
Abstract
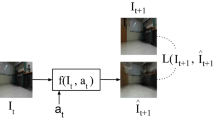
This study proposes an image-based action generation method using a controller that is trained with experiences autonomously collected by a robot. Operating a robot using its state or point in coordinate space is not always easy for human operators to control. This is because humans do not interpret the world as a coordinate space. Depending on the task, inputs such as voice-input or image-input are easier for human operators to use when managing a robot. Accordingly, we studied an image-based control method of robotic agents. Designing an image-based controller by hand for different tasks and input images is highly complex. Therefore, a controller which can be automatically trained from experiences collected by a robot is strongly preferred. In addition, when considering the operation of a robot in a real environment, the controller should guarantee the safety of a robot’s behavior in a way that is configurable and understandable by the human operator. However, most previous approaches trained the controller end-to-end, which does not guarantee the safety of the behavior learned by the controller. Instead of training the controller end-to-end, we train state prediction and cost estimation functions to solve the action generation as a path planning problem. By doing so, we can explicitly design and specify the undesired state of a robot in the configuration space. The results show that the proposed method can be used to provide safe navigation to different goal positions in a realistic living room-like environment with an hour of training data.
Similar content being viewed by others


References
Cabinet Office, Government of Japan: Moonshot research and development program https://www8.cao.go.jp/cstp/english/moonshot/top.html, Accessed 28 June 2020 (2019)
Foo, P, Warren, W, Duchon, A, Tarr, M: Do humans integrate routes into a cognitive map? map- versus landmark-based navigation of novel shortcuts. J. Exper. Psychol. Learn. Memory. Cogn. 31, 195–215,04 (2005)
Toyota Motor Corporation: Toyota shifts home helper robot r&d into high gear with new developer community and upgraded prototype. https://global.toyota/en/detail/8709541, (Accessed 28 June 2020) (2015)
Ebert, F, Finn, C, Lee, AX, Levine, S: Self-supervised visual planning with temporal skip connections. In: Proceedings of the 1st Annual Conference on Robot Learning, vol. 78, pp 344–356 (2017)
Finn, Chelsea, Goodfellow, Ian, Levine, Sergey: Unsupervised Learning for Physical Interaction through Video Prediction. In: Advances in Neural Information Processing Systems, vol. 29, pp 64–72 (2016)
Alan, W, Piergiovanni, AJ, Ryoo, Michael: Model-Based Behavioral Cloning with Future Image Similarity Learning, 3rd Annual Conference on Robot Learning, CoRL 2019. Proceedings, Osaka (2019)
Sun, L, Zhao, C, Yan, Z, Liu, P, Duckett, T, Stolkin, R: A novel weakly-supervised approach for rgb-d-based nuclear waste object detection. IEEE Sensors J. 19(9), 3487–3500 (2019)
Schaul, T, Horgan, D, Gregor, K, Silver, D: Universal value function approximators. In: Proceedings of the 32nd International Conference on Machine Learning, volume 37 of Proceedings of Machine Learning Research. PMLR, Lille, pp 1312–1320 (2015)
Hirose, N, Xia, F, Martín-Martín, R, Sadeghian, A, Savarese, S: Deep visual mpc-policy learning for navigation. IEEE Robot Autom Lett 4(4), 3184–3191 (2019)
Kumar, A, Gupta, S, Fouhey, D, Levine, S, Malik, J: Visual Memory for Robust Path Following. In: Advances in Neural Information Processing Systems, vol. 31, pp 765–774 (2018)
Pathak, D, Mahmoudieh, P, Luo, G, Agrawal, P, Chen, D, Shentu, Y, Shelhamer, E, Malik, J, Efros, AA, Darrell, T: Zero-Shot Visual Imitation. In: ICLR (2018)
Shyam, RA, Lightbody, P, Das, G, Liu, P, Gomez-Gonzalez, S, Neumann, G: Improving Local Trajectory Optimisation Using Probabilistic Movement Primitives. In: 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pp 2666–2671 (2019)
Karaman, S, Frazzoli, E: Sampling-based algorithms for optimal motion planning. Int. J. Rob. Res. 30(7), 846–894 (2011)
Kahn, G, Zhang, T, Levine, S, Abbeel, P: Plato: Policy Learning Using Adaptive Trajectory Optimization. In: 2017 IEEE International Conference on Robotics and Automation (ICRA), pp 3342–3349 (2017)
Burgard, W, Thrun, S, Fox, D: Probabilistic Robotic. MIT press, USA (2005)
Stojanovic, V, He, S, Zhang, B: State and parameter joint estimation of linear stochastic systems in presence of faults and non-gaussian noises. Int J Robust Nonlinear Control 30(16), 6683–6700 (2020)
Dong, X, He, S, Stojanovic, V: Robust fault detection filter design for a class of discrete-time conic-type non-linear markov jump systems with jump fault signals. IET. Control. Theory. Appl. 14(14), 1912–1919 (2020)
Chen, Z, Zhang, B, Stojanovic, V, Zhang, Y, Zhang, Z: Event-based fuzzy control for t-s fuzzy networked systems with various data missing. Neurocomputing 417, 322–332 (2020)
Liu, P, Yu, H, Cang, S: Adaptive neural network tracking control for underactuated systems with matched and mismatched disturbances. Nonlinear Dyn 98(2), 1447–1464 (2019)
Chiappa, S, Racaniere, S, Wierstra, D, Mohamed, S: Recurrent Environment Simulators. In: International Conference on Learning Representations (2017)
Hirose, N, Sadeghian, A, Xia, F, Martín-Martín, R, Savarese, S: Vunet: Dynamic scene view synthesis for traversability estimation using an rgb camera. IEEE Robot. Autom. Lett. 4(2), 2062–2069 (2019)
Lotter, W, Kreiman, G, Cox, D: Deep Predictive Coding Networks for Video Prediction and Unsupervised Learning. In: International Conference on Learning Representations (2017)
Mathieu, M, Couprie, C, LeCun, Y: Deep Multi-Scale Video Prediction beyond Mean Square Error. In: International Conference on Learning Representations (2015)
