
Abstract
Dealing with finite Markov chains in discrete time, the focus often lies on convergence behavior and one tries to make different copies of the chain meet as fast as possible and then stick together. There are, however, discrete finite (reducible) Markov chains, for which two copies started in different states can be coupled to meet almost surely in finite time, yet their distributions keep a total variation distance bounded away from 0, even in the limit as time tends to infinity. We show that the supremum of total variation distance kept in this context is \(\tfrac{1}{2}\).
Similar content being viewed by others

1 Introduction
When the long-time behavior of Markov chains is analyzed, one of the most common strategies is to couple several copies of the chain started in different states. In doing so, one standard approach is to define two copies of a Markov chain (started in different states) on a common probability space, correlated in such a way that they are likely to meet within some moderate time, and glue them together as soon as this happens.
This idea is so predominant that little attention was directed away from such couplings; in the standard reference [6], it was even claimed erroneously that any coupling of two Markov chains with the same transition probabilities can be modified so that the two chains stay together at all times after their first simultaneous visit to a single state. A counterexample to this statement was in fact given in [8]: If a coupling of two copies of the same Markov chain is changed in such a way that the second copy mimics the behavior of the first one once they meet, the altered individual process might no longer be a copy of the given chain.
For the sake of simplicity, we want to restrict our considerations to time-homogeneous Markov chains evolving in discrete time and on countable state spaces—except for Remark 1 and Theorem 4.3, where we discuss how the argument used to derive Theorem 4.1 applies to more general settings as well. So let \({{\mathbf {X}}}=(X_n)_{n\in {\mathbb {N}}_0}\) denote a Markov chain on a countable state space S with transition probabilities \(\{P(r,s)={\mathbb {P}}(X_{n+1}=s\,|\,X_n=r);\ r,s\in S,\ n\in {\mathbb {N}}_0\}\). While \({\mathcal {L}}(X_n)\) will be used as shorthand notation for the distribution of \(X_n\) in general, we will denote the distribution of \(X_n\) given \(X_0=x\), i.e., for a copy of the chain started in \(x\in S\), by \(P^n(x,.)\).
In what follows, we want to describe and investigate the kind of Markov chain, that was first introduced and analyzed by Häggström [3]: a chain in which two copies started in different states can be coupled such that they almost surely meet, but their distributions do not come arbitrarily close to one another with respect to total variation distance (cf. Definition 1). This phenomenon—that is somewhat counterintuitive in the light of the usual coupling constructions—will be referred to as segregation of two states. Further, we consider the constant
where the supremum is taken over finite Markov chain transition matrices P and states x and y, such that two copies of the chain corresponding to P, one started in x and the other in y, can be coupled to meet a.s. in finite time. To put it briefly, the main result of this paper is that \(\kappa \) equals \(\tfrac{1}{2}\).
As a preparation, the second section deals with the concept of couplings in general and convergence of Markov chains. Much of this is standard, but there is also the lesser known but crucial distinction between Markovian and faithful couplings. Section 3 presents Häggström’s result (\(\kappa \ge 3-2\sqrt{2}\)) and puts the idea of segregating Markov chains into a broader context.
In Sect. 4, more precisely in Theorem 4.1, we prove that the value \(\tfrac{1}{2}\) is an upper bound on \(\kappa \).
In Sect. 5, a constructive and intuitively accessible example of a Markov chain is given, that segregates two states such that the total variation distance kept can be pushed arbitrarily close to \(\tfrac{1}{\mathrm {e}}\). This improves on the example in [3] and serves as a warm up for the more technical and implicit construction in the last section.
Finally, in Sect. 6 we introduce and employ the idea of separation to show that for any \(\varepsilon >0\), there exist Markov chains segregating two states x and y such that copies started in these states can be coupled to meet almost surely while their distributions \(P^n(x,.)\) and \(P^n(y,.)\) have a total variation distance of at least \(\tfrac{1}{2}-\varepsilon \) for all \(n\in {\mathbb {N}}\), see Theorem 6.2. Together with the upper bound from Sect. 4, this establishes our main result, Theorem 6.1, stating that \(\kappa =\tfrac{1}{2}\).
2 Preliminaries: Convergence and Couplings
In order to quantify the difference between two probability measures (such as the distributions of two copies of a Markov chain at a fixed time), there are quite a few distance measures. The so-called total variation distance is among the most common ones.
Definition 1
Let \(\mu \) and \(\nu \) be two probability distributions on a countable set S. The total variation distance between the two measures is then defined as
This notion of distance is used in most of the standard convergence theorems on finite Markov chains as well (e.g., see Thm. 4.9 in [6]):
Theorem 2.1
Suppose \((X_n)_{n\in {\mathbb {N}}_0}\) is an irreducible and aperiodic Markov chain on a finite state space S. Then, there exists a unique limiting distribution \(\pi \) on S, called the stationary distribution, as well as constants \(\alpha \in (0,1)\) and \(C>0\) such that
for all \(x\in S,\ n>0\).
If the distribution of a Markov chain at time n converges to the same distribution \(\pi \) as n tends to infinity, irrespective of its starting distribution, a standard way to measure the speed of convergence is the variation distance
Sometimes it is more convenient, however, to consider the related function
Both these functions, d and \({\overline{d}}\), are non-increasing in n and \({\overline{d}}\) is in addition submultiplicative, i.e., \({\overline{d}}(m+n)\le {\overline{d}}(m)\cdot {\overline{d}}(n)\). Submultiplicativity need not hold for d, but can be verified for \(2\,d\) instead. Furthermore, it holds that \(d(n)\le {\overline{d}}(n)\le 2\,d(n)\). For proofs of the elementary facts just stated, we refer to Lemma 2.20 in [1]. Note that there S is assumed to be finite, but the arguments immediately transfer to countable S.
On the basis of the notion of distance d, the central concept of mixing time is defined, loosely speaking, as the time it takes until the effect of the starting distribution has begun to disappear substantially.
Definition 2
Given a Markov chain, for which the distribution of \(X_n\) converges to a fixed distribution \(\pi \) (irrespective of the distribution of \(X_0\)), define its mixing time by
As already mentioned, the tool that often makes proofs about convergence of Markov chains both short and elegant is the coupling approach. Let us therefore properly define this standard concept and then highlight which additional properties a coupling can have.
Definition 3
We define a coupling of two copies of a Markov chain on S to be a process \(((X_n,Y_n))_{n\in {\mathbb {N}}_0}\) on \(S\times S\), with the property that both \((X_n)_{n\in {\mathbb {N}}_0}\) and \((Y_n)_{n\in {\mathbb {N}}_0}\) are Markov chains on S with the same transition probabilities (but possibly different starting distributions).
If the process \(((X_n,Y_n))_{n\in {\mathbb {N}}_0}\) is itself a Markov chain (not necessarily time-homogeneous), it is called a Markovian coupling.
In order to get good estimates on mixing times, it is often of importance to bring into line the long-term behavior of the chain started in different states. In order to do so, one wants to make sure that the two coupled chains stay together once they meet, more precisely: if \(X_m=Y_m,\) then \(X_n=Y_n,\) for all \(n\ge m\). Couplings with this property are sometimes called “sticky” couplings. As noted in the introduction, it is however not possible to modify every coupling in such a way that it becomes sticky by simply glueing together the two copies once they meet, see Prop. 3 in [8] for an example. The crucial property is the following:
Definition 4
A Markovian coupling \(((X_n,Y_n))_{n\in {\mathbb {N}}_0}\) of two copies of a Markov chain is called faithful if for all \(x_n,y_n,x_{n+1},y_{n+1}\in S\), \(n\in {\mathbb {N}}_0\):
and
It should be mentioned that the term “Markovian coupling” is used in [6] to describe what we just defined as faithful coupling. However, since we actually want to focus on couplings that are not faithful (but may still be Markov chains—as both the example in Sect. 5 and the one in [3] are), we want to make this distinction by adopting the definitions in [8] and deviate from the notions in [6].
