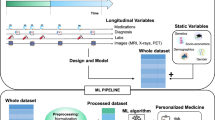
Large clinical datasets derived from insurance claims and electronic health record (EHR) systems are valuable sources for precision medicine research. These datasets can be used to develop models for personalized prediction of risk or treatment response. Efficiently deriving prediction models using real world data, however, faces practical and methodological challenges. Precise information on important clinical outcomes such as time to cancer progression are not readily available in these databases. The true clinical event times typically cannot be approximated well based on simple extracts of billing or procedure codes. Whereas, annotating event times manually is time and resource prohibitive. In this paper, we propose a two-step semi-supervised multi-modal automated time annotation (MATA) method leveraging multi-dimensional longitudinal EHR encounter records. In step I, we employ a functional principal component analysis approach to estimate the underlying intensity functions based on observed point processes from the unlabeled patients. In step II, we fit a penalized proportional odds model to the event time outcomes with features derived in step I in the labeled data where the non-parametric baseline function is approximated using B-splines. Under regularity conditions, the resulting estimator of the feature effect vector is shown as root-n consistent. We demonstrate the superiority of our approach relative to existing approaches through simulations and a real data example on annotating lung cancer recurrence in an EHR cohort of lung cancer patients from Veteran Health Administration.
Chubak J, Onega T, Zhu W, Buist DS, Hubbard RA. An electronic health record-based algorithm to ascertain the date of second breast cancer events. Medical care (2015)
de Boor C (2001) A Practical Guide to Splines. Springer, New York
Dean C, Balshaw R (1997) Efficiency lost by analyzing counts rather than event times in poisson and overdispersed poisson regression models. J Am Stat Assoc 92:1387–1398
Hassett MJ, Uno H, Cronin AM, Carroll NM, Hornbrook MC, Ritzwoller D. Detecting lung and colorectal cancer recurrence using structured clinical/administrative data to enable outcomes research and population health management. Medical care (2015)
Horn RA, Johnson CR (1990) Matrix analysis. Cambridge University Press, Cambridge
Rice JA, Silverman BW (1991) Estimating the mean and covariance structure nonparametrically when the data are curves. J Roy Stat Soc: Ser B (Methodol) 53:233–243
Royston P, Parmar MK (2002) Flexible parametric proportional-hazards and proportional-odds models for censored survival data, with application to prognostic modelling and estimation of treatment effects. Stat Med 21:2175–2197
Stark H, Woods JW (1986) Probability, random processes, and estimation theory for engineers. Prentice-Hall Inc, Upper Saddle River, NJ
Uno H, Cai T, Pencina MJ, D’Agostino RB, Wei L (2011) On the c-statistics for evaluating overall adequacy of risk prediction procedures with censored survival data. Stat Med 30:1105–1117
Uno H, Ritzwoller DP, Cronin AM, Carroll NM, Hornbrook MC, Hassett MJ (2018) Determining the time of cancer recurrence using claims or electronic medical record data. JCO Clinical Cancer Informatics 2:1–10
Zhang Y, Hua L, Huang J (2010) A spline-based semiparametric maximum likelihood estimation method for the cox model with interval-censored data. Scand J Stat 37:338–354
Zhang Y, Cai T, Yu S, Cho K, Hong C, Sun J et al (2019) High-throughput phenotyping with electronic medical record data using a common semi-supervised approach (phecap). Nat Protoc 14(12):3426–3444. https://doi.org/10.1038/s41596-019-0227-6
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
Appendices
In Appendix A, we present additional simulation studies with Gamma intensities, as well as extra information on the simulation settings. In Appendix B, we offer additional details on the data example of lung cancer recurrence with VACCR data. In Appendix C, we provide the theoretical properties for the derived features. In Appendix D, we provide the theoretical properties for the MATA estimator based on the proportional odds model. In Appendix F, we provide the detailed algorithm for optimization of the log-likelihood \(l_n\).
Appendix A additional simulation details
1.1 A1 simulation settings for the gaussian intensities
We first simulate Gaussian shape density, i.e., \(f_i^{\scriptscriptstyle [j]}\) is the density function of \(\hbox {Normal}(\mu _{ij},\sigma _{ij}^2)\) truncated at 0.
Set \(\mu _{ij}\) to be \({F_j}^{-1}\{\varPhi (\nu _{ij})\}\), \(F_j\) is the CDF of \(\hbox {Gamma}(k_{1j},\theta _{1j})\), with \(k_{1j}\sim \hbox {Uniform}(3,6)\) and \(\theta _{1j}\sim \hbox {Uniform}(2,3)\) for \(j=1,\cdots ,q\), and \({\varvec{\nu }}_i = (\nu _{i1},\cdots ,\nu _{iq})^\mathsf{\scriptscriptstyle T}\sim \hbox {MNormal}(\mathbf{0},\varSigma _{{\varvec{\nu }}})\), i.e., the multivariate normal distribution with mean \(\mathbf{0}\) and variance \(\varSigma _{{\varvec{\nu }}}\). For simplicity, we set \(\varSigma _{\varvec{\nu }}=\varSigma _{\varvec{\iota }}\). We further set \(\mu _{ij}\) to be one if it is less than one.
Simulate \(\sigma _{ij}\sim \hbox {Uniform}(0.5,s_j)\) with \(s_j=\mathrm{min}\{0.9\mu _{ij}, {F_j}^{-1}(0.5)\}\), where \(F_j\) is the CDF of \(\hbox {Gamma}(k_{1j},\theta _{1j})\). The way we simulate \(\mu _{ij}\) and \(\sigma _{ij}\) guarantees that the largest change in the intensity functions only occurs after patients enter the study, i.e., \(\mu _{ij}-\sigma _{ij}>0\), as expected in practice. Besides, the simulated \(\sigma _{ij}\) is not only controlled by the value of \(\mu _{ij}\) but also the median of \(\hbox {Gamma}(k_{1j},\theta _{1j})\). Thus \(\sigma _{ij}\) will not get too extreme even with a large peak time \(\mu _{ij}\). In other words, the corresponding largest change in the intensity function \(\mu _{ij}-\sigma _{ij}\) is more likely to occur near the peak time \(\mu _{ij}\) than much earlier than \(\mu _{ij}\) .
Finally, we set \(\alpha _c\), the constant in the nonparametric function \(\alpha (t)\), to be 7.5 and 1.1 to obtain an approximately \(30\%\) and \(70\%\) censoring rate.
1.2 A2 Simulation settings for the gamma intensity functions
We also consider gamma shape density, i.e., \(f_i^{\scriptscriptstyle [j]}(t)\) is the density function of \(\hbox {Gamma}(k_{ij},\theta _{ij})\), truncated at 0. We let \(f_i^{\scriptscriptstyle [j]}(t)\) be the density function of \(\hbox {Gamma}(k_{ij},\theta _{ij})\), truncated at 0. Set \(k_{ij}=F_j^{-1}\{\varPhi (\nu _{ij})\}\), where \(F_j\) is the CDF of \(\hbox {Uniform}(k_{\ell ,j},k_{u,j})\), with \(k_{\ell ,j}\sim \hbox {Uniform}(2,4)\), and \(k_{u,j}\sim \hbox {Uniform}(4,6)\), and \({\varvec{\nu }}_i=(\nu _{i1},\cdots ,\nu _{iq})^\mathsf{\scriptscriptstyle T}\sim \hbox {MNormal}(\mathbf{0},\varSigma _{{\varvec{\nu }}})\). Generate \(\theta _{ij}\) from Gamma \((a_{j},b_{j})\) truncated at its third quartile with \(a_j\sim \hbox {Uniform}(3,6)\), and \(b_j\sim \hbox {Uniform}(2,4)\). We set \(\alpha _c=6.8\) and 1.9 to obtain the approximate 30% and 70% censoring rates.
