
Abstract
The majority of multi-view methods in the literature are batch methods that need all data at the beginning of a training session. However, these methods are not scalable and need to retrain if new data are added or removed from the existing dataset. Incremental methods that support the addition of data samples have been developed, but these methods do not support the addition of views. To address this issue, we present view incremental decremental multi-view discriminant analysis (VIDMvDA) that updates a learned model without retraining when new views are added or existing views are deleted. VIDMvDA is presented in two forms: incremental learning and decremental unlearning. It provides closed-form solutions to update the within-class and the between-class scatter. We have measured the performance of our method against multi-view batch methods on criteria such as discriminability, order independence, classification accuracy, training time, and memory. We prove that using significantly less training time and memory, VIDMvDA constructs a similar discriminant subspace and has the same or better classification accuracy than the batch methods.









Similar content being viewed by others

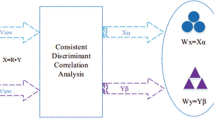

Data Availability
The datasets used in this study are publicly available at the following links:
– Handwritten Digits Dataset
– Caltech-7 Dataset
– AwA Dataset
References
Nigam K, Ghani R (2000) Analyzing the effectiveness and applicability of co-training. In: The conference on information and knowledge management. ACM, pp 86–93. https://doi.org/10.1145/354756.354805https://doi.org/10.1145/354756.354805
Wang W, Zhou ZH (2007) Analyzing co-training style algorithms. In: Proceedings of the 18th European conference on machine learning, Warsaw, Poland, vol 4701, pp 454–465
Zhang J, Zhang Y, Ji D, Liu M (2019) Multi-task and multi-view training for end-to-end relation extraction. Neurocomputing 364:245–253. https://doi.org/10.1016/j.neucom.2019.06.087
Hussain T, Muhammad K, Ding W, Lloret J, Baik SW, de Albuquerque VHC (2021) A comprehensive survey of multi-view video summarization. Pattern Recogn 109:107567. https://doi.org/10.1016/j.patcog.2020.107567
Portillo-Portillo J, Leyva R, Sanchez V et al (2018) A view-invariant gait recognition algorithm based on a joint-direct linear discriminant analysis. Applied Intell 48:1200–1217. https://doi.org/10.1007/s10489-017-1043-8
Xu W (2021) Graph-optimized coupled discriminant projections for cross-view gait recognition. Applied Intell 51:8149–8161. https://doi.org/10.1007/s10489-021-02322-5
Farquhar JDR, Hardoon DR, Meng H, Shawe-Taylor J, Szedmák S (2005) Two view learning: SVM-2K, theory and practice. In: Proceedings of the conference on neural information processing systems, pp 355–362. https://doi.org/10.5555/2976248.2976293
Su H, Maji S, Kalogerakis E, Learned-Miller EG (2015) Multi-view convolutional neural networks for 3D shape recognition. In: Proceedings of the international conference on computer vision. IEEE Computer Society, pp 945–953. https://doi.org/10.1109/ICCV.2015.114https://doi.org/10.1109/ICCV.2015.114
Blum A, Mitchell T (1998) Combining labeled and unlabeled data with co-training. In: Proceedings of the conference on computational learning theory. ACM Press, pp 92–100. https://doi.org/10.1145/279943.279962
Yan R, Naphade MR (2005) Semi-supervised cross feature learning for semantic concept detection in videos. In: Proceedings of the conference on computer vision and pattern recognition, pp I:657–663. https://doi.org/10.1109/CVPR.2005.317
Kan M, Shan S, Zhang H, Lao S, Chen X (2016) Multi-view discriminant analysis. IEEE Trans Pattern Anal Mach Intell 38(1):188–194. https://doi.org/10.1109/TPAMI.2015.2435740
You X, Xu J, Yuan W, Jing XY, Tao D, Zhang T (2019) Multi-view common component discriminant analysis for cross-view classification. Pattern Recogn 92:37–51. https://doi.org/10.1016/j.patcog.2019.03.008
Chumachenko K, Raitoharju J, Iosifidis A, Gabbouj M (2021) Speed-up and multi-view extensions to subclass discriminant analysis. Pattern Recog 111:107660. https://doi.org/10.1016/j.patcog.2020.107660
Sharma KK, Seal A (2021) Outlier-robust multi-view clustering for uncertain data. Knowl-Based Syst 211:106567. https://doi.org/10.1016/j.knosys.2020.106567
Li Y, Liao H (2021) Multi-view clustering via adversarial view embedding and adaptive view fusion. Applied Intell 51:1201–1212. https://doi.org/10.1007/s10489-020-01864-4
Zhang GY, Chen XW, Zhou YR, Wang CD, Huang D, He XY (2022) Kernelized multi-view subspace clustering via auto-weighted graph learning. Appl Intell 52:716–731. https://doi.org/10.1007/s10489-021-02365-8
Zhu S, Sun X, Jin D (2016) Multi-view semi-supervised learning for image classification. Neurocomputing 208:136–142. https://doi.org/10.1016/j.neucom.2016.02.072
Wang S, Wang Z, Guo W (2021) Accelerated manifold embedding for multi-view semi-supervised classification. Inf Sci 562:438–451. https://doi.org/10.1016/j.ins.2021.03.040
