
Abstract
Large amounts of subtitles, from movies and TV shows, can be easily found on the web, for free, in almost every language. Several corpora, built from subtitles, with different annotations and purposes, are currently available. Considering that new sets of subtitles are constantly being released, we propose B-Subtle, an open source framework that allows the automatic creation of corpora constituted of sequential pairs of dialogue turns, gathered from subtitles. With the help of a configuration file, the B-Subtle framework permits to enrich subtitles and dialogue turns with extra information (such as movie genre or the polarity of an utterance); in addition, it allows different types of filtering to be applied to both subtitle files and dialogue turns. Therefore, with B-Subtle, each one can create his/her own corpus, tailored to his/her needs. Moreover, in order to replicate the process in a future experiment, the user just needs to save the configuration file. In this paper, we describe B-Subtle and demonstrate how to build different corpora with it.


Notes
B-Subtle is in: https://gitlab.hlt.inesc-id.pt/lcoheur/b-subtle_v2.0.
For this, you will have to register in themoviedb and ask for your own API key. The access is limited to 40 API requests every 10 sec by IP address.
The actual version of B-Subtle limits producers to tools with existing Java libraries.
Danish, Dutch, English, Finnish, French, German, Hungarian, Italian, Norwegian, Porter, Portuguese, Romanian, Russian, Spanish, Swedish, Turkish.
Bulgarian, Chinese, Copti, Czech, Danish, Dutch, English, Estonian, French, Galician, German, Greek, Italian, Latin, Polish, Portuguese, Romanian, Russian, Slovak, Slovenian, Spanish, Swahili.
VERY_NEGATIVE, NEGATIVE, POSITIVE and VERY_POSITIVE are other options.
2016: Moana, Train to Busan, Fantastic Beasts and Where to Find Them, The Legend of the Tarzan, Silence, Inferno, La La Land, The Choice, Rogue One: A Star Wards Story, Arrival, London Has Fallen; 2017: Blade Runner 2049, Dunkirk, Beauty and the Best, Baywatch, Wonder Woman, Gifted, War for the Planet of the Apes, Ghost in the Shell, The Zookeeper’s Wife and Logan.
Notice that in the particular case of the external API, if something goes wrong with the availability of the external API or with the user local internet connection the information is lost; however, for most filtering if something ends before being complete, partial information is kept.
When using the diff parameter to define the maximum time allowed between an answer and a trigger.
References
Ameixa, D., Coheur, L., Fialho, P., Quaresma, P. (2014). Luke, I am your father: Dealing with out-of-domain requests by using movies subtitles. In Proceedings of the 14th International Conference on Intelligent Virtual Agents (IVA’14), Springer-Verlag, Berlin, Heidelberg, LNCS/LNAI.
Banchs, R., Li, H. (2012). IRIS: a chat-oriented dialogue system based on the vector space model. In Proc. 50th Annual Meeting of the ACL: System Demonstrations 50th Meeting ACL (System Demonstrations), pp. 37–42.
Banchs, R. E. (2012). Movie-dic: a movie dialogue corpus for research and development. In Proceedings of the 50th Annual Meeting of the Association for Computational Linguistics: Short Papers-Volume 2, Association for Computational Linguistics, pp. 203–207.
Gorinski, P. J., Lapata, M. (2015). Movie script summarization as graph-based scene extraction. In Proceedings of the 2015 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Association for Computational Linguistics, Denver, Colorado, pp. 1066–1076. https://www.aclweb.org/anthology/N15-1113.
Gorinski, P. J., Lapata, M. (2018). What’s This Movie About? A Joint Neural Network Architecture for Movie Content Analysis. In: Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), Association for Computational Linguistics, New Orleans, Louisiana, pp. 1770–1781.
Lison, P., Tiedemann, J. (2016). Opensubtitles2016: Extracting large parallel corpora from movie and tv subtitles. In Proceedings of the 10th International Conference on Language Resources and Evaluation.
Lison, P., Tiedemann, J., Kouylekov, M. (2018). OpenSubtitles2018: Statistical Rescoring of Sentence Alignments in Large, Noisy Parallel Corpora. In Proceedings of the Eleventh International Conference on Language Resources and Evaluation (LREC-2018), European Languages Resources Association (ELRA), Miyazaki, Japan.
