
Abstract
The paper describes our novel perspective on ‘searching to learn’ through collaborative information seeking (CIS). We describe this perspective, which motivated empirical work to ‘orchestrate’ a CIS searching to learn session. The work is described through the lens of orchestration, an approach which brings to the fore the ways in which: background context—including practical classroom constraints, and theoretical perspective; actors—including the educators, researchers, and technologies; and activities that are to be completed, are brought into alignment. The orchestration is exemplified through the description of research work designed to explore a pedagogically salient construct (epistemic cognition), in a particular institutional setting. Evaluation of the session indicated satisfaction with the orchestration from students, with written feedback indicating reflection from them on features of the orchestration. We foreground this approach to demonstrate the potential of orchestration as a design approach for researching and implementing CIS as a ‘searching to learn’ context.
Similar content being viewed by others

1 Introduction
Although information seeking is very common across a range of contexts, students—across a broad range of ages—experience difficulties with these tasks (Walraven et al. 2008). Of course, a part of this concern regards the skills that students have regarding the technical aspects of information seeking—the use of Boolean operators, database selection, and so on. However, more than this, the concern is that these skills of information seeking are bound up with complex literacy skills; that mature internet use involves skills of sourcing, corroborating, and integrating of claims (Rouet 2006) from across the web of complex documents and multi-media resources. The learning sciences have thus increasingly turned their attention to students practices of seeking and processing information (Barzilai and Zohar 2009, 2012; Bråten and Samuelstuen 2007; Bråten and Strømsø 2006; Chiu et al. 2013; Ferguson et al. 2013; Hofer 2004; Hsu et al. 2013; Hsu 2014; Lin and Tsai 2008; Singh et al. 2013; Tsai et al. 2012).
In this paper, we first outline our perspective on ‘searching to learn’, moving on to particularly flag the potential of collaborative information seeking task-contexts as sites of collaborative learning. We then present a particular learning context, in which a tool (Coagmento) was implemented to support learning, describing how the search system features, along with a designed work-context, foster learning. In this paper we focus on the ways in which ‘searching to learn collaboratively’ were orchestrated through the adaptation and adoption of the tool for the pedagogic purpose We do this through the framework of orchestration, an approach to technology-enhanced learning-design which: makes explicit the relationship between ‘background’ features (including theory, and the practical context of our work), ‘actors’ (those involved in the research), and ‘activities’ (the tasks undertaken in the research, and their particular design). An orchestration approach places particular salience on real-world contexts, and purposes, highlighting the significance of learning-design for understanding ‘searching to learn’ contexts. In taking an orchestration approach, rather than presenting empirical results indicating learning change, our specific aim is to flag broad principles regarding the application of search technologies to learning contexts, rather than taking such technologies to be ‘finished products’ absent of pedagogic context. That is, the aim of this paper is not to present the empirical results of a research study. Rather, it is to describe the novel application of a design process (orchestration) to a ‘searching to learn’ context that is specifically grounded in a collaborative pedagogic model. This application is discussed with reference to evaluation of the student’s experiences, and reflections from other key actors in the orchestration process.
1.1 Information seeking as learning
Earlier work (Marchionini 2006) considering the kind of search that could be characterized as ‘searching to learn’ noted that the type of information being sought and its purpose play key roles in the learning potential of search. Fact retrieval or ‘lookup’ searches provide different potential for learning than does ‘Learn’ and ‘Investigate’ search—search that is characterized as exploratory. In these exploratory searches, one must not only find an answer (precision oriented search), but find, compare, and evaluate information (more recall oriented search) (Marchionini 2006). Indeed, these distinctions can be associated with Bloom’s taxonomy (Bloom 1956)—a tool commonly used to analyse a hierarchy of question types in educational contexts. For example, relatively lower level questions, such as ‘where were the 2012 Olympics held?’ can be associated with precision-oriented ‘lookup’ searches (Marchionini 2006). In contrast, higher levels of Bloom’s taxonomy can be associated with exploratory search, involving iterating through searches and resources, managing multiple sources (of varying qualities), and comparative judgement of those sources (Marchionini 2006).
Much of the search time in learning search tasks is devoted to examining and comparing results and reformulating queries to discover the boundaries of meaning for key concepts. Learning search tasks are best suited to combinations of browsing and analytical strategies, with lookup searches embedded to get one into the correct neighborhood for exploratory browsing (Marchionini 2006, p. 43).
Exploratory searches, then, “support learning [and] aim to achieve: knowledge acquisition, comprehension of concepts or skills, interpretation of ideas, and comparisons or aggregations of data and concepts” (Marchionini 2006, p. 42). It is this type of search that we particularly focus on in this paper.
In thinking about ‘search’, then, we have come to think not only of learning to search—i.e., induction into the skills and knowledge to work with search engines and other systems to find information—but also searching to learn. Moreover, we intend not just that consideration be given to the content being learned through a lookup-search process: i.e., that in searching for information on flu shots, one comes to plug a defined information need on that topic. Instead, we argue that through searching students can engage in processes beyond verification of uncontentious facts, and into more socio-cultural processes and perspectives on literacy in which knowledge is constructed in negotiation with a particular social and information context (Knight and Littleton 2015; Sundin and Johannisson 2005). In our view, this richer conception of search as learning is fundamentally social in nature, studied well through the lens of collaborative information seeking (CIS).
1.2 Collaborative information seeking as learning
A particular focus of our own interest has been in the role of collaboration, as entwined with ‘searching as learning’. This has particular salience given that, in self-report surveys, CIS is flagged as a prominent phenomenon in educational contexts (Amershi and Morris 2008; Ba et al. 2002; Livingstone et al. 2005; SQW 2011). However, while CIS may be common in classroom and other learning contexts, it has been understudied in action, and thus its potential in high quality collaborative learning may be unmet (Knight and Littleton 2016). Thus, information seeking goes beyond individuals as searchers both in that it involves more complex information practices than query-response search systems, and insofar as:
when we seek information, particularly on the web, we engage with a network of linked documents with a rich set of intertextual ties; in a very real sense, reading much of the web involves an interaction with the thoughts of many people. (Knight and Littleton 2015, p. 5).
Collaboration in information seeking thus offers potential to expose students to a range of resources, and perspectives on them, both through their analysis of web-based media and through high quality dialogue which has a strong relationship to learning outcomes. In the extant literature, the ways in which collaborative dialogue is used are noted, for example: following the retrieval of results, but without analysis of the role of dialogue in building shared knowledge (Yue et al. 2012); in dividing labor (Shah 2013); in understanding communication patterns but not content (via a count of messages sent) (Shah and Marchionini 2010); in understanding the stage of the search process a pair has reached (Shah and González-Ibáñez 2010).
However, as Hertzum (2008) notes, dialogue plays a crucial facilitative role in information seeking activities motivated towards shared knowledge accumulation, suggesting further potential for analysis of this dialogue. Hertzum thus suggests that, as collaboration becomes closer, the shared language and knowledge should become closer, while in looser collaboration there may be more temporary and effortful attempts to maintain this common ground. Indeed, this collaborative dialogue is present not only at the traversal or evaluation stages of information seeking, but in defining the information needs too (Hyldegård 2006, 2009).
It has thus been proposed that collaborative dialogue might address the challenges that students face in information seeking tasks in which they may be “largely unable to select appropriate search strategies (planning), check their progress (monitoring) and assess the relevance of search outcomes (evaluating)” (Lazonder 2005, p. 466). In that classroom based study, 20 pairs of students (with a mean age of 20) engaged in an information seeking task, in which Lazonder proposed that verbalization might support self-regulation, and search-negotiation. Indeed, Lazonder found that paired participants did better and worked faster, using more sophisticated search strategies. In work developing this line of research (Knight 2012; Knight et al. 2014; Knight and Mercer 2015, 2016) we have explored this collaborative dialogue in classroom contexts, finding that success in information seeking was related to the kind of dialogue the students engaged in, despite their similar levels of prior academic attainment. As Kuiper et al. (2009) note, “…the conditions for students working collaboratively [in information seeking] deserve attention. Our results confirm the importance of collaborative inquiry activities being more than just ‘working together’”, suggesting that successful groups, “showed students who helped each other, who knew what everyone else was doing and who all shared the same goals. This resulted in a high motivation and an accumulation of knowledge.” (Kuiper et al. 2009, p. 679).
