
Abstract
Fact-based visual question answering aims at answer questions about images with the help of external knowledge, but understanding the comprehensive semantics of images and text is more challenging than understanding the semantics of text alone. Most existing methods do not take full advantage of the information included in the knowledge graph, which makes it difficult to comprehensively consider the information of all modals in the process of reasoning. In this article, we propose a question guided multi-modal receptive field reasoning network, which expands the receptive field of image to the text and knowledge graph. Specifically, our pattern generates a clue from images and text at each inference step. Subsequently, clues are introduced into the attention’s operator to perform explicit and implicit reasoning on the knowledge graph. We will divide the reasoning process into three steps, first encoding the image to identify objects that match the text and scoring them. There is one more point, using the object with the highest score as a clue, the relationships included in the text are picked-up. In the end, use the relationships and objects obtained from the first two steps as clues to retrieve the matching triplets in the knowledge graph. This manner can provide a more precise answer to the question. Without using the Pretrained model, our model improved its performance on the ‘FVQA’ and ‘ZSFVQA’ datasets by 1.74% and 0.41%. Our research provides a novel method for future multi-modal retrieval using knowledge graphs. Our code is available at https://github.com/ZuoZicheng/QuMuQA







Similar content being viewed by others
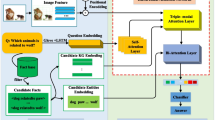
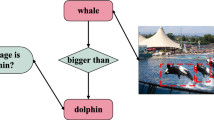

Availability of Supporting Data
The datasets generated during and/or analysed during the current study are available in the github repository, https://github.com/ZuoZicheng/QuMuQA.
References
Anderson P, JM Fernando B (2016) Spice: semantic propositional image caption evaluation. European Conf Comput Vis, 382–398
Ben-Younes H, TN Cadene R (2019) Block: bilinear superdiagonal fusion for visual question answering and visual relationship detection. Proc AAAI Conf Art Intell 33:8102–8109
Wang P, SC Wu Q (2017) Fvqa: fact-based visual question answering. IEEE Trans Pattern Anal Mach Intell 40:2413–2427
Narasimhan M, SA Lazebnik S (2018) Out of the box: reasoning with graph convolution nets for factual visual question answering. Adv Neural Inf Process Syst 31
Ding Y, Yu J, Liu B, Hu Y, Cui M, Wu Q (2022) Mukea: multimodal knowledge extraction and accumulation for knowledge-based visual question answering. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (CVPR), pp 5089–5098
Zheng W, Yan L, Zhang W, Wang F-Y (2023) Webly supervised knowledge-embedded model for visual reasoning. IEEE Trans Neural Netw Learn Syst, 1–15
Antol S, LJ Agrawal A (2015) Vqa: visual question answering. In: Proceedings of the IEEE international conference on computer vision, pp 2425–2433
Wang J, Dong Y (2021) Improve visual question answering based on text feature extraction. J Phys: Conf Series 1856:012025
Shih K J, HD Singh S (2016) Where to look: focus regions for visual question answering. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 4613–4621
Malinowski M, FM Rohrbach M (2015) Ask your neurons: a neural-based approach to answering questions about images. In: Proceedings of the IEEE international conference on computer vision, pp 1–9
Zhu Z, WY Yu J (2020) Mucko: multi-layer cross-modal knowledge reasoning for fact-based visual question answering. 2006–09073
Shao Z, Han J, Marnerides D, Debattista K (2022) Region-object relation-aware dense captioning via transformer. IEEE Trans Neural Netw Learn Syst, 1–12
Chu F, Cao J, Shao Z, Pang Y (2022) Illumination-guided transformer-based network for multispectral pedestrian detection. In: Fang L, Povey D, Zhai G, Mei T, Wang R (eds) Artificial intelligence. Springer, Cham, pp 343–355
Yu J, WY Zhu Z (2020) Cross-modal knowledge reasoning for knowledge-based visual question answering. Pattern Recognit 108:107563
Marino K, PD Chen X (2021) Krisp: integrating implicit and symbolic knowledge for open-domain knowledge-based vqa. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 14111–14121
Liu Y, Guo Y, Yin J, Song X, Liu W, Nie L, Zhang M (2022) Answer questions with right image regions: a visual attention regularization approach. ACM Trans Multimed Comput Commun Appl (TOMM) 18:1–18
