
Abstract
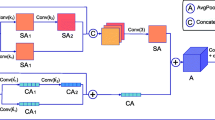
The receptive field of convolutional neural networks (CNNs) is focused on the local context, while the transformer receptive field is concerned with the global context. Transformers are the new backbone of computer vision due to their powerful ability to extract global features, which is supported by pre-training on extensive amounts of data. However, it is challenging to collect a large number of high-quality labeled images for the pre-training phase. Therefore, this paper proposes a classification network (CofaNet) that combines CNNs and transformer-based fused attention to address the limitations of transformers without pre-training, such as low accuracy. CofaNet introduces patch sequence dimension attention to capture the relationship among subsequences and incorporates it into self-attention to construct a new attention feature extraction layer. Then, a residual convolution block is used instead of multi-layer perception after the fusion attention layer to compensate for the limited feature extraction of the attention layer on small datasets. The experimental results on three benchmark datasets demonstrate that CofaNet achieves excellent classification accuracy when compared to some transformer-based networks without pre-traning.







Similar content being viewed by others


Data Availibility
CIFAR-10: https://www.cs.toronto.edu/~kriz/cifar.html, CIFAR-100: https://www.cs.toronto.edu/~kriz/cifar.html, Tiny ImageNet: https://tiny-imagenet.herokuapp.com
References
Long J, Shelhamer E, Darrell T (2015) Fully convolutional networks for semantic segmentation. In: Proceedings of the IEEE conference on computer vision and pattern recognition (CVPR), pp 3431–3440. https://doi.org/10.1109/CVPR.2015.7298965
Zhou Y, Zheng X, Ouyang W, et al (2022) A strip dilated convolutional network for semantic segmentation. Neural Process Lett 1–21. https://doi.org/10.1007/s11063-022-11048-5
Xiang X, Meng F, Lv N, et al (2022) Engineering vehicles detection for warehouse surveillance system based on modified yolov4-tiny. Neural Process Lett 1–17. https://doi.org/10.1007/s11063-022-10982-8
Ren S, He K, Girshick R, et al (2015) Faster r-cnn: towards real-time object detection with region proposal networks. Adv Neural Inf Process Syst (NeurIPS) 28
Dosovitskiy A, Beyer L, Kolesnikov A, et al (2020) An image is worth 16x16 words: transformers for image recognition at scale. In: Proceedings of international conference on learning representations (ICLR)
Sun C, Shrivastava A, Singh S, et al (2017) Revisiting unreasonable effectiveness of data in deep learning era. In: Proceedings of the IEEE international conference on computer vision (ICCV), pp 843–852. https://doi.org/10.1109/ICCV.2017.97
Liu Z, Lin Y, Cao Y, et al (2021) Swin transformer: hierarchical vision transformer using shifted windows. In: Proceedings of the IEEE international conference on computer vision (ICCV), pp 10012–10022. https://doi.org/10.1109/ICCV48922.2021.00986
Krizhevsky A, Hinton G et al (2009) Learning multiple layers of features from tiny images. ON, Canada, Toronto
Le Y, Yang X (2015) Tiny imagenet visual recognition challenge. CS 231N 7(7):3
Krizhevsky A, Sutskever I, Hinton GE (2017) Imagenet classification with deep convolutional neural networks. Commun ACM 6(60):84–90. https://doi.org/10.1145/3065386
Simonyan K, Zisserman A (2015) Very deep convolutional networks for large-scale image recognition. In: Proceedings of international conference on learning representations (ICLR)
Szegedy C, Liu W, Jia Y, et al (2015) Going deeper with convolutions. In: Proceedings of the IEEE conference on computer vision and pattern recognition (CVPR), pp 1-9. https://doi.org/10.1109/CVPR.2015.7298594
Ioffe S, Szegedy C (2015) Batch normalization: accelerating deep network training by reducing internal covariate shift. In: Proceedings of the international conference on machine learning (ICML), pp 448–456
Szegedy C, Vanhoucke V, Ioffe S, et al (2016) Rethinking the inception architecture for computer vision. In: Proceedings of the IEEE conference on computer vision and pattern recognition (CVPR), pp 2818-2826. https://doi.org/10.1109/CVPR.2016.308
Szegedy C, Ioffe S, Vanhoucke V, et al (2017) Inception-v4, inception-resnet and the impact of residual connections on learning. In: Proceedings of the AAAI conference on artificial intelligence, 31(1)
He K, Zhang X, Ren S, et al (2016) Deep residual learning for image recognition. In: Proceedings of the IEEE conference on computer vision and pattern recognition (CVPR), pp 770-778. https://doi.org/10.1109/CVPR.2016.90
Xie S, Girshick R, Dollár P, et al (2017) Aggregated residual transformations for deep neural networks. In: Proceedings of the IEEE conference on computer vision and pattern recognition (CVPR), pp 5987-5995. https://doi.org/10.1109/CVPR.2017.634
