
Abstract
Federated learning (FL) refers to a system of training and stabilizing local machine learning models at the global level by aggregating the learning gradients of the models. It reduces the concern of sharing the private data of participating entities for statistical analysis to be carried out at the server. It allows participating entities called clients or users to infer useful information from their raw data. As a consequence, the need to share their confidential information with any other entity or the central entity called server is eliminated. FL can be clearly interpreted as a privacy-preserving version of traditional machine learning and deep learning algorithms. However, despite this being an efficient distributed training scheme, the client’s sensitive information can still be exposed to various security threats from the shared parameters. Since data has always been a major priority for any user or organization, this article is primarily concerned with discussing the significant problems and issues relevant to the preservation of data privacy and the viability and feasibility of several proposed solutions in the FL context. In this work, we conduct a detailed study on FL, the categorization of FL, the challenges of FL, and various attacks that can be executed to disclose the users’ sensitive data used during learning. In this survey, we review and compare different privacy solutions for FL to prevent data leakage and discuss secret sharing (SS)-based security solutions for FL proposed by various researchers in concise form. We also briefly discuss quantum federated learning (QFL) and privacy-preservation techniques in QFL. In addition to these, a comparison and contrast of several survey works on FL is included in this work. We highlight the major applications based on FL. We discuss certain future directions pertaining to the open issues in the field of FL and finally conclude our work.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
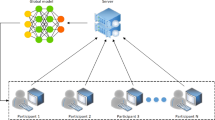
In the modern artificial intelligence (AI)-driven era, data holds prime importance. On the contrary, though AI has the power to enhance the lifestyle of humans, it also enhances the capability of attackers to exploit the privacy of online users. As a result, it is of the utmost necessity to preserve the confidentiality of user data. The fundamental idea behind FL is to allow numerous client entities to be involved in the model-driven training paradigm, wherein every local machine learning model is trained locally with raw data and collaboratively without uploading their private original (raw) data (McMahan et al. 2017a, b; Konečnỳ et al. 2016). In FL, the training of the selected machine learning model is performed by allowing the individual clients to learn locally on a local dataset comprising limited data and sending local model parameters only to a central coordinating entity called the server. The technique allows local models to learn vivid properties of data corresponding to the same problem over a wide variety of datasets stored in the local custody of multiple clients without violating privacy. The contributions from all the participating clients are captured by the central server to find an average gradient from all the gradients submitted by the clients. This aggregation generates an updated model that is globally distributed. Then the central server shares the updated gradients with the clients so that they can benefit from their learning experience and continue their local training in successive iterations. This procedure is repeatedly carried out with a set of clients willing to participate until a satisfactory amount of performance is obtained, usually when the globally aggregated model appears to have converged. FL considers an approach that is similar to bringing the code to the data, instead of the data to the code (Bonawitz et al. 2019). FL is also known as collaborative learning because the FL entities are bound by the collaboration agreement. Kairouz et al. (2021) proposed a broader definition of FL as Federated learning is a machine learning setting where multiple entities (clients) collaborate in solving a machine learning problem under the coordination of a central server or service provider. The general architecture of FL can be presented as shown in Fig. 1.

Basic architecture for FL
The architecture demonstrates that several participants collaboratively train a machine learning model across multiple iterations.
Figure 2 depicts an example of FL which predicts the next-word in mobile phones.

Federated learning example: next-word suggestions in mobile phone
A subset of remote devices (mobile phones) communicates with a central server at regular intervals to train an ML model. Selected mobile phone users execute local training on their confidential data during each training iteration, and local modifications are sent to the server. The server aggregates the updates and distributes the modified global model to another subset of mobile phones. This training procedure is iterative, and it continues until convergence is reached. FL is advantageous in this scenario because mobile device users need not share their private data globally, and they can also save their phone’s limited bandwidth and battery power. As a result, privacy is preserved for sensitive mobile data, and strain is reduced on the network. Researchers have been exploring the potential and usefulness of FL in the broad domains of smart healthcare, smart cities and homes, autonomous vehicles, insurance sectors, various industries, image classification, recommender systems, smart transportation, defense, etc., which are discussed in Sect. 10.
1.1 Motivation and scope of contributions
We have taken extreme care in streamlining the survey to deliver a multifaceted analysis of the state of ongoing research in FL. It highlights different research challenges along with various privacy concerns in the field of FL and summarizes the various privacy preservation techniques proposed. Several studies have identified that secret sharing (SS) can be a cost-effective technique for building privacy-preservation solutions for FL frameworks. Therefore, one of the focus areas of this study is to review the studies that present secure and effective FL frameworks utilizing secret sharing (SS) schemes. There are several survey works presented in the field of FL that provide a detailed review of data privacy issues and solutions for FL frameworks. However, none of the previous review work comprehensively covered all the important aspects, like the categorization of FL frameworks, the different challenges and security concerns, security solutions, opportunities for future research, and the main application areas of FL, which motivates us to present another survey work in the field that covers all the aforementioned aspects of FL in totality. In this study, we have identified several advantages of using secret sharing (SS) techniques over traditional encryption techniques and present an extensive review of SS-based security solutions.
The primary contributions of this survey are outlined below.
-
This survey work provides a thorough overview of FL, briefly describing its definition, framework, benefits, and methods of aggregation, followed by its classifications: horizontal FL, vertical FL, and federated transfer learning.
-
This survey presents a detailed study on the primary challenges of FL, which include optimizing high communication costs incurred during the transmission of gradients, system heterogeneity, statistical heterogeneity owing to differences in network bandwidth, physical components, available memory buffer, fairness issues, and data privacy from various cyberattack issues. This survey also identifies the research gaps still to be investigated by summarizing the most recent research findings in response to the critical need for security solutions in FL.
-
This survey highlights the most notable applications of the classical differential privacy, secure multi-party computation, homomorphic encryption and secret sharing in the field of privacy-preservation schemes for FL.
-
The survey encompasses the brief overview of Quantum Federated Learning (QFL) highlighting the different contributions of researchers in the ream of privacy preserving QFL.
-
This survey discusses that the collaboration of Blockchain and FL is a developing field of research and provide a privacy preserving framework.
-
This survey discusses some of the primary application fields for FL. The work also identifies and discusses the open challenges in the area of FL.
This survey can help researchers acquire an in-depth and enhanced understanding of the evolving FL landscape and identify areas requiring further exploration.
1.2 Salient features of the survey
Our aim is to produce a comprehensive analysis that provides a clear and concise picture of the current state of research in federated learning. The important features of the survey are listed below:
-
1.
A comprehensible introduction to the concept and framework of ‘FL’.
-
2.
A quick overview of aggregation processes.
-
3.
A compact discussion on its advantages.
-
4.
A brief discussion on its categorization.
-
5.
A compact study on the primary research challenges.
-
6.
An exploration of different security schemes to counter-act various attacks.
-
7.
An explicit discussion on secret sharing (SS)-based FL and the advantages of SS-based FL.
-
8.
An overview of QFL and privacy-preservation techniques in QFL
-
9.
Identification of the research gaps that are still to be investigated.
-
10.
A compact insight into the numerous applications.
-
11.
Identification of the open research questions with concluding remarks.
1.3 Organization of the paper
In Sect. 2, we discuss the steps used in the systematic review process; In Sect. 3, we discuss an overview of FL; Sect. 4 presents the different categorizations of FL; we discuss the challenges of FL in Sect. 5; in Sect. 5.5, general attacks on FL are broadly presented; in Sect. 6, some privacy-preserving schemes in FL are described; in Sect. 7, how FL framework is empowered by blockchain is described; in Sect. 8, we discuss SS-based security solutions for FL in detail; in Sect. 9, we discuss QFL briefly; in Sect. 9.1, we discuss privacy-preservation in QFL; in Sect. 10 presents various applications of FL; Sect. 11 presents comparisons of our work with other existing survey papers; we summarize the learnt lessons and identify the opportunities for future research in Sect. 12; and finally, in Sect. 13, we conclude. For the facilitation of ease of understanding and maintaining the coherence, we provide a table of abbreviations in Table 1 and a symbol table in Table 2.
2 Survey protocol
The objective of a comprehensive survey is to locate and conduct an in-depth analysis of any previously conducted research that is pertinent to a certain research subject by utilizing a clearly outlined search method. The final outcome of this survey is the identification of a number of research gaps in the already available literature that present interesting future research possibilities. The following tasks make up the steps of the systematic survey.
2.1 Formulation of research questions
We have designed this survey with enough focus to address the following Research Questions (RQs):
- RQ1::
-
How secure and efficient is FL with respect to privacy preservation and deployment in resource-constrained networks?
- RQ2::
-
What kinds of poisoning attacks are common in FL?
- RQ3::
-
What are the current state-of-the-art solutions proposed to prevent various security threats in FL and their aptness to work in the heterogeneous environment of FL systems?
- RQ4::
-
What are the different privacy-preserving solutions proposed in FL?
- RQ5::
-
What are the existing secret sharing-based privacy-preservation schemes proposed in FL?
- RQ6::
-
Why and where are secret sharing schemes used in FL to maintain privacy in FL?
- RQ7::
-
What is the current state of QFL? How is it expected to grow in coming years?
- RQ8::
-
How adaptable are the proposed privacy-preservation schemes in FL?
- RQ9::
-
What are the several real-time applications of FL?
- RQ10::
-
What are the various open issues that are yet to be explored?
The main aim of this survey is to answer the aforementioned research questions in a systematic manner and provide useful information regarding the development of various security schemes to preserve the privacy of participating entities in a federated setup. The entire paper is structured with a vision to facilitate researchers and beginners to explore the vulnerabilities of FL to security threats, the various available solutions, the utilization of secret sharing in secure FL, and how efficient they are when it comes to practical implementation.

Systematic review flow
2.2 Search strategy
At the outset, an acceptable collection of database is chosen in order to maximize the possibility of locating research studies that are relevant to the topic. The search is conducted from the year 2017 all the way until July 2023. The search is conducted using the following online database: IEEE Xplore, ACM, Springer, ArXiv, Elsevier, etc., in addition to the academic search engine Google Scholar. In addition, a preliminary investigation is carried out in order to fine-tune the search string. We go through the set of previously gathered research papers that are preserved in the database, had the highest number of citations, and are the most pertinent. In digital libraries, a search may be conducted using the keywords, such as: FL survey, Privacy-preserving FL, Secret sharing-based FL schemes, Communication-efficient FL schemes, Lightweight FL Schemes, Application areas of FL.
2.3 Selection criteria
During the stage of selection, only those research articles are chosen for further review that are able to provide answers to the predetermined research questions. These selection criteria are quickly followed up by an elimination strategy to remove redundancies and inconsistencies. At this point, unimportant research is removed from consideration based on an evaluation of the paper’s title, abstract, and complete text. The multiple phases of selection are depicted in Fig. 3. At the end, 274 research publications are finally chosen. In addition to this, we investigated the references to the most cited articles. The various scholarly articles cited and referred to in this survey are screened using the following evaluation checklist:
-
1.
Rating of the Journal and number of citations received.
-
2.
Studies that have problem descriptions provide a precise explanation.
-
3.
The explanation is presented in an understandable manner.
-
4.
studies provide answers to the questions posed in the research.
-
5.
Studies that provide technical knowledge and/or include detailed algorithms.
-
6.
Studies that mostly provide lightweight protocols in FL in terms of communication and computation overheads.
-
7.
Novel approaches that tackle possible threats and preserve acceptable privacy in FL.
-
8.
Studies make any kind of comparison with other comparable work that has already been done.
-
9.
Studies have appropriate conclusions that may be drawn from the study.
After the above-mentioned selection strategy, we are quite close to meeting our aim of drafting good research publications that include recent research carried out in the context of privacy-preserving FL. To offer ease of readability, we have limited our composition to a simple and lucid language while touching on all corners of the security solutions stated in literature from 2016 to 2023. Table 3 enlists the number of articles considered at each stage of review (excluding the articles required for the preliminary stages of the survey)Footnote 1. Figure 4 illustrates the number of articles per year used in the survey.

