
Abstract
The US mobile phone service industry has dramatically consolidated over the last two decades. One justification for consolidation is that merged firms can provide consumers with larger coverage areas at lower costs. We estimate the willingness to pay for national coverage to evaluate this justification for past consolidation. As market level quantity data are not publicly available, we devise an econometric procedure that allows us to estimate the willingness to pay using market share ranks collected from the popular online retailer Amazon. Our semiparametric maximum score estimator controls for consumers’ heterogeneous preferences for carriers, handsets and minutes of calling time. We find that national coverage is strongly valued by consumers, providing an efficiency justification for across-market mergers. The methods we propose can estimate demand for other products using data from online retailers where product ranks, but not quantities, are observed.



Similar content being viewed by others
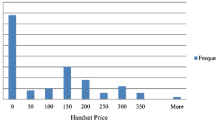

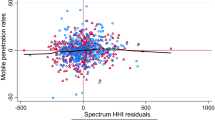
Notes
The maximum score approach has previously been used in industrial organization and marketing by Briesch et al. (2002).
The FCC uses data on the number of telephone numbers assigned to carriers to approximate market shares, rather than using data on actual customers. The FCC writes in response to a Department of Justice request to access its data on market shares, “The Commission has recognized that disaggregated, carrier-specific forecast and utilization data should be treated as confidential and should be exempt from public disclosure under 5 U.S.C. Section 552(b)(4).”
Some carriers have decided to take advantage of the network aspect of their products by offering free in-network calling. If two Verizon or two Cingular customers talk, the length of the call is not deducted from either customer’s bucket of included minutes from their subscription plans. Merging carriers create larger networks so that customers can better exploit free in-network calling. Unfortunately, major carriers either include unlimited in-network calling as part of all plans, or offer it as an add-on option. There is no variation within a carrier in whether in-network calling is included in a subscription plan, so we cannot estimate its value without using across-carrier variation in market share ranks.
We did not collect data on overage charges. An overage charge is the per-minute cost for calls that exceed the calling minutes for plan j. While we have no data on the usage of plan minutes, our measure does not account for the entirety of a plan’s price. Our assumption (relaxed a little in Section 5.4) is that a consumer uses all the minutes in his or her plan, and no more, so there are no overage charges.
The nests do not represent a dynamic choice problem. Rather, each nest represents the set of products that have the same fixed effect for consumer i, ν ihm .
Consumer-specific fixed effects at the carrier level capture carrier-specific features such as the coverage near a consumer’s house. In a model without fixed effects, the market and subscription plan specific errors ξ jm would account for omitted variables such as coverage quality.
Manski initially studied the properties of this estimator both for the two choice case and the three or more choices case. Much of the attention in the subsequent maximum score literature focuses on the two choice case, because the two choice case allows for relatively weak median independence assumptions about the relationship between errors and observables (Manski 1985; Horowitz 1992). Also, others have extended estimators for the two-choice case to more general ordered choice problems (Han 1987; Abrevaya 2000).
We can weaken the assumption of i.i.d. errors across choices in the same nest to be an exchangeable joint density. See Fox (2007).
For example, if we have added a penalty term \(\left(x_{j}^{'}\beta-p_{j}>x_{k}^{'}\beta-p_{k}\right)^{2}\) in the degree of an inequality violation and minimized the resulting penalties, then there is no guarantee that the true parameter in the data generating process would be in the identified set.
See Fox (2008) for another case where an objective function like (6) has both Manski (1975) and Han (1987) asymptotics. Note that Han (1987) motivates his estimator with ordered choice problems. His estimator involves combining different observations in a double summation. We study an unordered choice problem. Under a much stronger version of Assumption 1, we could use Han’s estimator to interact observations across markets if all markets had exactly the same set of plans. While most of the plans on offer are the same across markets, there is some small degree of variation in the offered plans, so we do not pursue this further.
Fox (2007) discusses this point in more detail for the maximum score estimator with individual data.
Bajari et al. (2007) prove the nonparametric identification of the distribution of random coefficients in the random coefficients logit model, with market share levels. Our results rely on continuous product characteristic variation across markets, the type of variation that we do not have in the mobile phone market. Therefore, we are skeptical about identifying the distribution of random coefficients with this type of data.
