
Abstract
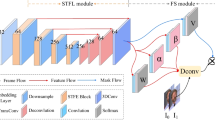
With the introduction of deformable convolution, the kernel-based Video Frame Interpolation (VFI) has made significant progress. However, there are still some problems, such as the limited spatial-temporal freedom degree in the sampling point extraction stage and the insufficient utilization of spatial-temporal information in the feature extraction stage of the kernel-based methods. In this paper, we propose a video frame interpolation method based on Enhanced Spatial-Temporal Freedom (ESTF), which consists of four modules for VFI. Specifically, we first combine 3D and deformable convolutions to extract spatial-temporal feature information in the proposed enhanced spatial-temporal feature extraction module. Then, we utilize an enhanced freedom fusion module to adaptively estimate parameters and generate intermediate frames by adaptive estimators and deformable fusion layers, respectively. Finally, a context extraction module and a residual contextual refinement module are utilized to extract context features for optimizing the generated frames. Extensive experimental results on various popular benchmarks such as Vimeo90K, GOPRO, and Adobe240 demonstrate that the proposed method achieves competitive performance against most existing methods, especially when dealing with complex motions.





Similar content being viewed by others


References
Mahajan D, Huang FC, Matusik W, Ramamoorthi R, Belhumeur P (2009) Moving gradients: a path-based method for plausible image interpolation. ACM Transactions on Graphics (TOG), pp 1–11
Liu Z, Yeh RA, Tang X, Liu Y, Agarwala A (2017) Video frame synthesis using deep voxel flow. In: 2017 IEEE International conference on computer vision (ICCV), pp 4473–4481
Liu Y, Liao YT, Lin YY, Chuang YY (2019) Deep video frame interpolation using cyclic frame generation. In: AAAI
Bao W, Lai WS, Zhang X, Gao Z, Yang MH (2019) Memc-net: motion estimation and motion compensation driven neural network for video interpolation and enhancement. IEEE Trans Pattern Anal Mach Intell. https://doi.org/10.1109/TPAMI.2019.2941941
Myungsub C, Choi J, Baik S, Kim T, Lee KM (2020) Scene adaptive video frame interpolation via meta-learning. In: 2020 IEEE/CVF Conference on computer vision and pattern recognition (CVPR), pp 9441–9450
Tulyakov S, Gehrig D, Georgoulis S, Erbach J, Gehrig M, Li Y, Scaramuzza D (2021) Time lens: Event-Based video frame interpolation. In: 2021 IEEE/CVF Conference on computer vision and pattern recognition (CVPR), pp 16155–16164
Bao W, Zhang X, Chen L, Ding L, Gao Z (2018) High-order model and dynamic filtering for frame rate up-conversion. IEEE Trans Image Process, pp 3813–3826
Jiang H, Sun D, Jampani V, Yang MH, Learned-Miller E, Kautz J (2018) Super slomo: high quality estimation of multiple intermediate frames for video interpolation. In: 2018 IEEE/CVF Conference on computer vision and pattern recognition, pp 9000–9008
Flynn J, Neulander I, Philbin J, Snavely N (2016) Deepstereo: Learning to predict new views from the world’s imagery. In: 2016 IEEE Conference on computer vision and pattern recognition (CVPR), pp 5515–5524
Zhou T, Tulsiani S, Sun W, Malik J, Efros AA (2016) View synthesis by appearance flow. In: European conference on computer vision (ECCV), pp 286–301
Kalluri T, Pathak D, Chandraker M, Tran D (2020) Flavr: Flow-agnostic video representations for fast frame interpolation. arXiv:2012.08512
Wu J, Yuen C, Cheung NM, Chen J, Chen CW (2015) Modeling and optimization of high frame rate video transmission over wireless networks. IEEE Trans Wirel Commun, pp 2713– 2726
Parihar AS, Varshney D, Pandya K, Aggarwal A (2021) A comprehensive survey on video frame interpolation techniques. Vis Comput, pp 1–25
Niklaus S, Mai L, Liu F (2017) Video frame interpolation via adaptive convolution. In: 2017 IEEE Conference on computer vision and pattern recognition (CVPR), pp 2270–2279
