
Abstract
The paper presents a formal model of the system of number representations as a multiplicity of mental number axes with a hierarchical structure. The hierarchy is determined by the mind as it acquires successive types of mental number axes generated by virtue of some algebraic mechanisms. Three types of algebraic structures, responsible for functioning these mechanisms, are distinguished: BASAN-structures, CASAN-structures and CAPPAN-structures. A foundational order holds between these structures. CAPPAN-structures are derivative from CASAN-structures which are extensions of BASAN-structures. The constructed formal model unifies two competitive conceptions of cognitive arithmetic: namely, the conception of the mental number line and the conception of parallel individuation. The paper is the continuation of a paper entitled Representational structures of arithmetical thinking, in which rich empirical evidence supporting the model is presented. The main result achieved in the present paper may be philosophically interpreted as an attempt to formalize the Kantian conception of the pure idea of time, understood as the a priori form of human arithmetical thinking. In this way, our theory may be comprehended as a result of applying the hard method of logical reconstruction of fundamental epistemological categories.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
The construction of a formal model for the representational structure of arithmetical thinking is the main aim of the paper. The presented model is comprehended as a system of hierarchical algebraic structures which are transformable into one another. In the first part of our research, entitled Representational structures of arithmetical thinking, this system is described as consisting of four modules: the shortest mental number line, the summation mental number line, the point-place mental number line and, finally, the purely point mental number line. These lines are understood as mechanisms which generate appropriate numerical representations, called mental number axes. These axes are understood as being composed of representations of succeeding numbers. When a subject executes any act of numerical reference, then in her/his mind the appropriate mental number axis or even axes are activated.
The shortest mental number line (SMNL) is responsible for our ability to subitize small cardinalities, not greater than two elements. This mechanism is activated in the minds of infants or even newborns. This is why they are able to behaviourally differentiate cardinalities equal to two, exposed to their sensual fields of perception during experiments (Feigenson and Carey 2003; Feigenson et al. 2002; Antell and Keating 1983; Xu and Spelke 2000; Lipton and Spelke 2003). The SMNL allows the mind to synthesise two-point number axes with a starting point and an endpoint. These axes are activated when the mind is required to react behaviourally to some stimuli in physical space. The SMNL constitutes the so-called motor code, that is, the dimension of response in later phases of cognitive development taking various directions (horizontal or vertical) and turns (from left to right, from right to left, from top to bottom–or from bottom to top), depending on cultural styles and schemata encoded in the given mind. The activation of two-point number axes, with the direction from left to right, in the mind may be interpreted as the process which determines the appearance of the Simon effect in experiments (Simon 1969; Hommel 1994; Eimer et al. 1995; Gevers and Lammertyn 2005; anonymous).
In the next phase of cognitive development, the mind expands the SMNL. This process culminates in shaping the summation mechanism of the mental number line. In the first stage of expansion, the SMNL is transformed into a summation mental number axis, which enables the mind to generate prolonged summation mental number axes, here called BASAN-axes. The mechanism of their generation is described by the structure named Basic Algebra of Summation Axis of Numbers (BASAN). In the second stage, BASAN-structures are extended to CASAN-structures (Complete Algebra of Summation Axis of Numbers). The difference between BASAN-axes and CASAN-axes involves two properties. BASAN-axes may only be prolonged, whereas CASAN-axes can be either prolonged or shortened. In BASAN-axes, the representation of the number zero (the representation of null) does not occur, whereas in CASAN-axes, the representation of the number zero is the initial segment. This means that the mind may acquire the notion of zero after having formatted the mechanism of generating CASAN-axes. The acquisition of CASAN-structures usually takes place during cognitive development before formal schooling has begun.
Mechanisms for processing number representations in accordance with the mechanism of CASAN-structures are not economical, because any activation of the representation of a given number enforces activations of all representations of numbers which are smaller than it. In particular, activations of representations of large numbers evoke a high system processing load, appearing on the level of the neuronal implementation of number representations. Hence, the mind transforms CASAN-structures into other, more economical, algebraic structures which are responsible for the generation of Complete Algebraic Point-Place Axes of Numbers (CAPPAN-axes). The main difference between summation axes and point-place axes is that, in the latter, representations of numbers as segments of a number axis do not need to include other representations as their parts, whereas in the former case, each representation of a given number includes all the representations of smaller numbers. In this way, an algebraic, point-place scaffolding of mental number axes diminishes the high processing load which accompanies summation number axes. On the basis of empirical data (Siegler and Opfer 2003; Siegler and Booth 2004; Booth and Siegler 2006; Berteletti et al. 2010; Barth and Paladino 2011; Cohen and Blanc-Goldhammer 2011), it is assumed in the model that CAPPAN-axes are logarithmically scaled.
Since even typical children in early education, given appropriate experimental conditions, are able to map numbers onto a number axis in an approximately linear manner, it should be assumed that they activate some mechanism of transforming logarithmically scaled point-place axes into linearly scaled, exact point-axes. Some researchers (e.g., Siegler and Opfer 2003) postulate that this ability to transform logarithmically scaled axes into linearly scaled point-axes develops gradually. The ability to generate linearly scaled, exact point-axes may be treated as a cognitive basis for developing expert mathematical knowledge consisted of theorems, strategies and definitions which are required for the solution of mathematical tasks with different degrees of difficulty. That is why the system of all mental number lines may be called premature arithmetical competence.
All of the above-distinguished mental number lines function in one integrated representational system of arithmetic thinking. They are activated in the mind, depending on the type of act of numerical reference executed by subjects in various computational situations. For some tasks, the mind may activate short summation axes. In some situations requiring more exact calculations, the mind activates point-place axes. The linearly scaled, exact point-axes are usually activated when the mind must engage digit numerals in its calculations. Furthermore, for the sake of representing two or more digit numbers, the mind engages clusters of number axes rather than single axes.
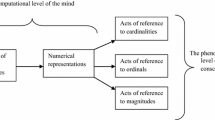
The inter-connections holding between distinguished mental number lines underlying numerical intentional acts of reference may be presented with the help of the following diagram (Fig. 1).

The left side of the diagram presents five subsystems of mental number lines in a hierarchical order. These are responsible for generating appropriate number representations in the mind which underlie intentional acts of numerical reference towards cardinalities and ordinals. Horizontal arrows designate relations between appropriate subsystems in the mind-model and corresponding types of intentional acts of numerical reference. Vertical arrows stand for consecutive transformations of mental number lines of the following types: the SMNL into the BASAN-MNL, the BASAN-MNL into the CASAN-MNL, the CASAN-MNL into the CAPPAN-MNL, and finally the CAPPAN-MNL into the LE-MNL
The above-distinguished mental number lines are understood as algebraic structures whose domains are mental number axes with various lengths, falling under appropriate types. Thus, one may adopt the terminological convention according to which mental number lines generate appropriate mental finite number axes with different lengths.
2 Basic Algebra of Summation Axes of Numbers (BASAN)
In the paper, we assume that the summation representation of numbers concerns merely non-symbolic numerals. The mechanism of generating summation mental number axes, based on BASAN-structures, takes part only in encoding processes. When a subject perceives a relatively small, non-symbolic numeral, then the BASAN-MNL is activated in her/his mind. In the next phase of any encoding process, in order to give a numerical result, a BASAN-number axis with an appropriate length is generated by virtue of the mechanism determined by the BASAN-MNL. In the case of the summation representation of numbers, parts of BASAN-number axes are appropriate representations of cardinalities or ordinals. When such a part of the BASAN-number axis is activated in the mind of any subject, then she/he takes an appropriate numerical attitude to refer toward perceived cardinality (numerosity).
BASAN-number axes are treated as segments consisting of sub-segments with a common starting point. The initial sub-segment on each BASAN-number axis is the representation of the cardinality one or the ordinal first. The representation of the cardinality two or the ordinal second is the result of the prolongation of the initial sub-segment representing the number one or the ordinal first. Similarly, coding the number three or the ordinal third requires that the sub-segment representing the number two or the ordinal second is extended with some sub-segment. Such sub-segments which function as units of prolongation are called coding units. They are not, however, number representations. They are only tools for synthesizing number representations and occur in them as their parts. Summation representations of numbers are parts of BASAN-number axes. Moreover, each representation of a smaller number is a part of any representation of the greater number. Hence, the representation of the number one is a part of all representations occurring on BASAN-number axes. The following diagram presents the geometrical structure of any BASAN-number axis.
The mechanism of summation encoding may be formalized as a system of algebraic operations determined by the structure of the following shape: 〈L, F i , n , P n i , O, A n i 〉, where L is the mental number line, understood as a vehicle of number representations and mental number axes A n i for i ≥ 1, where i is an index designating the finite length of an axis A i and n stands for the shape of coding unit P n i ; F i,n is a referential number code belonging to A n i ; P n i is a unit of coding correlated to A n i (this correlation is indicted by the same upper index n); and, finally, O is a one-place operator of the prolongation of elements of A n i with a unit of coding P n i . Because values of the operator O are also elements of A n i , O is an operator which may be iterated. Expressions of the shape α, β, and λ are variables ranging over any set A n i .
2.1 The Mental Number Line L
In the brain, mental number axes are sequences of sets of states of neuronal activations which appear in the subject’s performance of numerical acts of reference. These sets of states may be simply understood as sets of active neurons. Hence, L may be comprehended in the brain-model (on the distinction between the brain-model and the mind-model of the MNL, see Krysztofiak 2015) as a potential sequence of sets of neurons. Its counter-part in the mind-model is a sequence of points with values of neuronal activations. Each point, being a part of L, possesses a different value of neuronal activation. This is the only feature differentiating elements of L. Furthermore, the values of neuronal activations are changeable. This means that the same point may possess different values of neuronal activations depending on the length of L. When L is prolonged, values of neuronal activations, assigned to points which are parts of L before prolongation, increase. The direction of L is determined by decreasing values of the activation of succeeding points (see (H3) and (H4) in Krysztofiak 2015).
