
Abstract
Suppose \(\lambda \) and \(\mu \) are integer partitions with \(\lambda \supseteq \mu \). Kenyon and Wilson have introduced the notion of a cover-inclusive Dyck tiling of the skew Young diagram \(\lambda \backslash \mu \), which has applications in the study of double-dimer models. We examine these tilings in more detail, giving various equivalent conditions and then proving a recurrence which we use to show that the entries of the transition matrix between two bases for a certain permutation module for the symmetric group are given by counting cover-inclusive Dyck tilings. We go on to consider the inverse of this matrix, showing that its entries are determined by what we call cover-expansive Dyck tilings. The fact that these two matrices are mutual inverses allows us to recover the main result of Kenyon and Wilson. We then discuss the connections with recent results of Kim et al., who give a simple expression for the sum, over all \(\mu \), of the number of cover-inclusive Dyck tilings of \(\lambda \backslash \mu \). Our results provide a new proof of this result. Finally, we show how to use our results to obtain simpler expressions for the homogeneous Garnir relations for the universal Specht modules introduced by Kleshchev, Mathas and Ram for the cyclotomic quiver Hecke algebras.
Similar content being viewed by others

1 Introduction
The motivation for this paper is the study of the modular representation theory of the symmetric group, and more generally the representation theory of the cyclotomic Hecke algebra of type A. This area has recently been revolutionised by the discovery by Brundan and Kleshchev of new presentations for these algebras, which show in particular that the algebras are non-trivially \({\mathbb {Z}}\)-graded. The contribution in the present paper concerns the definition of the Specht modules, which play a central role in the representation theory of cyclotomic Hecke algebras. These modules have been studied within the graded setting by Brundan, Kleshchev and Wang, and developed further by Kleshchev, Mathas and Ram, who have given a presentation for each Specht module with a single generator and a set of homogeneous relations. These relations include homogeneous analogues of the classical Garnir relations for the symmetric group, which allow the Specht module to be expressed as a quotient of a ‘row permutation module’. Although the homogeneous Garnir relations are in some sense simpler than their classical counterparts, their statement in [10] is awkward in that the ‘Garnir elements’ involved are given as linear combinations of expressions in the standard generators \(\psi _1,\ldots ,\psi _{n-1}\) for the row permutation module which are not always reduced. Our main result concerning Specht modules is an expression for each Garnir relation as a linear combination of reduced expressions; this simplifies calculations with Specht modules, both theoretically and computationally.
But this result is a by-product of the main work in this paper, which is to consider tilings of skew Young diagrams by Dyck tiles. These tilings were introduced by Kenyon and Wilson, who defined in particular the notion of a cover-inclusive Dyck tiling. They used these tilings to give a formula for the inverse of a certain matrix M arising in the study of double-dimer models. We re-interpret the entries of M in terms of what we call cover-expansive Dyck tilings, and then, by proving recurrence relations for the numbers of cover-inclusive and cover-expansive Dyck tilings, we show that (sign-modified versions of) M and \(M^{-1}\) are in fact transition matrices for two natural bases for a certain permutation representation of the symmetric group. The fact that the two transition matrices are obviously mutually inverse provides a new proof of Kenyon and Wilson’s result. Along the way we give a result showing several different equivalent conditions to the cover-inclusive condition.
In order to derive our result on Garnir relations, we then express the sum of the elements of one of our two bases in terms of the other; this involves defining a certain function \(F\) on partitions, and proving a similar recurrence to the recurrence for cover-inclusive Dyck tilings. Combining this with our results on transition coefficients means that \(F(\lambda )\) equals the sum over all partitions \(\mu \subseteq \lambda \) of the number of cover-inclusive Dyck tilings of \(\lambda \backslash \mu \). In fact, this had already been shown by Kim, and then by Kim, Mészáros, Panova and Wilson, verifying a conjecture of Kenyon and Wilson. As well as providing a new proof of this result, our results working directly with the function \(F\) allow us to derive our application to Garnir relations without using Dyck tilings.
We now describe the structure of this paper. Section 2 is devoted to definitions. In Sect. 3 we study cover-inclusive Dyck tilings, giving equivalent conditions for cover-inclusiveness and then proving several bijective results which allow us to deduce recurrences for the number \({\text {i}}_{\lambda \mu }\) of cover-inclusive Dyck tilings of \(\lambda \backslash \mu \). In Sect. 4 we prove similar, though considerably simpler, recurrences for cover-expansive Dyck tilings. In Sect. 5 we recall the Young permutation module \(\mathscr {M}^{(f,g)}\) for the symmetric group; we define our two bases for this module, and use Dyck tilings to describe the transition coefficients. We then introduce the function \(F\) and use it to express the sum of the elements of the first basis in terms of the second, before summarising the relationship between our work and that of Kenyon, Kim, Mészáros, Panova and Wilson. Finally in Sect. 6 we give the motivating application of this work, introducing the Specht modules in the modern setting, and using our earlier results to give a new expression for the homogeneous Garnir relations.
Since the first version of this paper was written, we have become aware of the paper [12] by Shigechi and Zinn-Justin, where cover-inclusive and cover-expansive Dyck tilings are used in the calculation of parabolic Kazhdan–Lusztig polynomials. (They do not use the same terminology—in their paper, Dyck tiles are called “Dyck strips”, and the cover-inclusive and cover-expansive conditions are “rules I and II”. In addition—following the more widespread convention for Dyck paths—their convention for diagrams is the top-to-bottom reflection of ours.) It is likely that some of our results can be deduced from the results in [12].
2 Definitions
2.1 Partitions and Young diagrams
As usual, a partition is a weakly decreasing sequence \(\lambda =(\lambda _1,\lambda _2,\ldots )\) of non-negative integers with finite sum. We write this sum as \(|\lambda |\), and say that \(\lambda \) is a partition of \(|\lambda |\). When writing partitions, we may group equal parts together with a superscript, and omit trailing zeroes, and we write the partition \((0,0,\ldots )\) as \(\varnothing \).
The Young diagram of a partition \(\lambda \) is the set
We may abuse notation by identifying \(\lambda \) with its Young diagram; for example, we may write \(\lambda \supseteq \mu \) to mean that \(\lambda _i\geqslant \mu _i\) for all i. If \(\lambda \supseteq \mu \), then the skew Young diagram \(\lambda \backslash \mu \) is simply the set difference between the Young diagrams for \(\lambda \) and \(\mu \).
We draw (skew) Young diagrams as arrays of boxes in the plane, and except in the final section of this paper we use the Russian convention, where a increases from south-east to north-west, and b increases from south-west to north-east. For example, the Young diagram of \((7^2,4,3,2^2)\backslash (2,1^2)\) is as follows.

The conjugate partition to \(\lambda \) is the partition \(\lambda '\) obtained by reflecting the Young diagram for \(\lambda \) left to right; thus \(\lambda '_i=\left| \left\{ \left. j\geqslant 1\ \right| \ \smash {\lambda _j\geqslant i}\right\} \right| \) for all i.
We define a node to be an element of \({\mathbb {N}}^2\), and a node of \(\lambda \) to be an element of the Young diagram of \(\lambda \). The height of the node (a, b) is \(a+b\). The jth column of \({\mathbb {N}}^2\) is the set of all nodes (a, b) for which \(b-a=j\).
We use compass directions to label the neighbours of a node; for example, if \({\mathfrak {n}}\) is a node, then we write \(\mathtt {SW}({\mathfrak {n}})={\mathfrak {n}}-(0,1)\) and refer to this as the SW neighbour of \({\mathfrak {n}}\); we also write \(\mathtt {N}({\mathfrak {n}})={\mathfrak {n}}+(1,1)\), and similarly for the other compass directions.
A node \({\mathfrak {n}}\) of \(\lambda \) is removable if it can be removed from \(\lambda \) to leave the Young diagram of a partition (i.e. if neither \(\mathtt {NW}({\mathfrak {n}})\) nor \(\mathtt {NE}({\mathfrak {n}})\) is a node of \(\lambda \)), while a node \({\mathfrak {n}}\) not in \(\lambda \) is an addable node of \(\lambda \) if it can be added to \(\lambda \) to leave the Young diagram of a partition.
2.2 Tiles and tilings
We define a tile to be a finite non-empty set t of nodes that can be ordered \({\mathfrak {n}}_1,\ldots ,{\mathfrak {n}}_r\) such that \({\mathfrak {n}}_{i+1}\in \{\mathtt {NE}({\mathfrak {n}}_i),\mathtt {SE}({\mathfrak {n}}_i)\}\) for each \(i=1,\ldots ,r-1\). We say that t starts at its leftmost node, which we denote \({\text {st}}(t)\), and ends at its rightmost, which we denote \({\text {en}}(t)\). The height \({\text {ht}}(t)\) of t is defined to be \(\max \left\{ \left. {\text {ht}}({\mathfrak {n}})\ \right| \ \smash {{\mathfrak {n}}\in t}\right\} \), and we say that t is a Dyck tile if this maximum is achieved at the start and end nodes of t, i.e. \({\text {ht}}(t)={\text {ht}}({\text {st}}(t))={\text {ht}}({\text {en}}(t))\). t is big if it contains more than one node, and is a singleton otherwise. The depth of a node \({\mathfrak {n}}\in t\) is
Now suppose \(\lambda \) and \(\mu \) are partitions with \(\lambda \supseteq \mu \). A Dyck tiling of \(\lambda \backslash \mu \) is a partition of \(\lambda \backslash \mu \) into Dyck tiles. Given a Dyck tiling T of \(\lambda \backslash \mu \) and a node \({\mathfrak {n}}\in \lambda \backslash \mu \), we write \({\text {tile}}({\mathfrak {n}})\) for the tile containing \({\mathfrak {n}}\). We say that \({\mathfrak {n}}\) is attached to \(\mathtt {NE}({\mathfrak {n}})\) if \({\mathfrak {n}}\) and \(\mathtt {NE}({\mathfrak {n}})\) lie in the same tile in T, and similarly for \(\mathtt {SE}({\mathfrak {n}})\), \(\mathtt {NW}({\mathfrak {n}})\) and \(\mathtt {SW}({\mathfrak {n}})\). If t is a tile in T, the NE neighbour of t is the tile starting at \(\mathtt {NE}({\text {en}}(t))\), if there is one, while the SW neighbour of t is the tile ending at \(\mathtt {SW}({\text {st}}(t))\), if there is one. SE and NW neighbours of tiles are defined similarly.
Now we recast the main definition from [6]. Say that a Dyck tiling T of \(\lambda \backslash \mu \) is left-cover-inclusive if whenever \({\mathfrak {a}}\) and \(\mathtt {N}({\mathfrak {a}})\) are nodes of \(\lambda \backslash \mu \), \({\text {st}}({\text {tile}}(\mathtt {N}({\mathfrak {a}})))\) lies weakly to the left of \({\text {st}}({\text {tile}}({\mathfrak {a}}))\). Similarly, T is right-cover-inclusive if whenever \({\mathfrak {a}}\) and \(\mathtt {N}({\mathfrak {a}})\) are nodes of \(\lambda \backslash \mu \), \({\text {en}}({\text {tile}}(\mathtt {N}({\mathfrak {a}})))\) lies weakly to the right of \({\text {en}}({\text {tile}}({\mathfrak {a}}))\). Say that T is cover-inclusive if it is both left- and right-cover-inclusive.
We let \({\mathscr {I}}(\lambda ,\mu )\) denote the set of cover-inclusive Dyck tilings of \(\lambda \backslash \mu \) if \(\lambda \supseteq \mu \), and set \({\mathscr {I}}(\lambda ,\mu )=\emptyset \) otherwise. Let \({\text {i}}_{\lambda \mu }=\left| {\mathscr {I}}(\lambda ,\mu )\right| \).
Next we make a definition which is in some sense dual to the notion of cover-inclusiveness and which appears heavily disguised in [6]. Say that a Dyck tiling is left-cover-expansive if whenever \({\mathfrak {a}}\) and \(\mathtt {SE}({\mathfrak {a}})\) are nodes of \(\lambda \backslash \mu \), \({\text {st}}({\text {tile}}(\mathtt {SE}({\mathfrak {a}})))\) lies weakly to the left of \({\text {st}}({\text {tile}}({\mathfrak {a}}))\), and right-cover-expansive if whenever \({\mathfrak {a}}\) and \(\mathtt {SW}({\mathfrak {a}})\) are nodes of \(\lambda \backslash \mu \), \({\text {en}}({\text {tile}}(\mathtt {SW}({\mathfrak {a}})))\) lies weakly to the right of \({\text {en}}({\text {tile}}({\mathfrak {a}}))\). A Dyck tiling is cover-expansive if it is both left- and right-cover-expansive.
We write \({\text {e}}_{\lambda \mu }\) for the number of cover-expansive Dyck tilings of \(\lambda \backslash \mu \), setting \({\text {e}}_{\lambda \mu }=0\) if \(\lambda \nsupseteq \mu \). We shall see later that \({\text {e}}_{\lambda \mu }\leqslant 1\) for all \(\lambda ,\mu \).
Example
We illustrate four Dyck tilings of \((6^2,4,3,1^2)\backslash (4,1^2)\). Only the first one is cover-inclusive, and only the second is cover-expansive.

We end this section with some notation which we shall use repeatedly later. Suppose \(j\in {\mathbb {Z}}\) is fixed, and \(\lambda \) is a partition with an addable node \({\mathfrak {l}}\) in column j. We define \(X_{\lambda }\) to be the set of all integers x such that \(\lambda \) has a removable node \({\mathfrak {n}}\) in column \(j+x\), with \({\text {ht}}({\mathfrak {n}})={\text {ht}}({\mathfrak {l}})-1\), and \({\text {ht}}({\mathfrak {p}})<{\text {ht}}({\mathfrak {l}})\) for all nodes \({\mathfrak {p}}\in \lambda \) in all columns between j and \(j+x\). We set \(X_{\lambda }^+\) to be the set of positive elements of \(X_{\lambda }\). Note that \(x\in X_{\lambda }^+\) precisely when there is a Dyck tile \(t\subset \lambda \), starting in column \(j+1\) and ending in column \(j+x\), which can be removed from \(\lambda \) to leave a smaller partition; we denote this smaller partition \(\lambda ^{[x]}\). We define \(\lambda ^{[x]}\) for \(x\in X_{\lambda }^-=X_{\lambda }\setminus X_{\lambda }^+\) similarly.
Example
Take \(\lambda =(6,4^2,3,2^2)\). Then \(\lambda \) has an addable node in column 0, and for this node we have \(X_{\lambda }=\{-1,1,5\}\). The partitions \(\lambda ^{[x]}\) are as follows.

