
Abstract
Objectives In this large scale, mixed methods evaluation, we determined the impact and context of early childhood home visiting on rates of child abuse-related injury. Methods Entropy-balanced and propensity score matched retrospective cohort analysis comparing children of Pennsylvania Nurse–Family Partnership (NFP), Parents As Teachers (PAT), and Early Head Start (EHS) enrollees and children of Pennsylvania Medicaid eligible women from 2008 to 2014. Abuse-related injury episodes were identified in medical assistance claims with ICD-9 codes. Weighted frequencies and logistic regression odds of injury within 24 months are presented. In-depth interviews with staff and clients (n = 150) from 11 programs were analyzed using a modified grounded theory approach. Results The odds of a healthcare encounter for early childhood abuse among clients were significantly greater than comparison children (NFP: 1.32, 95% CI [1.08, 1.62]; PAT: 4.11, 95% CI [1.60, 10.55]; EHS: 3.15, 95% CI [1.41, 7.06]). Qualitative data illustrated the circumstances of and program response to client issues related to child maltreatment, highlighting the role of non-client caregivers. All stakeholders described curricular content aimed at prevention (e.g. positive parenting) with little time dedicated to addressing current or past abuse. Clients who reported a lack of abuse-related content supposed their home visitor’s assumption of an absence of risk in their home, but were supportive of the introduction of abuse-related content. Approach, acceptance, and available resources were mediators of successfully addressing abuse. Conclusions for Practice Home visiting aims to prevent child abuse among high-risk families. Adequate home visitor capacity to proactively assess abuse risk, deliver effective preventive curriculum with fidelity to caregivers, and access appropriate resources is necessary.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Significance Statement
What is already known on this topic? Reducing child maltreatment is a public health priority. At present, home visiting represents the primary available prevention strategy for child maltreatment; however, evaluations of home visiting success on this outcome have been varied.
What does this study add? Our mixed methods evaluation pairs a large administrative dataset that allows us to measure child abuse outcomes reliably across multiple home visiting programs with qualitative interviews with key stakeholders to demonstrate and explore home visiting’s impact on child maltreatment. We find no evidence of positive program effects but identify explanatory implementation factors potentially limiting program effectiveness.
Introduction
Child maltreatment is a serious public health problem (Children’s Bureau 2016) resulting in innumerable short and long-term health consequences including trauma, adverse physical and mental/behavioral health, changes to brain architecture and development, challenges to educational achievement, and reduced social-emotional functioning and relational attachment (Deutsch et al. 2015; Merrick and Latzman 2014). Unfortunately, prevention is challenging to achieve in public health programming, in part due to the level of support needed to overcome risk factors and bolster protective factors for families and communities (Agran et al. 2003; Frioux et al. 2014; Wood et al. 2012). Early childhood maltreatment prevention programs (i.e. home visitation) intervene at a critical period when children are most at risk (Schatz and Lounds 2007) and promote prevention though strengthening protective factors within a family and connecting families with community services. Programs teach approaches to child rearing, decreasing parental stress, provide guidance on reducing childhood hazard exposures, and serve a monitoring function for identifying and responding to maltreatment (Gomby et al. 1999).
Inconclusive and at times conflicting clinical trials and post-implementation studies regarding home visiting’s impact on child maltreatment rates have highlighted the need for further attention and evaluation (Institute of Medicine and National Research Council 2014; Rubin et al. 2014). The varied success in reducing child maltreatment necessitates further investigation into the conditions under which home visiting programs can achieve prevention, and for whom (Howard and Brooks-Gunn 2009).
Early results from home visiting evaluations suggested efficacy in decreasing child maltreatment. Notably, a randomized controlled trial of the Nurse–Family Partnership (NFP) resulted in 80% fewer injury and ingestion-related doctor visits in intervention group (though non-significant at 2 years) (Olds et al. 1994). However, following wide-scale replication of evidence-based home visiting programs, data are limited in supporting the effectiveness in preventing abuse (Matone et al. 2012). A 2013 review of home visitation programs found two programs reduced long-term child maltreatment reports or death contrasted by four other randomized trials showing no associated effect of home visitation on child maltreatment reports (Nelson et al. 2013; Rubin et al. 2014).
As home visiting programs have scaled in the context of the federal Maternal, Infant, and Early Childhood Home Visiting program (MIECHV) (“Patient Protection and Affordable Care Act” 2010), it is important to refine our understanding of their role and mechanism, and opportunities for maltreatment prevention. In this large scale, mixed methods evaluation, we aimed to estimate the effectiveness of three MIECHV-funded home visiting models in Pennsylvania (PA) on early childhood maltreatment ascertained from clinical diagnoses in emergency department and inpatient healthcare encounters. A concurrent qualitative analysis of interviews with program staff and clients explores the content of and response to curriculum related to child maltreatment.
Data and Methods
This study was performed within the Commonwealth of Pennsylvania (PA) MIECHV evaluation. The study followed a partially mixed, concurrent, equal status design, in which qualitative and quantitative data were analyzed separately and mixed at the stage of interpretation (Leech and Onwuegbuzie 2009). The study was approved by PA’s Department of Human Services with human subjects approval by the Children’s Hospital of Philadelphia’s Institutional Review Board.
