
Abstract
Disasters affect millions of people annually, causing large numbers of fatalities, detrimental economic impact and the displacement of communities. Policy-makers, researchers and industry professionals are regularly faced with these consequences and therefore require tools to assess the potential impacts and provide sustainable solutions, often with only very limited information. This paper focuses on the themes of “disaster management”, “natural hazards” and “simulation”, aiming to identify current research trends using bibliometric analysis. This analysis technique combines quantitative and statistical methods to identify these trends, assess quality and measure development. The study has concluded that natural hazards (73%) are more predominant in research than man-made hazards (14%). Of the man-made hazards covered, terrorism is the most prevalent (83%). The most frequent disaster types are climate related, and in this study hydrological (20%), geophysical (20%), meteorological (15%) and climatological (5%) were the most frequently researched. Asia experiences the highest number of disaster events as a continent but in this study was only included in 11% of papers, with North America being the most recurrent (59%). There were some surprising omissions, such as Africa, which did not feature in a single paper. Despite the inclusion of key words “simulation” and “agent based” in the searches, the study did not demonstrate there is a large volume of research being carried out using numerical modelling techniques. Finally, research is appearing to take a reactive rather than proactive approach to disaster management planning, but the merit of this approach is questionable.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
It has been reported that between 1994 and 2013, 218 million people were affected by natural disasters annually (CRED 2015). It has also been estimated that between 2000 and 2011, a total of $1.3 trillion worth of damage and 1.1 million fatalities were caused as a result of natural disasters (International Civil Defence Organisation 2016). In 2016, this resulted in “over 65 million refugees and displaced people in the world” (Cosgrave et al. 2016).
During 2016, the UN convened for the first time in its 70-year history a world summit on humanitarian assistance, stating that “today, the scale of human suffering is greater than at any time since the Second World War” (United Nations 2016). It is estimated that up to 130 million people across the globe currently rely on humanitarian assistance to survive (United Nations 2016). This has resulted in a renewed focus on disaster management policy (Ismail-Zadeh and Takeuchi 2007; Birkmann et al. 2010), which has the potential to greatly reduce the suffering of communities across the globe (Cutter 2016; Aka et al. 2017; Singh-Peterson et al. 2015). Consequently, there have been many international improvements and a recognition of the rewards of better planning for natural disasters, including improved early warning systems (Wenzel et al. 2001; Durage et al. 2013; Glade and Nadim 2014), improved application of risk registers on a range of scales (Glavovic et al. 2010; Markovic et al. 2016) and improved emergency communications (Miao et al. 2013; Lu and Xu 2014). In the developed world, natural hazards still impact on society; however, developed economies have the resources to be able to consider effective mitigations strategies pre-event, rather than firefighting the consequences post-event. This is a far more effective strategy for dealing with natural hazards and is achieved through the development of regulatory frameworks that develop mitigation strategies and plans to minimise the impacts of potential disasters. For example, in the UK the Civil Contingences Act 2004 was brought in to provide a single framework for civil protection in the UK (Cabinet Office 2013), whilst in the USA a national preparedness goal has been set out, which encourages the shared responsibility from the entire nation (FEMA 2016; Sadiq et al. 2016). This demonstrates that informed governmental policy on disaster management can be seen as a driver for change.
Currently, there is a reliance on testing contingency plans either through real-time simulation, which is costly in both monetary and resource terms (Cabinet Office and National Security and Intelligence 2013) or through scenario-based methodology in tabletop exercises, which can be unrealistic. Within the UK, regular real-life simulations are conducted, for example in March 2017, a mock terrorist exercise was conducted on the River Thames in London, including more than 200 Met Police officers (Beake 2017). Another example occurred in June 2015, when a week-long terrorist attack was simulated in central London, this involved over 1000 police officers, 2000 causalities made up of actors and dummies, and the event took over 6 months to plan and execute (BBC 2015; Paton and Warrell 2015). However, there is an alternative and more robust method to test, using computational approaches, which would allow for multiple runs and adjustments without the large financial or resource costs. However, at present, policies and frameworks do not explicitly outline the use of computational systems and modelling to help their progress.
To tackle this problem, academics and researchers have been developing modelling techniques and approaches, such as cellular automata, system dynamics and fault tree analysis, to try and simulate hazard types under particular scenario conditions (e.g. fire on a metro network, (Zhong et al. 2008; Lo et al. 2014) or pedestrian earthquake/tsunami evacuation (Wood et al. 2016; Peters et al. 2016; D’Orazio et al. 2014; Wood and Schmidtlein 2012). However, these models are often non-transferable, meaning that it is not possible to keep software “current” or future-proofed as the modelled problems are bespoke in nature. An alternative modelling approach is agent based modelling, which has been described as “one of the most important generic modelling frameworks to have been developed to date” (Batty et al. 2012). It has the capability to allow “one to simulate the individual diverse agents, measuring the resulting system behaviour and outcomes over time” (Crooks et al. 2008). Therefore, agent based modelling, unlike other modelling techniques, is transferable to many problems. For example, using an agent based model, human behaviour in a disaster can be simulated; this model can then be utilised in numerous contexts, e.g. for natural hazards, fires or terrorist attacks, where the human responses will be similar (i.e. flee the hazard).
This paper conducts a bibliometric analysis to explore this area of research and to identify the main themes of research at present, such as common hazard types and prevalent locations. Bibliometric analysis is a quantitative and statistical method, used to examine a collection of publications with the aim of identifying trends, assessing the quality and measuring the development of current research fields. The methodology used in this study is similar to those of Chappin and Ligtvoet (2014) and Chappin and van der Lei (2014), but we apply our study to a different topic area. There are alternative approaches available for a bibliometric analysis, such as Opdyke et al. (2017) who utilises the Web of Science and Engineering Village databases with NVivo qualitative analysis software to carry out their study. However, this study only considers a limited number of categories (e.g. author location, research methods) and provides a more “in depth” analysis, whereas this paper considers the “breadth” of research available.
2 Approach and methodology for bibliometric analysis
Bibliometric analysis utilises a literature search of information to analyse trends in the returned data. In this paper, we focused on several keywords regarding disaster management to generate a set of returned papers, which were then analysed for various characteristics. The trends found in these papers were then compared with current known disaster trends, to determine whether research tied into the current state of play (e.g. Is current research focusing on the most frequent, deadliest and costliest disasters?). Additionally, the trends were also considered in relation to recent international policy developments, assessing whether the policy advancements matched with the research being carried out.
In order to choose an appropriate academic search engine for the analysis, the search terms were entered into four different search engines: Web of Science, Scopus, Science Direct and Google Scholar (Table 1). The search was limited to searching for the keywords “natural hazards” and “disaster management”. Furthermore, as the interest lies with the simulation used to model natural hazards and disaster management scenarios, the search term “simulation” was also included. A variation was also included to specify “agent based simulation”, to identify whether stipulating a specific modelling technique returned more specific papers on the topic.