2 CIS orchestration and orchestrable technologies
There is thus a need to consider the means through which ‘[collaborative] searching to learn’ might be supported. That need goes beyond an analysis of tools or systems available to support collaboration. Instead, what is needed is an approach to deploying these tools within practical learning contexts that support the pedagogic aims of the searching task. Thus, in this paper, we describe a particular tool alongside how it has been deployed in a pedagogically motivated context, through the lens of orchestration:
‘the process of designing and managing in real-time (including awareness and adaptation mechanisms) the learning processes in an authentic computer-supported learning scenario’. The responsibilities in this process are shared among a number of actors, depending on the context (teachers, students, researchers or technologies), who aim to pragmatically align the context’s background elements (constraints, resources) towards a satisficing effect, shaped by their mental models, their theories and beliefs. (Prieto et al. 2015, p. 12).
The lens of orchestration provides a useful perspective on CIS because developing approaches to CIS in education is not simply a matter of providing a pedagogic instruction (qua “collaborate on this search”), nor tool (qua “use this tool to research…”), but an alignment of tool, situation, and pedagogy—this context is crucial to understanding CIS in learning contexts (Newman et al. 2016). For example, understanding the desired learning outcomes is important in understanding the potential of CIS for learning. As Shah notes:
…if two people working together can find twice as much information as either of them working independently, was that a good thing? How about the amount of time they spent cumulatively? The participants may not be able to find twice as many results, but what if they achieved better understanding of the problem or the information due to working in collaboration? Then there are other factors, such as engagement, social interactions, and social capital, which may be important depending upon the application, but are usually not looked at in non-interactive or a single-user IR evaluations. (Shah 2012a, pp. 115–116).
Thus far CIS tools have largely been described in terms of their awareness and communication features, with little discussion given to the wider context of orchestration. As Prieto et al. (2015) highlight, consideration of these issues is crucial for developing an understanding of how learning technologies might be successfully adopted by individual learners and institutions. Yet this context is crucial for the success of understanding a system’s role in ‘searching to learn’, beyond implementation within the scope of any particular experimental study. Prieto et al.’s model of orchestration thus took a consensus approach, putting forward a model that was evaluated by a panel of learning technology experts and revised based on this evaluation to focus on the key considerations in designing and evaluating learning technologies.
In characterising ‘orchestration’, Prieto et al. (2015) thus build on Prieto et al.’s (2011) review of the literature and conceptual framework in which eight aspects were identified: five characterizing orchestration; and three characterizing key contextual factors in orchestration. As Prieto et al. (2015) note, the five characterizing aspects are:
-
Design: the preparation and organisation of learning activities (often performed by a teacher) before their enactment. This aspect is clearly linked to instructional and learning design research.
-
Management: the many forms of coordination that take place during the enactment of the learning activities: classroom management, time management, group management, workflow management, and so on.
-
Awareness: the perceptual processes aimed at modelling what is happening in the learning situation, for example, students’ learning progress and actions: teacher monitoring, formative and summative assessment, peer awareness, and group awareness.
-
Adaptation: the interventions or adaptations to the designed/planned learning activities, to cope with unexpected or extraneous events, take advantage of emergent learning opportunities, or adapt to student learning progress.
-
Role of the teacher and other actors: the identification of who performs the previous four aspects, and what the relationship is between the actors (e.g. a teacher, a technological system, students themselves, and researchers).
(Prieto et al. 2015, p. 4).
With the three key contextual factors described as:
-
Theory: the mental models that different actors have about how the scenario should be orchestrated: teachers’ pedagogical beliefs, attitudes and ideas about ‘what works’ in the classroom, researchers’ own models and theories, and even student’s internal models of how they should work within the scenario.
-
Pragmatism: the intrinsic and extrinsic contextual constraints that the actors have to cope with—compliance with the mandatory curriculum, limited amount of time available for a lesson, need for discipline in the classroom, available economic resources, and so on.
-
Synergy: how the multiple elements present in the scenario (new technologies and legacy tools, learning activities at different social levels, students’ prior knowledge and learning styles) can be aligned by the orchestrators to achieve effective learning.
(Prieto et al. 2015, pp. 4–5).
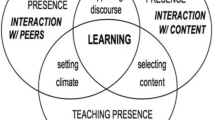
They thus propose a conceptual framework, depicted in Fig. 1 and addressed in the following sections.

Revised conceptual framework for orchestration in learning technology research (Prieto et al. 2015, p. 12)
Figure 1, for orchestration comprising: “activities that orchestration entails, actors that perform these activities and background that shapes the way orchestration is performed” which can “then be aligned with the intention of achieving the desired learning effect.” (Prieto et al. 2015, p. 11). In this model, then, one way to consider that alignment is in terms of each level of the model being ‘grounded on’ the lower level. In the following sections, then, we describe how the background context of the orchestration, the particular actors involved, and activities developed are each drawn into alignment.
2.1 Background—describing the orchestration context
2.1.1 Theories, models, and beliefs: literacy and epistemic cognition
Dealing with the kinds of dynamic texts encountered on the internet is a core component of literacy “Reading literacy is understanding, using, reflecting on and engaging with written texts, in order to achieve one’s goals, to develop one’s knowledge and potential, and to participate in society.” (OECD 2013, p. 9). The research undertaken for this paper was conducted in the context of an increasing focus of both educators and students on web-based materials, with a particular theorized construct identified as the lens through which to view the activity in this CIS context: epistemic cognition. Students’ epistemic cognition (for an early review, see Schraw 2001, and more recently, 2013) can be conceptualized as the lens through which students understand the information they require in order to answer any particular question, thus, these cognitions “are a lens for a learner’s views on what is to be learnt” (Bromme et al. 2009, p. 8). The seeking of particular claims and sources, their selection, and evaluation can be seen under this lens of epistemic cognition—beliefs about knowledge and knowing—brought to bear on information, and its relevance to particular tasks (Bromme et al. 2009), typically characterized as in Table 1.
Epistemic beliefs are particularly salient in information seeking, with teachers with more advanced beliefs utilizing more sophistication in their approaches to search tasks (Tsai et al. 2011), and students with more advanced beliefs engaging in more reflection regarding these beliefs in online information seeking (Mason et al. 2011). Specifically, those students with more advanced beliefs gather more trustworthy sources (Anmarkrud et al. 2014; Strømsø et al. 2011), and are more likely to focus on—and sense-make around—reliable sites than unreliable (Goldman et al. 2012).
With recent increases in use of technology across education, there has been growing interest in the analysis of digital traces generated through use of technologies to investigate learning (R. Ferguson 2012), although little of the epistemic cognition work has taken such an approach (for exceptions, see for example, Dimopoulos and Asimakopoulos 2010; Greene et al. 2010; Hsu et al. 2013; Hwang et al. 2008; Lin and Tsai 2008; Tseng et al. 2009). Given the potential of trace data for analysis of processes of epistemic cognition, processes well foregrounded in our dealings with information (Hofer 2001), the work described in this paper thus aimed to investigate the particular construct using a pedagogically grounded task, and a technology to support, and gather data on, work on that task.
2.1.2 Background requirements for a tool design
As noted in the introductory sections, a particular focus of our theoretical context is the potential of exploratory, collaborative, information seeking for learning. This search context should be drawn into alignment with the epistemic cognition construct. As such, a tool was required that would facilitate a CIS process, tracking trace data for the analysis of processes of epistemic cognition. These requirements included that students should be able to discuss (via a chat) the materials they encounter, that the tool would track their query and page browsing, and that they would be able to write a shared written report analysis as a ‘final product’.
A tool was thus required to support the CIS process. Several such tools exist, focusing variously on: algorithmic mediation of search results based on collaborator activity (for example, most recently, Böhm et al. 2016; and, FXPAL’s Cerchiamo Golovchinsky et al. 2008; and Querium Golovchinsky and Diriye 2011); awareness of searches conducted in a classroom environment via displaying the queries on a shared screen (ClassSearch, Moraveji et al. 2011; and SearchParty, Gubbels et al. 2012); recommender systems for queries and bookmarks based on collaborators investigating similar topics (in programming) (Bateman et al. 2013); and the support of co-located collaborative search (CoSearch, Amershi and Morris 2008).