3 Cover-inclusive Dyck tilings
In this section we examine cover-inclusive Dyck tilings in more detail. We give some equivalent conditions to the cover-inclusive condition, and then we prove a recurrence for the number \({\text {i}}_{\lambda \mu }\) of cover-inclusive Dyck tilings.
3.1 Equivalent conditions
Theorem 3.1
Suppose \(\lambda \) and \(\mu \) are partitions with \(\lambda \supseteq \mu \), and T is a Dyck tiling of \(\lambda \backslash \mu \). The following are equivalent.
-
1.
T is cover-inclusive.
-
2.
If \({\mathfrak {a}}\) and \(\mathtt {N}({\mathfrak {a}})\) are nodes of \(\lambda \backslash \mu \), then \({\text {dp}}(\mathtt {N}({\mathfrak {a}}))\geqslant {\text {dp}}({\mathfrak {a}})\).
-
3.
If \({\mathfrak {a}}\) and \(\mathtt {N}({\mathfrak {a}})\) are nodes of \(\lambda \backslash \mu \), then \({\text {tile}}({\mathfrak {a}})+(1,1)\subseteq {\text {tile}}(\mathtt {N}({\mathfrak {a}}))\).
-
4.
If \({\mathfrak {a}}\) and \(\mathtt {N}({\mathfrak {a}})\) are nodes of \(\lambda \backslash \mu \) and \(\mathtt {NW}({\mathfrak {a}})\) is attached to \({\mathfrak {a}}\), then \(\mathtt {NW}(\mathtt {N}({\mathfrak {a}}))\) is a node of \(\lambda \backslash \mu \) and is attached to \(\mathtt {N}({\mathfrak {a}})\).
-
5.
If \({\mathfrak {a}}\) and \(\mathtt {N}({\mathfrak {a}})\) are nodes of \(\lambda \backslash \mu \) and \(\mathtt {N}({\mathfrak {a}})\) is the end node of its tile, then \({\mathfrak {a}}\) is the end node of its tile.
-
6.
T is right-cover-inclusive.
-
7.
If \({\mathfrak {a}}\) and \(\mathtt {N}({\mathfrak {a}})\) are nodes of \(\lambda \backslash \mu \) and \(\mathtt {NE}({\mathfrak {a}})\) is attached to \({\mathfrak {a}}\), then \(\mathtt {NE}(\mathtt {N}({\mathfrak {a}}))\) is a node of \(\lambda \backslash \mu \) and is attached to \(\mathtt {N}({\mathfrak {a}})\).
-
8.
If \({\mathfrak {a}}\) and \(\mathtt {N}({\mathfrak {a}})\) are nodes of \(\lambda \backslash \mu \) and \(\mathtt {N}({\mathfrak {a}})\) is the start node of its tile, then \({\mathfrak {a}}\) is the start node of its tile.
-
9.
T is left-cover-inclusive.
Proof
- (1\(\Rightarrow \)2):
-
Take \({\mathfrak {a}}\in \lambda \backslash \mu \) such that \(\mathtt {N}({\mathfrak {a}})\in \lambda \backslash \mu \), and let \({\mathfrak {c}}={\text {st}}({\text {tile}}({\mathfrak {a}}))\). Since T is cover-inclusive, there is a node \({\mathfrak {b}}\) in \({\text {tile}}(\mathtt {N}({\mathfrak {a}}))\) in the same column as \({\mathfrak {c}}\), and
$$\begin{aligned} {\text {dp}}(\mathtt {N}({\mathfrak {a}}))\geqslant {\text {ht}}({\mathfrak {b}})-{\text {ht}}(\mathtt {N}({\mathfrak {a}}))\geqslant {\text {ht}}({\mathfrak {c}})+2-({\text {ht}}({\mathfrak {a}})+2)={\text {dp}}({\mathfrak {a}}). \end{aligned}$$ - (2\(\Rightarrow \)3):
-
Suppose (3) is false, and take \({\mathfrak {a}}\in \lambda \backslash \mu \) such that \(\mathtt {N}({\mathfrak {a}})\in \lambda \backslash \mu \) and \({\text {tile}}({\mathfrak {a}})+(1,1)\nsubseteq {\text {tile}}(\mathtt {N}({\mathfrak {a}}))\). There is a node \({\mathfrak {b}}\in {\text {tile}}({\mathfrak {a}})\) such that \({\mathfrak {b}}+(1,1)\notin {\text {tile}}(\mathtt {N}({\mathfrak {a}}))\), and we may assume that \({\mathfrak {b}}\) is attached to \({\mathfrak {a}}\); in fact, by symmetry, we may assume \({\mathfrak {b}}\) is either \(\mathtt {NE}({\mathfrak {a}})\) or \(\mathtt {SE}({\mathfrak {a}})\). If \({\mathfrak {b}}=\mathtt {NE}({\mathfrak {a}})\), then \(\mathtt {N}({\mathfrak {a}})\) is attached to neither its NE nor its SE neighbour, so is the end node of its tile, and in particular \({\text {dp}}(\mathtt {N}({\mathfrak {a}}))=0\). On the other hand \({\text {dp}}({\mathfrak {a}})>{\text {dp}}({\mathfrak {b}})\geqslant 0\), contradicting (2). If instead \({\mathfrak {b}}=\mathtt {SE}({\mathfrak {a}})\), then \(\mathtt {NE}({\mathfrak {a}})\) is attached to neither its NW nor its SW neighbour, so is the start node of its tile, and has depth 0; but \({\text {dp}}({\mathfrak {b}})>{\text {dp}}({\mathfrak {a}})\geqslant 0\), and again (2) is contradicted.
- (3\(\Rightarrow \)4):
-
This is trivial.
- (4\(\Rightarrow \)5):
-
Suppose (5) is false, and take \({\mathfrak {a}}\in \lambda \backslash \mu \) as far to the left as possible such that \(\mathtt {N}({\mathfrak {a}})\in \lambda \backslash \mu \) and is the end node of its tile, while \({\mathfrak {a}}\) is not the end node of its tile. Since \({\mathfrak {a}}\) is not the end node of its tile, it is attached to either \(\mathtt {SE}({\mathfrak {a}})\) or \(\mathtt {NE}({\mathfrak {a}})\). If \({\mathfrak {a}}\) is attached to \(\mathtt {SE}({\mathfrak {a}})\), then \(\mathtt {SE}({\mathfrak {a}})\) is attached to its NW neighbour, but \(\mathtt {N}(\mathtt {SE}({\mathfrak {a}}))=\mathtt {NE}({\mathfrak {a}}){}\) is not attached to its NW neighbour, contradicting (4).
So assume that \({\mathfrak {a}}\) is attached to \(\mathtt {NE}({\mathfrak {a}})\). This implies in particular that \({\mathfrak {a}}\) has positive depth.
Claim 1
If \({\mathfrak {c}}\in {\text {tile}}({\mathfrak {a}})\) and \(\mathtt {N}({\mathfrak {c}})\in {\text {tile}}(\mathtt {N}({\mathfrak {a}}))\), then \({\mathfrak {c}}\) is not the start node of \({\text {tile}}({\mathfrak {a}})\).
Proof
Since \({\text {tile}}(\mathtt {N}({\mathfrak {a}}))\) is a Dyck tile and \(\mathtt {N}({\mathfrak {a}})\) is its end node, we have \({\text {ht}}(\mathtt {N}({\mathfrak {c}}))\leqslant {\text {ht}}(\mathtt {N}({\mathfrak {a}}))\). Hence \({\text {ht}}({\mathfrak {c}})\leqslant {\text {ht}}({\mathfrak {a}})\), so \({\text {dp}}({\mathfrak {c}})\geqslant {\text {dp}}({\mathfrak {a}})>0\).
Claim 2
For every node \({\mathfrak {b}}\in {\text {tile}}(\mathtt {N}({\mathfrak {a}}))\) we have \(\mathtt {S}({\mathfrak {b}})\in {\text {tile}}({\mathfrak {a}})\).
Proof
If the claim is false, let \({\mathfrak {b}}\) be the rightmost counterexample. Obviously \({\mathfrak {b}}\ne \mathtt {N}({\mathfrak {a}})\), and in particular \({\mathfrak {b}}\) is not the end node of its tile, so \({\mathfrak {b}}\) is attached to either \(\mathtt {NE}({\mathfrak {b}})\) or \(\mathtt {SE}({\mathfrak {b}})\). In the first case, the choice of \({\mathfrak {b}}\) means that we have \(\mathtt {SE}({\mathfrak {b}})\in {\text {tile}}({\mathfrak {a}})\); neither \({\mathfrak {b}}\) nor \(\mathtt {S}({\mathfrak {b}})\) is in \({\text {tile}}({\mathfrak {a}})\), so \(\mathtt {SE}({\mathfrak {b}})\) is the start node of \({\text {tile}}({\mathfrak {a}})\), contradicting Claim 1.
So we can assume \({\mathfrak {b}}\) is attached to \(\mathtt {SE}({\mathfrak {b}})\). The choice of \({\mathfrak {b}}\) means that \(\mathtt {S}(\mathtt {SE}({\mathfrak {b}}))\in {\text {tile}}({\mathfrak {a}})\) and is not attached to \(\mathtt {S}({\mathfrak {b}})\). By Claim 1 \(\mathtt {S}(\mathtt {SE}({\mathfrak {b}}))\) is not the start node of \({\text {tile}}({\mathfrak {a}})\), so is attached to \(\mathtt {S}(\mathtt {S}({\mathfrak {b}}))\). But now \(\mathtt {S}({\mathfrak {b}})\) is not attached to either its NE or SE neighbour, so is the end node of its tile. \(\mathtt {S}(\mathtt {S}({\mathfrak {b}}))\) is not the end node of its tile, and this contradicts the choice of \({\mathfrak {a}}\).
Now let \({\mathfrak {b}}={\text {st}}({\text {tile}}(\mathtt {N}({\mathfrak {a}})))\). Then by Claim 2, \({\mathfrak {c}}:=\mathtt {S}({\mathfrak {b}})\in {\text {tile}}({\mathfrak {a}})\), and by Claim 1 \({\mathfrak {c}}\) is not the start node of \({\text {tile}}({\mathfrak {a}})\). So \({\mathfrak {c}}\) is attached to either \(\mathtt {NW}({\mathfrak {c}})\) or \(\mathtt {SW}({\mathfrak {c}})\). The first possibility contradicts (4), since \({\mathfrak {b}}\) is not attached to \(\mathtt {NW}({\mathfrak {b}})\), so assume that \({\mathfrak {c}}\) is attached to \(\mathtt {SW}({\mathfrak {c}})\). But then \(\mathtt {NW}({\mathfrak {c}})\) is attached to neither \({\mathfrak {b}}\) nor \({\mathfrak {c}}\), so is the end node of its tile, while \(\mathtt {SW}({\mathfrak {c}})\) is not the end node of its tile, and this contradicts the choice of \({\mathfrak {a}}\).
- (5\(\Rightarrow \)6):
-
Suppose T is not right-cover-inclusive, and take \({\mathfrak {a}}\in \lambda \backslash \mu \) such that \(\mathtt {N}({\mathfrak {a}})\in \lambda \backslash \mu \) and \({\text {tile}}({\mathfrak {a}})\) ends strictly to the right of \({\text {tile}}(\mathtt {N}({\mathfrak {a}}))\). Let \({\mathfrak {b}}={\text {en}}({\text {tile}}(\mathtt {N}({\mathfrak {a}})))\); then there is a node in \({\text {tile}}({\mathfrak {a}})\) in the same column as \({\mathfrak {b}}\), which we can write as \({\mathfrak {b}}-(h,h)\) for some \(h>0\). If we let \(i\in \{1,\ldots ,h\}\) be minimal such that \({\mathfrak {b}}-(i,i)\) is not the end node of its tile, then \(\mathtt {N}({\mathfrak {b}}-(i,i))\) is the end node of its tile, contradicting (5).
- (6\(\Rightarrow \)7):
-
Suppose \({\mathfrak {a}},\mathtt {N}({\mathfrak {a}})\in \lambda \backslash \mu \) and \({\mathfrak {a}}\) is attached to \(\mathtt {NE}({\mathfrak {a}})\). Then \({\text {en}}({\text {tile}}({\mathfrak {a}}))\) lies to the right of \({\mathfrak {a}}\), so by (6) \({\text {en}}({\text {tile}}(\mathtt {N}({\mathfrak {a}})))\) does too. So \(\mathtt {N}({\mathfrak {a}})\) is attached to either \(\mathtt {NE}(\mathtt {N}({\mathfrak {a}}))\) or \(\mathtt {SE}(\mathtt {N}({\mathfrak {a}}))\). But \(\mathtt {SE}(\mathtt {N}({\mathfrak {a}}))=\mathtt {NE}({\mathfrak {a}})\) is attached to \({\mathfrak {a}}\), so \(\mathtt {N}({\mathfrak {a}})\) is attached to \(\mathtt {NE}(\mathtt {N}({\mathfrak {a}}))\).
- (7\(\Rightarrow \)8):
-
This is symmetrical to the argument that 4\(\Rightarrow \)5.
- (8\(\Rightarrow \)9):
-
This is symmetrical to the argument that 5\(\Rightarrow \)6.
- (9\(\Rightarrow \)1):
-
Since 6\(\Rightarrow \)7\(\Rightarrow \)8\(\Rightarrow \)9, right-cover-inclusive implies left-cover-inclusive. Symmetrically, left-cover-inclusive implies right-cover-inclusive, and hence cover-inclusive. \(\square \)
We shall use these equivalent definitions of cover-inclusiveness, often without comment, in what follows. We also observe the following property of cover-inclusive Dyck tilings, which we shall use without comment.
Lemma 3.2
Suppose T is a cover-inclusive Dyck tiling of \(\lambda \backslash \mu \). If \({\mathfrak {n}}\in \lambda \backslash \mu \) is the highest node in its column in \(\lambda \backslash \mu \), then every node in \({\text {tile}}({\mathfrak {n}})\) is the highest node in its column in \(\lambda \backslash \mu \).
Proof
Suppose not, and take \({\mathfrak {m}}\in {\text {tile}}({\mathfrak {n}})\) which is not the highest node in its column. Without loss of generality we may assume \({\mathfrak {m}}\) lies in the column immediately to the right of \({\mathfrak {n}}\), i.e. \({\mathfrak {m}}\) is either \(\mathtt {NE}({\mathfrak {n}})\) or \(\mathtt {SE}({\mathfrak {n}})\). But if \({\mathfrak {m}}=\mathtt {NE}({\mathfrak {n}})\), then the assumption \(\mathtt {N}({\mathfrak {m}})\in \lambda \backslash \mu \) means that \(\mathtt {N}({\mathfrak {n}})\in \lambda \backslash \mu \) (otherwise \(\lambda \backslash \mu \) would not be a skew Young diagram), a contradiction. So assume \({\mathfrak {m}}=\mathtt {SE}({\mathfrak {n}})\). But now \({\mathfrak {m}}\) is attached to \(\mathtt {NW}({\mathfrak {m}})\) and \(\mathtt {N}({\mathfrak {m}})\in \lambda \backslash \mu \), so by Theorem 3.1(4) \(\mathtt {N}({\mathfrak {n}})\in \lambda \backslash \mu \), contradiction. \(\square \)
3.2 Recurrences
Now we consider recurrences. We start with a simple result.
Proposition 3.3
Suppose \(\lambda \) and \(\mu \) are partitions and \(j\in {\mathbb {Z}}\), and that \(\mu \) has an addable node \({\mathfrak {m}}\) in column j, but \(\lambda \) does not have an addable node in column j. Let \(\mu ^+=\mu \cup \{{\mathfrak {m}}\}\). Then \({\text {i}}_{\lambda \mu }={\text {i}}_{\lambda \mu ^+}\).
Proof
The fact that \(\lambda \) does not have an addable node in column j implies that \(\lambda \supseteq \mu \) if and only if \(\lambda \supseteq \mu ^+\), so we may as well assume that both of these conditions hold. Given a cover-inclusive Dyck tiling of \(\lambda \backslash \mu ^+\), we can obtain a tiling of \(\lambda \backslash \mu \) simply by adding the singleton tile \(\{{\mathfrak {m}}\}\), and it is clear that this tiling is a cover-inclusive Dyck tiling.
In the other direction, suppose T is a cover-inclusive Dyck tiling of \(\lambda \backslash \mu \); then we claim that \({\mathfrak {m}}\) forms a singleton tile. If we let \({\mathfrak {n}}\) denote the highest node in column j of \(\lambda \backslash \mu \), then (since \(\lambda \) does not have an addable node in column j) \(\mathtt {NE}({\mathfrak {n}})\) and \(\mathtt {NW}({\mathfrak {n}})\) are not both nodes of \(\lambda \backslash \mu \); suppose without loss that \(\mathtt {NE}({\mathfrak {n}})\notin \lambda \backslash \mu \). Then in particular \({\mathfrak {n}}\) is not attached to \(\mathtt {NE}({\mathfrak {n}})\) in T, and so [using Theorem 3.1(7)] \({\mathfrak {m}}\) is not attached to \(\mathtt {NE}({\mathfrak {m}})\). \({\mathfrak {m}}\) cannot be attached to \(\mathtt {SE}({\mathfrak {m}})\) or \(\mathtt {SW}({\mathfrak {m}})\) (since these are not nodes of \(\lambda \backslash \mu \)), and a node in a Dyck tile cannot be attached only to its NW neighbour. So \({\mathfrak {m}}\) is not attached to any of its neighbours, i.e. \(\{{\mathfrak {m}}\}\) is a singleton tile as claimed. We can remove this tile, and we clearly obtain a cover-inclusive Dyck tiling of \(\lambda \backslash \mu ^+\). So we have a bijection between \({\mathscr {I}}(\lambda ,\mu )\) and \({\mathscr {I}}(\lambda ,\mu ^+)\). \(\square \)
Now we prove a more complicated result, for which it will help us to fix some notation.

Note that if \(T\in {\mathscr {I}}(\lambda ,\mu ^+)\), then there must be at least one tile starting in column \(j+1\), since there are more nodes in column \(j+1\) of \(\lambda \backslash \mu ^+\) than in column j; so \({\scriptstyle \overrightarrow{\displaystyle T}}\) is well-defined, and similarly \({\scriptstyle \overleftarrow{\displaystyle T}}\) is well-defined.
To prove our main recurrence result for the numbers \({\text {i}}_{\lambda \mu }\), we give three results in which we construct bijections between sets of cover-inclusive Dyck tilings. The first of these is as follows; recall the definition of \(X_\lambda \) from Sect. 2.2.
Proposition 3.4

Proof
Note first that if \(\lambda ^+\nsupseteq \mu ^+\) then \(\lambda \nsupseteq \mu ^+\), so both sides equal zero. Conversely, if \(\lambda \nsupseteq \mu ^+\), then either \(\lambda ^+\nsupseteq \mu ^+\) or there are no nodes in column j of \(\lambda ^+\backslash \mu ^+\), so again both sides are zero. So we may assume that \(\lambda \supseteq \mu ^+\). We’ll construct a bijection

We begin by giving an example so that the reader can see how the bijection works; in this example, the tiling on the left lies in \(\left\{ \smash {T\in {\mathscr {I}}(\lambda ,\mu ^+)}\ \left| \ {\scriptstyle \overrightarrow{\displaystyle T}}\notin X_{\lambda }\right. \right\} \), and the tiling on the right is its image under \(\phi _1\). The nodes \({\mathfrak {l}}\) and \({\mathfrak {m}}\) are marked, the nodes in column j are shaded, and the tile t (introduced below) is marked with dots.

