
Abstract
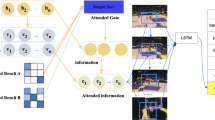
Video captioning is a computer vision task that generates a natural language description for a video. In this paper, we propose a multimodal attention-based transformer using the keyframe features, object features, and semantic keyword embedding features of a video. The Structural Similarity Index Measure (SSIM) is used to extract keyframes from a video. We also detect the unique objects from the extracted keyframes. The features from the keyframes and the objects detected in the keyframes are extracted using a pretrained Convolutional Neural Network (CNN). In the encoder, we use a bimodal attention block to apply two-way cross-attention between the keyframe features and the object features. In the decoder, we combine the features of the words generated up to the previous time step, the semantic keyword embedding features, and the encoder features using a tri-modal attention block. This allows the decoder to choose the multimodal features dynamically to generate the next word in the description. We evaluated the proposed approach using the MSVD, MSR-VTT, and Charades datasets and observed that the proposed model provides better performance than other state-of-the-art models.












Similar content being viewed by others


References
Aafaq N, Akhtar N, Liu W, Gilani SZ, Mian A (2019) Spatio-temporal dynamics and semantic attribute enriched visual encoding for video captioning. In: Proceedings of the IEEE conference on computer vision and pattern recognition (CVPR), pp 12487–12496
Abraham KT, Ashwin M, Sundar D, Ashoor T, Jeyakumar G (2017) An evolutionary computing approach for solving key frame extraction problem in video analytics. In: 2017 International conference on communication and signal processing (ICCSP), pp 1615–1619
Anderson P, Fernando B, Johnson M, Gould S (2016) Spice: Semantic propositional image caption evaluation. In: Leibe B, Matas J, Sebe N, Welling M (eds) Computer Vision – ECCV 2016, pp 382–398
Carreira J, Zisserman A (2017) Quo vadis, action recognition? A new model and the kinetics dataset. In: Proceedings of the IEEE conference on computer vision and pattern recognition (CVPR)
Chen DL, Dolan WB (2011) Collecting highly parallel data for paraphrase evaluation. In: Proceedings of the 49th annual meeting of the association for computational linguistics: human language technologies, pp 190–200
Chen M, Li Y, Zhang Z, Huang S (2018a) TVT: two-view transformer network for video captioning. In: Proceedings of the 10th asian conference on machine learning, ACML, vol 95, pp 847–862
Chen Y, Wang S, Zhang W, Huang Q (2018b) Less is more: Picking informative frames for video captioning. In: Proceedings of the 2018 european conference on computer vision(ECCV), pp 367–384
Denkowski M, Lavie A (2014) METEOR universal: Language specific translation evaluation for any target language. In: Proceedings of the ninth workshop on statistical machine translation, pp 376–380
Gan Z, Gan C, He X, Pu Y, Tran K, Gao J, Carin L, Deng L (2017) Semantic compositional networks for visual captioning. In: Proceedings of the 2017 IEEE conference on computer vision and pattern recognition (CVPR), pp 1141–1150
Gao L, Guo Z, Zhang H, Xu X, Shen HT (2017) Video captioning with attention-based LSTM and semantic consistency. IEEE Transactions on Multimedia 19(9):2045–2055
Gao L, Li X, Song J, Shen HT (2020) Hierarchical LSTMs with Adaptive Attention for Visual Captioning. Trans Patt Anal Mach Intell 42(5):1112–1131
Gao L, Wang X, Song J, Liu Y (2020) Fused GRU with semantic-temporal attention for video captioning. Neurocomputing 395:222–228
Guadarrama S, Krishnamoorthy N, Malkarnenkar G, Venugopalan S, Mooney R, Darrell T, Saenko K (2013) YouTube2Text: Recognizing and describing arbitrary activities using semantic hierarchies and zero-shot recognition. In: Proceedings of the 2013 IEEE international conference on computer vision (ICCV), pp 2712–2719
He K, Zhang X, Ren S, Sun J (2016) Deep residual learning for image recognition. Proceedings of the 2016 IEEE conference on computer vision and pattern recognition (CVPR) pp 770–778
Herdade S, Kappeler A, Boakye K, Soares J (2019) Image captioning: Transforming objects into words. In: Advances in neural information processing systems (NIPS) 2019, vol 32
Hori C, Hori T, Lee T, Zhang Z, Harsham B, Hershey JR, Marks TK, Sumi K (2017) Attention-based multimodal fusion for video description. In: Proceedings of the 2017 IEEE international conference on computer vision (ICCV), pp 4203–4212
Hou J, Wu X, Zhao W, Luo J, Jia Y (2019) Joint syntax representation learning and visual cue translation for video captioning. In: Proceedings of the IEEE international conference on computer vision (ICCV), pp 8918–8927
Jeripothula P, Vishnu C, Mohan C (2022) M-ffn: multi-scale feature fusion network for image captioning. Appl Intell 52:1–13