Number of articles reviewed per year
3 Overview of federated learning
The notion of decentralized learning across a wide range of clients is pioneered by Google (McMahan et al. 2017a; Konečnỳ et al. 2016; xxx yyy). McMahan et al. (2017a) provided the general description of FL, and Konečnỳ et al. (2016) explored more theoretical aspects of it. Afterward, several researchers (Smith et al. 2017; Chen et al. 2018; Zhao et al. 2018; Geyer et al. 2017; Bonawitz et al. 2019; Ng et al. 2021; Xu et al. 2021) focused on the communication challenges of FL, such as how to reduce the communication cost of uploading large matrices of gradients obtained in the course of a deep network, the unexpected dropout of devices caused by network connectivity, power, etc. Smith et al. (2017) introduced the intriguing novel concept of a systems-aware optimization framework for federated multitask learning. The authors showed how multitask learning effectively addressed the statistical problems in FL. Zhao et al. (2018) stated the challenges encountered in FL when private data in operation is statistically varied and not uniformly distributed. Chen et al. (2018) proposed a novel federated meta-learning framework where a parameterized algorithm is used instead of sharing a global model at each iteration. The authors showed that meta-learning is an appropriate alternative to encounter the statistical issues of FL. The paradigms discovered by Geyer et al. (2017) and Bonawitz et al. (2019) provide FL techniques with some improved security. However, these works emphasized on-device FL, where distributed mobile user interactions are involved. Some of the important optimization factors in these schemes are communication cost, highly imbalanced data distribution, and reliability of devices for optimization. However, these schemes are indeed similar to the general privacy preserving deep learning approach entailed by Shokri and Shmatikov (2015).
FL is primarily used for mobile and edge device applications. However, several advantages of FL encouraged the researchers to apply it to many more applications, including ones that may only have a few relatively dependable clients, such as numerous business applications. In the Gboard mobile keyboard, Google (Hard et al. 2018) makes wide use of FL. Apple (Woubie and Bäckström 2021) also uses it in QuickType keyboards and vocal classifiers in iOS applications. Leroy et al. (2019) investigated the applicability of FL on crowd-sourced speech data to learn a resource-constrained wake word detector. FL has a large-scale use in medical data segmentation (Xu et al. 2021; Lee and Shin 2020; Silva et al. 2019; Li et al. 2019), Internet of things (IoT) (Pang et al. 2020; Nguyen et al. 2019), smart homes (Yang et al. 2019; Yu et al. 2020), industrial IoT (Zhang et al. 2020; Qian et al. 2019; Zhou et al. 2021), finance (Yang et al. 2019), etc.
3.1 Definition of federated learning
FL can be broadly defined (Jiang et al. 2020) as joint training of machine learning models with distributed clients or devices and local data under federation. It allows participating entities, called clients or users, to infer useful information from their raw data without necessitating the need to upload their confidential information to any other entity or the central entity, called server, via any platform. Furthermore, the learning process is streamlined to mitigate the problems of different data holders participating without the disclosure or exchange of confidential data (Niknam et al. 2020), as described below.
-
Suppose there are n number of clients \(\{P_1, P_2, \ldots , P_n\}\), and \(\{I_1, I_2, \ldots , I_n\}\) are raw data held by respective clients.
-
In order to train a machine learning model by the participating clients, any of the following two methods can be used:
-
1.
Using any non-federated conventional method, where all clients \(\{P_1, P_2, \ldots , P_n\}\) consolidate their individual data \(\{I_1, I_2, \ldots , I_n\}\) and utilize \(I= \{I_1 \cup I_2 \ldots \cup I_n\}\) to train the model (say, \({\mathcal {M}}_c\) is the model after training).
-
2.
However, another way to train the machine learning model is using the concept of FL, in which clients train the model (say \({\mathcal {M}}_f\)) without intentional or unintentional leakage of private data to the central server.
-
1.
-
The FL process ensures that none of the clients shares its own data with the server. Hence, it strives to ensure the privacy and confidentiality of the client participants holding local data.
-
Let the predictive accuracy of \({\mathcal {M}}_c\) be \(\mathcal A_c\), and the predictive accuracy of \({\mathcal {M}}_f\) be \(\mathcal A_f\). Ideally, \({\mathcal {M}}_f\) should be very close to \(\mathcal M_c\).
-
If \(\epsilon\) is a real number such that,
$$\begin{aligned} |{\mathcal {A}}_f - {\mathcal {A}}_c| < \epsilon , \end{aligned}$$(1)then the FL algorithm has \(\epsilon\)-accuracy loss.
3.2 Basic framework of federated learning
FL differs from standard distributed machine learning, considering the devices involved and the dataset features. In classical distributed machine learning, all edge nodes have the same processing power, and data is partitioned evenly. This format is called Independent and Identically Distributed (IID). In FL, the hardware devices used are heterogeneous. Hence, data are found mostly in non-IID format, i.e., data differ in terms of quality, variety, and quantity (Li et al. 2020). Conventionally, any FL system comprises three main components: data, clients, and servers.
-
Data: It is a private asset for the clients, whose preservation is the prime motive of FL systems.
-
Clients: They are the participating entities whose role is to perform certain local computations and training on their private data and communicate the learned weights to the server.
-
Server: This is a central entity that is tasked with performing the aggregation of received parameters from several clients and broadcasting the updated learning weights.
The working process of a typical FL system is as follows:
- Step 1::
-
The clients develop a local model based on their trusted and confidential data.
- Step 2::
-
Model parameters are uploaded to the server.
- Step 3::
-
The server aggregates the received parameters and broadcasts updated weights to each of the clients.
- Step 4::
-
The Step 2 and Step 3 are repeated until a satisfactory level of convergence or accuracy is achieved by the clients with regard to their sample space.
Each participant maintains a database of raw data. This data is confidential, and it must not be shared with any other participant over the network. Exposure to this data violates the ethical privacy concerns of participating clients. The participants must ensure that this data is free from errors and ambiguous readings through appropriate pre-processing techniques. This pre-processing is an important step in ensuring that the data fed into the model for training is genuine and the results thus obtained are reliable. The clients use the preprocessed data to train local models. It is quite difficult to interpret any attribute of raw data (however, it is possible through reverse engineering) from the weights alone. The weights are uploaded to the server. The server accepts the weights and averages them to obtain the median values of the gradients submitted by the clients. The new weights are broadcast back to the clients. Upon receipt of the averaged weights, the clients retrain the local model with the updated gradients. This to-and-fro communication between the clients and center server continues until a satisfactory level of convergence or the desired level of accuracy and precision is achieved. In such a distributed training paradigm, each participating client is treated equally and without any partisanship (Zhao et al. 2020).
3.3 Advantages of federated learning
-
Privacy preserving: FL ensures that the privacy of the data remains intact and sensitive information is not exposed to unauthorized entities.
-
Decentralized: FL is a decentralized system that eliminates the need for a central authority to manage and control the data. This makes the system more resilient to attacks and ensures that the data is available to all participants, regardless of their location or affiliation.
-
Cost effective: By enabling participants to collaborate on training machine learning models, FL can reduce the overall cost of training by distributing computational resources across multiple devices. This can be particularly beneficial for organizations that cannot afford to invest in expensive hardware or cloud computing services.
3.4 Aggregation methods of federated learning
McMahan et al. (2017a) coined the very first averaging algorithm in FL context, the FedAvg algorithm. Since its discovery in 2017, the algorithm has mostly been employed to train uniformly distributed data. The algorithm is well appreciated and accepted as a standard algorithm in the federated framework set up by the research community. The FedAvg aggregation works only for a homogeneous distribution of model gradients submitted by each local client. The algorithm is as follows:
- Step 1::
-
Let the n number of clients be \(\{P_i\}_{i=1}^n\).
- Step 2::
-
The global model G initialized as \(G_0\).
- Step 3::
-
Local datasets are \(\{I_i\}_{i=1}^n\), across n clients.
- Step 4::
-
Each client \(P_i\) samples a batch of data \(D_i\) from the local dataset \(I_i\).
- Step 5::
-
Each client \(P_i\) computes the gradients \(G_i\) locally as \(Q_i\) = Train(\(D_i\), G).
- Step 6::
-
for each i do
$$\begin{aligned} G^{m+1} = G^m + \frac{\alpha }{n} \sum _{i = 1}^t ({Q_i} ^ {m+1} - G^m), \end{aligned}$$(2)where \(\alpha\) is the learning rate.
However, this algorithm has some limitations. The algorithm fails to achieve better system performance in cases where the dataset is not adequately and uniformly represented. Also, communication costs are high with this algorithm. Afterward, several studies improved the efficiency and accuracy of the baseline FedAvg algorithm (McMahan et al. 2017a). Li et al. (2020) proposed an algorithm called FedProx, which solves the problem of heterogeneity caused by differences in a client’s hardware, software, and network, as well as the statistical heterogeneity caused by a wide range of distributed data collected from a number of clients in remote areas. Huang et al. (2020) proposed Loss-based Adaptive Boosting (LoAdaBoost) FedAvg, which is an improved form of FedAvg algorithm (McMahan et al. 2017a). The proposed approach surpassed the FedAvg algorithm in terms of predicted accuracy and computational complexity. Pang et al. (2020) proposed a FL framework in which the central station is capable of detecting heterogeneity and arranging a firm collaboration plan for appropriate client selection. Such a type of method is known as self-organized FL. A collaborative learning strategy proposed by Han and Zhang (2020) trains models on optimal tuning for higher performance. The study by Roy et al. (2019) overcomes the limitations of a fixed server–client architecture in FL. It eliminates the need for a central server from the architecture and entrusts the responsibility of communication of weights among the participating clients itself to update the model in each iteration.
3.5 Machine learning (ML) vs. federated learning (FL)
Federated learning (FL) has several advantages over traditional machine learning (ML) methods. Here are some of the key advantages:
-
Privacy: In a traditional ML system, data samples are accumulated at a single point, say, a central station like a server. This necessity to store data at a single point leads to many problematic situations, like:
-
Under-fitting of the trained model on a scarce dataset that does not adequately represent real-world data,
-
Accumulation of genuine data in vast amounts for reliability of ML models,
-
Dependency on a central server.
These issues adversely affect performance in terms of accurate predictions, reliability, or interpretation. Data is considered a private asset by its owners and should not be disclosed publicly. FL comes to the rescue by allowing local clients to keep their confidential data confined to themselves and use the global knowledge of pre-trained models to refine their local models.
-
-
Efficiency: With FL, data is processed locally on users’ devices, which eliminates the tedious task of accumulating massive amounts of genuine and trusted data at a central station for global training. This can significantly reduce network bandwidth requirements and latency, making FL more efficient than traditional ML methods.
-
Scalability: The most obvious characteristic of FL is that it allows the training process to be distributed across a huge number of clients located in different geographical areas simultaneously, which makes it highly scalable. This is particularly useful for applications that involve a network comprising edge nodes dispersed in an area, like in IoT devices.
-
Robustness: FL can be more robust against noisy or unreliable data than traditional ML methods. This is because FL can leverage the diversity of data across many different devices to create a more robust and accurate model. Overall, FL offers several advantages over traditional ML methods, particularly with regard to privacy, confidentiality, efficiency, scalability, and robustness.
4 Categorization of federated learning
According to Yang et al. (2019), FL can be broadly classified into three categories: horizontal FL, vertical FL, and federated transfer learning (FTL). This categorization is based on the distribution of data sources among the clients or devices participating in the learning process. However, Yang et al. (2019) provided the architecture for horizontal FL system and vertical FL system and explained how these frameworks could be applied to a variety of domains, including smart retail, smart healthcare, and other domains.
-
Horizontal FL: It is also known as sample-based FL. It is used in situations where a dataset shares the same feature space, while data are different in sample instances. When FL is applied to IoT devices, it is horizontal FL as the data may differ in sample space but have the same feature dimension. Google keyboard uses horizontal FL, where the participating mobiles have different samples of training data with the same features. McMahan et al. (2017a)’s general description of FL, is based on basic horizontal FL framework. Later, Yang et al. (2019) introduced a hierarchical heterogeneous horizontal FL framework. In all the methodologies defined in (Lee and Shin 2020; Nguyen et al. 2019; Yu et al. 2020; Zhang et al. 2020; Zhou et al. 2021) data are partitioned horizontally in the data space.
