
Abstract
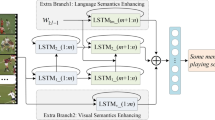
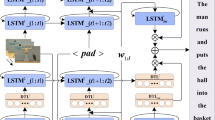
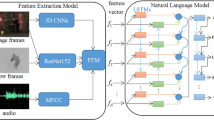
Video description is to translate video into natural language with appropriate sentence patterns and decent words. The task is challenging due to the great semantic gap between visual content and language. Nowadays, many well-designed models are developed. However, the language information is often insufficiently discovered and cannot be effectively integrated with visual representation, leading to that the correlations of vision and language are difficult to be constructed. Inspired by the process of human learning and cognition for vision and language, a deep collaborative cognition of vision and language based model (VL-DCC) is proposed in this work. In detail, an extra language encoding branch is designed and integrated with the visual motion encoding branch based on sequence to sequence pipeline during model learning, to simulate the process of human learning visual information and language. Additionally, a double VL-DCC (DVL-DCC) framework is developed to further improve the quality of generated sentences, where the element-wise addition and feature concatenation operation are employed and implemented on two different VL-DCC modules respectively to comprehensively capture visual and language semantics. Experiments on MSVD and MSR-VTT2016 datasets are conducted to evaluate the proposed model, and better results are achieved compared with the baseline model and other popular works, with the CIDEr reaching to 81.3 and 46.7 on the two datasets respectively.







Similar content being viewed by others
Data Availability
The datasets generated during and/or analysed during the current study are available in the [MSVD and MSR-VTT2016] repository, [“http://www.cs.utexas.edu/users/ml/clamp/videoDescription/YouTubeClips.tar”, and “https://www.mediafire.com/folder/h14iarbs62e7p/shared”].
References
Bai Y, Wang JY, Long Y, Hu BZ, Song Y, Pagnucco M, Guan Y (2021) Discriminative latent semantic graph for video captioning. In: ACM international conference on multimedia, pp 3556–3564
Ballas N, Yao L, Pal C, Courville A (2016) Delving deeper into convolutional networks for learning video representations. In: International conference on learning representations, pp 1–11
Banerjee S, Lavie A (2005) METEOR: an automatic metric for MT evaluation with improved correlation with human judgments. In: Annual meeting of the association for computational linguistics workshop, pp 65–72
Baraldi L, Costantino G, Rita C (2017) Hierarchical boundary-aware neural encoder for video captioning. In: IEEE conference on computer vision and pattern recognition, pp 3185–3194
Bin Y, Yang Y, Shen F, Xie N, Shen H, Li X (2019) Describing video with attention based bidirectional lstm. IEEE Trans Cybern 49 (7):2631–2641
Chen DL, Dolan WB (2011) Collecting highly parallel data for paraphrase evaluation. In: The 49th annual meeting of the association for computational linguistics, pp 190–200
Chen S, Jiang YG (2019) Motion guided spatial attention for video captioning. In: AAAI conference on artificial intelligence, pp 8191–8198
Chen J, Pan Y, Li Y, Yao T, Chao H, Mei T (2019) Temporal deformable convolutional encoder-decoder networks for video captioning. In: AAAI conference on artificial intelligence, pp 8167–8174
Chen Y, Wang S, Zhang W, Huang Q (2018) Less is more: picking informative frames for video captioning. In: European conference on computer vision, pp 367–384
Deb T, Sadmanee A, Bhaumik KK, Ali AA, Amin MA, Rahman AKMM (2022) Variational stacked local attention networks for diverse video captioning. In: IEEE winter conference on applications of computer vision, pp 4070–4079
Gan Z, Gan C, He X, Pu Y, Tran K, Gao J, Carin L, Deng L (2017) Semantic compositional networks for visual captioning. In: IEEE conference on computer vision and pattern recognition, pp 5630–5639
Gao L, Guo Z, Zhang H, Xu X, Shen HT (2017) Video captioning with attention-based lstm and semantic consistency. IEEE Trans Multimed 19 (9):2045–2055
Gao LL, Li XP, Song JK, Shen HT (2020) Hierarchical LSTMs with adaptive attention for visual captioning. IEEE Trans Pattern Anal Mach Intell 42(5):1112–1131
Guadarrama S, Krishnamoorthy N, Malkarnenkar G, Venugopalan S, Mooney R, Darrell T, Saenko K (2013) YouTube2Text: recognizing and describing arbitrary activities using semantic hierarchies and zero-shot. In: Proceedings of the IEEE international conference on computer vision, pp 2712–2719
