
Abstract
This paper provides a novel, simple, and computationally tractable method for determining an identified set that can account for a broad set of economic models when the economic variables are discrete. Using this method, we show using a simple example how imperfect instruments affect the size of the identified set when the assumption of strict exogeneity is relaxed. This knowledge can be of great value, as it is interesting to know the extent to which the exogeneity assumption drives results, given it is often a matter of some controversy. Moreover, the flexibility obtained from our newly proposed method suggests that the determination of the identified set need no longer be application specific, with the analysis presenting a unifying framework that algorithmically approaches the question of identification.














Similar content being viewed by others
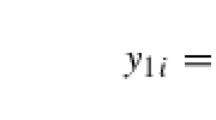


Notes
With some modification.
Therefore for all open subsets A of
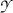 ,
,  is well defined.
is well defined.This statement is true only under additional assumptions, e.g. rank conditions, support conditions or completeness conditions.
This is Definition 1 in Galichon and Henry (2009).
The parameter \(\theta \) may consist of two parts, \(\theta = [\theta _1,\theta _2]\), so we can have \(G_{\theta _1}\) and \(\nu _{\theta _2}\).
Definition 2 in Galichon and Henry (2009), where the dependence of the identified set \(\Theta _{I}(p)\) on the distribution of observable variables p is made explicit.
The dependence of \(c_{ij}\) and \(\nu _j\) on parameter \(\theta \) is omitted for the sake of brevity.
We may be willing to make some assumptions about the distribution of variables in the form of moment equality or inequality. It is important to note here that the GH setup can handle moment inequalities \(E(\phi (Y))\le 0\) if \(E(m(U))=0\) is assumed (Ekeland et al. 2010). In this case, the correspondence G is restricted to take a specific form. However, within the GH framework, it is not possible to consider moment inequality and further information given by G.
If the observed variable is multidimensional we can stack it into a single vector. Summing across some sets of indices then allows us to formulate a restriction for only one dimension. As an example, suppose that the observed variables are (Y, X, Z); then, we can place a restriction on X only, so that X is independent of U.
The manner in which the independency restriction is relaxed is discussed in Sect. 4.
It is possible to determine the lower and upper bound of the threshold-crossing function t(X) without making this parametric assumption as in Chesher (2009), but instead assuming the monotonicity of t(X). For the sake of simplicity, we present the parametric example.
We could also assume that we observe the probability of Y, X given Z, such that for the sake of exposition, the probability of (Y, X, Z) is known.
In this case, parameter \(\theta \) affects the support restrictions (10) only.
Note that even though \(\pi \) is four dimensional, the problem still lies within the linear programming framework, as the elements of \(\pi \) can be stacked to make a vector of size \(n_Y \cdot n_X \cdot n_Z \cdot n_U\).
In order to avoid confusion with the probabilities \(p_{ijk}\) of the observed variables, the threshold-crossing function is denoted t(.) unlike in Chesher (2009), who set it as p(.).
The meaning with the second-last restriction is omitted: \(\sum _{i,j} \pi _{ijkl} = \sum _{i,j} p_{ijk} \nu _l \ \ \forall k,l\).
From Lemma 2, we can see that this interpretation is unaffected by the discretization of the unobserved variables.
\(ACE(D \rightarrow Y) = Pr(Y = y_1|D = d_1) - Pr(Y = y_1|D = d_0) = Pr(R_Y=1) + Pr(R_Y=2) -(Pr(R_Y=2)+Pr(R_Y=3)) = Pr(R_Y=1)-Pr(R_Y=3)\).
Instrument Z only affects Y via D: \(Pr(Y|D,Z,R_Y,R_D) = Pr(Y|D,R_Y,R_D)\), and this equation can be reformulated as \(Pr(Y,D,Z,r_Y,r_D)Pr(D,R_Y,R_D)=Pr(Y,D,r_Y,r_D)Pr(D,Z,R_Y,R_D)\).