A referee points out that for some set-identified estimators, the 95% confidence sets and set estimates will be the same with probability 1. Maximum score is not such an estimator. If the dependent variable (market share ranks) vary a lot conditional on covariates, the estimates using some subsamples will not be the same as with the full sample.
Note that we are discussing variation in the dependent variable. If the independent variables vary a lot across markets, then the identified set will be smaller than a case with no or a small amount of characteristic variation. If at least one independent variable per product has continuous support, then Manski (1985) and others show that the model is point identified and that the maximum score estimator is consistent. The typical large support assumption for the continuous characteristic can be relaxed while still maintaining point identification, as Horowitz (1998) discusses.
Some companies collect phone bills from consumers. Bill harvest data are not entirely appropriate, as at any given point in time the stock of mobile phone users has plans purchased from the menus of plans available in many different time periods. The time of plan purchase may not be observable.
If a researcher has another dataset with continuously measured shares s jm , it is easy to convert those shares into ranks.
We have used the Amazon site extensively and wish to explain a little of how the site worked in late 2005, when the data were collected. When you go to the site to shop for mobile phone plans, you are prompted to enter your zip code. Amazon uses the zip code to look up your geographic market. We collect market share rank data by choosing a zip code corresponding to each city. There are various pages. The page that presents the plans rank ordered by sales is reached by using the toolbar to search “Wireless Plans” for a blank string. All plans will appear, and you can sort them by sales rank. The resulting plans are presented in a matrix, with the top three plans in the first row, plans three to six in the second row, etc. A plan’s rank comes from its position in the matrix, not from a text label, as Amazon includes for books. You can verify the ordering of plans in the matrix by consulting another page, which lists the top five plans in numeric order, with the rankings listed explicitly. We clicked on each plan and manually copied its characteristics.
Amazon sells prepaid service, where a customer does not pay a set monthly fee. We do not consider the data on prepaid service, because plan characteristics such as price and anytime minutes are not comparable to the monthly values for subscription plans. A customer that uses all of his or her monthly minutes will find it cheaper to subscribe to a monthly plan.
While not in the table and our estimation sample, Nextel offers four plans that do not include free long distance. Nextel uses a proprietary phone technology that prohibits its customers from operating on networks owned by almost all other carriers. Consequently, Nextel does not levy charges to travelers, in part because its phones are incapable of operating off its network. We do not consider Nextel. Also, Cingular dropped its regional plans from Amazon just before data collection began.
The software toolkit Santiago and Fox (2007) implements subsampling and is available on the internet.
A referee reports out that the natural generalization of a confidence set for a point estimate to set estimation is a confidence collection (a set of sets). It is hard to visually describe a set of sets. Given that the natural measure is the (hard to compute) set of sets, the marginal benefit of reporting the set estimates in addition to the confidence sets may be small. We report both in Table 2 only to drive home their similarity.
A similar argument can be used to show that the confidence sets will be the same as the set estimates for other subsample sizes.
We did not collect data on the overage charge, the per-minute fee for making calls that exceed the monthly bucket of minutes. Therefore, we consider only one aspect of the price.
We cannot compute the presumably huge standard errors for an estimate using data on only market.
References
Abrevaya, J. (2000). Rank estimation of a generalized fixed-effects model. Journal of Econometrics, 95, 1–23.
Andrews, D. W. K., Berry, S., & Jia, P. (2005). Confidence regions for parameters in discrete games with multiple equilibria, with an application to discount chain store location. Yale University working paper.
Bajari, P., Fox, J. T., Kim, K. il., & Ryan, S. (2007). A simple nonparametric estimator for the distribution of random coefficients in discrete choice models. Working paper, October.
Beresteanu, A., & Molinari, F. (2008). Asymptotic properties for a class of partially identified models. Econometrica, 76(4), July.
Berry, S., Levinsohn, J., & Pakes, A. (1995). Automobile prices in market equilibrium. Econometrica, 63(4), 841–90.
Briesch, R. A., Chintagunta, P. C., & Matzkin, R. L. (2002). Semiparametric estimation of brand choice behavior. Journal of the American Statistical Association, 97(460), 973–982, December.
Brynjolfsson, E., Hu, Y., & Smith, M. D. (2003). Consumer surplus in the digital economy: Estimating the value of increased product variety at online booksellers. Management Science, 49(11), 1580–1596, November.