Ji W, Wang R, Tian Y, Wang X (2022) An attention based dual learning approach for video captioning. Applied Soft Computing 117:108–332
Jin T, Li Y, Zhang Z (2019) Recurrent convolutional video captioning with global and local attention. Neurocomputing 370:118–127
Karpathy A, Fei-Fei L (2017) Deep visual-semantic alignments for generating image descriptions. IEEE Transactions on Pattern Analysis and Machine Intelligence 39(4):664–676
Karpathy A, Toderici G, Shetty S, Leung T, Sukthankar R, Fei-Fei L (2014) Large-scale video classification with convolutional neural networks. In: International conference on computer vision and pattern recognition (CVPR)
Kingma DP, Ba J (2015) Adam: A method for stochastic optimization. In: 3rd International conference on learning representations, ICLR
Lan G, Xiao S, Wen J, Chen D, Zhu Y (2022) Data-driven deepfake forensics model based on large-scale frequency and noise features. IEEE Intelligent Systems pp 1–8
Li G, Zhu L, Liu P, Yang Y (2019) Entangled transformer for image captioning. In: 2019 IEEE/CVF International conference on computer vision (ICCV), pp 8927–8936
Liang G, Lv Y, Li S, Zhang S, Zhang Y (2022) Video summarization with a convolutional attentive adversarial network. Patt Recog 131:108–840
Lin CY (2004) ROUGE: A package for automatic evaluation of summaries. In: Proceedings of the ACL workshop on text summarization branches out, pp 74–81
Liu S, Ren Z, Yuan J (2020) Sibnet: Sibling convolutional encoder for video captioning. IEEE Transactions on Pattern Analysis and Machine Intelligence
Long X, Gan C, de Melo G (2018) Video captioning with multi-faceted attention. Transactions of the Association for Computational Linguistics 6:173–184
Money AG, Agius H (2008) Video summarisation: A conceptual framework and survey of the state of the art. Journal of Visual Communication and Image Representation 19(2):121–143
Pan Y, Yao T, Li H, Mei T (2017) Video captioning with transferred semantic attributes. In: Proceedings of the 2017 IEEE conference on computer vision and pattern recognition (CVPR), pp 984–992
Papineni K, Roukos S, Ward T, jing Zhu W (2002) BLEU: a method for automatic evaluation of machine translation. In: Proceedings of the 40th annual meeting of the association for computational linguistics (ACL), pp 311–318
Pasunuru R, Bansal M (2017) Reinforced video captioning with entailment rewards. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp 979–985
Pennington J, Socher R, Manning C (2014) GloVe: Global vectors for word representation. In: Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP), pp 1532–1543
Redmon J, Divvala S, Girshick R, Farhadi A (2016) You Only Look Once: Unified, real-time object detection. In: 2016 IEEE Conference on computer vision and pattern recognition (CVPR), pp 779–788
Ren S, He K, Girshick R, Sun J (2015) Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. In: Advances in neural information processing systems
Research M (2016) ACM Multimedia MSR video to language challenge
Russakovsky O, Deng J, Su H, Krause J, Satheesh S, Ma S, Huang Z, Karpathy A, Khosla A, Bernstein M, Berg AC, Fei-Fei L (2015) Imagenet large scale visual recognition challenge. J Comput Vis 115(3):211–252
Ryu H, Kang S, Kang H, Yoo CD (2021) Semantic grouping network for video captioning. In: Proceedings of the AAAI conference on artificial intelligence, pp 2514–2522
Shi X, Cai J, Gu J, Joty S (2020) Video captioning with boundary-aware hierarchical language decoding and joint video prediction. Neurocomputing 417:347–356
Sigurdsson GA, Varol G, Wang X, Farhadi A, Laptev I, Gupta A (2016) Hollywood in homes: Crowdsourcing data collection for activity understanding. In: Leibe B, Matas J, Sebe N, Welling M (eds) Computer Vision – ECCV 2016, pp 510–526
Sreeja M, Kovoor BC (2021) A unified model for egocentric video summarization: an instance-based approach. Computers & Electrical Engineering 92:107–161
Szegedy C, Ioffe S, Vanhoucke V, Alemi AA (2016) Inception-v4, inception-resnet and the impact of residual connections on learning. In: International conference on learning representation (ICLR) 2016 Workshop
Tran D, Bourdev L, Fergus R, Torresani L, Paluri M (2015) Learning spatiotemporal features with 3d convolutional networks. In: Proceedings of the 2015 IEEE international conference on computer vision (ICCV), pp 4489–4497
Traver VJ, Damen D (2022) Egocentric video summarisation via purpose-oriented frame scoring and selection. Expert Systems with Applications 189:11–6079
Tu Y, Zhou C, Guo J, Gao S, Yu Z (2021) Enhancing the alignment between target words and corresponding frames for video captioning. Pattern Recognition 111:107–702
Vaswani A, Shazeer N, Parmar N, Uszkoreit J, Jones L, Gomez AN, Kaiser Ł, Polosukhin I (2017) Attention is all you need. In: Advances in neural information processing systems, pp 5998–6008
