
Abstract
Miscalibration, the failure to accurately evaluate one’s own work relative to others' evaluation, is a common concern in social systems of knowledge creation where participants act as both creators and evaluators. Theories of social norming hold that individual’s self-evaluation miscalibration diminishes over multiple iterations of creator-evaluator interactions and shared understanding emerges. This paper explores intersubjectivity and the longitudinal dynamics of miscalibration between creators' and evaluators' assessments in IT-enabled social knowledge creation and refinement systems. Using Latent Growth Modeling, we investigated dynamics of creator’s assessments of their own knowledge artifacts compared to peer evaluators' to determine whether miscalibration attenuates over multiple interactions. Contrary to theory, we found that creator’s self-assessment miscalibration does not attenuate over repeated interactions. Moreover, depending on the degree of difference, we found self-assessment miscalibration to amplify over time with knowledge artifact creators' diverging farther from their peers' collective opinion. Deeper analysis found no significant evidence of the influence of bias and controversy on miscalibration. Therefore, relying on social norming to correct miscalibration in knowledge creation environments (e.g., social media interactions) may not function as expected.












Similar content being viewed by others


References
Alwin, D. F., & Krosnick, J. A. (1985). The measurement of values in surveys: a comparison of ratings and rankings. Public Opinion Quarterly, 49(4), 535–552. doi:10.1086/268949.
Amin, A., & Roberts, J. (2008). Knowing in action: beyond communities of practice. Research Policy, 37(2), 353–369. doi:10.1016/j.respol.2007.11.003.
Anders, R., & Batchelder, W. H. (2012). Cultural consensus theory for multiple consensus truths. Journal of Mathematical Psychology, 56(6), 452–469.
Bandura, A. (1962). Social learning through imitation. University of Nebraska Press.
Bandura, A. (1977). Self-efficacy: toward a unifying theory of behavioral change. Psychological Review, 84, 191–215. doi:10.1037/0033-295X.84.2.191.
Bandura, A., & Walters, R. H. (1963). Social Learning and Personality Development. New York, Holt, Rinehart and Winston [1963].
Barnett, W. (2003). The modern theory of consumer behavior: ordinal or cardinal? The Quarterly Journal of Austrian Economics, 6(1), 41–65.
Batchelder, W. H., & Anders, R. (2012). cultural consensus theory: comparing different concepts of Cultural truth. Journal of Mathematical Psychology, 56(5), 316–332.
Bentein, K., Vandenberghe, C., Vandenberg, R., & Stinglhamber, F. (2005). The role of change in the relationship between commitment and turnover: a latent growth modeling approach. Journal of Applied Psychology, 90(3), 468–482. doi:10.1037/0021-9010.90.3.468.
Black, P., & Wiliam, D. (1998). Assessment and classroom learning. Assessment in Education: Principles, Policy & Practice, 5(1), 7–74. doi:10.1080/0969595980050102.
Bostrom, R. P., & Heinen, J. S. (1977). MIS problems and failures: a socio-technical perspective. Part I: the causes. MIS Quarterly, 1(3), 17–32.
Bouzidi, L., & Jaillet, A. (2009). Can online peer assessment be trusted? Educational Technology & Society, 12(4), 257–268.
Brown, J. S., Collins, A., & Duguid, P. (1989). Situated cognition and the culture of learning. Educational Researcher, 18(1), 32–42. doi:10.3102/0013189X018001032.
Brown, J. S., & Duguid, P. (2001). Knowledge and organization: a social-practice perspective. Organization Science, 12(2), 198–213. doi:10.1287/orsc.12.2.198.10116.
Brutus, S., & Donia, M. B. L. (2010). Improving the effectiveness of students in groups with a centralized peer evaluation system. The Academy of Management Learning and Education (AMLE), 9(4), 652–662.
Brutus, S., Donia, M. B. L., & Ronen, S. (2013). Can business students learn to evaluate better? Evidence from repeated exposure to a peer-evaluation system. Academy of Management Learning & Education Academy of Management Learning & Education, 12(1), 18–31.
Buchy, M., & Quinlan, K. M. (2000). Adapting the scoring matrix: a case study of adapting disciplinary tools for learning centred evaluation. Assessment & Evaluation in Higher Education, 25(1), 81–91. doi:10.1080/713611419.
Campbell, D. J. (1988). Task complexity: a review and analysis. Academy of Management Review, 13(1), 40–52.
Carterette, B., Bennett, P. N., Chickering, D. M., & Dumais, S. T. (2008). Here or there: preference judgments for relevance. Lecture Notes in Computer Science, 4956, 16–27.
Cho, K., Chung, T. R., King, W. R., & Schunn, C. D. (2008). Peer-based computer-supported knowledge refinement: an empirical investigation. Communications of the ACM, 51(3), 83–88. doi:10.1145/1325555.1325571.
Conklin, J. (2001). Wicked problems and social complexity. Dialogue Mapping:Building Shared Understanding of Wicked Problems Retrieved from http://www.ideapartnership.org/documents/wickedproblems.pdf.
