
Abstract
While i-vectors with probabilistic linear discriminant analysis (PLDA) can achieve state-of-the-art performance in speaker verification, the mismatch caused by acoustic noise remains a key factor affecting system performance. In this paper, a fusion system that combines a multi-condition signal-to-noise ratio (SNR)-independent PLDA model and a mixture of SNR-dependent PLDA models is proposed to make speaker verification systems more noise robust. First, the whole range of SNR that a verification system is expected to operate is divided into several narrow ranges. Then, a set of SNR-dependent PLDA models, one for each narrow SNR range, are trained. During verification, the SNR of the test utterance is used to determine which of the SNR-dependent PLDA models is used for scoring. To further enhance performance, the SNR-dependent and SNR-independent models are fused using linear and logistic regression fusion. The performance of the fusion system and the SNR-dependent system is evaluated on the NIST 2012 speaker recognition evaluation for both noisy and clean conditions. Results show that a mixture of SNR-dependent PLDA models perform better in both clean and noisy conditions. It was also found that the fusion system is more robust than the conventional i-vector/PLDA systems under noisy conditions.













Similar content being viewed by others
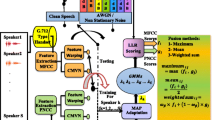
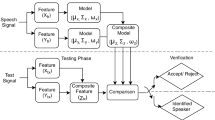
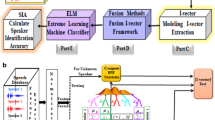
References
Bishop, C. (2006). Pattern recognition and machine learning. New York: Springer.
Brümmer, N. (2014). FoCal. https://www.sitesgooglecom/site/nikobrummer/focal.
Brümmer, N., & de Villiers, E. (2011). The Bosaris toolkit user guide: Theory, algorithms and code for binary classifier score processing. Documentation of Bosaris toolkit. https://sites.google.com/site/bosaristoolkit/
Dehak, N., Kenny, P., Dehak, R., Dumouchel, P., & Ouellet, P. (2011). Front-end factor analysis for speaker verification. IEEE Transactions on Audio, Speech, and Language Processing, 19(4), 788–798.
Ferrer, L., Bratt, H., Burget, L., Cernocky, H., Glembek, O., Graciarena, M., et al. (2011). Promoting robustness for speaker modeling in the community: The PRISM evaluation set. In Proceedings of NIST 2011 workshop.
Garcia-Romero, D., & Espy-Wilson, C. (2011). Analysis of i-vector length normalization in speaker recognition systems. In Proceedings of interspeech (pp. 249–252).
Garcia-Romero, D., Zhou, X., & Espy-Wilson, C. (2012). Multicondition training of Gaussian PLDA models in i-vector space for noise and reverberation robust speaker recognition. In 2012 IEEE international conference on acoustics, speech and signal processing (ICASSP, pp. 4257–4260).
Hasan, T., & Hansen, J. (2013). Acoustic factor analysis for robust speaker verification. IEEE Transactions on Audio, Speech, and Language Processing, 21(4), 842–853.
Hasan, T., & Hansen, J. (2014). Maximum likelihood acoustic factor analysis models for robust speaker verification in noise. IEEE Transactions on Audio, Speech, and Language Processing, 22(2), 381–391.
Hasan, T., Sadjadi, S. O., Liu, G., Shokouhi, N., Boril, H., & Hansen, J. H. L. (2013). CRSS system for 2012 NIST speaker recognition evaluation. In 2013 IEEE international conference on acoustics, speech and signal processing (ICASSP, pp. 6783–6787).
Hatch, A., Kajarekar, S., & Stolcke, A. (2006). Within-class covariance normalization for SVM-based speaker recognition. In Proceedings of the 9th international conference on spoken language processing, Pittsburgh, PA, USA (pp. 1471–1474).
Kenny, P. (2010). Bayesian speaker verification with heavy-tailed priors. In Proceedings of Odyssey. 2010 Speaker and language recognition workshop. Brno: Czech Republic.
Kenny, P., Boulianne, G., Ouellet, P., & Dumouchel, P. (2007). Joint factor analysis versus eigenchannels in speaker recognition. IEEE Transactions on Audio, Speech and Language Processing, 15(4), 1435–1447.
Kenny, P., Ouellet, P., Dehak, N., Gupta, V., & Dumouchel, P. (2008). A study of inter-speaker variability in speaker verification. IEEE Transactions on Audio, Speech and Language Processing, 16(5), 980–988.
Leeuwen, D. A., & Saeidi, R. (2013). Knowing the non-target speakers: The effect of the i-vector population for PLDA training in speaker recognition. In 2013 IEEE international conference on acoustics, speech and signal processing (ICASSP), Vancouver, BC, Canada (pp. 6778–6782).
Lei, Y., Burget, L., Ferrer, L., Graciarena, M., & Scheffer, N. (2012). Towards noise-robust speaker recognition using probabilistic linear discriminant analysis. In 2012 IEEE international conference on acoustics, speech and signal processing (ICASSP), Kyoto, Japan (pp. 4253–4256).
Lei, Y., Burget, L., & Scheffer, N. (2013). A noise robust i-vector extractor using vector Taylor series for speaker recognition. In 2013 IEEE international conference on acoustics, speech and signal processing (ICASSP, pp. 6788–6791).