Vedantam R, Zitnick CL, Parikh D (2015) CIDEr: Consensus-based image description evaluation. In: Proceedings of the 2015 IEEE conference on computer vision and pattern recognition (CVPR), pp 4566–4575
Venugopalan S, Rohrbach M, Donahue J, Mooney R, Darrell T, Saenko K (2015a) Sequence to sequence – video to text. In: Proceedings of the 2015 IEEE international conference on computer vision (ICCV), pp 4534–4542
Venugopalan S, Xu H, Donahue J, Rohrbach M, Mooney R, Saenko K (2015b) Translating videos to natural language using deep recurrent neural networks. In: Proceedings of the 2015 conference of the north american chapter of the association for computational linguistics: human language technologies, pp 1494–1504
Vinyals O, Toshev A, Bengio S, Erhan D (2015) Show and tell: A neural image caption generator. In: Proceedings of the 2015 IEEE conference on computer vision and pattern recognition (CVPR), pp 3156–3164
Wang C, Gu X (2022) Dynamic-balanced double-attention fusion for image captioning. Engineering Applications of Artificial Intelligence 114:105–194
Wang H, Gao C, Han Y (2020) Sequence in sequence for video captioning. Pattern Recognition Letters 130:327–334
Wang S, Lan L, Zhang X, Dong G, Luo Z (2020) Object-aware semantics of attention for image captioning. Multimedia Tools Application 79(3–4):2013–2030
Wang X, Chen W, Wu J, Wang Y, Wang WY (2018) Video captioning via hierarchical reinforcement learning. In: 2018 IEEE/CVF conference on computer vision and pattern recognition, pp 4213–4222
Wang Y, Huang G, Yuming L, Yuan H, Pun CM, Ling WK, Cheng L (2022) Mivcn: Multimodal interaction video captioning network based on semantic association graph. Appl Intell 52(5):5241–5260
Wu A, Han Y, Yang Y, Hu Q, Wu F (2019) Convolutional reconstruction-to-sequence for video captioning. IEEE Transactions on Circuits and Systems for Video Technology
Wu B, Niu G, Yu J, Xiao X, Zhang J, Wu H (2022) Towards knowledge-aware video captioning via transitive visual relation-ship detection. IEEE Transactions on Circuits and Systems for Video Technology 32(10):6753–6765
Wu X, Li G, Cao Q, Ji Q, Lin L (2018) Interpretable video captioning via trajectory structured localization. In: 2018 IEEE/CVF Conference on computer vision and pattern recognition (CVPR), pp 6829–6837
Xu J, Mei T, Yao T, Rui Y (2016) MSR-VTT: A Large Video Description Dataset for Bridging Video and Language. In: IEEE International conference on computer vision and pattern recognition (CVPR), pp 5288–5296
Xu K, Ba J, Kiros R, Cho K, Courville A, Salakhudinov R, Zemel R, Bengio Y (2015) Show, Attend and Tell: Neural image caption generation with visual attention. In: Proceedings of the 32nd international conference on machine learning, pp 2048–2057
Xu N, Liu A, Wong Y, Zhang Y, Nie W, Su Y, Kankanhalli M (2019) Dual-stream recurrent neural network for video captioning. IEEE Transactions on Circuits and Systems for Video Technology 29(8):2482–2493
Xu N, Liu AA, Nie W, Su Y (2019) Multi-guiding long short-term memory for video captioning. Multimed Syst 25(6):663–672
Yan C, Tu Y, Wang X, Zhang Y, Hao X, Zhang Y, Dai Q (2020) STAT: Spatial-temporal attention mechanism for video captioning. Trans Multimed 22(1):229–241
Ye H, Li G, Qi Y, Wang S, Huang Q, Yang MH (2022) Hierarchical modular network for video captioning. In: 2022 IEEE/CVF Conference on computer vision and Pattern Recognition (CVPR), pp 17918–17927
Yu J, Li J, Yu Z, Huang Q (2020) Multimodal transformer with multi-view visual representation for image captioning. IEEE Transactions on Circuits and Systems for Video Technology 30(12):4467–4480
Zhang J, Peng Y (2020) Video captioning with object-aware spatio-temporal correlation and aggregation. Trans Image Process 29:6209–6222
Zhao B, Li X, Lu X (2018) Video captioning with tube features. In: Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence, IJCAI-18, pp 1177–1183
Zhou D, Yang J, Bao R (2022) Collaborative strategy network for spatial attention image captioning. Applied Intelligence 52(8):9017–9032
Zhou K, Qiao Y, Xiang T (2018a) Deep reinforcement learning for unsupervised video summarization with diversity-representativeness reward. In: AAAI Conference on Artificial Intelligence
Zhou L, Zhou Y, Corso JJ, Socher R, Xiong C (2018b) End-to-end dense video captioning with masked transformer. In: Proceedings of the IEEE conference on computer vision and pattern recognition(CVPR), pp 8739–8748
Zhu X, Li L, Liu J, Peng H, Niu X (2018) Captioning transformer with stacked attention modules. Applied Sciences 8(5)
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Munusamy, H., C, C.S. Multimodal attention-based transformer for video captioning. Appl Intell 53, 23349–23368 (2023). https://doi.org/10.1007/s10489-023-04597-2
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10489-023-04597-2