Quantitative Data
Analytic Sample
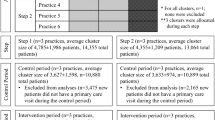
Data was obtained for clients enrolled in MIECHV funded PA nurse–family partnership (NFP, n = 22), parents as teachers (PAT, n = 9), or early head start (EHS, n = 7) from 2008 to 2014. Clients were matched to local-area non-client women (comparisons) who (1) had similarly aged children identified in birth certificate files and (2) resided in the same local implementing agency catchment area (i.e., county or multi-county service area). Inclusion criteria for clients and comparisons were as follows: (1) child affiliated with MIECHV program enrollment was identifiable in PA birth certificate files and (2) child affiliated with MIECHV program enrollment had enrollment in the state medical assistance program (Medicaid) during the outcome observation period.
Clients and potential comparisons were identified in a multisource administrative data file linked using an iterative deterministic approach reliant on unique identifiers constructed from social security numbers, names, and dates of birth that included program enrollment, vital statistics (birth and death), welfare eligibility, and medical assistance claim files (Dusetzina et al. 2014).
Quasi-experimental Design
The primary analysis examined if the prevalence and rate of child abuse episodes significantly differed between program clients and comparison women for NFP, EHS, and PAT programs separately. Two primary quasi-experimental methods were used for causal inference related to program effect on child abuse: entropy balancing for NFP and propensity score matching (PSM) for EHS and PAT. Both analytic approaches are widely used for obtaining covariate balance in observational data, but neither approach was suitable for all three program model analyses for the following reasons.
First, PSM has a disadvantage of dropping subjects unable to be matched to counterparts, which creates a biased sample. In the case of this study, PSM did not retain a generalizable subset of the clients in the NFP analysis (specifically, young mothers in rural areas were disproportionately dropped in attempted PSM). Entropy balancing retained all cases and was the approach used for NFP. While PSM was not the optimal approach for NFP, it was chosen for the EHS and PAT analyses because it allowed for standardized follow-up time in the outcome observation windows of matched sets of clients and comparisons. This is a critical analytic design feature for programs without standardized enrollment at a point in time. Unlike NFP, which uniformly enrolls clients into the program prior to a child’s birth, EHS and PAT programs do not uniformly enroll at a particular age. Therefore, for each client, PSM allowed for the identification of comparisons with similarly aged children at the time of program enrollment. The analysis then standardized observation periods for outcome ascertainment within matched sets of clients and comparisons using the client’s child’s age of enrollment and length of time in the program as the reference point (e.g., if client enrolled child at 3 months and was observed through month 27, all comparison children for that client are observed for months 3 through 27). This level of modeling flexibility is not possible with entropy balancing, but was also not necessary for NFP given the requirement of prenatal enrollment, which serves as a standardization (i.e., all client and comparison children begin observation at birth).
Both entropy balancing and PSM were performed within local implementing agency catchment areas (Matone et al. 2012) to address the possibility that there is confounding by geography (i.e., the outcomes might vary across sites at a community level beyond maternal-level characteristics). Catchments included each implementing agency’s county and contiguous counties. Clients enrolled in a program in a particular catchment were matched to comparison women living in the same catchment. Entropy balancing and PSM were performed within catchments, and then the samples were aggregated.
Description of PSM for EHS and PAT
PSM is a matching technique for observational data that mimics a randomized control trial by creating pairs (or sets) from clients and comparison women with similar values of the propensity score (Stuart 2010). Multivariable logistic regression models estimate the probability of program participation using available maternal sociodemographic and clinical characteristics—from birth certificate: mother’s age at birth (continuous), race/ethnicity (white/black/Hispanic/other), maternal education (< high school/high school or greater), gestational age (continuous), smoking prior to pregnancy (y/n); from welfare eligibility files: receipt of Temporary Assistance for Needy Families (TANF) or supplemental nutrition program prior to or during the first trimester of pregnancy (y/n); from medical assistance claims: Medicaid eligibility (y/n), maternal diagnosis of substance abuse, depression and/or bipolar disorder in the immediate preconception period or first trimester of pregnancy (y/n). A separate logistic regression model was performed within each of the catchment areas for each local implementing agency. Our matching approach used both caliper and exact matching on covariates to produce matched sets. Any nearest neighbor within a caliper of 0.05 was considered a match (up to a maximum of four comparison women per client). Matching was conducted exactly on catchment area, infant year of birth, and maternal age (< 18 years of age at birth or 18 and older). A threshold of 2.5 absolute percentage points was used to determine balance within each catchment area model. Interaction terms were added to the propensity score model when needed to achieve balance. Analytic weights were developed within matched sets; each comparison woman was given a weight equal to the inverse of the number of comparison women matched to that client and each client was given a weight of 1. These weights were applied to outcome modeling.
