
Abstract
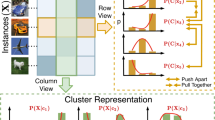
Contrastive learning has become one of the most important representation learning methods because it does not require data to be labeled. However, current contrast learning treats different negative instances equally as being pushed away evenly in the representation space. Intuitively, the impact of different classes of instances in the representation space is different. Therefore, in this paper, we combine contrastive learning and clustering to propose a prototypical contrastive learning (ProCL) for image classification. Specifically, ProCL performs representation learning by clustering semantically similar images into the same group and encouraging clustering consistency between different augmentations of the same image. For a given image, sampling is performed from different clusters in order to ensure semantic differences from negative samples. Moreover, the gaps in semantic information between the prototypes (clustering center) differ, ProCL further weights the negative samples according to the distance between the prototypes, so that those negative samples with appropriate prototype distances have larger weights. This weighting strategy proves to be more effective. The experimental results in several benchmarks demonstrate that ProCL has strong competitive performance.



Similar content being viewed by others


Data availability
Enquiries about data availability should be directed to the authors.
References
Krizhevsky, A., Sutskever, I., Hinton, G.E.: Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 25, 84–90 (2012)
Simonyan, K., Zisserman, A.: Very deep convolutional networks for large-scale image recognition. arXiv:1409.1556 (2014)
Szegedy, C., Liu, W., Jia, Y., Sermanet, P., Reed, S., Anguelov, D., Erhan, D., Vanhoucke, V., Rabinovich, A.: Going deeper with convolutions. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 1–9 (2015)
He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 770–778 (2016)
Huang, G., Liu, Z., Van Der Maaten, L., Weinberger, K.Q.: Densely connected convolutional networks. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 4700–4708 (2017)
Wu, Z., Xiong, Y., Yu, S.X., Lin, D.: Unsupervised feature learning via non-parametric instance discrimination. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 3733–3742 (2018)
He, K., Fan, H., Wu, Y., Xie, S., Girshick, R.: Momentum contrast for unsupervised visual representation learning. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 9729–9738 (2020)
Chen, X., Fan, H., Girshick, R., He, K.: Improved baselines with momentum contrastive learning. arXiv:2003.04297 (2020)
Misra, I., Maaten, L.V.d.: Self-supervised learning of pretext-invariant representations. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 6707–6717 (2020)
Chen, T., Kornblith, S., Norouzi, M., Hinton, G.: A simple framework for contrastive learning of visual representations. In: International conference on machine learning, pp. 1597–1607. PMLR (2020)
Chen, T., Kornblith, S., Swersky, K., Norouzi, M., Hinton, G.E.: Big self-supervised models are strong semi-supervised learners. Adv. Neural. Inf. Process. Syst. 33, 22243–22255 (2020)
Tian, Y., Sun, C., Poole, B., Krishnan, D., Schmid, C., Isola, P.: What makes for good views for contrastive learning? Adv. Neural. Inf. Process. Syst. 33, 6827–6839 (2020)
Grill, J.-B., Strub, F., Altché, F., Tallec, C., Richemond, P., Buchatskaya, E., Doersch, C., Avila Pires, B., Guo, Z., Gheshlaghi Azar, M.: Bootstrap your own latent-a new approach to self-supervised learning. Adv. Neural. Inf. Process. Syst. 33, 21271–21284 (2020)
Li, J., Zhou, P., Xiong, C., Hoi, S.C.: Prototypical contrastive learning of unsupervised representations. arXiv:2005.04966 (2020)
Asano, Y.M., Rupprecht, C., Vedaldi, A.: Self-labelling via simultaneous clustering and representation learning. arXiv:1911.05371 (2019)
Caron, M., Bojanowski, P., Joulin, A., Douze, M.: Deep clustering for unsupervised learning of visual features. In: Proceedings of the European conference on computer vision (ECCV), pp. 132–149 (2018)
Caron, M., Misra, I., Mairal, J., Goyal, P., Bojanowski, P., Joulin, A.: Unsupervised learning of visual features by contrasting cluster assignments. Adv. Neural. Inf. Process. Syst. 33, 9912–9924 (2020)
Li, J., Zhou, P., Xiong, C., Socher, R., Hoi, S.: Prototypical contrastive learning of unsupervised representations (2020)
Lin, S., Liu, C., Zhou, P., Hu, Z.-Y., Wang, S., Zhao, R., Zheng, Y., Lin, L., Xing, E., Liang, X.: Prototypical graph contrastive learning. IEEE Trans. Neural Netw. Learn. Syst. (2022)
