
Abstract
We apply Bayesian model averaging and a frequentistic model space analysis to assess the pricing determinants of credit default swaps (CDSs). Our study focuses on the complete model space of plausible models and thus supports ultimate robustness. Using a large dataset of CDS contracts we find that CDS price dynamics can be mainly explained by factors describing firms’ sensitivity to extreme market movements. More precisely, our results suggest that dynamic copula based measures of tail dependence incorporate most essential pricing information, making other potential determinants such as Merton-type factors or linear variables measuring the systematic market evolution negligible.





Similar content being viewed by others


Notes
A credit default swap (CDS) is a financial agreement that provides insurance against default risk of a reference entity. The seller of the CDS will compensate the buyer in the event of a loan default or some other predefined credit event. In exchange, the buyer of the CDS makes a series of payments (the CDS spread or premium, usually measured in basis points) to the seller.
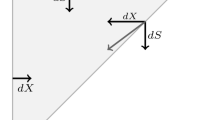
The long-run multiplier (also called long-run propensity) is the cumulative effect that a change in the variable \(X_{t}\) has on \(Y_{t}\), \(Y_{t+1}\), ..., \(Y_{t+h}\), with \(h\rightarrow \infty \). The exact mathematical definition is provided in Sect. 3.2.
With the CDS Big Bang on April 8, 2009 a move towards more standardized CDS contracts took place. Since then, contracts with no restructuring (XR) have become the convention for North America.
We observe high CDS spreads and spread changes especially for firms of the high yield index (CDX NA HY). The market kurtosis of the investment grade index (CDX NA IG) is considerably lower (skewness = -2.0479; kurtosis = 35.4789) than that of the overall market index as CDS in this index are characterized by a lower volatility. In Sect. 4.3, we provide a robustness check of our analysis that only considers investment grade index CDS contracts and confirms the results of our main analysis.
Several firms with CDS data in our sample are not traded publicly. However, some firms are traded publicly but financial accounting data is not available in Worldscope. The CDS spreads and tail dependence estimates of these firms are similar to the rest of the sample, ruling out a regularity in the firms that are dropped.
Estimating a principal component using only these 35 firms gives us a first principal component that is able to explain about \(35\%\) of the entire variation over the full sample period. The second principal component only explains approx. \(3\%\) of the remaining variance.
To control for firm value, we multiply the number of shares outstanding with the current share price.
To this day, many authors have applied BMA to economic topics, especially to empirical growth. The seminal papers on model averaging and growth are Fernandez et al. (2001) and Sala-I-Martin et al. (2004). Aside from empirical growth, model averaging techniques are also applied in forecasting financial variables such as stock returns (e.g. Avramov 2002; Cremers 2002) or exchange rates (e.g. Wright 2008). In the macro forecasting, Garratt et al. (2003) employ BMA to predict inflation and output growth in the UK and Wright (2009) forecasts U.S. inflation by BMA. Surprisingly, BMA is not yet established in the Finance literature.
For example, Baele et al. (2015) examine the systemic risk in U.S. banking and show that BMA reduces the root mean square error and therefore leads to a better out-of-sample performance.
Note that model averaging using smoothed AIC weights instead of BIC in the literature is often referred to as smoothed AIC estimator (S-AIC), see, e.g., Hansen (2007). We, however, use the term BMA more generally, to cover also the AIC weight variation. For a good overview of several weighting schemes suggested in the literature see, e.g., Moral-Benito (2015).
While this assumption is often made in the literature, some authors like Sala-I-Martin et al. (2004) actually define a prior for the model probabilities and suggest that there is usually a prior belief of researchers that the true model is rather parsimoniously specified. Since we restrict our model space to a maximum of four regressors, we do not face the problem of very large models.
A related strand of the model uncertainty literature suggests analyzing a Model Confident Set (MCS) (Hansen et al. 2011) which is also intended to overcome the problem of selecting one best model. The advantage of the MCS is that conditional on the limits to the information of the data, MCS seeks to find a group of models that are equally likely to be superior. A hypothesis test for equal predictive ability (EPA) is performed on the set of initial models M using an equivalence confidence level \(1-\alpha \). If the null hypothesis is rejected, an elimination rule is employed to remove an inferior model. The process is then repeated until the null hypothesis is not rejected and the remaining set of models is the MCS. Recently, authors like Samuels and Sekkel (2011) have applied MCS to create a set of best predictors by trimming the worst models. Applying three different trimming techniques (fixed trimming, MCS trimming, Occam’s window), Samuels and Sekkel (2011) show that trimmed forecast combinations outperform BMA on an untrimmed model space due to the parameter estimation error in small sample sizes.