Description of Entropy Balancing for NFP
Entropy matching is a multivariable weighting technique that creates a balanced sample by reweighting the control group (in this case the comparison women) to have the same covariate distribution as the treatment group (i.e., the clients) using the above described maternal sociodemographic and clinical characteristics. In this approach, specifications for each covariate can be applied as to whether exact balance between the two groups should be achieved on the first moment (mean), second moment (standard deviation), or higher moments (Hainmueller and Xu 2013). As is intended with this methodology, there is automatic balance created between the samples after conducting entropy balancing, so no additional balance checks or model adjustment to create balance was necessary. Covariates used in entropy balancing were the same as included in PSM.
Abuse and Injury Episode Creation
The primary outcome for this study was the presence of an abuse episode or high risk injury episode (composite measure) with a secondary outcome that identified the presence of any injury episode. Outcome measures were derived from child Medicaid claims. Episodes were created to conservatively count unique instances of abuse and injury recognizing that multiple claims/encounters may exist for a single event. The methodology of collapsing claim encounters to create episodes is described in Matone et al. 2012 and further in Online Appendix A.
Abuse episodes were those in which an ICD-9 code indicated child abuse (995.50-5, 995.59), as well as high risk injuries (HRI), specific types of severe injuries considered highly suspicious for abuse without the presence of a medical diagnosis of abuse in the medical record. These episodes feature injuries that include fractures of the femur, radius, ulna, tibia, fibula, humerus, ribs, or traumatic brain injuries within the first 24 months of life (without the presence of ICD-9 codes indicating an injury due to a motor vehicle crash) (Wood 2010) (Online Appendix B).
Injury outcomes included: superficial injuries, a composite of dislocation, fracture, and crush injuries, poisonings, and burns identified through ICD-9 codes.
The observation window for episodes were claims during 0 to 24 months of life for NFP cohort and, for EHS and PAT cohorts, 24 months post-enrollment, up to 6 years of life. Right-censoring of episodes occurred for children whose observation periods exceeded the study end period of 2014.
Outcome Models
The primary exposure was NFP, PAT, or EHS program participation. For EHS and PAT analyses, a weighted conditional logistic regression model was used to examine the unadjusted association between program participation and the primary outcome. For the NFP analysis, a weighted logistic regression with a random intercept for county was used to estimate the relationship between program participation and the primary outcome, controlling for the variability in the outcome across counties. The presence of abuse or injury prior to enrollment was included as an adjustment covariate in PAT and EHS final outcome models (not applicable for NFP modeling given prenatal enrollment) to account for baseline injury risk.
Sensitivity Analyses
Two sensitivity analyses were conducted to test if the relationship found between program participation and abuse outcome was robust to potential confounders that could not be included as covariates in the PSM or entropy balancing model. We tested for confounding between program participation and abuse by maternal psychosocial risk factors by separately including each risk factor in the primary outcome model and examining if the estimated odds ratio effect for the program participation, adjusting for the risk factor, changed by 10% or more. The risk factors ascertained from the literature to be confounders are (1) maternal previous involvement with child protective services (CPS) before pregnancy and (2) intimate partner violence (IPV) measured after conception (Berlin et al. 2011; Eckenrode et al. 2000).
To identify clients involved in CPS, NFP clients and comparisons residing in Philadelphia were linked to county child welfare records via first name, last name, date of birth, and gender. Child welfare systems are administered at the county-level in PA; Philadelphia represents the largest county in the state and produced a sample large enough for sensitivity analysis. For any clients and comparisons successfully linked to child welfare records, dates of protective service were provided. We identified mothers with childhood CPS involvement (prior to pregnancy).
Regarding the second sensitivity analysis, IPV was identified in maternal medical encounters as an ICD-9 code of 995.8x during the observation window of child’s date of conception through the first month of life. Even though we identified IPV in some clients after program enrollment occurred or after the program services could have started, we deemed this time window as most meaningful for measuring IPV for two reasons: (1) to reflect a baseline risk proximal to program enrollment and (2) to increase likelihood of ascertainment in medical assistance files given increased health seeking during pregnancy and increased risk period for IPV. While rates of IPV during pregnancy vary depending on the samples studied and measures used, the prevalence of IPV during pregnancy is elevated compared to women of non-reproductive age and may be increased compared to non-pregnant patients (Hellmuth et al. 2013; Jasinski 2004). Less biased screening (i.e. more universal screening) may occur during the prenatal period due to recommendations by professional organizations, such as the American Congress of Obstetricians and Gynecologists’ (ACOG), that providers should screen all women for IPV at periodic intervals, including during obstetric care (at the first prenatal visit, at least once per trimester, and at the postpartum checkup) (“ACOG Committee Opinion No. 518: Intimate partner violence” 2012).
For each set of primary analyses described above, we ran two additional models—one with a dichotomous covariate for presence of maternal involvement with CPS prior to childbirth and another with a covariate for presence of IPV within child’s date of conception through the first month of life.
Presentation of Results
Logistic regression results were expressed as odds ratios (with 95% confidence intervals) and standardized marginal probabilities. All analyses were conducted using SAS version 9.4, Stata version 14.2 and R. Stata’s ebalance package was used for entropy balancing and R’s MatchIt for PSM. All statistical tests were two-sided and used an alpha = 0.05 as the threshold for statistical significance.