1.3 A3 Results for gamma intensity setting
For the true feature sets, we reported the bias and standard error (se) of the non-zero coefficients, i.e., \({\varvec{\beta }}_1=(\beta _{11},\beta _{12})^\mathsf{\scriptscriptstyle T}\), from MATA and NPMLE in Table 5. Similar to the Gaussian intensities settings, we find that the MATA procedure performs well with small sample size regardless of the censoring rate, the correlation structure between groups of encounters, and the family of the intensity curves. MASA generally leads to both smaller bias and smaller standard error compared to the NPMLE. In the extreme case when \(n=200\) and the censoring rate reaches 70%, both estimators deteriorate. However, the resulting 95% confidence interval of MATA covers the truth as the absolute bias is less than 1.96 times standard error. In contrast, the NPMLE tends to be numerically unstable. We observe the estimation bias of NPMLE for \(n=400\) setting is larger than its own standard error and the the bias at \(n=200\) setting. These results is consistent with Theorem 2.
Table 5 Displayed are the bias and standard error of the estimation on \({\varvec{\beta }}_1=(\beta _{11},\beta _{12})^\mathsf{\scriptscriptstyle T}\) fitted with the true features from 400 simulations each with \(N+n=4,000\) and \(n=200\) and 400. Two methods, MATA and NPMLE, are contrasted. Panels from the top to bottom are Gamma intensities with the subject-specific follow-up duration under 30% and 70% censoring rate as discussed in Sect. A1. The results under independent groups of encounters are shown on the left whereas the results for correlated one are shown on the right
For both true and estimated feature sets, we computed the out-of-sample accuracy measures discussed in Sect. 2.3 on a validation data set. All other accuracy measures, i.e., Kendall’s-\(\tau \) type rank correlation summary measures \({\mathscr {C}}_{u}, {\mathscr {C}}_{u}^+\), and absolute prediction error \(\text{ APE}_u\) depend on u, which is easy to control for MATA and NPMLE but not for Tree and Logi. We therefore minimize the cross-validation error for the Tree approach and minimize the misclassification rate for the Logi approach at their first step, i.e., classifying the censoring status \(\varDelta \). For MATA and NPMLE, We calculate these accuracy measures at \(u=0.02\ell \) for \(\ell =0,1,\cdots ,50\) and pick the u with minimum \(\text{ APE}_u\). We then compare these measures at the selected u with Tree and Logi methods in Tables 6 and 7.
Table 6 True features, Gamma. Kendall’s-\(\tau \) type rank correlation summary measures (\({\mathscr {C}}\) and \({\mathscr {C}}^+\)), and absolute prediction error (\(\text{ APE }\)) are computed from four methods, MATA, NPMLE, Tree, and Logi, under \(q=10\) Gamma intensities over 400 simulations each with \(n+N=4,000\) and \(n=200\) or 400
Table 7 Estimated features, Gamma. Kendall’s-\(\tau \) type rank correlation summary measures (\({\mathscr {C}}\) and \({\mathscr {C}}^+\)), and absolute prediction error (\(\text{ APE }\)) are computed from four methods, MATA, NPMLE, Tree, and Logi, under \(q=10\) Gamma intensities over 400 simulations each with \(n+N=4,000\) and \(n=200\) or 400
Similar to the Gaussian intensities setting, the performance of the MATA estimator when fitted with the true features largely dominates that of NPMLE, Tree, and Logi, with higher \({\mathscr {C}}, {\mathscr {C}}^+\) and lower \(\text{ APE }\) in all cases except when the encounters are simulated from independent Gamma counting processes with 30% censoring rate. In this exceptional case, our MATA estimator has very minor advantage in \({\mathscr {C}}^+\) compared to NPMLE, and is still better in terms of \({\mathscr {C}}\) and \(\text{ APE }\). When fitted with the estimated features, there is no clear winner among the four methods when the labeled data size is \(n=200\); however, when the labeled data size increased to \(n=400\), MATA generally outperforms the other three approaches in terms of \(\text{ APE }\).
Supplementary Results on Simulations:
We show the sparsity in the simulated data in Tables 8. We show the Average Model Size and MSE of Estimation in Table 9.
Table 8 Estimated probability of having zero or \(\le 3\) encounter arrival times under each counting process \({\mathcal {N}}^{\scriptscriptstyle [j]}\) for \(j=1,\cdots ,10\) from a simulation with sample size 500, 000
We show the sparsity of features in Table 10. The radiotherapy, medication for systematic therapies and biopsy/excision has a zero code rate of 77.8%, 70.7% and 96.4%, respectively. Consequently, the estimated peak and largest increase time of these features are identical as the associated first occurrence time for most patients. Thus, only the first occurrence time and the total number of diagnosis and procedure code are considered for these features.
Table 10 Sparsity of the nine groups of medical encounter data analyzed in Sect. 5
We show the MATA and NPMLE coefficients for \(n=1000, 400, 200\) in Tables 11–13. Similar as in Sect. 4, our MATA estimator has smaller bootstrap standard error compared to the NPMLE. For the analysis with \(n=1000\), both MATA and NPMLE showed a significant impact of first arrival time and peak time of lung cancer code, first arrival time and first FPCA score of chemotherapy code, first arrival time of radiotherapy code, total number of secondary malignant neoplasm code, peak and change point times of palliative or hospice care in medical notes, first FPCA score and total number of recurrence in medical notes and first arrival time of biopsy or excision. MATA additionally finds the change point time of lung cancer code to have strong association with high risk of lung cancer recurrence. Furthermore, MATA excludes the stage II cancer, which coincides with the large p-values on those four group of encounters under NPMLE. For the analyses with \(n=200\) and \(n=400\), MATA excludes cancer stage, age at diagnosis and medication for systematic therapies, which coincides with the groups without any significant feature from the \(n=1000\) NPMLE analysis.
Table 11 Analysis with \(n=1000\). Estimated coefficient (“est”), bootstrap standard error (“boot.se”), and p-value (“pval”) over 400 bootstraps for the extracted feature sets, including first code time (1stCode), peak time (Pk), change point time (ChP), first FPC score (1stScore), and log of total number of codes (logN), from the nine groups of medical encounter data in 5
Table 12 Analysis with \(n=400\). Estimated coefficient (“est”), bootstrap standard error (“boot.se”), and p-value (“pval”) over 400 bootstraps for the extracted feature sets, including first code time (1stCode), peak time (Pk), change point time (ChP), first FPC score (1stScore), and log of total number of codes (logN), from the nine groups of medical encounter data in 5
Table 13 Analysis with \(n=200\). Estimated coefficient (“est”), bootstrap standard error (“boot.se”), and p-value (“pval”) over 400 bootstraps for the extracted feature sets, including first code time (1stCode), peak time (Pk), change point time (ChP), first FPC score (1stScore), and log of total number of codes (logN), from the nine groups of medical encounter data in 5
Instead of deriving asymptotic properties for truncated density \(f_{C_i}\), i.e., random density \(f_i\) truncated on \([0,C_i]\), we focus on the scaled densities \(f_{C_i,\mathrm{scaled}}\), which is \(f_{C_i}\) scaled to [0, 1]. As we assume censoring time \(C_i\) has finite support \([0,{{{\mathcal {E}}}}]\) with \({{{\mathcal {E}}}}<\infty \), \(f_{C_i,\mathrm{scaled}}\) and \(f_{C_i}\) shared the same asymptotic properties.