BMA should be preferred over the elastic net approach when there is an interest in analyzing (and filtering) the composition of the OLS model space. In addition, elastic net coefficient estimates are biased (while showing a smaller prediction error variance than OLS) which is induced by the penalty term used in the optimization setup.
Note, that the t-copula may converge against the Gauss copula and thus only capture linear dependence for large degrees of freedom parameter. However, in our sample, the estimate for the parameter capturing the degrees of freedom is never larger than 21. Hence, we do not observe convergence to linear dependence in our sample.
References
Ait-Sahalia, Y., & Lo, A. W. (2000). Nonparametric risk management and implied risk aversion. Journal of Econometrics, 94, 9–51.
Alexander, C., & Kaeck, A. (2008). Regime dependent determinants of credit default swap spreads. Journal of Banking & Finance, 32, 1008–1021.
Andersen, T. G., Bollerslev, T., Christoffersen, P. F., & Diebold, F. X. (2006). Handbook of economic forecasting. In G. Elliott, C. W. J. Granger, & A. Timmermann (Eds.), Volatility and correlation forecasting (pp. 778–878). Amsterdam: Elsevier.
Arakelyan, A., Rubio, G., & Serrano, P. (2015). The reward for trading illiquid maturities in credit default swap markets. International Review of Economics and Finance, 39, 376–389.
Augustin, P., Subrahmanyam, M. G., Tang, D. Y., & Wang, S. Q. (2014). Credit default swaps—A survey. Foundations and Trends in Finance, 9, 1–196.
Augustin, P., & Tédongap, R. (2011). Common factors and commonality in sovereign CDS spreads: A consumption-based explanation. Working paper.
Avramov, D. (2002). Stock return predictability and model uncertainty. Journal of Financial Economics, 64, 423–458.
Baele, L., De Bruyckere, V., De Jonghe, O., & Vander Vennet, R. (2015). Model uncertainty and systematic risk in US banking. Journal of Banking & Finance, 53, 49–66.
Bauwens, L., Laurent, S., & Rombouts, J. (2006). Multivariate GARCH models: A survey. Journal of Applied Econometrics, 21, 79–109.
Benkert, C. (2004). Explaining credit default swap premia. The Journal of Futures Markets, 24, 71–92.
Berg, D. (2009). Copula goodness-of-fit testing: An overview and power comparison. European Journal of Finance, 15, 675–701.
Berndt, A., & Obreja, I. (2010). Decomposing European CDS returns. Review of Finance, 14, 189–233.
Bollerslev, T., & Todorov, V. (2011). Tails, fears, and risk premia. The Journal of Finance, 66, 2165–2211.
Bollerslev, T., Todorov, V., & Xu, L. (2015). Tail risk premia and return predictability. Journal of Financial Economics, 118, 113–134.
Bongaerts, D., de Jong, F., & Driessen, J. (2011). Derivate pricing with liquidity risk: Theory and evidence from the credit default swap market. The Journal of Finance, 66, 203–240.
Breusch, T. (1978). Testing for autocorrelation in dynamic linear models. Australian Economic Papers, 17, 334–355.
Bujack, K. M., & Santamaria, M. T. C. (2016). Credit default swaps and financial risks in the 21st century. Working paper.
Buocher, C., Daníelsson, J., Kouontchoub, P., & Mailleta, B. (2014). Risk models-at-risk. Journal of Banking & Finance, 44, 72–92.
Burnham, K . P., & Anderson, D . R. (2002). Model selection and multimodel inference: A practical information-theoretic approach. Berlin: Springer.
Chabi-Yo, F., Ruenzi, S., & Weigert, F. (2014). Crash sensitivity and the cross-section of expected stock returns. Working paper.
Chen, X., & Fan, Y. (2006). Estimation and model selection of semiparametric copula-based multivariate dynamic models under copula misspecification. Journal of Econometrics, 135, 307–335.
Chen, X., Fan, Y., & Tsyrennikov, V. (2006). Efficient estimation of semiparametric multivariate copula models. Journal of the American Statistical Association, 101, 1228–1240.
Christoffersen, P., Errunza, V., Jacobs, K., & Langlois, H. (2012). Is the potential for international diversification disappearing? A dynamic copula approach. The Review of Financial Studies, 25, 3711–3751.