Qualitative Data
Setting and Participants
11 of the 38 PA MIECHV-funded programs were selected for the qualitative study, chosen to supply a representative sample of agencies, based on program size, location, and model type, including NFP, PAT, EHS, and Healthy Families America (HFA, which, due to data constraints, could only be included in the qualitative study). Program staff were interviewed during day-long site visits; enrolled clients, recruited with flyers and help from program staff, were interviewed over the phone. Participants were verbally consented before participating in interviews lasting between 30 and 60 min. Clients were sent a $20 gift card in appreciation for their time. Interviews took place between 2013 and 2015.
Measures and Analysis
The interdisciplinary project team worked with home visiting leadership to develop three distinct interview guides for program administrators, home visitors, and clients, each including questions on specific program outcomes (e.g. child maltreatment; See Online Appendix C for questions that elicited content related to child maltreatment.). De-identified transcripts were imported into NVivo 10 for coding and analysis. We used a modified Grounded Theory approach to coding (Glaser and Strauss 1967), including a priori codes relating to quantitative metrics included in the evaluation. Using a constant comparative approach, coders met regularly to review memos and coding comparison queries to discuss and refine node definitions and the application of codes. Discrepancies were resolved through group consensus. A thematic analysis was conducted on all interview content related to child maltreatment.
Results
Quantitative Data
Cohort Demographics
The entropy balanced NFP cohort included 8736 clients enrolled in 22 NFP programs between 2008 and 2014 matched to 165,033 comparisons. The propensity score matched PAT cohort included 851 clients enrolled in nine PAT programs matched to 2929 comparisons; EHS cohort included 866 clients enrolled in seven EHS programs propensity score matched to 3100 comparisons (Table 1).
Across all models, the majority of clients were unmarried and non-Hispanic white race/ethnicity. In terms of model-specific differences, compared to PAT and EHS client, NFP clients were most likely to be under the age of 18, most likely to be Hispanic, and least likely to smoke prior to pregnancy (Table 1).
Abuse Episodes Among Clients and Comparison Women
Across all models, children of clients were significantly more likely to experience an abuse episode than comparisons: NFP OR: 1.32, 95% CI [1.08, 1.62]; PAT OR: 4.11, 95% CI [1.60, 10.55]; EHS OR: 3.15, 95% CI [1.41, 7.06] (Table 2). Within NFP, 1.4% of client children (n = 120) and 1.0% of comparison children (n = 1488) sustained an abuse injury within 24 months of life; 1.1% (n = 9) of PAT-enrolled children and 0.3% of PAT comparison children (n = 9) sustained an abuse injury within 24 months of enrollment; and 1.3% of EHS program-enrolled children (n = 11) and 0.4% EHS comparison children (n = 14) sustained an abuse injury within 24 months of enrollment.
Distribution of Injury Types among Client Children with an Abuse Episode
The most frequent injury types among home visited children who experienced an abuse episode included superficial injuries and dislocation, fracture or crush injuries. Burns were the least prevalent injury type in aggregate. While poisonings were infrequent among NFP children with abuse episodes (2.0%), one in five children in PAT with abuse episodes experienced poisoning while dislocations, fractures and crush injuries occurred with half the frequency among PAT children than NFP children with abuse (23.5 versus 59.7%) (Table 3).
Sensitivity Analyses
The prevalence of maternal childhood CPS involvement (prior to pregnancy) was equitable between clients and comparisons, with greater than one-third of mothers having CPS involvement prior to their first pregnancy. The results of sensitivity analyses demonstrate a lack of confounding by CPS involvement on the relationship between program enrollment and abuse (Online Appendix D).
Roughly 1% of NFP and PAT clients and comparisons were diagnosed with IPV in the pregnancy period (Online Appendix E, Table 1). In sensitivity analyses, maternal IPV exposure was not found to be a confounder of the relationship of program enrollment and abuse (Online Appendix E). However, across both programs, mothers with diagnosed IPV were significantly more likely to have a child with an abuse episode than those without diagnosed IPV (NFP: 2.7 versus 1.2%, p = 0.027; PAT: 6.0 versus 0.6%, p = 0.027) (Online Appendix E, Table 2).
Qualitative Data
A total of 150 interviews were conducted with program administrators (N = 25), agency staff (N = 49), and home visiting clients (N = 76). The sample represents all four MIECHV-eligible evidence-based programs in PA, with greater representation from NFP (35% of staff and 47% of clients). Participants from urban and rural sites were equally represented (Table 4).
Our thematic analysis of the interview data related to child maltreatment identified two primary domains: (1) how programs and staff react when there is a suspicion of child maltreatment; and (2) how programs and staff address and clients engage with child maltreatment prevention strategies.
Program and Staff Responses to Suspicion or Incidents of Child Maltreatment
In a few instances during interviews, clients and home visitors described instances of potential child maltreatment, shedding light on how the program responds in such circumstances (Table 5).
Of the cases describing incidents concerning for abuse and neglect, most involved caregivers other than the client as the perpetrator, including partners, child siblings, and grandparents. Program responses tended to focus on supporting the client after the abuse had occurred with parenting support, referrals, and connections to resources. Some home visitors described relying on CPS to manage child maltreatment issues.