Crooks, T. (2001). The validity of formative assessments. University of Leeds.
Curran, P., Bauer, D., & Willoughby, M. (2004). Testing main effects and interactions in latent curve analysis. Psychological Methods, 9(2), 220–237.
Cusinato, A., Della Mea, V., Di Salvatore, F., & Mizzaro, S. (2009). QuWi: Quality control in Wikipedia. In Proceedings of the 3rd workshop on information credibility on the web (pp. 27–34). New York, NY, USA: ACM. doi:10.1145/1526993.1527001.
Dai, H., Zhu, F., Lim, E.-P., & Pang, H. (2012). Detecting Anomalies in Bipartite Graphs with Mutual Dependency Principles. In IEEE 12th International Conference on Data Mining (ICDM) 2012 (pp. 171–180). IEEE. Retrieved from http://ieeexplore.ieee.org/xpls/abs_all.jsp?arnumber=6413905
Dede, C. (2008). A seismic shift in epistemology. Educause Review, 43(3).
Dochy, F., Segers, M., & Sluijsmans, D. (1999). The use of self-, peer and Co-assessment in higher education: a review. Studies in Higher Education, 24(3), 331–350.
Dorst, K. (2003). The problem of design problems. Expertise in Design, 135–147.
Douceur, J. R. (2009). Paper rating vs. Paper ranking. ACM SIGOPS Operating Systems Review, 43(2), 117–121.
Duncan, T. E. (1999). An introduction to latent variable growth curve modeling: Concepts, issues, and applications. Mahwah, N.J.:L. Erlbaum Associates Retrieved from http://search.ebscohost.com/login.aspx?direct=true&scope=site&db=nlebk&db=nlabk&AN=19332.
Edwards, K. (2001). Epistemic communities. Situated Learning and Open Source Software Development. Epistemic Cultures and the Practice of Interdisciplinarity Retrieved from http://orbit.dtu.dk/fedora/objects/orbit:51813/datastreams/file_2976336/content.
Falchikov, N. (1986). Product comparisons and process benefits of collaborative peer group and self assessments. Assessment and Evaluation in Higher Education, 11(2), 146–166.
Falchikov, N., & Boud, D. (1989). Student self-assessment in higher education: a meta-analysis. Review of Educational Research, 59(4), 395–430. doi:10.3102/00346543059004395.
Ford, E., & Babik, D. (2013). Methods and Systems for Educational On-Line Methods.
Gagne, R. M. (1985). The conditions of learning and theory of instruction. Holt Rinehart & Winston.
Gersick, C. J. G. (1991). Revolutionary change theories: a multilevel exploration of the punctuated equilibrium paradigm. Academy of Management Review, 16(1), 10–36. doi:10.5465/AMR.1991.4278988.
Gillespie, A., & Cornish, F. (2010). Intersubjectivity: towards a dialogical analysis. Journal for the Theory of Social Behaviour, 40(1), 19–46. doi:10.1111/j.1468-5914.2009.00419.x.
Habermas, J. (1981). New social movements.
Hardaway, D. E., & Scamell, R. W. (2012). Open knowledge creation: bringing transparency and inclusiveness to the peer review process. MIS Quarterly, 36(2).
Hargrave, T. J., & Van de Ven, A. H. (2006). A collective action model of institutional innovation. Academy of Management Review, 31(4), 864–888.
Heersmink, R. (2013). A taxonomy of cognitive artifacts: function, information, and categories. Review of Philosophy and Psychology, 4(3), 465–481.
Hermida, A. (2011). Social media is inherently a system of peer evaluation [blog]. Retrieved September 21, 2012, from http://blogs.lse.ac.uk/impactofsocialsciences/2011/06/27/social-media-is-inherently-a-system-of-peer-evaluation-and-is-changing-the-way-scholars-disseminate-their-research-raising-questions-about-the-way-we-evaluate-academic-authority/.
Huhta, A. (2008). Diagnostic and formative assessment. In B. Spolsky, & F. M. Hult (Eds.), The handbook of educational linguistics (pp. 469–482). Blackwell Publishing Ltd. Retrieved from http://onlinelibrary.wiley.com/doi/10.1002/9780470694138.ch33/summary.
Hu, M., Lim, E.-P., Sun, A., Lauw, H. W., & Vuong, B.-Q. (2007). Measuring article quality in Wikipedia: Models and evaluation. In Proceedings of the sixteenth ACM conference on information and knowledge management (pp. 243–252). New York: ACM. doi:10.1145/1321440.1321476.
Jones, B. L., Nagin, D. S., & Roeder, K. (2001). A SAS procedure based on mixture models for estimating developmental trajectories. Sociological Methods & Research, 29(3), 374–393. doi:10.1177/0049124101029003005.
Joordens, S., Desa, S., & Paré, D. (2009). The pedagogical anatomy of peer assessment: dissecting a peerScholar assignment. Journal of Systemics, Cybernetics & Informatics, 7(5) Retrieved from http://www.iiisci.org/journal/CV$/sci/pdfs/XE123VF.pdf.
