
Abstract
This work belongs to the strand of literature that combines machine learning, optimization, and econometrics. The aim is to optimize the data collection process in a specific statistical model, commonly used in econometrics, employing an optimization criterion inspired by machine learning, namely, the generalization error conditioned on the training input data. More specifically, the paper is focused on the analysis of the conditional generalization error of the Fixed Effects Generalized Least Squares (FEGLS) panel data model, i.e., a linear regression model with applications in several fields, able to represent unobserved heterogeneity in the data associated with different units, for which distinct observations related to the same unit are corrupted by correlated measurement errors. The framework considered in this work differs from the classical FEGLS model for the additional possibility of controlling the conditional variance of the output variable given the associated unit and input variables, by changing the cost per supervision of each training example. Assuming an upper bound on the total supervision cost, i.e., the cost associated with the whole training set, the trade-off between the training set size and the precision of supervision (i.e., the reciprocal of the conditional variance of the output variable) is analyzed and optimized. This is achieved by formulating and solving in closed form suitable optimization problems, based on large-sample approximations of the generalization error associated with the FEGLS estimates of the model parameters, conditioned on the training input data. The results of the analysis extend to the FEGLS case and to various large-sample approximations of its conditional generalization error the ones obtained by the authors in recent works for simpler linear regression models. They highlight the importance of how the precision of supervision scales with respect to the cost per training example in determining the optimal trade-off between training set size and precision. Numerical results confirm the validity of the theoretical findings.
Similar content being viewed by others


1 Introduction
In various applications in economics, engineering, medicine, physics, and several other fields, one has often the need of approximating a function, based on a finite set of input/output noisy examples. This belongs to the typical class of problems investigated by supervised machine learning (Hastie et al. 2009; Vapnik 1998). In some cases, the noise variance of the output variable can be decreased, at least to some extent, by making the cost of each supervision larger. As an example, observations could be acquired by using more precise measurement devices (then, likely, having also larger acquisition cost). Similarly, each supervision could be made by an expert (also in this case, a larger cost would be expected by increasing the level of expertise). In all these situations, it can be useful to optimize the trade-off between the training set size and the precision of supervision. In the conference work Gnecco and Nutarelli (2019), this kind of analysis was conducted by proposing a modification of the classical linear regression model, in which one has the additional possibility to control the conditional variance of the output variable given the associated input variables, by changing the time (hence, the cost) dedicated to provide a label to each training input example, and fixing an upper bound on the time available for the supervision of the whole training set. Based on a large-sample approximation of the output of the ordinary least squares regression algorithm, it was shown in that work that the optimal choice of the supervision time per example highly depends on how the precision of supervision scales with respect to the cost per training example. The analysis was refined in Gnecco and Nutarelli (2019), where a related optimization problem, based on the analysis of the output produced by a different regression algorithm (namely, weighted least squares) was considered, obtaining similar results at optimality, for a model in which distinct training examples are possibly associated with different supervision times. Finally, in the conference work Gnecco and Nutarelli (2020), the analysis of the optimal trade-off between training set size and precision of supervision was extended to a more general linear model of the input/output relationship, namely, the fixed effects panel data model. In this model, observations associated with different units (individuals) depend also on additional constants, one for each unit, which make it possible to include, in the input/output relationship, unobserved heterogeneity in the data. Moreover, each unit is observed along another dimension, which is typically time. This kind of model (and its variations) is commonly applied in the analysis of data in both microeconomics and macroeconomics (Arellano 2004; Cameron and Trivedi 2005; Wooldridge 2002), where each unit may represent, for instance, a firm, or a country. It is also applied in biostatistics (Härdle et al. 2007) and sociology (Frees 2004). An important engineering application of the model (and of its variations) is in the calibration of sensors (Reeve 1988, Sect. 4.1).
In order to increase the applicability of the analysis carried out in our previous conference work (Gnecco and Nutarelli 2020), in this paper we extend it thoroughly in the following directions. First, Gnecco and Nutarelli (2020) investigated only the case in which the measurements errors of observations associated with the same unit are mutually independent. In this paper, we extend such analysis to the case of dependent measurement errors. Moreover, differently from Gnecco and Nutarelli (2020), we confirm the validity of the obtained theoretical results numerically. Further, in Gnecco and Nutarelli (2020), the optimal trade-off between training set size and precision of supervision was analyzed only for a fixed number of units, assuming that the number of observations associated with the same unit is large enough to justify a large-sample approximation with respect to the number of observations. In the last part of this work, we consider additionally the cases of a large-sample approximation with respect to the number of units, and of a large-sample approximation with respect to both the number of units and the number of observations per unit.
In line with the results of the theoretical analyses made in (Gnecco and Nutarelli 2019, 2019, 2020) for simpler linear regression models, we show that, also for the more applicable fixed effects generalized least squares panel data model, the following holds in general: when the precision of each supervision (i.e., the reciprocal of the conditional variance of the output variable, given the associated unit and input variables) increases less than proportionally versus an increase of the supervision cost per training example, the minimum (large-sample approximation of the) generalization error (conditioned on the training input data) is obtained in correspondence of the smallest supervision cost per example (hence, of the largest number of examples); when that precision increases more than proportionally versus an increase of the supervision cost per example, the optimal supervision cost per example is the largest one (which corresponds to the smallest number of examples). Differently from (Gnecco and Nutarelli 2019, 2019, 2020), in the analysis made in the present work, the number of training examples can be varied either by increasing the number of observations per unit, or the number of units, or both. In summary, the results of the analyses made in (Gnecco and Nutarelli 2019, 2019, 2020) and, for a different and more complex regression model, in this paper, highlight that increasing the training set size is not always beneficial, if a smaller number of more reliable data can be collected. Hence, not only the quantity of data, but of course, also their quality matters. This looks particularly relevant when the data collection process can be designed before data are actually collected.
The paper is structured as follows. Section 2 provides a background on the fixed effects generalized least squares panel data model. Section 3 presents the analysis of its conditional generalization error, and of the large-sample approximation of the latter with respect to time. Section 4 formulates and solves an optimization problem we propose in order to provide an optimal trade-off between training set size and precision of supervision for the fixed effects generalized least squares panel data model, using the large-sample approximation above. Section 5 presents some numerical results, which validate the theoretical ones. Finally, Sect. 6 discusses some possible applications and extensions of the theoretical results obtained in the work. Some technical proofs and remarks about the extension of the analysis made in the paper to other large-sample settings are reported in the Appendices.
2 Background
In this section, we recall some basic facts about the following Fixed Effects Generalized Least Squares (FEGLS) panel data model (see, e.g., Wooldridge 2002, Chapter 10). Specifically, we refer to the following model:
where the outputs \(y_{n,t} \in {\mathbb {R}}\) are scalars, whereas the inputs \({\underline{x}}_{n,t}\) (\(n=1,\ldots ,N,t=1,\ldots ,T\)) are column vectors in \({\mathbb {R}}^p\), and are modeled as random vectors. The superscript \('\) denotes transposition. The parameters of the model are the individual constants \(\eta _n\) (\(n=1,\ldots ,N)\), one for each unit, and the column vector \(\underline{\beta }\in {\mathbb {R}}^p\). The constants \(\eta _n\) are also called fixed effects. Eq. (1) represents a balanced panel data model, in which each unit n is associated with the same number T of outputs, each one at a different time t. The model represents the case in which the input/output relationship is linear, and different units, which are observed at the times \(t=1,\ldots ,T\), are associated with possibly different constants.
Note that the outputs \(y_{n,t}\) are actually unavailable; only their noisy measurements \(z_{n,t}\) can be obtained, which are assumed to be generated according to the following additive noise model:
where, for any n, the \(\varepsilon _{n,t}\) are identically distributed and possibly dependent random variables, having mean 0, and are further independent from all the \({\underline{x}}_{n,t}\). For any two units \(n \ne m\) and any two time instants \(t_1,t_2 \in \{1,\ldots ,T\}\), \(\varepsilon _{n,t_1}\) and \(\varepsilon _{m,t_2}\) are assumed to be independent. Hence, only the possibility of temporal dependence for the measurement errors associated with the same unit is considered in the following, in line with several works in the literature (see, e.g., Bhargava et al. (1982) and (Wooldridge 2002, Section 10.5.5)).
For each unit n, let \(X_n \in {\mathbb {R}}^{T \times p}\) be the matrix whose rows are the transposes of the \({\underline{x}}_{n,t}\); further, let \({\underline{z}}_n \in {\mathbb {R}}^T\) be the column vector which collects the noisy measurements \(z_{n,t}\), and \(\underline{\varepsilon }_n \in {\mathbb {R}}^T\) the column vector which collects the measurement noises \(\varepsilon _{n,t}\). The input/corrupted output pairs \(({\underline{x}}_{n,t},{\underline{z}}_{n,t})\), for \(n=1,\ldots ,N\), \(t=1,\ldots ,T\), are used to train the FEGLS model, i.e., to estimate its parameters.
The following first-order serial covariance form is assumed (see, e.g., Bhargava et al. (1982) and Wooldridge (2002, Section 10.5.5)) for the (unconditional) covariance matrix of the vector of measurement noises associated with the n-th unitFootnote 1, where \(\sigma > 0\) and \(\rho \in (-1,1)\) hold (here, \({\mathbb {E}}\) denotes the expectation operator):
which is a symmetric and positive-definite matrix. In other words, the measurement noise is assumed to be generated by a first-order autoregressive (AR(1)) process (Ruud 2000, Section 25.2). In the particular case of uncorrelated (\(\rho =0\)) and independent measurement noises, one obtains the model considered in Gnecco and Nutarelli (2020).
Let the matrix \(Q_T \in {\mathbb {R}}^{T \times T}\) be defined as
where \(I_T \in {\mathbb {R}}^{T \times T}\) is the identity matrix, and \({\underline{1}}_T \in {\mathbb {R}}^T\) a column vector whose elements are all equal to 1. One can check that \(Q_T\) is a symmetric and idempotent matrix (i.e., \(Q_T'=Q_T=Q_T^2\)), and its eigenvalues are 0 with multiplicity 1, and 1 with multiplicity \(T-1\). Hence, for each unit n, one can define
and
which represent, respectively, the matrix of time de-meaned training inputs, the vector of time de-meaned corrupted training outputs, and the vector of time de-meaned measurements noises. The goal of time de-meaning is to obtain a derived dataset where the fixed effects are removed, making it possible to estimate first the vector \(\underline{\beta }\), then - turning back to the original dataset - the fixed effects \(\eta _n\). The covariance matrix \({\mathbb {E}}\{\ddot{\underline{\varepsilon }}_n\ddot{\underline{\varepsilon }}_n'\}\) has the expression
which is symmetric and positive semi-definite, and has rank \(T-1<T\) (Wooldridge 2002). Although this deficient rank prevents the application of the most usual approach to Generalized Least Squares (GLS) estimation, based on the inversion of the covariance matrix \(\varOmega\) (which in this case cannot be inverted), one can still apply GLS by projecting Eqs. (1) and (2) onto the orthogonal complement L of the vector \({\underline{1}}_T\) by using \(Q_T\), then solving a standard GLS problem on L (Aitken 1936). This is formally obtained by replacing the inverse of the covariance matrix with its Moore-Penrose pseudoinverseFootnote 2 (denoted by \(\varOmega ^+\)), as made in the context of FEGLS estimation in Kiefer (1980, Im et al. (1999). More precisely, assuming the invertibility of the matrix \(\sum _{n=1}^N {{\ddot{X}}_n' {\varOmega ^{+}} {\ddot{X}}_n}\) (see Remark 3.1 for a justification of this assumption), the FEGLS estimate of \(\underline{\beta }\) is
The estimate \(\underline{\hat{\beta }}_{FEGLS}\) in (9) can be interpreted as the GLS estimate of \(\underline{\beta }\) obtained by replacing the original input/corrupted output training data with their de-meaned versions reported above. It is worth observing that the training input/corrupted output pairs \(\left( {\underline{x}}_{n,t},z_{n,t}\right)\) (\(n=1,\ldots ,N,t=1,\ldots ,T\)) are all used to estimate \(\underline{\beta }\).