[I]f there is any indication of violence in the home that would always be referred to [CPS], if that child was being exposed to that. A lot of times, you can just see it while you’re there. […] sometimes they don’t even try to hide it. Or they’ll […] say something that the other person has been doing or whatever. So we don’t get into that too much, other than to say a healthy environment is what our goal is here and whatever you need to do to get that. HFA/PAT Home Visitor, 801
Home visitors qualified their relationship with CPS in many ways, including their role as mandated reporters. Given the negative feelings often associated with CPS, some home visitors described being careful about how they explained their relationship with CPS to clients.
Approach to and Engagement with Child Maltreatment Prevention
Home visitors described focusing on content related to positive parenting, secure attachment, and stress management as the curricular drivers of child abuse prevention. Many staff referenced the program training they received, which taught them that supporting the development of a strong bond between a parent and child could reduce the chances of maltreatment.
We stress with [parents] attachment and bonding. Because if a parent does attachment and bonding, we’ve learned through all of our trainings with the HFA, they’re gonna be less likely to abuse their child […], and that is what everything circles back to. HFA Home Visitor, 103
Home visitors focused with parents on approaches and frameworks for disciplining children. The described curricula addressed strategies directed both at the children, to manage their behavior, and at the adults, to manage associated stress.
[T]he program talks about strategies with kids having temper tantrums and stuff. Not only things that you can do for the kiddo, but things as a parent. Maybe you need to step away, take a few breaths, collect yourself and then go back and address the issue. EHS Administrator, 1002
Parents valued this guidance and support, perceiving improvements in managing their reactions to frustrating child behaviors. Clients attributed personal changes to the general encouragement from home visitors to attend to their own personal needs and more specific support related to stress.
I get stressed out easy and she’s helped me learn how to deal with stressful situations, when it comes down with my daughter when she starts getting in her, “give me, wanna wanna” modes […] and I get really stressed about it. She helps me learn how to deal with the stress and teaches me how to deal with my daughter […]. […S]he told me, it’s important that you do this for yourself. Also, it’s important you do this for you daughter. I need to take a little down time. HFA Client, 1004
Some clients described how learning new discipline strategies gave them the opportunity to break a cycle of abuse.
We’ve talked about discipline, not so much of abuse. […] I think it’s effective to make sure that my child understands that I know what they want and kind of having different methods instead of going directly to a punishment. […]My parents disciplined me by beating me and punishing me for extremely long periods of time […]. […] Those things that I didn’t really know about prior to being involved in the program because those are things that weren’t taught to me as a child. PAT Client, 7020
When asked how they talked with their home visitor about protecting their child from abuse, a number of clients did not remember the subject being addressed. Many clients acknowledged that discussing child maltreatment should be part of the curriculum covered by their home visitor. Implied in the absence of direct discussions of child abuse was the described assumption that the home visitor knew there was not abuse occurring within the household.
I don’t remember talking about that. I would assume that she knows that we are not abusive at all here. But I know that she shouldn’t assume, because you don’t know what happens when someone leaves. PAT Client, 2004
From the client perspective, very few barriers to broaching the topic of abuse were described. One parent postulated that using videos to broach the subject of child maltreatment was the only way the program could address it without putting parents on the defensive.
I think that the videos and the conversations are really all they can do without having somebody be like, you’re intruding or PC or social warrior. That’s a sensitive subject for a lot of people, how you’re gonna discipline your kids or whatever. NFP Client, 5002
Some home visitors discussed difficulties encouraging families to alter behaviors. The set of norms a parent develops around how adults should interact with children from years of personal experience is difficult to contend with when misaligned with home visitor communication.
Challenges are we’re not there all the time to monitor them. We can refer them, we can’t force them to go. I mean, there’s a deep history in how people discipline their children and it’s hard to break that within a couple of months. NFP/PAT Home Visitor, 710
Unless a parent is personally invested in changing their patterns, it is difficult for the home visitor to champion change alone. When parents are open to using new strategies, true influence depends on the degree to which these strategies replace problematic practices.
I learned that there’s no wrong or right way to teach your child behaving. […] Like say if she would think I’m teaching her, like I pop her or whatever, that could be okay, to pop her, but you know, also you got to like start taking stuff away and then teaching her no, and telling her don’t do stuff. NFP Client, 7015
Discussion
This study demonstrates quantifiably increased risk of early childhood abuse-related injury among children of MIECHV clients compared to non-program enrolled comparison children across three home visiting programs (NFP, EHS, and PAT) implemented in a large state. Among client children experiencing abuse, elevated rates of fracture, dislocation, and crush injuries were seen in comparison to client children experiencing non-abuse related injuries.