In order to understand what makes faithful couplings special, note that in general a coupling of two copies \({{\mathbf {X}}}\) and \({\mathbf Y}\) of a Markov chain with transition probabilities \(\{P(r,s);\ r,s\in S\}\) fulfills
for all \(x_n,x_{n+1}\in S\), \(n\in {\mathbb {N}}_0\), and likewise
for all \(y_n,y_{n+1}\in S\), \(n\in {\mathbb {N}}_0\). So the extra condition on a faithful coupling amounts to \({\mathbb {P}}\left( X_{n+1}=x_{n+1}\,|\,(X_n,Y_n)=(x_n,y_n)\right) \) being constant in \(y_n\) and \({\mathbb {P}}\left( Y_{n+1}=y_{n+1}\,|\,(X_n,Y_n)=(x_n,y_n)\right) \) being constant in \(x_n\).
It is immediate to check that any faithful coupling can indeed be transformed into a sticky coupling by just letting the chains run according to the given coupling until they meet and then run them together as two identical copies of the same chain, without affecting the marginals. Exploiting this fact leads to the estimate
for any faithful coupling of two copies, \({{\mathbf {X}}}\) started in x and \({{\mathbf {Y}}}\) started in y, where
is the first meeting time of the coupled chains (cf. Thm. 1 in [8]).
3 Chains that Meet and Separate
If two copies of a Markov chain are coupled, but the coupling is not sticky, clearly they can meet in one state and separate afterward. As mentioned above, if the coupling is not faithful (i.e., violates the conditions given in Definition 4), in some cases it cannot be transformed into a sticky coupling by simply letting the two copies coalesce once they meet. As a by-product, Häggström [3] observed an even stronger form of incompatibility of two coupled copies of a chain that meet. He gives an example of a finite reducible Markov chain with the following property: Two copies of the chain, started in different states x and y, can be coupled in such a way that they meet almost surely in finite time, while the total variation distance of their distributions never drops below a fixed positive value. More precisely, he shows (see Prop. 4.1 in [3]):
Proposition 3.1
There exists a finite state Markov chain such that for two of its states x and y we have that
while on the other hand there exists a Markovian coupling of the chains \({{\mathbf {X}}}=(X_n)_{n\in {\mathbb {N}}_0}\) and \({\mathbf Y}=(Y_n)_{n\in {\mathbb {N}}_0}\), starting at \(X_0=x\) and \(Y_0=y\), with the property that their first meeting time \(\tau =\inf \{n\ge 0;\ X_n=Y_n\}\) is finite with probability 1.
Note that for any Markov chain and any two states x and y, the sequence \((||P^n(x,.)-P^n(y,.)||_{\mathrm {TV}})_{n\in {\mathbb {N}}_0}\) is non-increasing. This, together with the fact that the total variation distance is always nonnegative, guarantees the existence of \(\lim _{n\rightarrow \infty }||P^n(x,.)-P^n(y,.)||_{\mathrm {TV}}\).
In fact, the reducible Markov chain in the example given in [3] comprises only 6 states (see Fig. 1 below). For \(p\in [1-\frac{1}{2}\sqrt{2},\frac{1}{2}\sqrt{2}]\), two copies started in x and y can be coupled such that their first meeting time is a.s. less than or equal to 2 (for the explicit calculations, see Prop. 4.1 in [3]). The copies will reach one of the two absorbing states (a and b) after two steps and the probability that the chain started in x lands in a is \(1-2p\,(1-p)\), in b accordingly \(2p\,(1-p)\). By symmetry, for the chain started in y it is precisely reversed.

A first example of a segregating Markov chain—provided \(p\in [1-\frac{1}{2}\sqrt{2}, \frac{1}{2}\sqrt{2}] {\setminus }\{\frac{1}{2}\}\)
So for \(n\ge 2\), \(P^n(x,.)\) and \(P^n(y,.)\) are unchanging and different if \(p\ne \frac{1}{2}\). Choosing \(p=\frac{1}{2}\sqrt{2}\) (or \(p=1-\frac{1}{2}\sqrt{2}\)) maximizes their total variation distance at \(3-2\sqrt{2}\approx 0.17153\).
As mentioned in the introduction, we will call Markov chains that have the property described in Proposition 3.1 to be segregating the states x and y. From the convergence theorem, we know that such things cannot happen for irreducible finite Markov chains (not even periodic ones). In addition to that, even if the chain is either reducible or infinite, a coupling that lets two copies started in different states meet almost surely, while the total variation distance of their distributions stays bounded away from 0 for all time, cannot be faithful due to the coupling inequality (2).
4 The Upper Bound
From the previous section, we know that there exist finite reducible Markov chains that segregate two states x and y. A natural question in this respect is how large a total variation distance between \(P^n(x,.)\) and \(P^n(y,.)\) can be kept, under the condition that two copies started in x and y, respectively, can be coupled to meet in finite time almost surely—in other words, the value of \(\kappa \) as defined in (1). The example in [3] shows \(\kappa \ge 3-2\sqrt{2}\); the following theorem establishes \(\tfrac{1}{2}\) as an upper bound.
Theorem 4.1
Consider a Markov chain on the countable state space S and two fixed states x and y. Further, we denote by \({\mathbf X}=(X_n)_{n\in {\mathbb {N}}_0}\) and \({{\mathbf {Y}}}=(Y_n)_{n\in {\mathbb {N}}_0}\) two coupled copies of the chain, started in x and y, respectively, and their first meeting time by \(\tau \). If \({{\mathbf {X}}}\) and \({{\mathbf {Y}}}\) can be coupled in such a way that \({\mathbb {P}}(\tau <\infty )=1\), it holds that
This result is an immediate implication of the following proposition:
Proposition 4.2
Consider \({{\mathbf {X}}}=(X_n)_{n\in {\mathbb {N}}_0}\), \({\mathbf Y}=(Y_n)_{n\in {\mathbb {N}}_0}\) and \(\tau \) as above. Then, it follows that
Proof
Fix \(n\in {\mathbb {N}}_0\) and a subset \(A \subseteq S\) by means of which we define the processes \((M_t)_{t=0}^n\) and \((N_t)_{t=0}^n\) given by
and
It is easily checked that these processes are martingales (with respect to the filtrations generated by \({\mathbf {X}}\) and \({\mathbf {Y}}\) respectively). Further let \(B_x\) and \(B_y\) denote the events that \(M_t \ge \frac{1}{2}\) and \(N_t < \frac{1}{2}\), respectively, for all \(0 \le t \le n\). As the event \(B_x\cap B_y\) implies \(M_t\ne N_t\) and with that \(X_t\ne Y_t\) for all \(0 \le t \le n\) (almost surely), it follows that \(\{\tau \le n\}\) is (up to a nullset) contained in the union of \(B_x^{\,\text {c}}\) and \(B_y^{\,\text {c}}\).
