
Abstract
The advent of advanced in-vehicle sensors and communication technologies have facilitated the collection of large volume and almost real-time data on vehicles and drivers. Processing and analyzing this data provides unprecedented opportunities to offer remarkable insights and solutions for driving behavior detection. Characterizing driving behavior plays a key role in a variety of research areas such as traffic safety, the development of autonomous driving, and risk assessment. In this research, a novel framework, Multi-scale Space-time TRansformer (MSTR) is proposed for driving behavior detection using multi-modal data, i.e. front view video frames and vehicle signals. In particular, a multi-patch architecture is explored to capture driving scene features generated from different scales. Meanwhile, a Multi-patch Space-time Attention (MSA) module is designed for MSTR to model multi-scale features and capture spatial-temporal correlation simultaneously. Moreover, the extracted vehicle dynamics features are used as auxiliary to improve the robustness of detection, and a customized Cross-Modal Fusion (CMF) module is introduced to integrate these two different modality features efficiently. Finally, we experimentally validate the efficiency of our approach on a naturalistic driving data set containing over 2800 maneuvers recorded. The MSTR achieves state-of-the-art results with a low inference cost when compared to 3D convolutional networks, and it performs superior to a number of Transformer-based models and other advanced detection methods.








Similar content being viewed by others


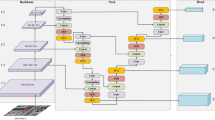
Data availability
The raw/processed data required to reproduce these findings cannot be shared at this time as the data also forms part of an ongoing study.
References
Akai N, Hirayama T, Morales LY et al (2019) Driving behavior modeling based on hidden markov models with driver’s eye-gaze measurement and ego-vehicle localization. IEEE intelligent vehicles symposium. IEEE, pp 949–956
Arnab A, Dehghani M, Heigold G et al (2021) Vivit: a video vision transformer. Proceedings of the IEEE/CVF international conference on computer vision, pp 6836–6846
Bertasius G, Wang H, Torresani L (2021) Is space-time attention all you need for video understanding? arXiv:2102.05095
Bulat A, Perez Rua JM, Sudhakaran S et al (2021) Space-time mixing attention for video transformer. Advances in neural information processing systems, 34
Cai Z, Fan Q, Feris RS, et al (2016) A unified multi-scale deep convolutional neural network for fast object detection. European conference on computer vision, pp 354–370
Carion N, Massa F, Synnaeve G et al (2020) End-to-end object detection with transformers. European conference on computer vision, pp 213–229
Carreira J, Zisserman A (2017) Quo vadis, action recognition? a new model and the kinetics dataset. Proceedings of the IEEE conference on computer vision and pattern recognition, pp 6299–6308
Chen LC, Papandreou G, Kokkinos I, Murphy K, Yuille AL (2017) Deeplab: semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans Pattern Anal Mach Intell 40(4):834–848
Deng Q, Wang J, Hillebrand K, Benjamin CR, Soffker D (2019) Prediction performance of lane changing behaviors: a study of combining environmental and eye-tracking data in a driving simulator. IEEE Trans Intell Transp Syst 21:3561–3570
Devlin J, Chang M W, Lee K et al (2018) BERT: pre-training of deep bidirectional transformers for language understanding. arXiv:1810.04805
Díaz-Álvarez A, Clavijo M, Jiménez F, Talavera E, Serradilla F (2018) Modelling the human lane-change execution behaviour through multilayer perceptrons and convolutional neural networks. Transport Res F: Traffic Psychol Behav 56:134–148
Dosovitskiy A, Beyer L, Kolesnikov A et al (2020) An image is worth 16x16 words: transformers for image recognition at scale. arXiv: 2010.11929
Fan H, Xiong B, Mangalam K et al (2021) Multiscale vision transformers. Proceedings of the IEEE/CVF international conference on computer vision, pp 6824–6835
Feichtenhofer C, Fan H, Malik J, et al (2019) Slowfast networks for video recognition. Proceedings of the IEEE/CVF international conference on computer vision, pp 6202–6211
Gao J, Murphey YL, Zhu HH (2019) Personalized detection of lane changing behavior using multisensor data fusion. Computing 101(12):1837–1860
Gao J, Yi JG, Murphey YL (2021) Joint learning of video images and physiological signals for lane-changing behavior prediction. Transp A: Transp Sci 18(3):1234–1253. https://doi.org/10.1080/23249935.2021.1936279
Gao J, Murphey YL, Yi JG et al (2022) A data-driven lane-changing behavior detection system based on sequence learning. Transp B: Transp Dyn 10(1):831–848
Ghiasi G, Lin TY, Le QV (2019) Nas-fpn: learning scalable feature pyramid architecture for object detection. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 7036–7045
Hong J, Sapp B, Philbin J (2019) Rules of the road: predicting driving behavior with a convolutional model of semantic interactions. Proc IEEE Conf Comput Vis Pattern Recognit:8454–8462
Huang G, Liu Z, Van Der Maaten L et al (2017) Densely connected convolutional networks. Proceedings of the IEEE conference on computer vision and pattern recognition, pp 4700–4708