For the first set of terms, limited to the search range of 2000–2017, “natural hazards”, “disaster management” and “simulation”, Google Scholar returned the largest number of results. The second set with the changed term for “agent based simulation” also returned the largest number of results in Google Scholar. Therefore, the literature search was conducted using the Google Scholar search engine; this is also a developing choice for scientific database selection. Whilst the search algorithm is not explicitly published, Google Scholar states that their aim is “to rank documents the way researchers do, weighing the full text of each document, where it was published, who it was written by, as well as how often and how recently it has been cited in other scholarly literature” (Google Scholar 2018). Previous studies have also shown that Google Scholar’s ranking algorithm is based on a number of metrics, rather than citations alone (Beel and Gipp 2009; White 2006). Previous bibliometric studies selected Scopus, for example, Chappin and van der Lei (2014) and Chappin and Ligtvoet (2014), but this would not have been possible in this study due to the low number of search results returned.
To carry out an in-depth bibliometric analysis, it was not possible to include all 17,200 and 18,400 returned papers in the study and the aim of the paper was to assess the current research direction in this field. Therefore, the search needed to be limited to a manageable number, whilst including sufficient papers to return a “meaningful” result. Hence, a sampling technique was required to obtain a manageable proportion of these papers to analyse. The aim was to concentrate on the most influential papers (e.g. those with a higher number of citations, published in recent years and high relevance to the field) and assumed that the Google search algorithm was a reasonable way of ranking these papers in order of influence. As such, the top proportion of papers from a returned Google Scholar keyword search was analysed.
To further test this, an analysis was conducted to show that the ranking for the two searches in Google Scholar were not purely based on the number of citations or publication year alone (Fig. 1), demonstrating that Google Scholar uses a range of metrics to rank documents. For this reason, the use of randomly selected papers was discounted as part of this study, as this was not likely to include the most influential papers in the field (e.g. as the majority of research papers in a field will have a relatively small number of citations), and therefore we could not meet the aims of the paper. It can also be argued that it was better to choose those papers that ranked highly in the Google Scholar search (and were therefore deemed to have greater influence) than a random sample, which may actually result in a set of papers that were published many years ago and have few, to no, citations.

a Number of citations versus Google Scholar search position, b year of publication versus Google Scholar search position
Using our methodology, it was infeasible to collect detailed data for all returned 17,200 and 18,400 papers in the Google Scholar searches, as previously stated. Therefore, a robust number of these papers needed to be selected for analysis. In order to do this, a citation distribution was constructed for both of the Google Scholar searches, which informed the number of papers that needed to be considered, for a chosen percentage of the total number of returned paper citations to be analysed. In this study, paper citations are being used as our proxy for influence. This methodology has previously been used by Redner (1998), Blanford (2016) and Laherrere and Sornette (1998), who have shown that a citation distribution follows either a power law or exponential distribution. To construct the citation distribution, all the returned papers from the search were considered and ranked in order of the number of citations (Figs. 2 and 3), before plotting an exponential trend line. Following this, the proportion of citations for a given number of papers was calculated (Tables 2 and 3), which allowed a selection to be made of the number of papers that returned a robust sample size. For one of the searches, our analysis provided a total of 11,617 citations, which is approximately 87% of the total number of citations (Table 2), which we deemed to be a “robust” quantity.

Citation distribution for search terms: natural hazards, disaster management and simulation. We have shown up to 55 papers for clarity, to better show the fit of the trend line. It can be seen that the trend line does not fit the papers with a high number of citations (e.g. the first six papers) particularly well; therefore, we calculate the percentage of citations using the trend line function and the actual data points in Table 2

Citation distribution for search terms: natural hazards, disaster management and agent based simulation. We have shown up to 55 papers for clarity, to better show the fit of the trend line. It can be seen that the trend line does not fit the papers with a high number of citations (e.g. the first four papers) particularly well; therefore, we calculate the percentage of citations using the trend line function and the actual data points in Table 3
Hence, it was decided that the first 50 papers for each of the two search criteria would be selected to be reviewed comprehensively (excluding books, links to PDF documents and other “non-journal paper” literature). After compiling the results for each set of search terms, then removing the crossover between the two sets, there were a total of 84 papers to be included in the study.
The in-depth analysis was carried out after the initial literature search and involved extracting relevant information from the papers upon reading; this was collated and then analysed to produce trends. The data collected included: the journal publication, corresponding author location, author’s keywords, length of study, methodology used, case study inclusion, hazards, quantitative study and number of Google Scholar citations. The bibliometric analysis was used to understand the types of research being carried out, such as the methodologies used, lengths of papers and types of studies (e.g. quantitative or qualitative). Assessment was also made on whether the search terms used in study, “simulation” or “agent based simulation”, resulted in a larger number of papers including modelling techniques.
This paper also considered whether comparisons could be drawn between the bibliometric analysis, key disaster trends and international policy. The aim of this was to provide a series of recommendations to further the research field by identifying gaps and areas to strengthen. To do this, two reviews were carried out on recent global disaster trends and current international global disaster management policy.
The key disaster trends were explored on a global basis using the Centre for Research on the Epidemiology of Disasters (CRED) report on the Human Cost of Natural Disasters (CRED 2015) and the International Disasters Database (EM-DAT 2016a, b). The aim was to identify common trends, such as the disaster impacts (number of fatalities, populations affected or damage caused). From this, common locations and disaster types could also be recognised.
A review was also undertaken of the international policies belonging to the UK, USA and New Zealand. These three developed countries had easily accessible, well-developed policies for disaster management, which could be traced back over a number of years to establish the developments over time. It is important to understand the interaction between the research community and policy-makers. The research community is made up of “experts” with many years of experience in their fields and policy-makers who can enact physical changes on a local, national and international scale within their fields. However, we do not necessarily know whether the opinions of research “experts” are influencing the decisions made by policy-makers. In terms of disaster management, this needs to be explored in two different ways: (1) Do the trends identified in research match the threats identified by government or other institutions? (2) Do the methodologies proposed by researchers (e.g. for testing disaster management plans) receive support or utilisation by policy-makers?
3 Bibliometric results and discussion
The bibliometric analysis analysed 84 papers in total; this resulted in the identification of common themes, which could then be compared.
3.1 What hazards are the focus?
This analysis shows that natural hazards (73%) are more commonly researched than man-made hazards (14%) (Fig. 4a), and for these man-made hazards terrorism (83%) is the concern of the majority. In general, generic natural hazards (37%) are covered more frequently than any one specific hazard type (Fig. 4a). Generic natural hazards, in this context, are those papers where a specific hazard type is not allocated and instead reference is only made to natural disasters in general. For the specific hazard types identified, the most common research hazards are hydrological (20%) and geophysical (20%), followed by meteorological (15%).

