
Abstract
Let the Ornstein–Uhlenbeck process \((X_t)_{t\ge 0}\) driven by a fractional Brownian motion \(B^{H }\) described by \(dX_t = -\theta X_t dt + \sigma dB_t^{H }\) be observed at discrete time instants \(t_k=kh\), \(k=0, 1, 2, \ldots , 2n+2 \). We propose an ergodic type statistical estimator \({\hat{\theta }}_n \), \({\hat{H}}_n \) and \({\hat{\sigma }}_n \) to estimate all the parameters \(\theta \), H and \(\sigma \) in the above Ornstein–Uhlenbeck model simultaneously. We prove the strong consistence and the rate of convergence of the estimator. The step size h can be arbitrarily fixed and will not be forced to go zero, which is usually a reality. The tools to use are the generalized moment approach (via ergodic theorem) and the Malliavin calculus.

Similar content being viewed by others

References
Biagini F, Hu Y, Ø ksendal B, Zhang T (2008) Stochastic calculus for fractional Brownian motion and applications. Probability and its applications. Springer, New York
Brouste A, Iacus SM (2013) Parameter estimation for the discretely observed fractional Ornstein–Uhlenbeck process and the Yuima R package. Comput Stat 28(4):1529–1547
Chen Y, Hu Y, Wang Z (2017) Parameter estimation of complex fractional Ornstein–Uhlenbeck processes with fractional noise. ALEA Lat Am J Probab Math Stat 14(1):613–629
Cheng Y, Hu Y, Long H (2020) Generalized moment estimation for Ornstein-Uhlenbeck processes driven by \(\alpha \)-stable lévy motions from discrete time observations. Stat Inference Stoch Process 23(1):53–81
Cheridito P, Kawaguchi H, Maejima M (2003) Fractional Ornstein-Uhlenbeck processes. Electron J Probab 8(3):1–14
Hu Y (2017) Analysis on Gaussian spaces. World Scientific Publishing Co., Pte. Ltd, Hackensack
Hu Y, Nualart D (2010) Parameter estimation for fractional Ornstein–Uhlenbeck processes. Stat Probab Lett 80(11–12):1030–1038
Hu Y, Song J (2013) Parameter estimation for fractional Ornstein–Uhlenbeck processes with discrete observations. In: Viens F, Feng J, Hu Y, Nualart E (eds) Malliavin calculus and stochastic analysis. Springer proceedings in mathematics & statistics, vol 34. Springer, Boston, pp 427–442
Hu Y, Nualart D, Zhou H (2019) Parameter estimation for fractional Ornstein–Uhlenbeck processes of general Hurst parameter. Stat Inference Stoch Process 22(1):111–142
Kubilius K, Mishura IS, Ralchenko K (2017) Parameter estimation in fractional diffusion models, vol 8. Springer, Berlin
Magdziarz M, Weron A (2011) Ergodic properties of anomalous diffusion processes. Ann Phys 326(9):2431–2443
Mustafa OG, Rogovchenko-Yuri V (2007) Estimates for domains of local invertibility of diffeomorphisms. Proc Am Math Soc 135(1):69–75
Panloup F, Tindel S, Varvenne M (2019) A general drift estimation procedure for stochastic differential equations with additive fractional noise. arXiv:1903.10769
Tudor CA, Viens FG et al (2007) Statistical aspects of the fractional stochastic calculus. Ann Stat 35(3):1183–1212
Acknowledgements
We thank the referees for the constructive comments.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supported by NSERC discovery grant and a startup fund of University of Alberta.
Appendices
Appendix A: Detailed computations
First, we need the following lemma.
Lemma A.1
Let \(X_t\) be the Ornstein–Uhlenbeck process defined by (1.1). Then
The above inequality also holds true for \(Y_t\).
Proof
From Cheridito et al. (2003, Theorem 2.3), we have that
But \(X_t=Y_t -e^{-\theta t} Y_0\). This combined with (A.2) proves (A.1). \(\square \)
Lemma A.2
Let \(X_t\) be defined by (1.1) and let a, b, c, d be integers. When \(H \in (0,\frac{1}{2})\cup (\frac{1}{2},\frac{3}{4})\) we have
Proof