Christoffersen, P., Jacobs, K., Jin, X., & Langlois, H. (2014). Dynamic dependence and diversification in corporate credit. Working paper.
Clark, T., & McCracken, M. (2001). Tests for equal forecast accuracy and ecompassing for nested models. Journal of Econometrics, 105, 85–110.
Clayton, D. (1978). A model for association in bivariate life tables and its application in epidemiological studies of familial tendency in chronic disease incidence. Biometrika, 65, 141–151.
Collin-Dufresne, P., Goldstein, R. S., & Martin, J. S. (2001). The determinants of credit spread changes. The Journal of Finance, 61, 2177–2207.
Cont, R. (2001). Empirical properties of asset returns: Stylized facts and statistical issues. Quantitative Finance, 1, 223–236.
Cont, R., & Kan, Y. H. (2011). Statistical modeling of credit default swap portfolios. SSRN working paper.
Coval, J. D., Jurek, J. W., & Stafford, E. (2009). Economic catastrophe bonds. American Economic Review, 99, 628–666.
Creal, D., Koopman, S. J., & Lucas, A. (2013). General autoregressive score models with applications. Journal of Applied Econometrics, 28, 777–795.
Cremers, K. M. (2002). Stock return predictability: A Bayesian model selection perspective. Review of Financial Studies, 15, 1223–1249.
Daníelsson, J. (2008). Blame the models. Journal of Financial Stability, 4, 321–328.
Demarta, S., & McNeil, A. J. (2005). The t copula and related copulas. International Statistical Review, 73, 111–129.
Derman, E. (1996). Model risk. Goldman Sachs Quantitative Strategies Research Notes.
Diebold, F., Hahn, J., & Tay, A. (1999). Multivariate density forecast evaluation and calibration in financial risk management: High frequency returns on foreign exchange. Review of Economics and Statistics, 81, 661–673.
Diebold, F., & Mariano, R. (1995). Comparing predicitve accuracy. Journal of Business and Economic Statistics, 13, 253–263.
Elliott, G., Gargano, A., & Timmermann, A. (2013). Complete subset regressions. Journal of Econometrics, 177, 357–373.
Ericsson, J., Jacobs, K., & Oviedo, R. (2009). The determinants of credit default swap premia. Journal of Financial and Quantitative Analysis, 44, 109–132.
Fernandez, C., Ley, E., & Steel, M. F. (2001). Benchmark priors for Bayesian model averaging. Journal of Econometrics, 100, 381–427.
Frahm, G., Junker, M., & Schmidt, R. (2005). Estimating the tail-dependence coefficient: Properties and pitfalls. Insurance: Mathematics and Economics, 37, 80–100.
Furnival, G., & Wilson, R. (1974). Regression by leaps and bounds. Technometrics, 16, 499–511.
Gârleanu, N., Pedersen, L. H., & Poteshman, A. M. (2009). Demand-based option pricing. Review of Financial Studies, 22, 4259–4299.
Garratt, A., Lee, K., Pesaran, M. H., & Shin, Y. (2003). Forecast uncertainties in macroeconomic modeling. Journal of the American Statistical Association, 98, 829–838.
Genest, C., Gendron, M., & Bourdeau-Brien, M. (2009). The advent of copulas in finance. The European Journal of Finance, 15, 609–618.
Genest, C., Ghoudi, K., & Rivest, L.-P. (1995). A semiparametric estimation procedure of dependence parameters in multivariate families of distributions. Biometrika, 82, 543–552.
Genest, C., & Rivest, L.-P. (1993). Statistical inference procedures for bivariate Archimedean copulas. Journal of the American Statistical Association, 88, 1034–1043.
Godfrey, L. (1978). Testing against general autoregressive and moving average error models when the regressors include lagged dependent variables. Econometrica, 46, 1293–1302.
Gourio, F. (2011). Credit risk and disaster risk. NBER working paper 17026.
Green, T. C., & Figlewski, S. (1999). Market risk and model risk for a financial institution writing options. The Journal of Finance, 54, 1465–1499.
Greene, W . H. (2003). Econometric analysis (5th ed.). Upper Saddle River: Prentice Hall.
Gumbel, E. (1960). Distributions des valeurs extrémes en plusiers dimensions. Publications de l’Institut de Statistique de l’Université de Paris, 9, 171–173.