a Disaster threats identified in research papers, b hazards identified in papers compared with the year of the paper’s publication
The papers in this study were limited to years between 2000 and 2017 (as previously discussed). From these papers, the peak number of papers published was during 2003 (Fig. 4b). Research on terrorism only appears in publications from 2001 onwards, the same year which saw the 9/11 USA terror attacks (Fig. 4b). Other than the link to terrorism, there seems to be no distinct pattern with the year of publication and the hazards researched in papers (Fig. 4b). For example, after the Hurricane Katrina event in 2005, there does not appear to be a significantly greater number of papers on meteorological hazards published.
From the 84 papers analysed, 48% of papers included a case study as part of their study. In agreement with the hazards covered in papers, the case studies included also primarily focus on natural hazard disasters (95%), rather than man-made hazards (Fig. 5a). Of the natural hazards covered, earthquakes (28%) and hurricanes/cyclones/typhoons (28%) are the most covered, followed by flooding (25%) (Fig. 5a). Other types of hazards, including landslides (4%), hailstorms (4%) or drought (2%), are not well covered in comparison (Fig. 5a). Generally, these are the hazards which are less prevalent worldwide and therefore the amount and availability of data for case studies are likely to be reduced. The pattern of case study hazards has not changed significantly over time, demonstrating a continual commitment to case studies on earthquakes, flooding and hurricanes/typhoons/cyclones (Fig. 5b).

a Disaster threats identified in case studies included within papers, b case study hazards identified compared with the year of the paper’s publication
3.2 What research is undertaken?
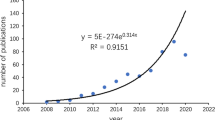
The results of this study have shown that the peak number of publications was seen in 2003 (13%), when the number of journal publications peaked, before gradually decreasing over the subsequent years until 2014 (2%) (Fig. 6a). From the papers analysed, nearly 50% use a review methodology and include little original or novel work (Fig. 6b). However, nearly 40% included some form of modelling technique in the paper, with the remaining 10% of papers consisting of case studies or introductory articles (Fig. 6b).

a Number of papers published each year, b types of methodologies featured in papers, c length of study based on references compared to the methodology of the paper completed, d types of study (quantitative versus qualitative), e type of study (quantitative versus qualitative) compared to case study inclusion in papers, f methodology of papers compared to the type of study (quantitative versus qualitative)
The exact study length of paper can be quite difficult to define, particularly in the case of review papers. Previous studies have tended to consider only case study papers and based the length upon the research period alone (Chappin and Ligtvoet 2014; Chappin and van der Lei 2014), with time periods defined as: short < 1 year, medium 1–10 years and long > 10 years. To adapt this technique for review papers, we consider the length of the paper to be based upon the references (e.g. we define the time period as the publication date of the paper itself to that of the earliest reference used). We also need to adapt the time periods used, as if the same criteria are applied we would have no short studies, 42% medium and 58% long. As such, we propose the following criteria: short < 10 years, medium 10–24 years and long > 25 years. Using this new timescale, we find that the analysed journal papers can be classified into: short (17%), medium (63%) and long (20%). Generally, papers with longer reference times tended to be review papers (Fig. 6c).
The papers were split into those that were qualitative (review or case study papers) and those that were quantitative (included modelling). Out of the 84 papers, over 50% were qualitative, which was interesting as one of the search terms was simulation, so it was anticipated there would be a larger number of quantitative papers (Fig. 6d). Out of the quantitative papers, 80% included a case study, whereas 80% of the qualitative papers do not contain a case study (Fig. 6e). Of the different methodologies used, over 80% of the review papers were qualitative and over 75% of the modelling papers were quantitative, which is as expected, for example if a paper uses review techniques it is more likely to be qualitative and vice versa (Fig. 6f).
3.3 Where is research focused?
An important aspect of disaster management is related to the location of threats. Certain locations are more vulnerable to specific hazards or more frequently experience event types. Therefore, there is a need to understand where current research is carried out and whether this correlates with the locations of the most frequent, deadly or costliest natural disasters across the globe. Locations feature in papers in numerous ways, including the author’s country, the research focus of papers and the location of case studies. By looking into these, it is possible to understand whether there is any correlation and if these locations are linked with the key disaster trends.
This study has found that corresponding authors are located across the globe, with the largest proportion in North America (59%), then Europe (18%), Oceania (12%) and Asia (11%) (Fig. 7a).The analysis also considered the focus of papers in terms of location. It was found that the focuses ranged from non-specific worldwide themes (44%) and developing countries (5%), to specifics on the USA (33%), others combined a country and a worldwide emphasis, for example USA/worldwide (10%), and some focused on specific locations (8%) (Fig. 7c). Also, a number of papers included case studies to help demonstrate their findings or for use within modelling techniques; the locations were North America (60%), Asia (18%), Europe (15%) and Oceania (7%) (Fig. 7e).

a Corresponding author location by continent—detailed author locations are as follows: North America (USA and Canada), Asia (Taiwan, Japan, China and Singapore), Europe (UK, the Netherlands, Germany, Sweden, Slovenia and Greece) and Oceania (Australia and New Zealand), b corresponding author location by continent compared to paper location focus, c research focus of the paper in terms of region covered in paper, specific location refers to studies in the following locations: Taiwan, UK, Greece, the Netherlands, Indonesia and Australia, d corresponding author location by continent compared to case studies location by continent, e case study locations by continent, f case study hazard types compared to case study continents
The corresponding authors can be used to give an indication of the likely area covered by a paper. It appeared that this may not be the case as over 40% of the papers had a worldwide/generic focus (e.g. they were not specific to any one country or continent). However, over 40% of the papers are specifically linked to either the USA or a combined USA/worldwide approach (Fig. 7c). This demonstrates that for some locations, the author location does influence the focus of the paper (Fig. 7b). It can be deemed that in general if an author is based in the USA, their research will focus on the USA (Fig. 7b). It is to be expected that there would be large amounts of research carried out in the USA, as they are frequently affected by natural hazards and the financial implications in absolute values are large for the country.
The obvious exception to this are the authors who choose to carry out generalised research and to not focus on a specific location. There are also some examples where author location does not affect the research location choice. For example, a UK author researches on a case study in Greece (Fig. 7b), but in contrast this is still part of the same continent.
There are a wide range of case studies included within the papers, with locations across the globe in North America, Asia, Europe and Oceania (Fig. 7e). This location spread is to be anticipated due to the corresponding author locations. Asia is not well covered with case studies (18%), and there are no case studies in Africa. Commonly, it is seen that case studies are carried out in the same locations as authors or in close proximity (Fig. 7d). This is likely to be due to the availability, accessibility or reliability of information and/or data and the local knowledge of authors. Also if there is any requirement for field trips or data collection, this is generally easier to facilitate when in close proximity. Again, the largest number of case studies is focused on North America (60%), tying into the frequency of events and the financial costs (Fig. 7d).