Niklaus S, Mai L, Liu F (2017) Video frame interpolation via adaptive separable convolution. In: 2017 IEEE International conference on computer vision (ICCV), pp 261–270
Lee H, Kim T, Chung TY, Pak D, Ban Y, Lee S (2020) Adacof: adaptive collaboration of flows for video frame interpolation. In: 2020 IEEE/CVF Conference on computer vision and pattern recognition (CVPR), pp 5315–5324
Dai J, Qi H, Xiong Y, Li Y, Zhang G, Hu H, Wei Y (2017) Deformable convolutional networks. In: 2017 IEEE International conference on computer vision (ICCV), pp 764–773
Zhu X, Hu H, Lin S, Dai J (2019) Deformable convnets v2: More deformable, better results. In: 2019 IEEE/CVF conference on computer vision and pattern recognition (CVPR), pp 9308–9316
Shi Z, Liu X, Shi K, Dai L, Chen J (2021) Video frame interpolation via generalized deformable convolution. IEEE transactions on multimedia
Chi Z, Mohammadi Nasiri R, Liu Z, Lu J, Tang J, Plataniotis KN (2020) All at once: Temporally adaptive multi-frame interpolation with advanced motion modeling. In: 2020 European conference on computer vision (ECCV), pp 107–123
Liu Y, Xie L, Siyao L, Sun W, Qiao Y, Dong C (2020) Enhanced quadratic video interpolation. In: European conference on computer vision (ECCV), pp 41–56
Xu X, Siyao L, Sun W, Yin Q, Yang MH (2019) Quadratic video interpolation. arXiv:1911.00627
Wang X, Jin Y, Li C, Cen Y, Li Y (2022) VSLN: View-aware Sphere learning network for cross-view vehicle re-identification. Int J Intell Syst, pp 1–21
Park J, Ko K, Lee C, Kim CS (2020) Bmbc: Bilateral motion estimation with bilateral cost volume for video interpolation. In: 2020 European conference on computer vision (ECCV), pp 109–125
Siyao L, Zhao S, Yu W, Sun W, Metaxas D, Loy CC, Liu Z (2021) Deep animation video interpolation in the wild. In: 2021 IEEE/CVF Conference on computer vision and pattern recognition (CVPR), pp 6587–6595
Teed Z, Deng J (2020) Raft: Recurrent all-pairs field transforms for optical flow. In: 2020 European conference on computer vision (ECCV), pp 402–419
Zhang H, Zhao Y, Wang R (2020) A flexible recurrent residual pyramid network for video frame interpolation. In: 2020 European conference on computer vision (ECCV), pp 474–491
Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: International conference on medical image computing and computer-assisted intervention, pp 234–241
Bao W, Lai WS, Ma C, Zhang X, Gao Z, Yang MH (2019) Depth aware video frame interpolation. In: 2019 IEEE/CVF Conference on computer vision and pattern recognition (CVPR), pp 3698–3707
Niklaus S, Liu F (2020) Softmax splatting for video frame interpolation. In: 2020 IEEE/CVF Conference on computer vision and pattern recognition (CVPR), pp 5436–5445
Sun D, Yang X, Liu MY, Kautz J (2018) Pwc-net: Cnns for optical flow using pyramid, warping, and cost volume. In: 2018 IEEE/CVF Conference on computer vision and pattern recognition (CVPR), pp 8934–8943
Sim H, Oh J, Kim M (2021) XVFI: Extreme video frame interpolation. In: 2021 IEEE/CVF conference on computer vision and pattern recognition (CVPR), pp 14489–14498
Lee S, Choi N, Choi WI (2022) Enhanced correlation matching based video frame interpolation. In: 2022 Proceedings of the IEEE/CVF winter conference on applications of computer vision, pp 2839–2847
Ding T, Liang L, Zhu Z, Zharkov I (2021) CDFI: Compression-Driven Network design for frame interpolation. In: 2021 IEEE/CVF Conference on computer vision and pattern recognition (CVPR), pp 8001–8011
Zhang Y, Sun Y, Liu S (2022) Deformable and residual convolutional network for image super-resolution. Appl Intell 52:295–304
Lu M, Hu Y, Lu X (2020) Driver action recognition using deformable and dilated faster r-CNN with optimized region proposals. Appl Intell 50(4):1100–1111
Liu YB, Jia RS, Liu QM, Zhang XL, Sun HM (2021) Crowd counting method based on the self-attention residual network. Appl Intell 51(1):427–440