To simplify notations we shall use \(X_k\), \(Y_k\) to represent \(X_{kh}\), \(Y_{kh}\) etc. From the relation (3.3) it is easy to see that
where \( I_{i, k, k'}=I_{i,a, b, k, k'} \), \(i=1, \ldots , 4\), denote the above i-th term.
Let us consider \(\frac{1}{n} \sum _{k,k'=1}^n I_{i, k,k'}^2 \) for \(i=2, 3, 4\). First, we consider \(i=2\). By Cheridito et al. (2003, Theorem 2.3), we know that \({\mathbb {E}}(Y_0Y_{k})\) converges to 0 when \(k\rightarrow \infty \). Thus by the Toeplitz theorem, we have
Exactly in the same way we have
When \(i=4\), we have easily
Now we have
First, let us consider \({\mathcal {I}}_{1,1,n}\). By the stationarity of \(Y_n\), we have
By Lemma A.1 for \(Y_t\) or an expression of \({\mathbb {E}}(Y_0Y_m) \) given in Cheridito et al. (2003, Theorem 2.3):
This means \({\mathbb {E}}(Y_0Y_m) = O(m^{2H-2})\) as \(m\rightarrow \infty \), which in turn means that \(\left| {\mathbb {E}}(Y_0Y_{|m+\rho _1|} ){\mathbb {E}} (Y_0Y_{|m+\rho _2|})\right| = O(m^{4H-4})\) for any arbitrarily given integers \(\rho _1\) and \(\rho _2\). Hence, when \(H<\frac{3}{4}\), \(\sum _{m=0}^{n-1} {\mathbb {E}}(Y_{0}Y_{|m+\rho _1| } ) {\mathbb {E}}(Y_{0}Y_{|m+\rho _2| })\) converges as n tends to infinity. This shows that the second and third terms in (A.8) are convergent.
Notice that for \(H <\frac{3}{4}\), \(m {\mathbb {E}}(Y_0Y_m)^2 =O(m^{4H-3})\rightarrow 0\) as \(m\rightarrow \infty \). By Toeplitz theorem we have
Thus, the fourth and fifth terms in (A.8) converges to 0. This implies that \({\mathcal {I}}_{1.1.n}\) converges to the right hand side of (A.3).
When one of the i or j is not equal to 1, we have by the Hölder inequality
which will go to 0 since \(\frac{1}{n} \sum _{k,k'=1}^n I_{i,a,b,k,k'}^2, n=1, 2, \ldots \) is bounded when \(i=1\) and converges to zero when \(i\not =1\) by (A.5)–(A.7). \(\square \)
Let \(G_n\) be defined by (4.2) in Sect. 4. Its Malliavin derivative is given by
Lemma A.3
Define the sequence of random variables \(J_n :=\langle DG_n,DG_n\rangle _{\mathcal {H}}\). Then
Proof
It is easy to see that \(J_n \) is a linear combination of terms of the following forms (with the coefficients being a quadratic forms of \({\alpha }, {\beta }, {\gamma }\)):
where \(k_1, k_2 \) may take \(k, k+1, k+2\), and \( k_1', k_2'\) may take \(k', k'+1, k'+2\). For example, one term is to take \(k_1= k_2=k \) and \(k_1'=k'+1\), \(k_2'=k' \) which corresponds to the product:
We will first give a detail argument to explain why
and then we outline the procedure that similar claims hold true for any terms in (A.11). Note that \({\mathbb {E}}( {\tilde{J}}_{0, n})\) will not converge to 0.
From the Proposition 4.2 it follows
Using (A.1) we have
Now it is elementary to see that \(I_{1, n}\rightarrow 0\) and \(I_{2, n}\rightarrow 0\) when \(n \rightarrow \infty \).
Now we deal with the general term
in (A.11), where \(k_1, k_2 \) may take \(k, k+1, k+2\), and \( k_1', k_2'\) may take \(k', k'+1, k'+2\). We use Proposition 4.2 to obtain
where \(k_1, k_2 \) may take \(k, k+1, k+2\), and \( k_1', k_2' \) may take \(k', k'+1, k'+2\), \(j_1, j_2 \) may take \(j, j+1, j+2\), and \( j_1', j_2' \) may take \(j', j'+1, j'+2\). Using (A.1) we have
Now it is elementary to see that \(I_{1, n}\rightarrow 0\) and \(I_{2, n}\rightarrow 0\) when \(n \rightarrow \infty \). \(\square \)
Appendix B: Determinant of the Jacobian of f
The goal of this section is to compute the determinant of the Jacobian of
(we use the integral form of the first component of f to simplify the computation of the determinant).
The Jacobian matrix of f is equivalent (their determinants are up to a sign) to \(J = (C_1, C_2, C_3)\), where the column vectors are given by
and \(C_3 = C_{3,1} + C_{3,2} + C_{3,3}\), where
and