-
Vertical FL: Vertical FL is also called feature-based FL. It is used when datasets are collected from the same sample instances but have different features. Smart retail and smart finance would be the two main applications for vertical FL. Information gathered in these industries is frequently utilized to create customer profiles. For example, a bank may have information on a customer’s spending habits, whereas a retailer may have information about a customer’s specific preferences for item selection. The bank and the merchant both serve a considerable customer base and offer various services (Jiang et al. 2020). A secure framework called SecureBoost is designed by Cheng et al. (2021) where vertically partitioned data collection is used.
-
Federated transfer learning (FTL): Federated Transfer Learning is mostly based on the concept of applying a pre-trained deep learning model developed for a problem to a completely new problem. Since the model is transferred from a known problem to an unknown problem, the issues of data labeling become evident and require manual intervention. The system also faces the problem of low data quality. The foremost objective of transfer learning is to figure out the similarity between the source domain and the target domain (Gao et al. 2019). While breaking the barriers of data islands, FTL is an effective technique to protect both data security and user privacy. Liu et al. (2020) designed the first complete stack for FL based on transfer learning, including training, evaluation, and cross-validation. The authors introduced FTL to broaden the scope of FL use when it comes to common parties with small intersections. Furthermore, the neural networks in this frame with additive HE techniques do not prevent privacy leakage; however, they provide equivalent accuracy to non-privacy-preserving methods. Sharma et al. (2019) used secret sharing technology instead of HE and reduced the computational overhead of the scheme proposed by Liu et al. (2020) without decreasing the accuracy rate. Chen et al. (2018) proposed a FL model that gathers data owned by different organizations via FL and offers personalized service for healthcare through transfer learning. Using deep neural networks, FTL could be used to teach autonomous vehicles to detect new road conditions (Jiang et al. 2020). Let each client \(P_i\) own a dataset \(I_i\) \(\forall\) i \(\in\) [n]. The characteristic feature of each type is formulated in Table 4 (Yin et al. 2021).
5 Challenges in federated learning
Various studies conducted on FL reveal that, along with several merits, a few challenges require addressing. This provides immense opportunities for future research in the field of FL. In this section, the primary challenges of FL, such as optimizing high communication costs, system heterogeneity, statistical heterogeneity, and data privacy issues are summarized (the challenges are as shown in Fig. 5).
5.1 Optimizing high communication cost
A FL system involves numerous devices used as clients across the network. If the number of devices increases, then the quality of the global model increases because a huge amount of data is available to train the model. However, it causes a significant increase in communication costs too. Whenever numerous devices participate in the training, the local models need to be frequently uploaded to the central server. It can be a bottleneck for large models because the wireless network has limited bandwidth. As a result, reducing communication costs is a major challenge in FL. The total number of communication rounds can be reduced, and the size of the data to be shared in each round of communication can be reduced as well. Several researchers explored this area to optimize the high communication costs in FL. Li et al. (2020) proposed one technique for selecting the clients in each communication round. The authors also mentioned that the challenges of FL provide several directions of work in a wide range of research. Nishio and Yonetani (2019) proposed a scheme that selects clients based on hardware characteristics. Caldas et al. (2018) introduced two novel strategies for reducing communication costs in FL. The first scheme uses some lossy compression technique on the global model, which is required to be sent to the clients. The second scheme allows clients to locally train smaller subsets of the global model; as a result, client-to-server communication and local computation are reduced. Yurochkin et al. (2019) proposed a FL model that avoids unwanted communication rounds by aggregating local models into a federated model that does not require additional parameters. Goetz et al. (2019) proposed a scheme, namely active federated learning, where in each round, clients are chosen with a probability based on the current model and data of the client in that round. This sampling scheme reduced the total number of required training iterations while keeping the same performance as classical FL. Zhu and Jin (2019) optimized Sparse Evolutionary Training (SET) to provide only a few parameters to the central server. Jiang and Ying (2020) proposed an adaptive technique for local training because each client manipulates predefined epochs in each round. The server determines the local training epochs on the basis of training time and training loss, reducing local training time when loss decreases. Hence, instead of sending the entire dataset through the network, it must create more communication-efficient ways that iteratively provide brief messages or model updates during training.

Challenges in FL
5.2 System heterogeneity
The heterogeneity of devices in the network participating in the training process affects overall performance of the FL model. Heterogeneity defines various devices network status, storage, computational, and communication capabilities. The processing capability of devices depends on hardware variation, network connectivity, and power level of devices. Even though primarily FedAvg algorithm (McMahan et al. 2017a) is established as a strategy to deal with heterogeneity, it is not robust enough to deal with it. Afterward, various researchers attempted to solve this problem by altering model aggregation approaches. System heterogeneity mainly refers to two aspects: (1) allocation of resources to heterogeneous devices, and (2) fault tolerance afforded to devices that are prone to becoming disconnected.
Bonawitz et al. (2019) proposed a selection method for authenticated devices from a set of devices participating in a federated system. It is important to Kang et al. (2019) that devices with enhanced quality engage in the training process, so the authors took client overhead into consideration. Tran et al. (2019) looked at the effect of heterogeneous power restrictions on training accuracy and convergence time. Nishio and Yonetani (2019) looked into different sampling policies for participating devices based on the available system resources. The goal is for the server to aggregate as many device updates as feasible within a predetermined time limit. Li et al. (2021) developed a set of fairness measures to evaluate device loss and an optimization technique to encourage fair resource allocation. Furthermore, it is necessary to check device’s power status and whether it is offline or active. Sometimes participating devices suddenly become offline due to system-related constraints. Also, participating devices may drop out due to connectivity or energy constraints before completing the assigned iteration during training. One solution might be to ignore fault of those devices, as proposed by Bonawitz et al. (2017) which is not always possible, especially when the devices hold important dataset characteristics. Wang et al. (2019) looked into the convergence guarantees of variants of FL methods. Low client participation is possible with the method by Li et al. (2020). As a result, optimization should continue to contribute to fault tolerance and resource allocation issues in FL. In the future, a potential solution to the issue of system heterogeneity may lie in implementation of fault-tolerant techniques for unsteady network environments.
5.3 Statistical heterogeneity
In traditional machine learning approaches, data are assumed to be independent and identically distributed (IID). This outline is appropriate for data collection and training in a distributed way. However, in FL, hardware devices used are heterogeneous, and data is collected from these devices mostly in non-IID format, i.e., data differ in terms of quality, variety, and quantity (Li et al. 2020). These data are hard to process and increase modeling and evaluation complexity. Modeling non-IID data and assessing convergence behavior of associated training techniques are complex tasks and open challenges in FL systems. The typical solutions are to concentrate on the global model, adjust local training mode, or add some additional data pre-processing steps (Li et al. 2020).
Several solutions are presented for dealing with heterogeneous data collected from various devices in FL. Smith et al. (2017) proposed one method to optimize data modeling in order to make it possible to personalize the experience for each individual device, such as MOCHA, which introduced multitask learning to make use of shared representation. Zhao et al. (2018) investigated transfer learning for personalization by running the FedAvg algorithm (McMahan et al. 2017a) after training a global model based on specific shared proxy data. According to Sattler et al. (2019), top-sparsification performs exceptionally well in non-IID FL contexts. A straightforward and practical pluralistic approach proposed by Eichner et al. (2019) addresses the cyclic patterns in data samples during FL. Though accuracy is the most important issue during federated training, some factors other than accuracy, such as fairness, should be considered when modeling federated data. A minimax optimization strategy is presented by Mohri et al. (2019) as a means of optimizing the centralized model for any target distribution that may be generated by a combination of client distributions. Li et al. (2019a) devised a framework in which devices that have more losses are given a higher relative weight in order to reduce volatility in the final accuracy distribution. The authors implemented this so that the overall accuracy would be more consistent.
Convergence behavior is another challenging topic at the aggregation stage. The presence of heterogeneity may cause the global model to misconverge. Wang et al. (2019) analyzed convergence guarantees based on gradient descent in non-IID data with assumptions like convexity. The authors improved the adaptive technique to lower the loss function under resource budget constraints. Li et al. (2019b) presented four types of convergence theorems for FedAvg (McMahan et al. 2017a) in non-IID scenarios, each with its own set of parameters or premises. These theorems reduced the theoretical gap in studying a FL algorithm’s convergence speed.
Statistical heterogeneity can be dealt with using a variety of heuristic approaches (Huang et al. 2020; Jeong et al. 2018), some of which involve the sharing of local device data or proxy data obtained from the server. Huang et al. (2020) combined clustering with FL to create a community-based FL approach for data pre-processing. The non-IID problem can be overcome by dividing independent data into distinct clusters and processing training in each community. However, these methods may be unrealistic in some situations, such as sending local data to the server (Jeong et al. 2018), which violates FL’s key privacy assumption, and sending globally shared proxy data to all devices (Huang et al. 2020; Zhao et al. 2018), which strains network bandwidth and requires careful generation or collection of such auxiliary data.
5.4 Fairness issues
The dominance of a group of clients over others in the federated setup is quite prevalent owing to its heterogeneous environment (Ray et al. 2022; Li et al. 2023). Data generated in the FL system is more often non-IID. This triggers a bias in the global model, favoring some clients over others. As a consequence, the global model that exhibits satisfactory performance on certain clients may not exhibit the same level of satisfactory performance on other clients, resulting in significant fairness concerns (Li et al. 2023; Wang et al. 2021). The concept of fairness in FL is mainly discussed in two broad categories (Chen et al. 2023). The first aspect is algorithmic fairness, which ensures that the output of a FL model does not exhibit bias against small groups based on sensitive attributes of clients. The second aspect relates to the equitable treatment of clients. In the vanilla FL setting, FL models that are trained on the larger dataset are assigned higher priority throughout the aggregation process. As a result, the global model will be adjusted to accurately represent the data distributions of clients with a larger dataset. This approach is quite trivial and does not hold good accuracy always, as it does not represent the real data fairly. Huang et al. (2022) introduced an algorithm called FedFa, which aims to enhance fairness and accuracy in horizontal FL systems. This is achieved by incorporating a double momentum gradient optimization scheme and a weight selection algorithm that facilitates training aggregation with more equitable weights. Liu et al. (2021) focuses on the challenges associated with ensuring fairness in a vertical FL system. The authors proposed a framework to address the fairness issues and solved the issues using an asynchronous gradient coordinate-descent ascent algorithm.
5.5 Privacy concern
FL explores the training of the given statistical model directly on remote clients and plays a significant part in ensuring the smooth operation of privacy-conscious applications in which training data are stored in edge locations (Ammad-Ud-Din et al. 2019; Hard et al. 2018; Huang et al. 2019; Zhao et al. 2020; Samarakoon et al. 2018). However, simply keeping data localized throughout training does not provide adequate privacy protection. The client’s sensitive information can be exposed to various security threats through the shared parameters. Even if only gradient data is passed to third parties or central servers, data privacy may still be compromised (Truex et al. 2019) by attackers. In FL, privacy definitions are usually divided into two categories: (i) global privacy and (ii) local privacy (Li et al. 2020). In global privacy, the server is assumed to be trusted. Hence, it is essential that the model updates that are generated at each communication round be kept secret from any untrustworthy third parties other than the central server. In terms of local privacy, the central server might be malicious. Hence, model updates created at each round must also be private to the central server in order to maintain local privacy. However, the general attacks on FL are essentially classified into two types (as shown in Fig. 6) and as described below (Li et al. 2020; Lyu et al. 2020):
5.5.1 Poisoning attack
Poisoning attack takes place during the training phase. Its goal is to either stop a model from being learned or affect it in such a way that it generates inferences that are beneficial to the attackers. This attack can be of two types: data poisoning attack and model poisoning attack. Both poisoning attacks try to alter the target model’s behaviour unfavorably.

Attacks in FL (Lyu et al. 2020)
-
Data poisoning attack: A data poisoning attack can be launched by any client participating in the FL training process. The attacker can train the model to misclassify several samples of data by adding them to the training set and labeling them with the intended target label. One data poisoning attack is the label-flipping attack proposed by Fung et al. (2018). The properties of the data are unchanged in this attack. However, the labels of the original training samples are switched to another class. For instance, malicious clients within the system have the ability to contaminate their dataset by converting all 0s into 1s. Another realistic data poisoning attack is the backdoor attack proposed by Gu et al. (2017). Backdoor attacks are a major risk in FL as data is obtained from malicious clients over extended periods of time. Backdoor attacks encompass the incorporation of malicious programs into a targeted model by means of corrupted updates transmitted from malicious clients. These attacks have the potential to make the global model act abnormally in response to particular inputs while making it appear normal in other contexts. The distributed backdoor attacks in FL are proposed in Bagdasaryan et al. (2020), Yang et al. (2019). They break one attack trigger into multiple portions and put each portion into separate attackers, rather than embedding the entire attack trigger into a single attacker. These attacks provide a novel assessment form for security analysis in FL.