Null findings on child abuse prevention to home visiting programs are not new to the field. Others have cited surveillance bias among enrolled families as a reason for the lackluster program effect on child maltreatment (Gomby et al. 1999; Olds et al. 1995). While surveillance bias may be a contributor to increased observation of abuse-related injury among client families, the bias is likely most relevant to minor injuries where healthcare seeking behavior was optional. In the case of more serious and emergent injuries, including fractures, dislocations, and crush injuries, the likelihood of a family to seek healthcare is likely less dependent on the presence of home visitor. Other considerations for the observed increased rate of abuse-related injury among home visited families include unidentified confounding that does not account for the referral bias driving higher risk clients into home visiting services. To address this concern, this study included two sensitivity analyses to account for potential confounding by the two strongest psychosocial risk factors associated with child maltreatment: maternal childhood involvement with CPS or IPV. Despite a high prevalence of maternal childhood CPS involvement among clients, this risk factor was found to be balanced between clients and comparison women and did not confound findings. Maternal IPV in pregnancy was also not an identified confounder in this study, though diagnosed rates of IPV were low and likely represented underascertainment of true IPV risks within the cohort. Among mothers with diagnosed IPV in pregnancy, rates of abuse were higher even after adjustment for program enrollment, indicating that these families may be a high risk subgroup of home visited clientele.
A strength of this study is the provision of qualitative contextual support for the development of hypotheses of why home visiting programs may struggle in reducing rates of child abuse. The instances of child abuse assessed in interviews described events where harm occurred to the child outside of the client’s oversight while under the supervision of a non-client caregiver. Acknowledging the limitation that interviewees may be more likely to discuss incidents in which they were not the perpetrator, the number of examples including other caregivers is still notable. The data are reflective of other information described by program sites suggesting that the vast majority of serious and abuse-related injuries take place while the child is in the care of a non-client caregiver, often an intimate partner. As programs encourage clients to engage in educational and professional advancements, it is important to address resultant childcare needs. Additionally, the role of non-clients in child maltreatment events makes evident the importance of delivering program curriculum to as many of the caregivers in contact with children as possible. Further support for this hypothesis is demonstrated by the quantitative sensitivity analysis of the significant impact of the presence of IPV on child abuse.
The curriculum related to child maltreatment, as well as home visitors’ delivery of it also plays a role in achieving intended program outcomes. Recent evidence suggests that home visiting programs may struggle to achieve positive child maltreatment outcomes due to ineffectual program delivery. Much of home visiting curricula is prepared to help parents decrease the effects of adverse childhood experiences (ACEs) on their children, even without a reduction in actual ACEs (McKelvey et al. 2016). However, home visitors themselves have not reported high efficacy in guiding discussions with parents related to sensitive topics such as maltreatment and violence (Duggan et al. 2007). Casillas et al. notes that child maltreatment outcomes in particular are negatively affected by low home visitor efficacy and fidelity in service provision (Casillas et al. 2016). Our qualitative data demonstrate variations in whether and how home visitors discussed child abuse with clients, such that a number of clients did not recollect the topic ever being raised. This finding may have been driven by role issues, as mandatory reporters and assumed affiliations with CPS were barriers to direct discussions of maltreatment. Home visitors also struggled against normative factors shaping behavior change, as well as those more directly related to maltreatment such as corporal punishment. A recent evaluation of PAT program in Connecticut demonstrated significant reductions in substantiated child maltreatment; however, this finding was driven by reductions in neglect with no demonstrated impact on child abuse. Such findings further highlight the need for additional supports around abuse specifically, but also provide support for qualitative findings in this study that suggest more home visitor comfort in the domains of parenting that may be more directly related to neglect-related maltreatment (Chaiyachati et al. 2018).
Despite hearing an openness to discussing issues of child maltreatment from more clients than those noting challenges, overall the qualitative data illustrate little direct engagement around child maltreatment. Interviews with clients and staff demonstrate that indirect approaches, such as activities to alter parenting styles or decrease maternal stress, are present and more likely to be delivered with fidelity. However, it is possible that focusing on supporting positive parenting and stress reduction is not sufficient to effectively reduce the risk of abuse incidents among the subset of home visited families most at-risk for maltreatment.
Finally, the qualitative data describe limited reactive responses to situations concerning for neglect and referral to outside resources—mainly CPS. The data highlights the dependence of home visiting success on the system of services in which the program resides. The importance of the quality, access, and connectedness of CPS, childcare, and healthcare to home visiting services towards the prevention of child maltreatment prevention cannot be overstated. The ability of home visitors to transition from reactivity to proactivity around child abuse is dependent on effective referral relationships, trust in the CPS system, and timely and affordable access to services that mitigate abuse risks, including childcare and healthcare.
This study has several limitations related to study design and data availability and reliability. The observational study design is subject to bias when estimating program effects; however the use of propensity score and entropy matching, which mimic randomization and control for measured differences between clients and comparisons and sensitivity analyses with likely confounders, minimizes this concern and is a widely accepted technique for estimating causality when randomization is not feasible or appropriate. Moreover, the standardized approach to outcome ascertainment using administrative rather than self-reported data coupled with the rigorous quasi-experimental design facilitate standardized interpretation of findings across three home visiting models and numerous diverse implementing sites. While our analyses were unable to take program dosage and the perpetrator of abuse incidents into account in a standardized fashion as this information was unavailable in administrative data files, this information was gleaned from qualitative interviews when it was addressed by home visitors or clients. The study is not able to account for surveillance bias; however, the study used an intention to treat design to observe children for two full years following enrollment while a significant proportion of families are not retained in services for this duration (Burwick et al. 2014). Lastly, given the sensitive nature of this topic, the qualitative interview data is likely impacted by social desirability bias.