Han, N., & Zhou, Y. (2015). Understanding the term structure of credit default swap spreads. Journal of Empirical Finance, 31, 18–35.
Han, Y., Gong, P., & Zhou, X. (2015). Correlations and risk contagion between mixed assets and mixed-asset portfolio VaR measurements in a dynamic view: An application based on time varying copula models. Physica A, 444, 940–953.
Hansen, B. E. (2007). Least squares model averaging. Econometrica, 75, 1175–1189.
Hansen, P. R., Lunde, A., & Nason, J. M. (2011). The model confidence set. Econometrica, 79, 453–497.
Hasan, I., Horvath, R., & Mares, J. (2016). What type of finance matters for growth? Bayesian model averaging evidence. World bank policy research working paper, 7645.
Hastie, T., Tibshirani, R., & Friedman, J. (2008). The elements of statistical learning (2nd ed.). Heidelberg: Springer.
Heinz, F. F., & Sun, Y. (2014). Sovereign CDS spreads in Europe—The role of global risk aversion, economic fundamentals, liquidity, and spillovers. IMF working paper.
Hoerl, A., & Kennard, R. (1970). Ridge regression: Biased estimation for nonorthogonal problems. Technometrics, 12(1), 55–67.
Hoeting, J. A., Madigan, D., Raftery, A. E., & Volinsky, C. T. (1999). Bayesian model averaging: A tutorial. Statistical Science, 14(4), 382–417.
Hull, J., & Suo, W. (2002). A methodology for assessing model risk and its application to the implied volatility function model. The Journal of Financial and Quantitative Analysis, 37, 297–318.
Jackwerth, J. C., & Rubinstein, M. (1996). Recovering probability distributions from option prices. The Journal of Finance, 51, 1611–1631.
Joe, H. (1997). Multivariate models and dependence concepts. London: Chapman & Hall.
Joe, H. (2015). Dependence modelling with copulas. Boca Raton: CRC Press.
Jondeau, E., & Rockinger, M. (2006). The Copula-GARCH model of conditional dependencies: An international stock market application. Journal of International Money and Finance, 25, 827–853.
Jorion, P., & Zhang, G. (2007). Good and bad credit contagion: Evidence from credit default swaps. Journal of Financial Economics, 84, 860–883.
Kapetanios, G., Labhard, V., & Price, S. (2008). Forecasting using bayesian and information theoretic model averaging: An application to UK inflation. Journal of Business and Economic Statistics, 26, 33–41.
Kass, R., & Raftery, A. (1995). Bayes factors. Journal of the American Statistical Association, 90, 773–795.
Keiler, S., & Eder, A. (2013). CDS spreads and systemic risk—A spatial econometric approach. Discussion paper Deutsche Bundesbank.
Kita, A. (2015). Predicting credit default swap spreads: The role of credit spread volatility. Working paper.
Kole, E., Koedijk, K., & Verbeek, M. (2006). Selecting copulas for risk management. Working paper.
Koziol, C., Koziol, P., & Schön, T. (2015). Do correlated defaults matter for CDS premia? An empirical analysis. Review of Derivatives Research, 18, 191–224.
Kullback, S., & Leibler, R. (1951). Oeconometrics and sufficency. Annals of Mathematical Statistics, 22, 79–86.
Kumar, A., & Lee, C. M. (2006). Retail investor sentiment and return comovements. The Journal of Finance, 61, 2451–2486.
Laeven, L., & Valencia, F. (2012). Systemic banking crises database: An update. IMF working paper.
Li, D. X. (2000). On default correlation: A copula function approach. The RiskMetrics Group working paper, 99-07.
Longstaff, F. A., Mithal, S., & Neis, E. (2005). Corporate yield spreads: Default risk or liquidity? New evidence from the credit default swap market. The Journal of Finance, 60, 2213–2253.
Madigan, D., & Raftery, A. (1994). Model selection and accounting for model uncertainty in graphical models using occam’s window. Journal of the American Statistical Association, 89, 1535–1546.
Madigan, D., & York, J. (1995). Bayesian graphical models for discrete data. International Statistical Review, 63, 215–232.
Meine, C., Supper, H., & Weiß, G. N. (2015). Do CDS spreads move with commonality in liquidity? Review of Derivatives Research, 18, 225–261.
Meine, C., Supper, H., & Weiß, G. N. (2016). Is tail risk priced in credit default swap premia? Review of Finance, 20, 287–336.