-
Model poisoning attack: The goal of model poisoning attacks is to insert hidden backdoors into the global model or to contaminate local model changes before they are sent to the server (Lyu et al. 2020). It involves designing a specific input for a machine learning model with the intention of producing an incorrect result. Model poisoning attacks can be of two types (Lyu et al. 2020): Non-targeted model poisoning attack resulting in an inaccurate outcome, and Targeted model poisoning attack attempting to inject false input into the training data. Bhagoji et al. (2019) studied poisoning attacks on model updates, in which a subset of updates is poisoned at each iteration. By analyzing a targeted model poisoning attack in which a single dishonest client misclassified the targeted model, the authors revealed that model poisoning attacks are stronger than data poisoning attacks. Zhang et al. (2019) developed poisoning attacks in FL, based on GAN (Generative Adversarial Nets). In the scheme, an attacker initially treats himself as a benign participant and secretly trains a GAN to resemble basic samples of other participants’ training dataset. Then the attacker has fully control on these data samples to generate poisoning updates. Now the attacker can compromise the global model by uploading the poisoning updates to the server. Model poisoning attacks necessitate advanced technological capabilities and a large amount of processing power. Anomaly detection on the server side and the hiding of classification results are challenging directions for future development to resist this type of attack.
5.5.2 Inference attack
Inference attacks are also called exploratory attacks. Instead of tampering with the targeted model, an inference attack either produces incorrect targeted or untargeted outputs or gathers evidence on the model properties. The efficiency of the inference attack is primarily determined by the adversary’s knowledge of the information in the model. It can be classified into two types (Lyu et al. 2020): (1) white-box attacks where attackers have full access to the FL model and (2) black-box attacks where attackers can only make queries to the FL model. However, attackers can perform both active and passive membership inference attacks, as discussed in Nasr et al. (2019), Melis et al. (2019). Nasr et al. (2019) proposed a white-box membership inference attack method that can be applied to the federated systems to infer information through a curious central server or any client. This work focused on malicious server assumptions, though it could not recover any information about a target client because the client update is not visible to the attacker. Melis et al. (2019) proposed a scheme in which an adversary can infer whether any given text appeared in the training dataset or not. It helps the attackers reveal any natural-language text appearing in the training dataset during FL. Wang et al. (2019) designed a general attack framework that is able to retrieve sensitive information from any target client. Zhu et al. (2019) proved that without any prior knowledge of the training set, a malicious attacker might totally steal the training data from gradients in a few rounds. Many researchers are investigating ways to develop more robust security measures to prevent these types of attacks.
6 Privacy-preservation in federated learning
Since data has always been a major priority for any user or organization, significant challenges are associated with data privacy preservation in FL (Liu et al. 2022). In this section, we review and compare various privacy solutions for FL to prevent data leakage. Differential privacy ensure that the aggregated model updates in FL cannot be used to infer specific data points. During FL training, noise is added to the model updates to ensure high privacy guarantees and maintain model utility. Homomorphic encryption can be applied to design privacy-preserving protocols against malicious adversaries during FL. Furthermore, homomorphic encryption can be applied to design privacy-preserving protocols against malicious adversaries during FL. Secure multi-party computation can be applied in order to implement a secure FL framework. Secret sharing techniques can be an effective solution for developing secure and efficient FL frameworks, which can be used to secure aggregation during FL. Blockchain can also be a perfect match for FL for developing essentially secure distributed systems. Various researchers proposed novel privacy-preserving techniques in FL as described below. Also, we compare different privacy-preserving techniques in FL in Table 5.
6.1 Differential privacy-based approaches
Differential privacy (DP) can be used in FL algorithms to prevent information leakage. The approach is to add noise to the model parameter data to hide sensitive information. So any other party cannot restore the original data by observing model parameters, and an inference attack can be prevented. Conventionally, DP is represented by two models: (i) the global model and (ii) the local model. The local model is concerned with the training data, while the global model is concerned with the FL model. Output perturbation, objective perturbation, and gradient perturbation are used (Kang et al. 2020) for achieving DP by adding noise to the final model, objective function, and gradient, respectively. Prior to the training, the initial dataset is uploaded to a data center, which is regarded as reliable by global model. In cases where the data center is not reliable, the implementation of local DP is recommended as an alternative approach, where the data is generated at random, prior to its exposure. Local DP aims the safety of interaction between the clients and the server only.
Though the FedAvg algorithm (McMahan et al. 2017a) is vulnerable to differential attacks, various researchers proposed their privacy-preserving FL schemes based on the idea of global and local DP. Global DP-based FL approaches are accurate while they preserve data privacy. Applied to a full dataset, these approaches achieves a reasonable statistical distribution by adding minimal noise. Geyer et al. (2017) used global DP to hide whether a client took part in the training process while preserving a high level of overall model performance. Wei et al. (2020) used global DP and proposed a strategy that uses noise to lower the hamming distance between gradient parameters generated from two datasets of the same length. As a result, neither the server nor the malicious user can discriminate between the gradient parameters of different users. These systems must carefully choose several hyperparameters that affect communication and accuracy. Naseri et al. (2020) experimented with both global and local DP-based secure FL architecture by minimizing the capability of potential adversaries.
When compared to global DP-based FL methods, the local DP-based FL methods offer a more robust encryption and privacy guarantee. Bhowmick et al. (2018) introduced a flexible version of local privacy. It provides superior model performance over rigorous local privacy and adequate privacy guarantees over global privacy. In the context of meta-learning, Li et al. (2019c) presented locally differentially-private algorithms that can be used in FL with personalization and give provable learning guarantees in convex contexts. Lu et al. (2019) proposed a differentially private asynchronous FL for mobile edge computing, utilizing local DP for model updates. Cao et al. (2020) designed a FL framework using local DP to protect privacy in IoT. For training large-scale networks, Truex et al. (2020) proposed a FL framework with local DP. Wang et al. (2020) developed a FL framework based on local DP for industrial-grade text mining, ensuring data privacy and model correctness.
6.2 Homomorphic encryption-based approaches
Homomorphic encryption (HE) is another privacy-preserving technique (Rivest et al. 1978) that can be used in FL (Zhang et al. 2020; Asad et al. 2020; Zhang et al. 2020) to prevent information from leaking during the sharing of gradient between the server and clients. Formally, HE is a type of encryption that permits computations on encrypted data without first decrypting it. Consider the following example:
Say, EncAlgo is an encryption algorithm. EncAlgo can be called homomorphic over an operator *, if it satisfies the following criteria: EncAlgo(\(R_1\)) * EncAlgo(\(R_2\)) = EncAlgo(\(R_1 * R_2\)); \(\forall R_1 , R_2\in R\), where, R represents a set of plaintext.
HE can be applied to design privacy-preserving protocols against malicious adversaries during FL. Both fully HE and partially HE fall under the broad category of HE methods. HE methods can also be separated into a third category known as hybrid encryption. There are two subtypes of partially HE: (1) additively HE and (2) multiplicative HE. Partially HE only supports either additive or multiplicative operations, which are referred to as additively HE and multiplicative HE, respectively. Operations that are additive and multiplicative can be carried out with fully HE. Fully HE offers a more secure method of data protection than partially HE does, although at the expense of increased computational requirements.
HE and DP can be utilized to protect the learning process by computing encrypted data. Hardy et al. (2017) proposed a three-party end-to-end solution in two phases: one phase is privacy-preserving entity resolution, and the other phase is federated logistic regression over messages encrypted with an additively homomorphic scheme. The system enables learning without disclosing the data that data providers share, and it is secure against an honest-but-curious adversary. Liu et al. (2020) first proposed FTL and used additively HE for modifying neural network models minimally with almost lossless accuracy. Iilias et al. (2019) proposed an enhanced FL framework where HE is employed to perform model training on encrypted data rather than on raw data. Hao et al. (2019) designed an efficient privacy-preserving scheme for FL, integrating DP and lightweight HE into its architecture. The scheme is based on a stochastic gradient descent approach and is robust to a curious-but-honest server. Aono et al. (2017) also used HE to protect the gradients of participating clients data on the honest-but-curious cloud server. Before being stored on the cloud server, all gradients are encrypted in the scheme. This solution can provide privacy protection without compromising the learning model’s accuracy.
6.3 Secure multi-party computation-based approach
Secure multi-party computation (SMPC) is a traditional cryptographic protocol that focuses on how to safely compute a function for several clients without relying on a trusted third party. Formally, n number of clients \(\{P_1, P_2, \ldots , P_n\}\) want to calculate a global function \(f\{I_1, I_2, \ldots , I_n\}\) from their individual dataset \(I_i\). A protocol is considered SMPC if it ensures (Li et al. 2018): (i) the function \(f\{I_1, I_2, \ldots , I_n\}\) is accurate, and (2) no private information of \(I_n\) is disclosed to other participants. To improve the privacy of FL, SMPC is frequently used. In a safe and reliable manner, secure multi-party computation calculates the sums of model parameter changes that come from each individual client’s device. Training in this manner has practical benefits, like the fact that a client’s device can share an update, ensuring that the server can only see it after averaging it with other clients’ updates. For example, Bonawitz et al. (2017) proposed a SMPC protocol for safeguarding individual clients model updates. The central server could not view any local updates in the approach; however, it could still view the precise aggregated results at each communication round. Though this methodology provides high security, it is still not applicable for broader-scale scenarios due to the high communication cost. In addition, Truex et al. (2019) investigated a hybrid technique that combined SMPC with DP. They enhanced model accuracy in FL while maintaining a tangible guarantee of privacy and safeguarding against extraction and collusion attacks. Zhu et al. (2020) proposed a privacy-preserving weighted FL scheme within an oracle-aided MPC framework.
6.4 Secret sharing-based approaches
HE technique may increase communication overhead because several pieces of data, such as the private keys, must be transmitted during the process. In addition to HE, other security schemes, such as secret sharing (SS), can be applied to generate a secure FL framework. SS-based FL (Bonawitz et al. 2017; Sharma et al. 2019; Xu et al. 2019) is another approach to privacy-preserving FL that relies on the use of SS techniques. SS-based FL can be used to secure aggregation during FL. In this approach (Shamir 1979), original secret data is divided into several parts or shares and distributed among a set of clients in a manner that ensures that no client can reconstruct the original secret data without the collaboration of the other clients. In the Sect. 8, we discuss SS-based security solutions for FL in detail.
6.5 Hybrid methods
In recent years, privacy-preservation in FL based on hybrid approaches are presented as a means of achieving an equilibrium between the trade-offs of data privacy and data utility. There are some limitations to the above-mentioned schemes. Cryptographic technique-based FL methods have a tendency to suffer from computation and communication overhead. Perturbation-based FL methods have a tendency to deteriorate the data utility. FL based on hybrid methods uses more than one privacy-preserving approaches and utilizes their advantages. DP and SMPC can be integrated to develop a secure FL framework (Mugunthan et al. 2019; Xu et al. 2019). DP and HE can be integrated to develop a secure FL framework (Hao et al. 2019, 2019; Truex et al. 2019). HE and SMPC can be integrated to develop a secure FL framework (Choquette-Choo et al. 2021; Truex et al. 2019). SS and SMPC can be integrated to develop a secure FL framework (Bonawitz et al. 2017; Sharma et al. 2019). HE and SS can be integrated to develop a secure FL framework (Zhao et al. 2020; Gao et al. 2019; Xu et al. 2019; Liu et al. 2020; Guo et al. 2020; Dong et al. 2020). By combining more than one technique, FL aims to strike a balance between collaborative model training and privacy preservation.
6.6 Other privacy-preservation techniques
There are some other methods proposed by various researchers to preserve privacy in FL. Here, we discuss a few of them.