Chernozhukov, V., Hong, H., & Tamer, E. (2007). Estimation and confidence regions for parameter sets in econometric models. Econometrica, 75(5), 1243–1284, September.
Chevalier, J., & Goolsbee, A. (2003). Price competition online: Amazon versus barnes and noble. Quantitative Marketing and Economics, 1(2), 203–222, June.
Fox, J. T. (2005). Consolidation in the wireless phone industry. NET Institute working paper 05–13.
Fox, J. T. (2007). Semiparametric estimation of multinomial discrete choice models using a subset of choices. RAND Journal of Economics, 38(4), 1002–1019.
Fox, J. T. (2008). Estimating matching games with transfers. Working paper.
Galichon, A., & Henry, M. (2006). Inference in incomplete models. Working paper.
Ghose, A., & Sundararajan, A. (2006). Software versioning and quality degradation? An exploratory study of the evidence. Working paper.
Han, A. K. (1987). Nonparametric analysis of a generalized regression model: The maximum rank correlation estimator. Journal of Econometrics, 35, 303–316.
Hong, H., & Tamer, E. (2003). Endogenous binary choice model with median restrictions. Economics Letters, 80, 219–225.
Horowitz, J. (1992). A smoothed maximum score estimator for the binary response model. Econometrica, 60(3), 505–31.
Horowitz, J. L. (1998). Semiparametric Methods in Econometrics. Lecture Notes in Statistics (Vol. 131). Springer.
Huang, C.-I. (2008). Estimating demand for cellular phone services under nonlinear pricing. Quantitative Marketing and Economics. doi:10.1007/s11129-008-9040-1.
Imbens, G., & Manski, C. F. (2005). Confidence intervals for partially identified parameters. Econometrica, 72, 1845–1857.
Kim, J., & Pollard, D. (1990). Cube root asymptotics. The Annals of Statistics, 18, 191–219.
Manski, C. (1975). Maximum score estimation of the stochastic utility model of choice. Journal of Econometrics, 3(3), 205–228.
Manski, C. (1985). Semiparametric analysis of discrete response: Asymptotic properties of the maximum score estimator. Journal of Econometrics, 27, 313–333.
Narayanan, S., Chintagunta, P. K., & Miravete, E. J. (2007). The role of self selection, usage uncertainty and learning in the demand for local telephone service. Quantitative Marketing and Economics, 5(1), 1–34, March.
Nevo, A. (2001). Measuring market power in the ready-to-eat cereal industry. Econometrica, 69(2), 307–342, March.
Newey, W., & McFadden, D. (1994). Large sample estimation and hypothesis testing. In Handbook of Econometrics (Vol. 4, pp. 2111–2245). Elsevier.
Pakes, A., Porter, J., Ho, K., & Ishii, J. (2006). Moment inequalities and their application. Working paper, November.
Petrin, A. (2002). Quantifying the benefits of new products: The case of the minivan. The Journal of Political Economy, 110(4), 705–729.
Romano, J. P., & Shaikh, A. M. (2006). Inference for the identified set in partially identified econometric models. Working paper, September.
Romano, J. P., & Shaikh, A. M. (2008). Inference for identifiable parameters in partially identified economic models. Journal of Statistical Planning and Inference, 138(9), 2786–2807, 1 September.
Rosen, A. M. (2006). Confidence sets for partially identified parameters that satisfy a finite number of moment inequalities. Working paper, June.
Santiago, D., & Fox, J. T. (2007). A toolkit for matching maximum score estimation and point and set identified subsampling inference. Working paper, January.
Sherman, R. P. (1993). The limiting distribution of the maximum rank correlation estimator. Econometrica, 61(1), 123–137, January.
Acknowledgements
Bajari thanks the National Science Foundation for generous research support. Fox thanks the National Science Foundation, the NET Institute, the Olin Foundation, and the Stigler Center for generous funding. Thanks to helpful comments from seminar participants at the International Industrial Organization Conference (IIOC), the Northwestern and University of Chicago IO-Marketing conference, and the STIET seminar at the University of Michigan. We thank Austan Goolsbee, Ali Hortacsu and Chad Syverson for providing access to the Forrester Data, and for helpful comments. We thank Dennis Carlton, Victor Chernozhukov, Anindya Ghose, Aviv Nevo, Amil Petrin, Bill Rogerson and Azeem Shaikh for detailed conversations. We thank anonymous referees for comments.
