
Abstract
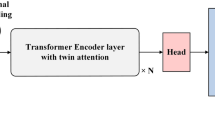
This paper presents Volumetric Transformer Pose Estimator (VTP), the first 3D volumetric transformer framework for multi-view multi-person 3D human pose estimation. VTP aggregates features from 2D keypoints in all camera views and directly learns the spatial relationships in the 3D voxel space in an end-to-end fashion. The aggregated 3D features are passed through 3D convolutions before being flattened into sequential embeddings and fed into a transformer. A residual structure is designed to further improve the performance. In addition, the sparse Sinkhorn attention is empowered to reduce the memory cost, which is a major bottleneck for volumetric representations, while also achieving excellent performance. The output of the transformer is again concatenated with 3D convolutional features by a residual design. The proposed VTP framework integrates the high performance of the transformer with volumetric representations, which can be used as a good alternative to the convolutional backbones. Experiments on the Shelf, Campus and CMU Panoptic benchmarks show promising results in terms of both Mean Per Joint Position Error (MPJPE) and Percentage of Correctly estimated Parts (PCP). Our code will be available.









Similar content being viewed by others

Data Availability
The datasets generated during the current study are available in the CMU Panoptic Dataset(domedb.perception.cs.cmu.edu), Campus (https://www.epfl.ch/labs/cvlab/data/data-pom-index-php/) and Shelf(http://campar.in.tum.de/Chair/MultiHumanPose.
References
Zhang, J. Cai, Y. Yan, S. Feng, J. et al. (2021) Direct multi-view multi-person 3d pose estimation. Advances in Neural Information Processing Systems 34
Dong, J ,Jiang, W. Huang, Q. Bao, H. Zhou, X. (2019) Fast and robust multi-person 3d pose estimation from multiple views. In:Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp 7792–7801
Huang, C. Jiang, S. Li, Y. Zhang, Z. Traish, J. Deng, C. Ferguson, S. Xu, R.Y.D. (2020) End-to-end dynamic matching network for multi-view multi-person 3d pose estimation. In: European Conference on Computer Vision, pp 477–493
Tu, H. Wang, C. Zeng, W. (2020) Voxelpose Towards multi-camera 3d human pose estimation in wild environment. In: European Conference on Computer Vision, pp 197–212. Springer
Wu, S. Jin, S. Liu, W. Bai, L. Qian, C. Liu, D. Ouyang, W. (2021) Graph-based 3d multi-person pose estimation using multi-view images. In: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp 11148–11157
Iskakov, K. Burkov, E. Lempitsky, V. Malkov, Y. (2019) Learnable triangulation of human pose. In: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp 7718–7727
Qiu, H. Wang, C. Wang, J. Wang, N. Zeng, W. (2019) Cross view fusion for 3d human pose estimation. In: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp 4342–4351
Li Z, Oskarsson M, Heyden A (2022) Detailed 3d human body reconstruction from multi-view images combining voxel super-resolution and learned implicit representation. Applied Intelligence 52(6):6739–6759
Zhang, Y. An, L. Yu, T. Li, X. Li, K. Liu, Y. (2020) 4d association graph for realtime multi-person motion capture using multiple video cameras. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp 1324–1333
Vaswani, A. Shazeer, N. Parmar, N. Uszkoreit, J. Jones, L. Gomez, A.N. Kaiser, L. Polosukhin, I. (2017) Attention is all you need. Advances in neural information processing systems 30
Carion, N. Massa, F. Synnaeve, G. Usunier, N. Kirillov, A. Zagoruyko, S. (2020) End-to-end object detection with transformers. In: European Conference on Computer Vision, pp 213–229
Zhu, X. Su, W. Lu, L. Li, B. Wang, X. Dai, J. (2020) Deformable detr: Deformable transformers for end-to-end object detection. arXiv:2010.04159
Mao, J. Xue, Y. Niu, M. Bai, H. Feng, J. Liang, X. Xu, H. Xu, C. (2021) Voxel transformer for 3d object detection. In:Proceedings of the IEEE/CVF International Conference on Computer Vision, pp 3164–3173
Guan, T. Wang, J. Lan, S. Chandra, R. Wu, Z. Davis, L. Manocha, D. (2022) M3detr: Multi-representation, multi-scale, mutual-relation 3d object detection with transformers. In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pp 772–782
Dosovitskiy, A. Beyer, L. Kolesnikov, A. Weissenborn, D. Zhai, X. Unterthiner, T. (2020) Dehghani, M. Minderer, M. Heigold, G. Gelly, S. et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929
Liu, Z. Lin, Y. Cao, Y. Hu, H. Wei, Y. Zhang, Z. Lin, S. Guo, B. (2021) Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pp 10012–10022
Li, N. Chen, Y. Li, W. Ding, Z. Zhao, D. (2022) Bvit: Broad attention based vision transformer. arXiv:2202.06268
Sun, C. Myers, A. Vondrick, C. Murphy, K. Schmid, C. (2019) Videobert: A joint model for video and language representation learning. In: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp 7464–7473