None of these tools provided the orchestration possibilities required in the context of this study, involving a synchronous collaborative classroom-based task, with a shared artefact (written report) produced, and collaborators working on separate computers. The extant literature highlights two key features for tools in such contexts: awareness, and communication features.
AwarenessFootnote 1 refers to collaborator’s awareness of each other’s activities and resources in their “searching and sense-making processes, including the task and its context, past and present actions, and various attributes of the information objects and the system” (Shah 2013, p. 3). Shah (2012a) thus proposes a taxonomy addressing four kinds of awareness building on established work (Liechti and Sumi 2002). The first—group awareness—concerns awareness of the group members’ activity and status; the second—workspace awareness—concerns a space to share and create a common product; the third—contextual awareness—concerns the task-context and the needs imposed by that context; and the final—peripheral awareness—concerns the awareness of the individual and collective’s information history, i.e., what they have viewed and done previously.
These awareness features may mitigate problems, such as redundant work, seen where users are asked to search in ‘parallel’ using separate computers, but without awareness tools (Amershi and Morris 2009). These awareness features have thus been implemented into search tools. For example, SearchTogether (Morris and Horvitz 2007) and its extension, CoSense (Paul and Morris 2009), included features that foregrounded the query histories, page views, and comments/ratings on those pages, by collaborators. In addition, an instant messaging communication feature could be used to support collaborators in dividing their search tasks, with participants preferring this additional communication tool to automated means to divide searches (splitting search results pages, or giving different search engines to each participant in pair).
Similarly, Shah and Marchionini’s (2010) lab-study explored two awareness conditions in a task involving finding snippets related to a particular problem. A baseline group were given a chat tool, with no other communication or awareness features; one condition then also had an awareness feature indicating their own history of queries made and links clicked, while the other could additionally see the history of queries made and links clicked by their partner. That research indicated that the combination of communication and group-awareness features in the third condition resulted in more unique queries and engagement (Shah and Marchionini 2010), a claim supported by (Shah 2013).
That research has a continuing development in the browser add-on ‘Coagmento’ (Shah 2010; Shah et al. 2009). Coagmento integrates instant messaging (IM), shared query and page history, and annotations into a browser add-on, along with a shared document space/editor in which users may engage in collaborative writing. While each of these features might be independently adopted (for example, via the use of google docs), their integration into a single tool provides for an integrated experience by the end user, and a single database for the analyst. Moreover, work on this tool reports positively on user experiences (Shah 2012b), with the tool used extensively in research contexts, including the research described in this paper.
2.1.3 Institutional and cultural context and constraints
The study took place at the Maastricht University School of Business and Economics, during skills sessions for a first year Quantitative Economics class. This school is highly selective, with a strong international representation in the student body (over two thirds of the cohort from an international background, mostly European), and English as the primary language of instruction. It also employs a student-centred learning approach called “problem-based learning” (PBL). As PBL involves small-group collaborative learning on open-ended problems, these students are familiar with the use of collaborative learning activities such as those used in this research. This method of curriculum design has demonstrated outcomes, with student’s appreciating the style of learning, and gaining improved inter-personal skills for such tasks (H. G. Schmidt et al. 2009).
There were a number of stages to the study. In a pre-lab task participants completed a survey item (the Internet-Specific Epistemological [Beliefs] Questionnaire—ISEQ Bråten et al. 2005; Bråten and Weinstein 2004) providing data regarding their epistemic-beliefs. The primary tasks, comprising survey items and collaborative task, took place in a computer lab within the School of Business and Economics—the lab-session. The main task was a collaborative information seeking task involving dyads and triads searching for information on the web and co-authoring a report. At this stage the survey items regarding participant demographic features, and a set of feedback questions regarding the in-class task were completed. A final component involved an ‘at home’ task, comprised of an assessment task and a post-task feedback survey, which were to be completed at a location convenient for the individual participant.
2.2 Actors—Who was involved in the orchestration activities?
As detailed in Table 2 the study described was conducted by researchers collaborating with an academic-educator at a separate institution (Maastricht University), who led the teaching context into which the research was placed. Students participated on an opt-in basis, for dispensation on one of the weekly tasks within the course; students who chose not to participate in the study completed the regular assignment.
The researchers were from two separate institutions—with one team leading the development of the project and its theorization (‘researchers’), and the other modifying a developed tool and implementing the study design through an online platform (‘technology researchers and developers’). Within the class context the primary researcher was present in all sessions, with teaching assistants facilitating the class process. As such, the primary actor—and mode of orchestration—was the tool. The researchers thus required negotiated access both to the class-context, and to facilitate the setup of the lab-PCs (via the university’s IT support team). The tool—comprising a browser add-on and website (described further below)—thus became the key target in discussions regarding in the research process, and in the classroom-research itself.
2.3 Activities—describing the activities being orchestrated
The technologies were designed to route students through the core activities, following a process as indicated in Table 3.
2.3.1 Pre-lab
Participants in this study were in a cohort of students who have, in advance, consented to use of their educational data, in an anonymous format, for educational and research purposes, a process described in Tempelaar et al. (2012, sec. 3.2–3.3); specifically consenting to analysis of self-report questionnaires or psychometric instruments and educational outcomes. Students provide consent that data collected through surveys and lab activities are used for three purposes: building an individual data set for doing an end-of-the-course statistical project; evaluating and improving the educational design; and conducting educational research (common procedure for applying learning analytics in line with the national privacy guidelines). In addition, participants were: informed in advance a week prior of the study; given a briefing at the beginning of the study-session; and given both a paper description and full online consent form for further detail. All procedures and materials were negotiated with our collaborator and gatekeeper at Maastricht University. Prior to the class session, the students were informed of the research taking place, and what it would involve. At this time, a computer lab at Maastricht University was selected, and Firefox (Mozilla 2014) installed along with the customized Coagmento browser add-on (Shah 2014). Participants also completed some survey items (including the ‘ISEQ’ indicated in in Table 3).
2.3.2 Lab session
Before each individual study session, PCs were logged on to a generic logon, with Firefox open, and on the ‘login’ page for the study. The browser cache was cleared and any extra windows or programs open closed. Each PC also had a paper copy of core instructions, and the times for each task were written on a board at the front of the room for researcher and participant reference. Those times are given in Table 4.
Each session was facilitated by the researcher, and one lab assistant. The lab assistants were final year undergraduate students at Maastricht who are paid to assist in computer-lab sessions; because lab assistants rotate through sessions, occasionally two lab assistants would be present for part of any given session. At the start of each session, the lab-assistant outlined the context of the research study, and introduced the primary researcher to the class. The lab assistant reminded students they could participate in one of two tasks—the research task described in this paper, or an optional alternative task—and gave any other course notices. The lab assistant also reminded students to primarily work in English (which is the student’s usual practice at Maastricht). The primary researcher then introduced the study in more detail, noting the three tasks—a warmup, the main task, and the at home assessment task—and surveys to be taken. It was highlighted that the tasks would likely be in an area the students knew little about, but that this choice was deliberate, to see how people use tools to find and evaluate information together, and that hopefully the information would be novel and interesting to the students. It was also noted that they might feel like there was more information than they could deal with in the time alloted; again this was flagged as an intentional feature of the task, noting that the participants might need to make decisions about what resources to focus on. Students were told they would be asked to search the internet for resources. It was indicated that the research interest was in how people find and evaluate information together and using a tool to help support that. At this stage and throughout the session participant questions were answered with reference to the provided text instructions. Periodic software issues in the session were dealt with by refreshing the sidebar, or instructing the participant to click ‘home’ to reset the browser add-on and reload the active task.