2.2 Mental Number Axes A n i
Mental number axes are understood as finite subsets of L. They have different lengths indicated by the index i in A n i . The measurement of the length of any axis is the number of all points reassembling or constituting it. Each mental number axis, lying on L, may be prolonged. From an algebraic point of view, there are no limits to such prolongations. This is why the mental number line L is a potential vehicle for an infinite number of mental number axes. Set-theoretic elements of axes are mental representations of numbers. In the case of BASAN-axes, the relation of inclusion, which holds between number representations, determines the direction and linear order of any axis (See Fig. 2). The SMNL, which is constituted of only two points, is the distinguished mental number axis because it is included in every mental axis generated by the BASAN-structure.

The diagram presents the geometrical architecture of the BASAN-number axis with the length of four cardinalities. This axis is consisted of four number representations in such a way that the representation of number one is a part of the representations of all succeeding numbers. Similarly, the representation of number two is a part of all representations of numbers greater than two. The turn of arrows indicates that all succeeding representations are formatted by the prolongation of preceding representations. The dotted line shows that the BASAN-number axis may be prolonged. Sub-segments between 〈1, 2〉, 〈2, 3〉 and 〈3, 4〉 are coding units. Coding units become shorter with the formatting of subsequent representations. The representation of number zero does not occur on BASAN-number axes
2.3 The Referential Number Code F i,n
Each axis possesses a distinguished number representation, called a referential number code. In BASAN-axes, F i,n is usually the representation of the number one or of the ordinal first. However, in some situations the mind may activate F i,n , as the representation of a priming numeral stimulus. This takes place in experiments with the use of the priming technique.
2.4 The Unit of Coding P n i
Each mental number axis A n i is correlated with a unit of coding P n i . This is indicated by the upper index in A n i . Applications of P i n in processes of the synthesis of the mental number axis A n i may be treated as points belonging to the mental number line L. This means that when L, and, thereby, A n i , are prolonged, the mind adds a succeeding unit of coding, P n i , to the previously formatted units. The increase in the length of an axis A n i consists in binding the succeeding coding units in the succeeding segments. Each application of the coding unit P n i in the process of formatting the mental number axis A n i may be treated, on the level of the brain-model, as a process of activating the succeeding groups of neurons determining the value of neuronal activation correlated to a given application.
2.5 The Operator of Prolongation O
The mechanism of formatting number representations consists in the prolongation of the referential number code F i,n with the unit of coding P n i . In this way, the simplest mental number representations may be comprehended as n-tuples of the shape: 〈Rep(one), P n i , …, P n i 〉, where Rep(one) is the representation of the number one or the ordinal first. In many cases, Rep(one) is identical to F i,n . As applications of P n i are understood as points belonging to L, it may be said that they are constituted by applications of O to succeeding number representations. Since each application of P n i is correlated with the established value of neuronal activation, then each succeeding application of the prolongation operator O is correlated with the same value of neuronal activation correlated with a given application of P n i .
The following axioms define the structure 〈L, A n i , F i,n , P n i , O〉. Let us call this structure Basic Algebra of Summation Axis of Numbers (BASAN). ‘⊂’ stands for set-theoretic inclusion; ‘∈’ designates the relation of belonging an element to the set; ‘〈…〉’ is an operator of an ordered pair; and ‘≡’, ‘→’ and ‘∧’ are logical connectives (equivalence, implication and conjunction):
The axiom (A1, BASAN) says that each axis A n i with a length equal to i and with the coding unit P n i is contained in L. In accordance with (A2, BASAN), a referential number code F i,n belongs to A n i . Hence, F i,n is a distinguished number representation located on the mental number line L and correlated with the n-fold iteration of P n i . The axiom (A3, BASAN) describes the mechanism for building number representations. In light of this axiom, they are ordered pairs constructed out of some representation and the n-fold iteration of the coding unit P n i . Under the set-theoretic definition of an ordered n-tuple, 〈x1,…, xn〉 = 〈〈x1,…, xn−1〉, xn〉, representations of numbers located on the summation number axis are n-tuples of the shape: 〈F i , n , P n i ,…, P n i 〉. The axiom (A4, BASAN) says that each value of the operation of prolongation O applied to any element of L is also an element of L. This means that the operation of prolongation does not lead outside of L. The axiom (A5, BASAN) introduces the concept of an iterated operation of prolongation and, with (A4, BASAN), defines the mental number line L. In accordance with (A6, BASAN), for the axes A n1 and A n2 (pieces of the SMNL), a unit of coding is identical to a referential number code. This axiom does not exclude the situation in which axes have a length greater than 2 (i > 2) and P n i = F i,n . The axiom (A7, BASAN) is the definition of mental number axes. (Df. P i n) describes the way of constructing units of coding. For example, P 1 i = 〈P i 〉, P 2 i = 〈P i , P i 〉, P 3 i = 〈P i , P i , P i 〉, etc.
All structures which satisfy the above-formulated axioms form the family of BASAN-structures: BASAN 1 F , …, BASAN n F . The set of proposed axioms does not exclude the possibility of formatting mental number axes with lengths equal to one.
Depending on the construction of a unit of coding, one may distinguish various types of BASAN-structures. The primitive BASAN-structure takes the shape of a BASAN-structure for P i = F i . Let *BASAN n F be a canonical structure defined by adding the following facultative axiom to axioms of BASAN:
In accordance with (A8, *BASAN) and (Df. P i n), one may define the family of canonical BASAN-structures: *BASAN 1 F , …, *BASAN n F . Their peculiar feature consists in the fact that referential number codes correlated with axes generated by these structures are initial segments of these axes. Each BASAN n F -structure is responsible for generating in the mind an appropriate mental number axes A n i with various referential number codes and various lengths marked by i, where n is the length of a coding unit which serves to generate number representations belonging to A n i . One may say that the BASAN n F -structure determines a mechanism of abstracting number axes of the shape A n i from L.
According to the axioms of *BASAN 1 F , number representations located on the summation mental number axes take following shapes: 〈P i 〉, 〈P i , P i 〉, 〈P i , P i , P i 〉, etc. For *BASAN 2 F , succeeding number representations take shapes: 〈P i , P i 〉, 〈〈P i , P i 〉, 〈P i , P i 〉〉, 〈〈P i , P i 〉, 〈P i , P i 〉, 〈P i , P i 〉〉, etc. For n > 1, BASAN n F -structures participate in processes of counting or calculating groups of objects. For example, one may count pairs, threes, fours or even tens or hundreds of objects. In such situations, when one must count, for instance, three tens of objects (sweets or coins, for example), the BASAN 10 F -structure may be synthesized in the mind. The number representation of 30 may be formatted as an element of many axes of the shape A 10 i , for the length i ≥ 3.
The BASAN 1 F -structure determines the effective mechanisms for formatting representations of very small numbers. However, on the ground of the BASAN 1 F -structure, processes producing representations of large numbers are ineffective because of the length of the operational time required for formatting representations of such numbers. That is why, if the representation of the number one hundred is to be synthesized, then, for the sake of the synthesis of the representation of this number, the mind may select the BASAN 10 F -structure from the family of BASAN-structures. In this way, the length of the operational time needed for the synthesis of the representation under analysis is relatively short. BASAN n F -structures, for n > 1, cannot, however, be tools for synthesizing all representations of numbers. For instance, according to the BASAN 10 F -structure, numbers smaller than 10 cannot be synthesized.
In the set L, it is easy to define the relation of the order between representations.
Let α = 〈F j , P i , P i , P i 〉 and β = 〈F j , P i , P i , P i , P i , P i 〉. Hence, β = O2 (α), and therefore α ≤ β. It is easy to notice that 〈F j , P i , P i , P i 〉 is a part of 〈F j , P i , P i , P i , P i , P i 〉. This example shows that the process of synthesizing the representation 〈F j , P i , P i , P i , P i , P i 〉 must pass, as its phase, by the process of synthesizing the representation 〈F j , P i , P i , P i 〉. Because each axis A n i is a finite set of number representations, the relation ≤ establishes the linear order in A n i . It is easy to prove that for each i, the structure 〈A n i , ≤ B 〉, where A n i is a finite set, is a linear order. Because A n i is a finite set, for each pair of elements of A n i , it may be checked which of them is a part of the other. Axioms (A1, BASAN) − (A8, *BASAN), however, do not preserve the linear order of L in BASAN-structures. For proving such a formal property, one needs to adopt the principle of induction. That is why, in accordance with (A1, BASAN) − (A8, BASAN), L cannot even be treated as a line, although it is called the mental number line. That is why L is only the vehicle for mental number axes. Using an Aristotelian metaphor, one may say that L is the matter for axes as forms.
In the set of axes generated by the same BASAN n F -structure, that is, with the same coding unit P n i , one may define the relation in which one axis is a result of an extension of the second axis. Let this relation be called the elongation relation and be symbolized by the sign ‘⊢’. Let the phrase ‘The axis A n j is formatted by the elongation of an axis A n i ’ be formalized as ‘A n i ⊢ A n j ’.
For all lengths i and j, such that i is smaller than or equal to j, the axis A n j is formatted by the elongation of the axis A n i if and only if the referential number code F j,n , which is formatted in virtue of the i − 1-fold iteration of the prolongation operator O applied to the unit of coding P n i , belongs to the axis A n j and the unit of coding P n i belongs to both axes.