Guo YY, Zhang JQ, Gao LL (2019) Exploiting long-term temporal dynamics for video captioning. World Wide Web 22(2):735–749
Gupta A, Srinivasan P, Shi J, Davis LS (2009) Understanding videos, constructing plots learning a visually grounded storyline model from annotated videos. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 2012–2019
He K, Zhang X, Ren S, Sun J (2016) Deep residual learning for image recognition. In: IEEE conference on computer vision and pattern recognition, pp 770–778
Hou J, Wu X, Zhao W, Luo J, Jia Y (2019) Joint syntax representation learning and visual cue translation for video captioning. In: International conference on computer vision, pp 8918–8927
Jia Y, Shelhamer E, Donahue J, Karayev S, Long J, Girshick R et al (2014) Caffe: convolutional architecture for fast feature embedding. In: ACM conference on multimedia, pp 675–678
Kojima A, Tamura T, Fukunaga K (2002) Natural language description of human activities from video images based on concept hierarchy of actions. Int J Comput Vis 50(2):171–184
Krizhevsky A, Sutskever I, Hinton GE (2012) Imagenet classification with deep convolutional neural networks. In: Annual conference on neural information processing systems, pp 1097–1105
Lin TY, Maire M, Belongie S, Hays J, Perona P, Ramanan D, Dollr P, Zitnick CL (2014) Microsoft coco: common objects in context. In: European conference on computer vision, pp 740–755
Lin CY, Och FJ (2004) Automatic evaluation of machine translation quality using longest common subsequence and skip-bigram statistics. In: Annual meeting of the association for computational linguistics, pp 21–26
Long X, Gang C, Melo G (2018) Video captioning with multi-faceted attention. Trans Assoc Computat Ling 6:173–184
Nagel H-H (1994) A vision of “vision and language” comprises action: an example from road traffic. Artif Intell Rev 8(2):189–214
Nakamura K, Ohashi H, Okada M (2021) Sensor-augmented egocentric-video captioning with dynamic modal attention. In: ACM international conference on multimedia, pp 4220–4229
Pan BX, Cai HY, Huang DA, Lee KH, Gaidon A, Adeli E, Niebles JC (2020) Spatio-temporal graph for video captioning with knowledge distillation. In: IEEE conference on computer vision and pattern recognition, pp 10870–10879
Pan Y, Mei T, Yao T, Li H, Rui Y (2016) Jointly modeling embedding and translation to bridge video and language. In: IEEE conference on computer vision and pattern recognition, pp 4594–4602
Pan P, Xu Z, Yang Y, Wu F, Zhuang Y (2016) Hierarchical recurrent neural encoder for video representation with application to captioning. In: IEEE conference on computer vision and pattern recognition, pp 1029–1038
Papineni K, Roukos S, Ward T, Zhu WJ (2002) BLEU: a method for automatic evaluation of machine translation. In: Annual meeting of the association for computational linguistics, pp 311–318
Pei W, Zhang J, Wang X, Ke L, Shen X, Tai YW (2019) Memory-attended recurrent network for video captioning. In: IEEE conference on computer vision and pattern recognition, pp 8347–8356
Ramanishka V, Abir D, Huk PD, Subhashini V, Anne HL, Marcus R, Kate S (2016) Multimodal video description. In: ACM conference on multimedia conference, pp 1092–1096
Ren S, He K, Girshick R, Sun J (2017) Faster r-cnn: towards real-time object detection with region proposal networks. IEEE Trans Pattern Anal Mach Intell 39(06):1137–1149
Ryu H, Kang S, Kang H, Yoo CD (2021) Semantic grouping network for video captioning. In: AAAI conference on artifical intelligence, pp 1–9
Song YQ, Chen SZ, Jin Q (2021) Towards diverse paragraph captioning for untrimmed videos. In: IEEE conference on computer vision and pattern recognition, pp 11245–11254
Song J, Guo Y, Gao L, Li X, Alan H, Shen HT (2019) From deterministic to generative: multimodal stochastic rnns for video captioning. IEEE Trans Neural Netw Learn Syst 30(10):3047–3058
Song J, Guo Z, Gao L, Liu W, Zhang D, Shen H-T (2017) Hierarchical LSTM with adjusted temporal attention for video captioning. In: International joint conference on artificial intelligence, pp 2737–2743
Szegedy C, Liu W, Jia Y, Sermanet P, Reed S, Anguelov D, Erhan D, Vanhoucke V, Rabinovich A (2015) Going deeper with convolutions. In: IEEE conference on computer vision and pattern recognition, pp 1–9
