
Abstract
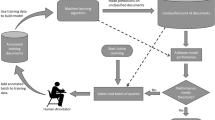
Machine learning and natural language processing algorithms are currently widely used to retrieve relevant documents in a variety of contexts, including literature review and systematic review. Supervised machine learning algorithms perform well in terms of retrieval metrics such as recall and precision, but require the use of a sizeable training dataset, which is typically expensive to develop. Unsupervised machine learning algorithms do not require a training dataset and may perform well in terms of recall, but are typically lower in precision, and do not offer a transparent means for decision-makers to justify selection choices. In this paper, we illustrate the use of a hybrid document classification method based on semi-supervised learning that we refer to as “supervised clustering.” We show that supervised clustering combines the ease of use of unsupervised algorithms with the retrieval efficiency and transparency of supervised algorithms. We demonstrate through simulations the high performance and unbiased predictions of supervised clustering when provided even with only minimal training data. We further propose the use of ensemble learning as a means to maximize retrieval efficiency and to prioritize the review of those documents that are not eliminated by the supervised clustering algorithm.





Similar content being viewed by others

References
Albalate A, Suchindranath A, Suendermann D, Minker W (2010) A semi-supervised cluster-and-label approach for utterance classification. In: Workshop proceedings of the 6th international conference on intelligent environments, pp 61–70
Aphinyanaphongs Y, Tsamardinos I, Statnikov A, Hardin D, Aliferis CF (2005) Text categorization models for high-quality article retrieval in internal medicine. J Am Med Inform Assoc 12:207–216
Bekhuis Tanja, Demner-Fushman Dina (2012) Screening nonrandomized studies for medical systematic reviews: a comparative study of classifiers. Artif Intell Med 55(3):197–207
Bishop CM (2006) Pattern Recognition and Machine Learning., vol 1. New York, Springer
Blei DM, Ng AY, Jordan MI (2003) Latent dirichlet allocation. J Mach Learn Res 3:993–1022
Chang C-C, Lin C-J (2011) LIBSVM: a library for support vector machines. ACM Trans Intell Syst Technol 2:1–39
Chapelle O, Scholkopf B, Zien A (2006) Semi-supervised learning. MIT Press, Cambridge
Cohen AM, Hersh WR, Peterson K, Yen P-Y (2006) Reducing workload in systematic review preparation using automated citation classification. J Am Med Inform Assoc 13:206–219
Cohen AM, Ambert K, McDonagh M (2012) Studying the potential impact of automated document classification on scheduling a systematic review update. BMC Med Inform Decis Mak 12(1):33
Dasarathy BV (1991) Nearest neighbour (NN) norms: NN pattern classification techniques. IEEE Computer Society Press, Los Alamitos
Devarajan K (2008) Nonnegative matrix factorization: an analytical and interpretive tool in computational biology. PLoS Comput Biol 4:e1000029
Dietterich TG (2000) Ensemble methods in machine learning. International workshop on multiple classifier systems. Springer, Berlin
Frunza O, Inkpen D, Matwin S, Klement W, O’blenis P (2011) Exploiting the systematic review protocol for classification of medical abstracts. Artif Intell Med 51:17–25
Goutte C, Gaussier E (2005) A probabilistic interpretation of precision, recall and F-score, with implication for evaluation. In: Losada DE, Fernández-Luna JM (eds) Proceedings of advances in information retrieval: 27th European conference on IR research. Springer, Santiago de Compostela, pp 345–359
Harris ZS (1954) Distributional structure. WORD 10:146–162
Hastie T, Tibshirani R, Friedman J (2009) The elements of statistical learning: data mining, inference, and Prediction. Springer, New York
Haynes RB, Wilczynski N, McKibbon KA, Walker CJ, Sinclair JC (1994) Developing optimal search strategies for detecting clinically sound studies in MEDLINE. J Am Med Inform Assoc 1:447–458
Ingersoll GS, Morton TS, Farris AL (2013) Taming text: how to find, organize, and manipulate it. Manning Publications Co., Greenwich
Jonnalagadda S, Petitti D (2013) A new iterative method to reduce workload in systematic review process. Int J Comput Biol Drug Des 6:5–17
Larsen RJ, Marx ML (2001) An introduction to mathematical statistics and its applications. Prentice Hall, Upper Saddle River, NJ
Le QV, Mikolov T (2014) Distributed representations of sentences and documents. In: Proceedings of the 31st international conference on machine learning, Bejing, pp 1188–1196
Li B, Yu S, Lu Q (2003) An improved k-nearest neighbor algorithm for text categorization. In: Proceedings of the 20th international conference on computer processing of oriental languages, Shenyang
Manning CD, Raghavan P, Schütze H (2008) Introduction to information retrieval. Cambridge University Press, Cambridge
O’Mara-Eves A, Thomas J, McNaught J, Miwa M, Ananiadou S (2015) Using text mining for study identification in systematic reviews: a systematic review of current approaches. Syst Rev 4:5
Pedregosa F, Varoquaux G, Gramfort A, Michel V, Thirion B, Grisel O, Blondel M, Prettenhofer P, Weiss R, Dubourg V (2011) Scikit-learn: machine learning in Python. J Mach Learn Res 12:2825–2830
Python Software Foundation. Python language reference (version 2.7)
Shemilt I et al (2014) Pinpointing needles in giant haystacks: use of text mining to reduce impractical screening workload in extremely large scoping reviews. Res Synth Methods 5(1):31–49
US EPA (2015) IRIS toxicological review of Dibutyl phthalate (Dbp) (preliminary assessment materials). US Environmental Protection Agency, Washington, DC, EPA/635/R-13/302
Wallace BC, Trikalinos TA, Lau J, Brodley C, Schmid CH (2010) Semi-automated screening of biomedical citations for systematic reviews. BMC Bioinform 11:55
Webb AR (2002) Statistical pattern recognition. Wiley, New York
Zhu X, Goldberg AB (2009) Introduction to semi-supervised learning. Synthesis lectures on artificial intelligence and machine learning. Morgan and Claypool Publishers, Los Altos
Acknowledgements
The development of the methods presented here was fully supported by ICF. The results presented here were generated for the purposes of this paper alone. The authors acknowledge EPA and NIEHS for supporting the application of the supervised clustering method in work the authors have performed for these agencies in a contracting capacity as employees of ICF since 2015.
Author information
Authors and Affiliations
Corresponding author
Electronic supplementary material
Below is the link to the electronic supplementary material.
Rights and permissions
About this article

Cite this article
Varghese, A., Cawley, M. & Hong, T. Supervised clustering for automated document classification and prioritization: a case study using toxicological abstracts. Environ Syst Decis 38, 398–414 (2018). https://doi.org/10.1007/s10669-017-9670-5
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10669-017-9670-5