Next, we define
where the infimum is understood to be n if the corresponding set is empty. Note that \(\tau _x\) and \(\tau _y\) are stopping times for \(M_t\) and \(N_t\), respectively. Since \((M_t)_{t=0}^n\) and \((N_t)_{t=0}^n\) are bounded martingales, the Optional Stopping Theorem (see for example Cor. 17.7 in [6]) gives the estimates
Combining these two inequalities, we get
Finally, maximizing the left-hand side over all subsets \(A\subseteq S\) yields
as claimed.\(\square \)
Remark 1
Reading carefully through the proof of Proposition 4.2, one may notice that the martingale argument used essentially does not require our general assumptions of time-homogeneity and countable state space. For time-inhomogeneous chains, \(M_t:={\mathbb {P}}\left( X_n \in A \,|\, X_t\right) \), can no longer be written as \(P^{n-t}(X_t, A)\) (likewise for \(N_t\)), but this does not impair the argument and we can again conclude \(\lim _{n\rightarrow \infty }||{\mathcal {L}}(X_n)-{\mathcal {L}}(Y_n)||_{\mathrm {TV}}\le \tfrac{1}{2}\), where \({\mathcal {L}}(X_n)\) denotes the distribution of \(X_n\). Given an uncountable state space, the first meeting time \(\tau \) is no longer measurable by default. If we add this as an extra condition, however, the above proof (with the minor modification that only measurable sets A are considered) extends to this setting as well.
To fully exhaust the range of validity of this argument, let us leave the default preconditions for a moment and consider continuous-time Markov processes in full generality (as e.g., Kallenberg [5] defines them). In this case, we have to add further technical assumptions to save the line of reasoning and result of Proposition 4.2. For a measurable set \(A\subseteq S\), time horizon \(T>0\) and \(0\le t\le T\), define (similar to the above)
Theorem 4.3
Consider a continuous-time Markov process (not necessarily time-homogeneous) with general state space S. Let \({\mathbf X}=(X_t)_{t\ge 0}\) and \({{\mathbf {Y}}}=(Y_t)_{t\ge 0}\) denote two coupled copies of the process, that are started in fixed states x and y respectively, and let \(\tau \) denote their first meeting time. Fix a time horizon \(T>0\) and assume that \(\{\tau \le T\}\) is measurable. If for all measurable sets \(A\subseteq S\), it is possible to choose versions of the martingales \((M_t)_{t\in [0,T]}\) and \((N_t)_{t\in [0,T]}\), as defined in (4), that are a.s. continuous from the right, while having the property that for all \(t\in [0,T]\), \(X_t=Y_t\) implies \(M_t=N_t\), it holds that
Proof
Again, we fix some measurable subset \(A\subseteq S\) and define the martingales \((M_t)_{t\in [0,T]}\) and \((N_t)_{t\in [0,T]}\) as in (4), with the two additional properties stated in the theorem. Following the proof of Proposition 4.2 (literally, besides replacing n by T), we can still conclude that \(\{\tau \le T\}\cap (B_x\cap B_y)\) is a nullset. Continuity from the right of \((M_t)_{t\in [0,T]}\) and \((N_t)_{t\in [0,T]}\) implies \(M_{\tau _x}\le \frac{1}{2}\) on \(B_x^{\,\text {c}}\) and \(N_{\tau _y}\ge \frac{1}{2}\) on \(B_y^{\,\text {c}}\). Using the Optional Stopping Theorem for continuous-time martingales (see e.g., Thm. (3.2) in [7]), we can conclude just as above. \(\square \)
Remark 2
A simple way to ensure the assumed properties of \((M_t)_{t\in [0,T]}\) and \((N_t)_{t\in [0,T]}\) is to consider a topology on S and to require two things: first, that the Markov process a.s. has right-continuous sample paths and second that the transition probabilities \({\mathbb {P}}(X_T\in A \,|\, X_t=x)\) are continuous in \(t\in [0, T)\) and \(x\in S\) for all measurable \(A\subseteq S\).
As an aside, it might be worth noting that the analogue of Proposition 4.2 is not valid if we drop the additional assumptions completely, as it might be possible then to alter trajectories without changing transition probabilities. For instance, consider the process \((X_t)_{t\in [0,1]}\) on \(S=\{0, 1\}\) defined by
Two independent copies, started at 0 and 1, respectively, and using independent copies of \(\xi \), will almost surely meet, but the total variation distance of their distributions stays 1 for all \(t\in [0,1]\).
Besides these generalizations, the statement from Proposition 4.2 can also be used to get upper bounds on mixing times—similar to the usual approach, see for example Cor. 5.3 in [6]—replacing the coupling inequality (2) as starting point. In doing so, we pay by an additional factor \(\tfrac{1}{2}\) in front of \({\mathbb {P}}(\tau \le n)\), but can in return employ any kind of coupling, not only faithful ones. It remains to be seen whether this will ever turn out useful in practice as basically all standard coupling constructions are faithful. However, we want to mention at this point that non-Markovian couplings actually already proved to be useful in applications, cf. [4] for instance.
Proposition 4.4
Consider a Markov chain \({\mathbf {X}}=(X_n)_{n\in {\mathbb {N}}_0}\) with the property that \({\mathcal {L}}(X_n)\) converges to a fixed distribution \(\pi \) irrespectively of the starting distribution. Further, suppose that for some \(\alpha \in (0,1]\) and each pair of states \(x,y\in S\) there exists a (not necessarily faithful or even Markovian) coupling \(((X_n,Y_n))_{n\in {\mathbb {N}}_0}\) of two copies of the chain started in x and y, respectively, such that the first meeting time \(\tau \) of the two coupled processes fulfills \({\mathbb {P}}(\tau \le n)\ge \alpha \). Then
Proof
From Proposition 4.2 we can conclude that
Consequently, as \({\overline{d}}\) is submultiplicative and dominates d, we get for any \(k\in {\mathbb {N}}:\)
Choosing \(k\ge \frac{\log \left( \tfrac{1}{4}\right) }{\log \left( 1-\tfrac{\alpha }{2}\right) }\), this estimate becomes
\(\square \)
5 A Simple Example that Narrows the Gap
In this section, we will present another finite state Markov chain that improves on the value of \(3-2\sqrt{2}\) established by Häggström [3]. To begin with, let us prepare a lemma, which will come in useful when the total variation distance in our example of a finite segregating Markov chain is to be assessed.
Consider a sequence of independent Bernoulli trials, each with success probability \(p<1\). The distribution of the number of successful attempts until r failures have occurred is called the negative binomial distribution with parameters r and p and commonly denoted by \(\mathrm {NB}(r,p)\).
Lemma 5.1
For \(\mu :=\mathrm {NB}(1,p)\) and \(\nu :=\mathrm {NB}(2,p)\), it holds that
for any \(p\in [0,1)\). If \(p=\tfrac{m}{m+1}\), where \(m\in {\mathbb {N}}_0\), this value simplifies to \(p^{\tfrac{1}{1-p}}\).
Proof
A standard calculation shows that for two probability distributions \(\mu \) and \(\nu \) on a discrete space S, their total variation distance can be calculated as
see for example Remark 4.3 in [6]. For \(\mu =\mathrm {NB}(1,p)\) and \(\nu =\mathrm {NB}(2,p)\), we have:
which implies \(\mu (k)\ge \nu (k)\) for \(k\le \big \lfloor \tfrac{p}{1-p}\big \rfloor =:m\).
Consequently, using the well-known formulas for a finite geometric sum and its derivative, we can compute the total variation distance and get
If \(p=\tfrac{m}{m+1}\), for some \(m\in {\mathbb {N}}_0\), the number \(\tfrac{p}{1-p}=m\) is integer and an elementary simplification of the expression to the right in (5) verifies the final claim. \(\square \)
Let us now use this lemma to establish the following result:
Proposition 5.2
For all \(\varepsilon >0\), there exists a Markov chain segregating two states x and y such that
Proof
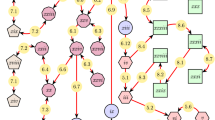
Let us consider the finite reducible MC depicted in Fig. 2. The state space S comprises \(3m+5\) states, among which the two initial states x and y as well as the \(m+2\) absorbing states labeled \(0,\dots ,m\) and >.