Kamsu-Foguem, B., Tchuenté-Foguem, G., & Foguem, C. (2014). Using conceptual graphs for clinical guidelines representation and knowledge visualization. Information Systems Frontiers, 16(4), 571–589. doi:10.1007/s10796-012-9360-2.
Kass, R. E., & Raftery, A. E. (1995). Bayes factors. Journal of the American Statistical Association, 90(430), 773–795. doi:10.1080/01621459.1995.10476572.
Kass, R. E., & Wasserman, L. (1995). A reference Bayesian test for nested hypotheses and its relationship to the Schwarz criterion. Journal of the American Statistical Association, 90(431), 928–934. doi:10.1080/01621459.1995.10476592.
King, A. (1989). Verbal interaction and problem-solving within computer-assisted cooperative learning groups. Journal of Educational Computing Research, 5(1), 15.
Kirsh, D. (2010). Thinking with external representations. AI & SOCIETY, 25(4), 441–454.
Koriat, A., Lichtenstein, S., & Fischhoff, B. (1980). Reasons for confidence. Journal of Experimental Psychology: Human Learning & Memory Journal of Experimental Psychology: Human Learning & Memory, 6(2), 107–118.
Kreps, D. M. (1997). Intrinsic motivation and extrinsic incentives. American Economic Review, 87(2), 359–364.
Krosnick, J. A. (1999). Maximizing questionnaire quality. In J. P. Robinson, P. R. Shaver, & L. S. Wrightsman (Eds.), Measures of political attitudes (pp. 37–57). San Diego, CA US: Academic Press.
Krosnick, J. A., Thomas, R., & Shaeffer, E. (2003). How Does Ranking Rate?: A Comparison of Ranking and Rating Tasks. In Conference Papers – American Association for Public Opinion Research (p. N.PAG).
Kruger, J., & Dunning, D. (1999). Unskilled and unaware of it: how difficulties in recognizing one’s own incompetence lead to inflated self-assessments. Journal of Personality and Social Psychology, 77(6), 1121–1134. doi:10.1037/0022-3514.77.6.1121.
Kruger, J., & Dunning, D. (2002). Unskilled and unaware–but why? A reply to Krueger and Mueller. Journal of Personality and Social Psychology, 82(2), 189–192.
Lauw, H. W., Lim, E.-P., & Wang, K. (2006). Bias and Controversy: Beyond the Statistical Deviation. In Proceedings of the 12th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (pp. 625–630). ACM. Retrieved from http://dl.acm.org/citation.cfm?id=1150478
Lauw, H. W., Lim, E.-P., & Wang, K. (2008). Bias and controversy in evaluation systems. IEEE Transactions on Knowledge and Data Engineering, 20(11), 1490–1504.
Leite, W. L., & Stapleton, L. M. (2011). Detecting growth shape misspecifications in latent growth models: an evaluation of fit indexes. The Journal of Experimental Education, 79(4), 361–381. doi:10.1080/00220973.2010.509369.
Lichtenstein, S., & Fischhoff, B. (1980). Training for calibration. OBHP Organizational Behavior and Human Performance, 26(2), 149–171.
Lindblom-ylänne, S., Pihlajamäki, H., & Kotkas, T. (2006). Self-, peer- and teacher-assessment of student essays. Active Learning in Higher Education, 7(1), 51–62.
Lin, S. S.., Liu, E. Z.., & Yuan, S. M. (2001). Web-based peer assessment: feedback for students with various thinking-styles. Journal of Computer Assisted Learning, 17(4), 420–432. doi:10.1046/j.0266-4909.2001.00198.x
Markus, M. L., & Robey, D. (1988). Information technology and organizational change: causal structure in theory and research. Management Science Management Science, 34(5), 583–598.
Matusov, E. (1996). Intersubjectivity without agreement. Mind, Culture, and Activity, 3(1), 25–45. doi:10.1207/s15327884mca0301_4.
McKenzie, C. R. (1997). Underweighting alternatives and overconfidence. YOBHD Organizational Behavior and Human Decision Processes, 71(2), 141–160.
Meyer, B. D. (1995). Natural and quasi-experiments in economics. Journal of Business & Economic Statistics, 13(2).
Miller, G. A. (1956). The magical number seven, plus or minus two: some limits on our capacity for processing information. Psychological Review, 63(2), 81.
Miranda, S. M., & Saunders, C. S. (2003). The social construction of meaning: an alternative perspective on information sharing. Information Systems Research, 14(1), 87–106.
Mizzaro, S. (2003). Quality control in scholarly publishing: a new proposal. Journal of the American Society for Information Science and Technology, 54(11), 989–1005.
Norman, D. A. (1992). Design principles for cognitive artifacts. Research in Engineering Design Research in Engineering Design, 4(1), 43–50.
Orsmond, P., Merry, S., & Reiling, K. (2000). The use of student derived marking criteria in peer and self-assessment. Assessment and Evaluation in Higher Education, 25(1), 23–38. doi:10.1080/02602930050025006.