With the help of the elongation relation, one may describe the mechanism of transforming the SMNL into summation mental number axes which may be still prolonged. For BASAN 1 F -structures, the SMNL is identical to A 12 , consisting of two number representations taking the following shapes: 〈P〉 and 〈P, P〉, such that 〈P〉 ≤ B 〈P, P〉. If the axis with a length equal to four is formatted by the elongation of the SMNL, that is, SMNL ⊢ A 14 , then the referential number code F 4,1, belonging to A 14 , should be formatted as the result of O 2−1(〈P〉). Representations of the succeeding numbers: three and four, belonging to A 14 , will be synthesized as 〈F 4,1, P〉 and 〈F 4,1, P, P〉. If A 16 is formatted in the next stage, then 〈F 4,1, P, P〉 becomes the referential number code for A 16 . It should be also emphasized that the mind may form various BASAN 1 F -axes with the same length, depending on the shape of the referential number code activated during calculations. For instance, any axis A 14 may be correlated with an F 4,1 identical to P, 〈P, P〉 or 〈P, P, P〉. Each sub-segment of a given BASAN 1 F -axis may be its referential number code. When F 4,1 is identical to P, the BASAN 1 F -axis becomes the canonical *BASAN 1 F -axis.
When a child learns to calculate non-symbolic numerals up to ten, it is probable that BASAN 1 F -axes are formatted in its mind by virtue of the sequence of the following mechanisms: SMNL ⊢ A 13 , A 13 ⊢ A 14 , A 14 ⊢ A 15 , …, A 19 ⊢ A 110 . The competence to form canonical *BASAN n F -axes with lengths of two to ten points is a basis for the development of subsequent competencies of forming axes according to BASAN n F -mechanisms, where n is greater than one. In this way, the mind learns to calculate non-symbolic numerals grouped in pairs, threes, fours or even in tens. Canonical *BASAN n F -structures enable the mind to acquire the notion of equinumerosity for small cardinals.
3 Complete Algebra of Summation Axes of Numbers (CASAN)
Experimental data show that, in the case of non-symbolic numerals, representations of numbers smaller than the number represented by a referential number code are also formatted in the mind. Therefore, it is justifiable to assume that processes of formatting and activating representations of numbers may proceed, not only in virtue of prolongation O, but also in virtue of the converse operation O −, called the operation of shortening, or abridgment. The introduction of the operation of shortening O − into the formal model describing mechanisms of processing number representations on summation mental number axes additionally allows us to explain how the representation of the number zero (0) is synthesized. It is therefore justified to assume that BASAN-structures which have been previously encoded in the mind are transformed into CASAN-structures (Complete Algebra of Summation Axis of Numbers) which take the shape: 〈L, F i,n , P n i , O, O −, 0, A n i 〉. Each BASAN n F -structure is transformable into a corresponding CASAN n F -structure. The axioms which define these structures are as follows:
According to the axiom (A1, CASAN), each CASAN n F -axis A n i with length equal to i and with the coding unit P n i , understood as a set of number representations, is contained in L. The second axiom (A2, CASAN) says that the reference number code correlated with A n i is a number representation. The axioms (A3, CASAN), (A4, CASAN) and (A5, CASAN) describe the mechanism of formatting number representations in virtue of applying the prolongation operation O. This operation does not lead out of L and produces mental number representations as n-tuples of the following shape: 〈0, P n i ,…, P n i 〉. Hence, each CASAN n F -representation of a number stems from the representation of the number zero. This makes them different from BASAN n F -representations of numbers. The axiom (A5, CASAN) establishes that 0 is the generator of all number representations lying on each CASAN n F -axis. In this way, each CASAN n F -axis possesses two generators. The second one is a referential number code F i,n . According to the axiom (A14, CASAN), each number representation belonging to a given axis A n i may be formatted by the use of some iteration of the prolongation function O or some iteration of the shortening function O − in application to F i,n . The axiom (A6, BASAN) establishes that for very short CASAN n F -axes, their referential number code is their initial segment 〈0, P n i 〉. The axiom (A7, CASAN), in conjunction with other axioms, says that for each pair of number representations, the first of them is derived by prolongation of the second one or, conversely, the second one is derived by prolongation of the first one. According to this axiom, for any two iterations of the prolongation of the operator O, it is a fact that the former is generated from the latter by superposition with some other iteration of O or, conversely, the latter is generated from the former by superposition with some other iteration of O. In conjunction with the other axioms, this means that for any two number representations belonging to the same axis, the former is accessible by prolongation from the latter or, conversely, the latter is accessible from the former by prolongation. In this way, L becomes a linearly ordered set of number representations because the prolongation operation satisfies the totality condition. The axioms (A8, CASAN), (A9, CASAN) and (A12, CASAN) describe the main properties of the representation of the number zero, which belongs to all CASAN n F -axes. It is different from a coding unit P n i and, finally, it is a distinguished number representation because it cannot be shortened by the application of O − to another number representation. The axioms (A10, CASAN) and (A11, CASAN) show that the operation of shortening O − is the inverse of the prolongation operation O. The axiom (A13, CASAN) says that the operation of shortening does not lead out of L. The definition (Df. P n) establishes the way of constructing coding units for CASAN n F -axes formatted during calculations of objects grouped in pairs, threes, fours and tens, etc.
In the similar way as in the case of BASAN n F -structures, for canonical *CASAN n F - structures, one must adopt the facultative axiom:
Each CASAN n F -structure is an extension of the appropriate BASAN n F - structure by adding the representation of the number 0 and the operation of shortening O −. The mental mechanism of formatting this representation consists in the application of the shortening operator to the initial segment in any BASAN n F -axis. This means that the mind encodes the representation of zero after it acquires the competence in the application of the shortening operation. This explains the fact that children master the concept of zero only after they master concepts of one, two, three or even four.
The definition of the order ≤ C in CASAN-structures is analogous to (Df. ≤ B ).
For each i and n, 〈A n i , ≤ C 〉 is a linear order. There is one difference between BASAN n F -structures and CASAN n F -structures: In CASAN-structures, 〈L, ≤ C 〉 is a linear order, whereas in BASAN n F -structures, an analogous fact cannot be proved for ≤ C . The axiom (A7, CASAN) preserves the fact that 〈L, ≤ C 〉 is a linear order in CASAN n F -structures.
The above-formalized mind-model of the MNL may be criticized for having the following two disadvantages:
-
(i)
Mechanisms for the synthesis of representations of large numbers would have to be regulated by CASAN n F -structures with large indices determining referential number codes. Hence, for the sake of synthesizing representations of large numbers, the processing of CASAN n F -structures would require an extremely long operational time.
-
(ii)
A unit of coding P n i in BASAN n F -structures, as well as in CASAN n F -structures, would have the same representational properties in all cases of synthesizing number representations. This means that the mind would have to use the same coding unit P n i when processing representations of small numbers as well as large numbers. It seems, however, that coding units for representations of small numbers differ from coding units for representations of large numbers. These differences are indicated by size and distance effects. This is why mental number axes formatted in virtue of BASAN n F - and CASAN n F -mechanisms are interpreted as having logarithmic scales in which distances between points become shorter. Thus, it is justifiable to distinguish many CASAN n F -structures for a given n which use units of coding P n i with different lengths.
For instance, if n = 1 in the canonical *CASAN n F -structure, then F i,n is defined as O(〈0, P 〉). The formation of the representation of the number 666 requires, using only one CASAN 1 P -structure, the use of 665 applications of the prolongation operator O to F i,n . Even if the mind constructs F i,n as O 600 〈0, P〉 in virtue of the mechanism determined by some other CASAN n F -structure, the number of applications of O to F will be sixty six. It is obvious that this number of applications does not comprise the whole operational time needed for synthesizing the representation of the number 666. In this situation, the priming representation F i,n must be first formatted and activated. This, however, requires a long additional operational time. In this case, a referential number code might be, for instance, the representation of the number 100. The above-presented formal model, however, predicts a situation in which many CASAN n F -structures are activated in the mind for the sake of formatting representations of large numbers. If the mind uses three CASAN n F -structures of shapes 〈L, F i,1, P 1 i , O, O −, 0, A i 〉, 〈L, F i,10, P i 10, O, O −, 0, A i 〉 and 〈L, F i,100, P i 100, O, O −, 0, A i 〉, then the representation of the number 666 may be treated as a structure composed of three representations of the ordinal 6 located on three axes: A 1 i , A 10 i , A 100 i correlated with three units of coding: P 1 i , P 10 i , P 100 i . In this case, the operational time needed for synthesizing the representation of the number 666, without the use of priming processing, would comprise eighteen applications of the operator of prolongation O, spread over three axes, to the representation of the number zero. The use of priming processing technique would also shorten the operational time of synthesis. The representation of the number 666, formatted by the use of *CASAN n F -structures, would be a structure composed of three representations of the ordinal 6 spread over three axes generated, respectively, from the following structures: *CASAN 1 F , *CASAN 10 F and *CASAN 100 F . In these structures, number referential codes take shapes determined by the following equations: F i,1 = 〈0, P 1 i 〉, F i,10 = 〈0, P 10 i 〉 and F i,100 = 〈0, P 100 i 〉. Hence, the representation of the number 666, synthesized with the use of canonical *CASAN n F -structures, is identical to the triple of the shape: 〈O 6(〈0, P 1 i 〉), O 6(〈0, P 10 i 〉), O 6(〈0, P 100 i 〉)〉.
The second disadvantage may be avoided by the introduction of the neuronal valuation mechanism into the model. The description of this mechanism requires the use of the concept of points upon which mental number axes, generated by BASAN n F -structures as well as CASAN n F -structures, are founded. As was noted above, the points correlated with the same axis differ from each other with respect to their neuronal activations. The neuronal valuation mechanism consists in introducing functions of neuronal valuations Val K,j into BASAN n F -structures and CASAN n F -structures. Each function Val K,j , correlated with the axis A j with the length equal to j, where K stands for the intensity of a given neuronal activation, assigns neuronal activations to points upon which the axis A n j is founded. Neuronal activations may be treated as numbers of neurons activated in the brain during the activations of number representations in the mind.