Conclusion
Home visiting programs have a stated objective of preventing child abuse-related injury among high-risk families. The success of abuse prevention depends on the strength of the curriculum, the fidelity of delivery, and whether it reaches the people in caregiving roles. Given that home visitors depend greatly on other community agencies and public systems, it is naïve to expect home visiting to achieve strong outcomes without a well-integrated and -resourced service network. Programs and clients would benefit from curriculum that more directly and proactively addresses child maltreatment, as well as knowledge of and access to quality childcare options.
Change history
28 August 2018
The article “A Mixed Methods Evaluation of Early Childhood Abuse Prevention Within Evidence-Based Home Visiting Programs”, written by M. Matone, K. Kellom, H. Griffis, W. Quarshie, J. Faerber, P. Gierlach, J. Whittaker, D. M. Rubin and P. F. Cronholm, was originally published electronically on the publisher’s internet portal (currently SpringerLink) on 31 May 2018 without open access. With the author(s)’ decision to opt for Open Choice the copyright of the article changed on 27 July 2018 to © The Author(s) 2018 and the article is forthwith distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits use, duplication, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license and indicate if changes were made.
References
ACOG Committee Opinion No. 518. (2012). Intimate partner violence. Obstetrics Gynecology, 119(2 Pt 1), 412–417. https://doi.org/10.1097/AOG.0b013e318249ff74.
Administration for Children and Families. https://www.acf.hhs.gov/sites/default/files/cb/cm2015.pdf. Accessed 1 Mar 2018
Agran, P. F., Anderson, C., Winn, D., Trent, R., Walton-Haynes, L., & Thayer, S. (2003). Rates of pediatric injuries by 3-month intervals for children 0 to 3 years of age. Pediatrics, 111(6), e683–e692. https://doi.org/10.1542/peds.111.6.e683.
Berlin, L. J., Appleyard, K., & Dodge, K. A. (2011). Intergenerational continuity in child maltreatment: Mediating mechanisms and implications for prevention. Child Development, 82(1), 162–176. https://doi.org/10.1111/j.1467-8624.2010.01547.x.
Burwick, A., Zaveri, H., Shang, L., Boller, K., Daro, D., Strong, D. (2014). Costs of early childhood home visiting: An analysis of programs implemented in the supporting evidence-based home visiting to prevent child maltreatment initiative.
Casillas, K. L., Fauchier, A., Derkash, B. T., & Garrido, E. F. (2016). Implementation of evidence-based home visiting programs aimed at reducing child maltreatment: A meta-analytic review. Child Abuse & Neglect, 53, 64–80. https://doi.org/10.1016/j.chiabu.2015.10.009.
Chaiyachati, B. H., Gaither, J. R., Hughes, M., Foley-Schain, K., & Leventhal, J. M. (2018). Preventing child maltreatment: Examination of an established statewide home-visiting program. Child Abuse & Neglect, 79, 476–484. https://doi.org/10.1016/j.chiabu.2018.02.019.
Children’s Bureau. (2016). Child maltreatment 2015. Washington, DC: Administration on Children Youth and Families.
Deutsch, S. A., Lynch, A., Zlotnik, S., Matone, M., Kreider, A. R., & Noonan, K. (2015). Mental health, behavioral and developmental issues for youth in foster care. Current Problems in Pediatric and Adolescent Health Care, 45(10), 292–297. https://doi.org/10.1016/j.cppeds.2015.08.003.
Duggan, A., Caldera, D., Rodriguez, K., Burrell, L., Rohde, C., & Crowne, S. S. (2007). Impact of a statewide home visiting program to prevent child abuse. Child Abuse & Neglect, 31(8), 801–827. https://doi.org/10.1016/j.chiabu.2006.06.011.
Dusetzina, S. B., Tyree, S., Meyer, A. M., Meyer, A., Green, L., & Carpenter, W. R. (2014). Linking data for health services research: A framework and instructional guide. Rockville, MD: Agency for Healthcare Research and Quality.
Eckenrode, J., Ganzel, B., Henderson, C. R. Jr., Smith, E., Olds, D. L., Powers, J., … Sidora, K. (2000). Preventing child abuse and neglect with a program of nurse home visitation: The limiting effects of domestic violence. JAMA, 284(11), 1385–1391.
Frioux, S., Wood, J. N., Fakeye, O., Luan, X., Localio, R., & Rubin, D. M. (2014). Longitudinal association of county-level economic indicators and child maltreatment incidents. Maternal and Child Health Journal, 18(9), 2202–2208. https://doi.org/10.1007/s10995-014-1469-0.
Glaser, B. G., & Strauss, A. L. (1967). The discovery of grounded theory: Strategies for qualitative research. New York: Aldine de Gruyter.
Gomby, D. S., Culross, P. L., & Behrman, R. E. (1999). Home visiting: Recent program evaluations: Analysis and recommendations. The Future of Children, 9(1), 4–26.
Hainmueller, J., & Xu, Y. (2013). Ebalance: A Stata package for entropy balancing. Journal of Statistical Software, 54(7).
