
Abstract
Self-reports or professional interviews have typically been used to diagnose depression, although these methods often miss significant behavioral signals. Sometimes, people with depression may not express their feelings accurately, which can make it hard for psychologists to diagnose them correctly. We believe that paying attention to how people speak and behave can help us better identify depression. In real-life situations, psychologists can use different methods, like listening to how someone talks, their body language and change in their emotions while talking. To detect signs of depression more accurately authors presents MANOBAL, a system that analyzes voice, text, and facial expressions to detect depression. We use the DAIC-WoZ dataset, which was requested from the University of Southern California (UoS). We used this dataset for the multimodal depression detection model. Deep learning is challenged with such complicated data, therefore MANOBAL used a multimodal method. It uses elements from audio recordings, text, and facial expressions to predict both depression and its severity. This fusion has two advantages: first, it can substitute for uncertain data in one modality (such as voice) by using input from another (text, facial expressions). Second, it can give more weight to more dependable data sources, which improves accuracy. Small datasets are not very helpful when testing accuracy in fusion models, but MANOBAL overcomes this by exploiting DAIC-Woz dataset's transfer characteristics and increasing training labels. The initial results are encouraging, with a root mean square error of 0.168 for predicting depression severity. Experiments show the effectiveness of combining modalities. High-level features based on Mel Frequency Cepstral Coefficients (MFCC) give useful information on depression, but adding additional audio characteristics and facial action unit increases accuracy by 10% and 20%, respectively.












Similar content being viewed by others


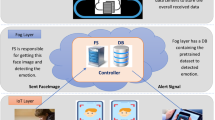
Data availability
Not Applicable.
References
Abbaschian, B.J., Sierra-Sosa, D., Elmaghraby, A.: Deep learning techniques for speech emotion recognition, from databases to models. Sensors 21(4), 1249 (2021). https://doi.org/10.3390/s21041249
Alanazi, S.A., et al.: Public’s mental health monitoring via sentimental analysis of financial text using machine learning techniques. Int. J. Environ. Res.s Public Health 19, 15 (2022). https://doi.org/10.3390/ijerph19159695
Babu, N.V., Kanaga, E.G.: Sentiment analysis in social media data for depression detection using artificial intelligence: a review. SN Comput. Sci. 3(1), 74 (2022). https://doi.org/10.1007/s42979-021-00958-1
Bota, P.J., Wang, C., Fred, A.L., Da Silva, H.P.: A review, current challenges, and future possibilities on emotion recognition using machine learning and physiological signals. IEEE Access 26(7), 140990–141020 (2019)
Campbell, F., Blank, L., Cantrell, A., Baxter, S., Blackmore, C., Dixon, J., Goyder, E.: Factors that influence mental health of university and college students in the UK: a systematic review. BMC Public Health 22(1), 1778 (2022). https://doi.org/10.1186/s12889-022-13943-x
Chung, J., Teo, J.: Mental Health prediction using machine learning: taxonomy, applications, and challenges. Appl. Comput. Intell. Soft Comput. 5(2022), 1–9 (2022). https://doi.org/10.1155/2022/9970363
Ehiabhi, J., Wang, H.: A systematic review of machine learning models in mental health analysis based on multi-channel multi-modal biometric signals. BioMedInformatics 3(1), 193–219 (2023). https://doi.org/10.3390/biomedinformatics3010014
Garcia-Ceja, E., Riegler, M., Nordgreen, T., Jakobsen, P., Oedegaard, K.J., Tørresen, J.: Mental health monitoring with multimodal sensing and machine learning: a survey. Pervasive Mobile Comput. 1(51), 1–26 (2018). https://doi.org/10.1016/j.pmcj.2018.09.003
Hernández-Torrano, D., Ibrayeva, L., Sparks, J., Lim, N., Clementi, A., Almukhambetova, A., Nurtayev, Y., Muratkyzy, A.: Mental health and well-being of university students: a bibliometric mapping of the literature. Front. Psychol. 9(11), 540000 (2020). https://doi.org/10.3389/fpsyg.2020.01226
Kazemitabar, M., Lajoie, S.P., Doleck, T.: Analysis of emotion regulation using posture, voice, and attention: a qualitative case study. Comput. Education Open 2, 100030 (2021). https://doi.org/10.1016/j.caeo.2021.100030
Khalil, R.A., Jones, E., Babar, M.I., Jan, T., Zafar, M.H., Alhussain, T.: Speech emotion recognition using deep learning techniques: a review. IEEE Access 7, 117327–117345 (2019). https://doi.org/10.1109/ACCESS.2019.2936124
Lin, L., Chen, X., Shen, Y., Zhang, L.: Towards automatic depression detection: a bilstm/1d cnn-based model. Appl. Sci. (switzerland) 10(23), 1–20 (2020). https://doi.org/10.3390/app10238701
Nandwani, P., Verma, R.: A review on sentiment analysis and emotion detection from text. Soc. Netw. Anal. Mining 11(1), 81 (2021). https://doi.org/10.1007/s13278-021-00776-6
Rahman, R.A., Omar, K., Noah, S.A.M., Danuri, M.S.N.M., Al-Garadi, M.A.: Application of machine learning methods in mental health detection: a systematic review. IEEE Access 8, 183952–183964 (2020). https://doi.org/10.1109/ACCESS.2020.3029154
Rai, B.K.: BBTCD: blockchain based traceability of counterfeited drugs. Health Serv Outcomes Res Methodol 23(3), 337–353 (2023)
Rai, B.K., Fatima, S., Satyarth, K.: Patient-centric multichain healthcare record. Int. J.E-Health Med. Commun. (IJEHMC) 13(4), 1–4 (2022). https://doi.org/10.4018/IJEHMC.309439
Rai, B. K., Kumar, G., and Balyan, V. Eds., “AI and Blockchain in Healthcare,” 2023, doi: https://doi.org/10.1007/978-981-99-0377-1.
Shatte, A.B., Hutchinson, D.M., Teague, S.J.: Machine learning in mental health: a scoping review of methods and applications. Psychol. Med. 49(9), 1426–1448 (2019)
Tavabi, L.: “Multimodal machine learning for interactive mental health therapy,” In: ICMI 2019 - Proceedings of the 2019 International Conference on Multimodal Interaction, Association for Computing Machinery, Inc, Oct. 2019, pp. 453–456. doi: https://doi.org/10.1145/3340555.3356095.
Thieme, A., Belgrave, D., Doherty, G.: Machine learning in mental health: a systematic review of the HCI literature to support the development of effective and implementable ML systems. ACM Transact. Comput.-Human Interact. (TOCHI) 27(5), 1–53 (2020)
Xie, W. et al., “Interpreting Depression from Question-wise Long-term Video Recording of SDS Evaluation,” Jun. 2021. http://arxiv.org/abs/2106.13393
Funding
This work was not funded.
Author information
Authors and Affiliations
Contributions
IJ, BT and AS have done review work. BKR and IJ wrote the proposed work. All authors reviewed the manuscript.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare no conflict of interest associated with this study.
Ethical approval
Not applicable.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Rai, B.K., Jain, I., Tiwari, B. et al. Multimodal mental state analysis. Health Serv Outcomes Res Method (2024). https://doi.org/10.1007/s10742-024-00329-2
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s10742-024-00329-2