed that it suffers from the same drawbacks as MALA.
4 Applications
This section demonstrates P-MALA on two challenging high-dimensional and non-smooth models that are widely used in statistical signal and image processing and that are not well addressed by existing MCMC methodology. The first example considers the computation of Bayesian credibility regions for an image resolution enhancement problem. The second example presents a graphical posterior predictive check of the popular nuclear-norm model for low-rank matrices.
4.1 Bayesian image deconvolution with a total-variation prior
In image deconvolution or deblurring problems, the goal is to recover an original image \(\varvec{x}\in {\mathbb {R}}^n\) from a blurred and noisy observed image \(\varvec{y}\in {\mathbb {R}}^n\) related to \(\varvec{x}\) by the linear observation modelFootnote 2 \(\varvec{y}= H\varvec{x}+ \varvec{w}\), where \(H\) is a linear operator representing the blur point spread function and \(\varvec{w}\) is the sample of a zero-mean white Gaussian vector with covariance matrix \(\sigma ^2\varvec{I}_n\) (Hansen et al. 2006). This inverse problem is usually ill-posed or ill-conditioned, i.e. either \(H\) does not admit an inverse or it is nearly singular, thus yielding highly noise-sensitive solutions. Bayesian image deconvolution methods address this difficulty by exploiting prior knowledge about \(\varvec{x}\) in order to obtain more robust estimates. One of the most widely used image priors for deconvolution problems is the improper total-variation norm prior, \(\pi (\varvec{x}) \propto \exp {\left( -\alpha \Vert \nabla _d \varvec{x}\Vert _1\right) }\), where \(\nabla _d\) denotes the discrete gradient operator that computes the vertical and horizontal differences between neighbour pixels. This prior encodes the fact that differences between neighbour image pixels are often very small and occasionally take large values (i.e. image gradients are nearly sparse). Based on this prior and on the linear observation model described above, the posterior distribution for \(\varvec{x}\) is given by
Image processing methods using (14) are almost exclusively based on maximum-a-posteriori (MAP) estimates of \(\varvec{x}\) that can be efficiency computed using proximal optimisation algorithms (Afonso et al. 2011). Here we consider the problem of computing credibility regions for \(\varvec{x}\), which we use to assess the confidence in the restored image. Precisely, we note that (14) is log-concave and use P-MALA to compute marginal \(90\,\%\) credibility regions for each image pixel. There are several computational strategies for evaluating the proximity mapping of \(g(\varvec{x}) = -\Vert \varvec{y}-H\varvec{x}\Vert ^2/2\sigma ^2 -\alpha \Vert \nabla \varvec{x}\Vert _1\). Here we take advantage of the fact that in high-dimensional scenarios \(\delta \) is typically set to a small value and use the approximation (12) \(\hbox {prox}^{\delta /2}_{g}(\varvec{x}) \approx \hbox {prox}^{\delta /2}_{g_2}\{\varvec{x}+ \delta \nabla g_1(\varvec{x})/2\}\) with \(g_1(\varvec{x}) = -\Vert \varvec{y}-H\varvec{x}\Vert ^2/2\sigma ^2\) and \(g_2(\varvec{x}) = -\alpha \Vert \nabla \varvec{x}\Vert _1\), and where we note that \(\nabla g_1\) is Lipschitz continuous and that \(\hbox {prox}^{\delta /2}_{g_2}(\varvec{x})\) can be efficiently computed using a parallel implementation of Chambolle (2004).
