
Abstract
High performance and distributed computing systems such as peta-scale, grid and cloud infrastructure are increasingly used for running scientific models and business services. These systems experience large availability variations through hardware and software failures. Resource providers need to account for these variations while providing the required QoS at appropriate costs in dynamic resource and application environments. Although the performance and reliability of these systems have been studied separately, there has been little analysis of the lost Quality of Service (QoS) experienced with varying availability levels. In this paper, we present a resource performability model to estimate lost performance and corresponding cost considerations with varying availability levels. We use the resulting model in a multi-phase planning approach for scheduling a set of deadline-sensitive meteorological workflows atop grid and cloud resources to trade-off performance, reliability and cost. We use simulation results driven by failure data collected over the lifetime of high performance systems to demonstrate how the proposed scheme better accounts for resource availability.
Similar content being viewed by others
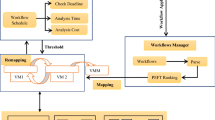

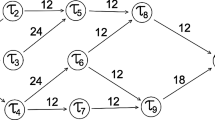
References
Alonso, G., Hagen, C., Agrawal, D., Abbadi, A.E., Mohan, C.: Enhancing the fault tolerance of workflow management systems. In: IEEE Concurrency, 2000
Availability prediction service. http://nws.cs.ucsb.edu/ewiki/nws.php?id=Availability+Prediction+Service%
Blythe, J., Jain, S., Deelman, E., Gil, Y., Vahi, K., Mandal, A., Kennedy, K.: Task scheduling strategies for workflow-based applications in grids. In: CCGRID, pp. 759–767 (2005)
Braun, T.D., Siegel, H.J., Beck, N.: A comparision of eleven static heuristics for maping a class of independent tasks onto heterogeneous distributed computing systems. J. Parallel Distrib. Comput. (2001)
da Lu, C., Reed, D.A.: Assessing fault sensitivity in MPI applications. In: Proc. of Supercomputing, 2004
Droegemeier, K.K., et al.: Service-oriented environments for dynamically interacting with mesoscale weather. Comput. Sci. Eng. (2005)
Haverkort, B.R., Marie, R., Rubino, G., Trivedi, K.: Performability Modelling. Wiley, New York (2001)
Hwang, S., Kesselman, C.: A flexible framework for fault tolerance in the grid. J. Grid Comput. (2003)
Inca real time monitoring suite. http://inca.sdsc.edu/
Kennedy, K., et al.: Toward a framework for preparing and executing adaptive grid programs. In: Proceedings of NSF Next Generation Systems Program Workshop (International Parallel and Distributed Processing Symposium), 2002
Khalili, O., He, J., Olschanowsky, C., Snavely, A., Casanova, H.: Measuring the performance and reliability of production computational grids. In: The 7th IEEE/ACM International Conference on Grid Computing, 2006
Kramer, W., Ryan, C.: Performance variability of highly parallel architectures. In: International Conference on Computational Science, 2003
Los almos reliability data. http://institutes.lanl.gov/data/fdata/
Malewicz, G.: Parallel scheduling of complex dags under uncertainty. In: Proceedings of the 17th Annual ACM Symposium on Parallel Algorithms (SPAA), pp. 66–75 (2005)
Meyer, J.F.: On evaluating the performability of degradable computing systems. IEEE Trans. Comput. (1980)
Nurmi, D., Brevik, J., Wolski, R.: Minimizing the network overhead of checkpointing in cycle harvesting cluster environments. Future Gener. Comput. Syst. (2006)
Ramakrishnan, L., Reed, D.A.: Performability modeling for scheduling and fault tolerance strategies for grid workflows. In: ACM/IEEE International Symposium on High Performance Distributed Computing, 2008
Reed, D.A., da Lu, C., Mendes, C.L.: Reliability challenges in large systems. Future Gener. Comput. Syst. (2006)
Sahner, R.A., Trivedi, K.S., Puliafito, A.: Performance and Reliability Analysis of Computer Systems: An Example-Based Approach Using the SHARPE Software Package. Kluwer Academic, Dordrecht (1996)
Sakellariou, R., Zhao, H., Tsiakkouri, E., Dikaiakos, M.: Scheduling workflows with budget constraints. In: Gorlatch, S., Danelutto, M. (eds.) Integrated Research in GRID Computing, CoreGRID, pp. 189–202. Springer, New York (2007)
Schopf, J., Berman, F.: Performance prediction in production environments. In: Proceedings of IPPS/SPDP, 1998
Schroeder, B., Gibson, G.: A large-scale study of failures in high-performance computing systems. In: Proc. of the International Conference on Dependable Systems, 2006
Weissman, J.B.: Fault tolerant computing on the grid: what are my options? In: HPDC, 1999
Yu, J., Buyya, R.: Scheduling scientific workflow applications with deadline and budget constraints using genetic algorithms. Sci. Program. 14(3–4), 217–230 (2006)
Zhang, Y., Mandal, A., Casanova, H., Chien, A., Kee, Y., Kennedy, K., Koelbel, C.: Scalable grid application scheduling via decoupled resource selection and scheduling. In: CCGrid, 2006
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Ramakrishnan, L., Reed, D.A. Predictable quality of service atop degradable distributed systems. Cluster Comput 16, 321–334 (2013). https://doi.org/10.1007/s10586-009-0078-y
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10586-009-0078-y