6.6.1 Additive and multiplicative perturbation-based approaches
Perturbation is the process of introducing minor alterations to the input data with the intention of observing the impact that these modifications have on model performance. Perturbation-based FL is further classified into: (i) Additive Perturbation, (ii) Multiplicative Perturbation. FL methods based on additive perturbation (Yin et al. 2021) attempt to protect privacy by introducing random noise into weight or gradient updates (Feng et al. 2020; Geyer et al. 2017; Hao et al. 2019; Wei et al. 2020). One advantage of this approach is its simplicity, ability to maintain the statistical properties, and lack of requirement for understanding the original data distribution. The perturbation maintains the privacy of the datasets while not compromising the accuracy of the FL (Chamikara et al. 2021). The original data is transformed into a different space through the use of a multiplicative perturbation (Yin et al. 2021), as opposed to the addition of random noise to the data. Multiplicative weight update-based FL frameworks (Zhang et al. 2020) avoid gradient information leaking to curious servers by applying local weight updates. Sometimes the perturbation process is controlled by global parameters produced by the centralized server (Chamikara et al. 2021), making it vulnerable to an honest but curious server. In general, multiplicative perturbation-based FL approaches (Reisizadeh et al. 2020; Zhang et al. 2020; Feng et al. 2020) are stronger than additive perturbation-based FL methods. This is due to the fact that the reconstruction of the original data values is more challenging with multiplicative perturbation-based FL methods.
6.6.2 Anonymization technique-based approaches
Anonymization technique is used to remove personally identifiable information from data sets, maintaining the anonymity of the individuals the data describe. This is mainly done with the motive to preserve privacy of user’s data (Choudhury et al. 2020). Hao et al. (2022) presented weight anonymized factorization for federated learning (WAFFLe), which makes use of neural network weight factorization and Bayesian non-parametrics. They replaced the notion of a single central server with a dictionary of rank-1 weight factor matrices. The criterion for selecting these weight factors is done such that each local device can have a model tailored to its own data distribution, with the weight factors’ learning load being shared throughout devices. Secondly, to promote factor sparsity and factor reuse, they applied the Indian Buffet Process (Ghahramani and Griffiths 2005) as a prior. Variational inference is then used to determine the factor distribution for each client. The distribution capturing the factors a client uses is kept local, even while updates to the dictionary of factors are sent to the server. By hiding the factors a client is utilizing, this provides an additional layer of security and makes it more difficult for an adversary to carry out membership inference attacks or dataset reconstruction. Orekondy et al. (2018) proposed a method employing data-augmentation techniques that incorporate adversarial biases into device data, providing significant defense against de-anonymization risks without compromising much with the integrity of data. Additionally, studies (Choudhury et al. 2020; Song et al. 2020; Zhao et al. 2021; Xie et al. 2019) provide further details on anonymization techniques.
7 FL framework empowered by blockchain
The collaboration of Blockchain and FL is a developing field of research that integrates two emerging technologies to compliment each other and provide a robust security and privacy preserving framework. The combination of these two technologies introduced a flexible framework (Awan et al. 2019; Martinez et al. 2019; Pokhrel and Choi 2020; Majeed et al. 2019) that has the ability to verify the local model updates. Blockchain technology has evolved into a broad variety of versions that can satisfy a number of requirements in many real-world settings. Blockchain is a distributed ledger technology that provides a secure, transparent, and decentralized way of storing and sharing data. Each node in a blockchain network (or a chosen committee) plays an equal role and collaborates to uphold the community by reaching a consensus and encoding the public ledger locally. It enables participants to transact and interact with one another without requiring them to rely on a centralized authority. Blockchain enabled FL (Kim et al. 2019; Kim and Hong 2019; Bao et al. 2019) aims to create a secure and transparent way of training machine learning models across multiple participants while ensuring privacy, data ownership, and trust. In a blockchain enabled FL system (Chai et al. 2020; Ma et al. 2021; Myrzashova et al. 2023), the training data remains with the participants, and only the model updates are shared with the blockchain network. The blockchain acts as a decentralized ledger that records model updates, ensuring transparency and immutability. Additionally, the blockchain network can also incentivize participants to contribute their computational resources and data to the system, making it more efficient and scalable. Some other research works presented in Lu et al. (2020), Lu et al. (2019), Hieu et al. (2020), Toyoda and Zhang (2019), ur Rehman et al. (2020), Qu et al. (2020) proved that blockchain can be a perfect match for FL for developing essentially secure distributed systems. Overall, blockchain enabled FL has the ability to completely transform the manner in which ML models are trained, enabling secure and privacy-preserving collaborations across multiple participants, industries, and domains.
8 Secret sharing-based security solutions for federated learning
In the area of information security, secret sharing (SS) has evolved as a branch of research to secure sensitive information from misuse by unauthorized parties. The development of safe and efficient FL frameworks may benefit from the utilization of SS as an effective approach. In a (t, n) threshold secret sharing (TSS) scheme, the owner of the secret or a reliable third party, also known as dealer, divides a secret into n parts that are referred to as shares (or shadows). The shares are distributed among n number of authorized participants in such a way that each participant holds exactly one share. Reconstruction of the secret or secrets can be done only when an authorized set of participants pool their corresponding shares. In the (t, n) - TSS scheme, t number (referred to as the threshold value) of shares has to be combined to reconstruct the secret. A threshold number of participants, or more than that, submit their shares to the combiner for reconstructing the secret. However, the secret cannot be reconstructed if the number of shares is less than the value of t. Both Shamir (1979) and Blakley and Safeguarding cryptographic keys, in, (1979) are the first to independently introduce two distinct TSS schemes. Shamir’s scheme, Shamir (1979) is based on the Lagrange polynomial interpolation, while the Blakley method (Blakley and Safeguarding cryptographic keys, in, 1979) is based on the concept of hyperplane geometry. On the basis of the Chinese Remainder Theorem (CRT), Mignotte (1982) and Asmuth and Bloom (1983) introduced another two secret sharing schemes. Several researchers (Pang and Wang 2005; Steinfeld et al. 2007; Maji et al. 2021; Hineman and Blaum 2022) have extended the scheme proposed by Shamir (1979) using different innovative concepts. The formal definition of (t, n) - TSS scheme (Stinson and Paterson 2018) is mentioned as follows:
Definition 1
A (t, n) -TSS scheme is a method of allocating shares of a secret S among a set of participants \(\mathcal {P} = \{P_1, P_2, \cdots , P_n\}\), in such a manner that any t or more \((\le n)\) participants can compute the S, however, no group of \(t - 1\) or lesser participants can do the same. Figure 7 briefly depicts the process of (t, n) - TSS.

The process of (t, n) -TSS scheme
Multiple secrets can also be shared concurrently in a multi-secret sharing (MSS) scheme. Some popular MSS schemes are presented in He and Dawson (1995), Li et al. (2005), Deshmukh et al. (2018), Endurthi et al. (2014). Shamir (1979) assumes all three actors (dealer, participants, and combiner) in the SS process are honest. However, in real situations, there is no certainty that these criteria always hold, and as a result, significant security risks arise during the SS process. There are several possibilities for cheating, as described by Zhao et al. (2007). It is possible that the dealer can send fake shares to the participants, preventing them from ever obtaining the real secret. If a participant acts as a cheater and sends a fake share during the recovery process, the real secret can not be reconstructed. An intruder may alter the shares during the share distribution phase. An adversary may act as the combiner, asking for shares from participants; as a result, the actual secret is revealed to the wrong entity. The verifiable secret sharing (VSS) addresses these concerns regarding data security during the SS process. Cheating detection and/or cheater identification are the primary objectives of the VSS schemes. Zhao et al. (2007) extended YCH scheme (Yang et al. 2004) into a verifiable multi-secret sharing (VMSS) scheme that maintains the security of both the shares and the secret. Subsequently, many VSS schemes (Dehkordi and Mashhadi 2008; Hu et al. 2012; Chattopadhyay et al. 2018; Kandar and Dhara 2020) are proposed to prevent different kinds of cheating in the SS process.
8.1 The essential entities of a TSS scheme
A TSS scheme consists of the following primary entities:
-
Secret or secrets: A secret S or a set of secrets {\(S_1, S_2, \ldots , S_k\)} is/are the secret data need to be shared among a group of participants.
-
Shares: The secret/secrets have to be encoded into n shares, say \(s_1, s_2, \ldots , s_n\) such that none of them individually reveals any information about the secrets.
-
Dealer: Dealer D is mainly responsible for encoding the secret/secrets into n shares and distributing them to the participants in such a way that exactly one share is given to each of the participants. The dealer is either the legal owner of the secret/secrets or a trusted third party.
-
Participants: Participants are denoted as set \(\mathcal {P} = \{P_i\}_{i=1}^n\) and they are the individuals that are looking for the secret/secrets.
-
Combiner: A combiner C is primarily responsible for decoding the secret/secrets if an authorized subset of participants submit their shares.
8.2 Shamir’s TSS scheme (Shamir 1979)
Shamir (1979) proposed a TSS scheme based on Lagrange interpolating polynomial. Given any t points \(\{(x_i, y_i )\}_{i=1}^t\) those lie on a polynomial, the unique \((t-1)^{\textrm{th}}\) degree polynomial \(g^t (x)\) can be reconstructed using Lagrange’s interpolation theorem as follows:
The following is a description of the various stages of the scheme:
8.2.1 Construction phase
Step 1. The dealer D chooses a large prime p such that \(p > n\) and a secret \(S \in \mathbb {Z}_p\).
The dealer generates a \((t-1)^{\textrm{th}}\) degree polynomial as follows:
where \(a_0 = S\) and \(a_1, a_2, \ldots , a_{t-1} \in \mathbb {Z}_p\) are chosen arbitarily.
Step 2. D computes n unique shares as:
Then he/she sends each \(s_i\) to \(P_i\) via secure channels (for \(i = 1 \text { to } n\)).
8.2.2 Recovery phase
Without loss of generality, assume that \(\{P_i\}_{i=1}^t\) submit their shares \(\{s_i\}_{i=1}^t\). Using Lagrange interpolation, we can find the secret as follows:
8.3 Secret sharing-based FL schemes
FL relies on secure model aggregation to protect the FL datasets while permitting global aggregation. It can train global or personalized models using any aggregation-based FL technique. Model aggregation in FL systems must be resilient to user dropouts for a variety of reasons, making its design much more complicated. Several studies are being conducted in FL with the intention of enhancing data privacy by utilizing SS schemes. We provide an overview of these research works in this section.
Bonawitz et al. (2017) used a SS scheme and double-masking protocol to resolve the security challenges of FL. In this system, a trustworthy authority randomly generates a key pair consisting of public and private keys and a random noise for each client. When a client wants to share local gradients, he offers a portion of his secret key, which is then encrypted using the public keys of other users in addition to some noise generated at random. When added together, all of this additional data is either recovered by the SS scheme or cancelled out. The messages are then delivered to the server. The server computes the random noise as well as other information, and then it aggregates gradients based on the SS protocol. In this study, the authors also consider network instabilities and provide a way to assist clients who suddenly drop out during the training phase.
Apart from the protocol for secure aggregation proposed in Bonawitz et al. (2017), there are other research works that aim at making secure aggregation more efficient. The scheme developed by Bonawitz et al. (2017) is extended by both VerifyNet (Xu et al. 2019) and VeriFL (Guo et al. 2020). Both (Xu et al. 2019; Guo et al. 2020) provided the verifiability property above Bonawitz et al.’s scheme (Bonawitz et al. 2017) to assure the validity of the aggregation; however, these protocols require the assistance of a trusted third party in order to produce public and private key pairs for all the clients. The scheme proposed by Bell et al. (2020) and Choi et al. (2020) reduced the overhead in comparison to Bonawitz et al. (2017) by using secure aggregation protocols with polylogarithmic communication and computation complexity. Their central concept is to substitute the star topology associated with the communication network described in Bonawitz et al. (2017) with arbitrary subgroups of clients and to use SS for just a certain number of client pairs as opposed to all client pairs. So et al. (2022) come up with a new protocol that offers the same level of privacy and dropout-resiliency guarantees as Bonawitz et al. (2017) while at the same time significantly decreasing the aggregation complexity and, consequently, the runtime complexity. Another scheme proposed by So et al. (2021) used the idea of circular communication topology and reduced the computation and communication overhead of secure aggregation over Bonawitz et al. (2017). The authors (So et al. 2021) used additive SS combined with erasure correcting codes for tolerance of dropout clients involved in FL.