It is also the case that hazards reflect the common hazards seen on a continent rather than extreme or one-off events, for example North America experiences flooding, earthquake and hurricanes, whilst Asia experiences flooding, earthquakes, typhoons and landslides (Fig. 7f). This is to be expected for case studies, as a quantity of reliable data is often required.
3.4 Where to find this research?
The vast majority of research is undertaken in academic institutions and in research facilities across the globe. With large volumes of research produced on different topic areas, it is necessary to understand whether this information is located in the same journals, what impact this research has and whether citations can help to increase the prevalence and impact of the research.
The most prevalent journal in this study was Natural Hazards (10%), Natural Hazards Review (8%) and Disaster Prevention and Management: An International Journal (7%) (Fig. 8). In total, 57 different journals were recorded in the study; out of a total of 84 papers, there were only 11 instances where there were repeated articles in the same journal publication. The highest impact factors do not correspond with the mostly commonly used journals in this study (Fig. 8). It is perhaps not surprising that all of the most prevalent journals in the study contain a keyword from the search criteria, e.g. “natural hazards” or “disaster management”.

Most prevalent journal publications in the study and their corresponding impact factors
Google Scholar as part of its search results provides a record of the number of citations a paper has received. The majority of the papers in this study have been cited 0–100 times (33%), 101–200 (25%) or 201–300 (11%). This shows that as the number of citations increases, the number of papers achieving the level required decreases; however, there are examples of some journals being cited over 1000 times and one is cited over 3000 times (Fig. 9). It is also interesting to consider the number of citations given by Google Scholar and the position of the journal paper in the Google Scholar search results. This shows that Google Scholar does not identify journal papers on the number of citations alone (Fig. 10). In the search that uses simulation, there are a number of papers with higher numbers of citations in the initial results compared to the “agent based simulation” search where the number of citations is spread more evenly amongst the search position.

Number of Google Scholar citations for journal papers in the study

Number of citations according to Google Scholar and the journal paper’s position in the returned Google Scholar search a search terms: natural hazards, disaster management and simulation, b search terms: natural hazards, disaster management and agent based simulation
Of the most prevalent journals, the Google Scholar citations indicate that Natural Hazards has a range between 0 and 300 citations, Natural Hazards Review has a larger range of 0–700 citations and Disaster Prevention and Management has a range between 0 and 500 times (Fig. 11). This shows that journals with a higher number of published papers (in this study) do not correlate with a higher number of citations per paper, according to Google Scholar, nor does having a higher journal impact factor link to a larger number of citations. For example, Environmental Modelling and Software has one paper with 0–100 citations and another with 101–200 citations, whilst in Tourism Management one paper has 101–200 citations and one has 501–600 citations (Fig. 11). However, the exception to this is Global Environmental Change which has one paper cited 1001–2000 times and one cited over 3000 times (Fig. 11), which ties well with the high impact rating. This indicates that the topic and contents of the paper are the driving factors behind citations, rather than the high impact factor of the journal.

Number of citations according to Google Scholar for most common journals and total number of journals in the study with corresponding Google Scholar citations
3.5 Keyword search terms
With any journal publication, authors are required to select several keywords to reflect the overall themes of the paper. This can be a good indication of the overarching themes of the work and can be influential in whether a paper appears in a search or not. The keywords from all the papers were collected together as part of this study. It is interesting to note that not all papers provided keywords with 26% not including keywords. From the keywords, the search terms of “natural hazards”, “disaster management” and “simulation” were removed. “Agent based simulation” was not removed, as although this was one of the search criteria, it was decided to determine how prevalent the term was within the keywords.
After removing the search terms, the most prevalent words were “risk” (5%), “modelling” (3%), “flood” (3%), “GIS” (3%), “evacuation” (3%) and “emergency” (3%) (Fig. 12a, c). It is interesting to note that “agent” (1%) was not in the top keywords, even though it had been one of the search criteria for the papers.

a Author’s chosen keyword terms, produced by Word Clouds (2017), b terms selected by reader on completion of reading papers, produced by Word Clouds (2017), c most common keyword occurrence (selection after reading and by author), d search terms used in Google Scholar compared with modelling techniques included in papers
Although the keywords can be useful for determining the themes of a paper, keywords can often be limited to a selection list (set by the journal), meaning that important themes may be missing. Therefore, after analysing the 84 papers, the key themes and terms were extracted by the reader from the papers to determine whether this matched with the author’s keyword selection. The most common terms were “risk” (4%), “vulnerability” (2%), “evacuation” (2%), “emergency” (2%) and “systems” (2%) (Fig. 12b, c). Again, the term agent (0.8%) was not in the top keywords, even though it had been one of the search criteria for the papers. This shows that there is correlation between the author’s selection and those chosen after reading the papers, suggesting that the use of lists for keyword selection does not adversely affect the selection of keywords.
The search terms selected for the literature search were aimed at producing results relating to modelling and simulation techniques in a disaster management context for natural hazards. However, when the search term “simulation” was used, over 60% of the papers included no modelling, and the modelling papers did not relate to agent based modelling (Fig. 12d). Using the search term “agent based simulation”, 50% of the papers generated contained no modelling, 35% contained reference to a modelling technique and only 15% of the papers specifically used agent based modelling (Fig. 12d). There were a number of papers that appeared as results for both “simulation” and “agent based simulation”; of these papers, over 60% had no modelling included, with just under 20% having a modelling technique in and the same amount (< 20%) having a specific mention of agent based modelling (Fig. 12d). Despite the use of specific search terms to extract modelling- and simulation-based papers, the use of these search terms was not particularly successful at producing relevant results.
4 Key disaster trends
4.1 Overview
The UN Office for Disaster Risk Reduction (UNISDR) considers disasters as: “a serious disruption of the functioning of a community or a society involving widespread human, material, economic or environmental losses and impacts, which exceeds the ability of the affected community or society to cope using its own resources” (UNISDR 2009). The data in this section have been collated to demonstrate the frequency of natural disasters and how communities have been affected (including fatalities and economic impacts), to enable an exploration of the current disaster trends across the globe. The data have been obtained from the EM-DAT, the International Disaster Database produced by the Centre for Research on the Epidemiology of Disasters (CRED) (Guha-Sapir et al. 2016a, b) and from the “The Human Cost of Disasters: A Global Perspective” report (CRED 2015). For a disaster to be included within the EM-DAT database it must meet one of the following criteria: (1) 10 or more people died, (2) 100 or more people were affected, (3) there was a declaration of a state of emergency or (4) there was a call for international emergency assistance (EM-DAT 2016a, b).
The prevalence of natural disasters has remained relatively static over the past 20 years; however, the number of people affected, fatalities and economic costs continue to grow (CRED 2015). During the study period (1994–2013), the largest number of people, around 600–700 million, affected in 2002, and the second highest in 1998 around 300–400 million people (CRED 2015). Generally, the number of people affected is around 200–300 million people per year (CRED 2015), from which it can be calculated that approximately 2–3% of the world’s population is affected by a natural disaster each year.