Huang G, Liu Z, Van Der Maaten L, et al (2017) Densely connected convolutional networks. In: Proceedings of the IEEE conference on computer vision and pattern recognition (CVPR), pp 2261-2269. https://doi.org/10.1109/CVPR.2017.243
Ding X, Zhang X, Ma N, et al (2021) Repvgg: Making vgg-style convnets great again. In: Proceedings of the IEEE conference on computer vision and pattern recognition (CVPR), pp 13728-13737. https://doi.org/10.1109/CVPR46437.2021.01352
Liu Z, Mao H, Wu CY, et al (2022) A convnet for the 2020s. In: Proceedings of the IEEE conference on computer vision and pattern recognition (CVPR), pp 11966-11976. https://doi.org/10.1109/CVPR52688.2022.01167
Tan M, Le Q (2019) Efficientnet: Rethinking model scaling for convolutional neural networks. In: Proceedings of the international conference on machine learning (ICML), pp 6105–6114
Hu J, Shen L, Sun G (2018) Squeeze-and-excitation networks. In: Proceedings of the IEEE conference on computer vision and pattern recognition (CVPR), pp 7132-7141. https://doi.org/10.1109/CVPR.2018.00745
Wang Q, Wu B, Zhu P, et al (2020) Eca-net: Efficient channel attention for deep convolutional neural networks. In: Proceedings of the IEEE conference on computer vision and pattern recognition (CVPR), pp 11531-11539. https://doi.org/10.1109/CVPR42600.2020.01155
Woo S, Park J, Lee JY, et al (2018) Cbam: Convolutional block attention module. In: Proceedings of the european conference on computer vision (ECCV), pp 3–19
Li X, Wang W, Hu X, et al (2019) Selective kernel networks. In: Proceedings of the IEEE conference on computer vision and pattern recognition (CVPR), pp 510-519. https://doi.org/10.1109/CVPR.2019.00060
Guo MH, Lu CZ, Hou Q, et al (2022) Segnext: Rethinking convolutional attention design for semantic segmentation. Preprint at arXiv:2209.08575
Zhu B, Hofstee P, Lee J, et al (2021) An attention module for convolutional neural networks. In: Proceedings of 30th international conference on artificial neural networks, Bratislava, Slovakia, pp 167-168. https://doi.org/10.1007/978-3-030-86362-3_14
Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Adv Neural Inf Process Syst (NeurIPS) 30
Devlin J, Chang MW, Lee K, et al (2018) Bert: pre-training of deep bidirectional transformers for language understanding. In: Proceedings of the conference on empirical methods in natural language processing (EMNLP)
Brown T, Mann B, Ryder N et al (2020) Language models are few-shot learners. Adv Neural Inf Process Syst (NeurIPS) 33:1877–1901
Russakovsky O, Deng J, Su H et al (2015) Imagenet large scale visual recognition challenge. Int J Comput Vis 115:211–252
Touvron H, Cord M, Douze M, et al (2021) Training data-efficient image transformers & distillation through attention. In: Proceedings of the international conference on machine learning (ICML), pp 10347–10357
Yuan L, Chen Y, Wang T, et al (2021) Tokens-to-token vit: Training vision transformers from scratch on imagenet. In: Proceedings of the IEEE international conference on computer vision (ICCV), pp 538-547. https://doi.org/10.1109/ICCV48922.2021.00060
Han K, Xiao A, Wu E et al (2021) Transformer in transformer. Adv Neural Inf Process Syst (NeurIPS) 34:15908–15919
Yuan K, Guo S, Liu Z, et al (2021) Incorporating convolution designs into visual transformers. In: Proceedings of the IEEE international conference on computer vision (ICCV), pp 559-568. https://doi.org/10.1109/ICCV48922.2021.00062
Srinivas A, Lin TY, Parmar N, et al (2021) Bottleneck transformers for visual recognition. In: Proceedings of the IEEE conference on computer vision and pattern recognition (CVPR), pp 16514-16524. https://doi.org/10.1109/CVPR46437.2021.01625
Guo J, Han K, Wu H, et al (2022) Cmt: Convolutional neural networks meet vision transformers. In: Proceedings of the IEEE conference on computer vision and pattern recognition (CVPR), pp 12165-12175. https://doi.org/10.1109/CVPR52688.2022.01186
Li J, Xia X, Li W, et al (2022) Next-vit: Next generation vision transformer for efficient deployment in realistic industrial scenarios. Preprint at arXiv:2207.05501v4
Funding
This work was supported in part by the National Natural Science Foundation of China under Grant 62001236, in part by the Natural Science Foundation of the Jiangsu Higher Education Institutions of China under Grant 20KJA520003, in part by the Six Talent Peaks Project of Jiangsu Province under Grant JY-051.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The author declares that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Jiang, J., Xu, H., Xu, X. et al. Transformer-Based Fused Attention Combined with CNNs for Image Classification. Neural Process Lett 55, 11905–11919 (2023). https://doi.org/10.1007/s11063-023-11402-1
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11063-023-11402-1