Magarreiro, D., Coheur, L., Melo, F. (2014). Using subtitles to deal with out-of-domain interactions. In Proceedings of the 18th Workshop on the Semantics and Pragmatics of Dialogue (SEMDIAL), SEMDIAL, Edinburgh, United Kingdom. http://semdial.org/anthology/Z14-Magarreiro_semdial_0015.pdf.
Martinez, V., Somandepalli, K., Singla, K., Ramakrishna, A., Uhls, Y., Narayanan, S. (2019). Violence Rating Prediction from Movie Scripts. In Proceedings of Proceedings of Thirty-Third AAAI Conference on Artificial Intelligence.
Paetzold, G., Specia, L. (2016). Collecting and Exploring Everyday Language for Predicting Psycholinguistic Properties of Words. In Proceedings of COLING 2016, the 26th International Conference on Computational Linguistics: Technical Papers, The COLING 2016 Organizing Committee, Osaka, Japan pp. 1669–1679.
Satwik Kottur, V. C., Wang, Xiaoyu. (2017). Exploring personalized neural conversational models. In Proceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence, IJCAI-17 pp. 3728–3734.
Schmid, H. (1995). Improvements in part-of-speech tagging with an application to german. In Proceedings of the ACL SIGDAT-Workshop pp 47–50.
Serban, I. V., Sordoni, A., Bengio, Y., Courville, A. C., & Pineau, J. (2016). Building end-to-end dialogue systems using generative hierarchical neural network models. AAAI, 16, 3776–3784.
Tandon, N., Weikum, G., Melo, G. d., De, A. (2015). Lights, Camera, Action: Knowledge Extraction from Movie Scripts. In Proceedings of the 24th International Conference on World Wide Web, ACM, New York, NY, USA, WWW ’15 Companion pp 127–128.
Xing, Y., Fernández, R. (2018). Automatic Evaluation of Neural Personality-based Chatbots. In Proceedings of the 11th International Conference on Natural Language Generation, Association for Computational Linguistics, Tilburg University, The Netherlands pp. 189–194.
Acknowledgements
This work was supported by national funds through Fundação para a Ciência e Tecnologia (FCT) with reference UIDB/50021/2020.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
Appendices
Appendix A: Filters
In total, B-Subtle implements:
-
5 Metadata Collectors;
-
12 groups of Metadata Filters, integrating 52 Metadata Filters (for instance, the general Audience Metadata filter comprises filters such as audienceAdult and audienceCertification);
-
8 Interaction Collectors;
-
10 groups of Interaction Filters, leading to 43 Interaction Filters;
-
1 Conversation Filter.
When dealing with input data that is rich in metadata, filters may be applied. Two types of filters can be used: Metadata Filters and Interaction Filters. In the following we present some examples the filters that can be used in B-Suble.
2.1 Metadata filters
The following filters are some of the available possibilities:
-
Audience: allows filtering subtitle files according to an audience rating/certification. This information can be added by the themoviedb Metadata Collector, which supports a flag for adult movies. It also supports filtering by motion picture content rating when provided together with a country identifier (different countries have different criteria for content and age rating). Examples: applying the flag for filtering adult movies will result in skipping those subtitle files; defining the content rating value as M/16 with Portugal as a country would result in accepting all subtitle files from movies with that content rating.
-
Country: allows filtering subtitles of movies/TV shows made in a specific country or set of countries. Using a regular expression for the country name is also supported. Example: the generated corpus can be made of subtitle files from movies made in countries starting with “Po” by using the following regular expression:
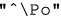
.
-
Country quantity: allows filtering subtitles of movies/TV shows made in a determined quantity of countries. A maximum, minimum or exact quantity can be defined. A range can also be used. Example: defining a range value of 2 to 4 would result in accepting subtitle files from movies filmed in at least 2 countries but filmed in less than 4 countries.
-
Duration: allows filtering by the total duration of the movie (in minutes). A maximum, minimum or exact quantity can be defined. A range can also be used. Example: the corpus being generated can be composed of subtitles from movies with less than 90 minutes by defining it as the maximum quantity of minutes allowed.
-
Encoding: allows filtering subtitle files written in a specific encoding. Using a regular expression for the encoding is also supported as well as the existence of it (one might want to filter only the subtitle files that have the encoding correctly identified). Example: only subtitles in “utf-8” will be gathered.