Following the introduction to the session students were given logins for the research-website, using separate PCs (seated roughly back to back), with a userID (used as the primary identifier throughout the research) and simple password; as part of the login process students gave their Maastricht student ID twice (matched to ensure no typographical errors). On login participants were instructed to read a briefing sheet and tick a box to confirm consent to participate, and then to make use of the instructions to continue on the tasks. Consent granted permission to Maastricht University to share data with the Open University team, and incorporated the standard terms of use of Coagmento (http://www.coagmento.org/terms.php) including the collection of browser-data (which was specifically verbally noted, separately included in the consent details, with a link to the Coagmento terms also provided).
Once participants had passed the consent pages, the first task presented was a ‘warmup’ task—three short fact-retrieval questions as indicated below—proving a period in which partners could familiarize themselves with the tool and each other. For this warmup task, each question for each pair was populated with a randomly selected country from a pre-created list, to minimize the risk of copying the answers of those seated nearby.
Please type the answers to the following three prompts in your Task Pad (click in the bar at the top of the browser). You may use the internet to find the answers.
-
In 2010 what was the educational expenditure per primary student in [XXX] as a % of GDP?
-
In 2010 what was the total health expenditure as a % of GDP in [XXX]?
-
How much (in US dollars) does a big mac cost in [ZZZ]?
If you find the warmup taking too long (over 10 min) but you feel you’re now comfortable with using Coagmento, you should move on to Task 1.
During this slot, the lab assistant and primary researcher addressed any queries, and assisted participants in identifying the various functions of Coagmento and the research-website. Specifically, participants were reminded to open their sidebar to view the ‘chat’ and queries of their partner, shown where the ‘task pad’ was located to write their answers, and shown the ‘home’ and ‘active task’ buttons so they could get back to the question prompt. The task pad was pre-populated with some guidance text for its use. Towards the end of this slot the ‘submission’ button was highlighted to participants, noting that both partners in the team would need to click ‘submit’ in order to move on to the main task. Participants were given a 3 min warning, and encouraged to submit after 10 min on this task. The researcher and lab assistant ensured all participants started the main task with minimal difference, and participants spent approximately 45 min on this task, receiving a 10 min warning before the end of that slot. The session ended with a short (less than 10 min) exit questionnaire. At the end of each session the procedure described above was followed to setup for the following group.
2.3.3 Task design
The extant literature in collaborative information seeking, and epistemic cognition, has tended towards pre-assigned tasks which cover particular aspects of topics or attend to a particular range of sources—for example involving finding as much information on a particular theme as possible (but with little analysis of that information), or selecting information from pre-assigned sources of varying quality. A key distinction emerging from the epistemic cognition literature is between ‘summarizing’ and ‘argument construction’ tasks—i.e., tasks in which participants must summarize documents, versus those in which they must build an argument around them (Bråten and Strømsø 2009). Relatedly, in the information seeking literature, a systematic review of the literature (Wildemuth and Freund 2012) on eliciting exploratory search notes suggests some key lessons for task design:
-
1.
Tasks should be focused on learning and investigation.
-
2.
Context and situation should be specified but the topic or request may introduce enough ambiguity and open-endedness to produce exploratory behaviors.
-
3.
Multiple facets should be included in the task and search topic.
-
4.
Possibility for eliciting dynamic and multi-stage search should be considered; in some cases tasks can be written to provoke this, but this will not always be the most appropriate approach.
-
5.
Data collection and evaluation should be aligned with the goals of the task
These lessons provide key context for orchestrating learning episodes in search contexts. In the research described in this paper two themes were selected: One using multiple pre-selected documents (the MDP task), and the second involving searching for information on the internet (the CIS task). Topics with conflicting perspectives and a variety of source-qualities were sought to foreground participant’s commitments to varying source-content qualities. A topic was identified which:
-
1.
Provided a focused topical research area which could be studied in isolation, within a 1 h session;
-
2.
Was not a topic that was high profile or/and large scale controversies (such as climate change, or genetically modified crops, both of which receive a lot of press coverage);
-
3.
Had a variety of source-types and qualities referring to it, from varying perspectives.
The topic of ‘red yeast rice’ was selected based on its presence under the sub-category of ‘Medical controversies’ in Wikipedia’s Scientific controversies category. This case was identified as interesting because:
-
1.
Using search engines to seek information on health issues, such as use of food supplements, is a common issue (See, for example: use of Wikipedia, Heilman et al. 2011; survey data, Horgan and Sweeney 2012; and log data, Schmidt 2012) and requires evaluation of claims from across various types of sources;
-
2.
The Wikipedia article on ‘red yeast rice’ is not particularly high quality (it is rated ‘b-class’ in the ‘alternative medicine WikiProject’ quality scale). Monascus purpureus (its scientific name) does not receive a rating on any relevant scientific or medical WikiProject scales (but is a stub article, i.e. it is very short);
-
3.
Search engine results pages show varying results for queries on ‘red yeast rice’ and monascus purpureus;
-
4.
The controversy is largely around restrictions and side effects (i.e. it is uncontroversial that the substance has a medical effect, although risks and scope of those effects are disputed).
Further research indicated a range of materials published on the topic, with three key themes identified (that red yeast rice should be treated as a statin; second that the concentration levels of the active ingredient vary; and third that some samples have been contaminated with citrinin). Again, the potential set of documents participants might encounter in researching the assigned topic offers conflicting information from sources of varying quality, with a range of sub-topics present. As such, the topic provided offers a good seed for probing students’ abilities to extract, integrate and evaluate information from across sources.
In prior work (Anmarkrud et al. 2014; Bråten et al. 2014) students were given six texts to read (on the cancer-risks of mobile phones) with conflicting perspectives and varying source-feature trustworthiness, with the framing prompt to:
The participants were instructed to read the six ‘search results’ over 40 min, in order to provide their friend with “well-grounded advice”. They were then given an essay prompt, to address in 20 min, without access to the source-documents:
You are now going to write a brief report where you judge the health risk of cell phone use. Base your report on the texts that you just read and try to express yourself clearly and elaborate the information—preferably in your own words. Justify your conclusions by referring to the sources you have been working with. (Anmarkrud et al. 2014, p. 4; Bråten et al. 2014, p. 15)
Building on the task design used in that research, the task prompt for the research was written to foreground student’s understanding of knowledge claims, and support for those claims. For example whether they corroborated, emphasized source features and source-credibility, or evaluated source-content and methods used in sources. Thus, students were not asked to “refer to the sources you have been working with”, but instead asked to “Produce a summary of the best supported claims you find and explain why you think they are.” The aim of these instructions is to guide the participants in their task, encouraging them to explain their decision processes as they go, while not directing them in particular to either sourcing via corroboration or authority (and explanations thereof). The text below thus gives the full task instructions used in the research: For this task you will be researching the safety of ‘Red Yeast Rice’
For this task you will be researching the safety of ‘Red Yeast Rice’
Your task is to act as an advisor to an official within the science ministry. You are advising an official on the issues below. The official is not an expert in the area, but you can assume they are a generally informed reader. They are interested in the best supported claims in the documents. Produce a summary of the best supported claims you find and explain why you think they are. Note you are not being asked to “create your own argument” or “summarise everything you find” but rather, make a judgement about which claims have the strongest support.
You and your partner should work together to find relevant materials on the internet. You should:
Read the questions/topic areas provided, these will require you to find information and arguments to present the best supported claims, you should decide with your partner which are best as you read.
Group information together by using headings in the Editor
You should work with your partner to explain why the claims you’ve found are the best available
You should spend about 45 min on this task
The official has heard that French officials have raised some concerns about the safety of ‘Red Yeast Rice’ and potential contamination, and would like a briefing on its potential risk.
2.3.4 Post-lab
At the end of the lab-session week, all participants were emailed (by the course leader and Maastricht collaborator) with a link to the second (at home) task, and asked to complete it within a week. This task involved logging in (using their Maastricht student ID), completing a training exercise or diagnostic assessment, followed by marking two peers’ outputs in sequence, and then finally marking their own collaboratively authored output (self-assessment). This was followed by a short feedback survey, after which participants were thanked for taking part, and informed all tasks had been completed.
Following the second task, all participants were sent a debrief sheet giving further details of the study and inviting them to contact the researcher if they had any further questions. They were also sent a link to access the feedback from the assessment exercise at this time, and informed that they should contact the researcher or course leader if any feedback was inappropriate.