Goodfellow, I., PougeAbadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., Courville, A., Bengio, Y.: Generative adversarial nets. Adv. Neural Inf. Process. Syst. 35(1), 53–65 (2014)
Vincent, P., Larochelle, H., Bengio, Y., Manzagol, P.-A.: Extracting and composing robust features with denoising autoencoders. In: Proceedings of the 25th international conference on machine learning. pp. 1096–1103 (2008)
Kingma, D.P., Welling, M.: Auto-encoding variational bayes. arXiv:1312.6114 (2013)
Rezende, D.J., Mohamed, S., Wierstra, D.: Stochastic backpropagation and variational inference in deep latent gaussian models. In: International conference on machine learning, vol. 2, p. 2. Citeseer (2014)
Ye, M., Zhang, X., Yuen, P.C., Chang, S.-F.: Unsupervised embedding learning via invariant and spreading instance feature. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 6210–6219 (2019)
Chen, X., He, K.: Exploring simple siamese representation learning. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 15750–15758 (2021)
Shah, A., Sra, S., Chellappa, R., Cherian, A.: Max-margin contrastive learning. (2021)
Liu, B., Wang, B.: Bayesian self-supervised contrastive learning. (2023)
Wang, Z., Wang, Y., Hu, H., Li, P.: Contrastive learning with consistent representations. (2023)
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A.N., Kaiser, Ł., Polosukhin, I.: Attention is all you need. Adv. Neural Inf. Process. Syst. 30 (2017)
Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., et al.: An image is worth 16x16 words: Transformers for image recognition at scale. arXiv:2010.11929 (2020)
Chen, X., Xie, S., He, K.: An empirical study of training self-supervised visual transformers. (2021)
Caron, M., Touvron, H., Misra, I., Jégou, H., Mairal, J., Bojanowski, P., Joulin, A.: Emerging properties in self-supervised vision transformers. In: Proceedings of the IEEE/CVF international conference on computer vision, pp. 9650–9660 (2021)
Cuturi, M.: Sinkhorn distances: lightspeed computation of optimal transportation distances. pp. 2292–2300 (2013)
Maji, S., Rahtu, E., Kannala, J., Blaschko, M., Vedaldi, A.: Fine-grained visual classification of aircraft. arXiv:1306.5151 (2013)
Fei-Fei, L., Fergus, R., Perona, P.: Learning generative visual models from few training examples: an incremental Bayesian approach tested on 101 object categories. In: 2004 conference on computer vision and pattern recognition workshop, pp. 178–178. IEEE (2004)
Krause, J., Deng, J., Stark, M., Fei-Fei, L.: Collecting a large-scale dataset of fine-grained cars (2013)
Krizhevsky, A., Hinton, G., et al.: Learning multiple layers of features from tiny images (2009)
Cimpoi, M., Maji, S., Kokkinos, I., Mohamed, S., Vedaldi, A.: Describing textures in the wild. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 3606–3613 (2014)
Nilsback, M.-E., Zisserman, A.: Automated flower classification over a large number of classes. In: 2008 sixth Indian conference on computer vision, graphics & image processing, pp. 722–729. IEEE (2008)
Bossard, L., Guillaumin, M., Gool, L.V.: Food-101—mining discriminative components with random forests. In: European conference on computer vision, pp. 446–461. Springer (2014)
Parkhi, O.M., Vedaldi, A., Zisserman, A., Jawahar, C.: Cats and dogs. In: 2012 IEEE conference on computer vision and pattern recognition, pp. 3498–3505, IEEE (2012)
Xiao, J., Hays, J., Ehinger, K.A., Oliva, A., Torralba, A.: Sun database: large-scale scene recognition from abbey to zoo. In: 2010 IEEE computer society conference on computer vision and pattern recognition, pp. 3485–3492. IEEE (2010)
Everingham, M., Van Gool, L., Williams, C.K., Winn, J., Zisserman, A.: The pascal visual object classes (VOC) challenge. Int. J. Comput. Vision 88(2), 303–338 (2010)
Ericsson, L., Gouk, H., Hospedales, T.M.: How well do self-supervised models transfer? In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 5414–5423 (2021)
Funding
Not received.
Author information
Authors and Affiliations
Contributions
HY wrote the entire manuscript text and all authors reviewed the manuscript.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Ethical approval
This article does not contain any studies with human participants or animals performed by any of the authors.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Yang, H., Li, J. Prototypical contrastive learning for image classification. Cluster Comput 27, 2059–2069 (2024). https://doi.org/10.1007/s10586-023-04046-2
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10586-023-04046-2