Lin T Y, Dollár P, Girshick R et al (2017) Feature pyramid networks for object detection. Proceedings of the IEEE conference on computer vision and pattern recognition, pp 2117–2125
Lin T Y, Goyal P, Girshick R et al (2017) Focal loss for dense object detection. Proceedings of the IEEE international conference on computer vision, pp 2980–2988
Liu Y, Ott M, Goyal N et al (2019) Roberta: a robustly optimized bert pretraining approach. arXiv:1907.11692
Liu L, Jiang H, He P et al (2019) On the variance of the adaptive learning rate and beyond. arXiv:1908.03265
Liu Z, Ning J, Cao Y et al (2021) Video swin transformer. arXiv:2106.13230
Murphey YL, Wang K, Molnar LJ, Eby DW, Giordani B, Persad C, Stent S (2021) Development of data mining methodologies to advance knowledge of driver behaviors in naturalistic driving. SAE Int J Transp Saf 8(2):77–94
Newell A, Yang K, Deng J (2016) Stacked hourglass networks for human pose estimation. European conference on computer vision, pp 483–499
Peng X, Liu R, Murphey YL et al (2018) Driving behavior detection via sequence learning from vehicle signals and video images. 24th international conference on pattern recognition, pp 1265–1270
Ramanishka V, Chen Y T, Misu T et al (2018) Toward driving scene understanding: a dataset for learning driver behavior and causal reasoning. Proceedings of International Conference on Computer Vision and Pattern Recognition, pp 7699–7707
Rueckauer B, Lungu IA, Hu Y, Pfeiffer M, Liu SC (2017) Conversion of continuous-valued deep networks to efficient event-driven networks for image classification. Front Neurosci 11:682
Sevilla-Lara L, Zha S, Yan Z et al (2021) Only time can tell: discovering temporal data for temporal modeling. Proceedings of the IEEE/CVF winter conference on applications of computer vision, pp 535–544
Simonyan K, Zisserman A (2014) Very deep convolutional networks for large-scale image recognition. arXiv:1409.1556
Sun K, Xiao B, Liu D et al (2019) Deep high-resolution representation learning for human pose estimation. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 5693–5703
Szegedy C, Liu W, Jia Y et al (2015) Going deeper with convolutions. Proceedings of the IEEE conference on computer vision and pattern recognition, pp 1–9
Szegedy C, Vanhoucke V, Ioffe S et al (2016) Rethinking the inception architecture for computer vision. Proceedings of the IEEE conference on computer vision and pattern recognition, pp 2818–2826
Szegedy C, Ioffe S, Vanhoucke V, Alemi A (2017) Inception-v4, inception-resnet and the impact of residual connections on learning. Thirty-first AAAI conference on artificial intelligence, vol 31
Touvron H, Cord M, Douze M et al (2021) Training data-efficient image transformers & distillation through attention. International conference on machine learning, pp 10347–10357
Vaswani A, Shazeer N, Parmar N et al (2017) Attention is all you need. Advances in neural information processing systems, pp 5998–6008
Wang W, Xie E, Li X et al (2021) Pyramid vision transformer: a versatile backbone for dense prediction without convolutions. arXiv:2102.12122
Wang W, Zhou S, Li J, et al. (2021) Temporal pulses driven spiking neural network for time and power efficient object recognition in autonomous driving. 25th international conference on pattern recognition, pp 6359–6366
Wang QH, Wang LN, Xu S (2021) Research and application of spiking neural network model based on LSTM structure. Appl Res Comput 38(5):1381–1386
Xie DF, Fang ZZ, Jia B, He Z (2019) A data-driven lane-changing model based on deep learning. Transp Res Part C Emerg Technol 106:41–60
Xie J, Hu K, Li G, Guo Y (2021) CNN-based driving maneuver classification using multi-sliding window fusion. Expert Syst Appl 169:114442
Xu H, Das A, Saenko K (2017) R-c3d: region convolutional 3d network for temporal activity detection. Proceedings of the IEEE international conference on computer vision, pp 5783–5792
Yang F, Yang H, Fu J et al (2020) Learning texture transformer network for image super-resolution. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 5791–5800
Yang S, Gao T, Wang J et al (2021) Efficient spike-driven learning with dendritic event-based processing. Front Neurosci 15:97
Zhao H, Shi J, Qi X et al (2017) Pyramid scene parsing network. Proceedings of the IEEE conference on computer vision and pattern recognition, pp 2881–2890
Zhou B, Lapedriza A, Xiao J et al (2014) Learning deep features for scene recognition using places database. Adv Neural Inf Proces Syst 27
Zhu X, Su W, Lu L et al (2020) Deformable DETR: deformable transformers for end-to-end object detection. arXiv: 2010.04159
Acknowledgments
This research is supported by the Wuhan Science and Technology Bureau (2022010801020380), State Key Laboratory of Precision Blasting (PBSKL2022302) and Jianghan University (2021yb148).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
No potential conflict of interest is reported by the authors.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Gao, J., Yi, J. & Murphey, Y.L. Multi-scale space-time transformer for driving behavior detection. Multimed Tools Appl 82, 24289–24308 (2023). https://doi.org/10.1007/s11042-023-14499-7
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11042-023-14499-7