A segregating MC allowing for a fairly large total variation distance of two copies started in x and y respectively
It is immediate to check that the two copies, started in x respectively y, will hit an absorbing state after at most \(m+2\) steps and that on \(\{0,\dots ,m\}\) the distributions \(P^{m+2}(x,.)\) and \(P^{m+2}(y,.)\) coincide with \(\mathrm {NB}(1,p)\) and \(\mathrm {NB}(2,p)\), respectively. The probabilities to land in the state labeled > are
where \(Z_1\sim \mathrm {NB}(1,p)\) and \(Z_2\sim \mathrm {NB}(2,p)\).
Choosing \(p=\tfrac{m}{m+1}\), we can conclude from Lemma 5.1 that
for all \(n\ge m+2\). Writing \(q:=\tfrac{1}{1-p}=m+1\) shows
Taking m large enough, more precisely such that \(\big (1-\frac{1}{m+1}\big )^{m+1}> \frac{1}{\mathrm {e}}-\varepsilon \), will establish the claim if we can present a coupling that ensures that the two copies started in x and y will meet with probability 1, either before or when they hit an absorbing state.
In order to establish such a coupling, let \({\mathbf Y}=(Y_n)_{n\in {\mathbb {N}}_0}\) be a copy of the MC started in y. The copy \({{\mathbf {X}}}=(X_n)_{n\in {\mathbb {N}}_0}\) started in x mimics all movements of \({{\mathbf {Y}}}\), with the delay of one step, until it finally hits an absorbing state: First, it will move downwards until the two processes meet—in particular this implies that its first step is downwards with probability 1, as \(x\ne y\). Then, once \(X_n=Y_n\) for some \(1\le n\le m+1\), the next step of the process \({{\mathbf {X}}}\) is to move to the right to an absorbing state, i.e., \(X_{n+1}=n-1\). If \({{\mathbf {Y}}}\) never moves to the right, neither does \({\mathbf X}\) and both finally end up in the state >.
First of all, we need to check whether the two coordinate processes are indeed copies of the MC given in Fig. 2: It is obvious from our construction that it suffices to verify this for the process \({{\mathbf {X}}}\). The way \({{\mathbf {X}}}\) is defined—to move downwards in the first step and then always imitate the previous move of \({{\mathbf {Y}}}\) until ending up in an absorbing state—gives the right marginals due to the structure of the MC: As all the non-absorbing states apart from x have the same transition probabilities (p downwards and \(1-p\) to the right), \({{\mathbf {X}}}\) performs indeed a random walk on the graph in Fig. 2 according to the transition probabilities of the MC. Note that there is just this one way \({{\mathbf {Y}}}\) can end up in an absorbing state before it meets \({{\mathbf {X}}}\), namely if it moves downwards only. Then, however, \({{\mathbf {X}}}\) copies this behavior and ends up in the state > as well, so the coupling guarantees \(\tau \le m+2\) with probability 1. This trivially implies the almost sure finiteness of the first meeting time \(\tau \) and in conclusion the claim that the MC segregates the two states x and y. \(\square \)
In order to get the idea of how faithfulness plays a crucial role in this context, it is worth noting that the coupling in our example—likewise the one in [3]—is in fact Markovian, but not faithful. Such couplings, however, have to be non-faithful as faithfulness would imply that the total variation distance necessarily tends to 0 as already mentioned at the end of Sect. 3.
6 Closing the Gap
In this last section, we want to further improve the lower bound \(\frac{1}{\mathrm {e}}\), established by the example from the previous section, in order to determine the true value of the constant \(\kappa \), defined in (1). These efforts amount to the following:
Theorem 6.1
The value of \(\kappa \), denoting the supremum of \(\lim _{n\rightarrow \infty }||P^n(x,.)-P^n(y,.)||_{\mathrm {TV}}\) taken over all segregating Markov chains and segregated states x and y, is \(\tfrac{1}{2}\).
In view of Theorem 4.1, the final step to derive this result lies in proving that for any \(\varepsilon >0\), a value of at least \(\tfrac{1}{2}-\varepsilon \) can actually be attained. In order to do so, we will focus on (reducible) Markov chains with a specific structure which allows us to consider even simpler chains in finite time instead: When talking about a Markov chain with finite time horizon \({{\mathbf {X}}}=(X_t)_{t=0}^T\) on state space S with transition probabilities \(\{P(r,s);\ r,s\in S\}\), we are in fact thinking of a different chain, namely the reducible Markov chain \({{\mathbf {Y}}}=(Y_n)_{n\in {\mathbb {N}}_0}\) on the state space \(S\times \{0,\dots ,T\}\), with transition probabilities
In other words, we consider the evolution in time as new generations of states and stop the original chain at time T by making all states corresponding to time T absorbing. Incidentally, the example given in [3] is also of this kind; it corresponds to a two state Markov chain with \(T=2\) (cf. Fig. 1).
So for the remainder of this article, we actually consider Markov chains in discrete, finite time and with finite state space only. With this simplification in mind, we want to prove the following:
Theorem 6.2
For any \(\varepsilon >0\), there exists a Markov chain \({\mathbf {X}}\), two states x and y and a positive integer T such that
and such that there is a coupling of two copies of the chain, \(((X_t,Y_t))_{t=0}^T\), with initial states x and y, respectively satisfying
Before proceeding with a proof of this theorem, we want to introduce an alternative way to view segregating couplings. Let \({\mathbf {X}}\) be any discrete-time Markov chain with a finite state space S, and fix two states \(x, y\in S\) and a positive integer T.
For any coupling of two copies of this chain, \(((X_t,Y_t))_{t=0}^T\), started in \(X_0=x\) and \(Y_0=y\), respectively, one can consider the corresponding meeting probability
A natural question to ask in this setting is how large one can make this probability for a given (finite) Markov chain and given x, y and T by maximizing over all such couplings. Let \({\mathcal {X}}\) denote the subset of \(\{x\}\times S^{T}\) consisting of all possible trajectories of \({\mathbf {X}}=(X_t)_{t=0}^T\), and, respectively, \({\mathcal {Y}}\subseteq \{y\}\times S^{T}\) for \({\mathbf {Y}}=(Y_t)_{t=0}^T\). Observe that any coupling of \({\mathbf {X}}\) and \({\mathbf {Y}}\) is determined by the values \((p_{{{\mathbf {x}}}{{\mathbf {y}}}})_{{\mathbf {x}}\in {\mathcal {X}}, {\mathbf {y}}\in {\mathcal {Y}}}\), where \(p_{{{\mathbf {x}}}{{\mathbf {y}}}}\) denotes the probability of the event that both \({\mathbf {X}}={\mathbf {x}}=(x_t)_{t=0}^T\) and \({\mathbf {Y}}={\mathbf {y}}\). We will denote the maximal value of (6) by \({\mathcal {C}}_T(x,y)\) and call it the optimal meeting probability.
While finding explicit couplings that maximize the meeting probability can quickly become cumbersome as the number of possible trajectories grows, it turns out that the problem of optimizing the meeting probability has a useful dual, which allows us to determine \({\mathcal {C}}_T(x,y)\) without having to deal with the couplings directly. This duality corresponds to the idea of max-flow min-cut and König’s theorem in combinatorial optimization.
Definition 5
Let \({\mathcal {A}}=(A_t)_{t=0}^T\) be a sequence of subsets of S, the (finite) state space of the considered Markov chain \({\mathbf {X}}\). We will refer to any such sequence as a separating sequence. We define the separation of any separating sequence as
We say that the separating sequence is non-trivial if both summands on the right-hand side in (7) are nonzero. We further define the optimal separation \({\mathcal {S}}_T(x,y)\) as the maximum separation over all possible separating sequences.