The lowest frequency of natural disasters occurs in low-income countries (17%), whilst the other income groups have more of an even split: high income (26%), upper-middle income (30%) and lower-middle income (27%) (CRED 2015). However, the lowest number of fatalities from natural hazards occurs in the high-income group (13%), followed by upper-middle-income group (19%); conversely, the highest fatalities are in the lower-middle-income group (35%) and low-income group (33%) (CRED 2015). Therefore, it could be argued that low-income countries are disproportionately impacted by natural disasters, as with each disaster that occurs the community is severely impacted, causing the development of these countries to be broken by the cycle of recovery.
In terms of economic damage by country’s income group, the economic damage in absolute terms shows that high-income countries experience the largest losses (64%), followed by upper-middle-income countries (26%), whereas low-income countries experience much smaller (3%), followed by lower-middle-income countries (7%) (CRED 2015). Alternatively, if the economic damage is expressed as a percentage of GDP, then for the low-income countries the losses are the greatest (5.1%) compared to the lower-middle-income (0.2%), high-income (0.3%) and upper-middle-income country groups (0.6%) (CRED 2015). Therefore, it could be argued that again low-income countries are disproportionately impacted, as the disasters that occur result in funds being diverted to recovery efforts rather than allowing communities to continue developing; this can also compound debt problems for low-income countries.
4.2 What hazards are there?
Natural hazards are primarily categorised into either hydrological (e.g. flooding), geological (e.g. earthquakes), meteorological (e.g. cyclones) or climatological (e.g. drought). Other types of disasters do occur, and these are predominantly caused by human events, such as war and terrorism. There are also biological events, which are normally a result of nature but can also be caused or aggravated by human actions.
In terms of natural disasters, the disaster types occur in different proportions, affect different numbers of people, cause differing amounts of fatalities and incur different financial costs, as shown in Fig. 13a. The disaster types also affect infrastructure including housing, health facilities and schools differently (Fig. 13b). From these two figures, it is possible to draw several conclusions: hydrological events are the most frequent, geophysical hazards are the deadliest, hydrological events affect the greatest number of people and meteorological hazards are the costliest. In terms of damaged houses and health/school facilities, hydrological events are the worst, but for destroyed health and school facilities the worst is from meteorological events.

a Natural disaster types: global frequency of events, people affected by hazards and fatalities caused by different types—information taken from CRED (2015), b natural disaster types: global effects on infrastructure in terms of houses damaged and health and school facilities destroyed or damaged—information taken from CRED (2015)
4.3 Where are the disasters?
Natural disasters are experienced across the globe, with Asia experiencing the largest number of disasters followed by the Americas, and then Africa and Europe, and Oceania experiencing the smallest numbers (CRED 2015). In terms of specific countries, India, China, the USA and Philippines have each experienced the largest number of natural disasters, around 243–509 disasters across a 20-year period (CRED 2015).
The prevalence of natural disasters does not necessarily link to the financial impact of disasters. However, in absolute values the USA has experienced the largest financial impact due to natural disasters, followed by Japan and then China (CRED 2015) (Table 4). This shows that in some cases, the frequency of disasters impacts the level of financial toil. However, the disaster type (e.g. hydrological, meteorological or geophysical) has a greater impact on the likely financial cost. The disaster type also significantly contributes to the other impacts such as number of people affected and fatalities.
Financial damage can also be calculated as a percentage of a country’s GDP, which vastly changes the countries affected by financial hardship (Table 5). Korea Democratic People’s Republic has the largest proportion of economic losses in terms of GDP (38.9%), followed by Mongolia (33.9%) and Haiti (14.9%) (CRED 2015).
For the period 2000–2016, there were many high impact individual natural disasters; the costliest of these was the Tohoku earthquake in Japan (March 2011), with estimated damage of $210 billion, followed by Hurricane Katrina in the USA (August 2005) at $125 billion and then the Sichuan earthquake in China (May 2008) with costs of $85 billion (EM-DAT 2016a, b).
4.4 Governmental policy
Governmental policy can be a key driver for change across the globe. Examples of good policy practice can be used to drive forward changes in other nations as they strive to meet the benchmarks set out. In the UK, more effective disaster management has been driven through the Civil Contingences Act (2004), which provides a single framework for civil protection in the UK and introduces the duty to create Local Resilience Forums (LRFs) (Cabinet Office 2013). The LRFs have statutory duties as local authorities to prevent serious damage to their local communities. Each geographical area is based on police force boundaries and is “required to prepare to deliver an appropriate emergency response and to maintain normal services during a crisis” (Newcastle City Council 2014). To help this, risks need to be identified in each area, so community risk registers and frameworks have been set out (Northumbria Local Resilience Forum 2014; London Resilience Partnership 2017).
Once risks have been identified and management plans are in place, the validity of these plans needs to be tested to ensure they are adequate in dealing with the anticipated risks. Therefore, there is a requirement to run emergency planning scenarios. These are included within the Civil Contingencies Act, which states that Category 1 responders must include provision for carrying out exercises and training staff on their emergency plans (Cabinet Office and National Security and Intelligence 2013). Currently, three types of exercises are proposed: (1) discussion based, (2) tabletop and (3) live (Cabinet Office and National Security and Intelligence 2013). Discussion-based exercises are relatively cheap to run and easy to prepare so are often utilised for training purposes. Tabletop drills are based on scenarios, which are useful for validation purposes and exploring weaknesses, with low costs other than staff time, but more planning and preparation is required. Live exercises are a real-life simulation of an event, which is expensive to run, demands very extensive planning and can be disruptive to the general public. Currently, there is no provision to utilise computational modelling for planning and preparation. However, this could provide a more robust method for testing scenarios, allowing planners to test multiple runs without the resource and cost requirements. Previously, models would not have been capable of this but with the emergence of new techniques and additional computer power, it is now possible to test computationally.
The UK’s National Security Strategy states that “the security of our nation is the first duty of government” and that “it is the foundation of our freedom and our prosperity” (Cabinet Office and National Security and Intelligence 2010). Therefore, to supplement the Community Risk Registers produced by LRFs, the UK Government carries out a National Risk Assessment (NRA) annually. This is a classified document; however, the Government also produces an annual publically available version of this document, namely the National Risk Register (NRR) (Cabinet Office 2008). The NRA and NRR were first published in 2008 as a response to the National Security Strategy (Cabinet Office and National Security and Intelligence 2010) with the aim of capturing a range of emergencies that might have a substantial impact on all, or a significant part of the UK. These documents outline the larger, national picture of risks compared with the localised risks considered by the LRFs (Cabinet Office 2008). The 2008 NRR showed that the highest impact event was anticipated to be pandemic influenza, but that the most likely events were attacks on transport or electronic attacks, although the impacts were deemed to be smaller (Cabinet Office 2008). The most recent NRR was produced in 2015; this adapted the previous register and better quantified the likelihoods of risks and impacts, by indicating the relative likelihood of events occurring in the next five years such as “between 1 in 20 and 1 in 2”. The register was split into two parts: risks of terrorist or malicious attacks and other risks (Cabinet Office 2015). In terms of terrorist attacks, a catastrophic terrorist attack was seen as medium–low plausibility but had the highest impact, whereas cyber-attacks compromising data confidentiality are highly plausible but have low impact (Cabinet Office 2015). For the other risks, pandemic influenza has the highest impact and its relative likelihood of occurring in the next 5 years is between 1 in 20 and 1 in 2 (Cabinet Office 2015).