Piaget, J., & Gabain, M. (1926). The language and thought of the child, by Jean Piaget...Preface by Professor E. Claparède. London, K. Paul, Trench, Trubner & co., ltd.; New York, Harcourt Brace & company, inc., 1926.
Pulford, B. D., & Colman, A. M. (1997). Overconfidence: feedback and item difficulty effects. PAID Personality and Individual Differences, 23(1), 125–133.
Raman, K., & Joachims, T. (2014). Methods for Ordinal Peer Grading. arXiv:1404.3656 [cs]. Retrieved from http://arxiv.org/abs/1404.3656
Rittel, H. W. J., & Webber, M. M. (1973). Dilemmas in a general theory of planning. Policy Sciences, 4(2), 155–169. doi:10.1007/BF01405730.
Roos, M., Rothe, J., Rudolph, J., Scheuermann, B., & Stoyan, D. (2012). A Statistical Approach to Calibrating the Scores of Biased Reviewers: The Linear vs. the Nonlinear Model. In Proceedings of the 6th Multidisciplinary Workshop on Advances in Preference Handling. Retrieved from http://mpref2012.lip6.fr/proceedings/RoosMPREF2012.pdf
Ryvkin, D., Krajč, M., & Ortmann, A. (2012). Are the unskilled doomed to remain unaware? Journal of Economic Psychology, 33(5), 1012–1031. doi:10.1016/j.joep.2012.06.003.
Sadler, P. M., & Good, E. (2006). The impact of self-and peer-grading on student learning. Educational Assessment, 11(1), 1–31.
Sage, A. P., & Rouse, W. B. (1999). Information systems frontiers in knowledge management. Information Systems Frontiers, 1(3), 205–219.
Salazar-Torres, G., Colombo, E., Da Silva, F. S. C., Noriega, C. A., & Bandini, S. (2008). Design issues for knowledge artifacts. Knowledge-Based Systems, 21(8), 856–867. doi:10.1016/j.knosys.2008.03.058.
Sargeant, J., Mann, K., van der Vleuten, C., & Metsemakers, J. (2008). “Directed” self-assessment: practice and feedback within a social context. Journal of Continuing Education in the Health Professions, 28(1), 47–54.
Scheff, T. J. (2006). Goffman unbound!: A New paradigm for social science. Boulder, Colo.:Paradigm Publishers.
Schleicher, D. J., Bull, R. A., & Green, S. G. (2008). Rater reactions to forced distribution rating systems. Journal of Management, 35(4), 899–927. doi:10.1177/0149206307312514.
Schutz, A. (1967). The Phenomenology of the Social World. Translated by George Walsh and Frederick Lehnert. With an introd. by George Walsh. Evanston, Ill.:Northwestern University Press.
Schwarz, G. (1978). Estimating the dimension of a model. The Annals of Statistics, 6(2), 461–464. doi:10.1214/aos/1176344136.
Shah, N. B., Bradley, J. K., Parekh, A., Wainwright, M., & Ramchandran, K. (2013). A case for ordinal peer evaluation in MOOCs. NIPS Workshop on Data Driven Education Retrieved from http://lytics.stanford.edu/datadriveneducation/papers/shahetal.pdf.
Sharp, G. L., Cutler, B. L., & Penrod, S. D. (1988). Performance feedback improves the resolution of confidence judgments. YOBHD Organizational Behavior and Human Decision Processes, 42(3), 271–283.
Shepard, L. A. (2007). Formative assessment: Caveat emptor. Erlbaum.
Sieck, W. R., & Arkes, H. R. (2005). The recalcitrance of overconfidence and its contribution to decision aid neglect. J. Behav. Decis. Making Journal of Behavioral Decision Making, 18(1), 29–53.
Sieck, W. R., Merkle, E. C., & Van Zandt, T. (2007). Option fixation: a cognitive contributor to overconfidence. Organizational Behavior and Human Decision Processes, 103(1), 68–83. doi:10.1016/j.obhdp.2006.11.001.
Simon, H. A. (1959). Theories of decision-making in economics and behavioral science. The American Economic Review, 49(3), 253–283.
Simon, H. A. (1969). The sciences of the artificial. The MIT Press.
Simon, H. A. (1973). The structure of ill-structured problems. ARTINT Artificial Intelligence, 4(3), 181–201.
Simon, H. A. (1979). Information processing models of cognition. Annual Review of Psychology, 30(1), 363–396.
Slavin, R. E. (1992). When and why does cooperative learning increase academic achievement? Theoretical and empirical perspectives:Cambridge University Press.
Sluijsmans, D., Brand-Gruwel, S., van Merriënboer, J. J. G., & Bastiaens, T. J. (2002). The training of peer assessment skills to promote the development of reflection skills in teacher education. Studies in Educational Evaluation, 29(1), 23–42. doi:10.1016/S0191-491X(03)90003-4.
Sluijsmans, D., Brand-Gruwel, S., van Merrienboer, J., & Martens, R. (2004). Training teachers in peer-assessment skills: effects on performance and perceptions. Innovations in Education and Teaching International, 41(1), 59–78.
Stewart, N., Brown, G. D. A., & Chater, N. (2005). Absolute identification by relative judgment. Psychological Review, 112(4), 881–911.