Liu et al. (2020) provide a new technique for integrating HE and SS methods using beaver triples into two-party computation with neural networks within the FTL framework. This is done in such a way that only a few changes to the neural network need to be made; however, the accuracy should be nearly lossless. The other major benefit of the SS-based schemes is that computation is significantly quicker than with the HE-based methods. Sharma et al. (2019) used the SS technique and demonstrated the usefulness and scalability of a secure FTL model for semi-honest as well as malicious parties. The authors show how two parties can work together to create an FTL model that is able to protect their data from being accessed by unauthorized parties while correctly predicting the labels that should be applied to the dataset pertaining to the target domain. They reduced the overhead of the scheme proposed by Liu et al. (2020) without decreasing the accuracy rate. Gao et al. (2019) used an end-to-end privacy-preserving multi-party learning approach for constructing a heterogeneous FTL framework that is based on SS and HE. Participants in FL execute a secure model update correspondingly when the secure gradient value is obtained. This process can be performed locally based on both SS and HE. The approach is susceptible to being manipulated by either a dishonest server or harmful users.
Xu et al. (2019) designed a verifiable federal learning framework VerifyNet, which is considered the first procedure that can verify the accuracy of a model retrieved from the cloud. The authors proposed to apply a double masking protocol with a combination of SS and a key agreement technique to improve the confidentiality of gradients in FL. In addition, the framework enables clients to withdraw during the training phase. However, the drawbacks of this scheme are: (1) it depends on a fully trusted third party, i.e., the key generation center (KGC), and (2) there is an opportunity for improvement in performance to guarantee the accuracy of results returned to the server. Han et al. (2022) used the methods of data auditing and certificate-less tag creation in VerifyNet (Xu et al. 2019) to address security and performance challenges. They eliminated the requirement of using a fully trusted third party in their scheme in order to make it more applicable to practical situations. Instead, they are operating under the assumption that the key generation center (KGC) is honest yet curious. In addition to this, the approach is able to validate whether the outcomes provided by the server are accurate.
Kadhe et al. (2020) introduced a secure aggregation protocol that is computationally and communicatively efficient and also resistant to client breakdowns. The proposed scheme relies on a MSS scheme based on the fast Fourier transform. The MSS scheme is information-theoretically secure and strikes a balance between the number of secrets, the privacy threshold, and the dropout tolerance. Zhao et al. (2020) came up with a secure member selection technique for the FL framework that avoids the need to establish a private channel for the pre-distribution of keys. The proposed technique is easily extensible to cover other key agreement efforts based on similarity. The scheme merges the private set intersection (PSI) and Shamir’s SS (Shamir 1979) to implement entity-based validation. When the PSI and SS schemes are combined, the secure member selection approach has zero information leakage. This strategy can defend trial-and-error attacks, conspiracy attacks, and replay attacks, or at least a portion of each of these types of attacks. In the context of collaborative and few-party FL, Beguier and Tramel (2020) proposed an effective and safe method for performing secure aggregation over compressed model updates. The secure aggregation protocol functions between multiple servers with minimal communication and computation costs and no preprocessing latency. However, since this scheme is only tested on data that is independently and identically distributed (IID), it is unknown whether it is compatible with the non-IID data that is frequently utilized in FL.
Liu et al. (2020) proposed a privacy-preserving federated k-means scheme for proactive caching in the next generation of cellular networks. The scheme is based on two techniques that protect privacy: FL and SS. Proactive caching estimates content popularity using k-means. To train a k-means model, base stations must collect user location and content choice data, which may result in user privacy leakage. Current privacy-preserving k-means algorithms typically result in a significant decrease in user experience quality and cannot handle user dropout. A suite of SS protocols is used in the proposed scheme to enable lightweight and efficient FL of k-means. When there are dropout users, this technique provides privacy-preserving k-means training for proactive caching. Instead of transmitting encrypted data directly, the proposed scheme transmits shared secret gradients, which are more secure and require less processing time. In addition, the user dropout condition is considered for privacy-preserving k-means, making the scheme more applicable to real-world applications. Szatmari et al. (2020) proposed a secure framework that combines FL with SS in the context of hearing aids with the purpose of training models locally while maintaining the particular user’s privacy. This is necessary because hearing healthcare data is of a very sensitive nature. In the proposed scheme, SS hides the gradient value during local training at the client’s end. Thus, gradient values from each layer of all models used for local training are turned into secret shares and sent to the other devices. When all devices have all the secret shares for the corresponding layer value, the aggregation is done. All devices record the aggregated data as secret shares. A trusted authority takes the aggregated layer values in the form of secret shares, converts them to real numbers, and produces a weighted average based on the number of clients who submit shares. Finally, the aggregated values are added to a ResNet model and sent back to all clients for another epoch of training on local datasets. As a result, no entity has access to the raw values associated with the data other than the clients who own the data and the trusted authority that receives aggregated values.
Roy et al. (2022) proposed an efficient scheme that facilitates secure aggregation of authenticated updates. The proposed scheme has the ability to enforce arbitrary integrity checks and remove defective updates from the aggregate without compromising privacy. The proposed scheme ensures input privacy based on Shamir’s TSS scheme (Shamir 1979). Verifiable secret sharing (VSS), which confirms the validity of shares of the original secret, ensures input integrity. The authors employed multiple trusted verifiers in a single-server environment by having clients serve as verifiers for one another under the guidance of the server. Utilizing the TSS scheme, multiple subsets of clients, each of which is capable of emulating the verification protocol, are created. Jiang et al. (2021) adopted the Diffie–Hellman key agreement based on discrete logarithms and Shamir’s TSS protocol (Shamir 1979) and proposed a privacy-preserving FL scheme that drops the assumption of threshold while maintaining security assurance.
In FL, all participating clients and the server share local gradients to prevent direct information leakages; however, an adversary can use the gradients to extract information. Some quantized gradient methods have been presented for FL gradient synchronization with low network communication costs. These approaches quantize float gradients into low-precision numbers while preserving valuable information. TernGrad (Wen et al. 2017) is one of the most effective methods for quantizing gradients into ternary vectors. In order to develop a FL system that is both effective and safe, Dong et al. (2020) integrate privacy-preserving approaches with TernGrad. First, the authors take a look at the ways in which TernGrad (Wen et al. 2017) violates users’ privacy. They devised a plan of attack and conducted an attack, and then, as a solution to the privacy issue, they provided two different privacy-protecting methods. The first protocol is based on Shamir’s TSS (Shamir 1979), and the second one is based on Paillier HE. The proposed schemes (Dong et al. 2020) are designed to defend against an adversary who is honest yet curious, or who is partially honest. Dong et al. (2019) proposed another SS-based reliable protocol for the local gradients’ sharing by clients, which involves easy arithmetic calculations. Thus, the authors boost the efficiency of the scheme while maintaining strong security. The scheme is resistant to adversaries that are semi-honest. In the semi-honest setting, the protocol is designed using Shamir’s TSS (Shamir 1979). As long as no more than \(t-1\) (where t is the threshold) servers are able to collude and at least two participating clients are trustworthy, the protocol can withstand different threat models. The scheme proposed by Zhang et al. (2022) also employs Shamir’s TSS (Shamir 1979) and Diffie-Hellman key exchange to enable a dropout-tolerant and collusion-resistant solution for FL participants. SS concepts are also used in the schemes introduced by Zhang et al. (2017), Zhu et al. (2020) and Wu et al. (2020) in order to develop reliable and secure FL frameworks. The scheme proposed by Zhu et al. (2020) introduced a flexible privacy-preserving weighted FL within the framework for SS, where individual private data is divided into arbitrary shares and allocated across a set of predefined computing servers. SS-based FL is still a presently underway research field, and ongoing efforts are being made to improve the efficiency and scalability of SS-based FL.
8.4 Advantages of secret sharing (SS)-based FL
Secret Sharing (SS) based FL offers a number of benefits, including the following:
-
Privacy-preserving: SS-based FL ensures that participants’ data remains private while distributing it across multiple devices and participants.
-
Decentralized: SS-based FL is also a decentralized approach that does not depend on a centralized authority to administer and govern the data.
-
Efficient: SS-based FL can be more efficient than other privacy-preserving techniques that rely on encryption or obfuscation since the shares can be combined locally without requiring a lot of computational resources.
-
Robust: SS-based FL is also robust to malicious participants since it requires a certain threshold of participants to collaborate to reconstruct the original data. Therefore, it is difficult for a single participant to fake the data or corrupt the system.
-
Flexible: SS-based FL is flexible since it allows participants to define their own sharing policies and rules that suit their specific requirements.
9 Quantum federated learning (QFL)
Quantum federated learning (QFL) is an area of study that combines the ideas of quantum computing (QC) with FL. It is an innovative framework (Chen and Yoo 2021; Chehimi et al. 2023) that integrates the computational capabilities of quantum technologies with the benefits of traditional FL. FL is supposed to preserve raw data on local clients; however, exchanging model updates during training in FL can expose sensitive data to attackers. While traditional encryption-based methods offer some sort of security, sometimes they may not be sufficient against advanced attacks. QFL can improve privacy by adopting quantum-secured techniques, such as quantum key distribution (QKD), which offer greater safety against surveillance and hacking than classical encryption-based methods. In addition, QFL improves computational efficiency, reduces communication overhead, and increases scalability in comparison to traditional FL.
The quantum computer is a computational paradigm that makes use of the laws of quantum mechanics (QM) to improve the efficiency with which complex computations are carried out in comparison to classical computers. QFL has the capability to be implemented across classical and quantum communication networks, thereby providing information-theoretic security measures that exceed those of conventional FL frameworks. QFL can revolutionize ML model development, training, and deployment by combining the computational benefits of QC with the privacy-preserving capabilities of FL. The primary objectives for the development of QFL include the following:
-
Integrating quantum principles into FL could enhance the privacy and security aspects. QFL offers unique capabilities in SMPC and uses quantum-secured techniques, like QKD, making it more robust against classical attacks.
-
FL involves aggregating updates from multiple devices, and the optimization process can benefit from quantum algorithms and quantum data encoding (QDE), leading to faster convergence and reduced computational time.
-
Quantum entanglement connects particles regardless of distance. QFL could use this property to manage the global model across decentralized devices faster and more efficiently.
-
QC could open up new ways to do ensemble learning, in which many quantum models or hybrid quantum-classical models are trained on devices that are spread out. FL could be used to aggregate these quantum ensemble models.
-
QFL might involve the training of quantum neural networks or quantum-inspired models across distributed devices. FL would facilitate the collaboration and combination of knowledge from diverse quantum nodes.
-
QFL uses quantum computers’ parallelism property to handle large datasets and train complicated models across several nodes, enabling scalable FL.
-
As quantum computers become more prevalent, QFL is designed to handle and learn from quantum datasets more efficiently than classical methods.
The integration of QC and FL can create new opportunities and challenges in various fields, including healthcare, telecommunications, transportation, finance, networking, smart cities, etc. Qu et al. (2023), Xu et al. (2023), Wang et al. (2023), Zhao (2023), Pujahari and Tanwar (2022), Ren et al. (2023). Qu et al. (2023) proposed a QFL framework in 5G mobile network for intelligent diagnosis. Xu et al. (2023) proposed a secure FL sytem for quantum autonomous driving to improve the robustness of FL-enabled autonomous vehicular networks. The method proposed by Wang et al. (2023) utilizes variational quantum algorithms-based ML for local FL training, efficiently managing huge datasets and complex models, and accelerating FL convergence. Zhao (2023) proposed a generic framework for QFL on non-IID data with one-shot communication complexity which significantly outperforms conventional ones. Ren et al. (2023) integrated QKD into the FL system and proposed a quantum-secured distributed intelligent system to ensure the continued security of communication and data. Pujahari and Tanwar (2022) proposed a two-tier QFL comprises QNN operations in both the access points and the cloud. In the paper. numerous possible QFL implementations in 5G networks, critical technological issues, and unresolved problems pertaining to QFL research in wireless communications are addressed.