Figure 3 presents an experiment with the “cameraman” image, which is a standard image to assess deconvolution methods (Oliveira et al. 2009). Figure 3a, b shows the original cameraman image \({\varvec{x}}_0\) of size \(128\times 128\) and a blurred and noisy observation \(\varvec{y}\), which we produced by convoluting \({\varvec{x}}_0\) with a uniform blur of size \(9\times 9\) and adding white Gaussian noise to achieve a blurred signal-to-noise ratio (BSNR) of \(40\) dB (\(\text {BSNR} = 10\log _{10}\{\text {var}(H{\varvec{x}}_0)/\sigma ^2\}\)). The MAP estimate of \(\varvec{x}\) obtained by maximising (14) is depicted in Fig. 3c. This estimate has been computed with the proximal optimisation algorithm of Afonso et al. (2011), and by using the technique of Oliveira et al. (2009) to determine the value of \(\alpha \). By comparing Fig. 3a, c we observe that the MAP estimate is very accurate and that it restored the sharp edges and fine details in the image. Finally, Fig. 3d shows the magnitude of the marginal \(90\,\%\) credibility regions for each pixels, as measured by the distance between the 95 and \(5\,\%\) quantile estimates. These estimates were computed from a 20,000-sample chain generated with P-MALA using a thinning factor of 1000 to reduce the algorithm’s memory foot-print and \(1\) million burn-in iterations. These credibility regions show that there is a background level of uncertainty of about \(30\) grey-levels, which is approximately \(10\,\%\) of the dynamic range of the image (\(256\) grey-levels). More importantly, we observe that there is significantly more uncertainty concentrated at the contours and object boundaries in the image. This reveals that model (14) is able to accurately detect the presence of sharp edges in the image but with some uncertainty about their exact location. Therefore computing credibility regions could be particularly relevant in applications that use images to determine the location and the size of objects, or to compare the size of a same object appearing in two different images. For example, in oncological medical imaging, where deconvolution is increasingly used to improve the resolution of images that are subsequently used to assess the evolution of tumour boundaries over time and make treatment decisions.

a Original cameraman image (\(128\times 128\) pixels), b blurred image, c MAP estimate computed with (Afonso et al. 2011), d pixel-wise \(90\,\%\) credibility intervals estimated with P-MALA
Moreover, to asses the efficiency of P-MALA we repeated the experiment with a variation of MALA for partially non-differentiable target densities that uses only the gradient of the differentiable term of (14), i.e. \(\nabla \log g_1 (\varvec{x})= H^T(\varvec{y}-H\varvec{x})/\sigma ^2\) (this variation of MALA was recently used in Schreck et al. (2013) for a Bayesian variable selection problem with a Bernulli–Laplace prior that is also non-differentiable). Figure 4 compares the first \(20\) lags of the sample autocorrelation function of the chains generated with P-MALA and MALA, computed using \(\log \pi (\varvec{x}|\varvec{y})\) as scalar summary. We observe that the chain produced with P-MALA has significantly lower autocorrelation and therefore higher effective sample sizeFootnote 3 (ESS). P-MALA was almost twice as computationally expensive as MALA due to the overhead associated with evaluating the proximity mapping of \(g_2\) (the total computational times were 49 h for P-MALA and 28 h for MALA). However, because P-MALA is exploring the parameter space significantly faster than MALA, its time-normalised ESS was \(4.5\) times better than that of MALA (\(50.8\) and \(11.04\) samples per hour respectively), confirming the good performance of the proposed methodology. Preconditioning MALA with the (regularised) inverse Fisher information matrix \((H^T H + \epsilon \mathbb {I}_n)^{-1}\) led to poor mixing, possibly because most of the correlation structure in the posterior distributions comes from the non-differentiable prior \(\pi (\varvec{x}) \propto \exp {[-\alpha \Vert \nabla _d\varvec{x}\Vert _1]}\) and is not captured by this metric.

Autocorrelation comparison between P-MALA and MALA when simulating from (14)
4.2 Nuclear-norm models for low-rank matrix estimation
In this experiment we use P-MALA to perform a graphical posterior predictive check of the widely used nuclear norm model for low-rank matrices (Fazel 2002). Simulating samples from distributions involving the nuclear norm is challenging because matrices are often high-dimensional and because this norm is not continuously differentiable; thus making it difficult to use gradient-based MCMC methods such as MALA and HMC. For simplicity we present our analysis in the context of matrix denoising, however the approach can be easily applied to other low-rank matrix estimation problems such as matrix completion and decomposition (Candès and Plan 2009; Candès and Tao 2009; Chandrasekaran et al. 2011, 2012; Candès et al. 2011).