Remark 2.1
Another commonly used approach to deal with the issue above is to drop one of the time periods from the analysis, in order to get an invertible covariance matrix. It can be rigorously proved (see, e.g. (Im et al. 1999, Theorem 4.3)) that this second approach is equivalent to the one based on the Moore-Penrose pseudoinverse (producing exactly the same FEGLS estimate), and that it does not matter which time period is dropped, as the resulting GLS estimator has always the same form. Therefore, dropping the last row of \(Q_T\), one gets the matrix \({\tilde{Q}}_T \in {\mathbb {R}}^{(T-1)\times T}\), from which one obtains the matrix \(\tilde{{\ddot{X}}}_n := {\tilde{Q}}_T X_n \in {\mathbb {R}}^{(T-1) \times p}\), the column vector \(\tilde{\ddot{{\underline{z}}}}_n := {\tilde{Q}}_T {\underline{z}}_n \in {\mathbb {R}}^{T-1}\), and the column vector \(\tilde{\ddot{\underline{\varepsilon }}}_n:= {\tilde{Q}}_T \underline{\varepsilon }_n \in {\mathbb {R}}^{T-1}\). Moreover, denoting by \({\tilde{X}}_n \in {\mathbb {R}}^{(T-1) \times p}\), \(\tilde{{\underline{z}}}_n \in {\mathbb {R}}^{T-1}\), and \(\tilde{\underline{\varepsilon }}_n \in {\mathbb {R}}^{T-1}\) the matrix and the vectors obtained by removing the last row, respectively, from \(X_n\), \({\underline{z}}_n\), and \(\underline{\varepsilon }_n\), one gets
which is, differently from \(\varOmega\), an invertible matrix, with inverse \({\tilde{\varOmega }^{-1}} = ({\tilde{Q}}_T \varLambda {\tilde{Q}}_T')^{-1}\). The resulting FEGLS estimate is
(see, e.g., Wooldridge (2002)). The FEGLS estimate \(\underline{\hat{\beta }}_{FEGLS}\) and the alternative one \(\underline{\hat{\beta }}_{FEGLS}^{alt}\) are actually identical (Im et al. 1999, Theorem 4.3). This equivalence is obtained by expressing such estimates in terms of the original variables before de-meaning, then exploiting the proof of (Im et al. 1999, Theorem 4.3), which shows that \(Q_T'\varOmega ^{+} Q_T={\tilde{Q}}_T' \tilde{\varOmega }^{-1} {\tilde{Q}}_T\) (this still holds if an observation different from the last one is dropped, and \({\tilde{Q}}_T\) is redefined accordingly).
The FEGLS estimates of the \(\eta _n\) (also called fixed effects residuals (Wooldridge 2002)) are
They are obtained by subtracting the estimate \(\underline{\hat{\beta }}_{FEGLS}'{\underline{x}}_{n,t}\) of \(\underline{\beta }'{\underline{x}}_{n,t}\) from each corrupted output \(z_{n,t}\), then performing an empirical average, limiting to training data associated with the unit n. The FEGLS estimates reported in Eq. (12) are motivated by the fact that the \(\eta _n\) are constants, whereas the \(\varepsilon _{n,t}\) have mean 0.
By taking expectations, it readily follows from their definitions that the estimates (9) and (12) are conditionally unbiased with respect to the training input data \(\{{\underline{x}}_{n,t}\}_{n=1,\ldots ,N}^{t=1,\ldots ,T}\), i.e., that
where \({\underline{0}}_p \in {\mathbb {R}}^p\) is a column vector whose elements are all equal to 0, and, for any \(i=1,\ldots ,N\),
Finally, the covariance matrix of \(\underline{\hat{\beta }}_{FEGLS}\), conditioned on the training input data, is
3 Conditional generalization error and its large-sample approximation
The goal of this section is to analyze the generalization error associated with the FEGLS estimates (9) and (12), conditioned on the training input data, by providing its large-sample approximation. Then, in Sect. 4, the resulting expression is optimized, after choosing suitable models for the standard deviation \(\sigma\) of the measurement noise and for the time horizon, which is chosen in such a way it satisfies a suitable budget constraint.
First, we express the generalization error or expected risk for the i-th unit (\(i=1,\ldots ,N\)), conditioned on the training input data, by
where \({\underline{x}}_i^{test} \in {\mathbb {R}}^p\) is independent from the training data. It is the expected mean squared error of the prediction of the output associated with a test input, conditioned on the training input data.
As shown in Appendix 1, we can express the conditional generalization error (16) as follows, highlighting its dependence on \(\sigma ^2\):
where some computations (reported in Appendix 1) show that
and
Next, we obtain a large-sample approximation of the conditional generalization error (17) with respect to T, for a fixed number of units N. Such an approximation is useful, e.g., in the application of the model to macroeconomics data, for which it is common to investigate the case of a large horizon T.
Under mild conditions (e.g., if for the unit i the \({\underline{x}}_{i,t}\) are mutually independent, identically distributed, and have finite moments up to the order 4), the following convergences in probabilityFootnote 3 hold (their proofs are reported in Appendix 2):
Similarly, if for each fixed unit n the \({\underline{x}}_{n,t}\) are mutually independent, identically distributedFootnote 4, and have finite moments up to the order 4, and one makes the additional assumption (whose validity is discussed extensively in Appendix 2) that
(where, for a symmetric matrix \(M \in {\mathbb {R}}^{T \times T}\), \(\Vert M\Vert _2=\underset{t=1,\ldots ,T}{\max }|\lambda _t(M)|\) denotes its spectral norm), then also the following convergence in probability holds:
where
is a symmetric and positive semi-definite matrix. In the following, its positive definiteness (hence, its invertibility) is also assumed.
Remark 3.1
The existence of the probability limit (23) and the assumed positive definiteness of the matrix \(A_N\) guarantee that the invertibility of the matrix \(\sum _{n=1}^N {{\ddot{X}}_n' \varPhi ^{+} {\ddot{X}}_n}\) (see the invertibility assumption before Eq. (9)) holds with probability near 1 for large T.
When (20), (21), and (23) hold, inserting such probability limits in Eq. (17), one gets the following large-sample approximation of the conditional generalization error (17) with respect to T:
where, for a vector \({\underline{v}} \in {\mathbb {R}}^p\), \(\Vert {\underline{v}}\Vert _2\) denotes its \(l_2\) (Euclidean) norm, and \(A_N^{-\frac{1}{2}}\) is the principal square root (i.e., the symmetric and positive definite square root) of the symmetric and positive definite matrix \(A_N^{-1}\). Eq. (25) is obtained taking into account that, as a consequence of the Continuous Mapping Theorem (Florescu 2015, Theorem 7.33), the probability limit of the product of two random variables equals the product of their probability limits, when the latter two exist. By doing this, the third and sixth terms of Eq. (17) cancel out due to Eq. (21), whereas the second term is computed using Eq. (18).
Interestingly, the large-sample approximation (25) has the form \(\frac{\sigma ^2}{T} K_i\), where
is a positive constant (possibly, a different constant for each unit i). This simplifies the analysis of the trade-off between training set size and precision of supervision performed in the next section, since one does not need to compute the exact expression of \(K_i\) to find the optimal trade-off.
In Appendix 3, an extension of the analysis made above is presented, by considering, respectively, the case of large N, and the one in which both N and T are large.
4 Optimal trade-off between training set size and precision of supervision for the fixed effects generalized least squares panel data model under the large-sample approximation
In this section, we are interested in optimizing the large-sample approximation (25) of the conditional generalization error when the variance \(\sigma ^2\) is modeled as a decreasing function of the supervision cost per example c, and there is an upper bound C on the total supervision cost NTc associated with the whole training set. In the analysis, N is fixed, and T is chosen as \(\left\lfloor \frac{C}{N c} \right\rfloor\). Moreover, the supervision cost per example c is allowed to take values on the interval \([c_{\mathrm{min}}, c_{\mathrm{max}}]\), where \(0< c_{\mathrm{min}} < c_{\mathrm{max}}\), so that the resulting T belongs to \(\left\{ \left\lfloor \frac{C}{N c_{\mathrm{max}}} \right\rfloor , \ldots , \left\lfloor \frac{C}{N c_{\mathrm{min}}} \right\rfloor \right\}\). In the following, C is supposed to be sufficiently large, so that the large-sample approximation (25) can be assumed to hold for every \(c \in [c_{\mathrm{min}}, c_{\mathrm{max}}]\).
Consistently with (Gnecco and Nutarelli 2019, 2019, 2020), we adopt the following model for the variance \(\sigma ^2\), as a function of the supervision cost per example c:
where \(k,\alpha > 0\). For \(0< \alpha < 1\), the precision of each supervision is characterized by “decreasing returns of scale” with respect to its cost because, if one doubles the supervision cost per example c, then the precision \(1/\sigma ^2(c)\) becomes less than two times its initial value (or equivalently, the variance \(\sigma ^2(c)\) becomes more than one half its initial value). Conversely, for \(\alpha > 1\), there are “increasing returns of scale” because, if one doubles the supervision cost per example c, then the precision \(1/\sigma ^2(c)\) becomes more than two times its initial value (or equivalently, the variance \(\sigma ^2(c)\) becomes less than one half its initial value). The case \(\alpha =1\) is intermediate and refers to “constant returns of scale”. In all the cases above, the precision of each supervision increases by increasing the supervision cost per example c. Finally, it is worth observing that, according to the model (3) for the covariance matrix of the vector of measurement noises, the correlation coefficient between successive measurement noises does not depend on c.
Concluding, under the assumptions above, the optimal trade-off between the training set size and the precision of supervision for the fixed effects generalized least squares panel data model is modeled by the following optimization problem:
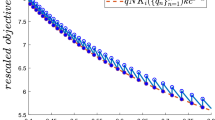
By a similar argument as in the proof of Gnecco and Nutarelli (2019, Proposition 3.2), when C is sufficiently large, the objective function \(C K_i k\frac{c^{-\alpha }}{\left\lfloor \frac{C}{N c} \right\rfloor -1}\) of the optimization problem (28), rescaled by the multiplicative factor C, can be approximated, with a negligible error in the maximum norm on \([c_{\mathrm{min}}, c_{\mathrm{max}}]\), by \(N K_i k c^{1-\alpha }\). In order to illustrate this issue, Fig. 1 shows the behavior of the rescaled objective functions \(C K_i k\frac{c^{-\alpha }}{\left\lfloor \frac{C}{N c} \right\rfloor -1}\) and \(N K_i k c^{1-\alpha }\) for the three cases \(0<\alpha = 0.5 < 1\), \(\alpha = 1.5 > 1\), and \(\alpha = 1\) (the values of the other parameters are \(k=0.5\), \(K_i=2\), \(N=10\), \(C={200}\), \(c_{\mathrm{min}}=0.4\), and \(c_{\mathrm{max}}=0.8\)). The additional approximation \({C N} K_i k\frac{c^{1-\alpha }}{C -N c}\) (which differs negligibly from \(N K_i k c^{1-\alpha }\) for large C) is also reported in the figure.