It is not too hard to see that the optimal meeting probability and optimal separation are related. Specifically, for any coupling \(((X_t, Y_t))_{t=0}^T\) such that \((X_0, Y_0) = (x, y)\) and any separating sequence \({\mathcal {A}}=(A_t)_{t=0}^T\), we have
Maximizing the meeting probability over all possible couplings of two copies, started in x, y respectively, and minimizing the upper bound by maximizing the separation \({\mathcal {S}}^{{\mathcal {A}}}_T(x,y)\) over all separating sequences yields
However, for our purposes (namely to guarantee \({\mathcal {C}}_T(x,y)\)=1), we rather need to bound \({\mathcal {C}}_T(x,y)\) from below. In this respect, it is quite convenient that the inequality (8) actually holds as an equality, as the following theorem shows.
Theorem 6.3
Given an arbitrary but fixed finite Markov chain \({\mathbf {X}}\), two states \(x,y\in S\) and time horizon T, we have
Proof
A simple way to prove the reverse inequality is to employ the max-flow min-cut theorem, in the same way it can be used to prove Strassen’s monotone coupling theorem. Starting from the sets \({\mathcal {X}}\) and \({\mathcal {Y}}\) as above, we build the following directed graph, which will be denoted by \(\vec {G}=(V,\vec {E})\):
First we let each \({\mathbf {x}}\in {\mathcal {X}}\) and \({\mathbf {y}}\in {\mathcal {Y}}\) be represented by a node. Then, we add two further nodes: a source s and a sink t. When it comes to the directed edges, there will be an arrow \((s,{\mathbf {x}})\) for all \({\mathbf {x}}\in {\mathcal {X}}\) and \(({\mathbf {y}},t)\) for all \({\mathbf {y}}\in {\mathcal {Y}}\). Additionally, we include the edge \(({\mathbf {x}},{\mathbf {y}})\), if the two trajectories \({\mathbf {x}}\in {\mathcal {X}}\) and \({\mathbf {y}}\in {\mathcal {Y}}\) share at least one state, i.e., \(x_t=y_t\) for some \(0\le t \le T\); in the sequel, we will write this as \({\mathbf {x}}\sim {\mathbf {y}}\).
Finally, we have to assign capacities to these directed edges: The edges \((s,{\mathbf {x}})\) and \(({\mathbf {y}},t)\) will get capacities \({\mathbb {P}}({\mathbf {X}}={\mathbf {x}})\) and \({\mathbb {P}}({\mathbf {Y}}={\mathbf {y}})\), respectively. All edges going in between \({\mathcal {X}}\) and \({\mathcal {Y}}\) get capacity 1, see Fig. 3 below for an illustration.

The auxiliary graph \(\vec {G}\) to which we apply the max-flow min-cut theorem
Let us now consider the minimum cut problem on \(\vec {G}\). From the fact that the cut \((\{s\},V{\setminus }\{s\})\) has value 1, we know that we can focus on cuts that are not cutting any edges going in between \({\mathcal {X}}\) and \({\mathcal {Y}}\) when trying to find a minimal one. For a cut \((B,B^\text {c})\) of this kind, with \(s\in B\) and \(t\in B^\text {c}\) say, we note that \({\mathbf {x}}\sim {\mathbf {y}}\) can not occur for \({\mathbf {x}}\in {\mathcal {X}}\cap B\) and \({\mathbf {y}}\in {\mathcal {Y}}\cap B^\text {c}\), due to the assumption that no such edges are cut. Furthermore, the edges cut incident to s have at least the value \({\mathbb {P}}(X\in {\mathcal {X}}\cap B^\text {c})\), the ones incident to t at least \({\mathbb {P}}(Y\in {\mathcal {Y}}\cap B)\).
Let us define the set sequence \({\mathcal {A}}=(A_t)_{t=0}^T\) by
in order to bound the value of the given cut from below by
Consequently, as this bound applies to any minimal cut, using the max-flow min-cut theorem (see for example Thm. 1, Chap. III in [2]) we are guaranteed the existence of a maximal flow of value at least \(2-{\mathcal {S}}_T(x,y)\). Let us denote the respective flow through the edge corresponding to \({\mathbf {x}}\sim {\mathbf {y}}\) by \(q_{{\mathbf {x}}{\mathbf {y}}}\).
We can use this maximal flow to establish a coupling of \({\mathbf {X}}\) and \({\mathbf {Y}}\) in the same vein as in the Doeblin coupling lemma (see for instance Prop. 4.7 in [6]): First we let \({\mathbf {X}}={\mathbf {x}}\) and \({\mathbf {Y}}={\mathbf {y}}\) simultaneously with probability \(q_{{\mathbf {x}}{\mathbf {y}}}\) for all \({\mathbf {x}}\sim {\mathbf {y}}\). Then, we define \({\mathbf {X}}\) to follow the trajectory \({\mathbf {x}}\) with the remaining probability
and similarly \({\mathbf {Y}}\) to follow the trajectory \({\mathbf {y}}\) with probability
independently, for all \({\mathbf {x}}\in {\mathcal {X}}\) and \({\mathbf {y}}\in {\mathcal {Y}}\).
From the flow constraints, we know that all these probabilities are in [0, 1] and the resulting coupling satisfies \({\mathbb {P}}({\mathbf {X}}\sim {\mathbf {Y}})\ge 2-{\mathcal {S}}_T(x,y)\). The theorem then follows by combining this inequality with (8).\(\square \)
One can observe that, as the left-hand side of (9) is a probability and hence at most 1, we must always have optimal separation at least 1. Indeed, we can obtain separation equal to 1, for instance by taking \(A_t=S\) for all \(0\le t \le T\). Recall that a separating sequence is called non-trivial if the probabilities that \(X_t\in A_t\) for all \(0\le t\le T\) given \(X_0 = x\) and \(X_t \not \in A_t\) for all \(0\le t \le T\) given \(X_0=y\) are both nonzero. Clearly, any trivial separating sequence has separation at most 1, so it follows from Theorem 6.3 that for any finite state Markov chain in discrete time, any x, y and T as above, the following two statements are equivalent:
-
(a)
The meeting probability under optimal coupling of two copies, started in x, y respectively, is 1.
-
(b)
For all non-trivial separating sequences \({\mathcal {A}}= (A_t)_{t=0}^T\), we get \({\mathcal {S}}_T^{{\mathcal {A}}} (x,y) \le 1\).
In order to get acquainted with the idea behind the concept of separation, let us take a look at the simplest non-trivial example:
Example 1
Let \(0 < \alpha \le \frac{1}{2}\). Consider the Markov chain \({\mathbf {X}}\) with state space \(\{0, 1\}\) and transition probabilities \(P(0,1) = P(1,0) = \alpha \) as well as \(P(0,0)=P(1,1) = 1-\alpha \), and take \(x=0,\ y=1\). As mentioned above, the case where \(T=2\) is Häggström’s [3] example of a segregating Markov chain.
Since this chain only has two states, any non-trivial separating sequence must have \(A_t= \{0\}\) or \(A_t=\{1\}\) for each \(0\le t\le T\). As \(\alpha \le \frac{1}{2}\), the non-trivial separating sequence given by \(A_t=\{0\}\) for all t is obviously best possible. It is immediate to check that its separation equals \(2(1-\alpha )^T\). Hence, the optimal meeting probability of two copies, started in states 0 and 1, respectively, is 1 if and only if \(2(1-\alpha )^T \le 1\). Using induction, one can easily check that for this chain we have
So by choosing \(\alpha = \alpha (T)\) such that \(2(1-\alpha )^T=1\), we obtain a Markov chain that segregates the states 0 and 1 with total variation distance \((2^{1-1/T} - 1)^T\), which tends to \(\frac{1}{4}\) as \(T\rightarrow \infty \).