Given T in \({\mathscr {I}}(\lambda ,\mu ^+)\) with \({\scriptstyle \overrightarrow{\displaystyle T}}\notin X_{\lambda }\), let t be the highest tile in T starting in column \(j+1\), and let A be the set of nodes in column j which are higher than \({\text {st}}(t)\). No node in column \(j+1\) can be attached to its NW neighbour, because the highest node in this column [namely \(\mathtt {SE}({\mathfrak {l}})\)] is not. So (by the choice of t) every node \({\mathfrak {b}}\) higher than \({\text {st}}(t)\) in column \(j+1\) is attached to \(\mathtt {SW}({\mathfrak {b}})\), and hence each \({\mathfrak {a}}\in A\) is attached to \(\mathtt {NE}({\mathfrak {a}})\). In a Dyck tiling a node cannot be attached only to its NE neighbour, so each \({\mathfrak {a}}\in A\) is attached to either its NW or SW neighbour. But a node in column \(j-1\) cannot be attached to its NE neighbour (because the highest node in column \(j-1\) is not), so every \({\mathfrak {a}}\in A\) is attached to \(\mathtt {NW}({\mathfrak {a}})\).
Now we consider columns x and \(x+1\), where \(x={\scriptstyle \overrightarrow{\displaystyle T}}+j=|t|+j\). Let \({\mathfrak {d}}=\mathtt {SE}({\mathfrak {l}})\). Then \({\mathfrak {d}}={\text {st}}(t)+(h,h)\) for some \(h\geqslant 0\), so by Theorem 3.1(3) \({\text {tile}}({\mathfrak {d}})\) contains \(t+(h,h)\). In particular, \({\text {tile}}({\mathfrak {d}})\) includes the node \({\mathfrak {e}}={\text {en}}(t)+(h,h)\) in column x, and (if \({\text {st}}(t)\ne {\text {en}}(t)\)) includes \(\mathtt {SW}({\mathfrak {e}})\). Since \({\mathfrak {d}}\) is the highest node in its column, the same is true for every node in \({\text {tile}}({\mathfrak {d}})\), and in particular neither \(\mathtt {N}({\mathfrak {e}})\) nor \(\mathtt {NW}({\mathfrak {e}})\) is a node of \(\lambda \). However, \({\mathfrak {e}}\) cannot be a removable node of \(\lambda \), since then \({\scriptstyle \overrightarrow{\displaystyle T}}=|t|\) would lie in \(X_{\lambda }\). So \(\mathtt {NE}({\mathfrak {e}})\) is a node of \(\lambda \backslash \mu \). Now \(\mathtt {NE}({\mathfrak {e}})\) is not attached to its NW neighbour (since this is \(\mathtt {N}({\mathfrak {e}})\notin \lambda \)), so no node in column \(x+1\) is attached to its NW neighbour, and so no node in column x is attached to its SE neighbour. This implies that any node in column x of positive depth must be attached to its NE neighbour, while any node in column x of depth 0 is the end node of its tile, and this tile has a NE neighbour. In particular, t has a NE neighbour.
Now suppose \({\mathfrak {a}}\in A\) has depth 1, and write \({\mathfrak {a}}={\text {st}}(t)+(i,i-1)\) for \(i>0\). Then \({\text {tile}}({\mathfrak {a}})\) contains \({\text {st}}(t)+(i,i)\), and hence contains \({\text {en}}(t)+(i,i)\). Since \({\mathfrak {a}}\) has depth 1, \({\text {en}}(t)+(i,i)\) has depth 0, and so from the last paragraph \({\text {en}}(t)+(i,i)\) is the end node of \({\text {tile}}({\mathfrak {a}})\), and \({\text {tile}}({\mathfrak {a}})\) has a NE neighbour.
Now we can construct \(\phi _1(T)\) as follows.
-
For each \({\mathfrak {a}}\in A\) of depth at least 2, change \({\text {tile}}({\mathfrak {a}})\) by replacing \({\mathfrak {a}}\) with \(\mathtt {N}({\mathfrak {a}})\).
-
For each \({\mathfrak {a}}\in A\) of depth 1, let \(u={\text {tile}}({\mathfrak {a}})\). Then u has a NE neighbour v; replace u and v with the following tiles:
-
the tile consisting of the portion of u ending at \(\mathtt {NW}({\mathfrak {a}})\);
-
the tile obtained by combining \(\mathtt {N}({\mathfrak {a}})\), the portion of u starting at \(\mathtt {NE}({\mathfrak {a}})\), and v.
-
-
Finally, let w denote the NE neighbour of t, and replace t and w with the tile obtained by joining \(\mathtt {NW}({\text {st}}(t))\) to t and w.
Clearly all these new tiles are Dyck tiles. It is also clear that the last tile mentioned is a big tile starting in column j. So to see that \(\phi _1(T)\) lies in the codomain, all that remains is to check that \(\phi _1(T)\) is cover-inclusive. But this is easy using (for example) Theorem 3.1(4).
To show that \(\phi _1\) is a bijection, we construct the inverse map

Suppose T is a cover-inclusive Dyck tiling of \(\lambda ^+\backslash \mu ^+\) in which there is at least one big tile starting in column j. Since the highest node in column j [namely \({\mathfrak {l}}\)] is not attached to its NE or NW neighbour, no node in column j is attached to its NE or NW neighbour. So from top to bottom, column j of T consists of:
-
(possibly) some nodes attached to both their SE and SW neighbours;
-
at least one node attached only to its SE neighbour;
-
(possibly) some singleton tiles.
Construct \(\psi _1(T)\) as follows.
-
For each node \({\mathfrak {a}}\) in column j which is attached to its SE and SW neighbours, change \({\text {tile}}({\mathfrak {a}})\) by replacing \({\mathfrak {a}}\) with \(\mathtt {S}({\mathfrak {a}})\).
-
For each node \({\mathfrak {a}}\) in column j which is the start of a big tile, let \({\mathfrak {b}}\) be the first node of \({\text {tile}}({\mathfrak {a}})\) to the right of column j which has the same height as \({\mathfrak {a}}\). Replace \({\text {tile}}({\mathfrak {a}})\) and \({\text {tile}}(\mathtt {SW}({\mathfrak {a}}))\) with the following tiles:
-
the tile consisting of the portion of \({\text {tile}}({\mathfrak {a}})\) starting at \({\mathfrak {b}}\);
-
(if \({\text {tile}}({\mathfrak {a}})\) is the lowest big tile of T starting in column j) the tile consisting of the portion of \({\text {tile}}({\mathfrak {a}})\) running from \(\mathtt {SE}({\mathfrak {a}})\) to \(\mathtt {SW}({\mathfrak {b}})\);
-
(if \({\text {tile}}({\mathfrak {a}})\) is not the lowest big tile of T starting in column j) the tile obtained by joining together \({\text {tile}}(\mathtt {SW}({\mathfrak {a}}))\), the node \(\mathtt {S}({\mathfrak {a}})\) and the portion of \({\text {tile}}({\mathfrak {a}})\) running from \(\mathtt {SE}({\mathfrak {a}})\) to \(\mathtt {SW}({\mathfrak {b}})\).
-
Again, it is easy to check that the new tiles are all Dyck tiles, and checking that \(\psi _1(T)\) is cover-inclusive is straightforward using Theorem 3.1(4).
So \(\psi _1(T)\) is a cover-inclusive Dyck tiling. It remains to check that \({\scriptstyle \overrightarrow{\displaystyle \psi _1(T)}}\notin X_{\lambda }\). Let t be the highest tile in \(\psi _1(T)\) starting in column \(j+1\); then t starts at \(\mathtt {SE}({\mathfrak {a}})\), where \({\mathfrak {a}}\) is the lowest node in column j which is the start of a big tile in T, and ends at \(\mathtt {SW}({\mathfrak {b}})\), where \({\mathfrak {b}}\) is the first node in \({\text {tile}}({\mathfrak {a}})\) to the right of column j with the same height as \({\mathfrak {a}}\). In T, \(\mathtt {SW}({\mathfrak {b}})\) is attached to \({\mathfrak {b}}\), and so every node above \(\mathtt {SW}({\mathfrak {b}})\) in the same column is attached to its NE neighbour in T. In particular, the highest node in this column has a NE neighbour in \(\lambda \), and so is not removable; so \({\scriptstyle \overrightarrow{\displaystyle \psi _1(T)}}\notin X_{\lambda }\).
So our two maps \(\phi _1,\psi _1\) really do map between the specified sets. It is easy to see from the construction that they are mutual inverses. \(\square \)
Symmetrically, we have the following result.
Proposition 3.5

Our next bijective result is the following.
Proposition 3.6
For each \(x\in X_{\lambda }^+\),
Proof
Fix \(x\in X_{\lambda }^+\). Our aim is to define a bijection
Again we begin with an example to illustrate the bijection. In this example \(x=5\), and the nodes in columns j and \(j+x+1\) are shaded, and the tiles \(\rho \) and t (introduced below) are marked with dots.

Since \(x\in X_{\lambda }^+\), there is a Dyck tile \(\rho \subset \lambda \) consisting of the highest nodes in columns \(j+1,\ldots ,j+x\) of \(\lambda \). Take \(T\in {\mathscr {I}}(\lambda ,\mu ^+)\) with \({\scriptstyle \overrightarrow{\displaystyle T}}=x\), and let t be the highest tile in T starting in column \(j+1\). Then every northward translate of t is an interval in a tile; in particular, \({\text {tile}}(\mathtt {SE}({\mathfrak {l}}))\) contains a translate \(t+(h,h)\) for some \(h\geqslant 0\); since \(\mathtt {SE}({\mathfrak {l}})\) is the highest node in its column, the same is true for every node in \({\text {tile}}(\mathtt {SE}({\mathfrak {l}}))\), so the translate \(t+(h,h)\) coincides with \(\rho \).
Consider the nodes in column j of \(\lambda \backslash \mu ^+\). Arguing as in the proof of Proposition 3.4, every node \({\mathfrak {a}}\) in column j which is higher than t is attached to \(\mathtt {NE}({\mathfrak {a}})\) and \(\mathtt {NW}({\mathfrak {a}})\).
Next we consider nodes in column \(j+x\). The highest node in column \(j+x\) of \(\lambda \backslash \mu ^+\) is the end node of \(\rho \), and so is not attached to its NE neighbour (since this node is not in \(\lambda \)); hence no node in column \(j+x\) is attached to its NE neighbour. So no node in column \(j+x+1\) is attached to its SW neighbour. So from top to bottom, the nodes in column \(j+x+1\) higher than \({\text {en}}(t)\) comprise:
-
(possibly) some nodes attached to their NW neighbours;
-
(possibly) some nodes attached to neither their NW nor SW neighbours.
Now we can construct \(\phi _2(T)\) by doing the following, for each pair \(({\mathfrak {a}},{\mathfrak {d}})\) of nodes with \({\mathfrak {a}}\) in column j, \({\mathfrak {d}}\) in column \(j+x+1\) and \({\text {ht}}({\mathfrak {a}})={\text {ht}}({\mathfrak {d}})>{\text {ht}}(t)\).
-
If \({\mathfrak {d}}\) is attached to \(\mathtt {NW}({\mathfrak {d}})\), then \({\mathfrak {a}}\) and \({\mathfrak {d}}\) lie in the same tile in T; change this tile by moving the portion lying in columns \(j+1\) to \(j+x\) south one step.
-
If \({\mathfrak {d}}\) is not attached to \(\mathtt {NW}({\mathfrak {d}})\), then \({\text {en}}({\text {tile}}({\mathfrak {a}}))=\mathtt {NW}({\mathfrak {d}})\) and hence \(\mathtt {NW}({\mathfrak {a}})\) has depth 0. Replace \({\text {tile}}({\mathfrak {a}})\) and \({\text {tile}}({\mathfrak {d}})\) with the following two tiles:
-
the portion of \({\text {tile}}({\mathfrak {a}})\) ending at \(\mathtt {NW}({\mathfrak {a}})\);
-
the tile obtained by joining the portion of \({\text {tile}}(\mathtt {SE}({\mathfrak {a}}))\) between columns \(j+1\) and \(j+x\) to \({\mathfrak {a}}\) and \({\text {tile}}({\mathfrak {d}})\).
-
Finally remove t. It is easy to see that the new tiles are Dyck tiles, and the cover-inclusive property follows very easily from the cover-inclusive property for T.
Now we construct the inverse map
Suppose T is a cover-inclusive Dyck tiling of \(\lambda ^{[x]}\backslash \mu ^+\). No node in column \(j-1\) or column j of \(\lambda ^{[x]}\) can be attached to its NE neighbour (since the NE neighbours of the highest nodes in these columns are not nodes of \(\lambda ^{[x]}\)). Hence from top to bottom the nodes in column j comprise:
-
(possibly) some nodes attached to their NW and SE neighbours;
-
(possibly) some nodes attached only to their SE neighbours;
-
(possibly) some singleton nodes.
Note that if \({\mathfrak {a}}\) is a node in column j which is not attached to \(\mathtt {NW}({\mathfrak {a}})\), then \(\mathtt {NW}({\mathfrak {a}})\) is the end node of its tile; in particular, \({\text {tile}}({\mathfrak {a}})\) has a NW neighbour.
Claim
Suppose \(r\geqslant 1\), and the node \({\mathfrak {a}}:={\mathfrak {l}}-(r,r)\) is attached to \(\mathtt {SE}({\mathfrak {a}})\). Then \({\text {tile}}({\mathfrak {a}})\) reaches column \(j+x+1\) and includes all the nodes in \(\rho -(r,r)\).
Proof
We proceed by induction on r. First suppose \(r=1\). Since \(x\in X_{\lambda }\), every node in columns \(j+1,\ldots ,j+x\) of \(\lambda \) has height less than \({\text {ht}}({\mathfrak {l}})\). Hence, every node in columns \(j+1,\ldots ,j+x\) of \(\lambda ^{[x]}\) has height less than \({\text {ht}}({\mathfrak {l}})-2={\text {ht}}({\mathfrak {a}})\); since \({\text {tile}}({\mathfrak {a}})\) is a Dyck tile, it must reach \({\text {ht}}({\mathfrak {a}})\) at some point to the right of \(\mathtt {SE}({\mathfrak {a}})\), and so must reach column \(x+j+1\). Furthermore, \({\mathfrak {a}}\) is the highest node in its column, so every node in \({\text {tile}}({\mathfrak {a}})\) is the highest in its column, and in particular the portion of \({\text {tile}}({\mathfrak {a}})\) between columns \(j+1\) and \(j+x\) must consist of the highest nodes in these columns, i.e. the nodes in \(\rho -(1,1)\).
Now suppose \(r>1\). By induction \({\text {tile}}({\mathfrak {a}})\) cannot include any of the nodes in \(\rho -(v,v)\) for any \(v<r\); all the remaining nodes in columns \(j+1,\ldots ,j+r\) have height less than \({\text {ht}}({\mathfrak {a}})\), and so (since \({\text {tile}}({\mathfrak {a}})\) must reach \({\text {ht}}({\mathfrak {a}})\) at some point to the right of \(\mathtt {SE}({\mathfrak {a}})\)) \({\text {tile}}({\mathfrak {a}})\) must reach column \(j+x+1\). The translate \({\text {tile}}({\mathfrak {a}})+(1,1)\) is contained in \({\text {tile}}(\mathtt {N}({\mathfrak {a}}))\), and by induction this includes the nodes in \(\rho -(r-1,r-1)\); so \({\text {tile}}({\mathfrak {a}})\) includes the nodes in \(\rho -(r,r)\).
Now we consider the nodes in column \(j+x+1\). If \({\mathfrak {d}}\) is a node in column \(j+x+1\), then by similar arguments to those used above, \({\mathfrak {d}}\) cannot be attached to \(\mathtt {NW}({\mathfrak {d}})\), and if \({\mathfrak {d}}\) is attached to \(\mathtt {SW}({\mathfrak {d}})\), then \({\text {tile}}({\mathfrak {d}})\) includes a node in column j and also includes all the nodes in \(\rho -(r,r)\), where \(r=\frac{1}{2}({\text {ht}}({\mathfrak {l}})-{\text {ht}}({\mathfrak {d}}))\).
So we find that if \({\mathfrak {a}}\) and \({\mathfrak {d}}\) are nodes in columns j and \(j+x+1\), respectively, with the same height, then \({\mathfrak {a}}\) is attached to \(\mathtt {SE}({\mathfrak {a}})\) if and only if \({\mathfrak {d}}\) is attached to \(\mathtt {SW}({\mathfrak {d}})\), and that in this case \({\text {tile}}({\mathfrak {a}})={\text {tile}}({\mathfrak {d}})\). Say that such a pair \(({\mathfrak {a}},{\mathfrak {d}})\) is a connected pair. Now we can construct \(\psi _2(T)\) as follows: for each connected pair \(({\mathfrak {a}},{\mathfrak {d}})\), write \({\mathfrak {a}}={\mathfrak {l}}-(r,r)\) and then:
-
if \({\mathfrak {a}}\) is attached to \(\mathtt {NW}({\mathfrak {a}})\), change \({\text {tile}}({\mathfrak {a}})\) by replacing the portion \(\rho -(r,r)\) with \(\rho -(r-1,r-1)\);
-
if \({\mathfrak {a}}\) is not attached to \(\mathtt {NW}({\mathfrak {a}})\), replace \({\text {tile}}(\mathtt {NW}({\mathfrak {a}}))\) and \({\text {tile}}({\mathfrak {a}})\) with the following two tiles:
-
the tile comprising \({\mathfrak {a}}\), \({\text {tile}}(\mathtt {NW}({\mathfrak {a}}))\) and \(\rho -(r-1,r-1)\);
-
the portion of \({\text {tile}}({\mathfrak {a}})\) starting at \({\mathfrak {d}}\).
-
Finally, add the tile \(\rho -(r,r)\), where r is the number of connected pairs.
Once more, we see that the new tiles are all Dyck tiles, and the cover-inclusive property is easy to check from the construction. Furthermore, the last tile mentioned above is the highest tile starting in column \(j+1\), and has size x.
So \(\psi _2\) really does map \({\mathscr {I}}(\lambda ^{[x]},\mu ^+)\) to \(\left\{ \left. T\in {\mathscr {I}}(\lambda ,\mu ^+)\ \right| \ \smash {{\scriptstyle \overrightarrow{\displaystyle T}}=x}\right\} \). And it is easy to see that \(\phi _2\) and \(\psi _2\) are mutual inverses. \(\square \)
Symmetrically, we have the following.
Proposition 3.7
For each \(x\in X_{\lambda }^-\),
Our third bijection involves the partition \({\lambda ^+}\).
Proposition 3.8

Proof
First observe that \(\lambda \supseteq \mu \) if and only if \(\lambda ^+\supseteq \mu ^+\), so we may as well assume that both these conditions hold. Next note that if \({\mathfrak {l}}={\mathfrak {m}}\), then \(\lambda \backslash \mu =\lambda ^+\backslash \mu ^+\), and this skew Young diagram contains no nodes in column j; in particular, it does not include \({\mathfrak {m}}\). So in this case, Proposition 3.8 amounts to the trivial statement \({\text {i}}_{\lambda \mu }={\text {i}}_{\lambda ^+\mu ^+}\).
So we assume that \(\lambda \supset \mu \) and \({\mathfrak {l}}\ne {\mathfrak {m}}\); so \({\mathfrak {m}}\) is a node of \(\lambda \backslash \mu \). Now we want to construct a bijection

The following diagrams gives an illustrative example of how our bijection works; the nodes in the same column as \({\mathfrak {l}}\) and \({\mathfrak {m}}\) are shaded to make it easier to see the effect on these nodes.