Concluding, under the approximation above, one can replace the optimization problem (28) with
whose optimal solutions \(c^\circ\) have the following expressions:
-
1.
if \(0< \alpha < 1\) (“decreasing returns of scale”): \(c^\circ = c_{\mathrm{min}}\);
-
2.
if \(\alpha > 1\) (“increasing returns of scale”): \(c^\circ = c_{\mathrm{max}}\);
-
3.
if \(\alpha = 1\) (“constant returns of scale”): \(c^\circ =\) any cost c in the interval \([c_{\mathrm{min}}, c_{\mathrm{max}}]\).
In summary, the results of the analysis show that, in the case of “decreasing returns of scale”, “many but bad” examples are associated with a smaller conditional generalization error than “few but good” ones. The opposite occurs for “increasing returns of scale”, whereas the case of “constant returns of scale” is intermediate. These results are qualitatively in line with the ones obtained in (Gnecco and Nutarelli 2019, 2019, 2020) for simpler linear regression problems, to which different regression algorithms were applied (respectively, ordinary least squares, weighted least squares, and fixed effects ordinary least squares). This depends on the fact that, in all these cases, the large-sample approximation of the conditional generalization error has the same functional form \(\frac{\sigma ^2}{T} K_i\) (although different positive constants \(K_i\) are involved in the various cases).
One can observe that, in order to discriminate among the three cases of the analysis reported above, one does not need to know the exact values of the constants \(\rho\), k, \(K_i\), and N. Moreover, to discriminate between the first two cases, it is not necessary to know the exact value of the positive constant \(\alpha\) (indeed, it suffices to know if \(\alpha\) belongs, respectively, to the interval (0, 1) or the one \((1,+\infty )\)). Interestingly, no precise knowledge of the probability distributions of the input examples (one for each unit) is needed. In particular, different probability distributions may be associated with different units, without affecting the results of the analysis. Finally, the same conclusions as above are reached if the objective function in (29) is replaced by the summation of the large-sample approximation of the conditional generalization error over all the N units. In that case, the constant \(K_i\) in (29) is replaced by \(K:=\sum _{i=1}^N K_i\).

Plots of the rescaled objective functions \(C K_i k\frac{c^{-\alpha }}{\left\lfloor \frac{C}{N c} \right\rfloor -1}\), \(C N K_i k c^{1-\alpha }\), \(C N K_i k\frac{c^{1-\alpha }}{C -N c}\), for \(\alpha = 0.5\) (a), \(\alpha = 1.5\) (b), and \(\alpha = 1\) (c). The values of the other parameters are reported in the text
5 Numerical results
In this section, the theoretical results obtained in the paper are tested through simulations. For each c, the following empirical approximation of the summation of the generalization error over all the units, conditioned on the training input data, is adopted. It is based on \({\mathcal {N}}^{tr}\) training sets and \(N^{test}_i\) test examples for each unit i (\(i=1,\ldots ,N\)), hence on a total number \(N^{test}=\sum _{i=1}^N N^{test}_i\) of test examples:
In Eq. (30), \(({\underline{x}}^{test}_{i,h}, y^{test}_{i,h})\) is the h-th generated test example for the unit i, and \(\underline{\hat{\beta }}_{FEGLS}^j\) is the estimate of the vector \(\underline{\beta }\) obtained using the j-th generated training set. Similarly, \(\hat{\eta }_{i,FEGLS}^{j}\) is the estimate of the individual constant \(\eta _i\) obtained using the j-th generated training set. For each choice of c, all the \({\mathcal {N}}^{tr}\) generated training sets share the same training input data matrices \(X_n\), but differ in the random choice of the measurement noise. The number of rows in each matrix \(X_n\) is increased when c is reduced from \(c_{\mathrm{max}}\) to \(c_{\mathrm{min}}\), by increasing the number of observations T. For a fair comparison, when doing this, the rows already present in each matrix \(X_n\) are kept fixed. Finally, the same test examples (generated independently from the training sets) are used to assess the performance of the fixed effects generalized least squares estimates for different costs per example c.
For the simulations, we choose \(N=20\) for the number of units, \(p = 5\) for the number of features, \(c_{\mathrm{min}} = 2\), \(c_{\mathrm{max}}=4\), \({\mathcal {N}}^{tr} = 100\) for the number of training sets, \(N^{test}_i=50\) for the number of test examples per unit (hence the total number of test examples is \(N^{test}=1000\)). The number of training examples per unit is \(T = 50\) for \(c=c_{\mathrm{min}}\), and \(T = 25\) for \(c=c_{\mathrm{max}}\). In this way, the (upper bound on the) total supervision cost is \(C = 2000\) for both cases. Without loss of generality, the constant k in the model (27) of the variance of the supervision cost is assumed to be equal to 1. The components of the parameter vector \(\underline{\beta }\) are generated randomly and independently according to a uniform distribution on \([-1, 1]\), obtaining
Similarly, the fixed effects \(\eta _n\) (for \(n=1,\ldots ,N\)) are generated randomly and independently according to a uniform distribution on \([-1, 1]\), obtaining the vector
For both training and test sets, the input data associated with each unit are generated as realizations of a multivariate Gaussian distribution with mean \({\underline{0}}\) and covariance matrix
which is symmetric and positive definite. This covariance matrix has been generated by setting \({\mathrm{Var}}\left( {\underline{x}}_{n,t}\right) ={\mathrm{Var}}\left( {\underline{x}}_i^{test}\right) ={A_x A_x'}\), where the elements of \({A_x} \in {\mathbb {R}}^{p \times p}\) have been randomly and independently generated according to a uniform probability density on the interval [0,1]. The parameter \(\rho\) in the covariance matrix (3) of the zero-mean vector of measurement noises (modeled in the simulations by a multivariate Gaussian distribution) is chosen to be equal to 0.3. As a robustness check, the whole procedure is repeated 100 times.
The results of the analysis are displayed in Tables 1 (for \(\alpha = 0.5\)), 2 (for \(\alpha = 1.5\)), and 3 (for \(\alpha = 1\)). Each table reports the results obtained in each repetition for \(c=c_{\mathrm{min}}\) and \(c=c_{\mathrm{max}}\). The total simulation time (for a MATLAB 9.4 implementation of the procedure) is of about 501 sec on a notebook with a 2.30 GHz Intel(R) Core(TM) i5-4200U CPU and 6 GB of RAM. A statistical analysis of the elements of the tables leads to the following conclusions:
-
1.
for \(\alpha =0.5\) (Table 1), the application of a one-sided Wilcoxon matched-pairs signed-rank test (Barlow 1989, Sect. 9.2.3) rejects the null hypothesis that the difference between the approximated performance index from Eq. (30) for \(c=c_{\mathrm{max}}\) and the one for \(c=c_{\mathrm{min}}\) has a symmetric distribution around its median and that median is smaller than or equal to 0 (p-value=\({1.9780 \cdot 10^{-18}}\), significance level set to 0.05);
-
2.
for \(\alpha =1.5\) (Table 2), the application of a one-sided Wilcoxon matched-pairs signed-rank test rejects the null hypothesis that the same difference as above has a symmetric distribution around its median and that median is larger than or equal to 0 (p-value=\({1.9780 \cdot 10^{-18}}\), significance level set to 0.05);
-
3.
for \(\alpha =1\) (Table 3), the application of a two-sided Wilcoxon matched-pairs signed-rank test fails to reject the null hypothesis that the same difference as above has a symmetric distribution around its median and that median is equal to 0 (p-value=0.4453, significance level set to 0.05).
Concluding, the tables show that the simulation results are in perfect agreement with the theoretical ones, leading to the same conclusions. Interestingly, this holds even though relatively small values for T have been chosen for the simulations.
6 Discussion and possible extensions
Up to the authors’ knowledge, the analysis and the optimization, made in the present article, of the conditional generalization error in regression as a trade-off between training set size and precision of supervision, has been carried out only rarely in the literature. In particular, the authors believe that it was never addressed for the fixed effects generalized least squares panel data model. Nevertheless, the methodology used in the present article is similar to the one exploited in the context of the optimization of sample survey design, in which some parameters of the design are optimized to minimize, e.g., the sampling variance (see, for instance, the classical solution provided by Neyman allocation for optimal stratified sampling design, in case the dataset has a fixed size (Groves et al. 2004). It also shares some similarity to the approach used in Nguyen et al. (2009) - in a context, however, in which linear regression is marginally involved, since only arithmetic averages of measurement results are considered - for the optimal design of measurement devices. Finally, the present article can also be related to some recent works which, according to an emerging trend in the literature, combine methods from machine learning, optimization, and econometrics (Athey and Imbens 2016; Bargagli Stoffi and Gnecco 2018, 2020; Varian 2014) (e.g., the generalization error - which is typically considered in machine learning, and optimized by solving suitable optimization problems - is not investigated in the classical analysis of the fixed effects generalized least squares panel data model (Wooldridge 2002, Chapter 10)). In this way, the interaction between machine learning and optimization—which appears commonly in the literature (Bennett and Parrado-Hernández 2006; Bianchini et al. 1998; Gnecco et al. 2013; Gori 2017; Özöğür-Akyüz et al. 2011; Sra et al. 2011)—is extended to the econometrics field.
For what concerns practical applications, the theoretical results obtained in the analysis made in this work could be applied to the acquisition design of fixed effects panel data in both microeconometrics and macroeconometrics (Greene 2003, Chapter 13). A semi-artificial validation on existing datasets could also be performed by inserting artificial noise with variance expressed as in Eq. (27), possibly with the inclusion of an additional constant term in that variance, to model the case of the original dataset before the insertion of the artificial noise. As a possible extension, one could investigate and optimize the trade-off between training set size and precision of supervision for the unbalanced FEGLS case (in which different units are associated with possibly different numbers of observations)Footnote 5, for the situation in which some parameters of the noise model have to be estimated either from the data or from a subset of the data, and for the case of a non-zero correlation of measurement errors for the observations associated with different units. Such developments could open the way to the application of the proposed framework to real-world problems, e.g., in econometrics. Another possible extension concerns the replacement in the investigation of the fixed effects panel data model with the random effects one (Greene 2003, Chapter 13), which is also commonly applied to deal with the analysis of economic data, and differs from the fixed effects panel data model in that its parameters are random variablesFootnote 6. In the present analysis, however, a possible advantage of the fixed effects panel data model is that it also makes it possible to get estimates of the individual constants \(\eta _n\) (see Eq. (12)), which appear in the expression (16) of the conditional generalization error. Finally, another possible extension involves the case of dynamic panel data models (Cameron and Trivedi 2005, Chapter 21).
Availability of data and material
The data used for the simulation results are available upon request to the corresponding author.
Code availability
The MATLAB code written to get the simulation results is available upon request to the corresponding author.