The USA, like the UK, is subjected to a number of natural and man-made hazards every year, for example in 2015 the USA experienced 28 recorded natural disasters with financial costs of approximately $21 billion (Guha-Sapir et al. 2016a, b), so there is a need to develop and improve disaster management strategies. The USA Department for Homeland Security has approached this by forming a national preparedness goal. This is set out as “a secure and resilient nation with the capabilities required across the whole community to prevent, protect against, mitigate, respond to, and recover from the threats and hazards that pose the greatest risk” (US Department of Homeland Security 2015), deeming a shared responsibility across the entire nation (FEMA 2015). Overall, FEMA’s mission can be described as ensuring “that as a nation we work together to build, sustain, and improve our capability to prepare for, protect against, respond to, recover from and mitigate all hazards” (FEMA 2017). The National Preparedness Goal is capability based, with 32 core capabilities (identified as part of a strategic national risk assessment), which are organised into five mission areas, namely prevention, protection, mitigation, response and recovery (US Department of Homeland Security 2015). This has been used to identify the types of threats that posed the greatest risk to the USA’s security, including natural, technological/accidental and adversarial/human-caused hazards. Currently, natural hazards, pandemic influenza, technological hazards, terrorism and cyber-attacks are classified as a significant risk to the USA in their strategic national risk assessment (US Department of Homeland Security 2015).
New Zealand is also susceptible to many natural hazards, including the Christchurch earthquake (February 2011), which caused 65 fatalities and $3 billion worth of damage (BBC 2011). Therefore, to reduce this vulnerability, risks categorised by type (e.g. geophysical, social and technological) have been identified and analysed by the Institution of Professional Engineers New Zealand (IPENZ), to enable measures to be put in place to either eliminate or reduce their impacts. This analysis covers the characteristics of hazards, in order to understand their relationship with national planning measures, which includes a range of likelihoods and consequences. The indicative risks show that cyber-attacks affecting data confidentiality are likely to occur at least once a year but are likely to have only minor consequences (Institution of Professional Engineers New Zealand (IPENZ) 2012), whereas a very large volcanic eruption is only likely to occur once in a millennium; however, the consequences would be considered catastrophic (Institution of Professional Engineers New Zealand (IPENZ) 2012). In particular, the IPENZ highlights that for natural hazards, each threat has a different profile, thereby suggesting that it is not appropriate to “lump together” all natural hazards and it would be more appropriate to target hazard-specific reduction measures to each individual hazard type. The national risk framework also incorporates the localised risks, with a risk exposure calculated for major settlements in New Zealand. This shows that any measures to mitigate natural hazards need to recognise the regional differences in terms of risk. New Zealand currently has a number of acts included in a regulatory framework, similar to the UK, including the Resource Management Act 1991, the Building Act 2004, the Civil Defence Emergency Management Act 2002, the Local Government Act 2002 and the Local Government Official Information and Meetings Act 1987 (Institution of Professional Engineers New Zealand (IPENZ) 2012). However, these acts are inconsistent with their definitions of natural hazards and do not include some important threats, and the range of restrictions to be imposed is limited (Institution of Professional Engineers New Zealand (IPENZ) 2012).
Despite the lack of recognition across the globe of the merits of computational modelling for disaster scenarios, the UK Government noted that “modelling and simulation techniques are important ways of enabling complex systems to be understood and manipulated in a virtual environment” (Council for Science and Technology (CST) 2009). As such, there is an understanding of the benefits of completing computational modelling from a government perspective. This commitment was shown through the recommendations made in “A National Infrastructure for the 21st Century” report (Council for Science and Technology (CST) 2009). Recommendation Three recommended “stimulating better understanding of the complexity and resilience of the national infrastructure, by commissioning research into scenario planning and modelling national infrastructure systems, from physical, economic and social perspectives” (Council for Science and Technology (CST) 2009), underlining the government’s commitment to facilitating the simulation and modelling of disaster management systems in natural hazard scenarios.
5 Conclusions and recommendations
This paper has carried out a bibliometric analysis in order to identify the main research themes and research gaps in the area of “natural hazards”, “disaster management” and “simulation” techniques (including agent based modelling). There is a need to determine whether research undertaken maps directly onto known disaster trends and government policy, such as frequency, location or impacts and perceived risks or if certain areas are being neglected, or “over researched”.
This analysis has shown that natural hazards (73%) are the primary focus of this type of research rather than man-made events (14%), which is to be anticipated as there are a larger number of recorded natural hazard events each year (Fig. 4a). This is observed in both the reviewed papers and case studies (where 95% focus on natural hazards). With respect to man-made hazards, the most common hazard is terrorism (83%); however, this was only observed in the research after the 9/11 terror attacks in the USA. This suggests that this high-profile event had a significant impact upon the research into man-made events, with a key focus of terrorism.
Within the reviewed papers, the most common disaster type is generic natural hazards (37%), which are covered more frequently than any one specific type (with hydrological (20%) being the highest recorded specific hazard type). The papers focusing on specific hazard types tie into the observed disaster trends, which show that over 90% of all natural disasters are climate related (CRED 2015), with 70% of these disaster events being storms or floods. This emphasises the need for these to be the predominant research topics.
The affected population for floods (55%) is the largest, which is followed by droughts (25%) that are considered climatological hazards. There is perhaps a lack of research into climatological hazards such as droughts or wildfires; considering the recent international climatological crisis in East Africa, it would appear timely to further research into this area. This drought crisis in East Africa and those experienced in other nations have been found to be linked with civil war (Maystadt and Ecker 2014; Couttenier and Soubeyran 2014). These hazards could be considered to be “multi-hazards” where two or more types of hazards occur simultaneously, or immediately after each other. Another example of “multi-hazards” is landslides which occur as a result of an earthquake or heavy rainfall event. These “multi-hazards” are not currently widely researched.
In general, it has been seen that the research is reactive rather than proactive. Despite numerous large scale disasters since the start of the twenty-first century, these events do not regularly appear in this set of papers [for example the Boxing Day Tsunami (December 2004), Hurricane Katrina (August 2005) or Great East Japan (Tohoku) Earthquake and Tsunami (March 2011)]. However, it is possible this could be attributed to the search algorithm utilised by Google Scholar, as a direct search for these events provides results from relevant papers. Many case study locations were in North America, which was also the primary location of the journal authors. Therefore, it can be assumed that this is a result of the availability of information and data, local knowledge or exposure to hazard types (e.g. past experiences) and also the closeness of location if field trips are required. As a result, there is less coverage of case studies in both Asia and Africa.