Let \(f^{\scriptscriptstyle [j]}_{\mu ,\mathrm{scaled}}(t)=E\{f_{C,\mathrm{scaled}}^{\scriptscriptstyle [j]}(t)\}\) and \(G_{\mathrm{scaled}}^{\scriptscriptstyle [j]}(t,s) = \mathrm{cov}\{f_{C,\mathrm{scaled}}^{\scriptscriptstyle [j]}(t),f_{C,\mathrm{scaled}}^{\scriptscriptstyle [j]}(s)\}\). The Karhunen-Loève theorem (Stark and Woods 1986) states
where \(\{\phi ^{\scriptscriptstyle [j]}_{k,\mathrm{scaled}}(t)\}\) are the orthonormal eigenfunctions of \(G^{\scriptscriptstyle [j]}_{\mathrm{scaled}}(t,s)\), \(\{\zeta ^{\scriptscriptstyle [j]}_{k,\mathrm{scaled}}\}\) are pairwise uncorrelated random variables with mean 0 and variance \(\lambda _{k,\mathrm{scaled}}^{\scriptscriptstyle [j]}\), and \(\{\lambda _{k,\mathrm{scaled}}^{\scriptscriptstyle [j]}\}\) are eigenvalues of \(G^{\scriptscriptstyle [j]}_{\mathrm{scaled}}(t,s)\).
For the i-th patient, conditional on \(f^{\scriptscriptstyle [j]}_{C_i}(t)\), and \(M_i^{\scriptscriptstyle [j]}= {\mathcal {N}}^{\scriptscriptstyle [j]}([0,C_i])\), the observed event times \(t_{i1}^{\scriptscriptstyle [j]},\cdots , t_{iM_i^{\scriptscriptstyle [j]}}^{\scriptscriptstyle [j]}\) are assumed to be generated as an i.i.d. sample \(t_{ij}^{\scriptscriptstyle [j]}\overset{\mathrm{iid}}{\sim } f_{C_i}^{\scriptscriptstyle [j]}(t)\). Equivalently, the scaled observed event times \(t_{i1}^{\scriptscriptstyle [j]}/C_i,\cdots , t_{iM_i^{\scriptscriptstyle [j]}}^{\scriptscriptstyle [j]}/C_i\overset{\mathrm{iid}}{\sim } f_{C_i,\mathrm{scaled}}^{\scriptscriptstyle [j]}(t)\). Following Wu et al. (2013), we estimate \(f^{\scriptscriptstyle [j]}_{\mu }(t)\) and \(G^{\scriptscriptstyle [j]}(t,s)\), which are the mean and covariance functions of scaled density \(f_{C, \mathrm{scaled}}^{\scriptscriptstyle [j]}(t)\) respectively, as
Here \(M^{\scriptscriptstyle [j]}_{\scriptscriptstyle \mathsf +}=\sum _{i=1}^{n+N} M^{\scriptscriptstyle [j]}_i\) is the total number of encounters. \(M^{\scriptscriptstyle [j]}_{\scriptscriptstyle \mathsf ++}=\sum _{i=1,M^{\scriptscriptstyle [j]}_i\ge 2}^{n+N} M^{\scriptscriptstyle [j]}_i(M^{\scriptscriptstyle [j]}_i-1)\) is the total number of pairs. \(\kappa _{\scriptscriptstyle \mu }\) and \(\kappa _{\scriptscriptstyle G}\) are symmetric univariate and bivariate probability density functions, respectively, with \(\kappa _{\scriptscriptstyle \mu }^h(x) = \kappa _{\scriptscriptstyle \mu }(x/h)/h\), \(\kappa _{\scriptscriptstyle G}^h(x_1,x_2) = \kappa _{\scriptscriptstyle G}(x_1/h, x_2/h)/h^{2}\). \(h_{\mu }^{\scriptscriptstyle [j]}\) and \(h_g^{\scriptscriptstyle [j]}\) are bandwidth parameters.
The estimates of eigenfunctions and eigenvalues, denoted by \({\widehat{\phi }}_{k,\mathrm{scaled}}^{\scriptscriptstyle [j]}(x)\) and \({\widehat{\lambda }}_{k,\mathrm{scaled}}^{\scriptscriptstyle [j]}\) respectively, are solutions to
with constraints \(\int _0^1 {\widehat{\phi }}_{k,\mathrm{scaled}}^{\scriptscriptstyle [j]}(s)^2ds=1\) and \(\int _0^1 {\widehat{\phi }}_{k,\mathrm{scaled}}^{\scriptscriptstyle [j]}(s){\widehat{\phi }}_{\ell ,\mathrm{scaled}}^{\scriptscriptstyle [j]}(s)ds=0\). One can obtain estimated eigenfunctions \({\widehat{\phi }}_{k,\mathrm{scaled}}^{\scriptscriptstyle [j]}(x)\) and eigenvalues \({\widehat{\lambda }}_{k,\mathrm{scaled}}^{\scriptscriptstyle [j]}\) by numerical spectral decomposition on a properly discretized version of the smooth covariance function \({\widehat{G}}_{\mathrm{scaled}}^{\scriptscriptstyle [j]}(t,s)\) (Rice and Silverman 1991; Capra and Müller 1997). Subsequently, we estimate
Let \({\widetilde{\zeta }}^{\scriptscriptstyle [j]}_{ik,\mathrm{scaled}} =( M^{\scriptscriptstyle [j]}_i)^{-1}\sum _{\ell =1}^{M^{\scriptscriptstyle [j]}_i}\phi ^{\scriptscriptstyle [j]}_{k,\mathrm{scaled}}(t_{i\ell }^{\scriptscriptstyle [j]}/C_i)-\int f^{\scriptscriptstyle [j]}_{\mu ,\mathrm{scaled}}(t)\phi ^{\scriptscriptstyle [j]}_{k,\mathrm{scaled}}(t)dt\) be the population counterpart of \({\widehat{\zeta }}^{\scriptscriptstyle [j]}_{ik,\mathrm{scaled}}\) constructed with true eigenfunctions. We show in Lemma A3 that \(\mathrm{max}_i |{\widehat{\zeta }}_{ik,\mathrm{scaled}}-{\widetilde{\zeta }}_{ik,\mathrm{scaled}}|\) goes to zero at any k as long as \(Nh_\mu ^2\rightarrow \infty \) and \(Nh_g^4\rightarrow \infty \).
We then estimate the scaled density \(f^{\scriptscriptstyle [j]}_{C_i,\mathrm{scaled}}(t)\) as
For the i-th patient and its j-th point process \({\mathcal {N}}_i^{\scriptscriptstyle [j]}\), we only observe one realization of its expected number of encounters on \([0,C_i]\), i.e., \(M_i={\mathcal {N}}_i^{\scriptscriptstyle [j]}([0,C_i])\). Following Wu et al. (2013), we approximate the expected numbers of encounters with observed encounters, and estimate \(\lambda _i(t)\) as \({\widehat{\lambda }}_i^{\scriptscriptstyle [j]}(t)=M_i{\widehat{f}}_{iK}^{\scriptscriptstyle [j]}(t)\), for \(t\in [0,C_i]\). We further estimate the derived feature \(\mathbf{W}_i^{\scriptscriptstyle [j]}\) as \({\widehat{\mathbf{W}}}_i^{\scriptscriptstyle [j]}= {{\mathcal {G}}}\circ {\widehat{f}}_{iK}^{\scriptscriptstyle [j]}\).