Notes
An important implication of first-order serial covariance in noise terms is the unreliability of classical test statistics, based on the assumption of uncorrelated noises (see, e.g., Im et al. (1999)). To deal with this issue, the usual approach adopted in the literature consists in explicitly taking into account the form (3) for the covariance matrix of the zero-mean vector of measurement noises associated with each unit.
It is recalled here from Strang (1993) that the Moore-Penrose pseudoinverse \(M^+\) of a matrix \(M \in {\mathbb {R}}^{T \times T}\) inverts a special restriction of the linear application represented by the matrix M, whose domain and codomain are restricted, respectively, to the row space of M and to the column space of M (which coincide in the case of a symmetric matrix). For a matrix \(M \in {\mathbb {R}}^{T \times T}\) with singular value decomposition \(M=U \varSigma V'\) (where \(U, V \in {\mathbb {R}}^{T \times T}\) are orthogonal matrices, and \(\varSigma \in {\mathbb {R}}^{T \times T}\) is a diagonal matrix whose non-zero entries are the singular values of M), the singular value decomposition of its Moore-Penrose pseudoinverse is \(M^+= U \varSigma ^+ V'\) (where \(\varSigma ^+ \in {\mathbb {R}}^{T \times T}\) is a diagonal matrix whose non-zero entries are the reciprocals of the singular values of M). Finally, in the particular case in which M is symmetric and positive semi-definite (e.g., when it is a covariance matrix), its singular values coincide with its positive eigenvalues, \(U \in {\mathbb {R}}^{T \times T}\) is an orthogonal matrix whose columns are its eigenvectors, \(V'=U^{-1}\), and \(M^+\) is symmetric and positive semi-definite. The concept of Moore-Penrose pseudoinversion can be extended to the cases of rectangular matrices and matrices with complex entries, but such extensions are not needed in this work.
We recall that a sequence of random real matrices \(M_{T}\), \(T=1,2,\ldots\), converges in probability to the real matrix M if, for every \(\varepsilon >0\), \({\mathrm{Prob}} \left( \left\| M_{T} - M\right\| > \varepsilon \right)\) (where \(\Vert \cdot \Vert\) is an arbitrary matrix norm) tends to 0 as T tends to \(+\infty\). In this case, we write \(\underset{T \rightarrow +\infty }{\mathrm{plim}} M_T=M\).
This does not exclude the possibility for the \({\underline{x}}_{n,t}\) and \({\underline{x}}_{m,t}\) associated with different units n and m to be dependent/not identically distributed.
The unbalanced case in which all the measurement errors are uncorrelated - therefore, the FEGLS model is replaced in the analysis by the simpler Fixed Effects (FE) model - is the subject of our recent work Gnecco et al. (2020).
If the additional assumptions of the random effects model hold, then both the fixed and the random effects estimates are consistent, but the latter is more efficient than the former. However, if they do not hold, then the random effects model provides inconsistent estimates (Greene 2003, Chapter 13).
We recall that a matrix \(M \in {\mathbb {R}}^{T \times T}\) is a symmetric Toeplitz matrix if it has the form
$$\begin{aligned} M= \begin{bmatrix} m_0 &{} m_1 &{} m_2 &{} \cdots &{} m_{T-2} &{} m_{T-1} \\ m_1 &{} m_0 &{} m_1 &{} m_2 &{} \cdots &{} m_{T-2} \\ m_2 &{} m_1 &{} m_0 &{} m_1 &{} \cdots &{} m_{T-3} \\ \cdots &{} \cdots &{} \cdots &{} \cdots &{} \cdots &{} \cdots \\ m_{T-1} &{} m_{T-2} &{} \cdots &{} m_2 &{} m_1 &{} m_0 \end{bmatrix}\,, \end{aligned}$$(A.18)where \(m_0,m_1,\ldots ,m_{T-1} \in {\mathbb {R}}\).
We recall that a sequence of random real variables \(b_T\), \(T=1,2,\ldots\), converges almost surely to \(b \in {\mathbb {R}}\) if \({\mathrm{Prob}}(\underset{T \rightarrow +\infty }{\lim }b_T = b)=1\)
We recall that a symmetric circulant matrix is a symmetric Toeplitz matrix (see footnote 7) with \(m_t=m_{T-t}\), for \(t=1,\ldots ,T-1\) (Gray 2006).
For example, \((Q_T C_T Q_T') (Q_T C_T^{-1} Q_T') (Q_T C_T Q_T')=(Q_T C_T Q_T')\) is checked by using a common basis of eigenvectors \({\underline{e}}_i \in {\mathbb {R}}^T\) (for \(i=1,\ldots ,T\)) of \(Q_T\) and \(C_T\), i.e., by showing that \((Q_T C_T Q_T') (Q_T C_T^{-1} Q_T') (Q_T C_T Q_T') {\underline{e}}_i=(Q_T C_T Q_T') {\underline{e}}_i\) for each such eigenvector.
Otherwise, if \({\underline{1}}_T\) were an eigenvector of \(\varPsi\), one could proceed likewise in item vi) of the proof of Eq. (A.46).
This assumption could be relaxed in order to apply in the analysis another suitable form of the weak law of large numbers, valid for the case of dependent/not identically distributed random variables.
This follows from the fact that the large-sample approximation (A.51) of the conditional generalization error is a decreasing function of N, for each fixed choice of the measurement noise variance \(\sigma ^2\), hence for each choice of c.
References
Aitken A. C. (1936). On least-squares and linear combinations of observations, Proceedings of the Royal Society of Edinburgh, 55, pp. 42-48.
Arellano, M. (2004). Panel data econometrics. Oxford: Oxford University Press.
Athey, S., & Imbens, G. (2016). Recursive partitioning for heterogeneous causal effects. Proceedings of the National Academy of Sciences, 113, 7353–7360.
Bai, Z., Cheng, P. E., & Zhang, C.-H. (1997). An extension of the Hardy-Littlewood strong law. Statistica Sinica, 7, 923–928.
Barata, J. C. A., & Hussein, M. S. (2012). The Moore-Penrose pseudoinverse: A tutorial review of the theory. Brazilian Journal of Physics, 42, 146–165.
Bargagli Stoffi, F. J., & Gnecco, G. (2018). Estimating heterogeneous causal effects in the presence of irregular assignment mechanisms, in Proceedings of the \(5^{\rm th}\) IEEE International Conference on Data Science and Advanced Analytics (IEEE DSAA 2018), Turin, Italy, pp. 1-10.
Bargagli Stoffi, F. J., & Gnecco, G. (2020). Causal tree with instrumental variable: An extension of the causal tree framework to irregular assignment mechanisms. International Journal of Data Science and Analytics, 9, 315–337.
Barlow, R. J. (1989). Statistics: A guide to the use of statistical methods in the physical sciences. Hoboken: Wiley.
Bennett, K. P., & Parrado-Hernández, E. (2006). The interplay of optimization and machine learning research. Journal of Machine Learning Research, 7, 1265–1281.
Bhargava, A., Franzini, L., & Narendranathan, W. (1982). Serial correlation and the fixed effects model. Review of Economic Studies, 49, 533–549.
Bianchini, M., Frasconi, P., Gori, M., & Maggini, M. (1998). Optimal learning in artificial neural networks: A theoretical view. In: Leondes, C. T. (ed.), Neural networks systems, techniques and applications, (pp. 1-51).
Cameron, A. C., & Trivedi, P. K. (2005). Microeconometrics: Methods and applications. Cambridge: Cambridge University Press.
Dattorro, J. (2019). Convex analysis \(\dagger\) Euclidean distance geometry, \({\cal{M}}\varepsilon \beta oo\) Publishing, https://web.stanford.edu/group/SOL/Books/0976401304.pdf.
Florescu, I. (2015). Probability and stochastic processes. Hoboken: Wiley.
Frees, E. W. (2004). Longitudinal and panel data: Analysis and applications in the social sciences. Cambridge: Cambridge University Press.
Gerschgorin, S. (1931). Über die abgrenzung der eigenwerte einer matrix. Izvestija Akademii Nauk SSSR, Serija Matematika, 7, 749–754.
Gilgen, H. (2006). Univariate time series in geosciences: Theory and examples. Berlin: Springer.
Gnecco, G., Gori, M., & Sanguineti, M. (2013). Learning with boundary conditions. Neural Computation, 25, 1029–1106.
Gnecco G., & Nutarelli, F. (2019). On the trade-off between number of examples and precision of supervision in regression problems, in Proceedings of the \(4^{\rm th}\) International Conference of the International Neural Network Society on Big Data and Deep Learning (INNS BDDL 2019), Sestri Levante, Italy, pp. 1-6.
Gnecco, G., & Nutarelli, F. (2019). On the trade-off between number of examples and precision of supervision in machine learning problems. Optimization Letters. https://doi.org/10.1007/s11590-019-01486-x.
Gnecco, G., & Nutarelli, F. (2020). Optimal trade-off between sample size and precision of supervision for the fixed effects panel data model. In Proceedings of the \(5^{\rm th}\) International Conference on machine Learning, Optimization & Data science (LOD 2019), Certosa di Pontignano (Siena), Italy. Lecture Notes in Computer Science, vol. 11943, pp. 1-12.
Gnecco, G., Nutarelli, F., & Selvi, D. (2020). Optimal trade-off between sample size, precision of supervision, and selection probabilities for the unbalanced fixed effects panel data model. Soft Computing, 24, 15937–15949.
Gori, M. (2017). Machine learning: A constraint-based approach. Burlington: Morgan Kaufmann.
Gray, R. M. (2006). Toeplitz and circulant matrices: A review. Delft: Now Publishers.
Greene, W. H. (2003). Econometric analysis. Delhi: Pearson Education.
Groves, R. M., Fowler, F. J., Jr., Couper, M. P., Lepkowski, J. M., Singer, E., & Tourangeau, R. (2004). Survey methodology. Hoboken: Wiley-Interscience.
Härdle, W., Mori, Y., & Vieu, P. (2007). Statistical methods for biostatistics and related fields. Berlin: Springer.
Hastie, T., Tibshirani, R., & Friedman, J. (2009). The elements of statistical learning: Data mining, inference, and prediction. Berlin: Springer.
Im, K. S., Ahn, S. C., Schmidt, P., & Wooldridge, J. M. (1999). Efficient estimation of panel data models with strictly exogenous explanatory variables. Journal of Econometrics, 93, 177–201.
Lee, M.-J. (2010). Micro-econometrics: Methods of moments and limited dependent variables. Berlin: Springer.
Kiefer, N. M. (1980). Estimation of fixed effect models for time series of cross-sections with arbitrary intertemporal covariance. Journal of Econometrics, 14, 195–202.
Maciejewski, A. A., & Klein, C. A. (1985). Obstacle avoidance for kinematically redundant manipulators in dynamically varying environments. International Journal of Robotics Research, 4, 109–116.
Nguyen, H. T., Kosheleva, O., Kreinovich, V., & Ferson, S. (2009). Trade-off between sample size and accuracy: Case of measurements under interval uncertainty. International Journal of Approximate Reasoning, 50, 1164–1176.
Özöğür-Akyüz, S., Ünay, D., & Smola, A. (2011). Guest editorial: Model selection and optimization in machine learning. Machine Learning, 85, 1–12.
Parlett, B. N. (1998). The symmetric eigenvalue problem. Philadelphia: SIAM.
Rao, C. P. (1973). Linear statistical inference and its applications. Hoboken: Wiley.
Reeve, C. P. (1988). A new statistical model for the calibration of force sensors, NBS Technical Note 1246, National Bureau of Standards, pp. 1-41.
