
Abstract
Automatic Speaker Verification (ASV) systems are vulnerable to spoofing attacks. Most existing spoofing detection systems rely on two main points; the feature extraction and the classification methodology. In this paper, we propose a new strategy to recognize the veritable discourse from the spoofed one. The thought depends on the investigation of the human voice to identify the relevant acoustic and glottal features. Those features will be utilized to separate between a veritable discourse and a spoofed one. We have tested numerous of speech acoustic and glottal flow features from all data sets of ASVspoof challenge 2015 and ASVspoof challenge 2017. Several features are extracted and analyzed to choose the most pertinent ones using feature engineering methodology. To detect the genuine speech from the spoofed one, conventional machine learning techniques are applied as classification techniques mainly Support Vector Machine (SVM) and eXtreme Gradient Boosting (XGBoost). Features exploration and analysis leads to pick up pertinent ones. These features are used then as input for the SVM with multiple kernel and for XGBoost classification techniques. The highest rate of achieving accuracy is about 98.80% obtained with the XGBoost classification technique. Experimental results show the validity and the robustness of the proposed method.










Similar content being viewed by others

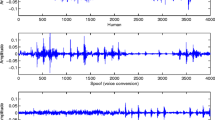
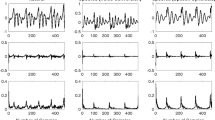
References
Alam M, Kenny P, Bhattacharya G, Stafylakis T (2015) Development of CRIM system for the automatic speaker verification spoofing and countermeasures challenge interspeech
Amin l, Shantanu Ch (2011) An overview of statistical pattern recognition techniques for speaker verification. IEEE Circ Syst Mag 11(2):62–81
Ben Ayed Mezghani D, Zribi Boujelbene S, Ellouze N (2010) Evaluation of SVM kernels and conventional machine learning algorithms for speaker identification. Int J Hybrid Inf Technol 3:3
Bhattacharyya D, Ranjan R, Alisherov F, Choi AM (2009) Biometric Authentication:, a review, International Journal of u-and e-Service. Sci Technol 2:3
Cemal H, Figen E (2011) Impact of voice excitation features on speaker verification. ELECO 7th International Conference on Electrical and Electronics Engineering, pp 157–160
Chen T, Guestrin C (2016) XGBOost: A Scalable Tree Boosting System. Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pp 785–794
Chen N, Qiany D, Chen H, YuK B (2015) Robust deep feature for spoofing detection-the SJTU system for ASVspoof 2015 challenge. 16th Annual Conference of the International Speech Communication Association interspeech, pp 2097–2101
Chen Z, Xie Z, Zhang W, Xu X (2017) Resnet and model fusion for automatic spoofing detection, interspeech, pp 102-106
Chennoukh S, Gerrits A, GMiet R (2001) Sluijter, Speech enhancement via frequency bandwidth extension using line spectral frequencies, acoustics, speech, and signal processing, 2001 international conference on acoustics. Speech Sign Process 1:665–668
Childers DG (1995) Glottal source modeling for voice conversion. Speech Comm 16(2):127–138
Chow D, Abdulla WH (2004) Speaker identification based on log area ratio and gaussian mixture models in Narrow-Band speech. PRICAI, pp 901–908
Cummings KE, Clements MA (1995) Analysis of the glottal excitation of emotionally styled and stressed speech. J Acoust Soc Am 98(1):88–98
Dave N (2013) Feature Extraction Methods LPC, PLP and MFCC In Speech Recognition, international journal for advance research in engineering and technology
De Leon PL, Apsingekar VR, Pucher M, Yamagishi J (2010) Revisiting the security of speaker verification systems against imposture using synthetic speech. IEEE Signal Processing Society, pp 1798–1801
Drugman T, Thomas M, Gudnason J, Naylor P, Dutoit T (2012) Detection of glottal closure instants from speech signals: A quantitative review. IEEE Trans Audio Speech Lang Process 20(3):994–1006
Duraibi S, Alhamdani W, Sheldon FT (2020) Voice Feature Learning using Convolutional Neural Networks Designed to Avoid Replay Attacks. IEEE Symposium Series on Computational Intelligence, pp 1845–1851
EBENUWA SH, SHARIF MH, ALAZAB M, AL-NEMRAT SAEED A (2019) Variance ranking attributes selection techniques for binary classification problem in imbalance data. IEEE Access 7:24649–24666
Estévez PA, Tesmer M, Perez CA, Zurada JM (2009) Normalized mutual information feature selection. IEEE Trans Neural Netw 20(2):189–201
Fang F, Yamagishi J, Echizen I, Sahidullah MD, Kinnunen T (2018) Transforming acoustic characteristics to deceive playback spoofing countermeasures of speaker verification systems. IEEE International Workshop on Information Forensics and Security, pp 1–9
Font R, Espin JM, Cano MJ (2017) Experimental analysis of features for replay attack detection–Results on the ASVspoof. Chall Interspeech 7-11:2017
H YU Z, Y ZHANG ZMA, GUO J (2017) DNN Filter bank cepstral coefficients for spoofing detection. IEEE Access, pp 4779–4787
Ji Z, Li Z, Li P, An M, Gao S, Wu D, Zhao F (2017) Ensemble learning for countermeasure of audio replay spoofing attack in ASVspoof2017. Interspeech 2017:87–91