Junhyuk, O, Guo, X, Lee, H, Lewis, RL, Singh, S: Action-Conditional Video Prediction Using Deep Networks in Atari Games. In: Advances in Neural Information Processing Systems, vol. 28, pp 2863–2871 (2015)
Andrychowicz, M, Wolski, F, Ray, A, Schneider, J, Fong, R, Welinder, P, McGrew, B, Tobin, J, Pieter Abbeel, O, Zaremba, W: Hindsight experience replay. In: Guyon, I, Luxburg, UV, Bengio, S, Wallach, H, Fergus, R, Vishwanathan, S, Garnett, R (eds.) Advances in Neural Information Processing Systems, vol. 30, pp 5048–5058. Curran Associates, Inc. (2017)
Eysenbach, Salakhutdinov, RR, Levine, S: Search on the Replay Buffer Bridging Planning and Reinforcement Learning. In: Advances in Neural Information Processing Systems, vol 32, pp 15220–15231 (2019)
Florensa, C, Degrave, J, Heess, N, Springenberg, JT, Riedmiller, MA: Self-supervised learning of image embedding for continuous control. NIPS 2018 Workshop on Probabilistic Reinforcement Learning and Structured Control (2018)
Codevilla, F, Müller, M, López, A, Koltun, V, Dosovitskiy, A: End-To-End Driving via Conditional Imitation Learning. In: 2018 IEEE International Conference on Robotics and Automation (ICRA), pp 4693–4700 (2018)
Kahn, G, Villaflor, A, Ding, B, Abbeel, P, Levine, S: Self-Supervised Deep Reinforcement Learning with Generalized Computation Graphs for Robot Navigation. In: 2018 IEEE International Conference on Robotics and Automation (ICRA), pp 5129–5136 (2018)
Zhu, Y, Mottaghi, R, Kolve, E, Lim, JJ, Gupta, A, Fei-Fei, L, Farhadi, A: Target-Driven Visual Navigation in Indoor Scenes Using Deep Reinforcement Learning. In: 2017 IEEE International Conference on Robotics and Automation (ICRA), pp 3357–3364 (2017)
Chaplot, Devendra S, Salakhutdinov, R, Gupta, A, Gupta, S: Neural topological slam for visual navigation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2020)
Shah, D, Eysenbach, B, Kahn, G, Rhinehart, N, Ving, SL: Learning open-world navigation with visual goals (2020)
Hochreiter, S, Schmidhuber, J: Long short-term memory. Neural Comput 9, 1735–80, 12 (1997)
Shi, W, Caballero, J, Huszar, F, Totz, J, Aitken, AP, Bishop, R, Rueckert, D, Wang, Z: Real-Time Single Image and Video Super-Resolution Using an Efficient Sub-Pixel Convolutional Neural Network. In: The IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2016)
Kingma, DP, Adam, JB: A Method for Stochastic Optimization. In: International Conference on Learning Representations (2015)
Lavalle, SM: Planning Algorithms. Cambridge University Press, USA (2006)
Mnih, V, Kavukcuoglu, K, Silver, D, Rusu, AA, Veness, J, Bellemare, MG, Graves, A, Riedmiller, M, Fidjeland, AK, Ostrovski, G, Petersen, S, Beattie, C, Sadik, A, Antonoglou, I, King, H, Kumaran, D, Wierstra, D, Legg, S, Hassabis, D: Human-level control through deep reinforcement learning. Nature 518(7540), 529–533 (2015)
Yamamoto, T, Terada, K, Ochiai, A, Saito, F, Asahara, Y, Murase, K: Development of the Research Platform of a Domestic Mobile Manipulator Utilized for International Competition and Field Test. In: 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pp 7675–7682 (2018)
Koenig, N, Howard, A: Design and Use Paradigms for Gazebo, an Open-Source Multi-Robot Simulator. In: IEEE/RSJ International Conference on Intelligent Robots and Systems, pp 2149–2154. Sendai, Japan (2004)
Acknowledgements
All authors contributed to the study conception and design. Material preparation, data collection, experiments, and analysis were performed by Yu Ishihara. The manuscript was written by Yu Ishihara and all authors commented on each version of the manuscript. All authors read and approved the manuscript.
Funding
This study was supported by the Core Research for Evolutional Science and Technology (CREST) of the Japan Science and Technology Agency (JST) under Grant Number JPMJCR19A1.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Competing Interests
The authors have no conflicts of interest to declare that are relevant to the content of this article.
Additional information
Availability of Data and Materials
The data that support the findings and results of this study are available from the corresponding author, upon reasonable request.
Ethical Approval
Not applicable.
Consent to Participate
Not applicable.
Consent to Publish
Not applicable.
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
Appendix
1.1 A Hyperparameter Search Result
Here, we will show the hyperparameter search results for the three parameters used in our algorithm: ε, T, and M. We investigated the effect of each parameter with the tasks and environment introduced in Section 4.1. We set the parameters ε, T, and M to 225, 150, and 32, respectively, except for the searching parameter in the following experiments.
1.2 A.1 Threshold ε
Table 3 shows the task execution results for three different parameters of ε = 100, 200, 300. ε is the parameter used to check the termination of the algorithm. When the estimated number of steps drops below ε, the robot stops. A small ε value will lead the robot close to the goal, but action needs to be accurate to reach the goal. Conversely, a large ε value will not require accurate action but the robot may stop far from the goal. From Table 3, we can verify that when ε was set to 100, the robot was more prone to fail compared to other values of ε. Particularly, in task 1, when the algorithm was run with ε = 100, it could not complete the trials. Figure 13 shows the trajectories taken by the robot in task 1 when ε was set to 100. We can verify that the robot failed to complete the task because the robot could not stop near the goal, even though it was able to find the goal. Values between ε = 200 and ε = 300 worked well across all the tasks. However, from Table 3, a greater epsilon value was shown to have a negative impact on the final position of the robot. According to these results, we used ε = 225 in the simulation and ε = 200 in the real robot experiments.

