
Abstract
As the computation power of modern high performance architectures increases, their heterogeneity and complexity also become more important. One of the big challenges of exascale is to reach programming models that give access to high performance computing (HPC) to many scientists and not only to a few HPC specialists. One relevant solution to ease parallel programming for scientists is domain specific language (DSL). However, one problem to avoid with DSLs is to mutualize existing codes and libraries instead of implementing each solution from scratch. For example, this phenomenon occurs for stencil-based numerical simulations, for which a large number of languages has been proposed without code reuse between them. The Multi-Stencil Framework (MSF) presented in this paper combines a new DSL to component-based programming models to enhance code reuse and separation of concerns in the specific case of stencils. MSF can easily choose one parallelization technique or another, one optimization or another, as well as one back-end implementation or another. It is shown that MSF can reach same performances than a non component-based MPI implementation over 16,384 cores. Finally, the performance model of the framework for hybrid parallelization is validated by evaluations.



























Similar content being viewed by others


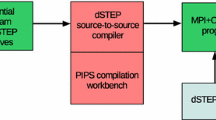
Notes
L2C has been recently extended with the possibility of static linking.
References
Allan, B.A., et al.: A component architecture for high-performance scientific computing. Int. J. High Perform. Comput. Appl. 20(2), 163–202 (2006)
Augonnet, C., Thibault, S., Namyst, R., Wacrenier, P.-A.: StarPU: a unified platform for task scheduling on heterogeneous multicore architectures. Concurr. Comput. Pract. Exp. 23(2), 187–198 (2011)
Baude, F., Caromel, D., Dalmasso, C., Danelutto, M., Getov, V., Henrio, L., Pérez, C.: Gcm: a grid extension to fractal for autonomous distributed components. Ann. Telecommun. 64(1–2), 5–24 (2009)
Bauer, M., Treichler, S., Slaughter, E., Aiken, A.: Legion: expressing locality and independence with logical regions. In: International Conference on High Performance Computing, Networking, Storage and Analysis. IEEE (2012)
Bigot, J., Hou, Z., Prez, C., Pichon, V.: A low level component model easing performance portability of hpc applications. Computing 96(12), 1115–1130 (2014)
Bigot, J., Pérez, C.: Increasing Reuse in Component Models through Genericity. Research Report RR-6941 (2009)
Camier, J.-S.: Improving performance portability and exascale software productivity with the∇ numerical programming language. In: Proceedings of the 3rd International Conference on Exascale Applications and Software, EASC ’15, pp. 126–131. University of Edinburgh, Edinburgh (2015)
Christen, M., Schenk, O., Burkhart, H.: PATUS: a code generation and autotuning framework for parallel iterative stencil computations on modern microarchitectures. In: Parallel and Distributed Processing Symposium (IPDPS), 2011 IEEE International, pp. 676–687. IEEE (2011)
Cordier, S., Coullon, H., Delestre, O., Laguerre, C., Le, M.H., Pierre, D., Sadaka, G.: Fullswof paral: comparison of two parallelization strategies (mpi and skelgis) on a software designed for hydrology applications. In: ESAIM: Proceedings, vol. 43, pp. 59–79. EDP Sciences (2013)
Coullon, H., Limet, S.: The SIPSim implicit parallelism model and the SkelGIS library. Pract. Exp. Concurr. Comput. 28, 2120–2144 (2015)
Coullon, H., Limet, S.: Algorithmic skeleton library for scientific simulations: Skelgis. In: International Conference on High Performance Computing and Simulation, HPCS 2013, Helsinki, Finland, July 1–5, 2013, pp. 429–436 (2013)
Coullon, H., Limet, S., Le Minh, H.: Parallelization of shallow-water equations with the algorithmic skeleton library SkelGIS. In: Elsevier (ed.) ICCS, volume 18 of Procedia Computer Science, pp. 591–600. Elsevier, Barcelone (2013)
Dagum, L., Menon, R.: Openmp: an industry standard api for shared-memory programming. IEEE Comput. Sci. Eng. 5(1), 46–55 (1998)
DeVito, Z., Joubert, N., Palacios, F., Oakley, S., Medina, M., Barrientos, M., Elsen, E., Ham, F. , Aiken, A., Duraisamy, K., Darve, E., Alonso, J., Hanrahan, P.: Liszt: a domain specific language for building portable mesh-based pde solvers. In: Proceedings of 2011 International Conference for High Performance Computing, Networking, Storage and Analysis, SC ’11, pp. 9:1–9:12. ACM, New York (2011)