Ruud, P. A. (2000). An introduction to classical econometric theory. Oxford: Oxford University Press.
Sra, S., Nowozin, S., & Wright, S. J. (Eds.). (2011). Optimization for machine learning. Cambridge: MIT Press.
Strang, G. (1993). The fundamental theorem of linear algebra. The American Mathematical Monthly, 100, 848–855.
Sun, F.-W. (2003). On the convergence of the inverses of Toeplitz matrices and its applications. IEEE Transactions in Information Theory, 40, 180–190.
Vapnik, V. N. (1998). Statistical learning theory. Hoboken: Wiley-Interscience.
Varian, H. R. (2014). Big data: New tricks for econometrics. Journal of Economic Perspectives, 28, 3–38.
Wedin, P. A. (1973). Perturbation theory for pseudo-inverses. BIT, 13, 217–232.
Wooldridge, J. M. (2002). Econometric analysis of cross section and panel data. Cambridge: MIT Press.
Funding
Open access funding provided by Scuola IMT Alti Studi Lucca within the CRUI-CARE Agreement. G. Gnecco and F. Nutarelli are members of GNAMPA (Gruppo Nazionale per l’Analisi Matematica, la Probabilità e le loro Applicazioni) - INdAM (Istituto Nazionale di Alta Matematica). The work was partially supported by the 2020 Italian project “Trade-off between Number of Examples and Precision in Variations of the Fixed-Effects Panel Data Model”, funded by INdAM-GNAMPA.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflicts of interest/competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Editor: Bart Baesens.
Appendices
Appendix 1: proofs of Eqs. (17), (18), and (19)
To simplify the notation, here and in the next appendices, \(Q_T\) will be often replaced by the shorthand Q. Also the dependence of \(\varPsi\) and \(\varPhi\) and other matrices/vectors on T will be typically omitted in the notation, apart from a few cases (e.g., in part of Appendix 2).
Proof of Eq. (17)
For \(n=1,\ldots ,N\), let \(\underline{\eta }_n \in {\mathbb {R}}^T\) be the column vector whose elements are all equal to \(\eta _n\). Using the expressions (1), (2), (6), and (9) respectively of \(y_{n,t}\), \(z_{n,t}\), \(\underline{\ddot{z}}_n\), and \(\underline{\hat{\beta }}_{FEGLS}\), and
one can write the term \(\underline{\hat{\beta }}_{FEGLS}-\underline{\beta }\) as follows:
In the following, to simplify the notation, we set \(B:=\left( \sum _{n=1}^N {{\ddot{X}}_n' \varOmega ^{+} {\ddot{X}}_n}\right) ^{-1}\) and \({\underline{b}}:=\sum _{n=1}^N {{\ddot{X}}_n' \varOmega ^{+} \ddot{\underline{\varepsilon }}_n}\).
Now, we expand the conditional generalization error (16) as follows:
Exploiting the conditional unbiasedness of \(\hat{\eta }_{i,FEGLS}\), and the expressions (1) of \(y_{n,t}\), (2) of \(z_{n,t}\), and (12) of \(\hat{\eta }_{i,FEGLS}\) (with the index n replaced by the index i), one gets
Then, taking into account (A.2) and (A.4), one gets
Expanding the square in the first term in the expression above, and splitting its last term in two parts, one obtains
In order to simplify the expressions above, one exploits the following properties:
for \(n \ne m\) (being \({\underline{0}}_{T \times T} \in {\mathbb {R}}^{T \times T}\) the matrix whose elements are all equal to 0), and
Then, expanding \({\underline{b}}\) and exploiting also the facts that \(\varOmega ^+ \varOmega \varOmega ^+=\varOmega\), \(B=B'\), the matrix \(\varOmega ^+\) is symmetric and deterministic, and all the \({\ddot{X}}_n\) are known once all the \({\underline{x}}_{n,t}\) are given, one gets
Finally, inserting (A.9) in (A.6), expanding the expressions of B and \({\underline{b}}\), and recalling that \({\mathbb {E}} \left\{ {\underline{\varepsilon }_i} {\underline{\varepsilon }_i'} \right\} =\sigma ^2 \varPsi\), one obtains Eq. (17). \(\square\)
Proof of Eq. (18)
The expression \({\underline{1}}_{{T}}' {\varPsi } {\underline{1}}_{{T}}\) in Eq. (18) is the summation of all the elements of the matrix \(\varPsi\). Now, the element \(\rho ^0=1\) appears in that summation T times, whereas the generic element \(\rho ^t\) (for \(t=1,\ldots ,{T-1})\) appears \(2(T-t)\) times. Hence,
Then, Eq. (18) is obtained from (A.10) by exploiting the following well-known expressions for the partial sums of the geometric series, and of its derivative:
and
where the right-hand side in Eq. (A.12) has been obtained by simplifying common factors in the numerator and the denominator. \(\square\)
Proof of Eq. (19)
We compute \(Q {\varPsi } {\underline{1}}_{T}\), as follows:
where the expression above of \(({\underline{1}}_T' \varPsi {\underline{1}}_T) {\underline{1}}_T\) comes from Eq. (18). Finally, Eq. (19) is obtained from Eq. (A.13) by expanding the elements of \({\varPsi } {\underline{1}}_{T}\), then simplifying the resulting expressions. \(\square\)
Appendix 2: proofs of the probability limits in Section 3
In the following, Eqs. (20) and (21) are derived under the common assumption that, for the unit i, the \({\underline{x}}_{i,t}\) are mutually independent, identically distributed, and have finite moments up to the order 4. To derive Eq. (23), one makes the similar assumption that, for each fixed unit n, the \({\underline{x}}_{n,t}\) are mutually independent, identically distributed, and have finite moments up to the order 4, together with the additional assumption \(\underset{T \rightarrow \infty }{\lim }\Vert \varPhi ^+-Q \varPsi ^{-1} Q'\Vert _2=0\) reported in Eq. (22). The validity of this last assumption is discussed extensively at the end of this appendix. Eqs. (20), (21), and (23) could be derived under more general conditions, but such possible extension is out of the scope of the paper.
Proof of Eq. (20)
Eq. (20) simply replaces the empirical average of the transposes of the \({\underline{x}}_{n,t}\) (which is \(\frac{1}{T} {\underline{1}}_{T}' {X}_i\)) with their common expected value \(\left( {\mathbb {E}} \left\{ {\underline{x}}_{i,1}\right\} \right) '\), and follows from Chebyschev’s weak law of large numbers (Ruud 2000, Sect. 13.4.2). \(\square\)
Proof of Eq. (21)
In order to prove Eq. (21), it is convenient to introduce (recalling the definition of \({\underline{u}}_T\) provided in Eq. (19)) the vector
since the argument of the probability limit in Eq. (21) can be written as follows:
In other words, the T elements of each row of \(X_i'\) are summed with (different and deterministic) weights \(v_{T,t}\) (the components of \({\underline{v}}_{T})\), for \(t=1,\ldots ,T\), then their weighted sum is divided by T. This suggests the application of a suitable form of the law of large numbers, which holds in this case: specifically, the one provided in (Bai et al. 1997, Theorem 2.1)). In view of the next application of that theorem, first we investigate the following properties of the various terms involved in Eqs. (A.14) and (A.15).
-
(i)
The Euclidean norm of the vector \({\underline{u}}_T\) is bounded from above as follows, for \(K_u>0\) independent from T:
$$\begin{aligned} \Vert {\underline{u}}_T\Vert _2 \le K_u \sqrt{T}\,. \end{aligned}$$(A.16)This follows from the fact that the absolute values of all the components of the vector \({\underline{u}}_T\), whose expression is reported in Eq. (19), are bounded from above by a sufficiently large \(K_u>0\), which is independent from T.
-
(ii)
All the eigenvalues of the matrix \(\varPsi\) belong to the interval \(\left[ \frac{1-\rho ^2}{1+\rho ^2+2\rho }, \frac{1-\rho ^2}{1+\rho ^2-2\rho }\right] \subset (0,+\infty )\). This result follows by observing that \(\varPsi\) is a symmetric Toeplitz matrixFootnote 7 (Gray 2006). Then, by (Gray 2006, Lemma 4.1), all the eigenvalues of \(\varPsi\) belong to the interval \([m_f,M_f]\), where \(m_f\) and \(M_f\) are respectively the minimum and the maximum of the function
$$\begin{aligned} f(\lambda ):=\sum _{k=-\infty }^{+\infty } \rho ^{|k|} e^{\iota k \lambda } \end{aligned}$$(A.19)on the interval \([0, 2\pi ]\), and \(\iota\) is the imaginary unit. By inverting the Fourier series above as in (Gilgen 2006, Eqs. (7.77–7.79)), one gets
$$\begin{aligned} f(\lambda )=\frac{1-\rho ^2}{1+\rho ^2-2\rho \cos (\lambda )}\,, \end{aligned}$$(A.20)from which one gets \(m_f=\frac{1-\rho ^2}{1+\rho ^2+2\rho }>0\) and \(M_f=\frac{1-\rho ^2}{1+\rho ^2-2\rho }<+\infty\) since \(\rho \in (-1,1)\), which concludes the proof of item ii).
-
(iii)
The matrix \(\varPhi\) has 0 as eigenvalue with multiplicity 1, and an associated eigenvector is \({\underline{1}}_T\).
This result follows from the characterization of the eigenvalues of a symmetric matrix \(M \in {\mathbb {R}}^{T \times T}\) as the stationary values of its Rayleigh quotient \(\frac{{\underline{x}}' M {\underline{x}}}{{\underline{x}}' {\underline{x}}}\) (with \({\underline{x}} \in {\mathbb {R}}^{T}\) and \({\underline{x}} \ne {\underline{0}}_T\)) (Parlett 1998, Chapter 1), the invertibility of the matrix \(\varPsi\), and the fact that Q has eigenvalue 0 with multiplicity 1, and associated eigenvector \({\underline{1}}_T\). Hence, for \({\underline{x}} \ne {\underline{0}}_T\), \(\frac{{\underline{x}}' M {\underline{x}}}{{\underline{x}}' {\underline{x}}}=0\) if and only \({\underline{x}}\) is proportional to \({\underline{1}}_T\).
-
(iv)
All the other eigenvalues of \(\varPhi\) belong to the interval \(\left[ \frac{1-\rho ^2}{1+ \rho ^2+2\rho },\frac{1-\rho ^2}{1+ \rho ^2-2\rho }\right] \subset (0,+\infty )\).
This follows again from the characterization of the eigenvalues of a symmetric matrix as the stationary values of its Rayleigh quotient, and also from Courant-Fisher’s maxmin theorem (Parlett 1998, Theorem 10.2.1) and from item ii). Indeed, by ordering the (real) eigenvalues of \(\varPsi\) and \(\varPhi\) respectively as \(\lambda _1(\varPsi ) \le \lambda _2(\varPsi ) \le \ldots \lambda _T(\varPsi )\) and \(\lambda _1(\varPhi ) \le \lambda _2(\varPhi ) \le \ldots \lambda _T(\varPhi )\), and recalling that \({\underline{x}}' \varPhi {\underline{x}}={\underline{x}}' Q \varPsi Q' {\underline{x}}={\underline{x}}' \varPsi {\underline{x}}\) for any \({\underline{x}} \in {\mathbb {R}}^T\) orthogonal to \({\underline{1}}_T\), one gets
from Courant-Fisher’s maxmin theorem, whereas
is obtained by expressing \(Q' {\underline{x}}\) by using a basis of orthonormal eigenvectors \({\underline{e}}_t\) of \(\varPsi\), associated with the respective eigenvalues \(\lambda _t(\varPsi )\), \(t=1,\ldots ,T\). Indeed, for some coefficients \(\alpha _t\), \(t=1,\ldots ,T\) (depending on \({\underline{x}}\)), one has
hence
whereas
Then, one gets
for any \({\underline{x}} \ne {\underline{0}}_T\).