Lei, Y., Mclaren, M., Ferrer, L., & Scheffer, N. (2014). Simplified VTS-based i-vector extraction in noise-robust speaker recognition. In 2014 IEEE international conference on acoustics, speech and signal processing (ICASSP, pp. 4065–4069).
Li, Q., & Huang, Y. (2010). Robust speaker identification using an auditory-based feature. In 2010 IEEE international conference on acoustics, speech and signal processing (ICASSP, pp. 4514–4517).
Mak, M. W., & Yu, H. B. (2013). A study of voice activity detection techniques for NIST speaker recognition evaluations. Computer, Speech and Language, 28(1), 295–313.
Mallidi, S., Ganapathy, S., & Hermansky, H. (2013). Robust speaker recognition using spectro-temporal autoregressive models. In Proceedings of interspeech.
Martin, A., Doddington, G., Kamm, T., Ordowski, M., & Przybocki, M. (1997). The DET curve in assessment of detection task performance. In Proceedings of Eurospeech’97 (pp. 1895–1898).
Martinez, D., Burget, L., Stafylakis, T., Lei, Y., Kenny, P., & Lleida, E. (2014). Unscented transform for i-vector-based noisy speaker recognition. In 2014 IEEE international conference on acoustics, speech and signal processing (ICASSP, pp. 4070–4074).
McLaren, M., Mandasari, M., & Leeuwen, D. (2012). Source normalization for language-independent speaker recognition using i-vectors. In Proceedings of Odyssey 2012: The speaker and language recognition workshop (pp. 55–61).
McLaren, M., Scheffer, N., Graciarena, M., Ferrer, L., & Lei, Y. (2013). Improving speaker identification robustness to highly channel-degraded speech through multiple system fusion. In 2013 IEEE international conference on acoustics, speech and signal processing (ICASSP, pp. 6773–6777).
Ming, J., Hazen, T., Glass, J., & Reynolds, D. (2007). Robust speaker recognition in noisy conditions. IEEE Transactions on Audio, Speech and Language Processing, 15(5), 1711–1723.
Neto, S. F. D. C. (1999). The ITU-T software tool library. International Journal of Speech Technology, 2(4), 259–272.
NIST. (2012). The NIST year 2012 speaker recognition evaluation plan. http://www.nistgov/itl/iad/mig/sre12cfm.
Pang, X. M., & Mak, M. W. (2014). Fusion of SNR-dependent PLDA models for noise robust speaker verification. In ISCSLP’2014 (pp. 619–623).
Pelecanos, J., & Sridharan, S. (2001). Feature warping for robust speaker verification. In Proceedings of Odyssey, 2001. The speaker and language recognition workshop, Crete, Greece (pp. 213–218).
Prince, S., & Elder, J. (2007). Probabilistic linear discriminant analysis for inferences about identity. In IEEE 11th international conference on computer vision, 2007 (ICCV 2007, pp. 1–8).
Rajan, P., Afanasyev, A., Hautamäki, V., & Kinnunen, T. (2014). From single to multiple enrollment i-vectors: Practical PLDA scoring variants for speaker verification. Digital Signal Processing Online. doi:10.1016/j.dsp.2014.05.001.
Rajan, P., Kinnunen, T., & Hautamäki, V. (2013). Effect of multicondition training on i-vector PLDA configurations for speaker recognition. In Proceedings of interspeech (pp. 3694–3697).
Rao, W., & Mak, M. W. (2013). Boosting the performance of i-vector based speaker verification via utterance partitioning. IEEE Transactions on Audio, Speech and Language Processing, 21(5), 1012–1022.
Reynolds, D. A., Quatieri, T. F., & Dunn, R. B. (2000). Speaker verification using adapted Gaussian mixture models. Digital Signal Processing, 10(1–3), 19–41.
Sadjadi, S. O., Hasan, T., & Hansen, J. (2012). Mean Hilbert envelope coefficients (MHEC) for robust speaker recognition. In Proceedings of interspeech (pp. 1696–1699).
Sadjadi, S., Pelecanos, J., & Zhu, W. (2014). Nearest neighbor discriminant analysis for robust speaker recognition. In Proceedings of interspeech (pp. 1860–1864).
Saeidi, R., & van Leeuwen, D. A. (2012). The Radboud University Nijmegen submission to NIST SRE-2012. In Proceedings of the NIST speaker recognition evaluation workshop.
Shao, Y., & Wang, D. (2008). Robust speaker identification using auditory features and computational auditory scene analysis. In 2008 IEEE international conference on acoustics, speech and signal processing (ICASSP, pp. 1589–1592).
Yu, C., Liu, G., Hahm, S., & Hansen, J. (2014). Uncertainty propagation in front end factor analysis for noise robust speaker recognition. In 2014 IEEE international conference on acoustics, speech and signal processing (ICASSP, pp. 4045–4049).
Yu, H., & Mak, M. (2011). Comparison of voice activity detectors for interview speech in NIST speaker recognition evaluation. In Proceedings of interspeech (pp. 2353–2356).
Acknowledgments
This work was in part supported by The Hong Kong Research Grant Council (Grant Nos. PolyU 152117/14E and PolyU 152068/15E) and The Hong Kong Polytechnic University (Grant No. 4-ZZCX).
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Pang, X., Mak, MW. Noise robust speaker verification via the fusion of SNR-independent and SNR-dependent PLDA. Int J Speech Technol 18, 633–648 (2015). https://doi.org/10.1007/s10772-015-9310-8
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10772-015-9310-8