
Abstract
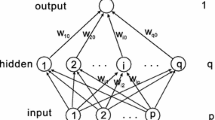
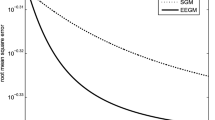
In this paper, a batch gradient algorithm with adaptive momentum is considered and a convergence theorem is presented when it is used for two-layer feedforward neural networks training. Simple but necessary sufficient conditions are offered to guarantee both weak and strong convergence. Compared with existing general requirements, we do not restrict the error function to be quadratic or uniformly convex. A numerical example is supplied to illustrate the performance of the algorithm and support our theoretical finding.
Similar content being viewed by others

References
Rumelhart DE, McClelland JL, The PDP Research Group: (1986) Parallel distributed processing-explorations in the microstructure of cognition. MIT Press, Cambridge
Meybodi MR, Beigy H (2002) A note on learning automata-based schemes for adaptation of BP parameters. Neurocomputing 48: 957–974
Qiu G, Varley MR, Terrell TJ (1992) Accelerated training of backpropagation networks by using adaptive momentum step. IEE Electron Lett 28(4): 377–379
Istook E, Martinez T (2002) Improved backpropagation learning in nerural networks with windowed momentum. Int J Neural Syst 12(3–4): 303–318
Chan LW, Fallside F (1987) An adaptive training algorithm for backpropagation networks. Comput Speech Lang 2: 205–218
Yu X, Loh NK, Miller WC (1993) A new acceleration technique for the backpropagation algorithm. IEEE Int Conf Neural Netw 3: 1157–1161
Yu C, Liu B (2002) A backpropagation algorithm with adaptive learning rate and momentum coefficient. IEEE Int Conf Neural Netw 2: 1218–1223
Shao HM, Zheng GF (2009) A new BP algorithm with adaptive momentum for FNNs training. WRI Glob Congr Intell Syst 4: 16–20
Bhaya A, Kaszkurewicz E (2004) Steepest descent with momentum for quadratic functions is a version of the conjugate gradient method. Neural Netw 17: 65–71
Torii M, Hagan MT (2002) Stability of steepest descent with momentum for quadratic functions. IEEE Trans Neural Netw 13(3): 752–756
Zhang NM, Wu W, Zheng GF (2006) Convergence of gradient method with momentum for two-layer feedforward neural networks. IEEE Trans Neural Netw 17(2): 522–525
Wu W, Xu YS (2002) Deterministic convergence of an online gradient method for neural networks. J Comput Appl Math 144(1–2): 335–347
Zhang C, Wu W, Xiong Y (2007) Convergence analysis of batch gradient algorithm for three classes of sigma-pi neural networks. Neural Process Lett 26: 177–189
Xu DP, Zhang HS, Liu LJ (2010) Convergence analysis of three classes of split-complex gradient algorithms for complex-valued recurrent neural networks. Neural Comput 22(10): 2655–2677
Yuan YX, Sun WY (2001) Optimization theory and methods. Science Press, Beijing
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Shao, H., Xu, D. & Zheng, G. Convergence of a Batch Gradient Algorithm with Adaptive Momentum for Neural Networks. Neural Process Lett 34, 221–228 (2011). https://doi.org/10.1007/s11063-011-9193-x
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11063-011-9193-x