Let [A j ] be the set of points upon which the number axis A n j , generated by BASAN n F -structures or CASAN n F -structures, is founded. Its definition for, BASAN n F - and CASAN n F -structures, respectively, takes the following shapes:
Both in the BASAN n F -structures and in CASAN n F -structures, points are the same objects understood as i-iterations of the prolongation operation applied to a single coding unit. To speak technically, points are exponents of the prolongation operation. In the case of CASAN n F -structures, 0 is not a point. Each [A n j ] is a linearly ordered finite set. That is why each element of any [A n j ] may be numbered. Let 1, 2, …, m be numbers of consecutive points generated by CASAN-structures. For all n and m, the following theorem holds:
In accordance with (T1), all CASAN-axes with the same length but with different coding units are identical.
The function Val K,j may be formalized as operating on numbers of points and returning values of neuronal activations, where ! is a factorial and / is a quotient.
The condition (Df. Val K,n ,1) determines the number of neurons required for the activation of the first point numbered a One on the j-long number axis A n j with intensity K. The second condition determines the number of neurons required for the activation of the point with number m on the j-long axis with intensity K. The parameter K is constant. Because representations of numbers belonging to a given axis A n j are founded upon consecutive points, one may define the implementation function Imp K,j , correlated with Val K,j , which attributes sequences of neuronal activations to representations of numbers belonging to a given axis A n j :
What is important is that (Df. Imp K,n ) works for all representations of numbers equal to or smaller than j, and only for some representations of numbers greater than j. This set of representations of numbers with lengths greater than j, for which the condition (Df. Val K,j ,2) works, constitutes the interval of prolongation of a given axis A n j .
Let us exemplify the job of both functions defined above. Let K be equal to 1. Let us assume that the mind is set to detect about seven objects. Hence, it synthesizes the 7-points long axis. Therefore, the neuronal valuation function takes the shape: Val 1,7. On the basis of (Df. Val K,j ,1), one gets Val 1,7 (1) = 7! = 1· 2 · 3 · 4 · 5 · 6 · 7 = 5040. Hence, all points belonging to our axis are implemented in the brain in accordance with the following digital circuit: (1, 5040), (2, 2520), (3, 1680), (4, 1260), (5, 1008), (6, 840), (7, 720). The mind is able to prolong this axis for successive points: (8, 630), (9, 560), (10, 504). If number representations take summation shapes, numbers of neuronal activations required for implementing them are as follows: (one, 5040), (two, 7560), (three, 9240), (four, 10500), (five, 11508), (six, 12348), (seven, 13068), (eight, 13698), (nine, 14258), (ten, 14762). For example, Imp K,j (three) = 〈Val K,j (1), Val K,j (2), Val K,j (3)〉. In result, one gets: Imp K,j (three) = 〈5040, 2520, 1680〉. Adding these neural values, the result is 9240.
According to the definitions of the neuronal valuation functions (Df. Val K,j ) and the implementation function (Df. Imp K,j ), the brain is able to implement only sufficiently short summation number axes. For j = 20, the number of neurons in the brain is not sufficient to implement a 20-points long axis. In accordance with our definitions, this number is equal to j! (factorial), that is, 670,442,572,800,000 × 5040. Any attempt to implement a logarithmic number axis with twenty points would lead to “overheating of the brain”.
To summarize, for the sake of representing very small numbers, a single-axis mechanism of summation coding is used, determined by BASAN n F -structures or CASAN n F -structures, generating axes A n j for low indices j. For syntheses of representations of relatively large numbers, many mental number axes A n j for low indices j, determined by CASAN n F -structures, are used. In the case of axes A n j for greater indices j, it is impossible to implement number representations in the brain because of an insufficient number of neurons. That is why the mind must transform the mechanism of CASAN n F -structures into a more economical mechanism of formatting number representations, determined by CAPPAN-structures (Complete Algebraic Point-Place Axes of Numbers- structures).
4 The Point-Place Representation of Numbers on the Mental Number Axes
Mechanisms of processing number representations in accordance with CASAN n F -structures are not economical, because activations of representations of large numbers evoke a high system processing load. Hence, the mind transforms CASAN n F -structures into other, more economical algebraic structures, here called point-place mental number axes.
The structure of the shape, 〈Ψ, M 0,…, M z , [A n j ], 0, ≤, S, δ0,…, δz〉, describes the mechanism of the point-place representation of numbers. Ψ is the function which attributes each element of a summation axis A n j to a corresponding point belonging to [A n j ]. Ψ transforms CASAN-axes into linearly ordered sets of points belonging to CAPPAN-axes. M 0,…, M z are mental point-place number axes (CAPPAN-axes) with differing degrees of exactness (precision). The lower index ‘z’ stands for the degree of exactness. If z increases, the degree of exactness also increases. Hence, for instance, the degree of exactness of M 3 is higher than the degree of exactness of M 1. [A n j ] is a denumerable set of points upon which the number axis A n j , generated by CASAN n F -structures, is founded. 0 is the representation of the number zero belonging to any axis generated by a given CASAN n F -structure. ≤ is the relation of linear ordering in [A n j ]. S is the function of the type: S ⊂ [A n j ] × PP([A n j ] ∪ {0}), where P is a power-set function. Values of S are called neighborhoods of points. Any neighborhood of a given point is a set of other points. Hence, S assigns sets of sets of points to a given point. δ0,…, δz are functions which assign distinguished neighborhoods to points. They are called functions of selection. In other words, each function from the set δ0,…, δz assigns to any point h from [A n j ] some distinguished element of S(h). Values of functions δ0,…, δz are representations of numbers belonging, respectively, to M 0,…, M z . δ0,…, δz are thus functions of synthesis which correspond, respectively, to mental point-place number axes M 0,…, M z . Thus, one may say that the function δz synthesizes the number axis M z . The index occurring both in ‘M z ” and in ‘δz’ indicates the degree of exactness with which the axis M z is synthesized by δz.
4.1 The Function Ψ
Let us define the function Ψ, which transforms number representations belonging to any summation axis A n j , generated by a given CASAN n F -structure, into a corresponding point belonging to the set [A n j ] ∪ {0}:
On the basis of (Df. Ψ), it is easy to prove the following theorem:
The set [A n j ] ∪ {0} is the point-image of the function Ψ for the summation axis A n j . Let us accept that Ψ*(A n j ) = [A n j ] ∪ {0}.
4.2 The Relation of Linear Ordering ≤
Let us define the relation ≤ in the following way:
It is easy to prove that ≤ satisfies all the conditions of linearly ordering relations.
4.3 The Function of Neighborhoods of Points S
For the sake of defining the function S, let us define the function which produces point intervals formed of elements of the class Ψ*(A n j ). Let λ be the lambda-operator (abstractor).
The point interval [ k, h ] is the set of points including all the points between and including k and h. The shortest intervals possess the shape [ k, k ].
For each k from Ψ*(A n j ), the function S produces the set of all point neighborhoods. S is defined with the help of the relation of equinumerosity ≈.
A point interval [ t, k ] belongs to the set of all point neighborhoods of point h if and only if the point interval [ t, h ] is equinumerous to the point interval [ h, k ]. This means that the point h divides each of its neighborhoods in half. It is easy to notice that for each S(h), the relation of inclusion determines a linear ordering of its elements. For instance, the set of neighborhoods of the point 3 consists of the following point intervals : [3, 3], [2, 4], [1, 5], [0, 6]. Furthermore, each S(h) is a finite set. If the number of a point h belonging to Ψ*(A n j ) increases, the cardinality of the set S(h) also increases.
4.4 Functions of Selection δ0,…, δz
Let δ0 be a basic function of selection ascribing a distinguished point-neighborhood to each point from Ψ*(A n j ). Because S(h) is a linearly ordered set whose order is determined by the relation of inclusion between elements of S(h), so in each subset of S(h) there exists a distinguished, maximal element. Let Max ⊆ be the function which selects the maximal element from any class of sets due to the relation of inclusion. The definition of δ0 proceeds as follows (where Card is a function ascribing to any set its cardinality):
In accordance with (Df. δ0), the distinguished neighborhood of h is the maximal element, due to the relation of inclusion, in the subset of S(h) formed by sets with a cardinality less than Card [1, h ]. For example, it is easy to derive the fact that δ0(3) = [3, 3], because the cardinalities of the other two neighborhoods, that is, [2, 4] and [1, 5], are not less than the cardinality of [1, 3]. Values of the function of selection δ0 are representations of numbers on the mental point-place axis M 0. It is easy to prove: δ0(0) = [0, 0], δ0(1) = [1, 1], δ0(2) = [2, 2 ]. Hence, representations of initial numbers, that is, δ0(0), δ0(1), δ0(2) and δ0(3), belonging to M 0 and synthesized by the selection function δ0, take the shape of a point.
Functions of the selection, which act with greater precision, may be defined with the help of the operation of cutting a point in neighborhoods. Let Cut be defined in the following way, where Seq is the successor function determined on Ψ*(A n j ).
The Cut function shortens a given point interval by the same length on both sides. The Cut function enables the construction of a sequence of selection functions in which each succeeding function produces representations of numbers with increasing precision. The Cut function may be iterated.
The definition of functions of selection for indices of precision greater than 0 takes the following shape:
The upper index in δz indicates the degree of precision which is correlated with the index of iteration in Cut z.
It is easy to prove the following theorem:
In accordance with (T7), if the selection function δz assigns to h a number representation taking the shape of a point, then the selection function δw with the degree of precision w greater than z also assigns to h a number representation taking the shape of a point.