For notation simplicity in the proof, we drop the superscript \(^{\scriptscriptstyle [j]}\), the index for the j-th counting process, for \(j=1,\cdots ,q\) throughout the appendix.
Derivative of the Mean and Covariance Functions:
Nonparametric estimation of the mean and covariance function on the scaled densities are
Here \(M_{\scriptscriptstyle \mathsf +}=\sum _{i=1}^{n+N} M_i\) is the total number of encounters. \(M_{\scriptscriptstyle \mathsf ++}=\sum _{i=1,M_i\ge 2}^{n+N} M_i(M_i-1)\) is the total number of pairs. \(\kappa _{\scriptscriptstyle \mu }\) and \(\kappa _{\scriptscriptstyle G}\) are symmetric univariate and bivariate probability density functions, respectively, with \(\kappa _{\scriptscriptstyle \mu }^h(x) = \kappa _{\scriptscriptstyle \mu }(x/h)/h\), \(\kappa _{\scriptscriptstyle G}^h(x_1,x_2) = \kappa _{\scriptscriptstyle G}(x_1/h, x_2/h)/h^{2}\). \(h_{\mu }\) and \(h_g\) are bandwidth parameters.
for \(\nu =0,u=1\) and \(\nu =1,u=0\), where for an arbitrary bivariate function h, \(h^{(\nu ,u)}(x,y)=\partial ^{\nu +u} G(x,y)/\partial ^{\nu } x\partial ^u y.\)
Assume the following regularity conditions holds.
(A1)
Scaled random densities \(f_{C_i,\mathrm{scaled}}\), its mean density \(f_{\mu ,\mathrm{scaled}}\), covariance function \(g_{\mathrm{scaled}}\) and eigenfunctions \(\phi _{k,\mathrm{scaled}}(x)\) are thrice continuously differentiable.
(A2)
\(f_{C_i,\mathrm{scaled}}\), \(f_{\mu ,\mathrm{scaled}}\) and their first three derivatives are bounded, where the bounds hold uniformly across the set of random densities.
(A3)
\(\kappa _1(\cdot )\) and \(\kappa _2(\cdot ,\cdot )\) are symmetric univariate and bivariate density function satisfying
Denote the Fourier transformations \(\chi _1(t) = \int \hbox {exp}(-iut)\kappa _1(u)du\) and \(\chi _2(s,t)= \int \hbox {exp}(-ius-ivt)\kappa _2(u,v)dudv\). \(\int |\chi _1(u)|du<\infty \) and \(\int |u\chi _1(u)|du<\infty \). \(\int |\chi _2(u,v)|dudv<\infty \), \(\int |u\chi _2(u,v)|dudv<\infty \) and \(\int |v\chi _2(u,v)|dudv<\infty \).
(A5)
The numbers of observations \(M_i\) for the j-th trajectory of i-th object, are i.i.d. r.v.’s that are independent of the densities \(f_i\) and satisfy
\(M_i,i=1,\cdots ,n+N\) are i.i.d positive r.v. generated from a truncated-Poisson distribution with rate \(\tau _N\), such that \(\hbox {pr}(M_i=0)=0\), and \(\hbox {pr}(M_i=k)={\tau _N}^k\hbox {exp}(-\tau _N)/[k!\{1-\hbox {exp}(-\tau _N)\}]\) for \(k\ge 1\).
(A8)
\(\omega _i = E(M_i\mid C_i) = E(N_i[0,C_i]\mid C_i)\) and \(f_{C_i,\mathrm{scaled}},i=1,\cdots ,n+N\) are independent. \(E{\omega _i}^{-1/2}=O(\alpha _N)\), where \(\alpha _N\rightarrow 0\) as \(N\rightarrow \infty \) for \(j=1,\cdots ,q\).
(A9)
The number of eigenfunctions and functional principal components \(K_i\) is a r.v. with \(K_i\overset{d}{=}K\), and for any \(\epsilon >0\), there exists \(K_\epsilon ^*<\infty \) such that \(\hbox {pr}(K>K_\epsilon ^*)<\epsilon \) for \(j=1,\cdots ,q\).
The proof on the mean density and covariance function can be found in Wu et al. (2013). Here we only obtain the proof for the derivative of the mean density function. The proof for the derivative of the covariance function is similar.
Then (A.9) follows by applying (A.7). \(\square \)
Derivative of the Estimated Density Functions:
Lemma A3
Under regularity conditions A1–A9, for any \(\epsilon >0\), there exists an event \(A_\epsilon \) with \(\hbox {pr}(A_\epsilon )\ge 1-\epsilon \) such that on \(A_\epsilon \) it holds that
The existence of \(A_\epsilon \) for (A.10) - (A.11) are guaranteed by the Theorem 3 in Wu et al. (2013). We followed their definition of \(A_\epsilon \), i.e., \(A_\epsilon ^c = \{K>K_\epsilon ^*\}\cup \{M_i=1,i=1,\cdots ,n+N\}\), and prove for (A.12).
Assume \(f_{C_i,\mathrm{scaled}}\) is locally unimodal, i.e., \(f'_{C_i,\mathrm{scaled}}(x)=0\) has a unique solution, denoted by \(x_{i0}\), in a neighbourhood of \(x_{i0}\), denoted by \(\mathcal{B}(x_{i0}) = (x_{i0}-\varDelta x_{i0}, x_{i0} + \varDelta x_{i0})\). Further assume \(|f''_{C_i,\mathrm{scaled}}|\) is bounded away from 0 in \(\bigcup _{x_{i0}: f'_{C_i,\mathrm{scaled}}(x_{i0})=0}{{{\mathcal {B}}}}(x_{i0})\), and the bound holds uniformly across \(i=1,\cdots ,n+N\). Let \(\widehat{x}_{i0}\) be the solution of \({\widehat{f}}'_{C_i,\mathrm{scaled}}(x)=0\) which is closet to \(x_{i0}\). Then
where \({x_{i0}}^*\) is an intermediate value between \(x_{i0}\) and \({\widehat{x}}_{i0}\).
Thus, \(|\widehat{x}_{i0}-x_{i0}|=O_p\left( \alpha _N+h_g^2+\frac{1}{\sqrt{N}h_g^3}+h_\mu ^2+\frac{1}{\sqrt{N}h_\mu ^2}\right) \). This further implies \({\widehat{x}}_{i0}\) is the only solution of \(\widehat{f}'_{C_i,\mathrm{scaled}}\) in \({{{\mathcal {B}}}}(x_{i0})\). In other words, there is one-to-one correspondence between estimated peak and the true peak and the estimated peak converges to the true peak uniformly.
The derivation of the change point is similar, and here we only list the order of the absolute difference between estimated change point \({\widehat{y}}_{i0}\) and the true change point \(y_{i0}\).
For peak and change point, the approximation error would decay faster than \(n^{-1/2}\) when the unlabeled data expand with \(\alpha _N \ll n^{-1/2}\) in follow-up duration and \(N \gg n^3\) in sample size. In that case, we may choose \((n/N)^{1/8} \ll h_g \ll n^{-1/4}\) and \((n/N)^{1/6} \ll h_{\mu } \ll n^{-1/4} \) so that Assumption (C5) is satisfied.