Stone, E. R., & Opel, R. B. (2000). Training to improve calibration and discrimination: the effects of performance and environmental feedback. YOBHD Organizational Behavior and Human Decision Processes, 83(2), 282–309.
Surowiecki, J. (2004). The wisdom of crowds: Why the many are smarter than the Few and How collective wisdom shapes business, economies, societies, and nations. New York:Doubleday.
Sutton, D. C. (2001). What is knowledge and can it be managed? European Journal of Information Systems, 10(2), 80–88.
Taras, M. (2002). Using assessment for learning and learning from assessment. Assessment & Evaluation in Higher Education, 27(6), 501–510. doi:10.1080/0260293022000020273.
Topping, K. J. (1998). Peer assessment between students in colleges and universities. Review of Educational Research, 68(3), 249–276. doi:10.3102/00346543068003249.
Topping, K. J. (2005). Trends in peer learning. Educational Psychology, 25(6), 631–645. doi:10.1080/01443410500345172.
Tung, W.-F., Yuan, S.-T., Wu, Y.-C., & Hung, P. (2014). Collaborative service system design for music content creation. Information Systems Frontiers, 16(2), 291–302. doi:10.1007/s10796-012-9346-0.
Uebersax, J. S. (1988). Validity inferences from interobserver agreement. Psychological Bulletin, 104(3), 405–416.
Van Gennip, N. A. E., Segers, M. S. R., & Tillema, H. H. (2009). Peer assessment for learning from a social perspective: the influence of interpersonal variables and structural features. Educational Research Review, 4(1), 41–54. doi:10.1016/j.edurev.2008.11.002.
Van Gennip, N. A. E., Segers, M. S. R., & Tillema, H. H. (2010). Peer assessment as a collaborative learning activity: the role of interpersonal variables and conceptions. Learning and Instruction, 20(4), 280–290. doi:10.1016/j.learninstruc.2009.08.010.
Walsham, G. (2006). Doing interpretive research. European Journal of Information Systems, 15(3), 320–330.
Wang, M. (2011). Integrating organizational, social, and individual perspectives in web 2.0-based workplace E-learning. Information Systems Frontiers, 13(2), 191–205. doi:10.1007/s10796-009-9191-y.
Wang, S.-L., & Wu, P.-Y. (2008). The role of feedback and self-efficacy on web-based learning: the social cognitive perspective. Computers & Education, 51(4), 1589–1598. doi:10.1016/j.compedu.2008.03.004.
Yu, F. Y., Liu, Y. H., & Chan, T. W. (2005). A web-based learning system for question-posing and peer assessment. Innovations in Education and Teaching International, 42(4), 337–348.
Zheng, Z. (. E.)., Pavlou, P. A., & Gu, B. (2014). Latent growth modeling for information systems: theoretical extensions and practical applications. Information Systems Research, 25(3), 547–568. doi:10.1287/isre.2014.0528.
Zigurs, I., & Buckland, B. K. (1998). A theory of task: technology fit and group support systems effectiveness. MIS Quarterly, 22(3), 313–334.
Author information
Authors and Affiliations
Corresponding author
Appendices
Appendix 1: Measurement Operationalization (Single-Group Ranking Model)
Suppose, each peer group consists of N subjects that are indexed i = {1, 2, …, N}. Each subject i rank-orders other (N-1) subjects' Artifacts so that the “best” is ranked 1 and the “worst” is ranked (N-1), that is, here only subject i’s rank-ordering of his peers' Artifacts is considered. The matrix of mutual evaluations of Artifacts produced by the group is
where ranks given are in rows, ranks received are in columns, a ij denotes a rank given by a subject i to a subject j for the Artifact (or, symmetrically, received by a subject j from a subject i). Note that a i = [a i1 a i2 … a ij … a iN ] is a row vector of ranks given by a subject i to all his peers such that
where E j is the indicator function such that
Note that the row vector e = [E 1 E 2 … E N ] is the vector of the indicator function’s values. These conditions constitute the data integrity constraints. The first condition means that a subject i’s assessment of his own Submission is not included in this matrix. The second condition means that each peer’s Artifact, without exceptions, needs to be rank-ordered. The third condition means that rank-ordering is enforced, that is, no two peers' Artifacts may have the same rank. Note that relaxing this assumption allows each Artifact to be rated rather than ranked. The forth condition means that a missing Artifact is given N points.