The next example is supposed to illustrate that reducible Markov chains obtained from irreducible and aperiodic finite chains in finite time, in the way described before Theorem 6.2, usually do segregate any two states:
Example 2
Let \({\mathbf {X}}\) be any irreducible aperiodic Markov chain with a finite state space S, and let x and y be any two states. Pick \(\varepsilon >0\) and \(n\in {\mathbb {N}}\) such that \(P^n(x', y') \ge \varepsilon \) for all \(x',y'\in S\). Then, for any non-trivial separating sequence \((A_t)_{t=0}^{nk}\), we have
for any \(k\in {\mathbb {N}}\). Hence, by taking \(T=nk\) for a sufficiently large k it follows that the optimal meeting probability during [0, T] is 1. This shows that, unless \(||P^T(x,.)- P^T(y,.)||_{\mathrm {TV}}=0\), the Markov chain segregates the two states x and y, choosing T sufficiently large.
We now turn to the proof of Theorem 6.2. Let \({\mathbf {X}}\) be the Markov chain with state space \(\{0, 1, \dots , L\}\) for some positive integer L and transition probabilities given by \(P(0, 1) = P(L, L-1) = 1-P(0, 0) = 1-P(L, L) = \alpha \) as well as \(P(i, i+1) = P(i, i-1) = \frac{1}{2}\) for all \(0< i < L\), see Fig. 4. Such chains, with \(S=\{0, 1, \dots , L\}\) and the additional property that \(|X_{t+1}-X_t|\le 1\) a.s. for all t, are commonly called finite birth-and-death chains, cf. Section 2.5 in [6]. To begin with, our main interest lies in the optimal meeting probability of this chain given the starting states \(x=0\) and \(y=L\). We will then show that we can obtain segregation between 0 and L with total variation arbitrarily close to \(\frac{1}{2}\) by choosing L, T and \(\alpha \) appropriately.

A birth-and-death chain on \(\{0, 1, \dots , L\}\) as basic building block
The qualitative behavior of this chain for small \(\alpha \) is easy to describe: Most of the time, the process is either at 0 or L. Occasionally, that is at rate \(\alpha \), the process takes one step inwards and typically moves around for order L steps before hitting one of the marginal states 0 or L, more precisely the expected time to reach \(\{0,L\}\), when starting in state 1 equals \(L-1\). With probability \(1-\frac{1}{L}\), it will return to the same side it started at, with probability \(\frac{1}{L}\) it will cross over to the opposite side (check the analysis of the so-called gambler’s ruin problem in Section 2.1 in [6] for the explicit calculations).
In preparation to the in-depth analysis of the separation of states 0 and L, let us collect a few general estimations for this chain in the following lemma, which will come in useful later on. For the sake of clarity, we will use the standard big O notation to represent error terms, i.e., for any nonnegative function f in k and \(\alpha \), the expression \(O(f(k,\alpha ))\) denotes a quantity that is bounded in absolute value by \(c\cdot f(k,\alpha )\), where the constant \(c>0\) does not depend on \(k,\ \alpha \) or t.
Lemma 6.4
-
(a)
For any \(1 \le i \le L-1\) and \(t\ge 0\) we have
$$\begin{aligned} \begin{aligned} P^t(0, i)=P^t(L, L-i)\le 2\alpha . \end{aligned} \end{aligned}$$ -
(b)
For any \(t\ge 0\) we have
$$\begin{aligned} P^t(0, 0) = P^t(L, L) = \frac{1}{2} + \frac{1}{2} \left( 1-\frac{2\alpha }{L}\right) ^t + O(L\alpha ), \end{aligned}$$(10)$$\begin{aligned} ||P^t(0,.)- P^t(L,.)||_{\mathrm {TV}} = \left( 1-\frac{2\alpha }{L}\right) ^t + O(L\alpha ). \end{aligned}$$(11) -
(c)
For any \(0\le k \le L-1\) and \(t\ge 0\) we have
$$\begin{aligned} \begin{aligned}&{\mathbb {P}}\left( X_{t'} \le k \text { for all }0\le t' \le t\,|\, X_0=0\right) \\&\quad = {\mathbb {P}}\left( X_{t'} \ge L- k \text { for all }0\le t' \le t\,|\, X_0=L\right) \\&\quad = \left( 1 - \frac{\alpha }{k+1}\right) ^t + O(k\alpha ). \end{aligned} \end{aligned}$$(12)
Proof
-
(a)
The first statement easily follows by induction on t using the recursion
$$\begin{aligned} P^{t+1}(0, i) = P^t(0, i-1)\, P(i-1, i) + P^t(0, i+1)\, P(i+1, i), \end{aligned}$$which holds for any \(t\ge 0\) and any \(1\le i \le L-1\).
-
(b)
To show the second claim, consider the sequence \(a_t = {\mathbb {E}}\left[ X_t \,|\, X_0=0\right] \). Using part (a), we know that
$$\begin{aligned} a_t = L\cdot P^t(0, L)+O(L^2\alpha )=L-L\cdot P^t(0, 0) + O(L^2\alpha ), \end{aligned}$$(13)where the error terms are bounded by \(2\,L^2\alpha \) in absolute value. Furthermore, since \({\mathbb {E}}\left[ X_{t+1}-X_t\,|\, X_t\right] \) equals \(\alpha \) if \(X_t=0\), \(-\alpha \) if \(X_t=L\) and 0 otherwise, we can infer from (13)
$$\begin{aligned} a_{t+1}&= a_t + \alpha \cdot P^t(0, 0) - \alpha \cdot P^t(0, L)\\&= a_t + \alpha \,\left( 1 - \frac{a_t}{L} \right) - \alpha \, \frac{a_t}{L} + O(L\alpha ^2), \end{aligned}$$which implies
$$\begin{aligned} a_{t+1}-\frac{L}{2} = \left( 1-\frac{2\alpha }{L}\right) \cdot \left( a_t - \frac{L}{2}\right) + O(L\alpha ^2), \end{aligned}$$where the error term is bounded by \(4\,L\alpha ^2\) in absolute value irrespectively of t. Solving this recursion, using \(a_{0} = 0\) and \(\sum _{k=0}^{t-1}(1-\tfrac{2\alpha }{L})^k\le \tfrac{L}{2\alpha }\), yields
$$\begin{aligned} a_t = \frac{L}{2} - \frac{L}{2}\,\left( 1-\frac{2\alpha }{L}\right) ^t + O(L^2\alpha ). \end{aligned}$$The estimate (10) immediately follows from (13), which together with part (a) implies (11).
-
(c)
The case \(k=0\) is obvious, so we may assume \(k>0\). Let \(\tau \) denote the first time \(t\ge 0\) for which \(X_t = k+1\). Consider the sequence \(b_t = {\mathbb {E}}\left[ X_{t\wedge \tau }\,|\, X_0=0\right] \), where \(t\wedge \tau \) denotes the minimum of t and \(\tau \). Note that part (a) implies \({\mathbb {P}}\left( X_{t\wedge \tau } = i \,|\, X_0=0\right) \le {\mathbb {P}}\left( X_t = i \,|\, X_0=0\right) \le 2\alpha \) for any \(i\in \{1,\dots ,k\}\) and further
$$\begin{aligned} \begin{aligned} b_t&= (k+1)\cdot {\mathbb {P}}\left( X_{t\wedge \tau } = k+1 \,|\, X_0=0\right) + O(k^2\alpha )\\&= k+1 - (k+1)\cdot {\mathbb {P}}\left( X_{t\wedge \tau } = 0 \,|\, X_0=0\right) + O(k^2\alpha ). \end{aligned} \end{aligned}$$(14)With the same reasoning as in part (b), we end up in a similar situation with \(b_0=0\) and \(b_t\) satisfying the recursive formula
$$\begin{aligned} b_{t+1}&= b_t + \alpha \cdot {\mathbb {P}}\left( X_{t\wedge \tau } = 0 \,|\, X_0=0\right) \\&=b_t + \alpha \left( 1 - \frac{b_t}{k+1}\right) + O(k \alpha ^2). \end{aligned}$$Solving it gives \(b_t = k+1 - (k+1)\,( 1 - \frac{\alpha }{k+1})^t + O(k^2 \alpha )\) and plugging this into (14) completes the proof of part (c), using
$$\begin{aligned} {\mathbb {P}}\left( 1\le X_{t\wedge \tau }\le k \,|\, X_0=0\right) =O(k\alpha ) \end{aligned}$$and noting that \(X_{t\wedge \tau }\le k\) if and only if \(X_{t'}\le k\) for all \(0\le t'\le t\).
