
Abstract
A novel method, called Opposite Maps, is introduced with the aim of generating reduced sets for efficiently training of support vector machines (SVM) and least squares support vector machines (LSSVM) classifiers. The main idea behind the proposed approach is to train two vector quantization (VQ) algorithms (one for each class, \({\fancyscript{C}}_{-1}\) and \({\fancyscript{C}}_{+1}\), in a binary classification context) and then, for the patterns of one class, say \({\fancyscript{C}}_{-1}\), to find the closest prototypes among those belonging to the VQ algorithm trained with patterns of the other class, say \({\fancyscript{C}}_{+1}\). The subset of patterns mapped to the selected prototypes in both VQ algorithms form the reduced set to be used for training SVM and LSSVM classifiers. Comprehensive computer simulations using synthetic and real-world datasets reveal that the proposed approach is very efficient and independent of the type of VQ algorithm used.




Similar content being viewed by others
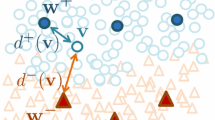

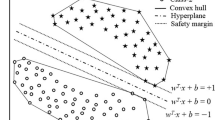
Notes
Karush–Kuhn–Tucker systems.
References
Amorim RC, Mirkin B (2012) Minkowski metric, feature weighting and anomalous cluster initializing in K-means clustering. Pattern Recognit 45:1061–1075
Balczar JL, Dai Y, Watanabe O (2001) A random sampling technique for training support vector machines. In: Proceedings of the 12th international conference on algorithmic learning theory (ALT’01), pp 119–134
Blachnik M, Kordos M (2011) Simplifying SVM with weighted LVQ algorithm. In: Proceedings of the 12th international conference on intelligent data engineering and automated learning IDEAL’2011. Springer, pp 212–219
Burges CJC (1996) Simplified support vector decision rules. In: Proceedings of the 13th international conference on machine learning (ICML’96). Morgan Kaufmann, pp 71–77
Carletta J (1996) Assessing agreement on classification tasks: the kappa statistic. Comput Linguist 22(2):249–254
Carvalho BPR, Braga AP (2009) IP-LSSVM: a two-step sparse classifier. Pattern Recognit Lett 30:1507–1515
Cohen JA (1960) Coefficient of agreement for nominal scales. Educ Psychol Meas 20(1):37–46
D’Amato L, Moreno JA, Mujica R (2004) Reducing the complexity of kernel machines with neural growing gas in feature space. In: Proceedings of the IX Ibero-American artificial intelligence conference (IBERAMIA’04), vol LNAI-3315. Springer, pp 799–808
Downs T, Gates KE, Masters A (2002) Exact simplification of support vector solutions. J Mach Learn Res 2:293–297
Fritzke B (1995) A growing neural gas network learns topologies. Advances in neural information processing systems 7. MIT Press, Cambridge, pp 625–632
Fung G, Mangasarian OL (2001) Proximal support vector machine classifiers. In: Provost F, Srikant R (Eds) Proceedings of the 7th ACM SIGKDD international conference on knowledge discovery and data mining (KDD’01), pp 77–86
Geebelen D, Suykens JAK, Vandewalle J (2012) Reducing the number of support vectors of SVM classifiers using the smoothed separable case approximation. IEEE Trans Neural Netw Learn Syst 23(4): 682–688
Girolami M (2002) Mercer kernel-based clustering in feature space. IEEE Trans Neural Netw 13(3): 780–784
Hoegaerts L, Suykens JAK, Vandewalle J, De Moor B (2004) A comparison of pruning algorithms for sparse least squares support vector machines. In: Proceedings of the 11th international conference on neural information processing (ICONIP’04), pp 22–25
Hussain A, Shahbudin S, Husain H, Samad SA, Tahir NM (2008) Reduced set support vector machines: application for 2-dimensional datasets. In: Proceedings of the 2nd international conference on signal processing and communication systems (ICSPCS’08), pp 1–4
Jin B, Zhang Y-Q (2006) Classifying very large data sets with minimum enclosing ball based support vector machine. In: Proceedings of 2006 IEEE international conference on fuzzy systems, pp 364–368