Let \(\varvec{x}\) be an unknown low-rank matrix of size \(n = n_1 \times n_2\) (represented as a point in \({\mathbb {R}}^n\) by lexicographic ordering), and \(\varvec{y}= \varvec{x}+ \varvec{w}\) a noisy observation contaminated by zero-mean white Gaussian noise with covariance matrix \(\sigma ^2\varvec{I}_n\). For example, \(\varvec{x}\) can represent a low-rank covariance matrix in a model selection problem, the background component of a video signal in an object tracking problem, or a rank-limited image in a signal restoration or reconstruction problem (Candès et al. 2011; Chandrasekaran et al. 2012; Recht et al. 2010). In the low-rank matrix denoising problem, we seek to recover \(\varvec{x}\) from \(\varvec{y}\) under the prior knowledge that \(\varvec{x}\) has low rank; that is, that most of its singular values are zero. A convenient model for this type of problem is the nuclear norm prior \( \pi (\varvec{x}) \propto \exp (-\alpha ||\varvec{x}||_*)\), where \(||\varvec{x}||_*\) denotes the nuclear norm of \(\varvec{x}\) and is defined as the sum of its singular values (Fazel 2002). The popularity of this prior stems from the fact that the nuclear norm is the best convex approximation of the rank function, and it leads to a posterior distribution that is log-concave and whose MAP estimate can be efficiently computed using proximal algorithms (Recht et al. 2010). The posterior distribution of \(\varvec{x}\) given \(\varvec{y}\) is
where \(\sigma ^2\) and \(\alpha \) are fixed positive hyper-parameters. It is useful to think of (15) as an extension the Bayesian LASSO model (Park and Casella 2008) to matrices with sparse singular values, in which the singular values of \(\varvec{x}\) are assigned exponential priors.
It is well documented that under certain conditions on the true rank and \(\sigma ^2\), the MAP estimate maximising (15) accurately recovers the true null and column spaces of \(\varvec{x}\) (Candès and Plan 2009; Candès and Tao 2009; Negahban and Wainwright 2012; Rahul et al. 2010). This has led to the general consensus that the nuclear-norm prior is a useful model for low-rank matrix estimation problems and that the errors introduced by using the convex approximation to the rank function do not have a significant effect on the inferences. Here we adopt a Bayesian model checking viewpoint and assess the nuclear-norm model by comparing the observation \(\varvec{y}\) to replicas \(\varvec{y}^\mathrm{rep}\) generated by drawing samples from the posterior predictive distribution \(f(\varvec{y}^\mathrm{rep}|\varvec{y}) = \int _{{\mathbb {R}}^{n\times m}} f(\varvec{y}^\mathrm{rep}|\varvec{x})\pi (\varvec{x}|\varvec{x})\text {d}\varvec{x}\), as recommended by (Gelman et al. (2013), Chap. 6). This technique for checking the fit of a model to data is based on the intuition that “If the model fits, then replicated data generated under the model should look similar to observed data. To put it another way, the observed data should look plausible under the posterior predictive distribution” (Gelman et al. 2013, Chap. 6). In this paper we perform a graphical check and compare visually \(\varvec{y}\) and its replicas \(\varvec{y}^\mathrm{rep}\). In specific applications one could also use \(\varvec{y}^\mathrm{rep}\) to compute posterior predictive p-values that evaluate specific aspects of the model that are relevant to the application (Gelman et al. 2013, Chap. 6).
Figure 5 presents an experiment with MATLAB’s “checkerboard” image. Figure 5a shows the original checkerboard image \(\varvec{x}_0\) of size \(n = 64\times 64\) pixels and rank \(2\). Figure 5b shows a noisy observation \(\varvec{y}\) produced by adding Gaussian noise with variance \(\sigma ^2 = 0.01\), leading to a signal-to-noise ratio (SNR) of \(15\) dB which is standard for image denoising problems (\(\text {SNR} = 10\log _{10}(||\varvec{x}_0||^2/n m\sigma ^2)\)). The MAP estimate obtained by maximising (15) is depicted in Fig. 5c. This estimate has been computed via singular value soft-thresholding, and by setting \(\alpha =1.15/\sigma ^2\) to minimise Stein’s unbiased risk estimator, which are standard procedures in low-rank matrix denoising (Candès et al. 2013). By comparing Fig. 5a, c we observe that the MAP estimate is indeed very close the original image \(\varvec{x}_0\), confirming that the nuclear-norm prior is a good model for low-rank signals (the estimation mean-squared error is \(6.45 \times 10^{-4}\), which is \(15\) times better than the original error of \(0.01\)). Note however that this prior is a simplistic model for \(\varvec{x}_0\) in the sense that it does not include many of its main features; e.g. that \(\varvec{x}_0\) is piecewise constant, periodic, highly symmetric, or that its pixel only take 3 values. Also, its representation of the singular values is approximate given that the true singular values are perfectly sparse rather than exponentially distributed. Therefore it is interesting to examine if the predictions of the model exhibit all the relevant features of \(\varvec{y}\), or if they highlight limitations of (15).