-
Genre: allows filtering subtitles of movies/TV shows belonging to a specific genre or set of genres. Using a regular expression for the genre type is also supported. 28 genres are supported. Example: this filter allows to build a corpus with subtitles with genre “Western”.
-
IMDb identifier: allows filtering subtitle files that have the IMDb ID present in the metadata fields.
-
Movie title: allows subtitle files to be filtered by movie name by providing a regular expression. The existence of that field in the metadata can also be tested (one might want to filter subtitles that have a movie title associated, some of them might not have that information included, since this field is not provided by OpenSubtitles2016 Corpus files).
-
Original language: allows filtering subtitles of movies/TV shows made in a specific language or languages. Using a regular expression for the original language is also supported. Example: we can build a corpus with subtitles in Portuguese.
-
Movie rating: allows filtering subtitle files based on the movie rating associated with the subtitles. It supports checking for the existence of that field in the metadata as well as a maximum, minimum, exact or range of values. Example: A corpus with subtitles from movies with a maximum movie rating of 7.2 can be gathered.
-
Subtitle rating: allows filtering subtitle files based on the subtitle rating associated. It supports checking for the existence of that field in the metadata as well as a maximum, minimum, exact or range of values. (e.g. accept only subtitle files with a rating above 6.3 in a scale of 0 to 10 by defining a minimum value).
-
Year: allows filtering files based on the release year of the movie. It supports checking for the existence of that field in the metadata as well as a maximum, minimum, exact or range of values. Example: we can build a corpus with subtitles from movies before the 70’s.
2.2 Interaction filters
In what concerns Interaction Filters, here follow some examples. Notice that some of these filters require a Producer to be applied a priori:
-
Interaction interval: allows filtering the value of time interval allowed between a trigger and an answer. It supports checking a maximum, minimum, exact, or range of values. Examle: this filter allows to collect interaction pairs where the answer appears up to 4 sec after the trigger);
-
Trigger/answer sentiment: allows filtering interaction pairs where the trigger/answer expresses a sentiment defined by the user (requires the Sentiment Producer Component). (e.g. accepting only triggers with a positive sentiment).
-
Trigger/answer tokens quantity: allows filtering interaction pairs where the trigger/answer has a determined amount of tokens (requires the Tokenizer Producer Component). A maximum, minimum or exact quantity can be defined. A range can also be used. Example: this filter allows to collect interactions in which answers have more than 5 tokens. Thus, sentences like “Yes you are!” are discarded.
-
Trigger/answer characters quantity: the same as the above, but considering the number of characters of each sentence. Example: the sentence “I am fine.” contains 10 characters and if we define this filter with a minimum characters quantity of 5, that sentence is accepted if it is part of a trigger/answer.
-
Trigger/answer regular expression: allows filtering interaction pairs where the trigger/answer matches some regular expression defined by the user. This filter gives a lot of flexibility such as building a regular expression that filters out triggers containing curse words. Example: we can collect all the interactions that start with a “what” and end with a “?”.
-
Trigger/answer text content: allows filtering interaction pairs where the trigger/answer starts with, contains or ends with some sequence of characters. The same result can be achieved by using a Trigger/Answer Regular Expression Filter, but since some users might not be advanced enough to use regular expressions we decided to provide this filter for simples use cases of text content starting with, containing or ending with some sequence of characters. Example: we can build a corpus with all the interactions in which the word “congratulations” appear.
Appendix B: Analytics
When generating a new corpus the end user might want to collect analytical data about the process of generating a corpus. We call it Global Analytics and it includes the following information:
-
Total input files processed (includes quantity and size);
-
Total invalid input files (includes quantity and size);
-
Total output files generated per output type (includes quantity and size);
-
Average time spent processing each file;
-
Total time spent processing all files;
-
Average time difference between trigger and answer;
-
Average interactions pairs extracted for each input file;
-
Input file with the most interactions pairs;
-
Largest input file;
-
Largest output file (per output type);
-
Total conversationsFootnote 18 gathered.
Rights and permissions
About this article

Cite this article
Ventura, M., Veiga, J., Coheur, L. et al. The B-Subtle framework: tailoring subtitles to your needs. Lang Resources & Evaluation 54, 1143–1159 (2020). https://doi.org/10.1007/s10579-020-09507-3
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10579-020-09507-3