Appendix D B-spline approximation and profile-likelihood estimation
Some Definitions on Vector and Matrix Norms:
For any vector \(\mathbf{a}=(a_{1},\ldots ,a_{s})^\mathsf{\scriptscriptstyle T}\in R^s \), denote the norm \(\Vert \mathbf{a}\Vert _r=(|a_1|^r+\dots +|a_s|^r)^{1/r}\), \(1\le r\le \infty \). For positive numbers \(a_n\) and \(b_n\), \(n>1\), let \(a_n\asymp b_n\) denote that \(\lim _{n\rightarrow \infty }a_n/b_n=c\), where c is some nonzero constant. Denote the space of the \(q^{th}\) order smooth functions as \(\mathbf{C}^{(q)}([0,{{\mathcal {E}}}] )=\left\{ \phi : \phi ^{(q)}\in \mathbf{C}[0,{{\mathcal {E}}}] \right\} \). For any \(s\times s\) symmetric matrix \(\mathbf{A}\), denote its \(L_q\) norm as \(\Vert \mathbf{A}\Vert _q =\mathrm{max}_{\mathbf{v}\in R^s,\mathbf{v}\ne 0}\Vert \mathbf{A}\mathbf{v}\Vert _q\Vert \mathbf{v}\Vert _q^{-1}\). Let \(\Vert \mathbf{A}\Vert _\infty =\mathrm{max}_{1\le i\le s}\sum _{j=1}^s|a_{ij}|\). For a vector \(\mathbf{a}\), let \(\Vert \mathbf{a}\Vert _{\infty }=\mathrm{max}_{1\le i\le s}|a_i|\).
We first assess the approximation error from using the estimated features \({\widehat{\mathbf{W}}}\) in \(l_n\). Once we establish the identifiability of \(l_n\) in the proof of Lemma 1, the approximation of losses would translate to the approximation of their minimums.
with \(\mathbf{Z}_i = (\mathbf{U}_i^\mathsf{\scriptscriptstyle T},\mathbf{W}_i{^{\scriptscriptstyle [1]}}^\mathsf{\scriptscriptstyle T},\ldots , \mathbf{W}_i{^{\scriptscriptstyle [q]}}^\mathsf{\scriptscriptstyle T})^\mathsf{\scriptscriptstyle T}\) be the loss with true features from the intensity functions. Let \(\varOmega \) be a sufficiently large compact neighborhood of
for \({\tilde{\mathbf{Z}}}_i\) between \({\widehat{\mathbf{Z}}}_i\) and \(\mathbf{Z}_i\). Since \(\varDelta _i\) is binary and \(\Vert {\varvec{\beta }}\Vert \) is bounded in compact set \(\varOmega \), we have
For \(T_2\), we apply the bounds for \(\varDelta _i\) and \(\Vert {\varvec{\beta }}\Vert \) along with the bound of the function \(e^x/(1+e^x) \in [0,1]\),
Thus, we obtain (A.14) by applying (A.16) and (A.17) to (A.15). \(\square \)
In the following theorems, we establish the consistency, asymptotic normality of our procedure.
Proof of Lemma 1
By Lemma A4, the loss with estimated features deviates from the loss with true features by at most \(\hbox {sup}_{i=1,\dots ,n}\Vert {\widehat{\mathbf{W}}}_i - \mathbf{W}_i\Vert \). Under Assumption (C5), the error decays faster than \(n^{-1/2}\) order. Thus, if either loss produces estimator identifying the true parameter at \(n^{-1/2}\) rate, both losses produce asymptotically equivalent consistent estimators. We focus the analysis of the loss with true features in the following.
For \(m\in C^q[0,{{\mathcal {E}}}] \), there exists \({\varvec{\gamma }}_0\in R^{P_n}\), such that
where \(\widetilde{m}(u)=\mathbf{B}_r^\mathsf{\scriptscriptstyle T}(u){\varvec{\gamma }}_0\) (de Boor 2001). In the following, we prove the results for the nonparametric estimator \( \widehat{m}(u,{\varvec{\beta }})\) in Theorem 1 when \({\varvec{\beta }}={\varvec{\beta }}_0\). Then the results also hold when \({\varvec{\beta }}\) is a \(\sqrt{n}\)-consistent estimator of \({\varvec{\beta }}_0\), since the nonparametric convergence rate in Theorem 1 is slower than \(n^{-1/2}\). Define the distance between neighboring knots as \(h_p=\xi _{p+1}-\xi _p,r\le p\le R_n+r\), and \(h=\mathrm{max}_{r\le p\le R_n+r}h_p\). Let \(\rho _n=n^{-1/2}h^{-1}+h^{q-1/2}\). We will show that for any given \(\epsilon >0\), for n sufficiently large, there exists a large constant \(C>0\) such that
This implies that for n sufficiently large, with probability at least \( 1-6\epsilon \), there exists a local maximum for (2) in the ball \(\{ {\varvec{\gamma }}_0+\rho _n{\varvec{\tau }}:\Vert {\varvec{\tau }}\Vert _2\le C\} \). Hence, there exists a local maximizer such that \(\Vert {\widehat{{\varvec{\gamma }}}}({\varvec{\beta }}_0)-{\varvec{\gamma }}_0\Vert _2=O_p(\rho _n)\). Note that
The first term above is negative-definite, and last two terms are also negative-definite because of Cauch-Schwartz inequality, hence \(\mathbf{S}_{{\varvec{\gamma }}{\varvec{\gamma }},i}({\varvec{\beta }}_0,{\varvec{\gamma }})\) is negative-definite. Thus, \(l_n({\varvec{\beta }}_0,{\varvec{\gamma }})\) is a concave function of \({\varvec{\gamma }}\), so the local maximizer is the global maximizer of (2), which will show the convergence of \({\widehat{{\varvec{\gamma }}}}({\varvec{\beta }}_0)\) to \({\varvec{\gamma }}_0\).
for some constant \(0<C_1'<\infty \) by Condition (C4). Thus, \(E(\Vert n^{-1}\mathbf{T}_{n1}\Vert _{2}^{2})\le P_nn^{-1}C_1'h\). By Condition (C3), we have \(h\asymp P_n^{-1}\). Then \(E(\Vert n^{-1}\mathbf{T}_{n1}\Vert _{2}^{2})\le C_1n^{-1}\) for some constant \(0<C_1<\infty \). Then for any \(\epsilon >0\), by Chebyshev’s inequality, we have \(\hbox {pr}(\Vert n^{-1}\mathbf{T}_{n1}\Vert _{2}\ge \sqrt{n^{-1}C_1\epsilon ^{-1}})\le \epsilon \), or equivalently
for a constant \(0<C_2'<\infty \) under Condition (C4). Therefore, \(E(\Vert \mathbf{T}_{n2}\Vert _2) \le \{P_n(C_2'h^{q+1}n)^2\}^{1/2} =P_n^{1/2}C_2'nh^{q+1}\le C_2nh^{q+1/2} \) for a constant \(0<C_2<\infty \), and \(E(\Vert \mathbf{T}_{n2}\Vert _{2}^2) \le P_n(C_2'h^{q+1}n)^2 \le (C_2nh^{q+1/2})^2\). Again by Chebyshev’s inequality, for \(1/4>\epsilon >0\), we have
when \(C>\mathrm{max}(C_3^{-1}\sqrt{C_1\epsilon ^{-1}},\epsilon ^{-1/2}C_3^{-1}C_2)\). This shows (A.19). Hence, we have \(\Vert {\widehat{{\varvec{\gamma }}}}({\varvec{\beta }}_0)-{\varvec{\gamma }}_0\Vert _{2}=O_p(\rho _n)=O_p(n^{-1/2}h^{-1}+h^{q-1/2})=o_p(1)\) under Condition (C3).