-
(v)
All the non-zero eigenvalues of the matrix \(\varPhi ^+\) belong to the interval \(\left[ \frac{1+ \rho ^2-2\rho }{1-\rho ^2},\frac{1+ \rho ^2+2\rho }{1-\rho ^2}\right] \subset (0,+\infty )\).
This follows from items iii) and iv) and the relation between the singular value decomposition of a symmetric positive semi-definite matrix and the singular value decomposition of its Moore-Penrose pseudoinverse, which has been reported in footnote 2.
-
(vi)
The Euclidean norm of the vector \({\underline{v}}_T\) is bounded from above as follows, for \(K_v>0\) independent from T:
$$\begin{aligned} \Vert {\underline{v}}_T\Vert _2 \le K_v \sqrt{T}\,. \end{aligned}$$(A.26)This is obtained by combining the definition of \({\underline{v}}_T\) provided in Eq. (A.14) with items i) and v), and the fact that the eigenvalue with maximus modulus of \(Q=Q'\) is 1. A possible expression for \(K_v\) is \(K_v=\frac{1+ \rho ^2+2\rho }{1-\rho ^2} K_u\).
-
(vii)
The following holds:
$$\begin{aligned} \underset{T \rightarrow \infty }{\limsup }\frac{1}{\sqrt{T}} \Vert {\underline{v}}_T\Vert _2 \le K_v < +\infty \,. \end{aligned}$$(A.27)This is obtained immediately from item vi).
To conclude the proof of Eq. (21), we first consider the case in which, for the unit i, all the \({\underline{x}}_{i,t}\) have mean \({\underline{0}}_p\). Later, this additional assumption is removed.
-
(viii)
Proof of Eq. (21) when all the \({\underline{x}}_{i,t}\) have mean \({\underline{0}}_p\).
Item vii) and the fact that all the elements of each row of \(X_i'\) have 0 mean, are independent, identically distributed, and their moments up to the order 4 are finite allow one to apply (Bai et al. 1997, Theorem 2.1), getting the following result, where, for \(r=1,\ldots ,p\), \((X_i' {\underline{v}}_T)_r\) denotes the r-th component of \(X_i' {\underline{v}}_T\):
$$\begin{aligned} \underset{T \rightarrow \infty }{\limsup }\frac{|(X_i' {\underline{v}}_T)_r|}{T^{\frac{3}{4}} (\log T)^{\frac{1}{4}}}=0 \,\,{\mathrm{almost surely}}\,\,\, \end{aligned}$$(A.28).Footnote 8 This, combined with the inequalities
$$\begin{aligned} 0 \le \underset{T \rightarrow \infty }{\liminf }\frac{|(X_i' {\underline{v}}_T)_r|}{T} \le \underset{T \rightarrow \infty }{\limsup }\frac{|(X_i' {\underline{v}}_T)_r|}{T} \le \underset{T \rightarrow \infty }{\limsup }\frac{|(X_i' {\underline{v}}_T)_r|}{T^{\frac{3}{4}} (\log T)^{\frac{1}{4}}} \end{aligned}$$(A.29)and the fact that almost sure convergence implies convergence in probability (Rao 1973), shows that, for all \(r=1,\ldots ,p\), one has
$$\begin{aligned} \underset{T \rightarrow +\infty }{\mathrm{plim}} {\frac{1}{T} (X_i' {\underline{v}}_{T})_r}=0\,. \end{aligned}$$(A.30)To conclude, one gets Eq. (21) from Eqs. (A.15) and (A.30), by exploiting the fact that, for a sequence of random matrices with fixed dimension, element-wise convergence in probability implies convergence in probability of the whole sequence (Lee 2010).
-
(ix)
Proof of Eq. (21) when all the \({\underline{x}}_{i,t}\) have the same mean \({\underline{m}} \in {\mathbb {R}}^p\).
We set \(\underline{{\bar{x}}}_{i,t}:={\underline{x}}_{i,t}-{\underline{m}}\), in such a way that the \(\underline{{\bar{x}}}_{i,t}\) have mean \({\underline{0}}_p\). Similarly, we set \({\bar{X}}_i=X_i-{\underline{1}}_T {\underline{m}}'\). Since \({\ddot{X}}_i=Q X_i=Q({\bar{X}}_i+{\underline{1}}_T {\underline{m}}')=Q{\bar{X}}_i= \ddot{{\bar{X}}}_i\), one reduces the analysis to the one made in item viii).
Remark 6.1
As a variation of item ii), a simpler argument (not based on the theory of Toeplitz matrices) can be used to prove that all the eigenvalues of the matrix \(\varPsi\) belong to the interval \(\left[ 1-\frac{2 \rho }{1-\rho },1+\frac{2 \rho }{1-\rho }\right]\). This result follows by seeing the matrix \(\varPsi\) as a perturbation of the identity matrix, then applying Gershgorin’s circle theorem (Gerschgorin 1931). Indeed, all the eigenvalues of \(\varPsi\) (which are non-negative since \(\varPsi\) is symmetric and positive semi-definite) belong to the union of the T Gershgorin’s circles \({{\mathcal {C}}}_i\) (\(i=1,\ldots ,T\)) in the complex plane, which have the same center 1 and respective radii \(\sum _{j=1,\ldots ,T,j\ne i} |{\varPsi }_{ij}|\). The latter radii can be bounded from above by \(\frac{2 \rho }{1-\rho }\), which follows from a geometric series argument based on Eq. (A.11). We have preferred to use in the main text the argument based on Toeplitz matrices, since imposing \(\left[ 1-\frac{2 \rho }{1-\rho },1+\frac{2 \rho }{1-\rho }\right] \subset (0,+\infty )\) requires the additional assumption \(\rho < \frac{1}{3}\) (instead, \(\left[ \frac{1-\rho ^2}{1+\rho ^2+2\rho }, \frac{1-\rho ^2}{1+\rho ^2-2\rho }\right] \subset (0,+\infty )\) holds for any \(\rho \in (-1,1)\)). Moreover, such argument produces an even better estimate (when \(\sum _{j=1,\ldots ,T,j\ne i} |{\varPsi }_{ij}|\) is replaced by its upper bound \(\frac{2 \rho }{1-\rho }\)), since \(1-\frac{2 \rho }{1-\rho }<\frac{1-\rho ^2}{1+\rho ^2+2\rho }\) and \(1+\frac{2 \rho }{1-\rho }=\frac{1-\rho ^2}{1+\rho ^2-2\rho }\), hence \(\left[ \frac{1-\rho ^2}{1+\rho ^2+2\rho }, \frac{1-\rho ^2}{1+\rho ^2-2\rho }\right] \subset \left[ 1-\frac{2 \rho }{1-\rho },1+\frac{2 \rho }{1-\rho }\right]\).
Proof of Eq. (23)
To make the reading easier, the proof of Eq. (23) is divided into several steps.
-
(i)
The following holds:
$$\begin{aligned} Q' \varPhi ^+ Q=\varPhi ^+\,. \end{aligned}$$(A.31)This is obtained as follows. First, since the matrix \(Q=Q'\) is idempotent, one gets
$$\begin{aligned} Q' \varPhi ^+ Q=\varPhi ^+ Q \end{aligned}$$(A.32)by (Maciejewski and Klein 1985, Appendix). Additionally, since Moore-Penrose pseudoinversion commutes with transposition (Barata and Hussein 2012), we get
$$\begin{aligned} \left( \varPhi ^+ Q\right) '=Q' \left( \varPhi ^+\right) '=Q' \left( \varPhi '\right) ^+=Q' \varPhi ^+=\varPhi ^+\,, \end{aligned}$$(A.33)where the last step follows again by (Maciejewski and Klein 1985, Appendix) and by the symmetry of \(\varPhi\). Transposing Eq. (A.33) and combining it with the symmetry of \(\varPhi ^+\) and with Eq. (A.32), we get Eq. (A.31).
-
(ii)
The following decomposition holds:
$$\begin{aligned} {\ddot{X}}_n' \varPhi ^+ {\ddot{X}}_n= & {} X_n' Q'\varPhi ^+ Q X_n =X_n' \varPhi ^+ X_n =X_n' \left[ \varPhi ^+ -Q \varPsi ^{-1} Q'\right] X_n + X_n' Q \varPsi ^{-1} Q' X_n\,. \end{aligned}$$(A.34)This is obtained straightforwardly, by applying item i) to get the second equality.
-
(iii)
Under the assumption \(\underset{T \rightarrow \infty }{\lim }\Vert \varPhi ^+-Q \varPsi ^{-1} Q'\Vert _{2}=0\) stated in Eq. (22), the following probability limit holds:
$$\begin{aligned} \underset{T \rightarrow +\infty }{\mathrm{plim}} \frac{1}{T} X_n' \left[ \varPhi ^+ -Q \varPsi ^{-1} Q'\right] X_n=0_{p \times p}\,. \end{aligned}$$(A.35)This is obtained as follows. Denoting by \(\epsilon >0\) an upper bound on the spectral norm of the matrix \(\varPhi ^+ -Q \varPsi ^{-1} Q'\) and by \({\underline{c}}_{n,h}\) the h-th column of \(X_n\), the absolute value of the element in position (h, k) of the matrix \(X_n' \left[ \varPhi ^+ -Q \varPsi ^{-1} Q'\right] X_n\) can be bounded from above as follows:
$$\begin{aligned} |(X_n' \left[ \varPhi ^+ -Q \varPsi ^{-1} Q'\right] X_n)_{h,k}| \le \epsilon \Vert {\underline{c}}_{n,h}\Vert _2 \Vert {\underline{c}}_{n,k}\Vert _2 \le \frac{1}{2} \epsilon (\Vert {\underline{c}}_{n,h}\Vert ^2+\Vert {\underline{c}}_{n,k}\Vert _2^2)\,, \end{aligned}$$(A.36)where Cauchy-Schwarz inequality has been applied, together with the elementary inequality \(|a| |b| \le \frac{a^2+b^2}{2}\), for \(a,b \in {\mathbb {R}}\). Since by the assumption \(\underset{T \rightarrow \infty }{\lim }\Vert \varPhi ^+-Q \varPsi ^{-1} Q'\Vert _{2}=0\) stated in Eq. (22) one can make \(\epsilon\) tend to 0 as T tends to \(+\infty\), and both \(\Vert {\underline{c}}_{n,h}\Vert _2^2\) and \(\Vert {\underline{c}}_{n,k}\Vert _2^2\) are summations of T independent and identically distributed random variables with finite mean and finite second order moments, by applying Chebyschev’s weak law of large numbers, one gets
$$\begin{aligned} \underset{T \rightarrow +\infty }{\mathrm{plim}} \frac{1}{T} |(X_n' \left[ \varPhi ^+ -Q \varPsi ^{-1} Q'\right] X_n)_{h,k}|=0\,. \end{aligned}$$(A.37)Finally, one gets Eq. (A.35) from Eq. (A.37), since for a sequence of random matrices with fixed dimension, element-wise convergence in probability implies convergence in probability of the whole sequence (Lee 2010).
