
Abstract
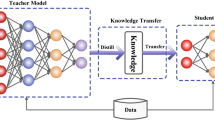
The heterogeneity of the data distribution generally influences federated learning performance in neural networks. For a well-performing global model, taking a weighted average of the local models, as in most existing federated learning algorithms, may not guarantee consistency with local models in the space of neural network maps. In this paper, we highlight the significance of the space of neural network maps to relieve the performance decay produced by data heterogeneity and propose a novel federated learning framework equipped with the decentralized knowledge distillation process (FedDKD). In FedDKD, we introduce a decentralized knowledge distillation (DKD) module to distill the knowledge of local models to teach the global model approaching the neural network map average by optimizing the divergence defined in the loss function, other than only averaging parameters as in the literature. Numerical experiments on various heterogeneous datasets reveal that FedDKD outperforms the state-of-the-art methods, especially on some extremely heterogeneous datasets.









Similar content being viewed by others


Data Availability
The additional datasets generated during and analyzed during the current study are available from the corresponding author upon reasonable request.
Code Availability
The source code will be available on GitHub.
References
McMahan HB, Moore E, Ramage D, Hampson S, Arcas BA (2017) Communication-efficient learning of deep networks from decentralized data. In: Proceedings of the 20th international conference on artificial intelligence and statistics (AISTATS)
Li T, Sahu AK, Talwalkar A, Smith V (2020) Federated learning: Challenges, methods, and future directions. IEEE Signal Proc Mag 37(3):50–60. https://doi.org/10.1109/msp.2020.2975749
Kairouz P, McMahan H, Avent B, Bellet A, Bennis M, Bhagoji A, Bonawitz K, Charles Z, Cormode G, Cummings R, D’Oliveira R, Eichner H, El Rouayheb S, Evans D, Gardner J, Garrett Z, Gascón A, Ghazi B, Gibbons P, Zhao S (2021) Advances and Open Problems in Federated Learning. https://doi.org/10.1561/9781680837896
Imteaj A, Thakker U, Wang S, Li J, Amini MH (2022) A survey on federated learning for resource-constrained iot devices. IEEE Internet of Things Journal 9(1):1–24. https://doi.org/10.1109/JIOT.2021.3095077
Wahab OA, Mourad A, Otrok H, Taleb T (2021) Federated machine learning: Survey, multi-level classification, desirable criteria and future directions in communication and networking systems. IEEE Communications Surveys & Tutorials 23(2):1342–1397. https://doi.org/10.1109/COMST.2021.3058573
Su Z, Wang Y, Luan TH, Zhang N, Li F, Chen T, Cao H (2022) Secure and efficient federated learning for smart grid with edge-cloud collaboration. IEEE Transactions on Industrial Informatics 18 (2):1333–1344. https://doi.org/10.1109/TII.2021.3095506
Zhang W, Zhou T, Lu Q, Wang X, Zhu C, Sun H, Wang Z, Lo SK, Wang F-Y (2021) Dynamic fusion-based federated learning for covid-19 detection. IEEE Internet of Things Journal PP:1–1. https://doi.org/10.1109/JIOT.2021.3056185
Zeng Q, Lv Z, Li C, Shi Y, Lin Z, Liu C, Song G (2022) Fedprols: federated learning for iot perception data prediction. Appl Intell, 1–13. https://doi.org/10.1007/s10489-022-03578-1
Li T, Sahu AK, Zaheer M, Sanjabi M, Talwalkar A, Smith V (2020) Federated optimization in heterogeneous networks. Proc Mach Learn Syst 2:429–450
Chen W, Bhardwaj K, Marculescu R (2021) Fedmax: Mitigating activation divergence for accurate and communication-efficient federated learning. In: Hutter F, Kersting K, Lijffijt J, Valera I (eds) Machine learning and knowledge discovery in databases. Springer, Cham, pp 348–363
Bottou L (2010) Large-scale machine learning with stochastic gradient descent. In: Lechevallier Y, Saporta G (eds) Proceedings of COMPSTAT’2010. Physica-Verlag HD, Heidelberg, pp 177–186