The QFL framework usually considers the classical server (same as in traditional FL) and quantum clients. The clients being quantum in nature are capable of encoding data into quantum states and Quantum machine learning (QML) model to compute the local model weights in each training round (Song et al. 2023). These local weights are then submitted to the server for aggregation and redistribution of global weights to all the clients for updating their local parameters. We provide a mathematical notion of QFL as defined by Song et al. (2023) in below:
Let each client \(P_i\), \(\forall\) i \(\in\) [n] have a repository of data samples denoted by
where n denotes the number of quantum clients, m denotes the dimension (cardinality of attribute space) of the input data sample x such that x \(\in\) \(\mathbb {R}^d\) and \(\{x_j ^{(i)}\}\) indicates the number of data owned by \(P_i\). An encoding quantum circuit (Chen and Yoo 2021) \(\mathbb {U}\)(x) is initialized as \(\mathbb {Q}_0\), where \(\mathbb {Q}\): \(\mathbb {R}\) \(\times\) \(\psi\), where \(\psi\) is a quantum state.
In each training round, the \(P_i\) transforms its local data (\(I^{(i)}\)) onto quantum state:
such that \(\mathbb {Q}^{(i)}\) and along with its parameterized quantum circuit \(\mathbb {V}\)(\(\theta\)) computes the local gradient \(\mathbb {G}_{L_i}\). The local gradients \(\{\mathbb {G}_{L_i} ^{(i)}\}_{j=1} ^ {n}\) \(\forall\) i \(\in\) [n] are then uploaded to the server for global aggregation.
The server performs the averaging operation:
In a typical federated setting, \(W_i\) = \(m_i/m\). The server then broadcasts the global gradient, \(\mathbb {G}_{B}\) to all the clients to carry out their local computation as:
where \(\alpha\) denotes the learning rate. The training process continues till convergence as in classical model.
9.1 Privacy-preservation in QFL
Quantum computers perform operations exponentially faster than classical computers (Huang et al. 2022). Post-quantum cryptographic techniques can be integrated into the FL system (Ren et al. 2023) to ensure the continuous security of communication and data. Since quantum procedures are difficult to comprehend and put into practice, they need the use of specialized hardware, which contributes to their level of sophistication. Local QFL model training involves applying quantum gates and circuits, leading to significant noise generation, especially on Noisy Intermediate-Scale Quantum (NISQ) devices (Preskill 2018). Aggregation of noisy parameters at the QFL server may obscure useful information, causing extended training periods and performance degradation. Small-scale local QML models on NISQ devices limit the analysis of high-dimensional data, hindering the potential benefits of QFL. Transmitting classical learning parameters in QML models over classical networks exposes vulnerabilities to conventional FL attacks. Quantum-specific features, such as quantum superposition, may be exploited, leading to privacy and security concerns in QFL deployments. However, continuous research is carried out to prioritize the development of scalable QFL algorithms and protocols. Investigation of advanced Quantum Error Correction (QEC) techniques, exploration of quantum-inspired classical approaches like tensor networks for data compression are now demanding research areas.
Several vulnerabilities are introduced in QFL frameworks, particularly when deployed over conventional networks. Classical learning parameters transmitted directly via QML are susceptible to conventional FL attacks, including monitoring and parameter alteration. The complexity of these vulnerabilities increases as a result of quantum-specific characteristics, such as quantum superposition, that might be naturally incorporated in the classical learning parameters. Significant vulnerabilities encompass membership inference attacks, which constitute a risk of sensitive data disclosures when combined with quantum generative models, and quantum shadow model attacks, which enable an adversary to approximate the features of quantum circuits. Both increase security and privacy concerns when deploying QFLs in comparison to traditional networks.
Quantum data privacy-preserving techniques consist of the implementation of quantum-based secure protocols, including quantum homomorphic encryption (QHE), quantum secure multi-party computation (QSMPC) and quantum differential privacy (QDP) (Ren et al. 2023; Chehimi et al. 2023; Yamany et al. 2021). With blind quantum computation (BQC) (Fitzsimons 2017), a client can use one or more remote quantum servers to carry out a quantum computation while maintaining the computation’s structure hidden. These techniques facilitate the collection of features from data while safeguarding sensitive information, as discussed below.
9.1.1 Quantum homomorphic encryption (QHE)
Quantum Homomorphic Encryption (QHE) executes computations on encrypted data without requiring decryption in QFL framework. QHE can be implemented in FL to protect the confidentiality of private information while allowing clients and the server to train a global model collaboratively. An advanced form of QHE, quantum fully HE (QFHE) permits arbitrary computations to be performed on encrypted data. In a FL configuration, clients can encrypt their confidential information prior to transmission to the server using QHE. Without accessing the raw data, the server can then conduct quantum computations, such as model updates, directly on the encrypted data. This procedure maintains the confidentiality of client’s sensitive information. Xu et al. (2023) presented a safe FL strategy for quantum autonomous driving that integrates the local differential privacy (DP) and homomorphic encryption (HE) to improve FL-enabled autonomous vehicular networks’ dependability and robustness. The HE approach of the scheme addresses eavesdropping and sybil attacks with minimal model accuracy loss.
9.1.2 Quantum secure multi-party computation (QSMPC)
Quantum Secure Multi-Party Computation (QSMPC) enables different users to compute a function jointly over their inputs while maintaining the confidentiality of the inputs. When implemented in FL, QSMPC can facilitate secure client interaction while safeguarding sensitive data. A fundamental QSMPC primitive, quantum oblivious transfer (QOT) enables a sender to convey one of multiple pieces of information to a receiver without the sender being aware of which piece was selected. During FL, QOT can serve as a foundational element for more intricate QSMPC, which safeguards the confidentiality of client data. Huang et al. (2022) implemented QSMPC, which uses QM properties to tackle the complexities associated with the secure computation of federated gradients. Dulek et al. (2020) discussed the proper functionality for achieving QSMPC with a dishonest majority (the comparison is presented in Table 6).
9.1.3 Quantum differential privacy (QDP)
Quantum differential privacy (QDP) is a privacy architecture (Hirche et al. 2023) that integrates controlled quantum noise into quantum data or calculations to protect individual data points while enabling accurate learning. In quantum local DP, each client adds noise locally before delivering data or model modifications to the server. This method improves privacy by preventing the server from accessing the original data or model updates. In order to increase the reliability and robustness of quantum autonomous vehicular networks enabled by FL, Xu et al. (2023) proposed a secure FL scheme that integrates the local differential privacy (DP) and homomorphic encryption (HE). In the proposed scheme, eavesdropping attacks while roadside unit (RSU) is absent are handled by local DP.
9.1.4 Blind quantum computing (BQC)
By leveraging the security features offered by BQC protocols, the integration of ML and quantum physics could potentially unlock novel possibilities for addressing private distributed learning challenges. A BQC protocol for distributed learning is presented by Chehimi et al. (2023), which effectively harnesses the computational capabilities of remote quantum servers while ensuring the confidentiality of sensitive data. Li et al. (2021) proposed a private single-party delegated training based on BQC. The authors further expanded the protocol to SMPC with DP, which is resistant to gradient attack. The scheme offers a significant framework for investigating the security implications of quantum advantages in the domain of ML with practical implementations. Qu et al. Qu and Wang (2021) proposed a quantum secure three-party computation protocol based on BQC, which is subsequently expanded to encompass a quantum SMPC protocol. We present a few quantum privacy-preserving techniques in QFL in Table 5.
9.2 Challenges in QFL
There are several potential challenges associated with QFL, discussed as follows:
-
The performance of the models depend largely on the quality of data encoding. The quantum bit, or qubit, is the basic building element of QC. Unlike classical bits, qubits can be represented by both 0 and 1, as well as a superposition of both the states. A qubit can exhibit a linear combination of the basic states denoted as follows: \(\psi\) = \(a|0\rangle + b|1\rangle\), where a and b are the amplitudes of the basic states,such that \(|\textit{a}^2|\) + \(|\textit{b}^2 |\) = 1. Building quantum computers with sufficient qubits and maintaining their coherence is challenging task.
-
Hardware challenges include tuning of the parameterized circuit and quantum nature of the communication and computation which throw a complete different set of challenges than those in classical model. Things becomes even complicated when the system is expected to scale up (Gurung et al. 2023).
-
Ensuring interoperability between different quantum systems and classical systems is essential for the widespread adoption of QFL.
-
Establishing guidelines and frameworks for the ethical use of QFL and addressing regulatory challenges are important aspects.
10 Applications of federated learning
There are several real-life applications of FL. In this section, we briefly discuss some of the areas where significant applications based on FL can be found.
10.1 Mobile and edge devices
Since Google introduced the concept of FL, researchers have proposed various schemes (Hard et al. 2018; Leroy et al. 2019; Yang et al. 2018) to predict users input from the Gboard mobile keyboard. Afterward, FL is applied to enhance the overall quality of the keyboard-search recommendations (Yang et al. 2018). It improves the ranking of browser history suggestions while maintaining the client’s privacy (Hartmann et al. 2019). FL can also be used for emoji prediction (Ramaswamy et al. 2019), human behavior prediction (Sozinov et al. 2018) and human trajectory prediction (Feng et al. 2020). Apple uses it in iOS for several applications (Woubie and Bäckström 2021) like the QuickType keyboard and the vocal classifier. In edge/mobile computing environments, novel FL techniques (Jiang et al. 2022; Lu et al. 2020) aims for faster training by resource-limited clients.
10.2 Internet of Things (IoT)
FL is extensively utilized in the realm of the Internet of Things (IoT) (Yang et al. 2019; Pang et al. 2020; Nguyen et al. 2019). IoT devices generate enormous amounts of data, which results in new challenges for improving the quality of service through data sharing. Data owners may have security and privacy issues, like information leakage, when sharing their private data. The loss of sensitive data threatens the data owners. Any organization would suffer significant reputational and financial losses for this. Safeguarding this private data and preventing data leakage is expensive. FL can be used in IoT applications where the training of a model involves enabling the various devices to function as local learners and then transmitting the parameters of the local models to a centralized server. Hence, a large amount of dataset need not be moved to the central server, and better data privacy can be achieved. Smart city applications can derive several benefits from FL in diverse ways (Zhang et al. 2015; Imteaj et al. 2019; Wang et al. 2017; Rasha et al. 2023). Smart transportation plays a vital role in smart cities because it supplies a variety of sensory data that directly impacts smart road traffic. Various FL-based algorithms (Alam et al. 2015; Samarakoon et al. 2019; Liu et al. 2020) are used to operate autonomous vehicles in smart cities. Albaseer et al. (2020) introduced a federated edge learning method for smart cities that uses unlabeled data. Saputra et al. (2019) proposed a federated energy demand learning method that enables charging stations to send and get data without revealing the original dataset. FL currently has numerous applications in the field of industrial Internet of Things (IIoT). Edge device failures have a significant impact on IIoT industrial product manufacturing. FL methods (Zhang et al. 2020; Qian et al. 2019; Zhang et al. 2020; Liu et al. 2020; Sun et al. 2020; Liu et al. 2019; Ge et al. 2021; Zhou et al. 2021; Zhang et al. 2021; Preuveneers et al. 2018) are used for detecting various anomalies such as industrial device failures, predicting faults in the devices, and diagnosing faults if any. Nguyen et al. (2019) proposed an anomaly detection technique for IoT devices based on FL. Leroy et al. (2019) conducted research into the use of FL to crowdsource voice data in order to train a resource-constrained wake word detector.
10.3 Medical applications
FL has a promising future in the medical sector as a revolutionary technique for ensuring data privacy (Xu et al. 2021; Lee and Shin 2020; Silva et al. 2019; Li et al. 2019; Chen et al. 2020; Lim et al. 2020; Gao et al. 2019; Ali et al. 2022). Smart healthcare based on FL has empowered clinical diagnostics. It can can solve the problem of inadequate healthcare, particularly regarding rare diseases (Nguyen et al. 2022; Dinh et al. 2023; Zhou et al. 2023). It safeguards patient privacy and achieves greater medical resources at a reasonable cost (Catarinucci et al. 2015; Nguyen et al. 2022; Ali et al. 2022). The FL framework is used to acquire and analyze biomedical data without revealing sensitive patient information (Li et al. 2019; Silva et al. 2019; Sharghi et al. 2015). It can also be used for drug discovery (Xiong et al. 2020; Chen et al. 2021), rare disease identification (Li et al. 2020), cardiac attack prediction (Brisimi et al. 2018) and patient’s mortality prediction (Huang et al. 2019). Although every single medical institute may have a substantial amount of patient-related information, it may be insufficient to train their own local prediction models. The solution for eliminating the barriers and enabling investigation across healthcare institutions is to use FL. A similar kind of FL can also be applied for disease prediction (Szegedi et al. 2019). As a result of the COVID-19 epidemic, some research works (Liu et al. 2020; Ulhaq and Burmeister 2020; Rahman et al. 2020; Kumar et al. 2021; Feki et al. 2021; Qayyum et al. 2021; Yang et al. 2021; Zhang et al. 2021) investigated whether FL could improve patient diagnosis while preserving medical data privacy.