Robots’s trajectory when ε is set to 100 in task 1. The robot failed to stop near the goal and keep finding the goal due to small threshold value
1.3 A.2 Prediction Steps T
The task execution results for four different parameters of T = 50, 100, 150, and 200 are shown in Table 4. T is the number of prediction steps. When the value of T is small, the computational time will be short but the prediction could be similar between the sampled paths. A similar prediction may lead to failure because the wrong path could be selected by the algorithm. Alternatively, a large T value requires more computational time. From Table 4, we can verify that a small T decreases the success rate of the tasks. A T greater than 150 worked well across the tasks. However, average computational times of the algorithm for T = 50, 100, 150, and 200 were 1.2s, 1.8s, 2.5s, and 3.0s, respectively. Considering the tradeoff between the success rate of the tasks and the computational time of the algorithm, we used M = 150 in our experiments.
1.4 A.3 Number of Sample Paths M
Table 5 shows the parameter search result for the four different parameters of M = 8, 16, 32, and 64. M is the number of paths sampled by the path planner π⋆. A small M may prevent the robot from reaching the goal because no path to the goal can be sampled. From Table 5, we can verify that there are only small differences in the performance among different values of M. However, in task 1, when M = 8 and M = 16, the success rate was slightly decreased. Figure. 14 shows the trajectory of the robot for M = 8 and M = 16. We can confirm that a small M made the robot fail to stop near the goal. From the experiment, an M greater than 32 worked well across all tasks. Thus, we used M = 32 in our experiments, considering the memory consumption of the GPU used for neural network computation.