It is easily seen that \(E\{\Vert \mathbf{S}_{{\varvec{\gamma }},i}({\varvec{\beta }}_0,m)\Vert _\infty ^d\}\le C_4^d h\) for a constant \(1<C_4<\infty \) and any \(d\ge 1\), by Bernstein’s inequality, under condition (C3), we have
where the inequality above uses the fact that for arbitrary u, only r elements in \(\mathbf{B}_r(u)\) are non-zero.
Let \(\widehat{\mathbf{e}}=\mathbf{V}_n({\varvec{\beta }}_0)^{-1} n^{-1}\sum _{i=1}^n\mathbf{S}_{{\varvec{\gamma }},i}({\varvec{\beta }}_0,m)\). Let \(\mathbf{Z}=(\mathbf{Z}_1^\mathsf{\scriptscriptstyle T},\dots , \mathbf{Z}_n^\mathsf{\scriptscriptstyle T})^\mathsf{\scriptscriptstyle T}\). By Central Limit Theorem,
where \(\hbox {var}( {\widehat{\mathbf{e}}}|\mathbf{Z}) =\{\mathbf{V}_n({\varvec{\beta }}_0)\}^{-1}\{ n^{-2}\sum _{i=1}^n\mathbf{S}_{{\varvec{\gamma }},i}({\varvec{\beta }}_0,m)^{\otimes 2}\} \{\mathbf{V}_n({\varvec{\beta }}_0)\}^{-1} \) and \(\mathbf{B}_r^\mathsf{\scriptscriptstyle T}(u)\hbox {var}( {\widehat{\mathbf{e}}} | \mathbf{Z})\mathbf{B}_r(u)={\widehat{\sigma }}^2(u,{\varvec{\beta }}_0)\). With Lemmas A7 and A9, we can get that \(c_5(nh)^{-1} \Vert \mathbf{B}_r(u)\Vert _2^2\le \mathbf{B}_r^\mathsf{\scriptscriptstyle T}(u)\hbox {var}( {\widehat{\mathbf{e}}}|\mathbf{Z})\mathbf{B}_r(u) \le C_5(nh)^{-1} \Vert \mathbf{B}_r(u)\Vert _2^2, \) for some constants \(0<c_5,c_5<\infty \). So there exist constants \(0<c_\sigma \le C_\sigma <\infty \) such that with probability approaching 1 and for large enough n,
Therefore by Slutsky’s theorem \({\widehat{\sigma }}^{-1}(u,{\varvec{\beta }}_0)\left\{ \widehat{m}(u,{\varvec{\beta }}_0)-\widetilde{m}(u)\right\} \rightarrow \hbox {Normal} (0,1)\) and \(\widehat{m}(u,{\varvec{\beta }}_0)-\widetilde{m}(u)=O_p\left\{ (nh)^{-1/2}\right\} \) uniformly in \(u\in [0,{{\mathcal {E}}}] \). By \(\hbox {sup}_{u\in [0,{{\mathcal {E}}}] }|m(u)-\widetilde{m}(u)|=O(h^q)\), we have \(|\widehat{m}(u,{\varvec{\beta }}_0)-m(u)|=O_p\{(nh)^{-1/2}+h^q\}\) uniformly in \(u\in [0,{{\mathcal {E}}}]\). By Slutsky’s theorem and Condition (C3), we have
Because \(\mathbf{S}_{{\varvec{\beta }}{\varvec{\beta }},i}({\varvec{\beta }},{\varvec{\gamma }})\) is negative definite and \(E\{\mathbf{S}_{{\varvec{\beta }},i}({\varvec{\beta }}_0,m)\}=\mathbf{0}\), similar but simpler derivation as for Theorem 1 can be used to show the consistency of the maximizer \({\widehat{{\varvec{\beta }}}}\).
Because at any \({\varvec{\beta }}\), \(\sum _{i=1}^n\mathbf{S}_{{\varvec{\gamma }},i}\{{\varvec{\beta }},{\widehat{{\varvec{\gamma }}}}({\varvec{\beta }})\}=\mathbf{0}\), hence
where \(\mathbf{r}_1\) is the residual term and is of smaller order of \(\mathbf{V}_n({\varvec{\beta }}_0)^{-1} E\left\{ \mathbf{S}_{{\varvec{\beta }}{\varvec{\gamma }},i}^\mathsf{\scriptscriptstyle T}({\varvec{\beta }}_0,m)\right\} \) componentwise. Note that \(\mathbf{S}_{{\varvec{\beta }}{\varvec{\gamma }},i}({\varvec{\beta }},{\varvec{\gamma }})=O_p(h)\) uniformly elementwise. Hence,
Here we use the fact that \(\Vert \mathbf{V}_n({\varvec{\beta }}_0)^{-1}\Vert _2 = O_p(h^{-1})\) and \(\Vert \mathbf{V}_n({\varvec{\beta }}_0)^{-1}\Vert _\infty =O_p(h^{-1})\), where the former one is a direct corollary of Lemma A5 and the latter one is shown in Lemma A8. Therefore, \(\Vert \mathbf{r}_1\Vert _2 = o_p(h^{-1/2})\) and \(\Vert \mathbf{r}_1\Vert _\infty =o_p(1)\).
By Taylor expansion, for \({\varvec{\beta }}^*=\rho {\varvec{\beta }}_0+(1-\rho ){\widehat{{\varvec{\beta }}}}\), \(0<\rho <1\),
where \(\mathbf{r}_2\) is the residual term and is of smaller order of \(E\{\mathbf{S}_{{\varvec{\beta }}{\varvec{\gamma }},i}({\varvec{\beta }}_0,m)\}{\partial {\widehat{{\varvec{\gamma }}}}({\varvec{\beta }}_0)}/{\partial {\varvec{\beta }}^\mathsf{\scriptscriptstyle T}}\) componentwise. We claim that the residual term \(\mathbf{r}_2\) satisfies \(\Vert \mathbf{r}_2\Vert _2=o_p(1)\) and \(\Vert \mathbf{r}_2\Vert _\infty =o_p(1)\). This is because
where \({\varvec{\gamma }}^*=\rho {\varvec{\gamma }}_0+(1-\rho ){\widehat{{\varvec{\gamma }}}}\), \(0<\rho <1\), and the residual term \(\mathbf{r}\) in the second last equality satisfies \(\Vert \mathbf{r}\Vert _\infty =O_p(n^{-1/2})\) and \(\Vert \mathbf{r}\Vert _2=O_p(n^{-1/2}h^{1/2})\).