As with exogenous instruments, the marginal distribution of X does not have any identifying power.
The observed probabilities \(p_{ijk}\) were obtained using the Matlab function mvtnorm.
Excluding the \(0\%\) and \(100\%\) quantiles.
As in Example 1, the distribution of exogenous variables per se does not have any identifying power. It is included purely for the simplicity of the exposition.
This is a 4-dimensional array \(\pi _{ijkl}\) stacked into a vector.
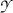 ,
,  is well defined.
is well defined.References
Andrews, D. W. K., & Shi, X. (2013). Inference based on conditional moment inequalities. Econometrica, 81, 609–666.
Angrist, J., Bettinger, E., Bloom, E., King, E., & Kremer, M. (2002). Vouchers for private schooling in Colombia: Evidence from a randomized natural experiment. The American Economic Review, 92, 1535–1558.
Artstein, Z. (1983). Distributions of random sets and random selections. Israel Journal of Mathematics, 46, 313–324.
Balke, A., & Pearl, J. (1994). Counterfactual probabilities: Computational Methods, bounds, and applications. In L. R. de Mantaras & D. Poole (Eds.), Uncertainty in artificial intelligence 10 (pp. 46–54). Burlington: Morgan Kaufmann.
Balke, A., & Pearl, J. (1997). Bounds on treatment effects from studies with imperfect compliance. Journal of the American Statistical Association, 439, 1172–1176.
Beresteanu, A., Molchanov, I., & Molinari, F. (2011). Sharp identification regions in models with convex moment predictions. Econometrica, 79, 1785–1821.
Beresteanu, A., Molchanov, I., & Molinari, F. (2012). Partial identification using random set theory. Journal of Econometrics, 166, 17–32.
Beresteanu, A., & Molinari, F. (2008). Asymptotic properties for a class of partially identified models. Econometrica, 76, 763–814.
Boykov, Y., & Kolmogorov, V. (2001). An experimental comparison of min-cut/max-flow algorithms for energy minimization in vision. IEEE Transactions on Pattern Analysis and Machine Intelligence, 26, 359–374.
Brock, W. A., & Durlauf, S. N. (2001). Discrete choice with social interactions. Review of Economic Studies, 68, 235–260.
Bugni, F. A. (2010). Bootstrap inference in partially identified models defined by moment inequalities: Coverage of the identified set. Econometrica, 78, 735–753.
Chernozhukov, V., Hansen, C., & Jansson, M. (2009). Finite sample inference for quantile regression models. Journal of Econometrics, 152, 93–103.
Chernozhukov, V., Hong, H., & Tamer, E. (2007). Estimation and confidence regions for parameter sets in econometric models 1. Econometrica, 75, 1243–1284.
Chernozhukov, V., Lee, S., & Rosen, A. M. (2013). Intersection bounds: Estimation and inference. Econometrica, 81, 667–737.
Chesher, A. (2009). Single equation endogenous binary reponse models. In CeMMAP working papers CWP23/09, Centre for Microdata Methods and Practice, Institute for Fiscal Studies.
Chesher, A. (2010). Instrumental variable models for discrete outcomes. Econometrica, 78, 575–601.
Chesher, A., Rosen, A. M., & Smolinski, K. (2013). An instrumental variable model of multiple discrete choice. Quantitative Economics, 4, 157–196.
Chiburis, R. C. (2010). Bounds on treatment effects using many types of monotonicity. Unpublished manuscript.
Conley, T. G., Hansen, C. B., & Rossi, P. E. (2012). Plausibly exogenous. Review of Economics and Statistics, 94, 260–272.
Ekeland, I., Galichon, A., & Henry, M. (2010). Optimal transportation and the falsifiability of incompletely specified economic models. Economic Theory, 42, 355–374.
Freyberger, J., & Horowitz, J. L. (2015). Identification and shape restrictions in nonparametric instrumental variables estimation. Journal of Econometrics, 189, 41–53.
Galichon, A., & Henry, M. (2009). A test of non-identifying restrictions and confidence regions for partially identified parameters. Journal of Econometrics, 152, 186–196.