Kim On CH, Pandiyan PM, Yaacob S, Saudi A (2006) Mel-Frequency Cepstral coefficient analysis in speech recognition international conference on computing & informatics
Kinnunen T, Sahidullah M, Delgado H, Todisco M, Evans N, Yamagishi J, Lee A (2017) The ASVspoof. Challenge:, Assess Limits Replay Spoofing Attack Detect Interspeech 2-6:2017
Kinnunen T, Zhang B, Zhu J, Wang Y (2007) Speaker Verification with Adaptive Spectral Subband Centroids, international conference on Advances in Biometrics, pp 58–66
Lavrentyeva G, Novoselov S, Tseren A, Volkova M, Gorlanov A (2019) A Kozlov, STC antispoofing systems for the ASVspoof2019 challenge, interspeech, pp 1033–1037
Novoselov S, Kozlov A, Lavrentyeva G, Simonchik K, Shchemelinin V (2016) STC Antispoofing systems for the ASVspoof 2015 challenge. IEEE international conference on acoustics speech and signal processing, pp 5475–5479
Novoselov S, Kozlov A, Lavrentyeva G, Simonchik K, Shchemelinin V (2016) STC Antispoofing systems for the ASVspoof 2015 challenge, IEEE International Conference on Acoustics Speech and Signal Processing (ICASSP)
Patel T (2015) Patil, Combining evidences from mel cepstral, cochlear filter cepstral and instantaneous frequency features for detection of natural vs. spoofed speech interspeech 16th Annual Conference of the International Speech Communication Association
Patil H, Kamble M, Patel T, Soni M (2017) Novel variable length teager energy separation based instantaneous frequency features for replay detection, interspeech, pp 12–16
Paul D, Sahidullah Md, Saha G (2017) Generalization of spoofing coutermeasures : A case study with ASVSPOOF 2015 and BTAS 2016 corpora, IEEE International Conference on Acoustics. Speech and Signal Processing, pp 2047–2051
Rahmeni R, Aicha AB, Ben Ayed Y (2019) Speech spoofing countermeasures based on source voice analysis and machine learning techniques, pp 668–675
Rahmeni R, Aicha AB, Ben Ayed Y (2020) Speech spoofing detection using SVM and ELM technique with acoustic features, pp 1–4
Rahmeni R, Aicha AB, Ben Ayed Y (2020) Acoustic features exploration and examination for voice spoofing counter measures with boosting machine learning techniques, pp 1073–1082
Rosenberg AE (1976) Automatic speaker verification: a review. Proc IEEE 64(4):475–487
Satoh T, Masuko T, Kobayashi T, Tokuda K (2001) A Robust Speaker Verification System against Imposture Using an HMM-based Speech Synthesis System. Eurospeech, pp 759–762
Satoh T, Masuko T, Kobayashi T, Tokuda K (2001) A robust speaker verification system against imposture using a HMM-based speech synthesis system. Eurospeech, pp 759–762
Scholkopf B, Smola AJ (2001) Learning with kernels: support vector machines, regularization, optimization, and beyond MIT press
Sheridan RP, Min Wang W, Liaw A, Ma J, Gifford EM (2016) Extreme gradient boosting as a method for quantitative Structure–Activity relationships. J Chem Inf Model 56(12):2353–2360
Sin Chee L, Chia Ai O, Hariharan M, Yaacob S (2009) Automatic detection of prolongations and repetitions using LPCC. International Conference for Technical Postgraduates, pp 1–4
Sri Rama Murty K, Yegnanarayana B (2006) Combining evidence from residual phase and MFCC features for speaker recognition. IEEE Sign Process Lett 13(1):52–55
Todisco M, Delgado H, Evans N (2016) A new feature for automatic speaker verification anti-spoofing: constant q cepstral coefficients odyssey
Viswanathan R, Makhoul J (1975) Quantization properties of transmission parameters in linear predictive systems. IEEE Trans Acoustic Speech Sign Process 23(3):309–321
Williams ChKI (2003) Learning with kernels: support vector machines, regularization, optimization, and beyond. J Am Stat Assoc 98(462):489–489
Witkowski M, Kacprzak S, Zelasko P, Kowalczyk K, Gałka J (2017) Audio Replay Attack Detection Using High-Frequency Features, interspeech, pp 27–31
Wu Z, Evans N, Kinnunen T, Yamagishi J, Alegre F, Li H (2014) Spoofing and countermeasures for speaker verification: a survey. Speech Comm 66:130–153
Xiao X, Tian X, Du S, Xu H, Chng ES, Haizhou L (2015) Spoofing Speech Detection Using High Dimensional Magnitude and Phase Features:, the NTU Approach for ASVspoof 2015 Challenge, interspeech, pp 2052–2056
Xiao X, Tian X, Du S, Xu H, Chng E, Li H (2015) Spoofing speech detection using high dimensional magnitude and phase features: the NTU approach for ASVspoof 2015 challenge Interspeech
Yu L, Liu H (2003) Feature selection for High-Dimensional data: a fast Correlation-Based filter solution, machine learning. Proceedings of the Twentieth International Conference, pp 856–863
Yu B, Qiu W, Chen Ch, Ma A, Jiang J, Zhou H, Ma Q (2020) Submito-XGBoost: predicting protein submitochondrial localization by fusing multiple feature information and eXtreme gradient boosting. Bioinformatics 36 (4):1074–1081
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of Interests
The authors declare that they have no conflict of interest.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Rahmeni, R., Aicha, A.B. & Ayed, Y.B. Voice spoofing detection based on acoustic and glottal flow features using conventional machine learning techniques. Multimed Tools Appl 81, 31443–31467 (2022). https://doi.org/10.1007/s11042-022-12606-8
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11042-022-12606-8