Suppose we have \(T\in {\mathscr {I}}(\lambda ,\mu )\) with \({\mathfrak {m}}\) lying in a big tile. Then \({\mathfrak {m}}\) is attached to both \(\mathtt {NE}({\mathfrak {m}})\) and \(\mathtt {NW}({\mathfrak {m}})\), and hence every node \({\mathfrak {a}}\) in column j is attached to both \(\mathtt {NE}({\mathfrak {a}})\) and \(\mathtt {NW}({\mathfrak {a}})\). In particular, every node in column j has depth at least 1. Now we construct \(\phi _3(T)\) from T as follows. For each node \({\mathfrak {a}}\) in column j:
-
if \({\mathfrak {a}}\) has depth greater than 1, then change \({\text {tile}}({\mathfrak {a}})\) by replacing \({\mathfrak {a}}\) with \(\mathtt {N}({\mathfrak {a}})\);
-
if \({\mathfrak {a}}\) has depth 1, then replace \({\text {tile}}({\mathfrak {a}})\) with the following three tiles:
-
the portion of \({\text {tile}}({\mathfrak {a}})\) ending in column \(j-1\);
-
the portion of \({\text {tile}}({\mathfrak {a}})\) starting in column \(j+1\);
-
the singleton tile \(\{\mathtt {N}({\mathfrak {a}})\}\).
-
Clearly all these new tiles are Dyck tiles. The cover-inclusive property follows easily from the corresponding property of T, and in particular the fact [Theorem 3.1(2)] that depth weakly decreases down columns in a cover-inclusive tiling. Moreover, \(\phi _3(T)\) has no big tile starting or ending in column j, so lies in the codomain.
To show that \(\phi _3\) is a bijection, we construct its inverse

Suppose \(T\in {\mathscr {I}}(\lambda ^+,\mu ^+)\), and that there is no big tile in T starting or ending in column j. The highest node in column j of \(\lambda ^+\backslash \mu ^+\), namely \({\mathfrak {l}}\), is not attached to \(\mathtt {NE}({\mathfrak {l}})\) or \(\mathtt {NW}({\mathfrak {l}})\) (since these are not nodes of \({\lambda ^+}\)) and so no node in column j is attached to its NE or NW neighbour. So every node in column j is either a singleton or attached to both its SE and SW neighbours. Now we can construct \(\psi _3(T)\) from T as follows: for each node \({\mathfrak {a}}\) in column j, replace the tiles \({\text {tile}}({\mathfrak {a}})\), \({\text {tile}}(\mathtt {SW}({\mathfrak {a}}))\), \({\text {tile}}(\mathtt {SE}({\mathfrak {a}}))\) (which might or might not coincide) with the tile obtained by taking the union of these three tiles and replacing \({\mathfrak {a}}\) with \(\mathtt {S}({\mathfrak {a}})\).
Again, it is easy to check that \(\psi _3(T)\) is a cover-inclusive Dyck tiling, and clearly \({\mathfrak {m}}\) lies in a big tile in \(\psi _3(T)\). Furthermore, it is easy to see that \(\phi _3\) and \(\psi _3\) are mutually inverse. \(\square \)
Now we combine Propositions 3.4–3.8 to prove our main recurrence. We retain the assumptions and notation from above.
Our main result is as follows. Recall that \({\text {i}}_{\lambda \mu }\) denotes the total number of cover-inclusive Dyck tilings of \(\lambda \backslash \mu \).
Proposition 3.9
With notation as above,
Proof
By Proposition 3.6, we have
So

by Proposition 3.4.
Symmetrically, we have

Now consider \({\text {i}}_{\lambda \mu }\). Obviously we have
and by Proposition 3.8

Hence

Since a cover-inclusive Dyck tiling cannot contain big tiles starting and ending in the same column, the sum of the last three terms is \({\text {i}}_{\lambda ^+\mu ^+}\), and we are done. \(\square \)
4 Cover-expansive Dyck tilings
In this section we consider cover-expansive Dyck tilings, proving similar (though considerably simpler) recurrences to those in Sect. 3.
4.1 Basic properties
We begin by studying left- and right-cover-expansive Dyck tilings. In contrast to cover-inclusive Dyck tilings, it is not the case that the left-cover-expansive and right-cover-expansive conditions are equivalent. For example, the unique Dyck tiling of \((2)\backslash \varnothing \) is left- but not right-cover-expansive.
We begin with equivalent conditions to the left- and right-cover-expansive conditions.
Proposition 4.1
Suppose \(\lambda \) and \(\mu \) are partitions with \(\lambda \supseteq \mu \), and T is a Dyck tiling of \(\lambda \backslash \mu \).
-
1.
T is left-cover-expansive if and only if for every tile t in T, we have \(\mathtt {NW}({\text {st}}(t))\notin \lambda \backslash \mu \).
-
2.
T is right-cover-expansive if and only if for every tile t in T, we have \(\mathtt {NE}({\text {en}}(t))\notin \lambda \backslash \mu \).
Proof
We prove (1); the proof of (2) is similar.
Suppose T is left-cover-expansive. Given a tile t, let \({\mathfrak {a}}=\mathtt {NW}({\text {st}}(t))\). If \({\mathfrak {a}}\in \lambda \backslash \mu \), then by the left-cover-expansive property \({\text {st}}({\text {tile}}({\mathfrak {a}}))\) lies weakly to the right of \({\text {st}}(t)\); but \({\mathfrak {a}}\) lies strictly to the left of \({\text {st}}(t)\), a contradiction.
Conversely, suppose the given property holds, and \({\mathfrak {a}},\mathtt {SE}({\mathfrak {a}})\) are nodes of \(\lambda \backslash \mu \). Let \({\mathfrak {b}}={\text {st}}({\text {tile}}(\mathtt {SE}({\mathfrak {a}})))\), and suppose \({\mathfrak {b}}\) lies in column i. Then \(\mathtt {NW}({\mathfrak {b}})\notin \lambda \backslash \mu \), and hence there are no nodes in column \(i-1\) of \(\lambda \backslash \mu \) higher than \({\mathfrak {b}}\) (otherwise \(\lambda \backslash \mu \) would not be a skew Young diagram). In particular, there are no nodes of \({\text {tile}}({\mathfrak {a}})\) in column \(i-1\), and hence \({\text {st}}({\text {tile}}({\mathfrak {a}}))\) lies weakly to the right of \({\mathfrak {b}}\). \(\square \)
Lemma 4.2
Suppose \(\lambda ,\mu \) are partitions with \(\lambda \supseteq \mu \), and T is a left-cover-expansive Dyck tiling of \(\lambda \backslash \mu \). If \({\mathfrak {a}}\in \lambda \backslash \mu \) is the lowest node in its column, then every node in \({\text {tile}}({\mathfrak {a}})\) to the right of \({\mathfrak {a}}\) is the lowest node in its column.
Proof
Suppose \({\mathfrak {a}}\) lies in column i, and proceed by induction on the number of nodes to the right of \({\mathfrak {a}}\) in \({\text {tile}}({\mathfrak {a}})\). Assuming \({\mathfrak {a}}\) is not the end node of its tile, there is a node \({\mathfrak {b}}\) in \({\text {tile}}({\mathfrak {a}})\) in column \(i+1\), which must be either \(\mathtt {NE}({\mathfrak {a}})\) or \(\mathtt {SE}({\mathfrak {a}})\). The only way \({\mathfrak {b}}\) can fail to be the lowest node in column \(i+1\) is if \({\mathfrak {b}}=\mathtt {NE}({\mathfrak {a}})\) and \(\mathtt {SE}({\mathfrak {a}})\in \lambda \backslash \mu \). But in this case, \(\mathtt {SE}({\mathfrak {a}})\) is not attached to \({\mathfrak {a}}\) or to \(\mathtt {S}({\mathfrak {a}})\) (which is not a node of \(\lambda \backslash \mu \)), and so \(\mathtt {SE}({\mathfrak {a}})\) is the start of its tile; but this contradicts Proposition 4.1.
So \({\mathfrak {b}}\) is the lowest node in its column. By induction every node to the right of \({\mathfrak {b}}\) in the same tile is the lowest node in its column, and we are done. \(\square \)
Proposition 4.3
Suppose \(\lambda ,\mu \) are partitions with \(\lambda \supseteq \mu \). Then \(\lambda \backslash \mu \) admits at most one left-cover-expansive Dyck tiling, and at most one right-cover-expansive Dyck tiling. If \(\lambda \backslash \mu \) admits both a left- and a right-cover-expansive Dyck tiling, then these tilings coincide.
Proof
We use induction on \(|\lambda \backslash \mu |\). If \(\lambda =\mu \) then the result is trivial, so assume \(\lambda \supset \mu \). Let \({\mathfrak {a}}\) be the unique leftmost node of \(\lambda \backslash \mu \), and suppose \({\mathfrak {a}}\) lies in column i. Let \(m\geqslant 0\) be maximal such that columns \(i,\ldots ,i+m\) each contain a node of height at most \({\text {ht}}({\mathfrak {a}})\). Suppose T is a left-cover-expansive Dyck tiling of \(\lambda \backslash \mu \).
Claim 1
\({\text {tile}}({\mathfrak {a}})\) consists of the lowest nodes in columns \(i,\ldots ,i+m\).
Proof
Since \({\mathfrak {a}}\) is the start node of its tile, every node in \({\text {tile}}({\mathfrak {a}})\) has height at most \({\text {ht}}({\mathfrak {a}})\), and in particular \({\text {tile}}({\mathfrak {a}})\) cannot contain a node in column \(i+m+1\) or further to the right.
Now we prove by induction on l that \({\text {tile}}({\mathfrak {a}})\) contains the lowest node in column l, for \(i\leqslant l\leqslant i+m\). Let \({\mathfrak {b}}\) be the lowest node in column l; then (assuming \(l>i\)) the lowest node in column \(l-1\) is either \(\mathtt {NW}({\mathfrak {b}})\) or \(\mathtt {SW}({\mathfrak {b}})\). In the first case, \({\mathfrak {b}}\) cannot be the start of its tile, by Proposition 4.1; \({\mathfrak {b}}\) cannot be attached to \(\mathtt {SW}({\mathfrak {b}})\), since this is not a node of \(\lambda \backslash \mu \), and so \({\mathfrak {b}}\) is attached to \(\mathtt {NW}({\mathfrak {b}})\), and hence lies in \({\text {tile}}({\mathfrak {a}})\). In the second case, the fact that \({\text {ht}}(\mathtt {SW}({\mathfrak {b}}))<{\text {ht}}({\mathfrak {b}})\leqslant {\text {ht}}({\mathfrak {a}})\) means that \(\mathtt {SW}({\mathfrak {b}})\) cannot be the end node of \({\text {tile}}({\mathfrak {a}})\), so is attached to either \({\mathfrak {b}}\) or \(\mathtt {S}({\mathfrak {b}})\); but \(\mathtt {S}({\mathfrak {b}})\) is not a node of \(\lambda \backslash \mu \), and hence \(\mathtt {SW}({\mathfrak {b}})\) is attached to \({\mathfrak {b}}\), i.e. \({\mathfrak {b}}\in {\text {tile}}({\mathfrak {a}})\).
The definition of m means that the nodes in \({\text {tile}}({\mathfrak {a}})\) can be removed to leave a smaller skew Young diagram \(\lambda \backslash \nu \), and the fact that T is left-cover-expansive means that \(T\setminus \{{\text {tile}}({\mathfrak {a}})\}\) is a left-cover-expansive Dyck tiling of \(\lambda \backslash \nu \). By induction on \(|\lambda \backslash \mu |\) there is at most one such tiling, and so T is uniquely determined.
So there is at most one left-cover-expansive Dyck tiling of \(\lambda \backslash \mu \), and similarly at most one right-cover-expansive Dyck tiling. To prove the final statement, we continue to assume that \(\lambda \backslash \mu \) is non-empty; we choose a connected component \({\mathcal {C}}\) of \(\lambda \backslash \mu \), and let \({\mathfrak {a}}\) denote the unique leftmost node of \({\mathcal {C}}\), and \({\mathfrak {c}}\) the unique rightmost node of \({\mathcal {C}}\). (So there is no node in the column to the left of the column containing \({\mathfrak {a}}\) or in the column to the right of the column containing \({\mathfrak {c}}\), but there are nodes in all columns in between.)
Claim 2
Suppose there exists a left-cover-expansive Dyck tiling T of \(\lambda \backslash \mu \). Then \({\text {ht}}({\mathfrak {a}})\leqslant {\text {ht}}({\mathfrak {c}})\), and if equality occurs then \({\mathfrak {a}}\) and \({\mathfrak {c}}\) lie in the same tile in T.
Proof
Let \({\mathfrak {b}}_1,\ldots ,{\mathfrak {b}}_r\) be the nodes in \({\mathcal {C}}\) which are both the end nodes of their tiles and the lowest nodes in their columns, numbering them so that they appear in order from left to right. Then \({\mathfrak {b}}_1={\text {en}}({\text {tile}}({\mathfrak {a}}))\) by Claim 1, and \({\mathfrak {b}}_r={\mathfrak {c}}\). We claim that \({\text {ht}}({\mathfrak {b}}_1)<\cdots <{\text {ht}}({\mathfrak {b}}_r)\). Given \(1\leqslant l<r\), let \({\mathfrak {d}}\) be the lowest node in the column to the right of \({\mathfrak {b}}_l\). Then \({\mathfrak {d}}\) is either \(\mathtt {NE}({\mathfrak {b}}_l)\) or \(\mathtt {SE}({\mathfrak {b}}_l)\); but in the latter case, \({\mathfrak {d}}\) must be the start node of its tile, and this contradicts Theorem 3.1. So \({\mathfrak {d}}=\mathtt {NE}({\mathfrak {b}}_l)\), and in particular \({\text {ht}}({\mathfrak {d}})>{\text {ht}}({\mathfrak {b}}_l)\). By Lemma 4.2 \({\text {en}}({\text {tile}}({\mathfrak {d}}))={\mathfrak {b}}_{l+1}\), and hence \({\text {ht}}({\mathfrak {b}}_{l+1})={\text {ht}}({\mathfrak {d}})>{\text {ht}}({\mathfrak {b}}_l)\).
So we have \({\text {ht}}({\mathfrak {a}})={\text {ht}}({\mathfrak {b}}_1)<\cdots <{\text {ht}}({\mathfrak {b}}_r)={\text {ht}}({\mathfrak {c}})\), so \({\text {ht}}({\mathfrak {a}})\leqslant {\text {ht}}({\mathfrak {c}})\), with equality if and only if \(r=1\), in which case \({\mathfrak {c}}={\mathfrak {b}}_1={\text {en}}({\text {tile}}({\mathfrak {a}}))\).
Now we can complete the proof. Assume there is a left-cover-expansive Dyck tiling T of \(\lambda \backslash \mu \) and a right-cover-expansive Dyck tiling U. By Claim 2, we have \({\text {ht}}({\mathfrak {a}})\leqslant {\text {ht}}({\mathfrak {c}})\), and symmetrically (since U exists) we have \({\text {ht}}({\mathfrak {a}})\geqslant {\text {ht}}({\mathfrak {c}})\). Hence \({\text {ht}}({\mathfrak {a}})={\text {ht}}({\mathfrak {c}})\), and so \({\mathfrak {a}},{\mathfrak {c}}\) lie in the same tile \(t\in T\), which consists of the lowest node in every column of \({\mathcal {C}}\). Similarly, t is a tile in U. Removing t from \(\lambda \backslash \mu \) yields a smaller skew Young diagram, and \(T\setminus \{t\}\) is a left-cover-expansive Dyck tiling of this diagram, while \(U\setminus \{t\}\) is a right-cover-expansive Dyck tiling. By induction \(T\setminus \{t\}=U\setminus \{t\}\), and hence \(T=U\). \(\square \)
Now we restrict attention to cover-expansive Dyck tilings. We shall need the following lemma, which examines the effect of the cover-expansive property on depths of nodes.
Lemma 4.4
Suppose \(\lambda \supseteq \mu \), T is a cover-expansive Dyck tiling of \(\lambda \backslash \mu \), and \({\mathfrak {a}},\mathtt {N}({\mathfrak {a}})\in \lambda \backslash \mu \). Then \({\text {dp}}(\mathtt {N}({\mathfrak {a}}))<{\text {dp}}({\mathfrak {a}})\).
Proof
Suppose the lemma is false, and take \({\mathfrak {a}}\in \lambda \backslash \mu \) as far to the left as possible such that \(\mathtt {N}({\mathfrak {a}})\in \lambda \backslash \mu \) and \({\text {dp}}(\mathtt {N}({\mathfrak {a}}))\geqslant {\text {dp}}({\mathfrak {a}})\). We have \(\mathtt {NW}({\mathfrak {a}})\in \lambda \backslash \mu \), and \(\mathtt {NW}({\mathfrak {a}})\) cannot be the end node of its tile by Proposition 4.1, so is attached to either \({\mathfrak {a}}\) or \(\mathtt {N}({\mathfrak {a}})\).
If \(\mathtt {NW}({\mathfrak {a}})\) is attached to \(\mathtt {N}({\mathfrak {a}})\), then \({\mathfrak {a}}\) must be attached to \(\mathtt {SW}({\mathfrak {a}})\) since it cannot be the start node of its tile (again by Proposition 4.1). But now \({\text {dp}}(\mathtt {NW}({\mathfrak {a}}))-{\text {dp}}(\mathtt {SW}({\mathfrak {a}}))=({\text {dp}}(\mathtt {N}({\mathfrak {a}}))+1)-({\text {dp}}({\mathfrak {a}})+1)\geqslant 0\), contradicting the choice of \({\mathfrak {a}}\).
So suppose instead that \(\mathtt {NW}({\mathfrak {a}})\) is attached to \({\mathfrak {a}}\). Then \(\mathtt {N}({\mathfrak {a}})\) cannot be the start node of its tile, since \({\text {dp}}(\mathtt {N}({\mathfrak {a}}))\geqslant {\text {dp}}({\mathfrak {a}})={\text {dp}}(\mathtt {NW}({\mathfrak {a}}))+1>0\). So \(\mathtt {N}({\mathfrak {a}})\) is attached to \(\mathtt {NW}(\mathtt {N}({\mathfrak {a}}))\). But now \({\text {dp}}(\mathtt {NW}(\mathtt {N}({\mathfrak {a}})))-{\text {dp}}(\mathtt {NW}({\mathfrak {a}}))=({\text {dp}}(\mathtt {N}({\mathfrak {a}}))-1)-({\text {dp}}({\mathfrak {a}})-1)\geqslant 0\), and again the choice of \({\mathfrak {a}}\) is contradicted. \(\square \)
We remark that, in contrast to the similar condition in Theorem 3.1(2) for cover-inclusive Dyck tilings, the condition in Lemma 4.4 does not imply the cover-expansive condition. For example, the unique Dyck tiling of \((2)\backslash \varnothing \) satisfies this condition (trivially) but is not right-cover-expansive.
The following lemma will be useful in the next section.
Lemma 4.5
Suppose \(\lambda \supseteq \mu \), and that \(\mu \) has an addable node in column j. If there exists a cover-expansive Dyck tiling of \(\lambda \backslash \mu \), then \(\lambda \) has either an addable or a removable node in column j.
Proof
Suppose not, and let T be the cover-expansive Dyck tiling of \(\lambda \backslash \mu \). There must be at least one node in column j of \(\lambda \backslash \mu \) (otherwise the addable node of \(\mu \) would also be an addable node of \(\lambda \)). Let \({\mathfrak {a}}\) be the highest node in column j, and consider the nodes attached to \({\mathfrak {a}}\) in T.
The lowest node in column j of \(\lambda \backslash \mu \), namely \({\mathfrak {m}}\), is not attached to its SW neighbour (since this is not a node of \(\lambda \backslash \mu \)). Now let \({\mathfrak {b}}\) be the highest node in column j which is not attached to its SW neighbour, and suppose \({\mathfrak {b}}\ne {\mathfrak {a}}\). Then the choice of \({\mathfrak {b}}\) means that \(\mathtt {NW}({\mathfrak {b}})\) is attached to \(\mathtt {N}({\mathfrak {b}})\), so \({\mathfrak {b}}\) is the start node of its tile; but \(\mathtt {NW}({\mathfrak {b}})\in \lambda \backslash \mu \), and this contradicts Proposition 4.1. So \({\mathfrak {b}}={\mathfrak {a}}\).
So \({\mathfrak {a}}\) is not attached to \(\mathtt {SW}({\mathfrak {a}})\), and symmetrically is not attached to \(\mathtt {SE}({\mathfrak {a}})\). If \({\mathfrak {a}}\) is attached to either \(\mathtt {NW}({\mathfrak {a}})\) or \(\mathtt {NE}({\mathfrak {a}})\), then (since T is a Dyck tiling) it is attached to both \(\mathtt {NW}({\mathfrak {a}})\) and \(\mathtt {NE}({\mathfrak {a}})\), and hence both of these nodes belong to \(\lambda \), so \(\lambda \) has an addable node in column j. The remaining possibility is that \({\mathfrak {a}}\) is a singleton tile. But now Proposition 4.1 implies that neither \(\mathtt {NW}({\mathfrak {a}})\) nor \(\mathtt {NE}({\mathfrak {a}})\) is a node of \(\lambda \backslash \mu \), so \(\lambda \) has a removable node in column j. \(\square \)
4.2 Recurrences
We now reassume the notation in Sect. 3: \(\lambda ,\mu \) are partitions with addable nodes \({\mathfrak {l}},{\mathfrak {m}}\), respectively, in column j, and \({\lambda ^+},\mu ^+\) are the partitions obtained by adding these nodes.
Proposition 4.6
Suppose \(\lambda \supseteq \mu ^+\), and let \({\mathfrak {a}}=\mathtt {S}({\mathfrak {l}})\). Then:
-
1.
there exists a cover-expansive Dyck tiling of \(\lambda \backslash \mu \) in which \({\mathfrak {a}}\) has depth 1 if and only if there exists a cover-expansive Dyck tiling of \(\lambda \backslash \mu ^+\);
-
2.
there exists a cover-expansive Dyck tiling of \(\lambda \backslash \mu \) in which \({\mathfrak {a}}\) has depth greater than 1 if and only if there exists a cover-expansive Dyck tiling of \(\lambda ^+\backslash \mu ^+\).
Proof
Suppose there is a cover-expansive Dyck tiling T of \(\lambda \backslash \mu \). Arguing as in the proof of Lemma 4.5, \({\mathfrak {a}}\) cannot be attached to either \(\mathtt {SE}({\mathfrak {a}})\) or \(\mathtt {SW}({\mathfrak {a}})\) (since \(\mu \) has an addable node in column j), and \(\{{\mathfrak {a}}\}\) cannot be a singleton tile (since \(\lambda \) has an addable node in column j). So \({\mathfrak {a}}\) is attached to both \(\mathtt {NW}({\mathfrak {a}})\) and \(\mathtt {NE}({\mathfrak {a}})\). So by the cover-expansive conditions, every node in column j is attached to its NE and NW neighbours.
-
1.
Suppose \({\mathfrak {a}}\) has depth 1 in T. We construct a cover-expansive Dyck tiling U of \(\lambda \backslash \mu ^+\) from T as illustrated in the following diagram.
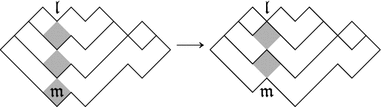
Formally, to construct a cover-expansive Dyck tiling of \(\lambda \backslash \mu ^+\):
-
replace \({\text {tile}}({\mathfrak {a}})\) with the two tiles comprising \({\text {tile}}({\mathfrak {a}})\setminus \{{\mathfrak {a}}\}\);
-
for every node \({\mathfrak {b}}\ne {\mathfrak {a}}\) in column j, change \({\text {tile}}({\mathfrak {b}})\) by replacing \({\mathfrak {b}}\) with \(\mathtt {N}({\mathfrak {b}})\).
It is easy to check that U really does give a cover-expansive Dyck tiling. For the other direction, suppose T is a cover-expansive Dyck tiling of \(\lambda \backslash \mu ^+\). We claim that every node in column j must be attached to its SW and SE neighbours. If there are no nodes in column j (i.e. if \({\mathfrak {m}}=\mathtt {S}({\mathfrak {l}})\)) then this statement is trivial, so suppose otherwise; then \({\mathfrak {a}}\in \lambda \backslash \mu ^+\). \({\mathfrak {a}}\) cannot be attached to \(\mathtt {NW}({\mathfrak {a}})\) in T, since then every node in column \(j-1\) would be attached to its SE neighbour; but the SE neighbour of the bottom node in column \(j-1\) is not a node of \(\lambda \backslash \mu ^+\). Since \({\mathfrak {a}}\) is not attached to \(\mathtt {NW}({\mathfrak {a}})\), it must be attached to \(\mathtt {SW}({\mathfrak {a}})\). Similarly \({\mathfrak {a}}\) is attached to \(\mathtt {SE}({\mathfrak {a}})\), and the cover-expansive property implies that every node in column j is attached to its SE and SW neighbours as claimed. Now we construct a cover-expansive Dyck tiling of \(\lambda \backslash \mu \) as follows:
-
for each node \({\mathfrak {b}}\) in column j, change \({\text {tile}}({\mathfrak {b}})\) by replacing \({\mathfrak {b}}\) with \(\mathtt {S}({\mathfrak {b}})\);
-
replace the tiles \({\text {tile}}(\mathtt {NW}({\mathfrak {a}}))\) and \({\text {tile}}(\mathtt {NE}({\mathfrak {a}}))\) with the tile obtained by joining these two tiles to \({\mathfrak {a}}\).
Again, it is easy to see that we have a cover-expansive Dyck tiling. Moreover, \({\mathfrak {a}}\) has depth 1 in this tiling, since \(\mathtt {NW}({\mathfrak {a}})\) is the end node of its tile in T, and so has depth 0 (in both tilings).
-
-
2.
Suppose \({\mathfrak {a}}\) has depth greater than 1 in T. Construct a cover-expansive Dyck tiling U of \(\lambda ^+\backslash \mu ^+\) from T as follows: for each node \({\mathfrak {b}}\) in column j, change \({\text {tile}}({\mathfrak {b}})\) by replacing \({\mathfrak {b}}\) with \(\mathtt {N}({\mathfrak {b}})\). Again, U is a Dyck tiling, since every node in column j of \(\lambda \backslash \mu \) has depth greater than 1 in T. And the cover-expansive property for U follows from that for T. The other direction is very similar.\(\square \)