a Original checkerboard image \(\varvec{x}_0\) (\(64\times 64\) pixels, rank \(2\)), b noisy observation \(\varvec{y}= \varvec{x}_0 + \varvec{w}\), c MAP estimate associated with (15), d–i Six replicas of \(\varvec{y}\) generated by sampling from the posterior predictive distribution \(f(\varvec{y}^\mathrm{rep}|\varvec{y})\)
Figure 5d–i depicts six random replicas of \(\varvec{y}\) drawn from the posterior predictive distribution \(f(\varvec{y}^\mathrm{rep}|\varvec{y})\) generated with P-MALA. We observe that the replicas are visually very similar to the original observation depicted in Fig. 5b and exhibit all of the main structural features of the checkerboard pattern that we mentioned above (e.g. periodicity, symmetries, etc.) as well as a grey-level histogram that is very similar to that of \(\varvec{y}\). This suggests that the model is indeed capturing the main visual characteristics of our data. The replicas for this experiment were generated by using P-MALA to simulate \(N=20\,000\) samples \(\{X^{(t)}, t=1,\ldots ,N\}\) distributed according to (15), and then sampling \(Y^{\mathrm{rep} (t)}|X^{(t)} \sim {\mathcal {N}}[X^{(t)},\varvec{I}\sigma ^2]\) (the pictures displayed in Fig. 5d–i correspond to \(t = 7500, 10000, 12500, 15000, 17500\), and \(20000\)). To implement P-MALA for (15) we used the exact proximity mapping
where \(\text {SVT}(\varvec{x},\tau )\) denotes the singular value soft-thresholding operator on \(\varvec{x}\) with threshold \(\tau \), that is evaluated by computing the singular value representation of \(\varvec{x}\) and replacing the singular values \(\{s_i: i = 1,\ldots ,\min (n1,n2)\}\) with \(\max {(s_i - \tau ,0)}\). We used 2000 burn-in iterations, a thinning factor of \(100\) to reduce the algorithm’s memory foot-print, and tuned the value of \(\delta \) to achieve an acceptance probability of approximately \(50\,\%\).
To illustrate the good mixing properties of P-MALA for this 4096-dimensional simulation problem, Fig. 6 shows a 1000-sample trace plot and an autocorrelation function plot of the chain \(\{X^{(t)}, t=1,\ldots ,N\}\), where we have used \(g[X^{(t)}]\) as scalar summary. The computing time, ESS and time-normalised ESS for this experiment are 19 min, 7930 samples and \(7.05\) samples per second. For comparison, repeating this experiment with a random walk Metropolis–Hastings (RWMH) algorithm required 6.5 min and produced a time-normalised ESS of \(0.23\) samples per second, approximately \(30\) times worse than P-MALA. Finally, note that MALA and HMC are not well defined for this model because \(||\varvec{x}||_*\) is not differentiable at points where \(\varvec{x}\) is rank deficient. From a practical standpoint one can still apply MALA to (15) because the probability of reaching a non-differentiable state is zero, however in our experience MALA does require \(\pi \in \mathcal {C}^1\) to perform well. Repeating this experiment with MALA produced a time-normalised ESS of \(0.08\) samples per second, \(90\) times worse than P-MALA and \(30\) times worse than RWHM [results computed by setting \(\delta \) to achieve an acceptance rate of approximately \(60\,\%\) and by computing the gradient of \(||\varvec{x}||_*\) via singular-value decomposition (Papadopoulo and Lourakis 2000)].