Merton, R. C. (1974). On the pricing of corporate debt: The risk structure of interest rates. The Journal of Finance, 29, 449–479.
Moral-Benito, E. (2012). Determinants of economic growth: A Bayesian panel data approach. Review of Economics and Statistics, 94, 566–579.
Moral-Benito, E. (2015). Model averaging in economics: An overview. Journal of Economic Surveys, 29, 46–75.
Nickell, S. (1981). Biases in dynamic models with fixed effects. Econometrica, 49, 1417–1426.
Oh, D. H., & Patton, A. J. (2013). Time-varying systemic risk: Evidence from a dynamic copula model of CDS spreads. Economic Research Initiatives at Duke (ERID) working paper.
Patton, A. J. (2006). Modelling asymmetric exchange rate dependence. International Economic Review, 47, 527–556.
Patton, A. J. (2009). Handbook of financial time series. In T. G. Andersen, R. A. Davis, J.-P. Kreiss, & T. V. Mikosch (Eds.), Copula-based models for financial time series. Berlin: Springer.
Qiu, J., & Yu, F. (2012). Endogenous liquidity in credit derivatives. Journal of Financial Economics, 103, 611–631.
Raftery, A. E., Madigan, D., & Hoeting, J. A. (1997). Bayesian model averaging for linear regression models. Journal of the American Statistical Association, 92, 179–191.
Rémillard, B. (2010). Goodness-of-fit tests for copulas of multivariate time series. Working paper.
Rosenblatt, M. (1952). Remarks on a multivariate transformation. The Annals of Mathematical Statistics, 23, 470–472.
Rubinstein, M. (1994). Implied binomial trees. The Journal of Finance, 49, 771–818.
Sala-I-Martin, X., Doppelhofer, G., & Miller, R. I. (2004). Determinants of long-term growth: A Bayesian averaging of classical estimates (BACE) approach. The American Economic Review, 94, 813–835.
Samuels, J. D., & Sekkel, R. M. (2011). Forecasting with large datasets: Trimming predictors and forecast combination. Technical report, working paper.
Sklar, A. (1959). Fonctions de répartition à n dimensions et leurs marges. Publications de l’Institut Statistique de l’Université de Paris, 8, 229–231.
Tang, D. Y., & Yan, H. (2008). Liquidity and credit default swap spreads. SSRN working paper.
Tibshirani, R. (1996). Regression shrinkage and selection via the lasso. Journal of the Royal Statistical Society Series B, 58(1), 267–288.
Volinsky, C., Madigan, D., Raftery, E., & Kronmal, R. (1997). Bayesian model averaging in proportional hazard models: Assessing the risk of a stroke. Applied Statistics, 46, 433–448.
Weiß, G. N., & Scheffer, M. (2015). Mixture pair-copula-constructions. Journal of Banking & Finance, 54, 175–191.
Wooldridge, J. (2003). Cluster-sample methods in applied econometrics. American Economic Review, 93, 133–138.
Wright, J. H. (2008). Bayesian model averaging and exchange rate forecasts. Journal of Econometrics, 146, 329–341.
Wright, J. H. (2009). Forecasting US inflation by Bayesian model averaging. Journal of Forecasting, 28, 131–144.
Zhang, B. Y., Zhou, H., & Zhu, H. (2009). Explaining credit default swap spreads with the equity volatility and jump risks of individual firms. The Review of Financial Studies, 22, 5099–5131.
Zou, H., & Hastie, T. (2005). Regularization and variable selection via the elatic net. Journal of the Royal Statistical Society, 67, 301–320.
Author information
Authors and Affiliations
Corresponding author
Additional information
The views expressed in this paper are those of the authors and do not necessarily reflect the opinions of the Deutsche Bundesbank. A part of this research was conducted while Matthias Pelster was a guest researcher at Deutsche Bundesbank. We thank the editor and an anonymous referee for helpful comments and suggestions. We are also grateful for comments from André Uhde, Christoph Memmel, Ariadna Dumitrescu, Arzé Karam, Carol Alexander, David Brown, and participants of the research seminars at Deutsche Bundesbank, Sussex University, and the University of Paderborn, and participants of the International Risk Management Conference 2016 in Jerusalem, the European Financial Management Association 2016 Annual Meetings in Basel, the Financial Management Association 2016 Annual Meetings in Las Vegas, the Southern Finance Association 2016 Annual Meetings in SanDestin, and the 4th Paris Financial Management Conference 2016.