Hellmuth, J. C., Gordan, K. C., & Stuart, G. L. (2013). Risk factors for intimate partner violence during pregnancy and postpartum. Archives of Women’s Mental Health, 16, 19–27.
Howard, K. S., & Brooks-Gunn, J. (2009). The role of home-visiting programs in preventing child abuse and neglect. The Future of Children, 19(2), 119–146.
Institute of Medicine, & National Research Council. (2014). New directions in child abuse and neglect research. Washington, DC: National Academies Press.
Jasinski, J. L. (2004). Pregnancy and domestic violence: A review of the literature. Trauma, Violence, and Abuse, 5(1), 47–64.
Leech, N. L., & Onwuegbuzie, A. J. (2009). A typology of mixed methods research designs. Quality and Quantity, 43(2), 265–275.
Matone, M., O’Reilly, A. L., Luan, X., Localio, R., & Rubin, D. M. (2012). Home visitation program effectiveness and the influence of community behavioral norms: A propensity score matched analysis of prenatal smoking cessation. BMC Public Health, 12, 1016. https://doi.org/10.1186/1471-2458-12-1016.
Matone, M., O’Reilly, A. L. R., Luan, X., Localio, A. R., & Rubin, D. M. (2012). Emergency department visits and hospitalizations for injuries among infants and children following statewide implementation of a home visitation model. Maternal and Child Health Journal, 16(9), 1754–1761. https://doi.org/10.1007/s10995-011-0921-7.
McKelvey, L. M., Whiteside-Mansell, L., Conners-Burrow, N. A., Swindle, T., & Fitzgerald, S. (2016). Assessing adverse experiences from infancy through early childhood in home visiting programs. Child Abuse & Neglect, 51, 295–302. https://doi.org/10.1016/j.chiabu.2015.09.008.
Merrick, M. T., & Latzman, N. E. (2014). Child maltreatment: A public health overview and prevention considerations. Online Journal of Issues in Nursing, 19(1), 1–1. https://doi.org/10.3912/OJIN.Vol19No01Man02.
Nelson, H. D., Selph, S., Bougastsos, C., & Blazina, I. (2013). Behavioral interventions and counseling to prevent child abuse and neglect: A systematic review to update the U.S. Preventative Services Task Force recommendation. Annals of Internal Medicine, 158(3), 179–190.
Olds, D., Henderson, C. R. Jr., & Kitzman, H. (1994). Does prenatal and infancy nurse home visitation have enduring effects on qualities of parental caregiving and child health at 25 to 50 months of life? Pediatrics, 93(1), 89–98.
Olds, D., Henderson, C. R. Jr., Kitzman, H., & Cole, R. (1995). Effects of prenatal and infancy nurse home visitation on surveillance of child maltreatment. Pediatrics, 95(3), 365–372.
Patient Protection and Affordable Care Act. § 2951 (2010).
Rubin, D. M., Curtis, M. L., & Matone, M. (2014). Child abuse prevention and child home visitation: Making sure we get it right. JAMA Pediatrics, 168(1), 5–6. https://doi.org/10.1001/jamapediatrics.2013.3865.
Schatz, J. N., & Lounds, J. J. (2007). Child maltreatment: Precursors of developmental delays. In J. G. Borkowski, J. R. Farris, T. L. Whitman, S. S. Carothers, K. Weed & D. A. Keogh (Eds.), Risk and resilience: Adolescent mothers and their children grow up (pp. 125–150). Mahwah, NJ: Lawrence Erlbaum.
Stuart, E. A. (2010). Matching methods for causal inference: A review and a look forward. Statistical Science: A Review Journal of the Institute of Mathematical Statistics, 25(1), 1.
Wood, J. N. (2010). Disparities in the evaluation and diagnosis of abuse among infants with traumatic brain injury. Pediatrics, 126(3), 408–414.
Wood, J. N., Medina, S. P., Feudtner, C., Luan, X., Localio, R., Fieldston, E. S., & Rubin, D. M. (2012). Local macroeconomic trends and hospital admissions for child abuse, 2000–2009. Pediatrics, 130(2), e358–e364. https://doi.org/10.1542/peds.2011-3755.
Acknowledgements
This evaluation was supported by a grant from the Department of Human Services, Commonwealth of Pennsylvania. We thank the Pennsylvania Department of Human Services, Pennsylvania Department of Health, and the MIECHV local implementing agencies across Pennsylvania for contributing data for this study. We are also grateful to the Office of Child Development and Early Learning of the Pennsylvania Department of Human Services for their consultation on Pennsylvania MIECHV programming and partnership in identifying evaluation priorities for the Commonwealth.
Author information
Authors and Affiliations
Corresponding author
Additional information
The original version of this article was revised due to a retrospective Open Access order.
Electronic supplementary material
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Matone, M., Kellom, K., Griffis, H. et al. A Mixed Methods Evaluation of Early Childhood Abuse Prevention Within Evidence-Based Home Visiting Programs. Matern Child Health J 22 (Suppl 1), 79–91 (2018). https://doi.org/10.1007/s10995-018-2530-1
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10995-018-2530-1