Corollary 4.7
\({\text {e}}_{\lambda \mu }={\text {e}}_{\lambda \mu ^+}+{\text {e}}_{\lambda ^+\mu ^+}\).
Proof
First suppose \(\lambda \supseteq \mu ^+\). The first paragraph of the proof of Proposition 4.6 shows that the node \({\mathfrak {a}}=\mathtt {S}({\mathfrak {l}})\) must have positive depth in a cover-expansive Dyck tiling of \(\lambda \backslash \mu \). Hence the result follows from Proposition 4.6.
Alternatively, suppose \(\lambda \nsupseteq \mu ^+\). Then we have \(\lambda \supseteq \mu \) if and only if \(\lambda ^+\supseteq \mu ^+\), and if these conditions hold then \(\lambda \backslash \mu =\lambda ^+\backslash \mu ^+\); so \({\text {e}}_{\lambda \mu }={\text {e}}_{\lambda ^+\mu ^+}\). \(\square \)
Proposition 4.8
\({\text {e}}_{\lambda ^+\mu }={\text {e}}_{\lambda \mu }\).
Proof
Suppose T is a cover-expansive Dyck tiling of \(\lambda ^+\backslash \mu \). Then \({\mathfrak {l}}\) cannot be attached to \(\mathtt {SE}({\mathfrak {l}})\), since then every node in column j would be attached to its SE neighbour; but \(\mathtt {SE}({\mathfrak {m}})\) is not a node of \(\lambda ^+\backslash \mu \). Similarly \({\mathfrak {l}}\) is not attached to \(\mathtt {SW}({\mathfrak {l}})\), so forms a singleton tile in T. Removing this tile yields a cover-expansive Dyck tiling of \(\lambda \backslash \mu \).
In the other direction, suppose T is a cover-expansive Dyck tiling of \(\lambda \backslash \mu \). From the proof of Proposition 4.6, \(\mathtt {S}({\mathfrak {l}})\) is attached to both \(\mathtt {SE}({\mathfrak {l}})\) and \(\mathtt {SW}({\mathfrak {l}})\). Hence if we add \({\mathfrak {l}}\) as a singleton tile, the resulting tiling is a cover-expansive Dyck tiling of \(\lambda ^+\backslash \mu \). \(\square \)
5 Young permutation modules for two-part compositions
In this section we apply our results on Dyck tilings to compute transition coefficients for two bases for a certain module for the symmetric group.
5.1 The Young permutation module \(\mathscr {M}^{(f,g)}\)
Suppose \(k\geqslant 0\), and let \({\mathfrak {S}}_k\) denote the symmetric group of degree k, with \(\{t_1,\ldots ,t_{k-1}\}\) the set of Coxeter generators (so \(t_i\) is the transposition  ). Let \({\mathbb {F}}\) be any field, and consider the group algebra \({\mathbb {F}}{\mathfrak {S}}_k\). Define \(s_i=t_i-1\in {\mathbb {F}}{\mathfrak {S}}_k\) for \(i=1,\ldots ,n-1\).
). Let \({\mathbb {F}}\) be any field, and consider the group algebra \({\mathbb {F}}{\mathfrak {S}}_k\). Define \(s_i=t_i-1\in {\mathbb {F}}{\mathfrak {S}}_k\) for \(i=1,\ldots ,n-1\).
Now write \(k=f+g\) with f, g non-negative integers. Consider the Young permutation module \(\mathscr {M}^{(f,g)}\) for \({\mathbb {F}}{\mathfrak {S}}_k\) indexed by the composition (f, g). This is just the permutation module on the set of cosets of the maximal Young subgroup \({\mathfrak {S}}_f\times {\mathfrak {S}}_g\), and has the following presentation:
Lemma 5.1
For \(1\leqslant i\leqslant k-2\), the element \(s_is_{i+1}s_i-s_i=t_is_{i+1}s_i-s_{i+1}s_i-s_i\) annihilates \(\mathscr {M}^{(f,g)}\).
Proof
In terms of permutations, the given element is

\(\mathscr {M}^{(f,g)}\) may be viewed as the permutation module on the set of f-subsets of the set \(\{1,\ldots ,k\}\); it is easily seen that the given element kills any such subset. \(\square \)
\(\mathscr {M}^{(f,g)}\) has a basis indexed by the set of minimal left coset representatives of \({\mathfrak {S}}_f\times {\mathfrak {S}}_g\) in \({\mathfrak {S}}_k\); this set is in one-to-one correspondence with the set \({\mathscr {P}}_{f,g}\) of partitions \(\lambda \) for which \(\lambda _1\leqslant f\) and \(\lambda _1'\leqslant g\); given \(\lambda \in {\mathscr {P}}_{f,g}\), we write the corresponding basis element as \(t_\lambda m\), where
Our objective here is to study the elements
for \(\lambda \in {\mathscr {P}}_{f,g}\). It is easy to see that \(\left\{ \smash {s_\lambda m}\ \left| \ \lambda \in {\mathscr {P}}_{f,g}\right. \right\} \) is also a basis for \(\mathscr {M}^{(f,g)}\), since when each \(s_\lambda m\) is expressed as a linear combination of the elements \(t_\mu m\), the matrix of coefficients is unitriangular with respect to a suitable ordering.
We shall use cover-expansive Dyck tilings to describe this transition matrix explicitly, and then describe its inverse using cover-inclusive Dyck tilings. We also give a simple expression for the sum \(\sum _{\lambda \in {\mathscr {P}}_{f,g}}t_\lambda m\) as a linear combination of the elements \(s_\lambda m\), which will be useful in Sect. 6.
5.2 Change of basis
Our first result on transition coefficients is the following.
Theorem 5.2
Suppose f, g are non-negative integers, and \(\mu \in {\mathscr {P}}_{f,g}\). Then

We begin with some simple observations concerning the actions of the generators \(t_1,\ldots ,t_{k-1}\) on the basis elements \(t_\lambda m\). We continue to use the Russian convention for Young diagrams.
Lemma 5.3
Suppose \(\lambda \in {\mathscr {P}}_{f,g}\) and \(1\leqslant i<k\). Then:
-
if \(\lambda \) has an addable node \({\mathfrak {l}}\) in column \(i-g\), then \(t_it_\lambda m=t_{\lambda ^+}m\), where \(\lambda ^+\) is the partition obtained by adding \({\mathfrak {l}}\) to \(\lambda \);
-
if \(\lambda \) has a removable node \({\mathfrak {l}}\) in column \(i-g\), then \(t_it_\lambda m=t_{\lambda ^-}m\), where \(\lambda ^-\) is the partition obtained by removing \({\mathfrak {l}}\) from \(\lambda \);
-
if \(\lambda \) has neither an addable nor a removable node in column \(i-g\), then \(t_it_\lambda m=t_\lambda m\).
Proof
This is an easy consequence of the definitions and the Coxeter relations. \(\square \)
Proof of Theorem 5.2
We proceed by downwards induction on \(|\mu |\). If \(\mu =(f^g)\), then \(s_\mu =t_\mu =1\) and the result follows. Assuming \(\mu \ne (f^g)\), \(\mu \) has an addable node in column j, for some \(-g<j<f\). We let \({\mu ^+}\) denote the partition obtained by adding this addable node; then we have \(s_\mu =s_{j+g}s_{\mu ^+}\), and by induction

Let \({\mathscr {P}}_{f,g}^+\) denote the set of \(\lambda \in {\mathscr {P}}_{f,g}\) having an addable node in column j, and for \(\lambda \in {\mathscr {P}}_{f,g}^+\) let \(\lambda ^+\) denote the partition obtained by adding this addable node; similarly, let \({\mathscr {P}}_{f,g}^-\) denote the set of partitions in \({\mathscr {P}}_{f,g}\) having a removable node in column j, and for each \(\lambda \in {\mathscr {P}}_{f,g}^-\) let \(\lambda ^-\) denote the partition obtained by removing this removable node. Note that the functions \(\lambda \mapsto \lambda ^+\) and \(\lambda \mapsto \lambda ^-\) define mutually inverse bijections between \({\mathscr {P}}_{f,g}^+\) and \({\mathscr {P}}_{f,g}^-\). Now

So Theorem 5.2 follows by induction. \(\square \)
Now we give our second main result on transition coefficients.
Theorem 5.4
Suppose f, g are non-negative integers, and \(\mu \in {\mathscr {P}}_{f,g}\). Then

The proof of this result is rather more difficult. To begin with, we compute the actions of \(s_1,\ldots ,s_{k-1}\) on the basis elements \(s_\lambda m\).
Proposition 5.5
Suppose \(\mu \in {\mathscr {P}}_{f,g}\) and \(1\leqslant i<k\). Then exactly one of the following occurs.
-
1.
\(\mu \) has an addable node in column \(i-g\). In this case \(s_is_\mu m=-2s_\mu m\).
-
2.
\(\mu \) has a removable node in column \(i-g\). In this case \(s_is_\mu m=s_{\mu ^-}m\), where \(\mu ^-\) denotes the partition obtained by removing this node.
-
3.
For some \(0\leqslant a\leqslant g\) we have \(\mu _a>i-g+a>\mu _{a+1}\) (where the left-hand inequality is regarded as automatically true in the case \(a=0\)).
-
(a)
If \(\mu _w<i-g+2a-w\) for all \(a<w\leqslant g\), then \(s_is_\mu m=0\).
-
(b)
Otherwise, let \(w>a\) be minimal such that \(\mu _w=i-g+2a-w\), and set
$$\begin{aligned} \mu ^{a,w}=(\mu _1,\ldots ,\mu _a,i-g+a,\mu _{a+1}+1,\ldots ,\mu _{w-1}+1,\mu _{w+1},\ldots ,\mu _g). \end{aligned}$$Then \(s_is_\mu m=s_{\mu ^{a,w}}m\).
-
(a)
-
4.
For some \(1\leqslant a<g\) we have \(\mu _a=\mu _{a+1}=i-g+a\).
-
(a)
If \(i+2a>k\) and \(\mu _w<i-g+2a-w\) for \(w=1,\ldots ,a-1\), then \(s_is_\mu m=0\).
-
(b)
Otherwise, let \(w<a\) be maximal such that \(\mu _w\geqslant i-g+2a-w\) (taking \(w=0\) if there is no such w), and define
$$\begin{aligned}&\mu ^{w,a}=(\mu _1,\ldots ,\mu _w,i-g+2a-w,\mu _{w+1}\\&\quad +1,\ldots ,\mu _{a-1}+1,\mu _{a+1},\ldots ,\mu _g). \end{aligned}$$Then \(s_is_\mu m=s_{\mu ^{w,a}}m\).
-
(a)
Examples.
-
1.
Suppose \(f=4\), \(g=5\) and \(\mu =(4,2^4)\). Then
$$\begin{aligned} s_\mu =s_6s_7s_5s_6s_4s_5s_3s_4. \end{aligned}$$Taking \(i=3\), we find that \(\mu \) satisfies condition 4(a) of Proposition 5.5, with \(a=4\). And indeed