Galichon, A., & Henry, M. (2011). Set identification in models with multiple equilibria. Review of Economic Studies, 78(4), 1264–1298.
Goldberg, A. V., Tarjan, R. E. (1986). A new approach to the maximum flow problem. In: Proceedings of the eighteenth annual ACM symposium on Theory of computing, New York, NY, USA: ACM, STOC ’86, pp. 136–146.
Hahn, J., & Hausman, J. (2005). Estimation with valid and invalid instruments. Annals of Economics and Statistics/Annales d’Économie et de Statistique, 79–80, 25–57.
Henry, M., Meango, R., & Queyranne, M. (2015). Combinatorial approach to inference in partially identified incomplete structural models. Quantitative Economics, 6, 499–529.
Honoré, B. E., & Tamer, E. (2006). Bounds on parameters in panel dynamic discrete choice models. Econometrica, 74, 611–629.
Huber, M., Laffers, L., & Mellace, G. (2017). Sharp IV bounds on average treatment effects on the treated and other populations under endogeneity and noncompliance. Journal of Applied Econometrics, 32, 56–79.
Imbens, G. W., & Angrist, J. D. (1994). Identification and estimation of local average treatment effects. Econometrica, 62, 467–475.
Imbens, G. W., & Manski, C. F. (2004). Confidence intervals for partially identified parameters. Econometrica, 72, 1845–1857.
Komarova, T. (2013). Binary choice models with discrete regressors: Identification and misspecification. Journal of Econometrics, 177, 14–33.
Laffers, L. (2013). A note on bounding average treatment effects. Economics Letters, 120, 424–428.
Laffers, L. (2015). Bounding average treatment effects using linear programming. Unpublished manuscript.
Lee, D. S. (2009). Training, wages, and sample selection: Estimating sharp bounds on treatment effects. The Review of Economic Studies, 76, 1071–1102.
Manski, C. F. (1990). Nonparametric bounds on treatment effects. American Economic Review, 80, 319–23.
Manski, C. F. (1995). Identification problems in the social sciences. Cambridge: Harvard University Press.
Manski, C. F. (2003). Partial identification of probability distributions. New York: Springer.
Manski, C. F. (2007). Partial identification of counterfactual choice probabilities. International Economic Review, 48, 1393–1410.
Manski, C. F. (2008). Partial identification in econometrics. In S. N. Durlauf & L. E. Blume (Eds.), The new palgrave dictionary of economics. Basingstoke: Palgrave Macmillan.
Manski, C. F., & Pepper, J. V. (2000). Monotone instrumental variables, with an application to the returns to schooling. Econometrica, 68, 997–1012.
Manski, C. F., & Thompson, T. S. (1986). Operational characteristics of maximum score estimation. Journal of Econometrics, 32, 85–108.
Nevo, A., & Rosen, A. M. (2012). Identification with imperfect instruments. Review of Economics and Statistics, 93, 127–137.
Papadimitriou, C. H., & Steiglitz, K. (1998). Combinatorial optimization; algorithms and complexity. New York: Dover Publications.
Romano, J. P., & Shaikh, A. M. (2010). Inference for the identified set in partially identified econometric models. Econometrica, 78, 169–211.
Rosen, A. M. (2008). Confidence sets for partially identified parameters that satisfy a finite number of moment inequalities. Journal of Econometrics, 146, 107–117.
Rubin, D. B. (1974). Estimating causal effects of treatments in randomized and nonrandomized studies. Journal of Educational Psychology, 66, 688–701.
Shaikh, A. M., & Vytlacil, E. J. (2011). Partial identification in triangular systems of equations with binary dependent variables. Econometrica, 79, 949–955.
Tamer, E. T. (2010). Partial identification in econometrics. Annual Review of Economics, 2, 167–195.
Acknowledgements
This research was supported by VEGA grant 1/0843/17. This paper is a revised chapter from my 2014 dissertation at the Norwegian School of Economics.
Author information
Authors and Affiliations
Corresponding author
Appendices
A Proofs
1.1 A.1 Proof of Lemma 1
Proof
We need to show that there exists  satisfying:
satisfying:

if and only if there exists  satisfying:
satisfying:
“\((\Rightarrow )\)” - Given \(\pi _1\), we construct \(\pi _2\) according to:

and this will ensure that {(C1),(C2),(C3M),(C4M),(C5)} implies {(D1),(D2),(D3M),(D4M),(D5)} as shown below:


“\((\Leftarrow )\)” - If we know \(\pi _2\), we obtain \(\pi _1\) using:

(note that (\(\Pi _1\)) implies (\(\Pi _2\))) and we now show that {(D1), (D2), (D3M), (D4M), (D5)} implies {(C1), (C2), (C3M), (C4M), (C5)}:

1.2 A.2 Proof of Lemma 2
Proof
Similarly to the proof of Lemma 1, we need to show that there exists  satisfying (C1), (C2), (C5) and:
satisfying (C1), (C2), (C5) and:

if and only if there exists  satisfying (D1), (D2), (D5) and:
satisfying (D1), (D2), (D5) and:

“\((\Rightarrow )\)” - Given \(\pi _1\), we construct \(\pi _2\) according to:

and this will ensure that {(C1), (C2), (C3M), (C4M), (C5)} imply {(D1), (D2), (D3M), (D4M), (D5)}. Because the partitioning of the  space using (PartU2) is finer than that using (PartU1), we find that {(C1), (C2), (C5)}, implying {(D1), (D2), (D5)} immediately using the proof of Lemma 1. It is therefore sufficient to show that {(C3M), (C4M)} imply {(D3M), (D4M)}:
space using (PartU2) is finer than that using (PartU1), we find that {(C1), (C2), (C5)}, implying {(D1), (D2), (D5)} immediately using the proof of Lemma 1. It is therefore sufficient to show that {(C3M), (C4M)} imply {(D3M), (D4M)}:


“\((\Leftarrow )\)” - Knowing \(\pi _2\), we obtain \(\pi _1\) using:

where \(\gamma \) is an arbitrary strictly positive probability density function. It is now sufficient to show that {(D3M),(D4M) (D5)} imply {(C3M),(C4M),(C5)}, because the proof of Lemma 1 reveals that {(C1),(C2)} imply {(D1),(D2)} and (PartU2) provides a finer discretization of  than does (PartU1):
than does (PartU1):


B Technical Details on the Presented Examples
1.1 B.1 Example 1
1.1.1 B.1.1 Chesher’s Approach
In order to present the identification result from Chesher (2009), we first introduce the basic definitions. The notation used differs from that in GH that is employed in the present study.
-
A model
 is defined as (10) with \(U \sim Unif(0,1)\) and
is defined as (10) with \(U \sim Unif(0,1)\) and 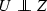 for all
for all  .
. -
A structure\(S \equiv \{t, F_{UX|Z}\}\) is a pair of a threshold-crossing function t and a cumulative distribution function of the conditional distribution of U and X given Z.
-
A structure S is said to be admitted by a model
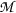 if \(F_{UX|Z}\) respects the independence property, that is \(F_U(u|z)\equiv F_{UX|Z}(u,\bar{x}|z)=u\) for all \(u \in (0,1)\) and all
if \(F_{UX|Z}\) respects the independence property, that is \(F_U(u|z)\equiv F_{UX|Z}(u,\bar{x}|z)=u\) for all \(u \in (0,1)\) and all 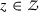 , where \(\bar{x}\) is the upper bound of X.
, where \(\bar{x}\) is the upper bound of X. -
A structure Sgenerates the joint distribution of Y and X given Z if \(F_{YX|Z}(0,x|z)=F_{UX|Z}(t(x),x|z)\).
-
Two structures \(S^* \equiv \{t^*, F^*_{UX|Z}\}\) and \(S^0 \equiv \{t^0, F^0_{UX|Z}\}\) are said to be observationally equivalent if they generate the same distribution of Y and X given Z for all
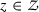 , that is if \(F^*_{YX|Z}(0,x|z) \equiv F^*_{UX|Z}(t^*(x),x|z) = F^0_{YX|Z}(0,x|z) \equiv F^0_{UX|Z}(t^0(x),x|z)\) for all
, that is if \(F^*_{YX|Z}(0,x|z) \equiv F^*_{UX|Z}(t^*(x),x|z) = F^0_{YX|Z}(0,x|z) \equiv F^0_{UX|Z}(t^0(x),x|z)\) for all 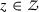 and for all
and for all 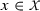 .
.
 is defined as (
is defined as (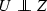 for all
for all  .
.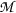 if
if 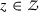 , where
, where 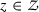 , that is if
, that is if 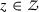 and for all
and for all 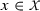 .
.Theorem 1 from Chesher (2009) states that having a structure \(S_0\) admitted by the model  that generates the conditional distribution of Y and X given Z with cumulative distribution function \(F^0_{YX|Z}\) and if this threshold-crossing function t is in structure S admitted by model
that generates the conditional distribution of Y and X given Z with cumulative distribution function \(F^0_{YX|Z}\) and if this threshold-crossing function t is in structure S admitted by model  that is observationally equivalent to \(S^0\), then t satisfies:
that is observationally equivalent to \(S^0\), then t satisfies:


where \(Pr_0\) states that probabilities were calculated using the measure that was generated by \(S^0\), that is using \(F^0_{YX|Z}\) and l and u stand for the lower and upper bound, respectively.
Given the continuity of X, the converse is also true. This is equivalent to saying that the set of all functions p satisfying the above set of inequalities is a sharply defined identified set. In Chesher (2010), this theorem is proven, even for a more general setup. It is important to note that the proof is constructive, so that for a given threshold-crossing function t, a suitable distribution function \(F_{UX|Z}\) is constructed such that \(\{t,F_{UX|Z}\}\) is admitted by the model  and generates the \(F_{YX|Z}\) observed in the data. This highlights the link to the GH setup, as the aim there is to find the joint probability distribution that satisfies the independence restriction, has correct marginals, and places all the probability on those combinations of variables that are compatible with the data.
and generates the \(F_{YX|Z}\) observed in the data. This highlights the link to the GH setup, as the aim there is to find the joint probability distribution that satisfies the independence restriction, has correct marginals, and places all the probability on those combinations of variables that are compatible with the data.
1.1.2 B.1.2 Illustration: Discrete Endogenous Variable
1.1.3 Construction of True Data-generating Process
The following example is taken from Chesher (2010). Suppose that both Y and X are binary; \(Y \equiv 1(Y^* \ge 0)\) and \(X \equiv 1(X^* \ge 0)\), where \(Y^*\) and \(X^*\) were generated in the following way:

with parameters:
and the instrument Z takes values in  .
.
However, the econometrician does not know how the data were generated. She only assumes (10) and  , \(U \sim Unif(0,1)\), \(t(X) = \Phi (-\theta _0 - \theta _1 X)\), and observes the distribution of the observable variables \(p_{ijk}\).Footnote 22 Even though it is impossible to recover the true value of \(\theta = (0,0.5)\) exactly, it is possible to at least create informative bounds for it.
, \(U \sim Unif(0,1)\), \(t(X) = \Phi (-\theta _0 - \theta _1 X)\), and observes the distribution of the observable variables \(p_{ijk}\).Footnote 22 Even though it is impossible to recover the true value of \(\theta = (0,0.5)\) exactly, it is possible to at least create informative bounds for it.
As the X threshold-crossing function t attains only two values, \(t(0)=\Phi (-\theta _0) = 0.5\) and \(t(1)=\Phi (-\theta _0-\theta _1)=0.308\).
1.1.4 B.1.3 Illustration: Continuous Endogenous Variable
1.1.5 Construction of the True Data-Generating Process
Suppose that the economic model is described by (10) and the data-generating process by (21) with the parameters:
as before, the only difference being that X is no longer binary (\(X=X^*)\).
The distribution of the observable variables \((Y^*,X|Z=z)\) (\(Y^*\) and X given \(Z=z\)) is given by \(N(\mu (z),\Sigma )\), where:
We provide details of the simulations here. Because of the continuity of X, the unobservable U was discretized as the equidistant point masses on [0, 1]. The distribution of observables is given by:
It is known that \((Y^*,X|Z) \sim N(\mu (z),\Sigma )\) and a suitable discretization of X is needed. It is easy to show that the density of \((Y^*|X=x,Z=z)\) is:
Integrating the corresponding probability density function at (\(-\infty \),0) gives us \(Pr(Y=0|X=x,Z=z)\). The distribution of X given \(Z=z\) is \(N(b_0+b_1 z,s_{vv})\), but now the question is how to discretize the support of X, which is \(\mathbb {R}\). If the number of nodes is \(n_x\), then one suggestion would be to set the z to its mean value, that is 0, and set the values of the discretized support of X to \(n_x\) equidistant quantiles.Footnote 23 Even though this discretization appears natural, it brings some degree of arbitrariness to the problem.
Finally, taking all the pieces together yields:
where all quantities on the right-hand side are known.
1.2 B.2 Example 2
1.2.1 B.2.1 Illustration
1.2.2 True Data-Generating Process
For the illustration, \((\epsilon _1,\epsilon _2)\) are assumed to be \(N(0,I_2)\). This assumption, together with (13) and (14), generates the distribution of Y and D given X and Z. The support of Z is assumed to be \(\{-1,1\}\) and the support of X is either \(\{0\}\) or \(\{-2,-1,0,1,2\}\). (X, Z) are assumed to be uniformly distributed.Footnote 24
1.3 B.3 Example 3
1.3.1 B.3.1 Balke and Pearl’s Approach
Balke and Pearl (1997) made use of the fact that these restrictions impose the following decomposition on the joint distribution of (Y, D, Z, U):
There exist four different functions from Z to D and four different functions from D to Y, hence 16 different types of individuals that we can consider. Hence, one can think of U as having a discrete support with 16 points, each point representing a pair of functions, one from Z to D and the second from D to Y. For instance, one type u may be persons who always accept treatment and who do not display a positive outcome irrespective of treatment. The bounds on (15) are found using linear program searching through the space of distributions of the types (U) subject to the joint distribution to be compatible with observed data Pr(y, d|z). The full setup, together with discussion, is in Balke and Pearl (1997, 1994).
1.4 B.4 Example 4
1.4.1 B.4.1 Komarova’s Approach
Following Manski and Thompson (1986):
together with the zero-median restriction (17), implies:
Therefore, the bounds on the parameter vector \(\beta \) are obtained as an intersection of linear half spaces. In Komarova (2013), a recursive procedure is proposed that translates this set of linear inequalities into bounds on the parameters.
C Implementation Issues
1.1 C.1 Extended GH Framework
Following routines were used and compared in order to solve linear program (12).
-
linprogFootnote 25—Matlab built in function from Optimization Toolbox. Interior point method was superior to simplex method because of the computational time. Since the objective value is not minimized to exact zeros, certain threshold had to be employed. Natural choice is the tolerance level of the optimization routine (\(10^{-8}\) for \(n_x = n_u = 40\) was used). Results for the two approaches were identical.
-
GNU Linear Programming Kit (GLPK)—Modified simplex method from Matlab MEX interface for the GLPK library.Footnote 26 Significantly faster than linprog with similar results.
Linear program is an old and well understood problem however if the discretization of X and U is large then the matrix that encodes the restrictions for the joint distribution can reach the limits of Matlab’s largest array that can be created.Footnote 27 For instance if the sizes of supports are \(n_x = n_u = 50\) together with \(n_y=2\) and \(n_z=30\), then the joint probability \(\pi _{ijkl}\) has 150, 000 elements. So that the matrix that carries the information about restrictions on \(\pi _{ijkl}\) will have 150, 000 columns. This is not a large problem, but the complexity grows exponentially with additional covariates. The most time consuming part is creating the matrices of equalities and inequalities that define the linear program. The computational burden is further increased when resampling methods, such as subsampling, are used for statistical inference. All these reasons allow us only to consider small problems, those with one or two parameters of interest.
1.2 C.2 Original GH Approach
Since the formulation is also a linear program both linprog and GLPK can be used. In addition to these two functions optimal transportation structure can be exploited and more efficient algorithms can be applied. Galichon and Henry (2011) refer to the link between optimal transportation and maximum flow problem studied in Papadimitriou and Steiglitz (1998). If the capacities \(\{\nu _j\},\{p_i\}\) of the arcs are the probabilities of the observables and unobservables respectively and the arcs with infinite capacity are between the values of the observables and unobservables that satisfy the economic model (\(y_i \in G_\theta (u_j)\) or \(c_{ij}=0\)), then the question of feasibility of the economic model reduces to checking whether the maximum flow is equal to one. The maximum flow formulation is illustrated on Fig. 15.

Reproduced from the Figures 7–8 from Papadimitriou and Steiglitz (1998) p. 145
These two algorithms are readily available
-
maxflow of M. Rubinstein implements Boykov and Kolmogorov max-flow/min-cut algorithm (Boykov and Kolmogorov 2001).Footnote 28
-
max_flow from Matlab Boost Graph Library written by D. Gleich implements push-relabel maximum flow algorithm of Goldberg and Tarjan (1986).Footnote 29
These combinatorial algorithms are computationaly very effective, indeed, the most challenging task is to efficiently implement the creation of the matrix that defines the graph. Since this matrix is smaller that the one from linear program, finer discretization can be employed if necessary. Even for very fine discretization maximum flow was calculated in a fraction of a second.
Rights and permissions
About this article

Cite this article
Lafférs, L. Identification in Models with Discrete Variables. Comput Econ 53, 657–696 (2019). https://doi.org/10.1007/s10614-017-9758-5
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10614-017-9758-5