Girdhar, R. Carreira, J. Doersch, C. Zisserman, A. (2019) Video action transformer network. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp 244–253
Lee, S. Yu, Y. Kim, G. Breuel, T. Kautz, J. Song, Y. (2020) Parameter efficient multimodal transformers for video representation learning. arXiv preprint arXiv:2012.04124
Wang, Y. Xu, Z. Wang, X. Shen, C. Cheng, B. Shen, H. Xia, H. (2021) End-to-end video instance segmentation with transformers. In:Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp 8741–8750
Yang, F. Yang, H. Fu, J. Lu, H. Guo, B. (2020) Learning texture transformer network for image super-resolution. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp 5791–5800
Qiu, C. Yao, Y. Du, Y. (2021) Nested dense attention network for single image super-resolution. In: Proceedings of the 2021 International Conference on Multimedia Retrieval, pp 250–258
Cai, R. Ding, Y.Lu, H. (2021) Freqnet: A frequency-domain image super-resolution network with dicrete cosine transform. arXiv:2111.10800
Mao, W. Ge, Y. Shen, C. Tian, Z. Wang, X. Wang, Z. Hengel, A.v.d. (2022) Poseur: Direct human pose regression with transformers. arXiv:2201.07412
Mao, W. Ge, Y. Shen, C. Tian, Z. Wang, X. Wang, Z. (2021) Tfpose: Direct human pose estimation with transformers. arXiv:2103.15320
Li, K. Wang, S. Zhang, X. Xu, Y. Xu, W. Tu, Z. (2021) Pose recognition with cascade transformers. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp 1944–1953
Stoffl, L. Vidal, M. Mathis, A. (2021) End-to-end trainable multi-instance pose estimation with transformers. arXiv:2103.12115
Lin, K. Wang, L. Liu, Z. (2021) End-to-end human pose and mesh reconstruction with transformers. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp 1954–1963
Sun, X. Xiao, B. Wei, F. Liang, S. Wei, Y. (2018) Integral human pose regression. In: Proceedings of the European Conference on Computer Vision (ECCV), pp 529–545
Devlin, J. Chang, M.-W. Lee, K. Toutanova, K. (2018) Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv:1810.04805
Adams, R.P. Zemel, R.S. (2011) Ranking via sinkhorn propagation. arXiv:1106.1925
Tay, Y. Bahri, D. Yang, L. Metzler, D. Juan, D.-C. (2020) Sparse sinkhorn attention. In: International Conference on Machine Learning, pp 9438–9447. PMLR
Sinkhorn R (1964) A relationship between arbitrary positive matrices and doubly stochastic matrices. The annals of mathematical statistics 35(2):876–879
Fournier, Q. Caron, G.M. Aloise, D. (2021) A practical survey on faster and lighter transformers. arXiv:2103.14636
Chu, H. Lee, J.-H. Lee, Y.-C. Hsu, C.-H. Li, J.-D. Chen, C.-S. (2021) Part-aware measurement for robust multi-view multi-human 3d pose estimation and tracking. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp 1472–1481
Zhang, Y. Wang, C. Wang, X. Liu, W. Zeng, W. (2021) Voxeltrack: Multi-person 3d human pose estimation and tracking in the wild. arXiv:2108.02452
Kitaev, N. Kaiser, L. Levskaya, A. (2020) Reformer: The efficient transformer. arXiv:2001.04451
Funding
This work was supported by the National Key Research and Development Program under Grant No. 2019YFC0118404, National Natural Science Foundation of China under Grant No.U20A20386, Zhejiang Provincial Science and Technology Program in China under Grant No. LQ22F020026, Zhejiang Natural Science Foundation under Grant No. QY19E050003, Zhejiang Key Research and Development Program under Grant No.2023C03194, Zhejiang Key Research and Development Program under Grant No. 2020C01050, the Key Laboratory fund general project under Grant No. 6142110190406, the key open project of 32 CETC under Grant No. 22060207026, the Open project of State Key Laboratory of CAD & CG at Zhejiang University under Grant No. A2212, Fundamental Research Funds for the Provincial Universities of Zhejiang under Grant No.GK219909299001-028.
Author information
Authors and Affiliations
Corresponding authors
Ethics declarations
Conflicts of interest/Competing interests
Gangyong Jia has received research grants from the National Natural Science Foundation of China, the \(32^{nd}\) Research Institute of China Electronics Technology Group Corporation (CETC), National University of Defense Technology and Zhejiang and Provincial Natural Science Foundation of China. Renshu Gu has received research grants from the Zhejiang Provincial Natural Science Foundation of China, the State Key Laboratory of CAD & CG at Zhejiang and Hangzhou Dianzi University.The authors declare they have no non-financial interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Chen, Y., Gu, R., Huang, O. et al. VTP: volumetric transformer for multi-view multi-person 3D pose estimation. Appl Intell 53, 26568–26579 (2023). https://doi.org/10.1007/s10489-023-04805-z
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10489-023-04805-z