Li X, Jiang M, Zhang X, Kamp M, Dou Q (2021) Fedbn: Federated learning on non-iid features via local batch normalization. In: International conference on learning representations
Wang H, Yurochkin M, Sun Y, Papailiopoulos D, Khazaeni Y (2020) Federated learning with matched averaging. In: International conference on learning representations
Zhu H, Xu J, Liu S, Jin Y (2021) Federated learning on non-iid data: a survey. Neurocomputing 465:371–390
Lin T, Kong L, Stich SU, Jaggi M (2020) Ensemble distillation for robust model fusion in federated learning. In: Proceedings of the 34th international conference on neural information processing systems
Mills J, Hu J, Min G (2022) Multi-task federated learning for personalised deep neural networks in edge computing. IEEE Transactions on Parallel and Distributed Systems 33:630–641
Li Q, He B, Song D (2021) Model-contrastive federated learning. In: 2021 IEEE/CVF Conference on computer vision and pattern recognition (CVPR). IEEE Computer Society, Los Alamitos, CA, USA, pp 10708–10717, DOI https://doi.org/10.1109/CVPR46437.2021.01057, (to appear in print)
Seoa H, Parkb J, Ohc S, Bennisd M, Kimc S. -L. (2022) Federated Knowledge Distillation, pp 457–485. https://doi.org/10.1017/9781108966559.019
Zhu Z, Hong J, Zhou J (2021) Data-free knowledge distillation for heterogeneous federated learning. In: International conference on machine learning, PMLR, pp 12878–12889
Yim J, Joo D, Bae J, Kim J (2017) A gift from knowledge distillation: Fast optimization, network minimization and transfer learning. In: 2017 IEEE Conference on computer vision and pattern recognition (CVPR). https://doi.org/10.1109/CVPR.2017.754, pp 7130–7138
Romero A, Kahou SE, Montréal P, Bengio Y, Montréal UD, Romero A, Ballas N, Kahou SE, Chassang A, Gatta C, Bengio Y (2015) Fitnets: Hints for thin deep nets. In: International conference on learning representations
Meng Z, Li J, Gong Y, Juang B-H (2018) Adversarial teacher-student learning for unsupervised domain adaptation. In: 2018 IEEE international conference on acoustics, speech and signal processing (ICASSP), pp 5949–5953
Chen G, Choi W, Yu X, Han TX, Chandraker M (2017) Learning efficient object detection models with knowledge distillation. In: NIPS
Tan S, Caruana R, Hooker G, Lou Y (2018) Distill-and-compare: Auditing black-box models using transparent model distillation. Proceedings of the 2018 AAAI/ACM Conference on AI, Ethics, and Society
Goldblum M, Fowl L, Feizi S, Goldstein T (2020) Adversarially robust distillation. In: AAAI
Netzer Y, Wang T, Coates A, Bissacco A, Wu B, Ng AY (2011) Reading digits in natural images with unsupervised feature learning. In: NIPS workshop on deep learning and unsupervised feature learning 2011. http://ufldl.stanford.edu/housenumbers/nips2011_housenumbers.pdf
Chelaramani S, Gupta M, Agarwal V, Gupta P, Habash R (2021) Multi-task knowledge distillation for eye disease prediction. In: 2021 IEEE Winter conference on applications of computer vision (WACV). https://doi.org/10.1109/WACV48630.2021.00403, pp 3982–3992
Li Z, Hu C, Guo X, Chen J, Qin W, Zhang R (2022) An unsupervised multiple-task and multiple-teacher model for cross-lingual named entity recognition. In: Proceedings of the 60th annual meeting of the association for computational linguistics (Volume 1: Long Papers). https://doi.org/10.18653/v1/2022.acl-long.14, https://aclanthology.org/2022.acl-long.14. Association for Computational Linguistics, Dublin, Ireland, pp 170–179
Vongkulbhisal J, Vinayavekhin P, Scarzanella MV (2019) Unifying heterogeneous classifiers with distillation. In: 2019 IEEE/CVF conference on computer vision and pattern recognition (CVPR), pp 3170–3179
You S, Xu C, Xu C, Tao D (2017) Learning from multiple teacher networks. In: Proceedings of the 23rd ACM SIGKDD international conference on knowledge discovery and data mining