-
(iv)
The following probability limit holds:
$$\begin{aligned} \underset{T \rightarrow +\infty }{\mathrm{plim}} \frac{1}{T} X_n' Q \varPsi ^{-1} Q' X_n=\frac{1+\rho ^2}{1-\rho ^2}{\mathbb {E}} \left\{ \left( {\underline{x}}_{n,1} - {\mathbb {E}} \left\{ {\underline{x}}_{n,1}\right\} \right) \left( {\underline{x}}_{n,1} - {\mathbb {E}} \left\{ {\underline{x}}_{n,1}\right\} \right) '\right\} \,. \end{aligned}$$(A.38)This is obtained as follows. Exploiting the symmetry of Q and the following Cholesky factorization (see, e.g. (Ruud 2000, Sect. 19.2))
$$\begin{aligned} \varPsi ^{-1}= \left( C_{\mathrm{Chol}}^{-1}\right) ' C_{\mathrm{Chol}}^{-1}\,, \end{aligned}$$(A.39)where
$$\begin{aligned} C_{\mathrm{Chol}}^{-1}= \frac{1}{\sqrt{1-\rho ^2}}{\begin{bmatrix} \sqrt{1-\rho ^2} &{} 0 &{} 0 &{} \cdots &{} \cdots &{} 0 \\ -\rho &{} 1 &{} 0 &{} 0 &{} \cdots &{} 0 \\ 0 &{} -\rho &{} 1 &{} 0 &{} \cdots &{} 0 \\ \cdots &{} \cdots &{} \cdots &{} \cdots &{} \cdots &{} \cdots \\ 0 &{} \cdots &{} \cdots &{} 0 &{} -\rho &{} 1 \end{bmatrix}}\,, \end{aligned}$$(A.40)one gets
$$\begin{aligned} X_n' {Q} \varPsi ^{-1} {Q'} X_n={X_n' Q' \varPsi ^{-1} Q X_n}={\underline{\ddot{x}}_{n,1} \underline{\ddot{x}}_{n,1}'} +\sum _{t=2}^{T}\left( \frac{1}{\sqrt{1-\rho ^2}} ({\underline{\ddot{x}}_{n,t}}-\rho {\underline{\ddot{x}}_{n,t-1}})\right) \left( \frac{1}{\sqrt{1-\rho ^2}} ({\underline{\ddot{x}}_{n,t}}-\rho {\underline{\ddot{x}}_{n,t-1}})\right) '\,. \end{aligned}$$(A.41)Hence, from Eq. (A.41) one gets
$$\begin{aligned}&\underset{T \rightarrow +\infty }{\mathrm{plim}} \frac{1}{T} \sum _{n=1}^N X_n' {Q} \varPsi ^{-1} {Q'} X_n \nonumber \\&\quad = {\underset{T \rightarrow +\infty }{\mathrm{plim}} \frac{1}{T} \left[ \underline{\ddot{x}}_{n,1} \underline{\ddot{x}}_{n,1}' +\sum _{t=2}^{T}\left( \frac{1}{\sqrt{1-\rho ^2}} (\underline{\ddot{x}}_{n,t}-\rho \underline{\ddot{x}}_{n,t-1})\right) \left( \frac{1}{\sqrt{1-\rho ^2}} (\underline{\ddot{x}}_{n,t}-\rho \underline{\ddot{x}}_{n,t-1})\right) '\right] }\,. \end{aligned}$$(A.42)Now, we compute the probability limit in the right-hand side of Eq. (A.42) by considering separately the following various terms.
-
(iv.a)
The following holds:
$$\begin{aligned} \underset{T \rightarrow +\infty }{\mathrm{plim}} \frac{1}{T} \underline{\ddot{x}}_{n,1} \underline{\ddot{x}}_{n,1}'=0_{p \times p}\,. \end{aligned}$$(A.43)This is obtained by applying directly Chebyschev’s inequality (Ruud 2000, Section D.2), since each element of the matrix \(\underline{\ddot{x}}_{n,1} \underline{\ddot{x}}_{n,1}'\) has finite mean and finite second order moments.
-
(iv.b)
Similarly, since the addition of a finite number of terms like the one reported in Eq. (A.43) does not change the probability limit, one gets
$$\begin{aligned} \underset{T \rightarrow +\infty }{\mathrm{plim}} \frac{1}{T} \sum _{t=2}^{T} \underline{\ddot{x}}_{n,t} \underline{\ddot{x}}_{n,t}'= & {} \underset{T \rightarrow +\infty }{\mathrm{plim}} \frac{1}{T} \sum _{t=2}^{T} \underline{\ddot{x}}_{n,t-1} \underline{\ddot{x}}_{n,t-1}' \nonumber \\= & {} \underset{T \rightarrow +\infty }{\mathrm{plim}} \frac{1}{T} \sum _{t=1}^{T} \underline{\ddot{x}}_{n,t} \underline{\ddot{x}}_{n,t}' \nonumber \\= & {} \underset{T \rightarrow +\infty }{\mathrm{plim}} \frac{1}{T} X_n' Q' Q X_n \nonumber \\= & {} {\mathbb {E}} \left\{ \left( {\underline{x}}_{n,1} - {\mathbb {E}} \left\{ {\underline{x}}_{n,1}\right\} \right) \left( {\underline{x}}_{n,1} - {\mathbb {E}} \left\{ {\underline{x}}_{n,1}\right\} \right) '\right\} \,, \end{aligned}$$(A.44)where the last equality is obtained by exploiting the eigendecomposition of \(Q' Q\) (which, combined with the assumptions on the \({\underline{x}}_{n,t}\), shows that each element in position (h, k) of the matrix \(X_n' Q' Q X_n\) is the summation of \(T-1\) independent random variables with mean \(( {\mathbb {E}} \{ ( {\underline{x}}_{n,1} - {\mathbb {E}} \{ {\underline{x}}_{n,1}\} ) ( {\underline{x}}_{n,1} - {\mathbb {E}} \{ {\underline{x}}_{n,1}\})' \}) _{h,k}\) and the same finite variance), then applying Chebyschev’s weak law of large numbers.
-
(iv.c)
Moreover,
$$\begin{aligned}&\underset{T \rightarrow +\infty }{\mathrm{plim}} \frac{1}{T} \sum _{t=2}^{T} \underline{\ddot{x}}_{n,t} \underline{\ddot{x}}_{n,t-1}' \nonumber \\&\quad =\underset{T \rightarrow +\infty }{\mathrm{plim}} \frac{1}{T} \sum _{t=2}^{T} \left( {\underline{x}}_{n,t} -\frac{\sum _{\tau =1}^T {\underline{x}}_{n,\tau }}{T}\right) \left( {\underline{x}}_{n,t-1}-\frac{\sum _{\tau =1}^T {\underline{x}}_{n,\tau }}{T}\right) ' \nonumber \\&\quad =\underset{T \rightarrow +\infty }{\mathrm{plim}} \frac{1}{T} \sum _{t=2}^{T} \left[ {\underline{x}}_{n,t} {\underline{x}}_{n,t-1}'-{\underline{x}}_{n,t} \frac{\sum _{\tau =1}^T {\underline{x}}_{n,\tau }'}{T}-\frac{\sum _{\tau =1}^T {\underline{x}}_{n,\tau }}{T} {\underline{x}}_{n,t-1}' +\frac{\sum _{\tau =1}^T {\underline{x}}_{n,\tau }\sum _{\tau =1}^T {\underline{x}}_{n,\tau }'}{T^2}\right] \nonumber \\&\quad = {\mathbb {E}} \left\{ {\underline{x}}_{n,1}\right\} {\mathbb {E}}\left\{ {\underline{x}}_{n,1}'\right\} - {\mathbb {E}} \left\{ {\underline{x}}_{n,1}\right\} {\mathbb {E}}\left\{ {\underline{x}}_{n,1}'\right\} - {\mathbb {E}} \left\{ {\underline{x}}_{n,1}\right\} {\mathbb {E}}\left\{ {\underline{x}}_{n,1}'\right\} + {\mathbb {E}} \left\{ {\underline{x}}_{n,1}\right\} {\mathbb {E}}\left\{ {\underline{x}}_{n,1}'\right\} \nonumber \\&\quad =0_{p \times p}\,, \end{aligned}$$(A.45)where the second-last equality comes from the fact that the probability limit of the product of two factors equals the product of the probability limits of the two factors, when the latter probability limits exist (this is a consequence of the Continuous Mapping Theorem (Florescu 2015, Theorem 7.33)), and from the assumptions on the \({\underline{x}}_{n,t}\).
-
(iv.d)
Finally, Eq. (A.38) is obtained by combining items iv.a), iv.b), and iv.c), and taking into account the constant factors in Eq. (A.42).
-
(iv.a)
-
(v)
Final part of the proof of Eq. (23).
To conclude, one gets Eq. (23) by combining Eqs. (A.34), (A.35), and (A.38), then summing over N.
Discussion of the validity of the assumption \(\underset{T \rightarrow \infty }{\lim }\Vert \varPhi ^+-Q \varPsi ^{-1} Q'\Vert _{2}=0\)
First, we prove a related result. In the following, for a matrix \(M \in {\mathbb {R}}^{T \times T}\), \(\Vert M\Vert _{HS}=\sqrt{\frac{1}{T}\sum _{i,j=1}^{T} M_{i,j}^2}\) denotes its Hilbert-Schmidt norm (Gray 2006, Eq. (2.17)), which is a scaled version of its Frobenius norm \(\Vert M\Vert _{F}=\sqrt{\sum _{i,j=1}^{T} M_{i,j}^2}\).
The following holds:
Eq. (A.46) is derived by combining several steps, which are listed next, together with pointers to some theoretical results available in the literature that are directly applied for their proofs, and checks of the assumptions of such results in the context of our analysis. In the following, for a better clarity of exposition of this part, the dependence of \(\varPsi\) and other matrices on T is highlighted by including the subscript T in the notation.
-
(i)
\(\underset{T \rightarrow \infty }{\lim }\Vert \varPsi _T-C_T\Vert _{HS}=0\), where \(C_T\) is a suitable symmetric and positive definite circulant matrixFootnote 9 approximation of the symmetric Toeplitz matrix \(\varPsi _T\) (application of (Gray 2006, Lemma 4.6) to the circulant matrix approximation \(C_T\) of \(\varPsi _T\) coming from (Gray 2006, Eq. (4.32)), where \(C_T\) is also symmetric and positive definite due to the symmetry and positive definiteness of the Toeplitz matrix \(\varPsi _T\); the application itself of (Gray 2006, Lemma 4.6) is made possible in this case by the convergence of \(1 + 2 \sum _{k=1}^{+\infty }|\rho |^k\)).
-
(ii)
\(\underset{T \rightarrow \infty }{\lim }\Vert \varPhi _T -Q_T C_T Q_T'\Vert _{HS}=0\) (definition of \(\varPhi _T\) as \(\varPhi _T=Q_T \varPsi _T Q_T'\); combination of item i) with (Gray 2006, Lemma 2.3) and the fact that \(\Vert Q_T\Vert _2=\underset{t=1,\ldots ,T}{\max }|\lambda _t(Q_T)|=1\)).