3 Orchestrating CIS through use of a software tool
Coagmento was used to orchestrate the collaborative searching to learn process in this research. Coagmento was designed with CSCL and CSCW literature in mind in addition to the CIS requirement that it support the logging and sharing of search queries, aligning well with the orchestration background requirements noted above. As indicated in Fig. 2, Coagmento thus comprises: a query logger; a bookmark and ‘snippet’ tool to clip and share short website excerpts; a ranking tool to rank queries and bookmarks; tagging for bookmarks; a chat tool. In the standard version of Coagmento, these datasets are associated with ‘projects’ that users may join and leave. However, these projects may be pre-created and populated with group members, such that on logging into Coagmento the users are assigned to groups with access to only a single default project (a key orchestration feature for this research). In addition to the end-user data as described, Coagmento tracks page views during browsing, and text copied within the browser (thus meeting a key contextual factor: research projects require access to data for analysis).

Coagmento Screenshots (from top: a A full screen display from a browser window; b The tool bar element; c Sidebar with Chat displayed; d Sidebar with Snippets displayed)
In order to deploy the study, a website was designed to guide participants through each stage—from logging in at the start of the lab-session, to completion of the at home task. For the lab-session, students were required to login to the website, and could then make use of a browser add-on (Coagmento) which was required for some stages of the task. The add-on consisted of a toolbar (along the top of the browser screen), and a sidebar (along the right-hand side of the browser screen). Functions in this add-on became active/inactive depending on the task-stage. For the at home element students were not required to use the browser add-on (and could use the browser of their preference), simply logging into the website using their student ID instead. The modified version of Coagmento thus provided:
-
1.
A set of menus via a toolbar, as in Fig. 2b:
-
a.
‘Home’ which takes participants back to the main introductory page (from which they can navigate forward)
-
b.
‘System Guide’ which gives participants some instructions on using Coagmento
-
c.
‘Snip’ which allows participants to create a shared copy of any “snipped” text from a webpage
-
d.
‘Task pad’ which takes participants to the shared editor for the task-stage they are at
-
e.
‘Active Task’ which opens a popup of the instructions for the stage they are currently on
-
a.
-
2.
A set of interaction interfaces via a sidebar, as in Fig. 2c, d:
-
a.
A ‘Chat’ tab for the collaborators within any group, automatically using and storing their Coagmento login usernames
-
b.
A ‘History’ tab, which displays the searches and snippets of the user and their collaborator (note only ‘Snippets’ are displayed in Fig. 2c, in the live version the Sidebar displayed ‘Searches’ as default, with ‘Snippets on an additional tab next to it)
-
c.
A ‘Submit’ button, used to submit the answers at the end of the warmup and main task—the button asked participants to confirm with their partner (in the chat) and once confirmed, the page would reload with the subsequent task displayed.
-
a.
4 Evaluating the orchestration of CIS
A number of approaches were taken to evaluate the orchestration of this collaborative information seeking for learning session. Importantly, while prior work has tended to focus on surface-level outcomes such as the number of results found, or chat messages exchanged, in learning contexts features related directly to learning artefacts or processes should be assessed (Knight 2015). The primary analysis of these features is reported elsewhere (Knight 2016; Knight et al. 2017), indicating that although differences could be identified in both process and quality of artefact produced between the pairs, drawing relationships between log-data analyses and artefact-outcomes was challenging.
In addition to explicit evaluation of the learning artefacts, students also completed a feedback evaluation of their experience in the orchestrated tasks, as indicated in Table 5. Analysis of this data shows generally positive levels of satisfaction regarding the collaboration, with a more neutral response to the task generally, and the browser add-on. Across all measures, large standard deviations can be observed (from 1.94 to 2.11), implying group differences in responses to the questions.
Correlational analysis, reported in Table 6 (using Pearson’s method) on pair-mean scores (i.e. the average ratings given to, for example, task satisfaction) and individual scores indicated relationships between:
-
task satisfaction and ratings of browser add-on intuitiveness, suggesting that those who found Coagmento more intuitive to use also found the task more satisfying;
-
collaborative satisfaction and task satisfaction, suggesting that those who found the collaboration more satisfying also found the task more satisfying (or the converse) perhaps because their collaboration increased task satisfaction, or because those more satisfied with the task were more likely to engage in satisfying collaboration;
-
finding the add-on intuitive, and partner agreement, perhaps indicating the success of the awareness features of Coagmento in groups scoring higher on these items,
-
add-on intuitiveness appears to be weakly correlated with search experience, indicating that those who rate their search skills higher also found the add-on more intuitive.
Pointing to the potential of tasks and technologies such as those used in this research is the participant written feedback, which was generally positive in nature. Visual inspection of the written feedback indicated a number of issues encountered with the use of the browser add-on (particularly, that the chat function was slow), with some issues raised by different participants as positive or negative points. For example, in line with quantitative measures of task-satisfaction some participants expressed that they enjoyed the collaborative element of the task with some particularly noting the use of the collaborative text editor as beneficial, while others expressed a preference for working alone on such tasks. Similarly, others indicated that a topic of more direct interest (or relevance) to them and their studies would be preferred, while a smaller number explicitly noted enjoying the different topic and appreciating that it was a topic few people in the classes would know about. In both tasks some participants also flagged the time constraints imposed; however these were introduced as a design decision serving both a pragmatic ends (to keep the task within a single session) and an experimental one (to ensure prioritisation of activity was necessary).
In the case of task design, some participants indicated that the task instructions could have been more explicit. This was sometimes specifically noted in the context of the assessment tasks, which were the stage at which the assessment criteria were made explicit through the use of the rubric. As noted in the discussion of the assessment development, previous research indicates that use of a rubric at both the task-completion and task-assessment time is optimal, and indeed some participants indicated that they did in fact evaluate sources; one participant said:
Also we didn’t know the criteria so we didn’t take a look at sources, source evaluation and making it into a coherent piece of information. We didn’t do this so we had really little point on it which is a pitty (sic) because it would have been easy points for us since we did use the spurces (sic) and in our head evaluated them. (general feedback, UID 493).
However, in this research a core interest was to explore between-group learning differences. Certainly exploring nuance in task design, instructions and assessment criteria is important. However, grounded in the orchestration background, the research reported gave the instruction to provide the “best supported claims” and “explain why”; the research interest, then, is precisely in understanding how participants interpret such instructions, and what information they provide to support their claims (their epistemic commitments around claim selection, provision of sourcing information, and connection of inter and intra-textual ties). Following on from this initial work, further research should investigate the potential of varying instruction types on within and between-group differences in task behavior.
Cutting across the participant feedback were two implementation issues related to pragmatic concerns about the research context and background. These in part relate to the need to minimize disruption and keep experimental time to a maximum of a single session:
-
1.
Participants had a short period to familiarize themselves with Coagmento, primarily through the instructions at the beginning, and the warmup task, with a self-report control item regarding how intuitive they found the browser add-on
-
2.
Participants had a short period to familiarize themselves with their partner, many of whom were not well known previously. Again the use of the warmup task provided a short period of familiarization session, with self-report items controlling for their prior familiarity with the partner, and level of agreement with them
Alternative designs (e.g. multi-session tasks) and self-selected groups may alter the feedback, and lead to differing task behaviours. A longer project involving use of CIS tools with a sustained partner would provide an interesting site for future research. Moreover, given quantitative feedback regarding the browser add-on was largely positive, a longer period of familiarization may offer limited gains.
5 Conclusion
This paper illustrates CIS as a key element of ‘searching to learn’, demonstrating the potential of orchestration as a lens on to research and teaching designs for understanding CIS as learning. To return to Prieto et al.’s (2015) five aspects of orchestration, the research described in this paper involved:
-
Design: The design of learning activities by the researcher, within the context of the particular institutional setting (and learning context).
-
Management: The management of groups into dyads/triads (manually), whose activity was then facilitated via the Coagmento tool, targeted at the designed tasks which were presented through a workflow system developed to work with the Coagmento tool and a website.