-
2.
Now suppose \(f=4\), \(g=5\) and \(\mu =(4,2,1^3)\). Then
$$\begin{aligned} s_\mu =s_6s_7s_4s_5s_6s_3s_4s_5s_2s_3s_4. \end{aligned}$$Taking \(i=2\), we find that \(\mu \) satisfies condition 4(b) of Proposition 5.5, with \(a=4\) and \(w=1\), giving \(\mu ^{w,a}=(4^2,3,2,1)\). Now we have
$$\begin{aligned} s_2s_\mu m&=s_2s_6s_7s_4s_5s_6s_3s_4s_5s_2s_3s_4m\\&=s_6s_7s_4s_5s_6(s_2s_3s_2)s_4s_5s_3s_4m\\&=s_6s_7s_4s_5s_6s_2s_4s_5s_3s_4m\\&=s_6s_7(s_4s_5s_4)s_6s_2s_5s_3s_4m\\&=s_6s_7s_4s_6s_2s_5s_3s_4m\\&=(s_6s_7s_6)s_4s_2s_5s_3s_4m\\&=s_6s_4s_2s_5s_3s_4m\\&=s_{(4^2,3,2,1)}m. \end{aligned}$$

Proof of Proposition 5.5
To see that \(\mu \) satisfies exactly one of the four conditions, let \({\mathfrak {l}}\) denote the lowest node in column j which is not a node of \(\mu \), and consider whether \(\mathtt {SE}({\mathfrak {l}})\) and \(\mathtt {SW}({\mathfrak {l}})\) lie in \(\mu \); for the purposes of this argument we regard all nodes of the form (a, 0) or (0, b) as lying in \(\mu \). If both \(\mathtt {SE}({\mathfrak {l}})\) and \(\mathtt {SW}({\mathfrak {l}})\) lie in \(\mu \), then \({\mathfrak {l}}\) is an addable node and we are in case (1). If neither lies in \(\mu \), then \(\mathtt {S}({\mathfrak {l}})\) is a removable node, and we are in case (2). If \(\mathtt {SE}({\mathfrak {l}})\in \mu \ni \!\!\!\!\!\!/\ \,\mathtt {SW}({\mathfrak {l}})\), then we are in case (3), while if \(\mathtt {SE}({\mathfrak {l}})\notin \mu \ni \mathtt {SW}({\mathfrak {l}})\) then we are in case (4).
Now we analyse the four cases in Proposition 5.5.
-
1.
Since \(\mu \) has an addable node in column \(i-g\), \(s_\mu \) can be written in the form \(s_is_{\mu ^+}\). We have \(s_i^2=-2s_i\), and the result follows.
-
2.
By definition (and the fact that \(s_i\) and \(s_j\) commute when \(j\ne i\pm 1\)) \(s_{\mu ^-}=s_is_\mu \).
-
3.
-
(a)
We proceed by induction on i. Consider the case \(a=g\). In this case \(s_\mu \) only involves terms \(s_j\) for \(j\geqslant i+2\), so (since \(s_im=0\)) we get \(s_is_\mu m=0\). Now suppose \(a<g\), and set
$$\begin{aligned} \bar{\mu }=(\mu _1,\ldots ,\mu _a,i-g+a,\mu _{a+2},\ldots ,\mu _g). \end{aligned}$$Then \(\bar{\mu }\) satisfies the inductive hypothesis, with a replaced by \(a+1\) and i replaced by \(i-2\). Furthermore, we can write
$$\begin{aligned} s_\mu =s_{\mu _{a+1}+g-a}\ldots s_{i-1}s_{\bar{\mu }}. \end{aligned}$$\(\bar{\mu }\) has an addable node \((a+1,i-g+a+1)\) in column \(i-g\), so \(s_{\bar{\mu }}m\) can be written in the form \(s_ix\) for some \(x\in \mathscr {M}^{(f,g)}\). So we have

-
(b)
We use induction on \(w-a\). If \(w=a+1\), then we have \(s_\mu =s_{i-1}s_{\mu ^{a,w}}\), and \(\mu ^{a,w}\) has an addable node \((a+1,i-g+a+1)\) in column \(i-g\), so \(s_{\mu ^{a,w}}m\) can be written as \(s_ix\) for some \(x\in \mathscr {M}^{(f,g)}\). So by Lemma 5.1
$$\begin{aligned} s_is_\mu m=s_is_{i+1}s_ix=s_ix=s_{\mu ^{a,w}}m. \end{aligned}$$Now assume that \(w>a+1\), and as above set
$$\begin{aligned} \bar{\mu }=(\mu _1,\ldots ,\mu _a,i-g+a,\mu _{a+2},\ldots ,\mu _g). \end{aligned}$$Then \(\bar{\mu }\) satisfies the inductive hypothesis, with a replaced by \(a+1\) and i replaced by \(i-2\), and with the same value of w, yielding
$$\begin{aligned} \bar{\mu }^{a+1,w}= & {} (\mu _1,\ldots ,\mu _a,i-g+a,i-g+a-1,\mu _{a+2}+1,\ldots ,\mu _{w-1}\\&+1,\mu _{w+1},\ldots ,\mu _g). \end{aligned}$$As above we write \(s_{\bar{\mu }}=s_ix\), and obtain
$$\begin{aligned} \begin{array}{lll} s_is_\mu m&{}=s_{\mu _{a+1}+g-a}\ldots s_{i-2}s_{\bar{\mu }}m&{} \\ &{}=s_{\mu _{a+1}+g-a}\ldots s_{i-3}s_{\bar{\mu }^{a+1,w}}m&{} \hbox {by induction}\\ &{}=s_{\mu ^{a,w}}m.&{} \\ \end{array} \end{aligned}$$
-
(a)
-
4.
This is symmetrical to case (3), replacing partitions with their conjugates and swapping f and g.\(\square \)

We now seek to rephrase Proposition 5.5 so that for a given \(\lambda ,\mu \) we can write down the coefficient of \(s_\lambda m\) in \(s_is_\mu m\). Fix i, and suppose that as in part (3) of Proposition 5.5 we have \(\mu _a>i-g+a>\mu _{a+1}\) for some \(1\leqslant a\leqslant g\). Let \(w>a\) be minimal such that \(\mu _w=i-g+2a-w\), assuming there is such a w, and write \(\mu \mathop {\rightharpoondown }\limits ^{i}\mu ^{a,w}\), where \(\mu ^{a,w}\) is as defined in Proposition 5.5.
Now recall some notation from Sect. 2: if j is fixed and \(\lambda \) is a partition with an addable node \({\mathfrak {l}}\) in column j, then \(X_{\lambda }\) denotes the set of all integers x such that \(\lambda \) has a removable node \({\mathfrak {n}}\) in column \(j+x\), with \({\text {ht}}({\mathfrak {n}})={\text {ht}}({\mathfrak {l}})-1\), and \({\text {ht}}({\mathfrak {p}})<{\mathfrak {l}}\) for all nodes \({\mathfrak {p}}\) in all columns between j and \(j+x\). \(X_{\lambda }^+\) denotes the set of positive elements of \(X_{\lambda }\), and \(X_{\lambda }^-\) the set of negative elements. Given \(x\in X_{\lambda }^+\), \(\lambda ^{[x]}\) is the partition obtained from \(\lambda \) by removing the highest node in each column from \(j+1\) to \(j+x\); \(\lambda ^{[x]}\) is defined similarly for \(x\in X_{\lambda }^-\).
Lemma 5.6
Suppose \(\lambda ,\mu \in {\mathscr {P}}_{f,g}\) and \(1\leqslant i<k\), and set \(j=i-g\). Then \(\mu \mathop {\rightharpoondown }\limits ^{i}\lambda \) if and only if \(\lambda \) has an addable node in column j and \(\mu =\lambda ^{[x]}\) for some \(x\in X_{\lambda }^-\).
Proof
- \((\Rightarrow )\) :
-
If \(\mu \mathop {\rightharpoondown }\limits ^{i}\lambda \) then we have
$$\begin{aligned} \lambda =\mu ^{a,w}=(\mu _1,\ldots ,\mu _a,j+a,\mu _{a+1}+1,\ldots ,\mu _{w-1}+1,\mu _{w+1},\ldots ,\mu _g), \end{aligned}$$where \(\mu _a>j+a>\mu _{a+1}\) and \(w>a\) is minimal such that \(\mu _w\geqslant j+2a-w\). Observe that \(\lambda \) has an addable node \({\mathfrak {l}}=(a+1,j+a+1)\) in column j. The choice of w implies that \(\mu _{w-1}=\mu _w=j+2a-w\), and so \(\lambda \) has a removable node \({\mathfrak {n}}=(w,j+2a-w+1)\) in column \(j+x\), where \(x=2(a-w)+1\). Furthermore, \({\text {ht}}({\mathfrak {n}})=j+2a={\text {ht}}({\mathfrak {l}})-1\), and we claim that all the nodes in columns \(j+x+1,\ldots ,j-1\) of \(\lambda \) have height at most \(j+2a\): if this condition fails, then it must fail for a node of the form \((x,\lambda _x)\) with \(a+2\leqslant x\leqslant w-1\), but for x in this range we have \({\text {ht}}((x,\lambda _x))=x+\lambda _x=x+\mu _{x-1}+1\leqslant x+j+2a-x\). So \(x\in X_{\lambda }^-\).
To construct \(\mu \) from \(\lambda \) we remove the nodes
$$\begin{aligned}&(w,\mu _w+1),(w,\mu _w+2),\ldots ,(w,\mu _{w-1}+1),\\&(w-1,\mu _{w-1}+1),(w-1,\mu _{w-1}+2),\ldots ,(w-1,\mu _{w-2}+1),\\&\ldots \\&(a+2,\mu _{a+2}+1),(a+2,\mu _{a+2}+2),\ldots ,(a+2,\mu _{a+1}+1),\\&(a+1,\mu _{a+1}+1),(a+1,\mu _{a+1}+2),\ldots ,(a+1,j+a), \end{aligned}$$which lie in columns \(j+x,\ldots ,j-1\), respectively. So \(\mu =\lambda ^{[x]}\).
- \((\Leftarrow )\) :
-
Suppose \(\lambda \) has an addable node in column j. Writing this node as \((a+1,\lambda _{a+1}+1)\), we have \(a=0\) or \(\lambda _a>\lambda _{a+1}\), and \(\lambda _{a+1}-a=j\). Now suppose \(x\in X_{\lambda }^-\). Then \(\lambda \) has a removable node \({\mathfrak {n}}=(w,\lambda _w)\) in column \(j+x\), and \(w>a\) since \(x<0\). Then \(\lambda _w>\lambda _{w+1}\) and \(\lambda _w-w=j+x\), and (since \({\text {ht}}({\mathfrak {n}})={\text {ht}}({\mathfrak {l}})-1\)) \(w+\lambda _w=a+1+\lambda _{a+1}\). The fact that \({\text {ht}}({\mathfrak {p}})<{\text {ht}}({\mathfrak {l}})\) for all nodes \({\mathfrak {p}}\) in columns \(j+x+1,\ldots ,j-1\) implies in particular that \({\text {ht}}((x,\lambda _x))<{\text {ht}}({\mathfrak {l}})\) for \(a+2\leqslant x\leqslant w-1\), i.e. \(x+\lambda _x\leqslant a+1+\lambda _{a+1}\). Constructing \(\lambda ^{[x]}\) involves removing the nodes
$$\begin{aligned} (w,\lambda _w),{}&(w-1,\lambda _w),(w-1,\lambda _w+1),\ldots ,(w-1,\lambda _{w-1}),\\&(w-2,\lambda _{w-1}),(w-2,\lambda _{w-1}+1),\ldots ,(w-2,\lambda _{w-2}),\\&\ldots \\&(a+1,\lambda _{a+2}),(a+1,\lambda _{a+2}+1),\ldots ,(a+1,\lambda _{a+1}), \end{aligned}$$so
$$\begin{aligned} \lambda ^{[x]}=(\lambda _1,\ldots ,\lambda _a,\lambda _{a+2}-1,\ldots ,\lambda _w-1,\lambda _w-1,\lambda _{w+1},\ldots ,\lambda _g). \end{aligned}$$Setting \(\mu =\lambda ^{[x]}\), the (in)equalities observed above for \(\lambda \) give \(\mu _a>j+a>\mu _{a+1}\), \(\mu _x<j+2a-x\) for \(a<x<w\) and \(\mu _w=j+2a-w\). Furthermore, \(\lambda \) equals the partition \(\mu ^{a,w}\), so \(\mu \mathop {\rightharpoondown }\limits ^{i}\lambda \).\(\square \)
We now note a counterpart to this for part (4) of Proposition 5.5, which follows by conjugating partitions. Suppose that \(\mu \in {\mathscr {P}}_{f,g}\) satisfies the conditions of (4), and that \(\mu ^{w,a}\) is defined, and write \(\mu \mathop {\rightharpoonup }\limits ^{i}\mu ^{w,a}\).
Lemma 5.7
Suppose \(\lambda ,\mu \in {\mathscr {P}}_{f,g}\) and \(1\leqslant i<k\), and set \(j=i-g\). Then \(\mu \mathop {\rightharpoonup }\limits ^{i}\lambda \) if and only if \(\lambda \) has a removable node in column j and \(\mu =\lambda ^{[x]}\) for some \(x\in X_{\lambda }^+\).
The following result is now immediate from Proposition 5.5 and Lemmas 5.6 and 5.7.
Corollary 5.8
Suppose \(\mu \in {\mathscr {P}}_{f,g}\), and write \(s_is_\mu m\) as a linear combination  . Then \(a_\lambda \) equals:
. Then \(a_\lambda \) equals:
-
\(-2\), if \(\lambda \) has an addable node in column \(i-g\) and \(\mu =\lambda \);
-
1, if \(\lambda \) has an addable node in column \(i-g\), and
-
\(\mu \) is the partition obtained by adding this node, or
-
\(\mu =\lambda ^{[x]}\) for some \(x\in X_{\lambda }\);
-
-
0, otherwise.
Proof of Theorem 5.4
As with Theorem 5.2, we proceed by downwards induction on \(|\mu |\). If \(\mu =(f^g)\), then \(s_\mu =t_\mu \) and the result follows, since clearly \({\text {i}}_{\lambda \lambda }=1\).
Assuming \(\mu \ne (f^g)\), \(\mu \) has an addable node in column j for some \(-g<j<f\). We let \(\mu ^+\) denote the partition obtained by adding this addable node. Then \(t_\mu =t_{j+g}t_{\mu ^+}\), and by induction

As before, we write \({\mathscr {P}}_{f,g}^+\) for the set of \(\lambda \in {\mathscr {P}}_{f,g}\) having an addable node in column j, and for \(\lambda \in {\mathscr {P}}_{f,g}^+\) we let \(\lambda ^+\) denote the partition obtained by adding this addable node. We have

Theorem 5.4 follows by induction. \(\square \)
5.3 The sum of the elements \(t_\mu m\)
It will be critical in the next section to be able to express  in terms of the basis elements \(s_\lambda m\). To enable us to do this, we define an integer-valued function \(F\) on partitions.
in terms of the basis elements \(s_\lambda m\). To enable us to do this, we define an integer-valued function \(F\) on partitions.
If \(\lambda \) is a partition, we let \(\partial ^{a}\lambda \) denote the partition obtained by removing the first a parts of \(\lambda \), i.e. the partition \((\lambda _{a+1},\lambda _{a+2},\ldots )\), and let \(\partial _{b}\lambda \) denote the partition obtained by reducing all the parts by b (and deleting all negative parts), i.e. the partition \((\max \{\lambda _1-b,0\},\max \{\lambda _2-b,0\},\ldots )\). We write \(\partial ^{a}_{b}\lambda =\partial ^{a}\partial _{b}\lambda \).
Now we can define \(F\) recursively. Set \(F(\varnothing )=1\). Given a partition \(\lambda \ne \varnothing \), take a node (a, b) of \(\lambda \) for which \(a+b\) is maximal (call this a highest node of \(\lambda \)) and define
Now set
Lemma 5.9
\(F(\lambda )\) is well-defined, i.e. does not depend on the choice of (a, b).
Proof
Suppose (a, b) and \((\hat{a},\hat{b})\) are both highest nodes of \(\lambda \); in particular, \(a+b=\hat{a}+\hat{b}\). Assume without loss that \(a<\hat{a}\). Let \(\sigma =\partial ^{a}\lambda \) and \(\tau =\partial _{b}\lambda \) as above, and define \(\hat{\sigma },\hat{\tau }\) correspondingly. By induction \(F(\sigma ),F(\tau ),F(\hat{\sigma }),F(\hat{\tau })\) are well-defined, and we must show that
Now \((\hat{a}-a,\hat{b})\) is a highest node of \(\sigma \), so we have
where \(\xi =\partial ^{a}_{\hat{b}}\lambda \). Also, \((a,b-\hat{b})\) is a highest node of \(\hat{\tau }\), so that
So (since \(a+b=\hat{a}+\hat{b}\)) we obtain
Dividing both sides by \(F(\xi )\hat{a}!b!\) (which is obviously positive) and multiplying by \((a+b)!(\hat{a}-a)!=(\hat{a}+\hat{b})!(\hat{b}-b)!\) gives the result. \(\square \)
Remark
In the notation of the above lemma, we have
where we use \((x,y,z)!\) to denote the trinomial coefficient \(\frac{(x+y+z)!}{x!y!z!}\). We will refer to this as ‘factorising using the nodes (a, b) and \((\hat{a},\hat{b})\)’. This readily generalises to factorising using any number of highest nodes, with a corresponding multinomial coefficient.
Our main objective is to prove the following statement.
Theorem 5.10
Suppose f, g are non-negative integers. Then