Suppose C > 1 is the maximum possible attainment score for an Artifact; i.e., the attainment score of C is given to an Artifact that received the rank of 1, and the attainment score of 1 is given to an Artifact that received the rank of (N-1). A failure to submit an Artifact results in the attainment score of 0. Then the following transforms the rank a ij given by a subject i to subject j into the attainment score c ji received by subject j from subject i:
or
For example, suppose N = 6 subjects and C = 5 points. Then, the transformation rule is:
Rank a ij | Attainment score c ij |
|---|---|
1 | 5 |
2 | 4 |
3 | 3 |
4 | 2 |
5 | 1 |
Not submitted (6) | 0 |
The matrix of the individual Artifact attainment scores for the entire group is (scores received are in rows, scores given are in columns)
where scores received are in rows, scores given are in columns,
1 1×N = [1 1 … 1] is the row vector of ones,
c ji = 0 for all a ji = N, and
A subject i’s attainment score for the Artifact is the average attainment score received from all his peers, who submitted their evaluations, ideally (N-1). Hence, the column vector of attainment scores for Artifacts is
where the row vector f = [F 1 F 2 … F N ] is the vector of values of the indicator function F j such that
Hence, the attainment score for the Artifact of subject i is
where \( {{\boldsymbol{c}}_i}_{1\times N} \) is the row vector of Artifact attainment scores received by a subject i.
Subjects are also required to self-evaluate, that is, rank-order their own Artifacts among those of other peers. However, their self-ranking is not included in the calculation of attainment of their own Artifact. The difference between attainment measures derived from self-assessment and peer assessment results is computed as follows. Suppose α i is a rank given by a subject i to his own Artifact, such that α i coincides with one of the values a i . Then, self-evaluation score for Artifact attainment is defined as
and miscalibration, i.e., the difference between the attainment score produced by self-assessment and the attainment score produced by peer assessment) for the Artifact of a student i is defined as
The assessor error (ER) measures a given subject’s divergence from assessments of each peer’s Artifact by the rest of the peer group. Subject i’s assessor error is defined as
where |. | denotes the absolute value operator, and ø denotes an undefined (missing) value (assessor error cannot be calculated if assessment was not submitted). The column vector of assessor error measures is
where |. | denotes the matrix of absolute values of the element-wise differences of the two square matrices (not the determinant of the matrix). In this vector, all elements for which F i is zero are undefined (missing values).
The assessee error (EE) is a measure of divergence among peers in assessing a given subject’s Artifact. Subject i’s assesse error is defined as
The column vector of assesse error measures is
where Q N×N is a square matrix with zeros on the diagonal and ones off diagonal, the operator “°” denotes the Hadamard product of matrices (entry-wise product operator). In this vector, all elements for which E i is zero are undefined (missing values).
The average group assessor error (AGER) is defined as
The average group assessee error (AGEE) is defined as
It can be shown that corresponding AGER and AGEE are equal.
The intra-group inter-observer reliability (IGIOR) for any given group is defined as
where \( \overset{-}{\delta } \) is the AGER of the given group,
\( {\overset{-}{\delta}}_{con} \) is the AGER of the group with the perfect convergence among peers’ evaluations of each other’s Artifacts on the ordinal-scale (relative ranks),
\( {\overset{-}{\delta}}_{div} \) is the AGER of the group with the perfect divergence among peers’ evaluations of each other’s Artifacts on the ordinal-scale (relative ranks).
The IGIOR can be interpreted as how far the given peer group as a whole is from the perfect convergence on ranking each other’s Artifact. For a group with the perfect convergence, the IGIOR is equal 1; for a group with the perfect divergence, the IGIOR is equal 0. Note that since it can be shown that corresponding AGER and AGEE are equal, it does not matter whether either AGER or AGEE are used to compute the IGIOR.
Bias (normalized ER) is the ER adjusted for the chosen values of C so that it ranges between 0 and 1. Bias can be interpreted as a measure of a given subject’s divergence from the rest of the peer group in assessing each peer’s Artifact irrespective of the overall rank of the subject’s Artifact and the maximum possible attainment score.
A given subject i’s bias is defined as
where \( {r}_i \)is the rank of the subject i’s Artifact among the rest of the Artifacts of the peer group based on the Artifact’s attainment score (in other words, \( {r}_i \) corresponding to the larges value in the vector \( \overset{-}{\boldsymbol{c}} \) is equal to 1 and \( {r}_i \) corresponding to the smallest value in the vector \( \overset{-}{\boldsymbol{c}} \) is equal to N);
\( {\delta}_{con}\left({r}_i\right) \) is the ER corresponding to the rank \( {r}_i \) in the peer groups with the perfect convergence (IGIOR y = 1);
\( {\delta}_{div} \) is the ER in the peer groups with the perfect divergence (IGIOR y = 0). In a peer groups with the perfect divergence, all peers have the same ER because no one is better in assessing others than the rest of the group. Computations of \( {\delta}_{con}\left({r}_i\right) \) and \( {\delta}_{div} \) are explained in the appendix 2.
Controversy (normalized EE) is the EE adjusted for the chosen values of C so that it ranges between 0 and 1. Controversy can be interpreted as a measure of divergence among peers in assessment of a given subject’s Artifact irrespective of the overall ranks their Artifacts and the maximum possible attainment score for the Artifact.