-
Awareness: Awareness of student activity, captured via Coagmento, and surveys at various stages. Awareness was also a key feature built into the Coagmento tool, to support the CIS processes.
-
Adaptation: In the designed pedagogic context, the tool was adapted to meet the needs of the particular task—including a process to guide students through that task, and classroom based support provided to students by the teaching assistants.
-
Role: The research was designed such that the technology (Coagmento and its partner website) took on the key role—guiding students through the stages of their activities and providing communication and awareness tools for them (and the researchers data collection). While researchers and TAs were on hand to support the students if problems arose, the system was designed to require minimal expert support ‘in room’ for supporting the research/teaching activity.
The three key contextual factors have framed these orchestration aspects, specifically:
-
Theory: We have demonstrated how research in epistemic cognition and information seeking has framed the task design and implementation of Coagmento. In particular, epistemic cognition research was drawn on to design the tasks, providing requirements for the ways in which Coagmento could be designed, and used in class contexts.
-
Pragmatism: We have described the ways in which practical considerations—including the PBL context at Maastricht, the limited class time, the need to use Firefox for Coagmento, and the research needs of the study—have shaped our implementation
-
Synergy: We have drawn together these contextual factors and orchestration aspects in describing the way in which Coagmento acted as an agent to direct student and researcher/teaching activity.
Evaluation of the orchestration session indicates that students generally found the experience productive, and were satisfied with the tool and task design. The orchestration brought into alignment the particular background context of the institutional setting and learning theory, with a number of actors engaged in both the design and implementation of activities undertaken by the students. Although the orchestration was perceived to be successful by the students and other actors, it also highlighted the complexities of working together on an innovative CIS task with actors across different fields of expertise, with significant commitments of resources (particularly time) for implementation of even a relatively small orchestration of one CIS learning activity in this authentic context.
The paper thus illustrates the potential (and limitations) of CIS tools for such orchestration, highlighting some of the design decisions made and their practical implementations—going beyond reporting typical in research studies. In particular we note the importance of aligning background (including practical, and theoretical context), actors (including the design of the software), and the activities, and the potential of the orchestration frame to support this. The practical nature of the orchestration framework provides an approach to designing studies in authentic contexts, that can have impact in those very contexts. We thus flag the potential of orchestration in design of ‘real world’ tasks, moving beyond lab-based studies. While further work is required to develop additional pedagogic models of ‘search as learning’, and particularly the role of collaboration in that learning, this paper offers a way to frame the complex design decisions taken in such research tasks. The paper indicates the ways in which ‘searching to learn’, may be orchestrated through CIS which addresses pedagogically salient background context.
Notes
See also Sect. 4.4.3 of Shah (2012a) for a review of awareness in CIS systems.
References
Amershi, S., & Morris, M. R. (2008). CoSearch: A system for co-located collaborative web search. In Proceeding of the Twenty-Sixth Annual SIGCHI Conference on Human Factors in Computing Systems, pp. 1647–1656. http://research.microsoft.com/en-us/um/people/merrie/papers/cosearch.pdf.
Amershi, S., & Morris, M. R. (2009). Co-located collaborative web search, p. 3637. ACM Press. doi:10.1145/1520340.1520547.
Anmarkrud, Ø., Bråten, I., & Strømsø, H. I. (2014). Multiple-documents literacy: Strategic processing, source awareness, and argumentation when reading multiple conflicting documents. Learning and Individual Differences, 30, 64–76. doi:10.1016/j.lindif.2013.01.007.
Ba, H., Tally, W., & Tsikalas, K. (2002). Investigating children’s emerging digital literacies. The Journal of Technology, Learning and Assessment, 1(4). http://www.edtechpolicy.org/ArchivedWebsites/JCTE/v1n4_jtla1.pdf.
Barzilai, S., & Zohar, A. (2009). The Role of Epistemic Thinking in Online Learning. In Proceedings of the Chais Conference on Instructional Technologies Research 2009: Learning in the Technological Era. Raanana: The Open University of Israel. http://telem-pub.openu.ac.il/users/chais/2009/morning/1_2.pdf. Accessed 27 January 2012.
Barzilai, S., & Zohar, A. (2012). Epistemic thinking in action: Evaluating and integrating online sources. Cognition and Instruction, 30(1), 39–85. doi:10.1080/07370008.2011.636495.
Bateman, S., Gutwin, C. A., & McCalla, G. I. (2013). Social navigation for loosely-coupled information seeking in tightly-knit groups using webwear. In Proceedings of the 2013 Conference on Computer supported Cooperative Work, pp. 955–966. http://dl.acm.org/citation.cfm?id=2441885. Accessed 12 May 2013.
Bloom, B. S. (1956). Taxonomy of educational objectives, handbook 1: Cognitive domain (2nd ed.). Boston: Addison Wesley Publishing Company.
Böhm, T., Klas, C.-P., & Hemmje, M. (2016). Towards a probabilistic model for supporting collaborative information access. Information Retrieval Journal, 19(5), 487–509. doi:10.1007/s10791-016-9285-3.
Bråten, I., & Weinstein, C. E. (2004). Internet-specific epistemological questionnaire (ISEQ). Austin, TX: Department of Educational Psychology, University of Texas at Austin.
Bråten, I., & Strømsø, H. I. (2006). Epistemological beliefs, interest, and gender as predictors of internet-based learning activities. Computers in Human Behavior, 22(6), 1027–1042. doi:10.1016/j.chb.2004.03.026.
Bråten, I., & Samuelstuen, M. S. (2007). Measuring strategic processing: Comparing task-specific self-reports to traces. Metacognition and Learning, 2(1), 1–20. doi:10.1007/s11409-007-9004-y.
Bråten, I., & Strømsø, H. I. (2009). Effects of task instruction and personal epistemology on the understanding of multiple texts about climate change. Discourse Processes, 47(1), 1–31. doi:10.1080/01638530902959646.
Bråten, I., Strømsø, H. I., & Samuelstuen, M. S. (2005). The relationship between internet-specific epistemological beliefs and learning within internet technologies. Journal of Educational Computing Research, 33(2), 141–171. doi:10.2190/E763-X0LN-6NMF-CB86.
Bråten, I., Braasch, J. L. G., Strømsø, H. I., & Ferguson, L. E. (2014). Establishing trustworthiness when students read multiple documents containing conflicting scientific evidence. Reading Psychology. doi:10.1080/02702711.2013.864362.
Bromme, R., Pieschl, S., & Stahl, E. (2009). Epistemological beliefs are standards for adaptive learning: A functional theory about epistemological beliefs and metacognition. Metacognition and Learning, 5(1), 7–26. doi:10.1007/s11409-009-9053-5.
Chiu, Y.-L., Liang, J.-C., & Tsai, C.-C. (2013). Internet-specific epistemic beliefs and self-regulated learning in online academic information searching. Metacognition and Learning, 8(3), 235–260. doi:10.1007/s11409-013-9103-x.
Dimopoulos, K., & Asimakopoulos, A. (2010). Science on the web: Secondary school students’ navigation patterns and preferred pages’ characteristics. Journal of Science Education and Technology, 19(3), 246–265. doi:10.1007/s10956-009-9197-8.
Ferguson, R. (2012). The state of learning analytics in 2012: A review and future challenges (Technical Report No. kmi-12-01). Knowledge Media Institute: The Open University, UK. http://kmi.open.ac.uk/publications/pdf/kmi-12-01.pdf. Accessed 22 October 2012.
Ferguson, L. E., Bråten, I., Strømsø, H. I., & Anmarkrud, Ø. (2013). Epistemic beliefs and comprehension in the context of reading multiple documents: Examining the role of conflict. International Journal of Educational Research, 62, 100–114. doi:10.1016/j.ijer.2013.07.001.
Goldman, S. R., Braasch, J. L. G., Wiley, J., Graesser, A. C., & Brodowinska, K. (2012). Comprehending and learning from internet sources: Processing patterns of better and poorer learners. Reading Research Quarterly, 47(4), 356–381. doi:10.1002/RRQ.027.