We prove this using the following recurrence, in which we again use the notation \(X_{\lambda }\) and \(\lambda ^{[x]}\) from Sect. 2.
Proposition 5.11
Assume that \(\lambda \) is a partition with an addable node \({\mathfrak {l}}\) in column j, and let \(\lambda ^+\) denote the partition obtained by adding this node. Then
Proof
Write \({\mathfrak {l}}\) as (a, b). Suppose first of all that \({\mathfrak {l}}\) is not the unique highest node of \(\lambda ^+\). Take a highest node \({\mathfrak {m}}=(\hat{a},\hat{b})\ne {\mathfrak {l}}\), and suppose without loss that \(\hat{a}<a\). Since the height of \({\mathfrak {m}}\) is at least the height of \({\mathfrak {l}}\), \(\hat{b}-\hat{a}-j\) is strictly larger than any element of \(X_{\lambda }\). So \({\mathfrak {m}}\) is a highest node of \(\lambda ^{[x]}\) for every \(x\in X_{\lambda }\), as well as of \(\lambda \) and \(\lambda ^+\). By induction the result holds for the partition \((\lambda _{\hat{a}+1},\lambda _{\hat{a}+2},\ldots )\), and so it holds for \(\lambda \), factorising \(F(\lambda )\) (and also \(F(\lambda ^+)\) and \(F(\lambda ^{[x]})\) for each x) using the node \((\hat{a},\hat{b})\).
So we can assume that \({\mathfrak {l}}\) is the unique highest node of \(\lambda ^+\). Let \((a_1,b_1),\ldots ,(a_r,b_r)\) be the nodes of \(\lambda \) to the right of \({\mathfrak {l}}\) for which \(a_x+b_x=a+b-1\); order these nodes so that \(a_1>\cdots >a_r\). Note that if \(r\geqslant 1\), then automatically \((a_1,b_1)=(a-1,b)\). Similarly, let \((c_1,d_1),\ldots ,(c_s,d_s)\) be the nodes to the left of \({\mathfrak {l}}\) for which \(c_x+d_x=a+b-1\).
We compute \(F(\lambda ^+)\) by first factorising using the node \({\mathfrak {l}}\). We may also factorise \(F(\lambda )\) using the nodes \((a-1,b)\) and \((a,b-1)\) (omitting either or both of these, if a or b equals 1), and we readily obtain
Now we consider the partitions \(\lambda ^{[x]}\), for \(x\in X_{\lambda }^+\). From our assumptions so far, \(X_{\lambda }^+\) is the set of integers \(x_i=b_i-a_i-b+a\), for \(i=1,\ldots ,r\). Choose such an i, and set \(\kappa =\lambda ^{[x_i]}\). We wish to compare \(F(\kappa )\) with \(F(\lambda )\). To do this, we define
(where we put \(a_{i+1}=0\) if \(i=r\)), and we claim that \(F(\kappa )/F(\lambda )=F(\delta )/F(\gamma )\). If \(s=0\) and \(i=r\), then this is trivial since \(\gamma =\lambda \) and \(\delta =\kappa \); assuming instead that \(s\geqslant 1\) or \(i<r\), factorising both \(F(\kappa )\) and \(F(\lambda )\) at the nodes \((c_1,d_1),\ldots ,(c_s,d_s),(a_{i+1},b_{i+1}),\ldots ,(a_r,b_r)\) (i.e. at all the highest nodes of \(\kappa \)) gives the result.
Now \(\gamma \) has highest nodes \((a-1-a_{i+1},1)\) and \((a_i-a_{i+1},b_i-b+1)\) (which coincide if \(i=1\)), and we factorise \(F(\gamma )\) at these nodes, obtaining
where \(\mu =\partial ^{a_i-a_{i+1}}_{1}\gamma \) and \(\nu =\partial _{b_i-b+1}\gamma \).
Claim
\(\dfrac{F(\delta )}{F(\gamma )}=\dfrac{a_i-a_{i+1}}{(a-a_i)(a-a_{i+1})}\).
Proof
In the case where \(a_i=a_{i+1}+1\), we have \(\mu =\delta \) and \(\nu =\varnothing \), so the factorisation of \(F(\gamma )\) above gives the result. If \(a_i>a_{i+1}+1\), then \(\delta \) has a highest node \((a_i-a_{i+1}-1,b_i-b+1)\), and factorising at this node we get
The claim follows from this factorisation and the factorisation of \(F(\gamma )\) above, using the fact that \(a_i+b_i=a+b-1\).
This claim yields
and summing over i we obtain
A symmetrical calculation applies to partitions \(\lambda ^{[x]}\) for \(x\in X_{\lambda }^-\), yielding
Adding these two results together and combining with (\(\dagger \)) gives the result. \(\square \)
Corollary 5.12
For \(1\leqslant i<k\) we have

Proof
As above, write \({\mathscr {P}}_{f,g}^+\) for the set of \(\lambda \in {\mathscr {P}}_{f,g}\) having an addable node in column \(i-g\), and for each such \(\lambda \) let \(\lambda ^+\) denote the partition obtained by adding this addable node. Then by Corollary 5.8 we have

and each summand on the right-hand side is zero by Proposition 5.11. \(\square \)
Proof of Theorem 5.10
Corollary 5.12 shows that \(\sum _\lambda F(\lambda )s_\lambda m\) is killed by all of \(s_1,\ldots ,s_{k-1}\), and hence lies in a trivial submodule of \(\mathscr {M}^{(f,g)}\). But \(\mathscr {M}^{(f,g)}\) is a permutation module for a transitive action of \({\mathfrak {S}}_k\), and so has a unique trivial submodule, spanned by the sum of the elements of the permutation basis, i.e. \(\sum _\lambda t_\lambda m\). So the two sides agree up to multiplication by a scalar. On the other hand, it is clear that when the right-hand side is expressed as a linear combination of the \(t_\lambda m\), the coefficient of \(t_\varnothing m\) is \(F(\varnothing )=1\), so in fact the two sides are equal. \(\square \)
5.4 Results of Kenyon, Kim, Mészáros, Panova and Wilson
As we have mentioned, cover-inclusive Dyck tilings were introduced by Kenyon and Wilson in [6], and in fact the main result in their paper has a bearing on the results in the present paper.
First we explain how cover-expansive Dyck tilings appear in disguise in [6]. Given a partition \(\lambda \), we define a sequence of parentheses ( and ), by ‘reading along the boundary’ of \(\lambda \), as follows. Working from left to right, for each node \({\mathfrak {a}}\) such that \(\mathtt {NW}({\mathfrak {a}})\) is not a node of \(\lambda \), we write a ), and for each node \({\mathfrak {a}}\) such that \(\mathtt {NE}({\mathfrak {a}})\) is not a node of \(\lambda \) we write a (. (If neither \(\mathtt {NW}({\mathfrak {a}})\) nor \(\mathtt {NE}({\mathfrak {a}})\) is a node of \(\lambda \), then we write ) (.) We then append an infinite string of (s at the start of the sequence, and an infinite sequence of )s at the end. The resulting doubly infinite sequence is called the parenthesis sequence of \(\lambda \).
Example
Let \(\lambda =(5,3^2,1)\). Then the parenthesis sequence of \(\lambda \) is \(\cdots \texttt {(}\texttt {(}\texttt {(}\texttt {)}\texttt {(}\texttt {)}\texttt {)}\texttt {(}\texttt {(}\texttt {)}\texttt {)}\texttt {(}\texttt {)}\texttt {)}\cdots \), as we see from the Young diagram, in which we mark the boundary in bold, extending it infinitely far to the north-west and north-east; segments \(\diagdown \) contribute a ( to the parenthesis sequence, while segments \(\diagup \) contribute a ).

Now partition the parenthesis expression for \(\lambda \) into pairs, in the usual way for pairing up parentheses: each ( is paired with the first subsequent ) for which there are an equal number of )s and (s in between.
Example
Continuing the last example, we illustrate the pairs by numbering the \(\texttt {)}\)s in increasing order, and numbering each \(\texttt {(}\) with the same number as its corresponding \(\texttt {)}\):
Remark
We remark that in [6] and elsewhere, finite parenthesis expressions are used: instead of appending infinite strings of ( and ) at the start and end of the expression obtained from the partition, one appends sufficiently long finite strings that the resulting expression is balanced, meaning that it contains equally many (s and )s, and that any initial segment contains at least as many (s as )s. We find our convention more straightforward in the present context, and translation between the two conventions is very easy.
Now we recall a definition from [6]; it is phrased there in terms of finite Dyck paths, but it is more convenient for us to phrase it in terms of partitions. Given two partitions \(\lambda ,\mu \), write \(\lambda \mathop {\leftarrow }\limits ^{\texttt {()} }\mu \) if the parenthesis expression for \(\lambda \) can be obtained from that for \(\mu \) by taking some of the pairs \(\texttt {(}\cdots \texttt {)}\) and reversing them to get \(\texttt {)}\cdots \texttt {(}\).
With this definition, we can describe the connection to cover-expansive Dyck tilings. The following proposition is not hard to prove, and we leave it as an exercise for the reader.
Proposition 5.13
Suppose \(\lambda ,\mu \) are partitions. Then \(\lambda \mathop {\leftarrow }\limits ^{\texttt {()} }\mu \) if and only if \(\lambda \supseteq \mu \) and there is a cover-expansive Dyck tiling of \(\lambda \backslash \mu \).
Now we can describe the relationship between our results and those of Kenyon and Wilson. Suppose f, g are positive integers as in Sect. 5.1, and define matrices N, P with rows and columns indexed by \({\mathscr {P}}_{f,g}\), and with
Then Theorems 5.2 and 5.4 show that N and P are mutual inverses. In fact, Kenyon and Wilson prove this result, but in a slightly different form. They define a matrix M with \(M_{\lambda \mu }=1\) if \(\lambda \mathop {\leftarrow }\limits ^{\texttt {()} }\mu \) and 0 otherwise, and show (using a different recursion for \({\text {i}}_{\lambda \mu }\) from ours) that \((M^{-1})_{\lambda \mu }=(-1)^{|\lambda |+|\mu |}{\text {i}}_{\lambda \mu }\) [6, Theorem 1.5]. In view of Proposition 5.13, we have \(M_{\lambda \mu }={\text {e}}_{\lambda \mu }\), and so the main result of [6] shows that Theorems 5.2 and 5.4 are equivalent. (There is another minor difference with our results, in that instead of the set \({\mathscr {P}}_{f,g}\) of partitions lying inside a rectangle, they consider the set of partitions lying inside a partition of the form \((c,c-1,\ldots ,1)\); however, one can easily show the equivalence of the two results by taking very large bounding partitions and appropriate submatrices.)
Of course, using this result we could remove a lot of the work in this paper, but we prefer to keep our proofs, thereby keeping our paper self-contained and providing a new (albeit longer) proof of the main result of [6].
We remark that Kim [8, §7] observes a q-analogue of the above result (for which he also credits Konvalinka); in this, the integer \({\text {i}}_{\lambda \mu }\) is replaced with the polynomial
where |T| denotes the number of tiles in the tiling T, and similarly for \({\text {e}}_{\lambda \mu }\). It should be possible to give a new proof of this result using our techniques: in our bijective results (Propositions 3.3–3.8 and 4.6) it is easy to keep track of how the number of tiles in a tiling changes, so q-analogues of our recursive results can easily be proved. Replacing the group algebra of the symmetric group with the Hecke algebra of type A should enable q-analogues of Theorems 5.2 and 5.4 to be proved, yielding a new proof of Kim’s and Konvalinka’s result. We leave the details to the proverbial interested reader.
Another result from the literature relates to Theorem 5.10. To describe this relationship, we give an alternative characterisation of the function \(F\), for which we need another definition. Given a partition \(\lambda \), construct the parenthesis sequence of \(\lambda \) and divide it into pairs as above, and define a partial order on the set of pairs by saying that the pair \(\underset{a}{\texttt {(}}\cdots \underset{a}{\texttt {)}}\) is larger than the pair \(\underset{b}{\texttt {(}}\cdots \underset{b}{\texttt {)}}\) if the former is nested inside the latter: \(\underset{b}{\texttt {(}}\cdots \underset{\phantom {b}a}{\texttt {(}}\cdots \underset{\phantom {b}a}{\texttt {)}}\cdots \underset{b}{\texttt {)}}\). Call this partially ordered set \({\mathcal {P}}(\lambda )\).
Example
Continuing the last example and retaining the labelling for the pairs in the parenthesis sequence for \(\lambda \), we have the following Hasse diagram for \({\mathcal {P}}(\lambda )\).

Now we have the following.
Proposition 5.14
Suppose \(\lambda \) is a partition. Then \(F(\lambda )\) is the number of linear extensions of the poset \({\mathcal {P}}(\lambda )\).
A proof of this proposition was sketched by David Speyer in a response to the author’s MathOverflow question [13]. In a comment to the same answer, Philippe Nadeau pointed out that this provides a non-recursive expression for \(F(\lambda )\). To state this, we let \({\mathcal {P}}_N(\lambda )\) denote the poset obtained by taking the N largest elements of \({\mathcal {P}}(\lambda )\). Then for large enough N the number of linear extensions of \({\mathcal {P}}(\lambda )\) equals the number of linear extensions of \({\mathcal {P}}_N(\lambda )\). Given a pair \(p\in {\mathcal {P}}(\lambda )\), define its length l(p) to be 1 plus the number of intervening pairs. Now an easy exercise [11, p. 70, Exercise 20] gives the following.
Proposition 5.15
Suppose \(\lambda \) is a partition, and \(N\gg 0\). Then the number of linear extensions of the poset \({\mathcal {P}}_N(\lambda )\) equals
Example
Taking \(N=8\) in the last example and labelling each pair by its length, we have

So \(F(\lambda )\) is the number of linear extensions of \({\mathcal {P}}_8(\lambda )\), which is
The author is very grateful to David Speyer and Philippe Nadeau for these comments (and also to Gjergji Zaimi for similar comments in the same thread), which inspired the introduction of Dyck tilings in the present work.
Given Theorem 5.4 and Proposition 5.14, Theorem 5.10 is equivalent to the following theorem.
Theorem 5.16
Suppose \(\lambda \) is a partition and \(N\gg 0\). Then
This statement (in fact, a q-analogue) was conjectured by Kenyon and Wilson [6, Conjecture 1]. It was proved inductively by Kim [8, Theorem 1.1], and then a bijective proof was given by Kim, Mészáros, Panova and Wilson [9, Theorem 1.1]. We retain our proof of Theorem 5.10 to keep the paper self-contained (and so that Theorem 5.10 can be proved without reference to tilings), and we note in passing that this yields a new proof of Theorem 5.16.
6 The homogeneous Garnir relations
In this section we apply our earlier results to the study of representations of the (cyclotomic) quiver Hecke algebras (also known as KLR algebras) of type A, and in particular the homogeneous Garnir relations for the universal graded Specht modules of Kleshchev et al. [10].
6.1 The quiver Hecke algebra
Suppose \({\mathbb {F}}\) is a field of characteristic p, \(e\in \{2,3,4,\ldots \}\) and \(n\in {\mathbb {N}}\). The quiver Hecke algebra \({\mathcal {R}}_n\) of type A is a unital associative \({\mathbb {F}}\)-algebra with a generating set
and a somewhat complicated set of defining relations, which may be found in [3] or [10], for example. These relations allow one to write down a basis for \({\mathcal {R}}_n\): to do this, choose and fix a reduced expression \(w=t_{i_1}\ldots t_{i_r}\) for each \(w\in {\mathfrak {S}}_n\), and set \(\psi _w=\psi _{i_1}\ldots \psi _{i_r}\). Then the set
is a basis for \({\mathcal {R}}_n\).
The quiver Hecke algebra has attracted considerable attention in recent years, thanks to the astonishing result of Brundan and Kleshchev [3, Main Theorem] that when p does not divide e, a certain finite-dimensional ‘cyclotomic’ quotient of \({\mathcal {R}}_n\) is isomorphic to the cyclotomic Hecke algebra of type A (as introduced by Ariki–Koike [1] and Broué–Malle [2]) defined at a primitive eth root of unity in \({\mathbb {F}}\); when \(e=p\), there is a corresponding isomorphism to the degenerate cyclotomic Hecke algebra (which includes the group algebra \({\mathbb {F}}{\mathfrak {S}}_n\) as a special case). This in particular shows that these Hecke algebras (which include the group algebra of the symmetric group) are non-trivially \({\mathbb {Z}}\)-graded, and has initiated the study of the graded representation theory of these algebras.
A crucial role in the representation theory of Hecke algebras is played by the Specht modules. Brundan et al. [4] showed how to work with the Specht modules in the quiver Hecke algebra setting, demonstrating in particular that these modules are graded. Kleshchev, Mathas and Ram [10] gave a presentation for each Specht module with a single generator and a set of homogeneous relations. These relations include ‘homogeneous Garnir relations’; although these are in general simpler than the classical Garnir relations for ungraded Specht modules (which go back to [5] in the symmetric group case), the expressions given for these relations in [10] are quite complicated. The purpose of this section is to use the results of the previous section to give a simpler expression for each homogeneous Garnir relation. In computations with graded Specht modules using the author’s GAP programs, implementing these simpler expressions has been observed to have some benefits in terms of computational efficiency.
We now define the cyclotomic quotients of the quiver Hecke algebras and their Specht modules. Choose a positive integer l, and an l-tuple \((\kappa _1,\ldots ,\kappa _l)\in (\mathbb {Z}/e\mathbb {Z})^l\). For each \(a\in \mathbb {Z}/e\mathbb {Z}\) define \(\kappa (a)\) to be the number of values of j for which \(\kappa _j=a\), and define \({\mathcal {R}}^\kappa _n\) to be the quotient of \({\mathcal {R}}_n\) by the ideal generated by the elements \(y_1^{\kappa (i_1)}e({\mathbf {i}})\) for all \(i\in (\mathbb {Z}/e\mathbb {Z})^n\). We use the same notation for the standard generators of \({\mathcal {R}}_n\) and their images in \({\mathcal {R}}^\kappa _n\).
6.2 Row permutation modules and Specht modules
From now on, we stick to the case \(l=1\), which corresponds to the Iwahori–Hecke algebra of type A; there is no essential difference in the homogeneous Garnir relations for arbitrary l, and we save on notation and terminology by restricting to this special case. We work only with ungraded modules, since the grading plays no part in our results.
In the case \(l=1\), the Specht modules (by which we mean the row Specht modules of [10, §5.4]) are labelled by partitions. For the sake of alignment with the rest of the literature, we now change to using the English convention for Young diagrams in this section, where the first coordinate increases down the page and the second increases from left to right.
Suppose \(\pi \) is a partition of n. If (a, b) is a node, its residue is defined to be \({\text {res}}((a,b))=b-a+\kappa _1\ ({\text {mod}}\,e)\). A \(\pi \)-tableau is a bijection from the Young diagram of \(\pi \) to the set \(\{1,\ldots ,n\}\). We specify a particular \(\pi \)-tableau \({{\mathtt {T}}}^{\pi }\) by assigning the numbers \(1,\ldots ,n\) to the nodes
in order. For example, when \(\pi =(6,4,1^{2})\) we have