Let us exemplify the job of the selection function δz. For each z, δz(3) = [3, 3]. For the point 4 from each Ψ*(A n j ), such that 4 ∈ Ψ*(A n j ), δ0(4) = [3, 5] and δ1(4) = [4, 4]. For the point 8 from each Ψ*(A n j ), such that 8 ∈Ψ*(A n j ), one gets the following values for consecutive selection functions: δ0(8) = [5, 11], δ1(8) = [6, 10], δ2(8) = [7, 9] and δ3(8) = [8, 8]. It is easy to prove that for each h belonging to Ψ*(A n j ), there exists such z that δz(h) = [ h, h ].
4.5 Mental Point-Place Number Axes M 0,…, M z
A mental axis of number representations M z with the degree of precision z may be defined in the following way:
In light of (Df. M z ), M z is composed of all the distinguished point intervals, being values of the selection function δz applied to succeeding points of Ψ*(A n j ).
In accordance with (Df. M z ), the mental point-place number axis M 0, for instance, founded upon the CASAN-axis A 15 with the length equal to five points, should be the set of the following number representations: 0, [1,1], [2,2], [3,3], [3,5]. It is easy to see that the point-place number representation [4,6], belonging to the mental point-place number axis M 0, needs the longer CASAN-axis for its formatting, namely the CASAN-axis A 16 . This example shows that each mental point-place number axis M 0, resulting from the transformation of any CASAN-axis with a length greater than three points, is always shorter than the CASAN-axis at input.
Structures of shapes 〈Ψ, M z , [A n j ], 0, ≤ , S, δz〉 are sub-structures of the general structure of the shape 〈Ψ, M 0,…, M k , [A n j ], ≤ , 0, S, δ0,…, δk〉. Each CAPPAN-structure of the shape 〈Ψ, M z , [A n j ], 0, ≤, S, δz〉 determines the cognitive mechanism of formatting number representations with the degree of precision z. If the mind is going to enumerate some set of objects, for instance, it must derive an appropriate sub-structure 〈Ψ, M z , [A n j ], 0, ≤ , S, δz〉 from the general structure 〈Ψ, M 0,…, M k , [A n j ], ≤, 0, S, δ0,…, δk〉. The choice of sub-structure 〈Ψ, M z , [A n j ], 0, ≤, S, δz〉 is settled by the expected degree of precision of a given estimation. If the mind expects a high degree of precision for its calculation, then it generates and activates a mechanism of formatting representations of numbers coordinated to the selection function δz with a sufficiently high index z. If the computational intention is not directed to a high degree of precision (as when one wants to estimate the cardinality of objects approximately), then the mind generates and activates a mental number axis with a low degree of precision.
The representational mechanism activated by the mind during its acts of numeral reference may be formalized as an ordered pair composed of the structure 〈Ψ, M 0,…, M z , [A n j ], ≤, 0, S, δ0,…, δz〉 and the function of computational intention Ω, whose arguments are indices of precision and values are sub-structures of the shape: 〈Ψ, M z , [A n j ], 0, ≤ , S, δz〉.
During an act of numeral reference, the mind activates an intention of computational precision which selects an appropriate substructure from the set of all substructures of the structure 〈Ψ, M 0,…, M k , [A n j ], ≤, 0, S, δ0,…, δk〉.
Since even typical children in early education, given appropriate experimental conditions, are able to map numbers onto a number axis in an approximately linear manner, it should be assumed that they activate some mechanism for transforming logarithmically scaled point-place axes into linearly scaled, exact point-axes. Such transformations may be explained as being caused by a function of computational intention Ω for maximally high indices of computational precision which returns exact point number axes. Let Ω z→∞(z) be such a function of maximal computational intention. That is why all functions of computational intention, correlated with a structure 〈Ψ, M z , [A n j ], 0, ≤ , S, δz〉, for 0 ≤ z ≤ ∞, generate the sequence of sub-structures: Ω(0), Ω(1), Ω(2), …,Ω z→∞(z). In this way, exact point-axes appear as limit structures of point-place axes. Their vehicle may be interpreted as the LE-MNL.
5 Scaling the Mental Number Axes
The logarithmic scaling of the mental number axis, synthesized by the mind in accordance with the summation mechanism (CASAN-axis mechanism), may be explained by reference to an implementation mechanism of the mental number axis in the neuronal net, described by definitions: (Df. Val K,n ,1), (Df. Val K,n ,2) and (Df. Imp K,n ). For instance, if one assumes that the length of a section on the summation mental number CASAN-axis is proportional to the number of neurons required to store it in the mind (that is, for its implementation in the brain), then the logarithmic scaling of this axis may be explained by a power-saving mechanism of activation in processes of coding and saving numerical representations. If the scale of the mental number axis were linear (that is, for any two numerical summation representations O m(α) and O m(β), the lengths of point-intervals [Ψ(α),Ψ(O m(α))] and [Ψ(β),Ψ(O m(β))] were equal), then the number of neurons engaged in the synthesis of any summation numerical representation would be greater than the number needed for the synthesis of that representation in accordance with the logarithmic scale determined by the definition of the neuronal valuation function Val K,n . Moreover, if the value of the logarithmically-encoded number increases, then the gain by the power-saving activation of neurons also increases.
This sketch of an explanation assumes that a single neuron cannot be a tool for the implementation of the coding unit P n i on the ground of BASAN-structures and CASAN-structures. Furthermore, in the case of logarithmic scaling, the number of coding neurons correlated with the coding unit P n i decreases with iterations of the operation O in processes of the iterated prolongation of sections which represent numbers. This theoretical model predicts that the summation mechanism of coding number representations has a limitation. At some point, the amount of neurons required for the implementation of the coding unit P n i will be exhausted, since the mechanism involves the use of fewer and fewer neurons with each subsequent iteration of the operation O.
The question, however, remains: Are point-place mental number axes scaled logarithmically or linearly? According to the mechanism of logarithmic scaling, sections which encode numbers should get shorter as the value of encoded numbers increases. On the mental number axis synthesized in accordance with the point-place mechanism of encoding numbers, for each selection function δz, sections which represent numbers get longer as the value of encoded numbers increases. This is confirmed indirectly in (Cohen and Blanc-Goldhammer 2011). Furthermore, if an exponent in δz decreases, then the lengths of sections representing consecutive natural numbers increase. Hence, if the length of a section representing a given number is proportional to the number of neurons required for the activation of that representation, then the number of neurons required for the activation of a number representation on any point-place axis for each δz increases with each increase in numeral value. Moreover, it is worth noting that for sufficiently high values of exponents of the function δz, representations of numbers belonging to the starting interval are points, not sections. The extension of this starting interval on the point-place axis increases with the increase of the exponent of the selection function δz. Hence, we may accept the hypothesis that for each point-place axis, its starting interval of point-representations is scaled logarithmically, whereas the remainder of the axis consisting of place-representations gradually loses its logarithmic scale with the increase in values of represented numbers. This means that the sequence of distances between middles of consecutive sections representing numbers maps a logarithmic scale with decreasing accuracy.Footnote 1 It seems that the presence of a logarithmic scale on any point-place axis is not absolute; logarithmic scaling is relative. The process of scaling a point-place axis might be modeled in the following way: The mind first attributes three numbers (one, two, three) to points on an axis (representations underlying acts of subitizing); subsequently, it logarithmically scales sections representing numbers up to some limit on a given point-place axis.
By comparing the number of neuronal activations required for the implementation of summation number representations with the number required for point-place representations, it is easy to observe the neuronal activation advantage in favor of the point-place mechanism. This conclusion may be illustrated by the following chart (Table 1).
The chart also shows that the mechanism for transforming CASAN-axes into CAPPAN-axes may be explained by processes of diminishing high processing loads of CASAN-axes.
The question arises: What is the mechanism for the transformation of the logarithmic axis determined by Ω z→∞(z) into the so-called mental axis of exact numbers? Since the logarithmic scale of an axis is a function of the logarithmic scale imposed on successive numbers of neuronal activations required for implementing point-representations on an axis, then the linear scale of an axis should be implemented on the same numbers of neuronal activations. In the case of the logarithmic scale, the neuronal process of distinguishing between groups of neuronal activations manifests in the mind as the process of distinguishing between corresponding number representations. For instance (see the chart above), if the brain detects a group of 2,520 active neurons and distinguishes it from a group of 1,680 active neurons, then the mind correlated to the given brain activates two point-representations of numbers on a given number axis, namely, two and three. When two non-symbolic numerals (for instance, two stones on a pavement and three people standing near them) affect the mind, it is able to distinguish these cardinalities without the use of symbolic numerals (without verbal numerals and digits) in its experience, because the brain underlying the mind distinguishes between numbers of neuronal activations affected by two stones and three people. Therefore, the disappearance of the logarithmic scale of the mental number axis would cause the disappearance of the ability to non-verbally differentiate between non-symbolic numerals affecting the mind in various life-situations. In what ways could the brain distinguish between the same numbers of neuronal activations underlying different number representations belonging to a linearly scaled exact mental number axis?
Since number representations are associated with linguistic representations of symbolic numerals (representations of numeral inscriptions or of spoken numerals), the brain may differentiate two equinumerous groups of neuronal activations by distinguishing between different linguistic representations of symbolic numerals. This means that the mind is able to transform logarithmic mental number axes into linear mental axes of exact numbers only when it has mastered names of numbers (digit numerals as well as verbal numerals). When two non-symbolic numerals affect the mind, they cause processes of neuronal activations which implement appropriate number representations in the brain. In this way, the mind activates a mental number axis for some precision value of computational intention. When Ω(z) = Ω z→∞(z), the mind activates the logarithmic point-axis on which every point-representation is associated with some linguistic representation of a corresponding numeral. In the next phase, the brain transforms the logarithmic scale of successive numbers of neuronal activations underlying point-representations of corresponding numbers into a linear scale. On the cerebral level of implementation, this process consists in leveling the number of neuronal activations underlying number representations belonging to a given axis. It should be noticed, however, that the activation of any linear mental number axis is always accompanied by the activation of linguistic representations of symbolic numerals. In this way, when the mind is affected by some non-symbolic numeral, it has a tendency to verbally respond to it.