\(\square \)
Let us now take a closer look on the optimal separation of states 0 and L in this chain. To make our lives easier, we establish three auxiliary results showing that among the non-trivial separating sequences, there are very simple ones which are essentially best possible as T grows large.
Proposition 6.5
Let L be fixed, and let \(\alpha =\alpha (T) = {\varTheta }\left( \frac{1}{T}\right) \). Then, for sufficiently large T, any non-trivial separating sequence \({\mathcal {A}}=(A_t)_{t=0}^T\) such that \({\mathcal {S}}^{{\mathcal {A}}}_T(0,L)>1\) (if such exist) must satisfy \(0\in A_t\) and \(L\notin A_t\) for all \(0\le t \le T\).
Proof
By (10), we know that \(P^t(0, 0) = P^t(L, L) > 1/2\) for any \(0\le t \le T\) given T sufficiently large. Hence if \(0 \not \in A_{t_1}\) and \(L\in A_{t_2}\) for some \(0\le t_1, t_2 \le L\), then
So for T sufficiently large, either \(0\in A_t\) for all \(0\le t \le T\) or \(L\not \in A_t\) for all \(0\le t \le T\).
By symmetry, we can assume without loss of generality, that \(0 \in A_t\) for all \(0\le t \le T\). Note that if there is some \(t_1\) such that \(L \in A_{t_1}\), then by part (a) of Lemma 6.4, we get
So the proposition follows if we can show that there exists a constant \(\varepsilon >0\) such that for T sufficiently large any non-trivial separating sequence satisfies
First note that since \({\mathcal {A}}\) is non-trivial, there exists a trajectory \({\mathbf {y}}\in \{L\}\times S^T\) such that \(y_t\not \in A_t\) for all \(0\le t \le T\) and \({\mathbb {P}}({\mathbf {X}}={\mathbf {y}}\,|\,X_0=L)>0\). Further, recall that the chain can only attain \({\mathbf {y}}\) with positive probability if \(|y_{t+1}-y_t|\le 1\) for all \(0\le t\le T-1\).
Next, let \({\mathbf {X}}=(X_t)_{t=0}^{T+1}\) be a copy of the Markov chain started in \(X_0=0\). We define the process \({\mathbf {X}}'=(X'_t)_{t=0}^T\) as \(X'_t = X_{t+1}\) for all \(0\le t\le T\) if \(X_1=0\), and otherwise put \(X'_0=0\) and let this process evolve independently of \({\mathbf {X}}\). Clearly, this implies that \((X_t)_{t=0}^{T}\) and \({\mathbf {X}}'\) have the same distribution.
Now, if \(X_{t} = L\) for some \(0\le t \le T\), then the trajectory of \({\mathbf {X}}\) and \({\mathbf {y}}\) necessarily either intersect or cross. Consequently, we either have \(X_1\ne 0\) (which occurs with probability \(\alpha \)) or at least one of \({\mathbf {X}}\) and \({\mathbf {X}}'\) meets \({\mathbf {y}}\), and is thus outside \(A_t\) for some t. By the union bound, we find
From (12) we know that \({\mathbb {P}}(X_t\le L-1\text { for all }0\le t \le T\,|\, X_0=0)\) is bounded away from 1 as T tends to infinity with our choice of \(\alpha ={\varTheta }(\tfrac{1}{T})\). So choosing \(\varepsilon >0\) small, T large enough such that
will do the job.\(\square \)
Proposition 6.6
Let \({\mathcal {A}}=(A_t)_{t=0}^T\) be any separating sequence such that \(0 \in A_t\) and \(L\not \in A_t\) for all \(0\le t \le T\). For any \(0\le a \le T\), we define the separating sequence \({\mathcal {A}}^a =(A_t^a)_{t=0}^T\) by \(A^a_t:= A_{t+a\;(\text { mod }T+1)}\). Then
Proof
The case where \(a=0\) is obvious, so we may assume \(a>0\). By part (a) of Lemma 6.4, for any fixed \(0\le t\le T\), the probability that \(X_t \in A_t{\setminus } \{0\}\) given \(X_0=0\) is at most \(2\,L\alpha \). From this we can infer
where the first and last equality follow from the Markov property and the central one from time homogeneity of the chain.
By symmetry, the same argument works for the chain started at L and the sequence of complementary sets \((S{\setminus } A_t)_{t=0}^T\). \(\square \)
Proposition 6.7
For any separating sequence \({\mathcal {A}}=(A_t)_{t=0}^T\) such that \(0\in A_t\) and \(L\not \in A_t\) for all \(0\le t \le T\), there exists a \(k\in \{0,\dots ,L\}\) such that
where \(\underline{{\mathbf {k}}}\) denotes the constant separating sequence whose elements are all equal to the set \(\{0, 1, \dots , k\}\).
Proof
By Proposition 6.6, we have
For any \(0\le k \le L\), let us define
Note that the function f is decreasing, \(f(0)=1\) and \(f(L)=0\). To simplify the notation, we additionally set \(f(L+1) := 0\) and write \(M:=\max _{0\le t\le T} X_t\). Considering only the first summands coming from each of the separation terms \({\mathcal {S}}^{{\mathcal {A}}^a}_T(0,L),\ 0\le a\le T\), we find
Fix \(k\in \{0,\dots ,L\}\), pick \(k'\) to minimize \(\left| \{t: k'\in A_t\} \right| \) over \(\{0,\dots ,k\}\) and note that this implies
Let \(\tau \ge 0\) be the first time when the Markov chain visits state \(k'\). Given \(M=k\), we know \(\tau \le T\), hence
We conclude that
Arguing analogously in the case of \(X_0=L\), with the modifications that we consider \(\min _{0\le t\le T} X_t\) instead of \(\max _{0\le t\le T} X_t\) and \(\tau \) now denotes the first time when the chain is in state k, yields
where we used \(1-f(k)\ge 1-\tfrac{1}{T+1}\cdot \left| \{t: k\in A_t\} \right| \) to derive the inequality and the last equality follows from \(\sum _{k=0}^L f(k) - f(k+1) = 1\). By combining these two estimates, it follows that
From the fact that the coefficients \(f(k) - f(k+1),\ 0\le k\le L,\) sum up to 1, plus \(f(L) = f(L+1)\), we can conclude that there exists some \(k\in \{0,\dots ,L-1\}\) such that
which completes the proof. \(\square \)
Combining Propositions 6.5 and 6.7, it follows that for any fixed \(L\ge 1\), any \(\alpha = \alpha (T) = {\varTheta }\left( \frac{1}{T}\right) \) and T sufficiently large, the optimal separation \({\mathcal {S}}_T(0,L)\) is the maximum of 1 and
for \(0 \le k < L\), where the inequality follows from (12).