Golovchinsky, G., & Diriye, A. (2011). Session-based search with Querium. In Proceedings of the HCIR 2011 Workshop, Mountain View, CA, USA. http://fxpal.com/publications/FXPAL-PR-11-660.pdf. Accessed 12 May 2013.
Golovchinsky, G., Adcock, J., Pickens, J., Qvarfordt, P., & Back, M. (2008). Cerchiamo: A collaborative exploratory search tool. In Proceedings of Computer Supported Cooperative Work (CSCW). http://fxpal.fxpal.com/publications/FXPAL-PR-08-470.pdf. Accessed 12 May 2013.
Greene, J. A., Muis, K. R., & Pieschl, S. (2010). The Role of epistemic beliefs in students’ self-regulated learning with computer-based learning environments: Conceptual and methodological issues. Educational Psychologist, 45(4), 245–257. doi:10.1080/00461520.2010.515932.
Gubbels, M., Rose, A., Russell, D., & Bederson, B. B. (2012). SearchParty: Real-time Support for Social Learning in Synchronous Environments (No. HCIL-2012-21). Human-Computer Interaction Lab, University of Maryland. http://hcil2.cs.umd.edu/trs/2012-21/2012-21.pdf. Accessed 19 October 2012.
Heilman, J. M., Kemmann, E., Bonert, M., Chatterjee, A., Ragar, B., Beards, G. M., et al. (2011). Wikipedia: A key tool for global public health promotion. Journal of medical Internet research, 13(1). http://www.ncbi.nlm.nih.gov/pmc/articles/pmc3221335/. Accessed 6 April 2015.
Hertzum, M. (2008). Collaborative information seeking: The combined activity of information seeking and collaborative grounding. Information Processing and Management, 44(2), 957–962. doi:10.1016/j.ipm.2007.03.007.
Hofer, B. K. (2001). Personal epistemology research: Implications for learning and teaching. Educational Psychology Review, 13(4), 353–383. http://www.springerlink.com/index/R6R6241GP87047K6.pdf. Accessed 24 October 2012.
Hofer, B. K. (2004). Epistemological understanding as a metacognitive process: Thinking aloud during online searching. Educational Psychologist, 39(1), 43–55. doi:10.1207/s15326985ep3901_5.
Horgan, A., & Sweeney, J. (2012). University students’ online habits and their use of the internet for health information. CIN: Computers Informatics, Nursing, 30(8), 402–408. doi:10.1097/NXN.0b013e3182510703.
Hsu, L. (2014). An epistemological analysis of the application of an online inquiry-based program in tourism education. Australasian Journal of Educational Technology. doi:10.14742/ajet.v30i1.402.
Hsu, C.-Y., Tsai, M.-J., Hou, H.-T., & Tsai, C.-C. (2013). Epistemic beliefs, online search strategies, and behavioral patterns while exploring socioscientific issues. Journal of Science Education and Technology. doi:10.1007/s10956-013-9477-1.
Hwang, G.-J., Tsai, P.-S., Tsai, C.-C., & Tseng, J. C. R. (2008). A novel approach for assisting teachers in analyzing student web-searching behaviors. Computers & Education, 51(2), 926–938. doi:10.1016/j.compedu.2007.09.011.
Hyldegård, J. (2006). Collaborative information behaviour—Exploring Kuhlthau’s Information Search Process model in a group-based educational setting. Information Processing and Management, 42(1), 276–298. doi:10.1016/j.ipm.2004.06.013.
Hyldegård, J. (2009). Beyond the search process—Exploring group members’ information behavior in context. Information Processing and Management, 45(1), 142–158. doi:10.1016/j.ipm.2008.05.007.
Knight, S. (2012). Finding knowledge—The role of dialogue in collaborative information retrieval in the classroom (master’s). Cambridge: University of Cambridge.
Knight, S. (2015). Learning Indicators in SCIS Tasks. In 1st edition of the international workshop on the Evaluation on Collaborative Information Seeking and Retrieval ECol 2015. Presented at the 24th ACM International Conference on Information and Knowledge Management (CIKM 2015), Melbourne, Australia: ACM. doi:http://dx.doi.org/10.1145/2812376.2812378.
Knight, S. (2016). Developing Learning Analytics for Epistemic Commitments in a Collaborative Information Seeking Environment (Ph.D.). Open University, Milton Keynes, UK. Retrieved from http://oro.open.ac.uk/46143/.
Knight, S., Arastoopour, G., Williamson Shaffer, D., Buckingham Shum, S., & Littleton, K. (2014). Epistemic networks for epistemic commitments. In International Conference of the Learning Sciences. Boulder, CO: International Society of the Learning Sciences. http://oro.open.ac.uk/39254/. Accessed 11 November 2013.
Knight, S., & Littleton, K. (2015). Thinking, Interthinking, and technological tools. In R. Wegerif, L. Li, & J. C. Kaufman (Eds.), The routledge international handbook of research on teaching thinking (p. section 7(al)). Routledge. http://www.routledge.com/books/details/9780415747493/.
Knight, S., & Littleton, K. (2016). Learning through Collaborative Information Seeking. In P. Hansen, C. Shah, & C.-P. Klas (Eds.), Collaborative information seeking: Best practices, new domains, new thoughts. Berlin: Springer.
Knight, S., & Mercer, N. (2015). The role of exploratory talk in classroom search engine tasks. Technology, Pedagogy and Education, 24(3), 303–319. doi:10.1080/1475939X.2014.931884.
Knight, S., & Mercer, N. (2016). The role of collaborative, epistemic discourse in classroom information seeking tasks. Technology, Pedagogy and Education, 26(1), 33–50. doi:10.1080/1475939X.2016.1159978.
Knight, S., Rienties, B., Littleton, K., Mitsui, M., Tempelaar, D. T., & Shah, C. (2017). The relationship of (perceived) epistemic cognition to interaction with resources on the internet. Computers in Human Behavior, 73, 507–518. doi:10.1016/j.chb.2017.04.014.
Kuiper, E., Volman, M., & Terwel, J. (2009). Developing Web literacy in collaborative inquiry activities. Computers & Education, 52(3), 668–680. doi:10.1016/j.compedu.2008.11.010.
Lazonder, A. W. (2005). Do two heads search better than one? Effects of student collaboration on web search behaviour and search outcomes. British Journal of Educational Technology, 36(3), 465–475. doi:10.1111/j.1467-8535.2005.00478.x.
Liechti, O., & Sumi, Y. (2002). Editorial: Awareness and the WWW. International Journal of Human-Computer Studies, 56(1), 1–5. doi:10.1006/ijhc.2001.0512.
Lin, C., & Tsai, C. (2008). Exploring the structural relationships between high school students’ scientific epistemological views and their utilization of information commitments toward online science information. International Journal of Science Education, 30(15), 2001–2022. doi:10.1080/09500690701613733.
Livingstone, S., Bober, M., & Helsper, E. (2005). Internet literacy among children and young people: Findings from the UK Children Go Online project. London: LSE Research Online. http://eprints.lse.ac.uk/397/1/UKCGOonlineLiteracy.pdf. Accessed 10 October 2011.
Marchionini, G. (2006). Exploratory search: From finding to understanding. Communications of the ACM, 49(4), 41. doi:10.1145/1121949.1121979.
Mason, L., Boldrin, A., & Ariasi, N. (2010). Epistemic metacognition in context: Evaluating and learning online information. Metacognition and Learning, 5(1), 67–90. doi:10.1007/s11409-009-9048-2.
Mason, L., Ariasi, N., & Boldrin, A. (2011). Epistemic beliefs in action: Spontaneous reflections about knowledge and knowing during online information searching and their influence on learning. Learning and Instruction, 21(1), 137–151. doi:10.1016/j.learninstruc.2010.01.001.
Moraveji, N., Morris, M. R., Morris, D., Czerwinski, M., & Henry Riche, N. (2011). ClassSearch: Facilitating the development of web search skills through social learning. In Proceedings of the 2011 Annual Conference on Human Factors in Computing Systems, pp. 1797–1806.
Morris, M. R., & Horvitz, E. (2007). SearchTogether: An interface for collaborative web search. In Proceedings of the 20th Annual ACM Symposium on User Interface Software and Technology, pp. 3–12. http://dl.acm.org/citation.cfm?id=1294215. Accessed 29 April 2013.