What is the desirability of this process? If one assumes that leveling the number of neuronal activations underlying number representations involves the reduction of the number of neuronal activations in each group of neurons implementing number representations belonging to a point-axis, then the mechanism of the transformation of logarithmic axes into linear axes results in power-saving neuronal activation. Such a transformation might be interpreted as a mechanism protecting the brain from computational overworking. According to the definition (Df. Val K,j , 1 and 2), the brain is not able to implement long logarithmic number axes. For instance, for j ≥ 20, the number of neurons in the brain is not sufficient to implement axes greater than 20-points long. In such situations, the brain first implements relatively short, linearly-scaled axes of exact numbers and then extends them to the required length. This process is conditioned by processes of neuronal activations which implement representations of symbolic numerals.
To speak metaphorically, the brain must color groups of neurons underlying number representations with neurons underlying representations of corresponding symbolic numerals. They function as colors indicating that equinumerous groups of active neurons implement different number representations. Let C 1,…, C m be linguistic representations of symbolic numerals designating, respectively, numbers: 1,…, m. Let α m be a point-representation of the number m. Let Val K be the neuronal valuation function attributing representations of symbolic numerals to groups of appropriate active neurons, where K stands for the intensity of the implementation process. Let Γ be the function of coloring neuronal implementations of number representations defined in the following way:
Γ attributes values Val K (C m ) to values Val K,n (m). This function is acquired by the brain as children practice using numerals. Hence, associations of implementations of point-representations with implementations of representations of symbolic numerals may be treated as pairs of the shape: 〈Imp K,j (α m ), Val K (C m )〉. They may be treated as implementations of linguistic markers of point-representations belonging to the axis determined by the function of computational intention Ω z→∞. When the mind encodes these markers in its memory for the first three or four point-representations, then, by the use of the reduction function (leveling function) Red, its brain reduces values Val K,j (1), Val K,j (2), Val K,j (3), Val K,j (4) to some constant value k.
According to (Df. Red), the function Red is activated under the following condition: (i) representations of symbolic numerals and point-representations of the initial three or four numbers are encoded in the mind, (ii) they are implemented in neuronal activations in the brain by the functions Val K,j and Val K , and (iii) the function Γ colors neuronal implementations underlying point-representations of the initial three or four numbers.
To summarize, first the mind synthesizes summation mental number axes scaled logarithmically. In the next phase, the axes are transformed into point-place mental number axes for chosen selection functions δz coordinated with precise values of the computational intention function Ω. This transformation is enforced by a power-saving mechanism of neuronal activations. In the case of Ω z→∞(z), point-place mental number axes are transformed into point number axes scaled logarithmically. When point-representations of initial numbers are associated with corresponding representations of symbolic numerals, the transformation of the logarithmic scale of point-axes into linear scale axes is activated. In this way, the mind produces a pattern of the exact mental number line stored in memory, which is the starting-point for various arithmetical operations entangled in expert mathematical knowledge.
6 Empirical Verification of the Model
The presented formal model possesses its empirical evidence in the form of observational and experimental facts. One may distinguish the following main categories of evidence: (i) experimental data given in SNARC experiments (in particular, see: Dehaene et al. 1993; Zhou et al. 2008; Brysbaert 1995; Tlauka 2002; Castronovo and Seron 2007; Patro and Haman 2012) (ii) neurophysiological data concerned with processes of neuronal activations during acts of numerical reference; (iii) experimental data showing distance and size effects, and (iv) observational facts consisting in our peculiar numerical abilities, such as: subitizing small cardinalities, estimating quantificational sizes of numbers and, finally, counting high cardinalities in the case of savant syndrome.
6.1 SNARC, Size and Distance Effects in Light of the Model
These effects show that number representations encoded in the mind during acts of numerical reference towards cardinalities, ordinals and magnitudes, which reveal their spatial orientations, may be modelled as fragments of algebraic structures with linear orders. These structures take the shapes of finite mental number axes. Different degrees of the intensity of SNARC effects, which are indicated by different shapes of SNARC-functions observed as slopes on their charts, indicate that two types of mental number axes are encoded in the mind during acts of numerical reference. Experiments show that the intensity of SNARC effects is stronger in encoding than in decoding processes. This is also partly confirmed by experiments concerned with size and distance effects described in (Roggeman et al. 2007). Digits exhibit a weaker intensity of the distance and size effect in relation to non-symbolic numerals which induce encoding processes. That is why representations underlying encoding processes should be modelled in a different way than representations underlying decoding processes.
Priming effects observed in experiments show that acts of referring towards numerals from the range [1, 5] are facilitated by non-symbolic numeral stimuli with numerical values equal to or greater than the primed stimuli. These effects indicate that processes of activation of number representations entail activations of number representations whose number values are adjacent to the number values of representations at input. The above-constructed formal model formalizes these effects for small cardinalities or small ordinals as manifestations of activations of number representations belonging to summation mental number axes.
The phenomenon of the disappearance of priming effects with increased distances between priming numerals and primed numerals on both sides of an axis (Naccache and Dehaene 2001; Roggeman et al. 2007) indicates that the summation coding of number representations does not take place in each case of referring towards cardinalities or ordinals. The disappearance of priming effects is observed in decoding processes. This is interpreted, in accordance with the proposed model, as a marker of the transformation summation mental axes (CASAN-axes) into point-place mental axes (CAPPAN-axes).
6.2 Neurophysiological Data
According to data presented in (Nieder and Miller 2003, 2004; Nieder and Merten 2007), neurons in the brains of macaque monkeys may react centrally or peripherally to a given non-symbolic numeral stimulus. This means that the same neuron may react to many, but not all, of the different cardinalities of non-symbolic numerals. One of these cardinalities is the one which a given neuron is set to encode centrally. Other, relatively close cardinalities are encoded peripherally by other neurons. The activity of neurons attuned to certain number values changes in accordance with some pattern. For each neuron which encodes a succeeding number on the axis, its activity comprises an increasing interval of neurons representing number values that neighbor a given number. As a result, neurons which encode increasing number values became less selective. This effect is formalized in our model by point-place number representations belonging to CAPPAN-axes.
In processes of adaptation (habituation) of the neuronal net within the intra-parietal sulcus, the similar phenomena are also observed. With the progress of habituation, the net reacts to the cardinality N less and less until all reactions to the habituated numeral stimulus disappear. The empirical results indicate that with the increasing distance between a habituated numeral stimulus and an exhibited numeral stimulus, the intensity of activation also increases (Piazza et al. 2004, 2007; Cantlon et al. 2006). The empirical processes of habituation may be treated as empirical markers of the processes of decreasing indices of precision of the computational intention function Ω. When Ω returns CAPPAN-structures of the shape Ω(0), the structure 〈Ψ, M 0, [A n j ], 0, ≤, S, δ0〉 stops responding to a given, sufficiently high numeral. The limiting case of habituation, that is, the complete disappearance of the reaction, is a marker of the process of deactivation of the structure 〈Ψ, M z , [A n j ], 0, ≤, S, δz〉 for any z. The exhibition of the new numeral stimulus induces the process of activation of the new structure 〈Ψ, M w , [A n j ], 0, ≤, S, δw〉 with a sufficiently high index of precision. Along with the increased distance between the habituated numeral stimulus and the new numeral stimulus, the index of precision of computational intention Ω also increases, because of the activation of control attention processes stimulated by the new stimulus.
The greater involvement of attention control in counting tasks when, for instance, a person must compare the values of digits under time pressure, is confirmed by some experimental data (Anobile et al. 2012). In such situations, an index of precision which the function Ω returns is sufficiently high for the sake of operating with linearly scaled mental number axes. As a result, subjects are able to perform exact estimations of cardinalities. CAPPAN-axes, which underlie these acts of exact numerical reference, become generators of punctual number representations. The implementation function Imp K,j attributes these point-representations to groups of the most selective neurons. This effect is formalized in the model as the fact that Imp K,j (α) = 〈Val K,j (m)〉, where α = O m(0). Hence, the degree of selectivity of neurons implementing number representations is designated in the model by the lengths of number representations.
6.3 Subitizing
Our model provides a justification for the theory proposed in (Carey 2004; Le Corre and Carey 2007), according to which the mind of a child does not use the summation mental number axis, but encodes numeral representations in virtue of the parallel individuation mechanism. In accordance with the basic assumption of this conception, the mind of a child is able to generate representations of small manifolds consisting of one, two or three items. The mind uses the mechanism of ascribing the so-called attention-markers to different items given in its perceptual field. In this way, the mind may track all marked items simultaneously. As a result, the mind may individuate a few objects at the same time. Acts of tracking a small number of items in the perceptual field are called acts of subitizing.
The presented formal model predicts the mind’s ability to subitize up to three or even four items in its perceptual field. According to the model, for any selection function δz, the first three representations belonging to any mental number axis M z of any CAPPAN-axis, that is, representations of one, two and three, are points of the following shapes: [1, 1], [2, 2] and [3, 3]. This means that the mind is not able to go wrong when it calculates up to three objects. In other word, the ability to calculate up to three objects correctly is an a priori condition of the ability to calculate and estimate n-cardinality. When the mind uses the selection function δ0, it may go wrong in the case of tasks consisting in the estimation or calculation of cardinalities greater than three. For instance, a child may confuse four objects with three or five objects. But it is impossible for a child to confuse three objects with two objects. In this case, under the use of any selection function, it is meaningless to say that somebody sees approximately three people. Number representations underlying acts of subitizing are, in accordance with our model, initial punctual representations belonging to each CAPPAN-axis. Their punctual structure determines the exactness of subitizing.