To finish the proof of Theorem 6.2, we need one more elementary estimation:
Lemma 6.8
Given \(A > 0\), define the function
Then it holds
Proof
First note that the function \(f_A\) lies in \(C^\infty ((0,1))\) and is symmetric around \(x=\frac{1}{2}\). Calculating its first two derivatives gives
If \(x\in (0,1)\) is a stationary point of \(f_A\), we necessarily have
and as a consequence the sign of \(f_A''(x)\) is given by the sign of
Due to \(A>0\), the function \(g_A\) is strictly convex. Assuming the existence of two local maxima of \(f_A\) on (0, 1)—at points \(x_1<x_2\) say—forces the existence of a local minimum at \(x_3\in (x_1,x_2)\). Hence \(\max \{f_A''(x_1),f_A''(x_2)\}\le 0\le f_A''(x_3)\), which contradicts the strict convexity of \(g_A\).
Consequently, \(f_A\) can have at most one local maximum in (0, 1), which then lies at \(x=\tfrac{1}{2}\) for symmetry reasons. In conclusion, \(f_A\) either attains its maximum on (0, 1) at \(x=\frac{1}{2}\) or converges to its supremum on the boundary.\(\square \)
Proof of Theorem 6.2
Applying Lemma 6.8 to (16) with \(A=\alpha T/(L+1)\), we see that we can pick \(\delta >0\) arbitrarily small, choose
and find that the optimal separation of the states 0 and L in the chain \({\mathbf {X}}\) on [0, T] is 1 if T is chosen sufficiently large (after having fixed L). Hence, by Theorem 6.3 and (11) we know that the chain \((X_t)_{t=0}^T\) segregates 0 and L. From (11) we can further read off that for L fixed
Given \(\varepsilon >0\), we can choose \(\delta >0\) small, L large enough and then pick T sufficiently large to make the right-hand side of (17) larger than \(\frac{1}{2}-\varepsilon \). This completes the proof. \(\square \)
Remark 3
One downside of the implicit construction proving Theorem 6.2 is the fact that it does not give much information about the coupling involved. As the coupling will have to take into account the whole trajectories of the two individual copies, it is highly unlikely that the coupled process will have the Markov property. In this respect, it is still an open problem if the value of \(\frac{1}{\mathrm {e}}\), established in Sect. 5, can be pushed further (as supremum of achievable total variation distances that can be retained in segregating Markov chains), if we restrict ourselves to Markovian couplings.
We can however rule out that there exists a single chain in discrete time with two segregated states x and y such that
i.e., for which the value \(\frac{1}{2}\) actually is attained (cf. the following proposition, which slightly improves the result from Theorem 4.1).
Proposition 6.9
Consider a Markov chain in discrete time with countable state space S and two states \(x,y\in S\). If two copies, \({\mathbf {X}}=(X_t)_{t\in {\mathbb {N}}_0}\) and \({\mathbf {Y}}=(Y_t)_{t\in {\mathbb {N}}_0}\), started in x and y, respectively, can be coupled to meet almost surely in finite time, it follows that
Proof
As a matter of fact, we can alter the proof of Proposition 4.2 to derive the above statement: For the reasoning there to work, we need a function \(f: {\mathbb {N}}_0\times S\rightarrow [0,1]\), replacing the martingales \(M_t\) and \(N_t\), with the following two properties:
-
(i)
\(\big (f(t,X_t)\big )_{t\in {\mathbb {N}}_0}\) is a martingale with respect to the natural filtration of \({\mathbf {X}}\), and likewise for \({\mathbf {Y}}\).
-
(ii)
\(f(0,x)-f(0,y) = \lim \limits _{n\rightarrow \infty } ||P^n(x,.)-P^n(y,.)||_{\mathrm {TV}}\).
In order to compile such a function, let us define the sets \(A_n\subseteq S, n\in {\mathbb {N}}_0,\) via
which implies \(||P^n(x,.)-P^n(y,.)||_{\mathrm {TV}}=P^n(x,A_n)-P^n(y,A_n)\), and further \(f_n(t,s):=P^{n-t}(s,A_n)\) for all \(t\le n\). Finally, choose f to be the limit of a pointwise converging subsequence of the uniformly bounded sequence of functions \((f_{n})_{n\in {\mathbb {N}}_0}\).
Then (ii) is immediate and since for all \(n\in {\mathbb {N}}_0\), \(f_n(t,X_t)\) is a martingale for \(0\le t\le n\), bounded by 0 and 1 from below and above, respectively, the conditional dominated convergence theorem ensures that \(f(t,X_t)\) inherits these properties.
Analogously to the proof of Proposition 4.2, let us define
as well as
Note that the almost sure limit of \(f(t,X_t)\) as \(t\rightarrow \infty \) exists, according to Doob’s martingale convergence theorem, which implies that \(f(\tau _x,X_{\tau _x})\) is well defined even on \(B_x=\{\tau _x=\infty \}\). Further note that \(B_x^{\,\text {c}}\cup B_y^{\,\text {c}}\) is an almost sure event, due to the fact that \({\mathbf {X}}\) and \({\mathbf {Y}}\) meet in finite time with probability 1.
If \({\mathbb {P}}(B_x^{\,\text {c}})>0\), we get the strict inequality from (3) as \(f(\tau _x,X_{\tau _x})<\tfrac{1}{2}\) on \(B_x^{\,\text {c}}\):
If both \(B_x^{\,\text {c}}\) and \(\{f(t,Y_t)> \tfrac{1}{2}\text { for some }t\in {\mathbb {N}}_0\}\) have probability 0, the fact that \({\mathbf {X}}\) and \({\mathbf {Y}}\) meet a.s. forces the events \(\{f(t,X_t)=\tfrac{1}{2}\text { for some }t\in {\mathbb {N}}_0\}\) and \(\{f(t,Y_t)=\tfrac{1}{2}\text { for some }t\in {\mathbb {N}}_0\big \}\) to have probability 1. Changing the stopping times to
gives
Hence, by symmetry it is safe to assume \({\mathbb {P}}(B_x^{\,\text {c}})>0\), which verifies the claim. \(\square \)
References
Aldous, D., Fill, J.A.: Reversible Markov Chains and Random Walks on Graphs. Unfinished monograph, recompiled 2014 http://www.stat.berkeley.edu/~aldous/RWG/book
Bollobás, B.: Modern Graph Theory. Springer, Berlin (1998)
Häggström, O.: A note on disagreement percolation. Random Struct. Alg. 18(3), 267–278 (2001)
Hayes, T.P., Vigoda, E.: Variable length path coupling. Random Struct. Alg. 31(3), 251–272 (2007)
Kallenberg, O.: Foundations of Modern Probability. Springer, Berlin (1997)
Levin, D.A., Peres, Y., Wilmer, E.L.: Markov Chains and Mixing Times. American Mathematical Society, Providence (2008)
Revuz, D., Yor, M.: Continuous Martingales and Brownian Motion, 3rd edn. Springer, Berlin (1999)
Rosenthal, J.S.: Faithful couplings of Markov chains: now equals forever. Adv. Appl. Math. 18(3), 372–381 (1997)
Acknowledgements
First of all, we want to thank Jeff Steif for bringing this special kind of coupling to our attention. Then, we want to give thanks to him, Olle Häggström, Peter Hegarty and the anonymous referees for their valuable comments on earlier drafts.
Author information
Authors and Affiliations
Corresponding author
Additional information
Research supported by grants from the Swedish Research Council and the Royal Swedish Academy of Sciences.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Hirscher, T., Martinsson, A. Segregating Markov Chains. J Theor Probab 31, 1512–1538 (2018). https://doi.org/10.1007/s10959-017-0743-7
Received:
Revised:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10959-017-0743-7