Kanungo T, Mount DM, Netanyahu NS, Piatko CD, Silverman R, Wu AY (2002) An efficient k-means clustering algorithm: analysis and implementation. IEEE Trans Pattern Anal Mach Intell 24(7):881–892
Koggalage R, Halgamuge S (2004) Reducing the number of training samples for fast support vector machine classification. Neural Inf Process Lett Rev 2(3):57–65
Kohonen T (1990) The self-organizing map. Proc IEEE 78(9):1464–1480
Kohonen T (2003) Learning vector quantization. In: Arbib MA (ed) The handbook of brain theory and neural networks. MIT Press, Cambridge, pp 631–635
Kohonen TK (1997) Self-organizing maps. Springer, Berlin
Lee Y-J, Mangasarian OL (2001) SSVM: a smooth support vector machine for classification. Comput Optim Appl 20(1):5–22
Li Y, Lin C, Zhang W (2006) Improved sparse least-squares support vector machine classifiers. Neurocomputing 69:1655–1658
Linda O, Manic M (2009) GNG-SVM framework—classifying large datasets with support vector machines using growing neural gas. In: Proceedings of the IEEE international joint conference on, neural networks (IJCNN’2009), pp 1820–1826
MacQueen JB (1967) Some methods for classification and analysis of multivariate observations. In: Proceedings of 5th Berkeley symposium on mathematical statistics and probability, vol 1. University of California Press, Berkeley, pp 281–297
Mangasarian OL (2000) Generalized support vector machines. In: Schölkopf B, Smola AJ, Bartlett P, Schuurmans D (eds) Advances in large margin classifiers. MIT Press, Cambridge, pp 135–146
Nguyen GH, Phung S, Bouzerdoum A (2010) Efficient SVM training with reduced weighted samples. In: Proceedings of the 2010 IEEE World congress on, computational intelligence (WCCI’2010), pp 1764–1768
Pedreira CE (2006) Learning vector quantization with training data selection. IEEE Trans Pattern Anal Mach Intell 28(1):157–162
Peres RT, Pedreira CE (2009) Generalized risk zone: selecting observations for classification. IEEE Trans Pattern Anal Mach Intell 31(7):1331–1337
Platt JC (1999) Fast training of support vector machines using sequential minimal optimization. In: Advances in Kernel methods—support vector learning. MIT Press, Cambridge
Steinwart I (2003) Sparseness of support vector machines. J Mach Learn Res 4:1071–1105
Suykens JAK, Lukas L, Vandewalle J (2000) Sparse least squares support vector machine classifiers. In: Proceedings of the 8th European symposium on artificial, neural networks (ESANN’00), pp 37–42
Suykens JAK, Vandewalle J (1999) Least squares support vector machine classifiers. Neural Process Lett 9(3):293–300
Tang B, Mazzoni D (2006) Multiclass reduced-set support vector machines. In: Proceedings of the 23rd international conference on, machine learning (ICML’2006), pp 921–928
Thies T, Weber F (2004) Optimal reduced-set vectors for support vector machines with a quadratic kernel. Neural Comput 16(9):1769–1777
Tong S, Koller D (2001) Support vector machine active learning with applications to text classification. J Mach Learn Res 2:45–66
Vapnik VN (1998) Statistical learning theory. Wiley-Interscience, New York
Wang J, Neskovic P, Cooper LN (2007) Selecting data for fast support vector machines training. In: Shen K, Wang L (eds) Trends in neural computation, vol 35 of studies in computational intelligence (SCI). Springer, Berlin, pp 61–84
Xiong S-W, Niu X-X, Liu H-B (2005) Support vector machines based on substractive clustering. In: Proceedings of 2005 international conference on machine learning and cybernetics ,vol 7. pp 4345–4350
Yu H, Yang J, Han J (2003) Classifying large data sets using SVM with hierarchical clusters. In: Proceedings of the 9th ACM SIGKDD international conference on knowledge discovery and data mining (KDD’03). pp 306–315
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Neto, A.R.R., Barreto, G.A. Opposite Maps: Vector Quantization Algorithms for Building Reduced-Set SVM and LSSVM Classifiers. Neural Process Lett 37, 3–19 (2013). https://doi.org/10.1007/s11063-012-9265-6
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11063-012-9265-6