
Abstract
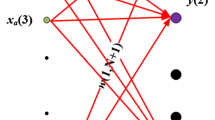
We analyze classification problems in which data is generated by a two-tiered random process. The class is generated first, then a layer of conditionally independent hidden variables, and finally the observed variables. For sources like this, the Bayes-optimal rule for predicting the class given the values of the observed variables is a two-layer neural network. We show that, if the hidden variables have non-negligible effects on many observed variables, a linear classifier approximates the error rate of the Bayes optimal classifier up to lower order terms. We also show that the hinge loss of a linear classifier is not much more than the Bayes error rate, which implies that an accurate linear classifier can be found efficiently.
Article PDF
Similar content being viewed by others


References
Anoulova, S., Fischer, P., Pölt, S., & Simon, H. U. (1996). Probably almost Bayes decisions. Information and Computation, 129(1), 63–71.
Bartlett, P. L., Jordan, M. I., & McAuliffe, J. D. (2006). Convexity, classification, and risk bounds. Journal of the American Statistical Association, 101(473), 138–156.
Bickel, P., & Levina, E. (2004). Some theory of Fisher’s linear discriminant function, ‘Naive Bayes’, and some alternatives when there are many more variables than observations. Bernoulli, 10(6), 989–1010.
Blei, D., Ng, A., & Jordan, M. (2003). Latent Dirichlet allocation. Journal of Machine Learning Research, 3.
Bshouty, N. H., & Long, P. M. (2009). Linear classifiers are nearly optimal when hidden variables have diverse effects. In COLT.
Caruana, R., & Niculescu-Mizil, A. (2006). An empirical comparison of supervised learning algorithms. In ICML (pp. 161–168).
Caruana, R., Karampatziakis, N., & Yessenalina, A. (2008). An empirical evaluation of supervised learning in high dimensions. In ICML (pp. 96–103).
Cryan, M., Goldberg, L. A., & Goldberg, P. W. (2001). Evolutionary trees can be learned in polynomial time in the two-state general Markov model. SIAM Journal on Computing, 31(2), 375–397.
Devroye, L., Györfi, L., & Lugosi, G. (1996). A probabilistic theory of pattern recognition. Berlin: Springer.
Diakonikolas, I., & Servedio, R. (2009). Improved approximation of linear threshold functions. In 24th conference on computational complexity (CCC) (pp. 161–172).
Domingos, P., & Pazzani, M. (1997). On the optimality of the simple Bayesian classifier under zero-one loss. Machine Learning, 29, 103–130.
Dubhashi, D., & Ranjan, D. (1998). Balls and bins: A study in negative dependence. Random Structures & Algorithms, 13(2), 99–124.
Duda, R. O., Hart, P. E., & Stork, D. G. (2000). Pattern classification (2nd ed.). New York: Wiley.
Hertz, J. A., Krogh, A., & Palmer, R. (1991). Introduction to the theory of neural computation. Reading: Addison-Wesley.
Hoeffding, W. (1963). Probability inequalities for sums of bounded random variables. Journal of the American Statistical Society, 58(301), 13–30.
Hofmann, T. (2001). Unsupervised learning by probabilistic latent semantic analysis. Machine Learning, 42(1/2), 177–196.
Hsieh, C. J., Chang, K. W., Lin, C. J., Keerthi, S. S., & Sundararajan, S. (2008). A dual coordinate descent method for large-scale linear SVM. In ICML.
Joachims, T. (1998). Text categorization with support vector machines: learning with many relevant features. In Proceedings of ECML-98, 10th European conference on machine learning (pp. 137–142).
Kuncheva, L. I. (2006). On the optimality of naive Bayes with dependent binary features. Pattern Recognition Letters, 27(7), 830–837.
Langseth, H., & Nielsen, T. D. (2006). Classification using hierarchical naive Bayes models. Machine Learning, 63(2), 135–159.
Neyman, J. (1971). Molecular studies of evolution: A source of novel statistical problems (pp. 1–27). New York: Academic Press.
Papadimitriou, C. H., Raghavan, P., Tamaki, H., & Vempala, S. (2000). Latent semantic indexing: A probabilistic analysis. Journal of Computer and System Sciences, 61(1), 217–235.
Pemmaraju, S. (2001). Equitable coloring extends Chernoff-Hoeffding bounds. In RANDOM.
Pollard, D. (1984). Convergence of stochastic processes. Berlin: Springer.
Schapire, R. E., & Singer, Y. (2000). BoosTexter: A boosting-based system for text categorization. Machine Learning, 39(2/3), 135–168.
Schmidt, J. P., Siegel, A., & Srinivasan, A. (1993). Chernoff-Hoeffding bounds for applications with limited independence. In SODA.
Servedio, R. A. (2007). Every linear threshold function has a low-weight approximator. Computational Complexity, 16(2), 180–209.
Shalev-Shwartz, S., Singer, Y., & Srebro, N. (2007). Pegasos: Primal estimated sub-gradient solver for SVM. In ICML (pp. 807–814).
Tibshirani, R., Hastie, T., Narasimhan, B., & Chu, G. (2002). Diagnosis of multiple cancer types by shrunken centroids of gene expression. Proceedings of the National Academy of Sciences of the United States of America, 99(10), 6567–6572.
Zhang, N. L. (2004a). Hierarchical latent class models for cluster analysis. Journal of Machine Learning Research, 5(6), 697–723.
Zhang, T. (2004b). Statistical behavior and consistency of classification methods based on convex risk minimization. Annals of Statistics, 32(1), 56–85.
Author information
Authors and Affiliations
Corresponding author
Additional information
Editor: Nicolo Cesa-Bianchi.
Rights and permissions
About this article
Cite this article
Bshouty, N.H., Long, P.M. Linear classifiers are nearly optimal when hidden variables have diverse effects. Mach Learn 86, 209–231 (2012). https://doi.org/10.1007/s10994-011-5262-7
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10994-011-5262-7