Appendices
Appendix
A Time-varying copula models
This section describes the time-varying copula models employed in our study as well as the estimation of tail dependence measures and goodness-of-fit tests.
1.1 A.1 Modeling extreme comovements
To capture the extreme comovement between financial time series, we rely on Copula-GARCH models (see Jondeau and Rockinger 2006) in our study. These models allow for some time-varying parameters in an autoregressive manner, conditional on the set of past information. To consider conditional distributions of some random variable \(X_t\) given an information set \(\mathscr {F}\), an extension of Sklar’s theorem (see Sklar 1959) is necessary. This extension to the conditional case is due to Patton (2006), who defines the conditional copula:
Here, \(X_i \mid \mathscr {F}_{t-1} \sim F_{i,t}\) and \(\mathbf {C}_t\) denotes the conditional copula of \(\mathbf {X}_t\) given \(\mathscr {F}_{t-1}\).
1.1.1 A.1.1 Univariate modeling of log differences
As noted by Sklar (1959), the use of copulas allows to define multivariate models where the marginal distributions are not of the same type as the copula model. Thus, we can combine non-parametric estimation for the marginal distributions with parametric estimation of the copula (see Chen and Fan 2006; Chen et al. 2006). As our study focuses on the dependence structures between CDS spreads, we are not interested in the estimation of the marginals and only estimate the copula. Estimation methods for the copula assume identical independent distributed data (see Genest et al. 1995). However, stylized facts of financial time series state that model residuals are often skewed and fat tailed in addition to a leverage effect (see Cont 2001; Joe 2015). Focusing on CDS spread time series, Cont and Kan (2011) provide evidence that CDS spread changes are stationary and exhibit positive autocorrelation. Moreover, the authors find that the returns are described by conditional heteroscedasticity, two-sided heavy tails, serial dependence in extreme values, and sizable co-movements that are not necessarily linked to credit events. Hence, as returns of financial data in general and specifically CDS data are usually not i.i.d. and we can confirm the stylized facts for our dataset, we have to filter the data first.
Thus, we first apply our data to an AR(m)-GARCH(p,q) model, before we standardize the i.i.d. residuals from the filtration to uniform. We use a probability integral transform of the following form. Due to the filtration, \(\epsilon _t\), \(t=1, \ldots , T\) is a time series of i.i.d. variables. Under the assumption \(\epsilon _t \sim F_i\), \(t = 1, \ldots , T\), \(u_{i,t} = F_i(\epsilon _t)\) is the probability integral transform of \(\epsilon _t\) with \(u_{i,t} \sim U[0,1]\), \(t =1, \ldots , T\). Specifically, we employ the empirical cumulative distribution function (CDF) for the transformation:
where \(\mathbf {1}\) denotes the indicator function. Finally, we can estimate the copula parameters using the uniform residuals with maximum likelihood estimation.
We do not summarize the estimation results for the univariate AR(m)-GARCH(p,q) model and copula model estimations to preserve space. The results are available from the authors upon request. We choose the AR lag m for each time series and the GARCH model according to the AIC value.
Figure 6 presents representative plots of autocorrelation functions of the CDS market changes prior to applying the AR-GARCH model and after filtering. Note that the residuals do not exhibit significant autocorrelations.

Autocorrelation functions before and after applying the AR-GARCH filter. The figure shows representative plots of autocorrelation functions of the CDS market changes prior to applying the AR-GARCH model and after filtering
1.1.2 A.1.2 Time-varying copulas
To allow for possible time-varying dependency structures (see, e.g. Andersen et al. 2006; Bauwens et al. 2006) between assets we make use of time-varying specifications of the copula models in our study. We follow Patton (2006) and Creal et al. (2013) to specify the time dynamics of the copulas.
Time-varying copula models can be characterized by their time-varying parameters. As noted by Patton (2006) it is “difficult to know what might (or should) influence” the copula parameter to change unless the parameter has some kind of interpretation. Hence, we limit our study to copulas characterized by such a parameter. For example, for the time-varying t-copula, the correlation among the risk factors and the degrees of freedom are time-varying, while for the Symmetrized Joe-Clayton Copula the upper and lower tail dependence parameter is time-varying and for the Clayton copula Kendall’s tau is the time-varying parameter.