Zhan X, Huang Y, Dong X, Cao Q, Liang X (2022) Pathreasoner: explainable reasoning paths for commonsense question answering. Knowl-Based Syst 235:107612
Li X, Wu B, Song J, Gao L, Zeng P, Gan C (2022) Text-instance graph: exploring the relational semantics for text-based visual question answering. Pattern Recognit 124:108455
Nawaz HS, Shi Z, Gan Y, Hirpa A, Dong J, Zheng H (2022) Temporal moment localization via natural language by utilizing video question answers as a special variant and bypassing nlp for corpora. IEEE Trans Circuits Syst Video Technol 32:6174–6185
Sharma H, Jalal AS (2022) A framework for visual question answering with the integration of scene-text using phocs and fisher vectors. Expert Syst Appl 190:116159
Yan L, Ma S, Wang Q, Chen Y, Zhang X, Savakis A, Liu D (2022) Video captioning using global-local representation. IEEE Trans Circuits Syst Video Technol 32(10):6642–6656
Yan L, Han C, Xu Z, Liu D, Wang Q (2023) Prompt learns prompt: exploring knowledge-aware generative prompt collaboration for video captioning. In: Proceedings of the thirty-second international joint conference on artificial intelligence. IJCAI ’23
Cai L, Fang H, Li Z (2023) Pre-trained multilevel fuse network based on vision-conditioned reasoning and bilinear attentions for medical image visual question answering. J Supercomput, 1–28
Li L, CY Gan Z (2019) Relation-aware graph attention network for visual question answering. In: Proceedings of the IEEE/CVF international conference on computer vision, pp 10313–10322
Gardères F, AB Ziaeefard M (2020) Conceptbert: concept-aware representation for visual question answering. Find Assoc Comput Linguist, 489–498
Wu J, SA Lu J (2022) Multi-modal answer validation for knowledge-based vqa. Proc AAAI Conf Artif Intell 36:2712–2721
Yang Z, GJ He X (2016) Stacked attention networks for image question answering. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 21–29
He K, RS Zhang X (2016) Deep residual learning for image recognition. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 770–778
Chen Z, GY Chen J (2021) Zero-shot visual question answering using knowledge graph. International Semantic Web Conference, 146–162
Farazi MR, Khan SH, Barnes N (2020) From known to the unknown: transferring knowledge to answer questions about novel visual and semantic concepts. Image Vis Comput 103:103985
Mikolov T, Chen K, Corrado G, Dean J (2013) Efficient estimation of word representations in vector space. arXiv:1301.3781
Speer R, HC Chin J (2017) Conceptnet 5.5: an open multilingual graph of general knowledge. Thirty-first AAAI conference on artificial intelligence
Tandon N, SF De Melo G (2014) Webchild: harvesting and organizing commonsense knowledge from the web. In: Proceedings of the 7th ACM international conference on Web search and data mining, pp 523–532
Pennington J, MCD Socher R (2014) Glove: global vectors for word representation. In: Proceedings of the 2014 conference on empirical methods in natural language processing, pp 1532–1543
Lu J, BD Yang J (2016) Hierarchical question-image co-attention for visual question answering. Adv Neural Inf Process Syst 77
Kim JH, ZBT Jun J (2018) Bilinear attention networks. Adv Neural Inf Process Syst 31
Funding
This research was supported by the National Social Science Foundation of China (19BYY076).
Author information
Authors and Affiliations
Contributions
Zicheng Zuo: Conceptualization, methodology, validation, writing - original draft. Yanhan Sun, Zhenfang Zhu, Mei Wu and Hui Zhao: Writing - review, editing and supervision.
Corresponding author
Ethics declarations
Ethical Approval
Not Applicable.
Competing Interests
We declare that we have no financial and personal relationships with other people or organizations that can inappropriately influence our work, there is no professional or other personal interest of any nature or kind in any product, service and/or company that could be construed as influencing the position presented in, or the review of, the manuscript entitled “Question Guided Multimodal Receptive Field Reasoning Network for Fact-based Visual Question Answering”.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Zuo, Z., Sun, Y., Zhu, Z. et al. Question guided multimodal receptive field reasoning network for fact-based visual question answering. Multimed Tools Appl (2024). https://doi.org/10.1007/s11042-024-19387-2
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1007/s11042-024-19387-2