ETP4HPC. ETP4HPC Strategic Research Agenda Achieving HPC leadership in Europe. Technical report, ETP4HPC (2013)
Ferrari, S., Saleri, F.: A new two-dimensional shallow water model including pressure effects and slow varying bottom topography. M2AN Math. Model. Numer. Anal. 38(2), 211–234 (2004)
Gautier, T., Lima, J.V.F., Maillard, N., Raffin, B.: Xkaapi: a runtime system for data-flow task programming on heterogeneous architectures. In: Proceedings of the 2013 IEEE 27th International Symposium on Parallel and Distributed Processing, IPDPS ’13, pp. 1299–1308. IEEE Computer Society, Washington (2013)
Giles, M.B., Mudalige, G.R., Sharif, Z., Markall, G., Kelly, P.H.J.: Performance analysis of the OP2 framework on many-core architectures. SIGMETRICS Perform. Eval. Rev. 38(4), 9–15 (2011)
Kaiser, H., Heller, T., Adelstein-Lelbach, B., Serio, A., Fey, D.: Hpx: a task based programming model in a global address space. In: Proceedings of the 8th International Conference on Partitioned Global Address Space Programming Models, PGAS ’14, pp. 6:1–6:11. ACM, New York (2014)
Kambadur, P., Gupta, A., Ghoting, A., Avron, H., Lumsdaine, A.: Pfunc: modern task parallelism for modern high performance computing. In: Proceedings of the Conference on High Performance Computing Networking, Storage and Analysis, SC ’09, pp. 43:1–43:11. ACM, New York (2009)
Lachat, C., Pellegrini, F., Dobrzynski, C.: PaMPA: parallel mesh partitioning and adaptation. In: 21st International Conference on Domain Decomposition Methods (DD21), Rennes, France. INRIA Rennes-Bretagne-Atlantique (2012)
Lanore, V. Pérez, C.: A reconfigurable component model for hpc. In: Proceedings of the 18th International ACM SIGSOFT Symposium on Component-Based Software Engineering, CBSE ’15, pp. 1–10. ACM, New York (2015)
Nieplocha, J., Palmer, B., Tipparaju, V., Krishnan, M., Trease, H., Aprà, E.: Advances, applications and performance of the global arrays shared memory programming toolkit. Int. J. High Perform. Comput. Appl. 20(2), 203–231 (2006)
Object Management Group. Corba component model 4.0 specification. Specification Version 4.0, Object Management Group (2006)
Pellegrini, F., Roman, J.: Scotch: a software package for static mapping by dual recursive bipartitioning of process and architecture graphs. In: Proceedings of the International Conference and Exhibition on High-Performance Computing and Networking, HPCN Europe 1996, pp. 493–498. Springer, London (1996)
Ragan-Kelley, J., Barnes, C., Adams, A., Paris, S., Durand, F., Amarasinghe, S.: Halide: a language and compiler for optimizing parallelism, locality, and recomputation in image processing pipelines. In: Proceedings of the 34th ACM SIGPLAN Conference on Programming Language Design and Implementation, PLDI ’13, pp. 519–530. ACM, New York (2013)
Richard, J., Lanore, V., Pérez, C.: Towards application variability handling with component models: 3d-fft use case study. In Proceedings of the 8th Workshop on UnConventional High Performance Computing (UCHPC), Vienna, Austria (To appear) (2015)
Schmitt, C., Kuckuk, S., Hannig, F., Köstler, H., Teich, J.: Exaslang: a domain-specific language for highly scalable multigrid solvers. In: Proceedings of the Fourth International Workshop on Domain-Specific Languages and High-Level Frameworks for High Performance Computing, WOLFHPC ’14, pp. 42–51. IEEE Press, Piscataway (2014)
Szyperski, C.: Component Software: Beyond Object-Oriented Programming, 2nd edn. Addison-Wesley Longman Publishing Co., Inc, Boston (2002)
Tang, Y., Chowdhury, R.A., Kuszmaul, B.C., Luk, C.-K., Leiserson, C.E.: The pochoir stencil compiler. In: Fortnow L., Vadhan S.P. (eds.) SPAA, pp. 117–128. ACM (2011)
Valdes, J., Tarjan, R.E., Lawler, E.L.: The recognition of series parallel digraphs. In: Proceedings of the Eleventh Annual ACM Symposium on Theory of Computing, STOC ’79, pp. 1–12. ACM, New York (1979)
Acknowledgements
This work has partially been supported by the PIA ELCI project of the French FSN. This work was granted access to the HPC resources of TGCC under the allocations t2015067470, x2016067617 and AP010610191 made by GENCI.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Coullon, H., Bigot, J. & Perez, C. Extensibility and Composability of a Multi-Stencil Domain Specific Framework. Int J Parallel Prog 47, 1046–1085 (2019). https://doi.org/10.1007/s10766-017-0539-5
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10766-017-0539-5