
Abstract
Sequential pattern mining is an important data mining problem with broad applications. While the current methods are inducing sequential patterns within a single attribute, the proposed method is able to detect them among different attributes. By incorporating the additional attributes, the sequential patterns found are richer and more informative to the user. This paper proposes a new method for inducing multi-dimensional sequential patterns with the use of Hellinger entropy measure. A number of theorems are proposed to reduce the computational complexity of the sequential pattern systems. The proposed method is tested on some synthesized transaction databases.
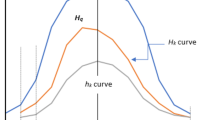
Similar content being viewed by others
References
Agrawal R, Srikant R (1995) Mining sequential patterns. Int Conf Data Engi 3–14
Masseglia F, Cathala F, Poncelet P (1998) The PSP approach for mining sequential patterns. In the 2nd European symposium on principles of data mining and knowledge discovery (PKDD’98). vol 1510, Nantes, France, LNAI, pp 176–184
Garafalakis M, Rastogi R, Shim K (2002) Mining sequential patterns with regular expression constraints. IEEE Trans Knowl Data Eng 14(3):530–552
Han J, Pei J, Mortazavi-Asl B, Chen Q, Dayal U, Hsu M-C (2000) FreeSpan: frequent pattern-projected sequential pattern mining. In: Proc 2000 int conf knowledge discovery and data mining (KDD00) Boston, MA pp 355–359
Pei J, Han J, Mortazavi-Asl B, Pinto H, Chen Q, Dayal U, Hsu M-C (2001) PrefixSpan: mining sequential patterns efficiently by prefix-projected pattern growth. Int conf on data Eng 215–224
Zaki MJ (2001) SPADE: an efficient algorithm for mining frequent sequences. In: Fisher D (ed) Mach Learn J, special issue on Unsupervised Learning vol. 42, nos (1/2) pp 31–60
Wang J, Han J (2004) BIDE: efficient mining of frequent closed sequences. Int Conf Data Eng (ICDE04)
Yan X, Han J, Afshar R (2003) CloSpan: mining closed sequential patterns in large databases. Int Conf Data Min
Tzvetkov P, Yan X, Han J (2003) TSP: mining Top-K closed sequential patterns. Int Conf Data Min
Kim H, Pei J, Wang W, Duncan D (2003) ApproxMAP: approximate mining of consensus sequential patterns. Int Conf Data Min
Pinto H, Han J, Pei J, Wang K, Chen Q, Dayal U (2001) Multi-dimensional sequential pattern mining. In: int conf on information and knowledge management. Atlanta, GA
Quinlan JR (1993) C4.5: programs for machine learning. Morgan Kaufmann Publisher
Kullback S (1968) Information theory and statistics. Dover Publications, New York
Beran RJ (1977) Minimum hellinger distances for parametric models. Ann. Statistics 5:445–463
Author information
Authors and Affiliations
Corresponding author
Additional information
Dr. Chang-Hwan Lee is a full professor at the Department of Information and Communications at DongGuk University, Seoul, Korea since 1996. He has received his B.Sc. and M.Sc in Computer Science and Statistics from Seoul National University in 1982 and 1988, respectively. He received his Ph.D. in Computer Science and Engineering from University of Connecticut in 1994. Prior to joining DongGuk University in Korea, he had worked for AT&T Bell Laboratories, Middletown, USA. (1994-1995). He also had been a visiting professor at the University of Illinois at Urbana-Champaign (2000-2001). He is author or co-author of more than 50 refereed articles on topics such as machine learning, data mining, artificial intelligence, pattern recognition, and bioinformatics.
Rights and permissions
About this article
Cite this article
Lee, CH. IMSP: An information theoretic approach for multi-dimensional sequential pattern mining. Appl Intell 26, 231–242 (2007). https://doi.org/10.1007/s10489-006-0016-0
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10489-006-0016-0