Patton (2006) defines the updating equation for the time-varying parameter of a bivariate model by
where m is a positive integer that characterizes the smoothness of the function and \(u_{1,t}\) and \(u_{2,t}\) are the probability integral transforms of the univariate marginals. Let \(\omega < 0\), \(A_1 > 0\), and \( 1> B_1 > 0\). If the most recent values of \(u_{1,t}\) and \(u_{2,t}\) are close together, hinting at a stronger dependence, \(f_{t+1}\) is likely to increase, while for recent values that are far apart \(f_{t+1}\) more likely decreases. We employ the approach by Patton for the symmetric t and the SJC copula. Time dynamics are captured for the symmetric t-copula by a time-varying correlation parameter \(\rho _t\) that follows the transformation \(\rho _t = \frac{1- e^{-f_t}}{1+e^{-f_t}} = \text {tanh}\left( \frac{f_t}{2}\right) \). The modified logistic transformation is used to keep \(\rho _t\) in \((-1,1)\) at all times.
Additionally, we allow for trends in the degrees of freedom (see also Christoffersen et al. 2014). We assume that the degree of freedom at time t is given by the exponential quadratic spline
\(\underline{\eta _C}\) marks the lower bound for the degrees of freedom and \(\delta _{C,0}, \ldots , \delta _{C,k+1}\) are scalar parameters that have to be estimated. We split the sample in k segments of equal length to obtain \( \{ t_0 = 0, t_1, t_2, ldots , t_k = T \}\). For our estimations, we set \(k=3\), which allows us to capture times of positive and times of negative trends.
By introducing time dependence in correlations and degrees of freedom, Christoffersen et al. (2014) allow for time variation in tail dependence that is distinct from time variation in correlations as tail dependence for the t-copula is characterized by both, correlation and degrees of freedom.
For the SJC copula we use \(\Lambda (x) \equiv \frac{1}{1 + e^{-x}}\) as logistic transformation, which is used to keep the parameters \(\tau ^U\) and \(\tau ^L\) in (0, 1) at all times (see Patton 2006).
For the Clayton and the Gumbel copula we rely on the generalized autoregressive score (GAS) model, GAS (1, 1), introduced by Creal et al. (2013), which is similar to the model of Patton (2006) for \(m=1\). Creal et al. (2013) provide a dynamic version of following their GAS specification. The density with regard to Creal et al. (2013) reads
For the Clayton copula the time-varying factor following the GAS equation reads
For the Gumbel copula the updating equation for the dynamic parameter is given by
and the density reads
The copula parameter of the Gumbel copula is required to be greater than one. Thus, we use the function \(\theta _t = 1 + \exp {f_t}\) to ensure this.
1.2 A.2 Measures of tail dependence
A convenient way to measure for the upper tail dependence at time t is via the probability limit:
Similarly, for the lower tail dependence
As far as our copula models are concerned, the Gumbel and the Clayton copula posses upper and lower tail dependence that is not equal to zero, while dependence in the opposite tail is zero for both cases. For the rotated versions of both copula models, dependence in the tails is opposite. For both (or all four, together with the rotated versions) copula models, the tail dependence depends on the dynamic copula parameter. The SJC copula is characterized by positive tail dependence in the lower and the upper tail, and these measures may be different. The tail dependence is given by the (time-varying) copula parameters. Lastly, the (symmetric) t-copula has the property of non-negative tail dependence for both tails. However, the lower and the upper tail dependence is identical for the symmetric t-copula. For all copulas included in our study, closed form equations for the tail dependence are established in the literature.
1.3 A.3 Tests of goodness of fit
This section briefly presents several goodness of fit tests that we employ to estimate the fit of each copula model and identify one model as the model with the best fit. Relying on the works of Genest et al. (2009), Kole et al. (2006) and Berg (2009), we first use the Kolmogorov–Smirnov test and the Cramer-von Mises test to test the goodness of fit of our copula models. Both of these tests rely on the empirical copula serving as a nonparametric estimate of the true conditional copula. However, as our estimated copula is time-varying, we cannot rely on the two tests directly. Instead, we follow Diebold et al. (1999), Genest et al. (2009) and Rémillard (2010) and employ the Rosenblatt transformation (Rosenblatt 1952) before using the Kolmogorov–Smirnov and the Cramer–von Misses tests.