We define an element \({\mathbf {i}}^\pi \) of \((\mathbb {Z}/e\mathbb {Z})^n\) by setting \({\mathbf {i}}^\pi _j={\text {res}}(({{\mathtt {T}}}^{\pi })^{-1}(j))\). For example, with \(\pi =(6,4,1^2)\), \(e=4\) and \(\kappa _1=0\), \({\mathbf {i}}^\pi \) is the sequence (0, 1, 2, 3, 0, 1, 3, 0, 1, 2, 2, 1).
Now we can define the row permutation module \({{\text {M}}^{\pi }}\) from [10, §5.3]. This has a single generator \(m^\pi \), and relations as follows:
-
\(e({\mathbf {i}}^\pi )m^\pi =m^\pi \);
-
\(y_jm^\pi =0\) for all j;
-
\(\psi _jm^\pi =0\) whenever j and \(j+1\) lie in the same row of \({{\mathtt {T}}}^{\pi }\).
It is easy to write down a basis for \({\text {M}}^{\pi }\). Say that a \(\pi \)-tableau \({\mathtt {T}}\) is row-strict if the entries increase from left to right along the rows. If \({\mathtt {T}}\) is row-strict, let \(w^{\mathtt {T}}\) be the permutation taking \({{\mathtt {T}}}^{\mu }\) to \({\mathtt {T}}\), and define \({\psi }^{{\mathtt {T}}}:=\psi _{w^{\mathtt {T}}}\), and \(m^{\mathtt {T}}=\psi ^{\mathtt {T}}m^\pi \). Then by [10, Theorem 5.6] the set \(\left\{ \left. m^{{\mathtt {T}}}\ \right| \ \smash {{\mathtt {T}}\text { a row-strict} \pi \text {-tableau}}\right\} \) is a basis for \({\text {M}}^{\pi }\).
The Specht module \({\text {S}}^{\pi }\) is the quotient of \({\text {M}}^{\pi }\) by the homogeneous Garnir relations, which we now define. Say that a node \({\mathfrak {n}}=(a,b)\) of \(\pi \) is a Garnir node if \((a+1,b)\) is also a node of \(\pi \). If \({\mathfrak {n}}\) is a Garnir node, define the Garnir belt \(\mathbf B^{{\mathfrak {n}}}\) to be the set of nodes
The Garnir tableau \({\mathtt {G}}^{{\mathfrak {n}}}\) is the tableau defined by taking \({\mathtt {T}}^\pi \) and rearranging the entries within \(\mathbf B^{{\mathfrak {n}}}\) so that they increase from bottom left to top right. For example, with \(\pi =(6,4,1^2)\) and \({\mathfrak {n}}=(1,3)\), the tableau \({\mathtt {G}}^{{\mathfrak {n}}}\) (with the Garnir belt \(\mathbf B^{\mathfrak {n}}\) shaded) is as follows.

Now we define bricks: an \({\mathfrak {n}}\)-brick is defined to be a set of e consecutive nodes in the same row of \(\mathbf B^{{\mathfrak {n}}}\) of which the leftmost has the same residue as \({\mathfrak {n}}\). For example, take \(\pi =(6,4,1^2)\) and \({\mathfrak {n}}=(1,3)\) as above. If \(e=2\), then the bricks are
while if \(e=3\) the bricks are
Let f denote the number of bricks in row a and g the number of bricks in row \(a+1\), and set \(k=f+g\). If \(k>0\), let \(d=d^{{\mathfrak {n}}}\) be the smallest number which is contained in a brick in \({\mathtt {G}}^{\mathfrak {n}}\), and for \(1\leqslant i<k\) define \(w_i\) to be the permutation
Recalling the notation \(\psi _w\) for \(w\in {\mathfrak {S}}_n\) from above, set \(\sigma ^{\mathfrak {n}}_i=\psi _{w_i}\); unlike the situation for arbitrary w, \(\psi _{w_i}\) does not depend on the choice of reduced expression for \(w_i\). Also set \(\tau ^{\mathfrak {n}}_i=\sigma ^{\mathfrak {n}}_i+1\).
Remark
In the definition [10, (5.7)], the elements \(\tau ^{\mathfrak {n}}_i,\sigma ^{\mathfrak {n}}_i\) include an idempotent \(e({\mathbf {i}}^{\mathfrak {n}})\) as a factor in order to make them homogeneous, but this factor is unnecessary for our purposes, so we prefer the simpler version.
Now let \({\mathtt {T}}^{{\mathfrak {n}}}\) be the tableau obtained from \({\mathtt {G}}^{{\mathfrak {n}}}\) by reordering the bricks so that their entries increase along row a and then row \(a+1\).
Continuing the example above, we illustrate the tableau \({\mathtt {T}}^{\mathfrak {n}}\) for \(e=2,3\), shading the Garnir belt and outlining the bricks:

Define \(\psi ^{{\mathtt {T}}^{\mathfrak {n}}}\) as above; as noted in [10, §5.4], \(\psi ^{{\mathtt {T}}^{\mathfrak {n}}}\) is independent of the choice of reduced expression for \(w_{{\mathtt {T}}^{\mathfrak {n}}}\).
Now we define elements of \({\mathcal {R}}^\kappa _n\) corresponding to the elements \(t_\lambda \) and \(s_\lambda \) of \({\mathbb {F}}{\mathfrak {S}}_k\) defined in Sect. 5. For \(\lambda \in {\mathscr {P}}_{f,g}\), define
and define \(\sigma ^{\mathfrak {n}}_\lambda \) similarly. Then the elements \(\sigma ^{\mathfrak {n}}_\lambda \psi ^{{\mathtt {T}}^{\mathfrak {n}}}\) are precisely the elements \(\psi ^{\mathtt {T}}\) for row-strict tableaux \({\mathtt {T}}\) obtained from \({\mathtt {G}}^{\mathfrak {n}}\) by permuting the bricks.
Now we can define the homogeneous Garnir relations and the Specht module. Given a Garnir node \({\mathfrak {n}}\), the corresponding Garnir element is

The Specht module \({\text {S}}^{\pi }\) is defined to be the quotient of \({\text {M}}^{\pi }\) by the relations \(g^{\mathfrak {n}}m^\pi =0\) for all Garnir nodes \({\mathfrak {n}}\) of \(\pi \).
6.3 Rewriting the Garnir relations
The difficulty with the definition of the Specht module given above, especially from a computational point of view, is that the individual terms \(\tau ^{\mathfrak {n}}_\lambda \psi ^{{\mathtt {T}}^{\mathfrak {n}}}m^\pi \) appearing in the Garnir relation are not readily expressed in terms of the standard basis \(\left\{ \left. m^{\mathtt {T}}\ \right| \ \smash {{\mathtt {T}}\text { row-strict}}\right\} \) for \({\text {M}}^{\pi }\); to express it in these terms, some quite involved reduction is required using the defining relations in \({\mathcal {R}}_n\).
Example
Take \(\pi =(11,5,3,1)\), \({\mathfrak {n}}=(1,5)\) and \(e=3\). Then we have \(f=2\), \(g=1\), and
while \(\psi ^{{\mathtt {T}}^{\mathfrak {n}}}=\psi _{6}\psi _{5}\psi _{7}\psi _{6}\psi _{8}\psi _{7}\psi _{9}\psi _{8}\psi _{10}\psi _{9}\psi _{11}\psi _{10}\psi _{15}\psi _{14}\psi _{13}\psi _{12}\psi _{11}\). Hence the Garnir element \(g^{\mathfrak {n}}\) is
A non-trivial calculation using the defining relations for \({\mathcal {R}}_n\) and the fact that \(m^\pi \) is killed by \(\psi _5\), \(\psi _6\) and \(\psi _7\) shows that \(\sigma ^{\mathfrak {n}}_1\psi ^{{\mathtt {T}}^{\mathfrak {n}}}m^\pi =0\). Hence
where

We wish to generalise the above example, to rewrite \(g^{\mathfrak {n}}m^\pi \) for an arbitrary Garnir node \({\mathfrak {n}}\) as a linear combination of elements \(\sigma ^{\mathfrak {n}}_\lambda \psi ^{{\mathtt {T}}^{\mathfrak {n}}}m^\pi \). Fortunately, all the computations that we need with the defining relations for \({\mathcal {R}}_n\) have already been done in [10].
Given a Garnir node \({\mathfrak {n}}\) of \(\pi \), define the brick permutation space \(T^{\pi ,{\mathfrak {n}}}\) to be the \({\mathbb {F}}\)-subspace of \({\text {M}}^{\pi }\) spanned by all elements of the form \(\sigma ^{\mathfrak {n}}_{i_1}\ldots \sigma ^{\mathfrak {n}}_{i_s}\psi ^{{\mathtt {T}}^{\mathfrak {n}}}m^\pi \). Then the \(\sigma ^{\mathfrak {n}}_i\), and hence the \(\tau ^{\mathfrak {n}}_i\), act on \(T^{\pi ,{\mathfrak {n}}}\), and we have the following.
Theorem 6.1
[10, Theorem 5.11] As operators on \(T^{\pi ,{\mathfrak {n}}}\), the elements \(\tau ^{\mathfrak {n}}_1,\ldots ,\tau ^{\mathfrak {n}}_{k-1}\) satisfy the Coxeter relations for the symmetric group \({\mathfrak {S}}_k\), and hence \(T^{\pi ,{\mathfrak {n}}}\) can be considered as an \({\mathbb {F}}{\mathfrak {S}}_k\)-module. In fact, as an \({\mathbb {F}}{\mathfrak {S}}_n\)-module \(T^{\pi ,{\mathfrak {n}}}\) is isomorphic to the Young permutation module \(\mathscr {M}^{(f,g)}\), with an isomorphism given by mapping \(\psi ^{{\mathtt {T}}^{\mathfrak {n}}}m^\pi \) to the standard generator \(m\).
By Theorem 6.1 and the discussion at the start of Sect. 5, the sets
are \({\mathbb {F}}\)-bases of \(T^{\pi ,{\mathfrak {n}}}\). Theorems 5.2 and 5.4 give the transition coefficients between these bases, while Theorem 5.10 gives the sum of the elements of the first basis in terms of the second basis. So we can immediately deduce the following, which is the main result of this section.
Theorem 6.2
Suppose \(\pi \) is a partition and \({\mathfrak {n}}=(a,b)\) is a Garnir node of \(\pi \), and let f, g denote the numbers of bricks in rows a and \(a+1\) of \(\mathbf B^{\mathfrak {n}}\), respectively. Define \(\sigma ^{\mathfrak {n}}_\lambda \) and \(\tau ^{\mathfrak {n}}_\lambda \) for \(\lambda \in {\mathscr {P}}_{f,g}\) as above, and define the modified Garnir element

Then:
-
1.
 ;
; -
2.
 ;
; -
3.
\(\hat{g}^{\mathfrak {n}}m^\pi =g^{\mathfrak {n}}m^\pi \).
 ;
; ;
;Hence, the Specht module \({\text {S}}^{\pi }\) is the quotient of \({\text {M}}^{\pi }\) by the relations \(\hat{g}^{\mathfrak {n}}m^\pi =0\) for all Garnir nodes \({\mathfrak {n}}\) of \(\pi \).
Remarks.
-
1.
Statements (1) and (2) in the theorem are not necessary for the Garnir relations, but may be of interest for computation in the row permutation modules; indeed, the coefficients in (1) are essentially the coefficients \(c_w\) appearing in [10, Corollary 5.12].
-
2.
We emphasise that the identities in Theorem 6.2 are not true if the terms \(m^\pi \) are omitted; in general, \(\tau ^{\mathfrak {n}}_\mu \) is not a linear combination of \(\sigma ^{\mathfrak {n}}_\lambda \)s (even if the idempotent \(e({\mathbf {i}}^{\mathfrak {n}})\) from [10, (5.7)] is reinstated in the definition of \(\sigma ^{\mathfrak {n}}_i\) and \(\tau ^{\mathfrak {n}}_i\)).
We end with an example which illustrates how the Garnir relations are used in Specht module computations. Say that a \(\pi \)-tableau is standard if the entries are increasing both along the rows and down the columns. If we let \(v^{\mathtt {T}}\) denote the image of \(m^{\mathtt {T}}\) in the Specht module, then by [10, Corollary 6.24] the set \(\left\{ \left. v^{\mathtt {T}}\ \right| \ \smash {{\mathtt {T}}\text { a standard} \pi \text {-tableau}}\right\} \) is a basis for \({\text {S}}^{\pi }\). The Garnir relations allow one to write \(v^{\mathtt {T}}\) as a linear combination of this basis when \({\mathtt {T}}\) is a row-strict, but not standard, tableau. The foundation for this is [10, Lemma 5.13] which does this in the case where \({\mathtt {T}}={\mathtt {G}}^{\mathfrak {n}}\) for a Garnir node \({\mathfrak {n}}\).
For our example, take \(\pi =(8,4)\) and \(e=2\). Let \({\mathfrak {n}}=(1,4)\). Then \(f=g=2\), and

As with any Garnir node, \({\mathtt {G}}^{\mathfrak {n}}\) is row-strict but not standard. The modified Garnir element is
and the corresponding Garnir relation yields
where \({\mathtt {U}},{\mathtt {V}},{\mathtt {W}},{\mathtt {X}},{\mathtt {Y}}\) are standard tableaux that we describe as follows. We represent the elements \(\psi ^{\mathtt {U}},\psi ^{\mathtt {V}},\psi ^{\mathtt {W}},\psi ^{\mathtt {X}},\psi ^{\mathtt {Y}}\) using the braid diagrams of Khovanov and Lauda [7]; by using shaded squares, we illustrate (reverting to the Russian convention!) how the labelling partitions \(\lambda \in {\mathscr {P}}_{2,2}\) arise.

References
Ariki, S., Koike, K.: A Hecke algebra of \((\mathbb{Z}/r\mathbb{Z})\wr {\mathfrak{S}}_{n}\) and construction of its irreducible representations. Adv. Math. 106, 216–243 (1994)
Broué, M., Malle, G.: Zyklotomische Heckealgebren. Astérisque 212, 119–189 (1993)
Brundan, J., Kleshchev, A.: Blocks of cyclotomic Hecke algebras and Khovanov–Lauda algebras. Invent. Math. 178, 451–484 (2009)
Brundan, J., Kleshchev, A., Wang, W.: Graded Specht modules. J. Reine Angew. Math. 655, 61–87 (2011)
Garnir, H.: Théorie de la representation lineaire des groupes symétriques. Mém. Soc. R. Sci. Liège 10, 100 (1950)
Kenyon, R., Wilson, D.: Double-dimer pairings and skew Young diagrams. Electron. J. Combin. 18, Paper 130 (2011)
Khovanov, M., Lauda, A.: A diagrammatic approach to categorification of quantum groups I. Represent. Theory 13, 309–347 (2009)
Kim, J.S.: Proofs of two conjectures of Kenyon and Wilson on Dyck tilings. J. Combin. Theory Ser. A. 119, 1692–1710 (2012)
Kim, J.S., Mészáros, K., Panova, G., Wilson, D.: Dyck tilings, linear extensions, descents, and inversions. arXiv:1205.6578
Kleshchev, A., Mathas, A., Ram, A.: Universal graded Specht modules for cyclotomic Hecke algebras. Proc. Lond. Math. Soc. 105, 1245–1289 (2012)
Knuth, D.: The art of computer programming. Volume 3: sorting and searching. Addison–Wesley Series in Computer Science and Information Processing. Addison-Wesley Publishing Co., Reading, MA–London–Don Mills, ON (1973)
Shigechi, K., Zinn-Justin, P.: Path representation of maximal parabolic Kazhdan–Lusztig polynomials. J. Pure Appl. Algebra 216, 2533–2548 (2012)
Speyer, D.: A function from partitions to natural numbers—is it familiar?mathoverflow.net/q/132548
Acknowledgements
The author is greatly indebted to David Speyer and Philippe Nadeau for comments on the online forum MathOverflow which inspired the author to introduce Dyck tilings into this paper.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Fayers, M. Dyck tilings and the homogeneous Garnir relations for graded Specht modules. J Algebr Comb 45, 1041–1082 (2017). https://doi.org/10.1007/s10801-016-0734-2
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10801-016-0734-2