In accordance with observations, infants (Feigenson and Carey 2003; Feigenson et al. 2002) and newborns (Antell and Keating 1983) are unable to differentiate cardinalities greater than three. Greater cardinalities are only recognized approximately by infants (Xu and Spelke 2000; Lipton and Spelke 2003). This means that number representations underlying such approximate acts of numerical reference possess the shape of sections belonging to CAPPAN-axes.
According to the model we are constructing, the development of computational abilities is correlated with the mind’s ability to generate and activate the mechanism of selection described by the selection function δz with a sufficiently high index of precision z. In the case of the use of the selection function δ1, the mind encodes all numerals from one to four as point representations. This means that the mind never confuses cardinality four with a lesser cardinality when it calculates the number of elements of various sets with the precision determined by δ1. Such a prediction is determined by the fact that the mental axis of numbers M 1 is composed of the following representations: [1, 1], [2, 2], [3, 3], [4, 4], [4, 6], [5, 7], [6, 8], etc. This way of encoding number representations may be observed in experiments with adults (Trick and Pylyshyn 1994) and with some animals (Hauser and Carey 2003). The representation of the number seven on the axis M 1 is the interval [6, 8]. When the mind estimates the cardinality of some class with seven elements, it may confuse this cardinality with all the cardinalities belonging to the interval [6, 8]. Our model predicts that in this case the mind never confuses the cardinality seven with cardinalities five or less than five and nine or greater than nine. This means that when the mind sees at a glance the seven-element manifold of items, then it will never assert that it perceives four objects.
Our model explains the phenomenon of the computational savant syndrome, which manifests in the ability to count high cardinalities (dots on a screen, people in a crowd, etc.). The mind which is able to count at a glance, for instance, fifteen dots on a screen, in an unambiguous way, functions in accordance with the computational mechanism determined by the selection function δz with a very high degree of precision (with high z). This ability would be a special case of the ability of subitizing. Our model predicts that ability to subitize up to ten items in the perceptual field requires the use of the selection function δ4. The number which designates the upper limit of subitizing might be treated as a marker of the degree of precision in the selection function δz.
The ability of parallel individuation (enabling acts of subitizing) for M 0 comprises only the first three cardinalities; for M 1 the mind is able to individuate up to five items at the same time. For M 2, the range of effective parallel individuation (subitizing) increases and comprises cardinalities up to seven. It is obvious that in perceptual situations there exists some limit to the degree of computational intention which the mind is not able to exceed. To generalize, if the degree of computational intention increases to some extent, then the range of effective parallel individuation expands. Hence, our model also explains how potential artificial minds might be able to individuate items belonging to classes with very large cardinalities.
6.4 Estimating Quantificational Sizes of Numbers
The logarithmic scaling of mental CASAN-axes may be considered responsible for computational skills consisting in the situational or contextual estimations of values (sizes) of natural numbers. In some situations, children estimate that two or three sweets are a small numbers of sweets. In the case of one hundred or two hundred specimens of a calculated collection, children’s estimations are often expressed with the phrase it is many. In some situations, children respond to the numeral million by the use of words expressing their astonishment at its numerical size. Such competence in assigning numbers to their quantificational sizes, understood as the subjective length of time needed for calculating all objects belonging to a set with a cardinality equal to a given number, also appears in various everyday situations in which the mature mind must evaluate the quantificational size of numbers whose numerals stand for cardinalities of various collections. The mind often uses verbal scales for the sake of estimating quantificational sizes of numbers. Some of these scales are created ad hoc in communicational situations. Let us take the following scale as an example: less than little, little, less than middling, middling, many, greater than many, extremely many. For some people, $2,000 is quite a lot of money, but for others it is little. An order of two thousand bricks in a building may be estimated as small, whereas a gardener who wants to build a small composter may estimate the quantificational size of two thousands bricks with the phrase, ‘too many’.
By virtue of the summation mechanism, a representation of each consecutive number is synthesized as a prolongation or an abridgement of a section at the input by the use of the coding unit P n j . With the logarithmic scale, the length of a coding unit decreases with the increase of an encoded number value in the summation way. Hence, the quantificational size of a number in a given encoding situation is correlated with the length of a coding unit P n j used by the mind in the last phase of the synthesis of a given number representation. If such a process requires the use of a relatively short coding unit P n j , then the mind will have a tendency to estimate a given number as high or very high. If a coding unit used in the synthesis of a given number representation is relatively long, then the mind will have a tendency to estimate a given number as low or very low. In this way, numbers ascribed by the mind to various collections determine the quantificational sizes of their cardinalities. One hundred apples may be comprehended as many because, for the sake of the synthesis of the number representation one hundred in a given encoding situation, the mind uses a short coding unit P n j in the last stage of the synthesis of the representation of the number one hundred. The same number representation may be synthesized by the use of a long coding unit in another encoding situation: for instance, when a person estimates the amount of a lump of money in her wallet. In this case, her mind estimates the number one hundred as low and thereby classifies the money in her wallet as little money. The number one is always estimated, regardless of the context, as a little (low) number.
Lengths of coding units P are determined by two parameters: (i) the value of neuronal activation of the point belonging to a given number representation α, synthesized in the last stage of the process of formatting α, and (ii) the value of the neuronal activation of the referential number code F i,n used in the process of formatting α. If α = O m(F i,n ), α = O h(〈0, P n j 〉) and F i,n = O t(〈0, P n j 〉), then the length of a unit coding P n j used in the last stage of synthesizing α is expressed by the ratio Val K,j (h)/Val K,j (t), where h = t + m. If h increases, then Val K,j (h) tends to zero. Hence, Val K,j (h)/Val K,j (t) also tends to zero. As a result, the length of a coding unit P n j used in the last step of the synthesis of α is estimated as short, and, thereby, the quantificational size of the number represented by α is estimated as high, great, big or even huge. If α = O −m(F i,n ), α = O h(〈0, P n j 〉) and F i,n = O t(〈0, P n j 〉), then the length of a unit coding P n j used in the last stage of synthesizing α is also expressed by the ratio Val K,j (h)/Val K,j (t), In this situation, however, h = t - m. If h decreases, then Val K,j (h) tends to Val K,j (1), Hence, Val K,j (h)/Val K,j (t) tends to return high number values. As a result, the quantificational size of the number represented by α is estimated as high. If Val K,j (h) and Val K,j (t) take similar number values, then the estimation of the quantificational size of the number represented by α depends on the estimation of the quantificational size of the number represented by the referential number code F j,n .
It is very difficult to explain the mind’s ability and inclination to assign numbers to their quantificational size by the mechanism of arithmetic scaling. On the summation axis scaled arithmetically, differences between lengths of consecutive number representations are constant. Hence, only their lengths might serve as markers of quantificational sizes of numbers. Such a mechanism imposes the same length upon a given representation, regardless of the context. Hence, the number ten, for instance, would have to be estimated by the mind in each situation as having the same quantificational size. This is not, however, the case. Ten broken teeth after boxing or ten children in a family manifest themselves as many, whereas ten people at a Madonna concert will always be estimated as an extremely small audience. Such a discrepancy in the estimation of the number ten in terms of its quantificational size may be easily explained on the basis of the model of logarithmically-scaled summation axes. When the mind synthesizes the representation of the number ten in the case of broken teeth or children in a family, it usually starts this process from a synthesis of the representation of some fixed number (that is, from a referential number code F j,n ); subsequently, by prolongation of F j,n , it finishes the synthesis by reaching the representation of ten. In the situation under analysis, F j,n is the representation of some number less than ten. It may be, for instance, the representation of number of teeth broken during a boxing match or the number of a friend’s children. If F j,n is the representation of the number one, then the length of the coding unit used in the synthesis of the representation of ten in the last phase is relatively short in comparison to the length of P n j used in the first step of the synthesis of the given representation. According to the logarithmic scale of the mental number axis, the ratio of the length of coding unit P used in the last phase of the synthesis of the representation of ten to the length of P n j used in the first step of the process of number representation synthesis (in this case, the length of the difference between the lengths of the representations of two and one) is 20 %. On the other hand, if the mind synthesizes the representation of the number ten in the situation of an audience at a Madonna concert, then it starts this process by a shortening mechanism from some referential number code F j,n , which is a representation of some number far greater than ten. Madonna concerts draw tens of thousands of people. There is thus a very large ratio of the length of coding unit P n j used in the last stage of synthesis of the number representation ten to the length of coding unit P n j used in the first step of the process of synthesis by the mechanism of shortening. This means that the length of the coding unit used in the last phase of the synthesis of the representation of ten is relatively long. Hence, the mind estimates the number of ten people at a Madonna concert as very small. To summarize, if the lengths of coding units used in the last phases of the synthesis of a number representation are relatively long, then the number represented by the given representation will be estimated by the mind as small with regards to its quantificational size. If the lengths of coding units used in the last phases of synthesis are relatively short, then the estimation of the given number with respect to its quantificational size will result in the verdict great.