The Rosenblatt transformation of the original data produces a vector of identical independent uniform distributed variables on the interval [0, 1]. In the bivariate case, the transform is given by
Note that the ordering of the variables affects the transformation. Employing the Rosenblatt transformation, the Kolmogorov–Smirnov and the Cramer–von Misses tests are as follows:
Note that these gof-tests are designed to test the fit of the copula model over the entire domain. For example, the Kolmogorov–Smirnov distances are sensitive to deviations in the center of the distribution. However, as our study focuses on tail dependence, we additionally estimate a non-parametric dynamic estimator of upper tail dependence. More precisely, we estimate the log estimator proposed by Frahm et al. (2005) using rolling window estimation. Note that we again perform the Rosenblatt transformation before estimating the log estimator of tail dependence. We then calculate the Integrated Anderson–Darling distances between the non-parametric tail dependence coefficients and the tail dependence coefficients we infer from the fitted copula models via
where \(\lambda ^U\) denotes the upper tail dependence coefficient, \(\hat{\lambda }^U\) denotes the empirical tail dependence coefficient, \(\hat{\theta }\) the estimated copula parameter(s), and the copula models are evaluated at every point on the lattice
Lastly, we estimate the fit of each copula model based on the AD-distance to Pickands dependency function evaluated at 0.5.
B Correlation analysis
In this section, we examine simple correlations of the regressors. Table 14 presents the largest correlations of regressors with CDS spreads, while Table 15 presents pairwise correlations between all variables included in the BMA regression setup. We observe the highest correlations between the first principal component, which is a weighted average of the individual CDS spreads measuring commonality, and the spreads, followed by the market and the spread. The higher correlation between Comm and CDS spreads can be attributed to the Commonality extracted by the pca. Thus, CDS spreads that experience less commonality with the other are attributed a lower weight. Also, correlations with overall market movements (Russell) and financial stress are high. Moreover, we observe high correlations between the CDS spreads and the tail dependence measured with the t-copula (0.52). We attribute this high correlation at least in part to the correlation being part of the tail dependence estimate.
Further correlations can be seen from Table 15. Most strikingly, high correlations between the tail dependence measures are estimated with different copula models. Note that the t-copula measure is least correlated with other copulas, but most correlated with market and commonality. Moreover, the other copula measures are not highly correlated with any of the other variables, which can be interpreted as a sign of uniqueness of the copula measures. The commonality factor is highly correlated with the financial distress indicator. Also, equity returns do not show any large correlations with other variables. Notable correlations are only formed with equity volatility and, not surprisingly, the change in firm value.
We run additional correlation analysis for our liquidity subsample period. We find that the liquidity measure is very unique as we do not observe any correlations above .3 (in absolute values). Consequently, we do not impose any exclusion restrictions on the liquidity measure.

LRM of all regressors in the elastic net estimation. The figure shows the LRM of all regressors in the regularization and variable selection via the elastic net method
C Variable selection via the elastic net
The elastic net regression (Zou and Hastie 2005; Hastie et al. 2008) is a “shrinkage” or regularization method that minimizes the sum of squared residuals subject to a penalty term that penalizes the aggregate size of the coefficients in the model. The penalty term is defined as a linear combination of a L2 (quadratic) and L1 (manhattan) norms. Formally, elastic net regression minimizes
where \(\alpha \) is a hyperparameter with values between 0 and 1 and controls how much L2 or L1 penalization is used. The special case \(\alpha =0\) correpsonds to the ridge regression (Hoerl and Kennard 1970) and \(\alpha =1\) to the lasso regression (Tibshirani 1996). The second hyper-parameter \(\lambda \) controls the “aggressiveness” of penalization for a given \(\alpha \). The usual approach to optimizing \(\lambda \) is through cross-validation, i.e. by minimizing the cross-validated mean squared error of prediction. Since the optimal \(\lambda \) depends upon \(\alpha \), usually a combined grid-search over different combinations of \(\lambda \) and \(\alpha \) is performed. The elastic net fits a model in which all potential predictors are contained which is possible due to the additional constraints or regularization on the coefficient estimates compared to OLS. The introduction of the regularization/penalty term induces an bias to the estimated coefficients, however, the mean squared prediction error is decreased compared to OLS estimation. In Figure 7 and Table 16 the results from the application of the elastic net method to our dataset are shown. The optimal \(\lambda \) in our application is found to be 0.012 and the optimal \(\alpha \) is 0.72.
Rights and permissions
About this article

Cite this article
Pelster, M., Vilsmeier, J. The determinants of CDS spreads: evidence from the model space. Rev Deriv Res 21, 63–118 (2018). https://doi.org/10.1007/s11147-017-9134-6
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11147-017-9134-6