Mozilla. (2014). Firefox. https://www.mozilla.org/en-US/firefox/new/. Accessed 6 April 2015.
Newman, K., Knight, S., Elbeshausen, S., & Hansen, P. (2016). Situating CIS—The importance of context in collaborative information seeking. In P. Hansen, C. Shah, & C.-P. Klas (Eds.), Collaborative information seeking: Best practices, new domains, new thoughts. Berlin: Springer.
OECD. (2013). PISA 2015: Draft reading literacy framework. OECD Publishing. http://www.oecd.org/pisa/pisaproducts/Draft%20PISA%202015%20Reading%20Framework%20.pdf. Accessed 22 April 2014.
Paul, S., A., & Morris, M. R. (2009). CoSense: Enhancing sensemaking for collaborative web search. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems (pp. 1771–1780). New York, NY, USA: ACM. doi:10.1145/1518701.1518974.
Prieto, L. P., Dimitriadis, Y., Asensio-Pérez, J. I., & Looi, C.-K. (2015). Orchestration in learning technology research: Evaluation of a conceptual framework. Research in Learning Technology. doi:10.3402/rlt.v23.28019.
Prieto, L. P., Holenko Dlab, M., Gutiérrez, I., Abdulwahed, M., & Balid, W. (2011). Orchestrating technology enhanced learning: A literature review and a conceptual framework. International Journal of Technology Enhanced Learning, 3(6), 583–598. http://www.inderscienceonline.com/doi/abs/10.1504/IJTEL.2011.045449. Accessed 8 August 2016.
Rouet, J.-F. (2006). The skills of document use: From text comprehension to web-based learning (1st ed.). Mahwah, NJ: Routledge.
Schmidt, C. W. (2012). Trending now: Using social media to predict and track disease outbreaks. Environmental Health Perspectives, 120(1), a30–a33. doi:10.1289/ehp.120-a30.
Schmidt, H. G., Molen, H. T. V. D., Winkel, W. W. R. T., & Wijnen, W. H. F. W. (2009). Constructivist, problem-based learning does work: A meta-analysis of curricular comparisons involving a single medical school. Educational Psychologist, 44(4), 227–249. doi:10.1080/00461520903213592.
Schraw, G. (2001). Current themes and future directions in epistemological research: A commentary. Educational Psychology Review, 13(4), 451–464. doi:10.1023/A:1011922015665.
Schraw, G. (2013). Conceptual integration and measurement of epistemological and ontological beliefs in educational research. ISRN Education. http://www.hindawi.com/isrn/education/aip/327680/. Accessed 15 January 2013.
Shah, C. (2010). Coagmento-a collaborative information seeking, synthesis and sense-making framework. Integrated demo at CSCW, 6–11. http://research.microsoft.com/en-us/um/redmond/groups/connect/CSCW_10/docs/p527.pdf. Accessed 12 May 2013.
Shah, C. (2012a). Information retrieval: Collaborative information seeking: The art and science of making the whole greater than the sum of all. Berlin: Springer.
Shah, C. (2012b). Coagmento: A case study in designing. In E. Currás & N. L. Romero (Eds.), Systems science and collaborative information systems: Theories, practices and new research: Theories, practices and new research (p. 242). Hershey, PA: IGI Global. http://www.igi-global.com/chapter/coagmento-case-study-designing-user/61295. Accessed 13 June 2015.
Shah, C. (2013). Effects of awareness on coordination in collaborative information seeking. Journal of the American Society for Information Science and Technology, n/a–n/a. doi:10.1002/asi.22819.
Shah, C. (2014). Coagmento. http://coagmento.org/. Accessed 6 April 2015.
Shah, C., & González-Ibáñez, R. (2010). Exploring information seeking processes in collaborative search tasks. Proceedings of the American Society for Information Science and Technology, 47(1), 1–7. doi:10.1002/meet.14504701211.
Shah, C., & Marchionini, G. (2010). Awareness in collaborative information seeking. Journal of the American Society for Information Science and Technology, 61(10), 1970–1986. doi:10.1002/asi.21379.
Shah, C., Marchionini, G., & Kelly, D. (2009). Learning design principles for a collaborative information seeking system. In CHI’09 Extended Abstracts on Human Factors in Computing Systems (pp. 3419–3424). ACM. http://dl.acm.org/citation.cfm?id=1520496. Accessed 20 April 2015.
Singh, R., Hsu, Y.-W., & Moon, N. (2013). Multiple perspective interactive search: A paradigm for exploratory search and information retrieval on the web. Multimedia Tools and Applications, 62(2), 507–543. http://link.springer.com/article/10.1007/s11042-011-0910-2. Accessed 27 August 2013.
SQW. (2011). Evaluation of the home access programme—Final report. DCSF. https://www.education.gov.uk/publications/eOrderingDownload/DFE-RR132.pdf. Accessed 14 October 2011.
Strømsø, H. I., Bråten, I., & Britt, M. A. (2011). Do students’ beliefs about knowledge and knowing predict their judgement of texts’ trustworthiness? Educational Psychology, 31(2), 177–206. doi:10.1080/01443410.2010.538039.
Sundin, O., & Johannisson, J. (2005). The instrumentality of information needs and relevance. In F. Crestani & I. Ruthven (Eds.), Context: Nature, impact, and role (Vol. 3507, pp. 107–118). Berlin, Heidelberg: Springer Berlin Heidelberg. http://www.springerlink.com/content/gb5gfmg8xn8u3gtx/. Accessed 31 January 2012.
Tempelaar, D. T., Niculescu, A., Rienties, B., Gijselaers, W. H., & Giesbers, B. (2012). How achievement emotions impact students’ decisions for online learning, and what precedes those emotions. The Internet and Higher Education, 15(3), 161–169. doi:10.1016/j.iheduc.2011.10.003.
Tsai, M.-J., Hsu, C.-Y., & Tsai, C.-C. (2012). Investigation of high school students’ online science information searching performance: The role of implicit and explicit strategies. Journal of Science Education and Technology, 21(2), 246–254. doi:10.1007/s10956-011-9307-2.
Tsai, P.-S., Tsai, C.-C., & Hwang, G.-J. (2011). The correlates of Taiwan teachers’ epistemological beliefs concerning Internet environments, online search strategies, and search outcomes. The Internet and Higher Education, 14(1), 54–63. doi:10.1016/j.iheduc.2010.03.003.
Tseng, J. C. R., Hwang, G.-J., Tsai, P.-S., & Tsai, C.-C. (2009). Meta-analyzer: A web-based learning environment for analyzing student information searching behaviors. Computing, Information and Control, 5(3), 567–579. http://www.ijicic.org/icic07-is03-12-1.pdf. Accessed 18 September 2014.
Walraven, A., Brand-Gruwel, S., & Boshuizen, H. (2008). Information-problem solving: A review of problems students encounter and instructional solutions. Computers in Human Behavior, 24(3), 623–648. doi:10.1016/j.chb.2007.01.030.
Wildemuth, B. M., & Freund, L. (2012). Assigning search tasks designed to elicit exploratory search behaviors. In Proceedings of the Symposium on Human-Computer Interaction and Information Retrieval (pp. 4:1–4:10). New York, NY, USA: ACM. doi:10.1145/2391224.2391228.
Yue, Z., Han, S., & He, D. (2012). Search tactics in collaborative exploratory web search. In Proceedings of HCIR 2012. Cambridge, MA. http://crystal.exp.sis.pitt.edu:8080/ips/paper/hcir2012_cs.pdf. Accessed 29 April 2013.
Acknowledgements
The work reported in this paper was conducted while the first author was a Ph.D. candidate at the Open University, UK, to whom he extends thanks. Thanks too to Dr Dirk Tempelaar’s lab assistants at Maastricht University, who assisted in supporting the lab-based orchestration.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Knight, S., Rienties, B., Littleton, K. et al. The orchestration of a collaborative information seeking learning task. Inf Retrieval J 20, 480–505 (2017). https://doi.org/10.1007/s10791-017-9304-z
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10791-017-9304-z