a 1000-sample trace plot and b autocorrelation plot using \(g[X^{(t)}]\) as scalar summary
5 Conclusion
This paper studied a new Langevin MCMC algorithm that use convex analysis, namely Moreau approximations and proximity mappings, to sample efficiently from high-dimensional densities \(\pi \) that are log-concave and possibly not continuously differentiable. This method is based on a new first-order approximation for Langevin diffusions that is constructed by first approximating the original diffusion \(Y(t)\) with an auxiliary Langevin diffusion \(Y_\lambda (t)\) with ergodic measure \(\pi _\lambda \), and then discretising \(Y_\lambda (t)\) using a forward Euler scheme with time step \(\delta =2\lambda \). The resulting Markov chain, P-ULA, is similar to ULA except for the fact that it uses proximity mappings of \(\log \pi \) instead of gradient mappings. This modification leads to a chain with favourable convergence properties that is geometrically ergodic in many cases for which ULA is transient or explosive. The proposed sampling method, P-MALA, combines P-ULA with a Metropolis–Hastings step guaranteeing convergence to the desired target density. It is shown that P-MALA inherits the favourable convergence properties of P-ULA and is geometrically ergodic in many cases for which MALA does not converge geometrically and for which manifold MALA is only geometric if the time step is sufficiently small. Moreover, because P-MALA uses proximity mappings instead of gradients it can be applied to target densities that are not continuously differentiable, whereas MALA and manifold MALA require \(\pi \in {\mathcal {C}}^1\) and \(\pi \in {\mathcal {C}}^2\) to perform well. Finally, P-MALA was validated and compared to other MCMC algorithms through illustrative examples and applications to real data, including two challenging high-dimensional experiments related to image deconvolution and low-rank matrix denoising. These experiments show that P-MALA can make Bayesian inference techniques practically feasible for high-dimensional and non-differentiable models that are not well addressed by the existing MCMC methodology.
Moreover, although only directly applicable to log-concave distributions, P-MALA can be used within a Gibbs sampler to simulate from more complex models. For example, it can be easily applied to a large class of bilinear models of the form (14) in which there is uncertainty about the linear operator \(H\) (e.g. semi-blind image restoration), as this models can be conveniently split into two high-dimensional conditional densities that are log-concave. Similarly, its application to hierarchical models involving unknown regularisation or noise power hyper-parameters is also straightforward. Future works will focus on the application of P-MALA to the development of new statistical signal and image processing methodologies. In particular, we plan to develop a general set of tools for computing Bayesian estimators and credibility regions for high-dimensional convex linear and bilinear inverse problems, as well as stochastic optimisation algorithms for empirical Bayes estimation in signal and image processing. Another important perspective for future work is to investigate the rate of convergence of P-MALA as a function of the dimension of \(\varvec{x}\). This cannot be achieved with the mathematical techniques used in of Theorems 3.1, 3.3 and 3.4, and will require using a more appropriate set of techniques based on the Wasserstain framework (see Ottobre and Stuart 2014 for more details). Preliminary analyses suggest that P-MALA’s mixing time depends on the shape of (the tail of) \(\pi \), unlike the random walk Metropolis–Hastings algorithm and MALA whose scaling is, under some conditions, independent of \(\pi \).
Also, in some applications the performance of P-MALA could be improved by introducing some form of adaptation or preconditioning that captures the local geometry of the target density. This could be achieved by learning the density’s covariance structure online (Atchade 2006) or by using an appropriate position-dependent metric. For models with \(\pi \in \mathcal {C}^2\) this metric can be derived from the Fisher information matrix or the Hessian matrix as suggested in Girolami and Calderhead (2011), and for other log-concave densities perhaps by using preconditioning techniques from the convex optimisation literature, such as Marnissi et al. (2014) for instance. A key factor will be the availability of efficient algorithms for evaluating proximity mappings on non-canonical Euclidean spaces (i.e. defined using a quadratic penalty functions of the form \((\varvec{u}-\varvec{x})^TA(\varvec{x})(\varvec{u}-\varvec{x})\) for some positive definite matrix \(A(\varvec{x})\)). This topic currently receives a lot of attention in the optimisation literature and is the focus of important engineering efforts. Alternatively, one could also consider extending our methods to other diffusions that are more robust to anisotropic target densities (Roberts and Stramer 2002; Stramer and Tweedie 1999a, b).