Liu Y, Zhang W, Wang J (2020) Adaptive multi-teacher multi-level knowledge distillation. Neurocomputing 415:106– 113
Chen Y, Ning Y, Slawski M, Rangwala H (2020) Asynchronous online federated learning for edge devices with non-iid data. 2020 IEEE International Conference on Big Data (Big Data), 15–24
Oh S, Park J, Jeong E, Kim H, Kim SL (2020) Mix2fld: Downlink federated learning after uplink federated distillation with two-way mixup. IEEE Commun Lett PP(99):1–1
Sui D, Chen Y, Zhao J, Jia Y, Sun W (2020) Feded: Federated learning via ensemble distillation for medical relation extraction. In: Proceedings of the 2020 conference on empirical methods in natural language processing (EMNLP)
Duan M, Liu D, Chen X, Tan Y, Ren J, Qiao L, Liang L (2019) Astraea: Self-balancing federated learning for improving classification accuracy of mobile deep learning applications, pp 246–254. https://doi.org/10.1109/ICCD46524.2019.00038
Amari S-i, Nagaoka H (2007) Methods of information geometry. Translations of Mathematical Monographs, 25–50. https://doi.org/10.1090/mmono/191/02
Kullback S, Leibler RA (1951) On information and sufficiency. Ann Math Statist 22(1):79–86
Tsybakov AB (2009) Introduction to Nonparametric Estimation. Springer series in statistics. Springer, Dordrecht. https://doi.org/10.1007/b13794
Cohen G, Afshar S, Tapson J, van Schaik A (2017) Emnist: Extending mnist to handwritten letters. In: 2017 International joint conference on neural networks (IJCNN). https://doi.org/10.1109/IJCNN.2017.7966217, pp 2921–2926
Caldas S, Duddu SMK, Wu P, Li T, Konečný J, McMahan HB, Smith V, Talwalkar A (2018) Leaf: A benchmark for federated settings. arXiv preprint arXiv:1812.01097 Presented at the 2nd International Workshop on Federated Learning for Data Privacy and Confidentiality (in conjunction with NeurIPS 2019)
Krizhevsky A, Hinton G (2009) Learning multiple layers of features from tiny images. Technical Report 0. University of Toronto, Toronto, Ontario
Netzer Y, Wang T, Coates A, Bissacco A, Wu B, Ng AY (2011) Reading digits in natural images with unsupervised feature learning. In: NIPS workshop on deep learning and unsupervised feature learning 2011. http://ufldl.stanford.edu/housenumbers/nips2011_housenumbers.pdf
Hull JJ (1994) A database for handwritten text recognition research. IEEE Trans Pattern Anal Mach Intell 16(5):550–554. https://doi.org/10.1109/34.291440
Ganin Y, Lempitsky V (2015) Unsupervised domain adaptation by backpropagation. In: International conference on machine learning, PMLR, pp 1180–1189
Lecun Y, Bottou L, Bengio Y, Haffner P (1998) Gradient-based learning applied to document recognition. Proc IEEE 86(11):2278–2324. https://doi.org/10.1109/5.726791
Acknowledgments
This work was supported by the National Key R&D Program of China (No. 2018AAA0100303); the National Natural Science Foundation of China (No. 62072111); the Shanghai Municipal Science and Technology Major Project (No. 2018SHZDZX01) and the ZHANGJIANG LAB; and the Technology Commission of Shanghai Municipality (No. 19JC1420101).
Funding
This work was supported by the National Key R&D Program of China (No. 2018AAA0100303); the National Natural Science Foundation of China (No. 62072111); the Shanghai Municipal Science and Technology Major Project (No. 2018SHZDZX01) and the ZHANGJIANG LAB; and the Technology Commission of Shanghai Municipality (No. 19JC1420101).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of Interests
The authors declare that they have no conflict of interest.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Electronic supplementary material
Below is the link to the electronic supplementary material.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Li, X., Chen, B. & Lu, W. FedDKD: Federated learning with decentralized knowledge distillation. Appl Intell 53, 18547–18563 (2023). https://doi.org/10.1007/s10489-022-04431-1
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10489-022-04431-1