By Central Limit Theorem, \(n^{1/2}({\widehat{{\varvec{\beta }}}}-{\varvec{\beta }})\rightarrow \hbox {Normal}\{\mathbf{0},\mathbf{A}^{-1}\varvec{\varSigma }(\mathbf{A}^{-1})^\mathsf{\scriptscriptstyle T}\}\), where \(\varvec{\varSigma }\) is given in Theorem 2. \(\square \)
Proof of Theorem 1
We prove the theorem in two steps. First we derive the asymptotic distribution of the solution \({\tilde{{\varvec{\theta }}}}\) by restricting \({\varvec{\theta }}\) to the oracle group selection set \({\mathcal {S}}\). Then we validate that the \({\tilde{{\varvec{\theta }}}}\) satisfies the optimality condition of the original problem (6). Without loss of generality, we rearrange the order of the covariates by moving the nonzero groups to the front. We would have simpler notation with \({\mathcal {S}} = \{1,\dots , card({\mathcal {S}})\}\). We denote the Hessian and its limit
and the sub-matrices notations \(A_{{\mathcal {S}},\cdot }\) for selecting rows, \(A_{\cdot ,{\mathcal {S}}}\) for selecting columns, \(A_{{\mathcal {S}},{\mathcal {S}}}\) for selecting rows and columns in \({\mathcal {S}}\cup \{p+1,\dots , p+P_n\}\). We denote the variance of score as \( \mathbf{V}= E \left\{ (\mathbf{S}_{{\varvec{\beta }},i}^\mathsf{\scriptscriptstyle T}, \mathbf{S}_{{\varvec{\gamma }},i}^\mathsf{\scriptscriptstyle T})^\mathsf{\scriptscriptstyle T}(\mathbf{S}_{{\varvec{\beta }},i}^\mathsf{\scriptscriptstyle T}, \mathbf{S}_{{\varvec{\gamma }},i}^\mathsf{\scriptscriptstyle T})\right\} . \)
Define the oracle selection subspace \(R^{{\mathcal {S}}} = \{{\varvec{\theta }}\in R^{p+P_n}: \theta _j = 0, \text { for } j\le p, j\notin {\mathcal {S}}\}\) and the estimator under oracle selection
Since \({\mathcal {S}}\) contains only groups with nonzero coefficient of \({\varvec{\beta }}_0\), and \({\widehat{{\varvec{\beta }}}}_{\scriptscriptstyle \mathsf MLE}\) is consistent for \({\varvec{\beta }}_0\) by Lemma 2, the denominators in the penalty terms in (A.30) \(\Vert {\widehat{{\varvec{\beta }}}}_{\scriptscriptstyle \mathsf MLE,[g]}\Vert _2\) are bounded away from zero. Then choosing \(\lambda = o(n^{-1/2})\), we have the solution as
In the proof of the Lemma 2, we have establish for \(h^q \ll n^{-1/2}\) the asymptotic normality of \({\hat{{\varvec{\theta }}}}_{\scriptscriptstyle \mathsf MLE}\) and the consistency of Hessian
The oracle selection estimator \({\tilde{{\varvec{\theta }}}}\) must satisfy the conditions in (A.34) for positions in \(R^{{\mathcal {S}}}\) by the same set of optimality conditions for (A.30). We only need to verify that \({\tilde{{\varvec{\theta }}}}\) also satisfy the conditions in (A.34) for \(j \in {\mathcal {S}}^c = \{1,\dots ,p\}\setminus {\mathcal {S}}\). By Lemma 2 and the definition of \({\mathcal {S}}\), we have
By definition \({\tilde{{\varvec{\theta }}}} \in R^{{\mathcal {S}}}\), the \({\mathcal {S}}^c\) components of \({\tilde{{\varvec{\theta }}}}\) are all zero,
for \(g:\, {\varvec{\beta }}_{0,[g]} = {\mathbf {0}}\), i.e. all elements in \({\mathcal {S}}^c\). Therefore, we conclude that \({\hat{{\varvec{\beta }}}}_{\scriptscriptstyle \mathsf glasso}= {\tilde{{\varvec{\beta }}}}\) with large probability. The asymptotic distribution of \({\tilde{{\varvec{\beta }}}}\) (A.33) is thus the asymptotic distribution of \({\hat{{\varvec{\beta }}}}_{\scriptscriptstyle \mathsf glasso}\). \(\square \)
Applying the \(\sqrt{n}\) asymptotical normality of \({\widehat{{\varvec{\gamma }}}}_{\scriptscriptstyle \mathsf glasso}\) and \({\widehat{{\varvec{\beta }}}}_{\scriptscriptstyle \mathsf glasso}\) of Lemma 1 and 1 along with Assumption (C5), we conclude that
where \({\varvec{\gamma }}^*\) is an arbitrary vector in \(R^{P_n}\) with \(\Vert {\varvec{\gamma }}^*-{\varvec{\gamma }}_0\Vert _2 = o_p(1)\). Furthermore, for arbitrary \(\mathbf{a}\in R^{P_n}\),
We only prove the result for \(\partial ^2l_n({\varvec{\beta }}_0,{\varvec{\gamma }}^*)/\partial {\varvec{\gamma }}\partial {\varvec{\gamma }}^\mathsf{\scriptscriptstyle T}\). The proof for \(\mathbf{V}_n({\varvec{\beta }}_0)\) can be obtained similarly. We have
for some constant \(0<C_1',C_1<\infty \), because \(\int _0^{{{\mathcal {E}}}}\mathbf{B}_r(u)^{\otimes 2} du\) is an r-banded matrix with diagonal and \(j^{\mathrm{th}}\) off-diagonal elements of order O(h) uniformly elementwise, for \(j=1,\cdots ,r-1\), and 0 elsewhere.
Next, we investigate the order of \(\Vert -n^{-1}\{\partial ^2l_n({\varvec{\beta }}_0,{\varvec{\gamma }}^{*})/\partial {\varvec{\gamma }}\partial {\varvec{\gamma }}^\mathsf{\scriptscriptstyle T}\}\Vert _\infty \). We have
with probability 1 as \(n\rightarrow \infty \), where \(0<c_2,c_2'<\infty \) are constants. Here, for an arbitrary matrix \(\mathbf{A}\) we use \(\mathbf{A}_{jk}\) to denote its element in the \(j^{\mathrm{th}}\) row and the \(k^{\mathrm{th}}\) column. In the above inequalities, we use the fact that B-spline basis are all non-negative and are non-zero on no more than r consecutive intervals formed by its knots.
where the second term \(O_p(n^{-1/2}h)\) in the last equality is obtained using both the Central Limit Theorem and the matrices above are banded to the first order. Specifically, \(-n^{-1}\partial ^2 l_n({\varvec{\beta }}_0,{\varvec{\gamma }}_0)/\partial {\varvec{\gamma }}\partial {\varvec{\gamma }}^\mathsf{\scriptscriptstyle T}-\mathbf{V}_n({\varvec{\beta }}_0)\) has diagonal and \(j^{\mathrm{th}}\) off-diagonal element with order \(O_p(h^{q+1}+n^{-1/2}h)\) for \(j=1,\cdots ,r-1\) and all the other elements of order \(O_p(h^{q+2}+n^{-1/2}h^2)\). Further,
is a matrix with all elements of order O(1) uniformly. It is easily seen that \(\mathbf{V}_0({\varvec{\beta }})\) is positive definite, and \(\mathbf{V}_1({\varvec{\beta }})\) is semi-positive definite.
According to Demko (1977) and Theorem 4.3 in Chapter 13 of DeVore and Lorentz (1993), we have
for some constant \(0<C'<\infty \). Furthermore, there exists constants \(0<C''<\infty \) and \(0<\lambda <1\) such that \(|\{\mathbf{V}_0({\varvec{\beta }})^{-1}\}_{jk}|\le C''\lambda ^{|j-k|}\) for \(j,k=1,\cdots ,P_n\).