We emphasise at this point that P-MALA complements rather than substitutes existing MALA and HMC methods by making high-dimensional simulation more efficient for target densities that are log-concave and have fast proximity mappings, in particular when they are not continuously differentiable. However, there are many models for which state-of-the-art MALA and HMC methods perform very well and for which P-MALA would not be applicable or computationally competitive.
Finally, we acknowledge that since the first preprint of this work (Pereyra 2013), two other works have independently proposed using proximity mappings in MCMC algorithms. These algorithms are similar to P-MALA in that they use thresholding operators within MALA and HMC algorithms (thresholding operators are a particular type of proximity mapping), but otherwise differ significantly from P-MALA. In particular, Schreck et al. (2013) considers a MALA for a variable selection problem and uses thresholding/shrinking operators to design a proposal distribution with atoms at zero (i.e. that generates sparse vectors with positive probability). Chaari et al. (2014) also considers an algorithm for a similar variable selection problem related to signal processing. Similarly to Schreck et al. (2013) that algorithm also uses thresholding operators, but to approximate gradients within an HMC leap-frog integrator. However, because thresholding operators are not continuously differentiable it is not clear if this integrator preserves volume and more crucially if the resulting HMC algorithm converges exactly to the desired target density.
Notes
A vector \(\varvec{u}\in {\mathbb {R}}^n\) is a subgradient of the concave function \(g\) at the point \(\varvec{x}_0 \in {\mathbb {R}}^n\) if \(g(\varvec{x}) \le g(\varvec{x}_0) + (\varvec{x}-\varvec{x}_0)^T\varvec{u}\) for all \(\varvec{x}\in {\mathbb {R}}^n\). The set \(\partial g(\varvec{x}_0)\) of all such subgradients is called the subdifferential set of \(g\) at the point \(\varvec{x}_0\).
Note that bidimensional and tridimensional images can be represented as points in \({\mathbb {R}}^n\) via lexicographic ordering.
Recall that \(\text {ESS} = N\{1+2\sum _k \gamma (k)\}^{-1}\), where \(N\) is the total samples and \(\sum _k \gamma (k)\) is the sum of the \(K\) monotone sample auto-correlations which we estimated with the initial monotone sequence estimator (Geyer 1992).
References
Afonso, M., Bioucas-Dias, J., Figueiredo, M.: An augmented Lagrangian approach to the constrained optimization formulation of imaging inverse problems. IEEE. Trans. Image Process. 20(3), 681–695 (2011)
Agarwal, A., Negahban, S., Wainwright, J.M.: Fast global convergence of gradient methods for high-dimensional statistical recovery. Ann. Stat. 40(5), 2452–2482 (2012)
Atchade, Y.: An adaptive version for the Metropolis adjusted Langevin algorithm with a truncated drift. Methodol. Comput. Appl. Probab. 8(2), 235–254 (2006)
Bauschke, H.H., Combettes, P.L.: Convex Analysis and Monotone Operator Theory in Hilbert Spaces. Springer, New York (2011)
Becker, S., Bobin, J., Candès, E.J.: NESTA: a fast and accurate first-order method for sparse recovery. SIAM J. Imaging Sci. 4(1), 1–39 (2009)
Candès, E.J., Plan, Y.: Matrix completion with noise. Proc. IEEE 98, 925–936 (2009)
Candès, E.J., Tao, T.: The power of convex relaxation: near-optimal matrix completion. IEEE Trans. Inf. Theory 56(5), 2053–2080 (2009)
Candès, E.J., Wakin, M.B.: An introduction to compressive sampling. IEEE Signal Process. Mag. 25(2), 21–30 (2008)
Candès, E. J., Li, X., Ma, Y., Wright, J.: Robust principal component analysis? J. ACM 58(3), 11:1–11:37 (2011)