Controversy of an Artifact produced by a subject i is defined as
Bias and controversy are recorded in vectors \( \widehat{\boldsymbol{\delta}} \) and \( \widehat{\boldsymbol{\gamma}} \) respectively. Normalization is necessary because while ER and EE are the same for all subjects in the peer group with the perfect divergence (because no one is better in assessing Artifacts than the rest of the group), in the peer group with the perfect convergence ER and EE have non-zero values and are non-linearly dependent on the rank r i of the subject i’s Artifact among the Artifacts of the peer group based on the attainment score. In other words, in a peer group with non-equal attainment scores (that is when at least some convergence exists among peer on the quality of each submission and submissions can be ranked based on the score), each rank position is characterized by a systematic non-zero ER and EE just because of its place in the relative ranking of peers' Artifacts. This is due to the fact that subjects’ own self-evaluations are not included in the computations of the attainment scores. A more detailed explanation of this phenomenon is given below.
This single-groups ranking model can be easily extended to multiple groups.
Appendix 2: Correcting Nonlinearity in Ranking (Computing AGER and AGEE for Peer Groups with Perfect Convergence and Perfect Divergence)
To determine IGIOR, bias and controversy, AGER and AGEE for the extreme special cases of the perfect convergence and the perfect divergence of a peer group need to be computed. In addition, ER for each relative rank position in a peer group needs to be computed for the case of perfect convergence.
First, let us consider the case of the perfect intra-group inter-observer convergence, that is, the summative assessment result for which IGIOR is equal 1. Suppose the row vector s 1 × N = [1, 2, …, N] is the vector of latent ranks of potential attainment (goodness) of a given set of Artifacts. That is, we assume that each Artifact is of such goodness and each subject has such evaluation skills that when asked to rank-order these Artifacts, the subjects come to the perfect convergence on ranking of each Artifact (we also assume that all subjects submit their Artifacts). Under these assumptions, the latent ranks should be equal to the ranks generated by the system, that is s i = r i for all i. However, since each Artifact’s attainment is computed using ranks received from peers (ranging in {1, 2, …, N-1}) and excluding subject’s self-ranking of his own Artifact, despite the perfect convergence each subject will make an assessor error (ER) of a various degree. For example, in a peer group of six subjects, subject 1 will not be able to give his own Artifact the rank of 1 but would have to give it to the Artifact of subject 2. Similarly, subjects 2, 3, 4, and 5 will have to give the rank of 5 to the Artifact of subject 6. Consequently, each Artifact will also bear an assessee error (EE) of varying degree.
The matrix A con of ranks given in a peer group with the perfect convergence is obtained from the vector s by the following transformation
where I N×N is the identity matrix, 1 1×N is a vector of ones,
H 1 N×N is a square shift matrix with all elements equal zero except for elements equal one just above the main diagonal,
H 2 N×N is a square shift matrix with all elements equal zero except for elements equal one just below the main diagonal,
T 1 N×N is a square matrix with all elements in the upper triangle above the main diagonal equal ones and all other equal zero,
T 2 N×N is a square matrix with all elements in the lower triangle below the main diagonal equal ones and all other equal zero, the operator “°” denotes the Hadamard product of matrices (entry-wise product operator).
For the special case of N = 6, the matrix A con looks as follows:
6 | 1 | 2 | 3 | 4 | 5 |
1 | 6 | 2 | 3 | 4 | 5 |
1 | 2 | 6 | 3 | 4 | 5 |
1 | 2 | 3 | 6 | 4 | 5 |
1 | 2 | 3 | 4 | 6 | 5 |
1 | 2 | 3 | 4 | 5 | 6 |
Using the rule for transforming ranks into scores the matrix of scores C con is obtained as
such that
For the case of N = 6 and C = 5, the matrix C con looks as follows:
0.00 | 5.00 | 5.00 | 5.00 | 5.00 | 5.00 |
5.00 | 0.00 | 4.00 | 4.00 | 4.00 | 4.00 |
4.00 | 4.00 | 0.00 | 3.00 | 3.00 | 3.00 |
3.00 | 3.00 | 3.00 | 0.00 | 2.00 | 2.00 |
2.00 | 2.00 | 2.00 | 2.00 | 0.00 | 1.00 |
1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 0.00 |
The column vector of attainment scores for the peer group in the perfect convergence is
The column vector of ER is
where |. | denotes the matrix of absolute values of the element-wise differences of the two square matrices (not the determinant of the matrix).
The column vector of EE is
where Q N×N is a square matrix with zeros on the diagonal and ones off diagonal, the operator “°” denotes the Hadamard product of matrices (entry-wise product operator).
The following table summarizes the attainment, assessor error (ER) and assessee errors (EE) scores for the case of the peer group with the perfect convergence where N = 6 and C = 5:
s = r | \( {\overset{-}{c}}_{con} \) | \( {\delta}_{con}(r) \) | \( {y}_{con}(r) \) |
|---|---|---|---|
1 | 5.00 | 2.00 | 0.00 |
2 | 4.20 | 1.20 | 1.60 |
3 | 3.40 | 0.80 | 2.40 |
4 | 2.60 | 0.80 | 2.40 |
5 | 1.80 | 1.20 | 1.60 |
6 | 1.00 | 2.00 | 0.00 |
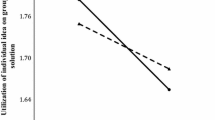
The following diagram graphically represents attainment, ER and EE scores for the extreme special case of the peer group with the perfect convergence where N = 6 and C = 5:

Non-linear Error Behavior in the Perfect Convergence Group (N = 6, C = 5)
Thus, we obtained ER and EE scores for the extreme special case of the peer group with the perfect convergence.