Tang P, Wang H, Li Q (2019) Rich visual and language representation with complementary semantics for video captioning. ACM Trans Multimed Comput Commun Appl 15(2:31):1–23
Tang PJ, Xia JW, Tan YL, Tan B (2020) Double-channel language feature mining based model for video description. Multimed Tools Appl 79:33193–33213
Vedantam R, Zitnick CL, Parikh D (2015) CIDEr: consensus-based image description evaluation. In: IEEE conference on computer vision and pattern recognition, pp 4566–4575
Venugopalan S, Hendricks LA, Mooney R, Saenko K (2016) Improving lstm-based video description with linguistic knowledge mined from text. In: Conference on empirical methods in natural language processing, pp 1961–1966
Venugopalan S, Rohrbach M, Donahue J, Mooney R, Darrell T, Saenko K (2015) Sequence to sequence-video to text. In: IEEE international conference on computer vision, pp 4534–4542
Venugopalan S, Xu H, Donahue J, Rohrbach M, Mooney R, Saenko K (2015) Translating videos to natural language using deep recurrent neural networks. In: The 2015 annual conference of the north american chapter of the ACL, pp 1494–1504
Wang X, Chen W, Wu J, Wang YF, Wang WY (2018) Video captioning via hierarchical reinforcement learning. In: IEEE conference on computer vision and pattern recognition, pp 4213–4222
Wang B, Ma L, Zhang W, Liu W (2018) Reconstruction network for video captioning. In: IEEE conference on computer vision and pattern recognition, pp 7622–7631
Wang J, Wang W, Huang Y, Wang L, Tan T (2018) M3: multimodal memory modelling for video captioning. In: IEEE conference on computer vision and pattern recognition, pp 7512–7520
Wang T, Zhang RM, Lu ZC, Zheng F, Cheng R, Luo P (2021) End-to-end dense video vaptioning with parallel decoding. In: IEEE international conference on computer vision, pp 4847–6857
Xu K, Ba JL, Kiros R, Cho K, Courville A, Salakhutdinov R, Zemel RS, Bengio Y (2015) Show, attend and tell: neural image caption generation with visual attention. In: International conference on machine learning, pp 2048–2057
Xu J, Mei T, Yao T, Rui Y (2016) MSR-VTT: a large video description dataset for bridging video and language. In: IEEE conference on computer vision and pattern recognition, pp 5288–5296
Xu J, Yao T, Zhang Y, Mei T (2017) Learning multimodal attention LSTM networks for video captioning. In: ACM conference on multimedia, pp 537–545
Xu WR, Yu J, Miao ZJ, Wang LL, Tian Y, Ji Q (2020) Deep reinforcement polishing network for video captioning. IEEE Trans Multimed 23:1772–1784
Yang Y, Zhou J, Ai J, Bin Y, Hanjalic A, Shen H (2018) Video captioning by adversarial lstm. IEEE Trans Image Process 27(11):5600–5611
Yao L, Torabi A, Cho K, Ballas N, Pal C, Larochelle H, Courville A (2015) Describing videos by exploiting temporal structure. In: IEEE international conference on computer vision, pp 4507–4515
Yu Y, Ko H, Choi J, Kim G (2017) End-to-end concept word detection for video captioning, retrieval, and question answering. In: IEEE conference on computer vision and pattern recognition, pp 3261–3269
Yu H, Wang J, Huang Z, Yang Y, Xu W (2016) Video paragraph captioning using hierarchical recurrent neural networks. In: IEEE conference on computer vision and pattern recognition, pp 4584–4593
Zhang W, Wang B, Ma L, Liu W (2019) Reconstruct and represent video contents for captioning via reinforcement learning. IEEE Trans Pattern Anal Mach Intell 42(12):3088–3101
Acknowledgements
This work was supported in part by National Natural Science Foundation of China (No. 62062041, 62141203), Jiangxi Provincial Natural Science Foundation (No. 20212BAB202020), Scientific Research Foundation of Education Bureau of Jiangxi Province (No. GJJ211009), and Ph.D. Research Initiation Project of Jinggangshan University (No. JZB1923, JZB1807).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Ethics approval
This article does not contain any study with human participants performed by any of the authors.
Consent to participate
Informed consent was obtained from all individual participants included in the study.
Conflict of Interests
All authors declare that they have no conflict of interest with other people or organizations.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Tang, P., Tan, Y. & Xia, J. Deep sequential collaborative cognition of vision and language based model for video description. Multimed Tools Appl 82, 36207–36230 (2023). https://doi.org/10.1007/s11042-023-14887-z
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11042-023-14887-z