Denote \(\mathbf{W}= -\mathbf{V}_0({\varvec{\beta }}_0)^{-1}\mathbf{V}_1({\varvec{\beta }}_0)\). There exists constant \(0<\kappa <\infty \) such that \(|\{\mathbf{V}_1({\varvec{\beta }}_0)\}_{jk}|<\kappa \) for \(j,k=1,\cdots ,P_n\). Hence,
where \(\kappa _1 = \mathrm{max}\{1,2C''\kappa (1-\lambda )^{-1}\}\ge 1\).
Let \(P_n h \le \kappa _2\), where \(1\le \kappa _2<\infty \) is a constant. Similar derivation as before shows there exists some constant \(0<{\widetilde{c}}<{\widetilde{C}}<\infty \), such that for arbitrary \(\mathbf{a}\in R^{P_n}\), \({\widetilde{c}}\Vert \mathbf{a}\Vert _2^2<\mathbf{a}^\mathsf{\scriptscriptstyle T}\mathbf{V}_0({\varvec{\beta }}_0)\mathbf{a}<{\widetilde{C}}\Vert \mathbf{a}\Vert _2^2\) and \({\widetilde{c}}\Vert \mathbf{a}\Vert _2^2<\mathbf{a}^\mathsf{\scriptscriptstyle T}\{\mathbf{V}_0({\varvec{\beta }}_0)-h\mathbf{V}_1({\varvec{\beta }}_0)\}\mathbf{a}<\widetilde{C}\Vert \mathbf{a}\Vert _2^2\). Hence,
where \(\mathbf{J}_{P_n} = (\mathbf{J}_{ij})_{1\le i,j\le P_n}\) with \(\mathbf{J}_{ij}=1\) if \(j-i=1\) and \(\mathbf{J}_{ij}=0\) otherwise. Here \(\kappa _4=4\kappa _1^2\kappa _2(1+\kappa _1\kappa _2\kappa _3)\).
Assume the result holds for \(2,\cdots ,P_n-1\), then for \(P_n\), denote \(\mathbf{W}_{P_n,-P_n} = (W_{P_n 1},\cdots ,W_{P_n (P_n-1)})^\mathsf{\scriptscriptstyle T}\) and \(\mathbf{W}_{-P_n,P_n} = (W_{1 P_n},\cdots ,W_{(P_n-1) P_n})^\mathsf{\scriptscriptstyle T}\), we have
where the numerator converges to \(2\kappa _4\hbox {exp}(\kappa _2\kappa _4)\) as \(h\rightarrow 0\), or equivalently, \(P_n\rightarrow \infty \). Here in the first equation above we use the fact that the \((j,k)^{\mathrm{th}}\) element of the matrix \((\mathbf{I}_{P_n}+h\mathbf{W}_{P_n})^{-1}\) is the determinant of the matrix \(\mathbf{I}_{P_n}+h\mathbf{W}_{P_n}\) without its \(j^{\mathrm{th}}\) column and \(k^{\mathrm{th}}\) row, divided by the determinant of \(\mathbf{I}_{P_n}+h\mathbf{W}_{P_n}\) itself. Specifically, when \(j=k\), the absolute value of that \((j,k)^{\mathrm{th}}\) element is \(|\mathrm{det}( \mathbf{I}_{P_n-1}+h\mathbf{W}_{P_n-1})|/|\mathrm{det} (\mathbf{I}_{P_n}+h\mathbf{W}_{P_n})|=a_{P_n-1}/|\mathrm{det} (\mathbf{I}_{P_n}+h\mathbf{W}_{P_n})\); when \(j\ne k\), with certain column operations, we obtain \(|\mathrm{det} (\mathbf{J}_{P_n-1}+h\mathbf{W}_{P_n-1})|/|\mathrm{det} (\mathbf{I}_{P_n}+h\mathbf{W}_{P_n})|=b_{P_n-1}/|\mathrm{det} (\mathbf{I}_{P_n}+h\mathbf{W}_{P_n})|\).
Now it remains to show that there exists \(\kappa _5>0\), such that
for some constant \(0<c<\infty \) (Horn and Johnson 1990; Golub and Van Loan 1996).
The proof for \(\left\{ -n^{-1}\partial ^2 l_n({\varvec{\beta }}_0,{\varvec{\gamma }}_0)/\partial {\varvec{\gamma }}\partial {\varvec{\gamma }}^\mathsf{\scriptscriptstyle T}\right\} ^{-1}\) is similar, and hence is omitted. \(\square \)
where \({\hat{G}}\) is the Kaplan-Meier or empirical distribution estimator for censoring time distribution, and \(\xi (s) = \{e^s(s-1)+1\}/(e^s-1)^2\). We solve the equation by classical Newton’s method. Then, we calculate the initial estimator for baseline function \({\widehat{\alpha }}_{\scriptscriptstyle \mathsf init}\) by solving
Update \(\widehat{{\varvec{\beta }}}_{\scriptscriptstyle \mathsf update}\) and \({\widehat{\alpha }}_{\scriptscriptstyle \mathsf update}\) from \(\widehat{{\varvec{\beta }}}_{\scriptscriptstyle \mathsf init}\) and \({\widehat{\alpha }}_{\scriptscriptstyle \mathsf init}\) with the alternative B-spline approximation
Setting the initial value \({\widehat{{\varvec{\beta }}}}^{[0]} = \widehat{{\varvec{\beta }}}_{\scriptscriptstyle \mathsf init}\) and \({\widehat{\alpha }}^{[0]} = {\widehat{\alpha }}_{\scriptscriptstyle \mathsf init}\), we perform the iterative algorithm:
Update \({\varvec{\beta }}\) by the pseudo logistic regression
If \(\varDelta _i = 0\), observation-i contributes one entry in the pseudo data, \(0 \sim {\widehat{\mathbf{Z}}}_i\) with offset \(\hbox {log}\left\{ {\widehat{\alpha }}(t)^{[k]}(X_i)\right\} \).
If \(\varDelta _i = 1\), observation-i contributes two entries in the pseudo data, \(0 \sim {\widehat{\mathbf{Z}}}_i\) and \(1 \sim {\widehat{\mathbf{Z}}}_i\) both with offset \(\hbox {log}\left\{ {\widehat{\alpha }}(t)^{[k]}(X_i)\right\} \).
The solution is \({\widehat{{\varvec{\beta }}}}^{[k]}\).
During this step, we compute the integrals \(\int _0^{X_i}B_{r,p}(t)dt\) once at the initiation step and use the computation repeatedly. The parameters at the convergence are \(\widehat{{\varvec{\beta }}}_{\scriptscriptstyle \mathsf update}\), \({\widehat{\alpha }}_{\scriptscriptstyle \mathsf update}\) and \(\widehat{{\tilde{{\varvec{\gamma }}}}}_{\scriptscriptstyle \mathsf update}\).
3.
Obtain the final MLE estimators \({\widehat{{\varvec{\beta }}}}_{\scriptscriptstyle \mathsf MLE}\) and \({\widehat{{\varvec{\gamma }}}}_{\scriptscriptstyle \mathsf MLE}\). We use \({\widehat{{\varvec{\beta }}}}^{[0]} = \widehat{{\varvec{\beta }}}_{\scriptscriptstyle \mathsf update}\) as initial value for \({\varvec{\beta }}\) and calculate the initial value for \({\varvec{\gamma }}\) from the linear regression
Liang, L., Hou, J., Uno, H. et al. Semi-supervised approach to event time annotation using longitudinal electronic health records.
Lifetime Data Anal28, 428–491 (2022). https://doi.org/10.1007/s10985-022-09557-5