Determinant of M for \(H\in (0,1)\) and \(\theta \in (2, 10)\)
By the linearity of the determinant, we have
It is easy to see that \(\det (C_1,C_2,C_{3,2}) = \det (C_1,C_2,C_{3,3}) =0\) (\(C_1\) is a proportional to \(C_{3,2}\) and to \(C_{3,3}\)). Therefore
Notice that
where
Since \(\theta >0\), \(\sigma >0\), \(\sin ( \pi H) > 0\) and \(\Gamma (2H+1) >0\) (for \(H \in (0,1)\)), \(\det (J)=0\) if and only if \(\det (M)=0\).
The determinant \(\det (J)\) or the determinant \(\det (M)\) depends also on h. To remove this dependence, we write \(M=(M_{ij})_{1\le i, j\le 3}\), where
Since \(\log (\frac{x}{h}) = \log (x) - \log (h)\), the determinant of M is equal to \(h^{6H+2}\) multiply the determinant of the following matrix:
Namely, the determinant \(\det (J)\) is a negative number multiplied by the determinant \(\det (N) \). Denote \(\theta '=h \theta \). The determinant of N a function of two variables only: \(\theta '\) and H. The plot in Fig. 2 shows that \(\det (N)\) is positive for \(H \in (0.03,1)\) and \(\theta ' \in (2 , 10 )\). Combining this with (B.2) and (B.3), we see that on
\(\det (J)\) is strictly negative hence is not singular.
Appendix C: Numerical results
For all the experiments, we take \(h=1\).
1.1 C.1. Strong consistency of the estimators
In this subsection, we illustrate the almost-sure convergence by plotting different trajectories of the estimators. We observe that when \(\log _2(n) \ge 14\), the estimators become very close to the true parameter.
However, since our estimators are random (they depend on the sample \(\{X_{kh}\}_{k=1}^n\)), what’s important to see in these figures is the deviations from the true parameter we are estimating. Even if three trajectories are not enough to make statements about the variance, the figures predict that the variance of \(\tilde{\theta }_n\) is very high compared to the other estimators (see Figs. 3, 4) and that, for H close to 0 (see Fig. 5), the deviations of \(\tilde{H}_n\) increase.

Convergence of \(\widetilde{H_n}\) for \(H =0.7\) and \(H =0.4\) (\(\theta =6, \sigma =2\))

Convergence of \(\widetilde{\theta _n}\) for \(\theta =6, H=0.7,\sigma =2\)

Convergence of \(\widetilde{\sigma _n}\) for \(\theta =6, H=0.7,\sigma =2\)
1.2 C.2. Mean and standard deviation/Asymptotic behavior of the estimators
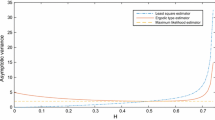
It is important to check the mean and deviation of our estimators. For example, a large variance implies a large deviation and therefore a “weak” estimator. That is why we plotted the mean and variance of our estimators for \(n=2^{12}\) over 100 samples.
As we observe, the standard deviation (s.d) of \(\tilde{\theta }_n\) is larger than the s.d of \(\tilde{\sigma }_n\) which is larger than the s.d of \(\tilde{H}_n\) (see Tables 1, 2). Notice also that the s.d of \(\tilde{H}_n\) increases as H decreases.
In Hu and Song (2013), the variance of the \(\theta \) estimator is proportional to \(\theta ^2\). In our case, it is difficult to compute the variances of our estimators (they depend on the matrix \(\Sigma \) (see Theorem 4.3) and the Jacobian of the function f (see Eq. (3.9)), however we should probably expect something similar which could explain the gap in the variances since the values of \(\theta \) are usually bigger that the values taken by \(\sigma \) or H.
Having access to 100 estimates of each parameter, we are also able to plot the distributions of our estimators to show that they effectively have a Gaussian nature (4.5) (Figs. 6, 7, 8).
Remark C.1
In practice, one may already know the value of one parameter, \(\sigma \) for example. In this case, it is important to point out that the estimators perform a lot better. For example, in Fig. 9, we plot the density of \(\theta _n\) and \(H_n\) for \(\sigma =1, H=0.6, \theta =6\) and for \(\log _2(n)\). Observe how the variance of the estimators is a lot smaller and the shape of the density is smoother.

Distribution of \(\widetilde{H_n}\) for \(H =0.7\) and \(H=0.4\) while \(\theta =6,\sigma =2\)

Distribution of \(\widetilde{\theta _n}\) for \(\theta =6, H=0.7,\sigma =2\)

Distribution of \(\widetilde{\sigma _n}\) for \(\theta =6, H=0.7,\sigma =2\)

Density plots of \(\theta _n\) and \(H_n\) when \(\sigma \) is known (\(=1\))
Rights and permissions
About this article

Cite this article
Haress, E.M., Hu, Y. Estimation of all parameters in the fractional Ornstein–Uhlenbeck model under discrete observations. Stat Inference Stoch Process 24, 327–351 (2021). https://doi.org/10.1007/s11203-020-09235-z
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11203-020-09235-z
Keywords
- Fractional Brownian motion
- Fractional Ornstein–Uhlenbeck
- Parameter estimation
- Malliavin calculus
- Ergodicity
- Stationary processes
- Newton method
- Central limit theorem