Cheng X, Chen Z (2020) Video frame interpolation via deformable separable convolution. In: AAAI
Gui S, Wang C, Chen Q, Tao D (2020) Featureflow: Robust video interpolation via structure-to-texture generation. In: 2020 IEEE/CVF Conference on computer vision and pattern recognition (CVPR), pp 14004–14013
Yuan M, Dai Q (2021) A novel deep pixel restoration video prediction algorithm integrating attention mechanism. Appl Intell, pp 1–19
Jing B, Ding H, Yang Z, Li B, Bao L (2021) Video prediction: a step-by-step improvement of a video synthesis network. Appl Intell, pp 1–13
Wang X, Jin Y, Cen Y, Lang C, Li Y (2021) PST-NET: Point cloud sampling via Point-Based transformer. In: International conference on image and graphics, pp 57–69
Kumar N, Sukavanam N (2020) An improved CNN framework for detecting and tracking human body in unconstraint environment. Knowledge-Based Systems, pp 193, 105198
Niklaus S, Liu F (2018) Context-aware synthesis for video frame interpolation. In: 2018 IEEE/CVF Conference on computer vision and pattern recognition (CVPR), pp 1701–1710
Hou Q, Zhou D, Feng J (2021) Coordinate attention for efficient mobile network design. In: 2021 IEEE/CVF conference on computer vision and pattern recognition (CVPR), pp 13713–13722
Odena A, Dumoulin V, Olah C (2016) Deconvolution and checkerboard artifacts. Distill e3
Fourure D, Emonet R, Fromont E, Muselet D, Tremeau A, Wolf C (2017) Residual conv-deconv grid network for semantic segmentation. arXiv:1707.07958
Zhang Y, Tian Y, Kong Y, Zhong B, Fu Y (2018) Residual dense network for image super-resolution. In: 2018 IEEE Conference on computer vision and pattern recognition (CVPR), pp 2472–2481
Wang X, Jin Y, Cen Y, Wang T, Tang B, Li Y (2022) LighTN: Light-weight Transformer Network for Performance-overhead Tradeoff in Point Cloud Downsampling. arXiv:2202.06263
Kingma DP, Ba J (2014) Adam: A method for stochastic optimization. arXiv:1412.6980
Xue T, Chen B, Wu J, Wei D, Freeman W (2018) Video enhancement with task-oriented flow. Int J Comput Vis 127:1106–1125
Nah S, Hyun Kim T, Mu Lee K (2017) Deep multi-scale convolutional neural network for dynamic scene deblurring. In: 2017 IEEE Conference on computer vision and pattern recognition, pp 3883–3891
Su S, Delbracio M, Wang J, Sapiro G, Heidrich W, Wang O (2017) Deep video deblurring for hand-held cameras. In: 2017 IEEE Conference on computer vision and pattern recognition (CVPR), pp 237–246
Soomro K, Zamir A, Shah M (2012) Ucf101: A dataset of 101 human actions classes from videos in the wild. arXiv:1212.0402
Wang Z, Bovik AC, Sheikh HR, Simoncelli EP (2004) Image quality assessment: from error visibility to structural similarity. IEEE transactions on image processing, pp 600–612
Nilsson J, Akenine-möller T (2020) Understanding ssim. arXiv:2006.13846
Zhang D, Lei W, Zhang W, Chen X (2021) Flow-based frame interpolation networks combined with occlusion-aware mask estimation. IET Image Processing, pp 4579–4587
Xiang X, Tian Y, Zhang Y, Fu Y, Allebach JP, Xu C (2021) Zooming SlowMo: An Efficient One-Stage Framework for Space-Time Video Super-Resolution. arXiv:2104.07473
Xu G, Xu J, Li Z, Wang L, Sun X, Cheng MM (2021) Temporal modulation network for controllable Space-Time video Super-Resolution. In: 2021 IEEE/CVF Conference on computer vision and pattern recognition (CVPR), pp 6388–6397
Acknowledgments
This work is supported by R&D Program of Beijing Municipal Education commission (KJZD20191000402) and National Nature Science Foundation of China (51827813, 61472029).
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Li, HD., Yin, H., Liu, ZH. et al. Enhanced spatial-temporal freedom for video frame interpolation. Appl Intell 53, 10535–10547 (2023). https://doi.org/10.1007/s10489-022-03787-8
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10489-022-03787-8