-
(iii)
\(\underset{T \rightarrow \infty }{\lim }\Vert \varPhi _T^+-(Q_T C_T Q_T')^+\Vert _{HS}=0\) (combination of item ii) with (Wedin 1973, Theorem 4.1), made possible by the fact that \(\varPhi _T\) and \(Q_T C_T Q_T'\) have the same rank \(T-1\), and the spectral norm of \(\varPhi _T^+\) and the one of \((Q_T C_T Q_T')^+\) are uniformly bounded with respect to T, due respectively to item iv) in the proof of Eq. (21) and to the characterization of the eigenvalues of \(C_T\) provided in (Gray 2006, Eq. (4.34)), combined with \(m_f = \frac{1-\rho ^2}{1+\rho ^2+2\rho } >0\).
-
(iv)
\(\underset{T \rightarrow \infty }{\lim }\Vert \varPsi _T^{-1}-C_T^{-1}\Vert _{HS}=0\) (application of (Gray 2006, Theorem 5.2 (b)) to the function \(f(\lambda )\) reported in Eq. (A.19)).
-
(v)
\(\underset{T \rightarrow \infty }{\lim }\Vert Q_T \varPsi _T^{-1} Q_T' -Q_T C_T^{-1} Q_T'\Vert _{HS}=0\) (obtained likewise item ii)).
-
(vi)
\(Q_T C_T^{-1} Q_T'=(Q_T C_T Q_T')^+\) (obtained by exploiting the following facts: since \(C_T\) is a symmetric matrix, it has the factorization \(C_T=U_T \varSigma _T U_T'\) for an orthogonal matrix \(U_T \in {\mathbb {R}}^{T \times T}\) and a diagonal matrix \(\varSigma _T \in {\mathbb {R}}^{T \times T}\) containing its eigenvalues, which are positive; since \(C_T\) is also a circular matrix, one can choose one column of \(U_T\) to be proportional to \({\underline{1}}_T\), since this is an eigenvector of \(C_T\) (Gray 2006, Theorem 3.1); \(Q_T\) represents the orthogonal projection of \({\mathbb {R}}^T\) onto its subspace L orthogonal to \({\underline{1}}_T\); as a consequence of the facts above, one can easily check that \(Q_T C_T^{-1} Q_T'\) satisfies all the defining propertiesFootnote 10 (Barata and Hussein 2012) of the Moore-Penrose pseudoinverse of \(Q_T C_T Q_T'\), hence \(Q_T C_T^{-1} Q_T'=(Q_T C_T Q_T')^+\) by the uniqueness of the Moore-Penrose pseudoinverse (Barata and Hussein 2012).
-
(vii)
Finally, Eq. (A.46) is obtained by combining items iii), v), and vi).
Remark 6.2
One can easily check (e.g., by a numerical study for selected values of T and of the parameter \(\rho\) in \(\varPsi\)) that, in general, the stronger result \(\varPhi ^+ = Q \varPsi ^{-1} Q'\) does not hold. This depends on the fact that, given two matrices \(M_1,M_2 \in {\mathbb {R}}^{T \times T}\), typically \((M_1 M_2)^+ \ne M_2^+ M_1^+\), apart from particular cases (Dattorro 2019, Eq. (E.0.0.0.1)).
Eq. (22), i.e., \(\underset{T \rightarrow \infty }{\lim }\Vert \varPhi ^+-Q \varPsi ^{-1} Q'\Vert _{2}=0\), represents a stronger convergence requirement on \(\varPhi ^+-Q \varPsi ^{-1} Q'\) with respect to the convergence result provided by Eq. (A.46), which has been proved above. This depends on the fact that, for any matrix \(M \in {\mathbb {R}}^{T \times T}\), one has \(\Vert M\Vert _2 \ge \Vert M\Vert _{HS}\) (Gray 2006, Eq. (2.19)). The validity of Eq. (22) has been assumed to complete the proof of Eq. (23) - specifically, of part of item iii) therein - since a similar argument based on Eq. (A.46) would be not enough to complete that proof. Although we are currently unable to provide a formal proof of Eq. (22) - which is why it has been reported here as an assumption - its validity is strongly supported by the numerical results shown in Fig. 2, where the spectral norm error \(\Vert \varPhi ^+-Q \varPsi ^{-1} Q'\Vert _{2}\) is reported for several choices of T and \(\rho\) (similar results are obtained for a wider range of values of T and other values of \(\rho\)). The difficulty in getting a proof of Eq. (22) depends on the fact that the vector \({\underline{1}}_T\) is not an eigenvector of \(\varPsi\) (although it is an eigenvector of its circulant matrix approximation). Hence, there is no guarantee a priori that all the elements of an orthonormal basis of eigenvectors of \(\varPsi\) have nonzero orthogonal projections onto \({\underline{1}}_T\) (indeed, it can be easily checked numerically - e.g., by finding a basis of eigenvectors of \(\varPsi\) for a few choices of T, then computing such orthogonal projections - that they are typically nonzero)Footnote 11. This suggests, as a possible way to proceed in the proof, to investigate theoretically if such orthogonal projections converge uniformly to 0 as T tends to \(+\infty\). In any case, in this appendix we have reported Eq. (A.46) together with its proof, because such equation is obviously related to Eq. (22), and because a proof of the latter could be obtained by combining Eq. (A.46) with specific properties of the matrix \(\varPsi\). It is also worth mentioning that such proof would be not necessarily based on the use of a circulant matrix approximation of \(\varPsi\), then of \(\varPsi ^{-1}\) (for which negative results on the spectral norm approximation error are known, unless a related but restricted notion of finite-term strong convergence is considered (Sun 2003, Theorem 1)).

Spectral norm error \(\Vert \varPhi ^+-Q \varPsi ^{-1} Q'\Vert _{2}\) as a function of T for a several choices of \(\rho \in (-1,1)\), and b other choices of \(\rho \in (-1,1)\) near either \(-1\) or 1
Appendix 3: other large-sample approximations of the conditional generalization error, and associated optimization problems
In the following, we report some notes about how the analysis made in Sects. 3 and 4 can be modified if one considers, respectively, the case of large N (whose application is potentially of interest in microeconometrics), and the one in which both N and T are large. For simplicity, we limit this extension of the analysis to the case \(\rho =0\), for which one obtains the simplified expressions \(\varPsi =I_T\) and \({\varPhi =Q} \varPsi {Q'}={Q Q'}=I_{T}-\frac{1}{T} {\underline{1}}_{T} {\underline{1}}_{T}'\). Then, one gets \({Q'\varPhi ^{+} Q}={\varPhi ^{+}}={Q Q'=Q' Q}\) by combining Eq. (A.31) and the relation between the singular value decomposition of a matrix and the singular value decomposition of its Moore-Penrose pseudoinverse.
First, we consider the case in which N is large. Assuming stationarity and mutual independence of different observations associated with the same unit, computations of the elements of the matrix
show that
Under mild technical conditions (e.g., under the additional assumption that mutual independence extends to all the \({\underline{x}}_{n,t}\), including those associated with different units, and that all the \({\underline{x}}_{n,t}\) are identically distributedFootnote 12 and have finite moments up to the order 4), from Eq. (A.48) one gets, applying Chebyschev’s weak law of large numbers likewise in part of Appendix 2,
where
is a symmetric and positive semi-definite matrix. Likewise for what concerns \(A_N\) in Sect. 3, the positive definiteness of A is also assumed in the following.
When (A.49) holds and \(\rho =0\), using also Eqs. (18) and (19) and the property \(Q {\underline{1}}_T={\underline{0}}_T\), one gets the following large-sample approximation with respect to N for the conditional generalization error (17), where the dependence on N has been highlighted:
where \(A^{-\frac{1}{2}}\) is the principal square root of the symmetric and positive definite matrix \(A^{-1}\).
Second, we consider the case in which both N and T are large. In this case, (A.49) is replaced by
for the same matrix A as above.
When (20) and (A.52) hold and \(\rho =0\), the conditional generalization error (17) has the following large-sample approximation with respect to N and T:
Starting from the large-sample approximations (A.51) and (A.53) for the conditional generalization error, and adopting the model (27) for the variance \(\sigma ^2\), two optimization problems similar to (28) can be stated and solved. For simplicity, in the following we make some approximations in the analysis of their optimal solutions.
In the first problem, one optimizes the corresponding large-sample approximation of the conditional generalization error with respect to N (or equivalently, with respect to c, as in (28)), whereas T is fixed. More precisely, for C sufficiently large (in such a way that the large-sample approximation (A.51) can be assumed to hold for every \(c \in [c_{\mathrm{min}}, c_{\mathrm{max}}]\)) and under the approximation \(NTc \simeq C\) at optimalityFootnote 13, setting
the first optimization problem can be written as
whose optimal solution \(c^\circ\) has the following expression:
-
1.
if \(0< \alpha < 1\) (“decreasing returns of scale”) and
-
(a)
\(c^\star :=\frac{C {(T-1)} \alpha }{K_i' {T^2} (1-\alpha )} \in [c_{\mathrm{min}}, c_{\mathrm{max}}]\): \(c^\circ = c^\star\);
-
(b)
\(c^\star < c_{\mathrm{min}}\): \(c^\circ = c_{\mathrm{min}}\);
-
(c)
\(c^\star > c_{\mathrm{max}}\): \(c^\circ = c_{\mathrm{max}}\);
-
(a)
-
2.
if \(\alpha > 1\) (“increasing returns of scale”): \(c^\circ = c_{\mathrm{max}}\);
-
3.
if \(\alpha = 1\) (“constant returns of scale”): \(c^\circ = c_{\mathrm{max}}\).
The analysis of the second problem (whose optimization variables are c, N, and T, as the large-sample approximation of the conditional generalizarion error with respect to both N and T is optimized) is slightly more involved, since it is formulated in terms of a larger number of optimization variables. Nevertheless, solving such problem can be reduced to solving, for each c, an optimization subproblem in which the same objective function is minimized with respect to the pair (N, T). In this problem, admissible such pairs have to satisfy the constraint \(N T c \le C\), and also two additional lower bounds \(N\ge N_{\mathrm{min}}>0\) and on \(T\ge T_{\mathrm{min}}>0\), under which the large-sample approximation made in (A.53) can be assumed to hold. More precisely, for C sufficiently large and under the approximations \(T-1 \simeq T\) and \(NTc \simeq C\) at optimality, setting
the second optimization problem can be written as
whose optimal solutions \(c^\circ\) have the following expressions (the optimal T is \(T^\circ \simeq \frac{C}{N_{\mathrm{min}} c^\circ }\)):
-
1.
if \(0< \alpha < 1\) (“decreasing returns of scale”): \(c^\circ = c_{\mathrm{min}}\);
-
2.
if \(\alpha > 1\) (“increasing returns of scale”): \(c^\circ = c_{\mathrm{max}}\);
-
3.
if \(\alpha = 1\) (“constant returns of scale”): \(c^\circ =\) any cost c in the interval \([c_{\mathrm{min}}, c_{\mathrm{max}}]\).
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Gnecco, G., Nutarelli, F. & Selvi, D. Optimal data collection design in machine learning: the case of the fixed effects generalized least squares panel data model. Mach Learn 110, 1549–1584 (2021). https://doi.org/10.1007/s10994-021-05976-x
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10994-021-05976-x