Candès, E.J., Sing-Long, C.A., Trzasko, J.D.: Unbiased risk estimates for singular value thresholding and spectral estimators. IEEE Trans. Signal Process. 61(19), 4643–4657 (2013)
Casella, B., Roberts, G., Stramer, O.: Stability of partially implicit Langevin schemes and their MCMC variants. Methodol. Comput. Appl. Probab. 13(4), 835–854 (2011)
Chaari, L., Batatia, H., Chaux, C. & Tourneret, J.-Y.: Sparse signal and image recovery using a proximal Bayesian algorithm. ArXiv e-prints (2014)
Chambolle, A.: An algorithm for total variation minimization and applications. J. Math. Imaging Vis. 20(1–2), 89–97 (2004)
Chandrasekaran, V., Jordan, M.I.: Computational and statistical tradeoffs via convex relaxation. Proc. Natl Acad. Sci. U.S.A. 110(13), 1181–1190 (2013)
Chandrasekaran, V., Sanghavi, S., Parrilo, P., Willsky, A.: Rank-sparsity incoherence for matrix decomposition. SIAM J. Optim. 21(2), 572–596 (2011)
Chandrasekaran, V., Parrilo, P.A., Willsky, A.S.: Latent variable graphical model selection via convex optimization. Ann. Stat. 40(4), 1935–1967 (2012)
Combettes, P., Wajs, V.: Signal recovery by proximal forward-backward splitting. Multiscale Model. Simul. 4(4), 1168–1200 (2005)
Combettes, P.L., Pesquet, J.-C.: Proximal splitting methods in signal processing. In: Bauschke, H.H., Burachik, R.S., Combettes, P.L., Elser, V., Luke, D.R., Wolkowicz, H. (eds.) Fixed-Point Algorithms for Inverse Problems in Science and Engineering, pp. 181–212. Springer, New York (2011)
Fazel, M.: Matrix rank minimization with applications. PhD thesis, Department of Electrical Engineering, Stanford University (2002)
Gelman, A., Carlin, J.B., Stern, H.S., Dunson, D.B., Vehtari, A., Rubin, D.B.: Bayesian Data Analysis, 3rd edn. Chapman and Hall/CRC, London (2013)
Geyer, C.J.: Practical Markov chain Monte Carlo. Stat. Sci. 7(4), 473–483 (1992)
Girolami, M., Calderhead, B.: Riemann manifold Langevin and Hamiltonian Monte Carlo methods. J. R. Stat. Soc. Ser. B 73(2), 123–214 (2011)
Hansen, P.C., Nagy, J.G., O’Leary, D.P.: Deblurring Images: Matrices, Spectra, and Filtering. SIAM, Philadelphia (2006)
Higham, D.J., Mao, X., Stuart, A.M.: Strong convergence of Euler-type methods for nonlinear stochastic differential equations. SIAM J. Numer. Anal. 40(3), 1041–1063 (2003)
Komodakis, N., Pesquet, J.-C.: Playing with duality: an overview of recent primal-dual approaches for solving large-scale optimization problems. ArXiv e-prints (2014)
Łatuszyński, K., Roberts, G.O., Thiéry, A., Wolny, K.: Discussion of Riemann manifold Langevin and Hamiltonian Monte Carlo methods by Mark Girolami and Ben Calderhead. J. R. Stat. Soc. Ser. B 73(2), 188–189 (2011)
Marnissi, Y., Benazza-Benyahia, A., Chouzenoux, E., Pesquet, J.-C.: Majorize-Minimize adapted Metropolis-Hastings algorithm. Application to multichannel image recovery. In: 22th European Signal Processing Conference (EUSIPCO 2014), Lisbon, Portugal (2014)
Martinet, B.: Regularisation d’inéquations variationelles par approximations successives. Revue Fran. d’Automatique et Infomatique Rech. Opérationelle 4, 154–159 (1970)
Mattingly, J., Stuart, A., Higham, D.: Ergodicity for SDEs and approximations: locally Lipschitz vector fields and degenerate noise. Stoch. Proc. Appl. 101(2), 185–232 (2002)
Meyn, S., Tweedie, R.: Markov Chains and Stochastic Stability. Springer, London (1993)
Moreau, J.-J.: Fonctions convexes duales et points proximaux dans un espace Hilbertien. C. R. Acad. Sci. Paris Sér. A Math. 255, 2897–2899 (1962)
Neal, R.: MCMC using Hamiltonian dynamics. ArXiv e-prints (2012)