The result of this is that research is not necessarily covering areas known to be vulnerable to hazards and that suffer disproportionate impacts when they do occur. For example, Haiti and Nepal have suffered repeated events in the past few years [e.g. Haiti (January 2010) or Nepal (April 2015) and (May 2015)]. These communities could benefit considerably from research, especially in terms of long-term projects on rebuilding efforts (Kennedy et al. 2008) (Gadal 2016). The lack of research may be due to a lack, or perceived lack, of appropriate funding, available information and data, language barriers, or local knowledge and inputs. In the case of research to give policy recommendations, there may be difficulties implementing measures, resulting in research that does not maximise impact opportunities.
This study has also highlighted the disparity between a government’s perceived risks and those that are “well” researched. Biological hazards were only captured infrequently (2%), which is significantly lower than any of the other natural hazards. This is despite the fact that all of the government policies researched (including the UK, USA and New Zealand) emphasised the significant risk and severe impact of pandemic influenza for communities. It would therefore appear that, in this study, there is a large difference in opinion between researchers and policy-makers on the significant risks likely to affect countries. However, again it is possible this could be attributed to the search algorithm utilised by Google Scholar or the wider classification of biological hazards as natural disasters, as a quick direct search for pandemic influenza provides results from relevant papers (Cooper et al. 2006; Aledort et al. 2007; Colizza et al. 2007).
This study aimed to consider research within the field of agent based modelling that has been undertaken. Despite using the terms “simulation” and “agent based simulation”, the number of models and simulation techniques found in the search results was limited. There were no specific modelling techniques repeatedly shown as keywords. This suggests that agent based modelling for natural hazards and disaster management is still emerging, highlighting an opportunity for research to expand. It has also been demonstrated that although governments and policy-makers are beginning to realise the benefits of computational modelling, the uptake and demand are not yet significant and further progression in terms of policy could help encourage future research.
Our review of research to date has shown that disaster management is a rapidly expanding area of research. This study has shown that this increased research interest is primarily in response to disasters in the developed world. However, the disasters provoking much of the recent research are rare events, and hence there is a risk of not covering all potential threats. This suggests that current research efforts need to be supplemented with more research relating to threats to developing countries, multi-hazards and emerging hazards, such as space weather, as currently these are rarely included in papers, but are still credible threats.
The literature also shows that models are important tools for preparing risk reduction strategies for known threats and that current tools for this are lacking. For more uncertain threats, such as those mentioned above, lack of case study material makes models essential for developing scenarios and hazard mitigation strategies. Modelling techniques can also be advanced to improve natural hazard disaster management in general, and this will help to demonstrate to policy-makers the benefits of utilising computational models over the current less effective or costly testing methods such as tabletop or real-life simulation. These topics can be used to further drive forward disaster management and to provide benefits for communities across the globe.
References
Aka FT et al (2017) Disaster prevention, disaster preparedness and local community resilience within the context of disaster risk management in Cameroon. Nat Hazards 86(1):57–88
Aledort JE, Lurie N, Wasserman J, Bozzette SA (2007) Non-pharmaceutical public health interventions for pandemic influenza: an evaluation of the evidence base. BMC Public Health 7(208):1–9
Batty M, Crooks AT, See LM, Heppenstall AJ (2012) Chapter 1 perspectives on agent-based models and geographical systems. In: Batty M, Crooks AT, Heppenstall AJ, See LM (eds) Agent-based models of geographical systems. Springer, Dordrecht, pp 1–15
BBC (2011) New Zealand earthquake: 65 dead in Christchurch. http://www.bbc.co.uk/news/world-asia-pacific-12533291. Accessed 11 May 2017
BBC (2015) Major counter-terrorism exercise in London. http://www.bbc.co.uk/news/uk-33315691. Accessed 4 Jan 2017
Beake N (2017) BBC News—Met officers hold mock terrorism exercise on River Thames. http://www.bbc.co.uk/news/uk-england-london-39320168. Accessed 30 Mar 2017
Beel J, Gipp B (2009) Google Scholar‘s ranking algorithm: an introductory overview. Rio de Janeiro, Brazil. In: Proceedings of the 12th international conference on scientometrics and informetrics (ISSI’09)
Birkmann J et al (2010) Extreme events and disasters: a window of opportunity for change? Analysis of organizational, institutional and political changes, formal and informal responses after mega-disasters. Nat Hazards 55(3):637–655
Blanford CF (2016) Impact factors, citation distributions and journal stratification. J Mater Sci 51:10319–10322
Cabinet Office (2008) National risk register of civil emergencies. Cabinet Office, London
Cabinet Office (2013) Emergency response and recovery. https://www.gov.uk/guidance/emergency-response-and-recovery. Accessed 23 Nov 2016
Cabinet Office (2015) National risk register for civil emergencies. Cabinet Office, London
Cabinet Office and National Security and Intelligence (2010) The National Security Strategy—a strong Britain in an age of uncertainty. Cabinet Office, London
Cabinet Office and National Security and Intelligence (2013) Emergency planning and preparedness: exercises and training. https://www.gov.uk/guidance/emergency-planning-and-preparedness-exercises-and-training. Accessed 23 Nov 2016
Chappin EJL, Ligtvoet A (2014) Transition and transformation: a bibliometric analysis of two scientific networks researching socio-technical change. Renew Sustain Energy Rev 30:715–723
Chappin EJL, van der Lei T (2014) Adaptation of interconnected infrastructures to climate change: a socio-technical systems perspective. Util Policy 31:10–17
Colizza V et al (2007) Modelling the worldwide spread of pandemic influenza: baseline case and containment interventions. PLOS Med 4(1):95–110
Cooper BS, Pitman RJ, Edmunds WJ, Gay NJ (2006) Delaying the international spread of pandemic influenza. PLOS Med 3(6):845–855
Cosgrave J, Crawford N, Mosel I (2016) ODI—10 things to know about refugees and displacement. https://www.odi.org/publications/9916-10-things-know-about-refugees-and-displacement. Accessed 19 Dec 2016