Bhattacharjee SD, Tolone WJ, Paranjape VS (2019) Identifying malicious social media contents using multi-view context-aware active learning. Futur Gener Comput Syst 100:365–379. https://doi.org/10.1016/j.future.2019.03.015
Cai JJ, Tang J, Chen QG, Hu Y, Wang X, Huang SJ (2019) Multi-view active learning for video recommendation. In: Proceedings of the twenty-eighth international joint conference on artificial intelligence, China, pp 2053–2059. https://doi.org/10.24963/ijcai.2019/284
Pang S, Ozawa S, Kasabov N (2005) Incremental linear discriminant analysis for classification of data streams. IEEE Trans Syst Man Cybern Part B (Cybern) 35(5):905–914. https://doi.org/10.1109/TSMCB.2005.847744
Zhao H, Yuen PC, Kwok JT (2006) A novel incremental principal component analysis and its application for face recognition. IEEE Trans Syst Man Cybern Part B (Cybern) 36(4):873–886. https://doi.org/10.1109/TSMCB.2006.870645
Nie X, Luo Y, Qiao H, Zhang B, Jiang ZP (2018) An incremental multi-view active learning algorithm for PolSAR data classification. In: International conference on pattern recognition. IEEE Computer Society, pp 2251–2255. https://doi.org/10.1109/ICPR.2018.8545325
Nie X, Fan M, Huang X, Yang W, Zhang B, Ma X (2020) Online semisupervised active classification for multiview PolSAR data. IEEE Trans Cybern. https://doi.org/10.1109/TCYB.2020.3026741
Shivagunde SS, Nadapana A, Saradhi VV (2021) Multi-view incremental discriminant analysis. Inf Fusion 68:149–160. https://doi.org/10.1016/j.inffus.2020.10.021
Kumar N, Madhavan S (2021) Incremental weighted linear discriminant analysis for face recognition. Adv Commun Comput Tech 668:677–687
Liu Y, Chen L, Zhu C (2018) Improved robust tensor principal component analysis via low-rank core matrix. IEEE J Sel Top Signal Process 12(6):1378–1389. https://doi.org/10.1109/JSTSP.2018.2873142
Gu B, Quan X, Gu Y, Sheng VS, Zheng G (2018) Chunk incremental learning for cost-sensitive hinge loss support vector machine. Pattern Recogn 83:196–208. https://doi.org/10.1016/j.patcog.2018.05.023
Kashef R (2021) A boosted SVM classifier trained by incremental learning and decremental unlearning approach. Expert Syst Appl 167:114154. https://doi.org/10.1016/j.eswa.2020.114154
Chen Y, Xiong J, Xu W, Zuo J (2019) A novel online incremental and decremental learning algorithm based on variable support vector machine. Clust Comput 22:7435—7445. https://doi.org/10.1007/s10586-018-1772-4
Lee WH, Ko BJ, Wang S, Liu C, Leung KK (2019) Exact incremental and decremental learning for LS-SVM. In: IEEE international conference on image processing (ICIP), pp 2334–2338. https://doi.org/10.1109/ICIP.2019.8803291
Yang M, Deng C, Nie F (2019) Adaptive-weighting discriminative regression for multi-view classification. Pattern Recogn 88:236–245. https://doi.org/10.1016/j.patcog.2018.11.015
López-López E, Regueiro CV, Pardo XM, Franco A, Lumini A (2019) Incremental learning techniques within a self-updating approach for face verification in video-surveillance. In: Iberian conference on pattern recognition and image analysis, vol 11868, pp 25–37
Ravanbakhsh M, Baydoun M, Campo D, Marin P, Martín D, Marcenaro L, Regazzoni CS (2018) Learning multi-modal self-awareness models for autonomous vehicles from human driving. IEEE Trans Intell Transp Syst 22:1866–1873. https://doi.org/10.23919/ICIf.2018.8455667
Zhou P, Shen YD, Du L, Ye F (2019) Incremental multi-view support vector machine. In: Proceedings of the SIAM international conference on data mining, pp 1–9. https://doi.org/10.1137/1.9781611975673.1https://doi.org/10.1137/1.9781611975673.1
Zhou P, Shen YD, Du L, Ye F, Li X (2019) Incremental multi-view spectral clustering. Knowl-Based Syst 174:73–86. https://doi.org/10.1016/j.knosys.2019.02.036
Blake CL, Merz CJ (1998) UCI repository of machine learning databases. https://archive.ics.uci.edu/ml/datasets/Multiple%2BFeatures. Accessed 2 October 2022
Li FF, Fergus R, Perona P (2004) Learning generative visual models from few training examples: an incremental Bayesian approach tested on 101 object categories. In: CVPR workshops. IEEE Computer Society, p 178. https://doi.org/10.1109/CVPR.2004.383
Lampert CH, Nickisch H, Harmeling S (2009) Learning to detect unseen object classes by between-class attribute transfer. In: IEEE conference on computer vision and pattern recognition, pp 951–958. https://doi.org/10.1109/CVPR.2009.5206594
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of Interests
The authors declare that they have no conflict of interest and have not received funding from any organization for the submitted work.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
Appendix A: Deriving the within-class scatter equation
Where,
Appendix B: Deriving the between-class scatter equation
Where,
Rights and permissions
Springer Nature or its licensor holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Shivagunde, S.S., Saradhi, V.V. View incremental decremental multi-view discriminant analysis. Appl Intell 53, 13593–13607 (2023). https://doi.org/10.1007/s10489-022-04168-x
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10489-022-04168-x