7 Concluding Notes
The present paper presents a formal model of the system of number representations as a multiplicity of mental number axes with a hierarchical structure. The hierarchy is determined by the mind as it acquires successive types of mental number axes. The first level of hierarchy consists of the mechanism which enables to generate summation mental number axes of three types: SMNL-axes, BASAN-axes and CASAN-axes. Axes of the first type are consisted of two points and they are responsible for the Simon effect (see Krysztofiak 2012) and our ability to subitize manifolds consisting of two items. With the cognitive development of an infant, the mechanism of formatting SMNL-axes is transformed into the mechanism of formatting axes of the second type, described by axioms of algebras of the shape 〈L, A n i , F i,n , P n i , O〉. Mental number axes determined by BASAN-structures are synthesized by the mind only by the use of the operator of prolongation O. The multiplicity of BASAN-structures is determined by the plurality of coding units P n i , the referential number codes F i,n and the length i of axes. As a result of the cognitive development of the mind, BASAN-structures are transformed into CASAN-structures which generate the mechanism of synthesizing summation mental number axes, not only by the use of the prolongation operator, but additionally by the use of the shortening operator O −. All axes generated by CASAN-structures stem from the representation of the number zero. This second category of mental number axes is determined by algebraic structures of the shape 〈L, F i,n , P n i , O, O −, 0, A n i 〉. This does not, however, mean that the mind’s ability to synthesize mental number axes according to BASAN-structures disappears. Both BASAN-structures and CASAN-structures generate number representations belonging to summation mental number axes in processes of encoding numbers; that is, in processes in which non-symbolic numerals affect the mind.
In the next phase of cognitive development, the mind transforms the generative mechanism based on CASAN-structures into a generative mechanism for synthesizing point-place mental number axes determined by CAPPAN-structures of the shape 〈Ψ, M z , [A n j ], 0, ≤, S, δz〉. This transformation is caused by the power-saving mechanism of neuronal activations which implement number representations in the brain. The function of computational intention Ω(z), playing a key role in this mechanism, generates algebraic structures correlated with various degrees of computational precision (precise values), in virtue of which the mind synthesizes corresponding point-place approximate mental number axes. In this phase, the mind acquires the ability to synthesize approximate point-place mental number axes with increasing degrees of precision. Hence, the development of abilities to control attention supports processes of synthesizing point-place mental axes with increasingly precise values. This phase is ended when the mind acquires the ability to synthesize exact mental number axes determined by Ω z→∞(z), where z → ∞ stands for maximal precision.
In the third phase, the logarithmic scale of mental number axes generated by the mechanism 〈Ω z→∞(z), 〈Ψ, M z , [A n j ], 0, ≤, S, δz≫ is transformed into a linear scale. This transformation is necessitated by the impossibility of implementing sufficiently long mental axes of exact numbers in the neuronal net. Its success may be crowned only in the case of the mind acquiring verbal numerals. If the mind creates associations of number representations with representations of verbal numerals, then it may synthesize representations of arbitrarily large numbers on the mental exact-number axes. The process of the creation of such associations consists in marking (coloring) neuronal implementations of point-number representations by neuronal implementations of representations of verbal numerals. It is governed by the function of reduction defined in (Df. Red). The ability to synthesize linearly scaled point-number axes allows the mind to build a mature mathematical competence.
The system of number representations is thus correlated in the mature mind with a system of linguistic representations of symbolic numerals which is also divided into at least two subsystems. One comprises representations of verbal numerals, whereas the other consists of representations of digit numerals. Both subsystems are associated in every mind which functions efficiently. However, it seems that the relation of translatability of both subsystems is settled by a third system: namely, the system of representations of logical symbolic numerals. This system enables the mind to translate verbal numerals into Arabic digit numerals and vice versa.
This model should have better verification. In particular, the hypothesis of many mental number axes generated by the mind in virtue of various algebraic mechanisms should be empirically tested. Research should aim at the construction of a formal model describing associations of number representations with representations of numerals. This requires, in turn, the construction of a logical grammar of numerals.
This last task should be focused upon investigations concerned with relations between mental number axes and semantic models of Peano arithmetic. In what ways are mental number axes transformed into semantic models of PA? Are they transformed into non-standard semantic models? These questions are a challenge for defenders of the philosophical conception of the origin of our expert mathematical knowledge from ‘folk mathematics.’
Notes
This hypothesis explains some empirical facts. If, in the classic experiment on axis scaling, subjects are first asked to locate relatively small numbers on the axis from 0 to 100 (for instance: 1, 4, 5, 10), and, subsequently, they must locate numbers from the interval (90, 100) on the same axis, then their marks on the axis run into one another. For numbers from the interval (90, 100), the marks with consecutive distances between them are constant. This is why such a fact may be interpreted as the empirical manifestation of the theoretical phenomenon of gradually losing logarithmic scale by an axis. However, from a logarithmic scaling point of view, if the distance from the starting point (zero) to one in the interval (0, 100) is sufficiently small, then distances between points from the interval (90, 100) are not perceptually distinguishable.
References
Anobile G, Cicchini GM, Burr DC (2012) Linear mapping of numbers onto space requires attention. Cognition 133(1):454–459
Antell SE, Keating D (1983) Perception of Numerical Invariance in Neonates. Child Dev 54:695–701
Barth HC, Paladino AM (2011) The development of numerical estimation: evidence against representational shift. Dev Sci 14(1):125–135
Berteletti I, Lucangeli D, Piazza M, Dehaene S, Zorzi M (2010) Numerical estimation in preschoolers. Dev Psychol 46:545–551
Booth JL, Siegler RS (2006) Developmental and individual differences in pure numerical estimation. Dev Psychol 41:189–201
Brysbaert M (1995) Arabic number reading: on the nature of the numerical scale and the origin of phonological recoding. J Exp Psychol Gen 124(434):452
Cantlon JF, Brannon EM, Carter EJ, Pelphrey KA (2006) Functional imaging of numerical processing in adults and 4-y-old children. PLoS Biol 4:844–854
Carey S (2004) Bootstrapping and the origins of concepts. Daedalus 133(1):59–68
Castronovo J, Seron X (2007) Semantic numerical representation in blind subjects: the role of vision in the spatial format of the mental number line. Q J Exp Psychol 60:101–119
Cohen DJ, Blanc-Goldhammer D (2011) Numerical bias in bounded and unbounded number line tasks. Psychon Bull Rev 18(2):331–338
Dehaene S, Bossini S, Giraux P (1993) The mental representation of parity and number magnitude. J Exp Psychol Gen 122(3):371–396
Eimer M, Hommel B, Prinz W (1995) S-R compatibility and response selection. Acta Psychol 90:301–313
Feigenson L, Carey S (2003) Tracking individuals via object-files: evidence from infants’ manual search. Dev Sci 6:568–584
Feigenson L, Carey S, Hauser M (2002) The representations underlying infants’ choice of more: object-files versus analog magnitudes. Psychol Sci 13:150–156
Gevers W, Lammertyn J (2005) The hunt for SNARC. Psychol Sci 47:10–21
Hauser M, Carey S (2003) Spontaneous representations of small numbers of objects by rhesus macaques: examinations of content and format. Cognitive Psychol 47:367–401
Hommel B (1994) Spontaneous decay of response-code activation. Psychol Res 56:261–268
Krysztofiak W (2012) Logiczna składnia liczebnika. Studium kognitywistyczne. Część I. Filozofia Nauki 20(1):59–91
Krysztofiak W (2015) Representational structures of arithmetical thinking: part I. Axiomathes. doi:10.1007/s10516-015-9271-1
Le Corre M, Carey S (2007) One, two, three, four, nothing more: an investigation of the conceptual sources of the verbal counting principles. Cognition 105:395–438
Lipton JS, Spelke ES (2003) Origins of number sense: large-number discrimination in human infants. Psychol Sci 14:396–401
Naccache L, Dehaene S (2001) The priming method: imaging unconscious repetition priming reveals an abstract representation of number in the parietal lobes. Cereb Cortex 11:966–974
Nieder A, Merten K (2007) A labeled-line code for small and large numerosities in the monkey prefrontal cortex. J Neurosci 27:5986–5993
Nieder A, Miller EK (2003) Coding of cognitive magnitude: compressed scaling of numerical information in the primate prefrontal cortex. Neuron 37:149–157
Nieder A, Miller EK (2004) A parieto-frontal network for visual numerical information in the monkey. Proc Natl Acad Sci USA 101:7457–7462
Patro K, Haman M (2012) The spatial-numerical congruity effect in preschoolers. J Exp Child Psychol 111:534–542
Piazza M, Izard V, Pinel P, Le Bihan D, Dehaene S (2004) Tuning curves for approximate numerosity in the human intraparietal sulcus. Neuron 44:547–555
Piazza M, Pinel P, Le Bihan D, Dehaene S (2007) A magnitude code common to numerosities and number symbols in human intraparietal cortex. Neuron 53:293–305
Roggeman C, Verguts T, Fias W (2007) Priming reveals differential coding of symbolic and nonsymbolic quantities. Cognition 105:380–394
Siegler RS, Booth JL (2004) Development of numerical estimation in young children. Child Dev 75:428–444
Siegler RS, Opfer JE (2003) The development of numerical estimation: evidence for multiple representations of numerical quantity. Psychol Sci 14:237–243
Simon JR (1969) Reaction toward the source of stimulation. J Exp Psychol 81:1974–1976
Tlauka M (2002) The processing of numbers in choice-reaction tasks. Aust J Psychol 54:94–98
Trick L, Pylyshyn ZW (1994) Why are small and large numbers enumerated differently? A limited capacity preattentive stage in vision. Psychol Rev 101:80–102
Xu F, Spelke ES (2000) Large number discrimination in 6-month old infants. Cognition 74:B1–B11
Zhou X, Chen C, Chen L, Dong Q (2008) Holistic or compositional representation of two-digit numbers? Evidence from the distance, magnitude, and SNARC effects in a number-matching task. Cognition 106:1525–1536
Acknowledgments
The paper is part of the project No [anonymous DEC-2011/o1/B/HS1/04029], supported by The National Centre of Science in Poland. The author thanks to Katarzyna Patro from The University of Warsaw for her creative assistance in developing empirical evidence of formal models constructed in the paper. My discussions with K. Patro contributed to a number of theoretical ideas proposed in the article.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Krysztofiak, W. Algebraic Models of Mental Number Axes: Part II. Axiomathes 26, 123–155 (2016). https://doi.org/10.1007/s10516-015-9270-2
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10516-015-9270-2