The AGER for the peer groups with the perfect convergence is
The AGEE for the peer groups with the perfect convergence is
For the peer group with the perfect convergence with N = 6 and C = 5, the AGER \( {\overset{-}{\delta}}_{con} \)and the AGEE \( {\overset{-}{\gamma}}_{con} \) are both equal 4/3.
Thus, we obtained values of AGER and AGEE for each relative rank for the extreme case of the perfect convergence.
Now, let us consider the case of the perfect intra-group inter-observer divergence, that is, the result of mutual summative peer assessment, for which IGIOR is equal zero. In this case, the row vector s 1×N = [1, 2, …, N] does not reflect latent ranks of quality of a given set of Artifacts. That is, we assume that each Artifact is of such goodness, and each subject has such evaluation skills that when asked to rank-order these Artifacts the subjects are not be able to converge on the goodness of Artifacts and their ranking, resulting in the perfect divergence on ranking of each Artifact (we also again assume that all subjects submit the deliverable). In other words, the latent goodness of all Artifacts and evaluation skills of all subjects are assumed to be absolutely equivalent/homogenous. Under these assumptions, each subject’s Artifact receives from his peers the entire range of possible ranks, and no one subject is better in assessing his peers than the rest of the group. The matrix A div of ranks given in a peer group with the perfect divergence, therefore, is a Latin square – an N × N matrix filled with integers from {1, 2, …, N}, each occurring exactly once in each row and exactly once in each column. One of the ways such matrix can be constructed is by the Cyclic Method (Bailey, 2008): Place s in reverse order (or \( \left(N+1\right)1-\boldsymbol{s} \)) in the top row of A div ; in the second row, shift all the integers to the right one place, moving the last symbol to the front; continue in this fashion, shifting each row one place to the right of the previous row.
For the special case of N = 6, the matrix A div looks as follows:
6 | 5 | 4 | 3 | 2 | 1 |
1 | 6 | 5 | 4 | 3 | 2 |
2 | 1 | 6 | 5 | 4 | 3 |
3 | 2 | 1 | 6 | 5 | 4 |
4 | 3 | 2 | 1 | 6 | 5 |
5 | 4 | 3 | 2 | 1 | 6 |
Note that for the purpose of obtaining ER and EE scores for the case of the perfect divergence the method of obtaining A div matrix does not matter as long as it is a Latin square with the diagonal elements equal N.
Similarly to the case of the perfect convergence, using the rule for transforming ranks into scores the matrix of attainment scores C div is obtained as
such that
For the case of N = 6 and C = 5, the matrix C div looks as follows:
0.00 | 5.00 | 4.00 | 3.00 | 2.00 | 1.00 |
1.00 | 0.00 | 5.00 | 4.00 | 3.00 | 2.00 |
2.00 | 1.00 | 0.00 | 5.00 | 4.00 | 3.00 |
3.00 | 2.00 | 1.00 | 0.00 | 5.00 | 4.00 |
4.00 | 3.00 | 2.00 | 1.00 | 0.00 | 5.00 |
5.00 | 4.00 | 3.00 | 2.00 | 1.00 | 0.00 |
The column vector of attainment scores for the group in the perfect convergence is
The column vector of assessor errors is
The column vector of assessee errors is
The following table summarizes attainment, bias and controversy scores for the case of the peer group with the perfect divergence where N = 6 and C = 5:
s = r | \( {\overset{-}{c}}_{div} \) | \( {\delta}_{div}(r) \) | \( {\gamma}_{div}(r) \) |
1 | 3.00 | 6.00 | 6.00 |
2 | 3.00 | 6.00 | 6.00 |
3 | 3.00 | 6.00 | 6.00 |
4 | 3.00 | 6.00 | 6.00 |
5 | 3.00 | 6.00 | 6.00 |
6 | 3.00 | 6.00 | 6.00 |
Thus, we obtained values of ER and EE for the extreme special case of the peer group with the perfect divergence. Note that all subjects' submissions in such group are characterized by equal attainment, ER and EE scores.
The AGER for the peer group with the perfect divergence is
The AGEE for the peer group with the perfect divergence is
For the peer group with the perfect divergence where N = 6 and C = 5, AGER \( {\overset{-}{\delta}}_{div} \)and AGEE \( {\overset{-}{\gamma}}_{div} \) are both equal 6.
Thus, we obtained values of AGER and AGEE for the extreme special case of the perfect divergence. The IGIOR for the case of the perfect convergence \( {y}_{con}=1 \) and for the case of the perfect divergence \( {y}_{div}=0. \)
Rights and permissions
About this article

Cite this article
Babik, D., Singh, R., Zhao, X. et al. What you think and what I think: Studying intersubjectivity in knowledge artifacts evaluation. Inf Syst Front 19, 31–56 (2017). https://doi.org/10.1007/s10796-015-9586-x
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10796-015-9586-x