Robots’s trajectory when M is set to 8(left) and 16(right) in task 1. The robot failed generating accurate paths and could not stop near the goal in some trials
B Navigation in an environment with unseen small obstacles
Here we show navigation results in an environment with unseen obstacles to check the robustness and the flexibility of our approach. We placed various obstacles in the environment used in Section 4.1 and conducted two experiments. See Fig. 15 for the overview of the environment. We first compared the navigation performance of our approach with DVMPC 2 in this new environment. We designed new navigation tasks (extra tasks) shown in Fig. 16 to compare the performance. In the second experiment, we conducted navigation tasks presented in Section 4.1 in this new environment to verify the effectiveness and the robustness of our approach. We used the same trained networks and configurations used in Section 4.1 for both experiments.

Simulation environment with unseen obstacles. Obstacles was placed after the data collection

Extra navigation tasks conducted in environment with small obstacles
Robot trajectory using DVMPC 2 and proposed method in extra tasks is shown in Fig. 17. From Fig. 17, we can confirm that DVMPC 2 fails navigating safely in the environment and collides with obstacles. In contrast, our approach succeeds navigating in the environment without colliding with obstacles. Overall navigation result is shown in Table 6. From the table, we can also verify that our proposed approach navigates robustly in the environment compared to DVMPC 2. DVMPC 2 failed navigating in extra task 3 and 4.

Comparison of robot trajectories during the simulation in the environment with small obstacles. The blue circle and yellow star denote the starting and goal positions, respectively. (In order of extra task 1, 2, 3, and 4 from the left)
Robot trajectory using proposed method in tasks 1 to 5 in the new environment is shown in Fig. 18. From the figure, we can verify that, even though new obstacles were placed, the robot succeeds navigating in the environment. Furthermore, by using collision-free paths generated by the path planner, the robot did not collide with obstacles including the ones which were newly added. Comparing the navigation result in Table 7 with Table 1, we can also verify that the existence of new obstacles did not change the overall performance of our proposed method, except for task 3. In task 3, we observed the robot navigating around the goal (See the third image in Fig. 18) in some trials. This behavior slowed down the robot reaching the goal. This is because the cost estimator failed estimating correct cost due to the obstacle placed near the goal. Training a robust estimator against unseen objects would be one of the future research direction.

Robot trajectories of task1 to task 5 during the simulation in the environment with unseen obstacles. The blue circle and yellow star denote the starting and goal positions, respectively. (In order of task 1, 2, 3, 4, and 5 from the left)
Rights and permissions
About this article

Cite this article
Ishihara, Y., Takahashi, M. Image-based Action Generation Method using State Prediction and Cost Estimation Learning. J Intell Robot Syst 103, 17 (2021). https://doi.org/10.1007/s10846-021-01465-4
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s10846-021-01465-4