Council for Science and Technology (CST) (2009) A National Infrastructure for the 21st Century. Council for Science and Technology, London
Couttenier M, Soubeyran R (2014) Drought and civil war in Sub-Saharan Africa. Econ J 121(575):201–244
CRED (2015) The human cost of natural disasters 2015—a global perspective. CRED and UNISDR, Brussels
Crooks AT, Castle CJE, Batty M (2008) Key challenges in agent-based modelling for geo-spatial simulation. Comput Environ Urban Syst 32(6):417–430
Cutter SL (2016) The landscape of disaster resilience indicators in the USA. Nat Hazards 80(2):741–758
D’Orazio M, Spalazzi L, Quagliarini E, Bernardini G (2014) Agent-based model for earthquake pedestrians’ evacuation in urban outdoor scenarios: behavioural patterns definition and evacuation paths choice. Saf Sci 62:450–465
Durage SW, Wirasinghe SC, Ruwanpura J (2013) Comparison of the Canadian and US Tornado Detection and Warning Systems. Nat Hazards 66(1):117–137
EM-DAT (2016) Disasters database—advanced search. http://www.emdat.be/advanced_search/index.html. Accessed 10 Mar 2017
EM-DAT (2016) EM-Dat frequently asked questions. http://www.emdat.be/frequently-asked-questions. Accessed 20 Dec 2016
FEMA (2015) Information sheet—National Preparedness Goal. Overview, 2nd edn. FEMA, Washington, DC
FEMA (2016) National Preparedness Goal. https://www.fema.gov/national-preparedness-goal. Accessed 20 Mar 2017
FEMA (2017) About the Agency—Mission. https://www.fema.gov/about-agency#
Forum Northumbria Local Resilience (2014) The Northumbria local resilience forum community risk register. Northumberland County Council, Morpeth
Gadal B (2016) Efforts of Nepal towards building a disaster resilient country. Oxfam—Disaster Risk Reduction and Humanitarian Program, Lalitpur
Glade T, Nadim F (2014) Early warning systems for natural hazards and risks. Nat Hazards 70(3):1669–1671
Glavovic BC, Saunders WSA, Becker JS (2010) Land-use planning for natural hazards in New Zealand: the setting, barriers, ‘burning issues’ and priority actions. Nat Hazards 54(3):679–706
Google Scholar (2018) About Google Scholar. https://scholar.google.com/scholar/about.html. Accessed 6 Jun 2018
Guha-Sapir D, Below R, Hoyois P (2016) EM-DAT: the CRED/OFDA International disaster database. http://www.emdat.be/database. Accessed 8 Dec 2016
Guha-Sapir D, Hoyois P, Below R (2016) Annual disaster statistical review 2015: the numbers and trends, Brussels: Centre for Research on the Epidemiology of Disasters (CRED)
Institution of Professional Engineers New Zealand (IPENZ) (2012) A Safer New Zealand—Reducing our exposure to natural hazards. IPENZ, Wellington
International Civil Defence Organisation (2016) Natural disasters/earthquakes. http://www.icdo.org/en/disasters/natural-disasters/earthquakes. Accessed 19 Dec 2016
Ismail-Zadeh A, Takeuchi K (2007) Preventative disaster management of extreme natural events. Nat Hazards 42(3):459–467
Kennedy J, Ashmore J, Babister E, Kelman I (2008) The meaning of ‘Build Back Better’: evidence from post-Tsunami Aceh and Sri Lanka. J Conting Crisis Manag 16(1):24–36
Laherrere J, Sornette D (1998) Stretched exponential distributions in nature and economy: “Fat Tails” with characteristic scales. Eur Phys J B 2:525–539
Lo SM, Wang WL, Liu SB, Ma J (2014) Using agent-based simulation model for studying fire escape process in metro stations. Proced Comput Sci 32:388–396
London Resilience Partnership (2017) London risk register. London Resilience, London
Lu Y, Xu J (2014) The progress of emergency response and rescue in China: a comparative analysis of Wenchuan and Lushan earthquakes. Nat Hazards 74(2):421–444
Markovic V et al (2016) Assessing drought and drought-related wildfire risk in Kanjiza, Serbia: the SEERISK methodology. Nat Hazards 80(2):709–726
Maystadt J-F, Ecker O (2014) Extreme weather and civil war: does drought fuel conflict in Somalia through livestock price shocks? Am J Agric Econ 96(4):1157–1182
Miao X, Banister D, Tang Y (2013) Embedding resilience in emergency resource management to cope with natural hazards. Nat Hazards 69(3):1389–1404
Newcastle City Council (2014) Resilient Newcastle. https://www.newcastle.gov.uk/environment-and-waste/emergencies/resilient-newcastle. Accessed 23 Nov 2016
Opdyke A, Javernick-Will A, Koschmann M (2017) Infrastructure hazard resilience trends: an analysis of 25 years of research. Nat Hazards 87(2):773–789
Paton E, Warrell H (2015) Financial times—Simulated terror attack to test London emergency services. https://www.ft.com/content/2e11646c-1ef9-11e5-ab0f-6bb9974f25d0. Accessed 4 Jan 2017
Peters J, Wood N, Wilson R, Miller K (2016) Intra-community implications of implementing multiple tsunami-evacuation zones in Alameda, California. Nat Hazards 84(2):975–995
Redner S (1998) How popular is your paper? An empirical study of the citation. Eur Phys J B 4:131–134
Sadiq A-A, Tharp K, Graham JD (2016) FEMA versus local governments: influence and reliance in disaster preparedness. Nat Hazards 82(1):123–138
Singh-Peterson L, Salmon P, Baldwin C, Goode N (2015) Deconstructing the Concept of shared responsibility for disaster resilience: a sunshine coast case study, Australia. Nat Hazards 79(2):755–774
UNISDR (2009) United Nations Office for Disaster Risk Reduction—Terminology. https://www.unisdr.org/we/inform/terminology. Accessed 28 Mar 2017
United Nations (2016) World Humanitarian Summit. https://www.worldhumanitariansummit.org/. Accessed 22 Dec 2016
US Department of Homeland Security (2015) National preparedness goal, 2nd edn. US Department of Homeland Security, Washington, DC
Wenzel F et al (2001) Potential of earthquake early warning systems. Nat Hazards 23(2):407–416
White B (2006) Examining the claims of Google Scholar as a serious information source. N Z Libr Inf Manag J 50:11–24
Wood NJ, Schmidtlein MC (2012) Anisotropic path modeling to assess pedestrian-evacuation potential from Cascadia-related tsunamis in the US Pacific Northwest. Nat Hazards 62(2):275–300
Wood N et al (2016) Pedestrian flow-path modeling to support tsunami evacuation and disaster relief planning in the U.S. Pacific Northwest. Int J Disaster Risk Reduct 18:41–55
Word Clouds (2017) Free online word cloud generator. http://www.wordclouds.com/. Accessed 1 Mar 2017
Zhong M et al (2008) Study of the human evacuation simulation of metro fire safety analysis in China. J Loss Prev Process Ind 21(3):287–298
Acknowledgements
This research was partly funded by the Engineering and Physical Sciences Research Council, UK (through a funded PhD studentship awarded to Barnes), and their support is gratefully acknowledged.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Electronic supplementary material
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Barnes, B., Dunn, S. & Wilkinson, S. Natural hazards, disaster management and simulation: a bibliometric analysis of keyword searches. Nat Hazards 97, 813–840 (2019). https://doi.org/10.1007/s11069-019-03677-2
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11069-019-03677-2