Author information
Authors and Affiliations
Corresponding author
A Proofs
A Proofs
1.1 A.1 Lemma 1
In what follows, drop the indices i and m, and use the shorthand notation a j for \(x_{jm}^{'}\beta-p_{jm}+\nu_{im}^{h}\). Also replace the conditioning arguments J m ,H m ,X m , \(\vec{p}_{m},I_{m},\left\{ \vec{\nu}_{im}\right\} _{i\in I_{m,}}\) of the densities of ε j and ξ j with \(\vec{a}\), the vector of the J a j ’s.
Both ε j and ξ j are not in the data. The joint density of all J ε J ’s and ξ j ’s is
First we will integrate out ε. Let \(\mbox{Pr}\left(j\mid\vec{a},\vec{\xi}\right)\) be the probability of picking j conditional on the realization of the ξ j ’s. The decision rule in Eq. (3) becomes
for all choices l.
First prove the “only if” direction: If a j + ξ j > a k + ξ k , then \(\mbox{Pr}\left(j\mid\vec{a},\vec{\xi}\right)>\mbox{Pr}\left(k\mid\vec{a},\vec{\xi}\right)\). By the definition of a choice probability,
where \(h\left(l\right)\) is a convenience function returning the nest of choice l. If \(h\left(j\,\right)=\) \(h\left(k\right)\), as in the statement of the lemma, \(\mbox{Pr}\left(j\mid\vec{a},\vec{\xi}\right)\) is the same function as \(\mbox{Pr}\left(k\mid\vec{a},\vec{\xi}\right)\), except that a k + ξ k replaces a j + ξ j in the upper limits, and a j + ξ j replaces the one term where a k + ξ k enters in \(\mbox{Pr}\left(j\mid\vec{a},\vec{\xi}\right)\). Let \(W\left(a_{j}+\xi_{j},a_{k}+\xi_{k}\right)\) be \(\mbox{Pr}\left(j\mid\vec{a},\vec{\xi}\right)\) as a function of a j + ξ j and a k + ξ k .
As a j + ξ j enters only upper limits of integrals in \(W\left(a_{j}+\xi_{j},a_{k}+\xi_{k}\right)\) , \(W\left(a_{j}+\xi_{j},a_{k}+\xi_{k}\right)\) is increasing in a j + ξ j . Also, a k + ξ k enters negatively in only one upper limit in \(W\left(a_{j}+\xi_{j},a_{k}+\xi_{k}\right)\). Because \(f_{h\left(j\right)}\left(\varepsilon_{j}\mid\vec{a},\vec{\xi}\right)\) has full support by Assumption 1, \(W\left(a_{j}+\xi_{j},a_{k}+\xi_{k}\right)\) is strictly increasing in a j + ξ k and strictly decreasing in a k + ξ k . Then if a j + ξ k > a k + ξ k , as in the statement of the lemma, \(W\left(a_{j}+\xi_{j},a_{k}+\xi_{k}\right)>W\left(a_{k}+\xi_{k},a_{j}+\xi_{j}\right)\). Likewise, the “if” direction is proved as the only way \(W\left(a_{j}+\xi_{j},a_{k}+\xi_{k}\right)>W\left(a_{k}+\xi_{k},a_{j}+\xi_{j}\right)\) is if a j + ξ j > a k + ξ k .
The above argument conditioned on \(\vec{\xi}\). We need to prove statements about \(\mbox{Pr}\left(j\mid\vec{a}\right)\) and \(\mbox{Pr}\left(k\mid\vec{a}\right)\). Again by the definition of a choice probability,
Because Assumption 1 states each \(f_{h\left(j\right)}\left(\varepsilon_{j}\mid\vec{a},\vec{\xi}\right)\) is exchangeable in the arguments ξ j and ξ k when \(h\left(j\right)=h\left(k\right)\) and the ξ jm ’s are i.i.d. within a nest, then \(\mbox{Pr}\left(j\mid\vec{a}\right)\) is the same function as \(\mbox{Pr}\left(k\mid\vec{a}\right)\), except where a j and a k enter the upper limits in \(\mbox{Pr}\left(j\mid\vec{a},\vec{\xi}\right)\). By a similar argument as with the W function above, the lemma is proved.