Negahban, S., Wainwright, M.J.: Restricted strong convexity and weighted matrix completion: optimal bounds with noise. J. Mach. Learn. Res. 13, 1665–1697 (2012)
Oliveira, J., Bioucas-Dias, J., Figueiredo, M.: Adaptive total variation image deblurring: a majorization-minimization approach. Signal Process. 89(9), 1683–1693 (2009)
Ottobre, M., Stuart, A.M.: Diffusion limit for the random walk Metropolis algorithm out of stationarity. ArXiv e-prints (2014)
Papadopoulo, T., Lourakis, M. I. A.: Estimating the Jacobian of the singular value decomposition: theory and applications. In: Proceedings of the 6th European Conference on Computer Vision-Part I (ECCV ’00), pp. 554–570 (2000)
Parikh, N., Boyd, S.: Proximal algorithms. Found. Trends Optim. 1(3), 123–231 (2014)
Park, T., Casella, G.: The Bayesian lasso. J. Am. Stat. Assoc. 103(482), 681–686 (2008)
Pereyra, M.: Proximal Markov chain Monte Carlo algorithms. ArXiv e-prints (2013)
Pesquet, J.-C., Pustelnik, N.: A parallel inertial proximal optimization method. Pac. J. Optim. 8(2), 273–305 (2012)
Pillai, N.S., Stuart, A.M., Thiry, A.H.: Optimal scaling and diffusion limits for the Langevin algorithm in high dimensions. Ann. Appl. Probab. 22(6), 2320–2356 (2012)
Rahul, M., Trevor, H., Robert, T.: Spectral regularization algorithms for learning large incomplete matrices. J. Mach. Learn. Res. 11, 2287–2322 (2010)
Recht, B., Fazel, M., Parrilo, P.A.: Guaranteed minimum rank solutions to linear matrix equations via nuclear norm minimization. SIAM Rev. 52(3), 471–501 (2010)
Robert, C.P., Casella, G.: Monte Carlo Statistical Methods, 2nd edn. Springer, New York (2004)
Roberts, G., Stramer, O.: Langevin diffusions and Metropolis–Hastings algorithms. Methodol. Comput. Appl. Probab. 4, 337–357 (2002)
Roberts, G.O., Tweedie, R.L.: Exponential convergence of Langevin distributions and their discrete approximations. Bernulli 2(4), 341–363 (1996)
Rockafellar, R.T.: Monotone operators and the proximal point algorithm. SIAM J. Control Optim. 14, 877–898 (1976)
Schreck, A., Fort, G., Le Corff, S., Moulines, E.: A shrinkage-thresholding Metropolis adjusted Langevin algorithm for Bayesian variable selection. ArXiv e-prints (2013)
Stramer, O., Tweedie, R.L.: Langevin-type models I: diffusions with given stationary distributions and their discretizations. Methodol. Comput. Appl. Probab. 1, 283–306 (1999a)
Stramer, O., Tweedie, R.L.: Langevin-type models II: self-targeting candidates for MCMC algorithms. Methodol. Comput. Appl. Probab. 1, 307–328 (1999b)
Yuan, Q., Minka, T. P.: Hessian-based Markov chain Monte Carlo Algorithms. Unpublished manuscript (2002)
Zhang, Y., Sutton, C.: Quasi-Newton Markov chain Monte Carlo. In: Advances in Neural Information Processing Systems (NIPS) (2011)
Acknowledgments
The author would like to thank the editor and two anonymous reviewers for their valuable suggestions to improve the manuscript. The author is also grateful to Ioannis Papastathopoulos, Gersende Fort, Nick Whiteley, Peter Green, Jonathan Rougier, Guy Nason, Nicolas Dobigeon, Steve McLaughlin, Hadj Batatia and Jean-Christophe Pesquet for helpful comments. Marcelo Pereyra holds a Marie Curie Intra-European Fellowship for Career Development. This work was supported in part by the SuSTaIn program - EPSRC grant EP/D063485/1 - at the Department of Mathematics, University of Bristol, and by a French Ministry of Defence postdoctoral fellowship.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Pereyra, M. Proximal Markov chain Monte Carlo algorithms. Stat Comput 26, 745–760 (2016). https://doi.org/10.1007/s11222-015-9567-4
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11222-015-9567-4