1.2 A.2 Lemma 2
Because expectation and integration are linear operators, conditioning on the number of consumers I m results in:
where the second-to-last equality is from the law of iterated expectations and the last equality uses the definition of a choice probability that integrates out consumer product specific error terms of the form ε ijm and product specific error terms of the form ξ jm .
First consider the “if” direction. Consider two products j and k in the same nest h, and let \(x_{jm}^{\prime}\beta-p_{jm}>x_{km}^{\prime}\beta-p_{km}\). Under Assumption 1, Lemma 1 states that
for all consumers. By the above market share algebra,
as by Lemma 1 each consumer chooses j more often than k. As \(E\left[s_{jm}\mid I_{m},\right.\) \(\left.J_{m},H_{m},X_{m},\vec{p}_{m}\right]>E\left[s_{km}\mid I_{m},J_{m},H_{m},X_{m},\vec{p}_{m}\right]\) for any number of consumers I m , \(E\left[s_{jm}\mid J_{m},H_{m},X_{m},\vec{p}_{m}\right]>E\left[s_{km}\mid J_{m},H_{m},X_{m},\vec{p}_{m}\right]\) unconditional on the unobserved (in our data) number of consumers I m .
The “only if” direction just reverses these documents, as the only way the sum of choice j’s probabilities can be greater than choice i’s under Lemma 1 is when \(x_{jm}^{\prime}\beta-p_{jm}>x_{km}^{\prime}\beta-p_{km}\).
1.3 A.3 Lemma 3
Drop the m index for simplicity. We are comparing products j and k, which are in the same nest. The rank of product j with a finite sample of I customers is \(\hat{r}_{j}\). The rank orders the (unobserved) market shares s j . The condition that \(\hat{r}_{j}>\hat{r}_{k}\) can be rewritten as \(\hat{s}_{j}>\hat{s}_{k}\). Dividing by a positive number \(\hat{s}_{j}+\hat{s}_{k}\), the inequality becomes
Define \(\tilde{s}\) to be \(\frac{\hat{s}_{j}}{\hat{s}_{j}+\hat{s}_{k}}\) , leaving \(1-\tilde{s}\) to be \(\frac{\hat{s}_{k}}{\hat{s}_{j}+\hat{s}_{k}}\). We want to show that \(P\left(\tilde{s}>\frac{1}{2}\right)>P\left(\tilde{s}<\frac{1}{2}\right)\).
First consider the case without product market error terms ξ j . We also condition on I jk , the number of people who buy either j or k. An individual i prefers j over k with probability q i . By Lemma 1, \(q_{i}>\frac{1}{2}\). However, because the density of errors and the realization of fixed effects vary across consumers, q i will be different for each consumer. We work with the number (rather then the fraction) of consumers who buy j out of the group who buy either j or k. Call this number r j . The random variable r k = I jk − r j is the number of consumers who pick k over j. Let \(r^{\star}=\frac{I_{jk}}{2}\). We want to show \(\mbox{Pr}\left(r_{j}>r^{\star}\right)>\mbox{Pr}\left(r_{k}>r^{\star}\right)\).
Now, if \(q_{i}=\frac{1}{2}\) for all i, \(\mbox{Pr}\left(r_{j}>r^{\star}\right)=\mbox{Pr}\left(r_{k}>r^{\star}\right)\) by the properties of the binomial distribution. By a monotonicity arguments, increasing even one q i will raise \(\mbox{Pr}\left(r_{j}>r^{\star}\right)\) and consequently weakly lower \(\mbox{Pr}\left(r_{k}>r^{\star}\right)\), as for odd I jk \(\mbox{Pr}\left(r_{j}>r^{\star}\right)+\mbox{Pr}\left(r_{k}>r^{\star}\right)=1\) and for even I jk \(\mbox{Pr}\left(r_{j}>r^{\star}\right)+\mbox{Pr}\left(r_{k}>r^{\star}\right)=1-\mbox{Pr}\left(r_{k}=r_{j}\right)\). So \(\mbox{Pr}\left(r_{j}>r^{\star}\right)>\mbox{Pr}\left(r_{k}>r^{\star}\right)\), and the “only if” direction of the lemma is proved. The “if” direction just reverses the above steps, as the only way one product is ranked higher than another more frequently is when the first product has a higher payoff.
The above argument conditioned on a value of I jk . As the lemma holds for any value of I jk , it holds unconditionally as well.
Now consider the case with both ξ j and ε ij errors. For each realization of ξ j , each consumer has a q i that involves the remaining uncertainty over the ε ij terms. Even if j has a higher mean payoff than k, it could be that \(q_{i}<\frac{1}{2}\) because of the realization of ξ j and ξ k . The probability q i is the probability of picking j over k given that the payoff of j is \(x_{j}^{\prime}\beta-p_{j}+\xi_{j}+\nu_{ih}\) and the payoff of k is \(x_{k}^{\prime}\beta-p_{k}+\xi_{k}+\nu_{ih}\). By Lemma 1, \(q_{i}>\frac{1}{2}\) when \(x_{j}^{\prime}\beta-p_{j}+\xi_{j}+\nu_{ih}>x_{k}^{\prime}\beta-p_{k}+\xi_{k}+\nu_{ih}\). In other words, either the realization of product and market specific shocks is such that \(q_{i}>\frac{1}{2}\) for everyone or \(q_{i}\leq\frac{1}{2}\) for everyone. So the lemma being proved holds if \(x_{j}^{\prime}\beta-p_{j}+\xi_{j}>x_{k}^{\prime}\beta-p_{k}+\xi_{k}\) more than half of the time when \(x_{j}^{\prime}\beta-p_{j}>x_{k}^{\prime}\beta-p_{k}\), which it does because Assumption 1 states that the ξ’s are i.i.d.
1.4 A.4 Lemma 4
Our identification under sampling error argument will show that the probability limit of \(Q_{M}\left(\beta\right)\) is uniquely maximized by the parameter vectors in the identified set B 0, which is defined in the statement of the lemma. Use the notation r j for the underlying random variable for market share ranks. If M→ ∞, the maximum score objective function converges to the population objective function
where we have factored the fixed-across-markets product characteristics out of the expectation over the preferences of customers and the number of such customers in each market m. The probability limit can be rewritten to focus on unique pairs of products as
For each pair of products, the objective function is the sum of two probabilities times mutually exclusive inequalities. \(Q_{\infty}\left(\beta\right)\) is maximized if the inequality multiplying the (weakly) greater of \(E\left\{ 1\left[r_{j}>r_{k}\right]\right\} \) and \(E\left\{ 1\left[r_{k}>r_{j}\right]\right\} \) is set to 1. Lemma 3 shows that \(E\left\{ 1\left[r_{j}>r_{k}\right]\right\} \) is larger than \(E\left\{ 1\left[r_{k}>r_{j}\right]\right\} \) precisely when \(x_{j}^{'}\beta^{0}-p_{j}\) is greater than \(x_{k}^{'}\beta^{0}-p_{k}\). Therefore, \(Q_{\infty}\left(\beta\right)\) is maximized for any β ∈ B 0, the identified set. Clearly β 0 ∈ B 0, the identified set.
For identification under sampling error, we also need to show that parameter vectors that are not part of the identified set do not maximize the objective function. Equivalently, we need to prove that if some β maximizes \(Q_{\infty}\left(\beta\right)\) then β ∈ B 0. If β maximizes \(Q_{\infty}\left(\beta\right)\), the larger of \(E\left\{ 1\left[r_{j}>r_{k}\right]\right\} \) and \(E\left\{ 1\left[r_{k}>r_{j}\right]\right\} \) enters the objective function for each pair of choices. That term multiplies one of the mutually exclusive indicator functions in β, so this β must maximize the non-sampling error objective function, (6). So by the definition of B 0 and Lemma 3, β ∈ B 0 and the identified set comprises the maximizers of the probability limit of the objective function under sampling error.
Rights and permissions
About this article
Cite this article
Bajari, P., Fox, J.T. & Ryan, S.P. Evaluating wireless carrier consolidation using semiparametric demand estimation. Quant Market Econ 6, 299–338 (2008). https://doi.org/10.1007/s11129-008-9044-x
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11129-008-9044-x
Keywords
- Market share ranks
- Semiparametric
- Demand estimation
- Amazon
- Mergers
- Antitrust
- Telecommunications
- Mobile phones
- Online
- Discrete choice