10.4 Recommender systems
Recommender systems are presently promising solutions to the problem of information overload. In order to develop a complete and deep user preference perception, recommender systems collect personal data from consumers and learn consumers behaviors. These centralized collections of data are delicate in terms of protecting individuals’ privacy, and any breach might cause severe consequences for both consumers and the companies providing the service (Bobadilla et al. 2013). When it comes to recommender system-based consumer marketplaces, customers’ primary concern is the protection of their personal information (Majeed and Lee 2020). FL research is successfully conducted in recommender systems (Malle et al. 2017; Ammad-Ud-Din et al. 2019; Jalalirad et al. 2019; Tan et al. 2020) for data security and privacy protection. Ali et al. (2021) used FL for context-aware recommender systems, which also retain a respectable accuracy level and ranking performance for recommendation while preserving privacy through FL. Qin et al. (2021) incorporated the FL paradigm into the recommender systems and introduced a privacy-preserved recommender system framework. It allows for online training and inference while maintaining user privacy and meeting legal and regulatory constraints.
10.5 Personalized FL
Personalized FL adapts a global FL model to individual clients. Individual clients usually perform better with personalized models than with global or local models. Various model aggregation techniques for personalized FL are presented in Wang et al. (2019), Hu et al. (2020), Deng et al. (2020), Mansour et al. (2020), Cho et al. (2021), Fallah et al. (2020), Dinh et al. (2020), Ding et al. (2022). However, these schemes do not allow clients to obtain personalized updates in gradient distributions from their local training data. Zhang et al. (2020) proposed a flexible framework for FL that does not restrict optimization for the distribution of local data. As an alternative to providing each client with the same weighted global model average based on local training size (McMahan et al. 2016), the authors calculate a weighted combination of the available models that most closely corresponds to the client’s interests, as determined by an assessment of a personalized target test distribution.
10.6 Other applications
Bakopoulou et al. (2019) utilized a federated architecture for mobile packet classification, which enables mobile devices to participate and train global models without releasing their initial training data. FL is also used for visual object recognition (Liu et al. 2020) and human activity recognition (Sozinov et al. 2018; Feng et al. 2020). It is also applicable in geospatial applications (Sprague et al. 2018), internet traffic classification (Mun and Lee 2020) and traffic speed forecasting (Zhang et al. 2021). FL has a wide variety of applications in several other fields, including quantum computing (Chehimi and Saad 2021), neural networks (Garg et al. 2020; Zhu et al. 2021) and natural language processing (Liu et al. 2019). FL has significant prospects in the areas of privacy-preserving crowdsourcing for localization (Ciftler et al. 2020), finance (Vatsalan et al. 2017; Liu et al. 2020), banking (Long et al. 2020) and data relevance analysis (Doku et al. 2019).
11 Comparison with other survey papers on federated learning
Several recent review works on FL are available in Li et al. (2020), Yang et al. (2019), Lyu et al. (2020), Jiang et al. (2020), Zhu et al. (2021), Zhang et al. (2021), Zhou et al. (2021), Nguyen et al. (2022), Xia et al. (2021), Li et al. (2021), Mothukuri et al. (2021), Xu et al. (2021), Ali et al. (2022), Abreha et al. (2022), Li et al. (2022), Agrawal et al. (2022), Banabilah et al. (2022), Majeed et al. (2022), Rodríguez-Barroso et al. (2023), Vucinich and Zhu (2023), Shi et al. (2023). Table 7 summarizes the studies conducted in some of these research papers. Almost all these research works discussed a comprehensive introduction to FL. However, they did not include all other relevant topics, such as the categorization of FL, various challenges associated with FL, potential risks to its privacy and security with possible attacks and defenses, and various applications of FL. The studies presented in Li et al. (2020), Zhou et al. (2021), Ali et al. (2022), Xia et al. (2021), Li et al. (2022), Agrawal et al. (2022), Mothukuri et al. (2021) do not include the categorization of FL. Though Yang et al. (2019), Lyu et al. (2020), and Li et al. (2021) discussed the categorization of FL, the various challenges associated with FL are not included in their review works. Agrawal et al. (2022) provided a comprehensive review of FL for intrusion detection systems; however, the review lacks discussion on research challenges. Shi et al. (2023) emphasized on fairness in FL and proposed several fairness metrics. Nevertheless, the study has limited exploration of security challenges in FL. Rodríguez-Barroso et al. (2023) presented a detail review precisely on the threats in FL and the defense mechanisms. However, the other research challenges on FL remain unaddressed. Also, the categorization and application areas in FL are not discussed in the survey. The surveys on FL presented by Ali et al. (2022), Xia et al. (2021), Abreha et al. (2022), Li et al. (2021), and Mothukuri et al. (2021) discuss the potential risks to FL’s privacy and security, along with the various attacks and defenses. On the other hand, the review works in Zhu et al. (2021), Zhou et al. (2021), Zhang et al. (2021), Banabilah et al. (2022) have limited discussions on various types of attacks on FL and the privacy-preservation techniques. Nguyen et al. (2022) discussed the opportunities of FL and focused on data privacy issues in the smart healthcare field. Jiang et al. (2020) elucidated the challenges, opportunities, and applications of FL in IoT. Li et al. (2020) and Lyu et al. (2020) presented comprehensive discussions of various attacks on FL. However, these studies do not include how these attacks can be prevented. Though Vucinich and Zhu (2023) conducted a vivid analysis of fairness in FL, the discussion of feasible solutions of attacks in FL is much confined to differential privacy only. The studies carried out in Lyu et al. (2020), Zhu et al. (2021), Mothukuri et al. (2021) do not cover the applications of FL. Some specific applications of FL are highlighted in Zhang et al. (2021), Jiang et al. (2020), Zhou et al. (2021), Nguyen et al. (2022), Ali et al. (2022), Xia et al. (2021), Abreha et al. (2022), Li et al. (2022), Majeed et al. (2022), Li et al. (2021). Majeed et al. (2022) discussed the technical applications of FL in COVID-19, identified potential challenges in FL and summarized certain open research questions. The limitation of the survey is that the security concerns remains unaddressed. Xu et al. (2021) discussed the general solutions to the research challenges in FL. The authors highlighted the potential consequences and implications of these solutions within the healthcare industry. Moreover, most of the other survey papers have not included the quantum federated learning (QFL), which is very dynamic and ongoing research trend now-a-days. We have included QFL in our paper, as an active area of research, in Sect. 9.
The aforementioned survey works do not encompass the entirety of FL. This incompleteness motivated us to present a comprehensive survey on FL that covers most of the essential aspects related to it. We emphasize a comprehensive literature review of FL, including categorization of FL, challenges associated with FL, different possible attacks on FL with privacy-preservation techniques, and lastly, a variety of applications of FL.
12 Summary of learnt lessons and opportunities for future research
FL is an emerging field of privacy-preservation schemes using AI and ML. It offers several advantages that make it an excellent solution for privacy-preserving and decentralized ML collaborations. It is broadly classified into three categories: horizontal FL, vertical FL, and federated transfer learning. However, it is a relatively newer field of research, and owing to its decentralized nature, there are a number of obstacles that need to be overcome, such as scalability, security, and regulatory compliance. The challenges associated with communication rounds, customization, absence of labels, resilience, continuity, etc. are studied briefly. This is especially true from an algorithmic point of view. In addition, the issues of resource limitations at the edge nodes, advanced security, and privacy are broadly open topics from the perspective of system architecture. Maintaining the integrity and confidentiality of the learned weights in each learning iteration in FL imposes a security challenge. Several cryptography paradigms are laid forward to mitigate the security challenges of honest but curious clients, malicious clients, dishonest servers, etc. However, existing security schemes fail to meet all the security requirements of a robust system, as discussed below:
-
1.
Several studies (Bonawitz et al. 2017; Truex et al. 2019; Zhu et al. 2020) are based on Secure Multi-party Computation (SMPC) and promise a higher level of security standard. However, the cost of communication hinders their application in industries. Most of the edge nodes are battery-operated and low-powered, and the cost of establishing such a security framework surpasses the capacity of a resource-constrained network.
-
2.
Recent approaches made in the direction of Homomorphic Encryption (HE) can be found in Zhang et al. (2020), Asad et al. (2020), Zhang et al. (2020), Hardy et al. (2017), Liu et al. (2020), Ilias and Georgios (2019), Hao et al. (2019), Aono et al. (2017). Additive and multiplicative HE enable secure transmission of gradients to the server to execute global averaging on the encrypted gradient itself. The algorithmic complexity makes it substantially difficult to design and carry out the decryption procedure. It has high latency, computational, and communication overheads. Notwithstanding these problems, it still continues to be a great defense strategy in FL as it does not compromise much on the accuracy of the models.
-
3.
Secret Sharing (SS)-based FL methods are described in Bonawitz et al. (2017), Xu et al. (2019), Guo et al. (2020). SS-based FL systems have a few drawbacks, including increased complexity and decreased accuracy. Nonetheless, it is still a productive topic of research, and ongoing efforts are being made to improve the efficiency and scalability of SS-based FL.
-
4.
Perturbation-based methods add a substantial amount of noise to training data, which deteriorates the quality of data used for training purposes. Several studies (McMahan et al. 2017a; Geyer et al. 2017; Wei et al. 2020; Naseri et al. 2020; Bhowmick et al. 2018; Li et al. 2019c) have investigated the use of differential privacy (DP) in FL. Some studies analyzed the importance of hiding the participation information of clients, while others worked on optimizing the noise. However, with respect to the high-dimensional local gradients, excessive noise injection is an inevitable problem. Most of the datasets that researchers considered are of low dimension and do not simulate a real-life scenario where the dimension of real data is not known before hand. Approximation-based theoretical analysis may fail to achieve desirable performance in practice.
-
5.
Anonymization-based methods remove personally identifiable information from training data to maintain the anonymity of data. Studies (Choudhury et al. 2020; Hao et al. 2022; Ghahramani and Griffiths 2005; Orekondy et al. 2018) related to this technique demonstrate the superiority of this technique over perturbation-based methods. Anonymization-based methods do not compromise the integrity of data; however, they result in less accuracy and do not maintain data relationships.
-
6.
Quantum Federated Learning (QFL): The advent of super-fast quantum computers poses a severe threat to classical cryptography schemes. Post-quantum cryptographic techniques can be integrated into the FL system (Ren et al. 2023) to ensure the continuous security of communication and data. Since quantum procedures are difficult to comprehend and put into practice, they need the use of specialized hardware, which contributes to their level of sophistication. Local QFL model training involves applying quantum gates and circuits, leading to significant noise generation, especially on Noisy Intermediate-Scale Quantum (NISQ) devices (Preskill 2018). Aggregation of noisy parameters at the QFL server may obscure useful information, causing extended training periods and performance degradation. Small-scale local QML models on NISQ devices limit the analysis of high-dimensional data, hindering the potential benefits of QFL. Transmitting classical learning parameters in QML models over classical networks exposes vulnerabilities to conventional FL attacks. Quantum-specific features, such as quantum superposition, may be exploited, leading to privacy and security concerns in QFL deployments. However, continuous research is carried out to prioritize the development of scalable QFL algorithms and protocols. Investigation of advanced Quantum Error Correction (QEC) techniques and exploration of quantum-inspired classical approaches like tensor networks for data compression are now demanding research areas.
-
7.
It also incorporates quantum-based secure protocols, such as secure multi-party quantum computation and quantum differential privacy, to enhance client privacy and investigate techniques like Blind Quantum Computing (BQC) and Quantum Key Distribution (QKD) for securing QFL deployments over classical networks (Huang et al. 2022; Chehimi et al. 2023; Yamany et al. 2021). The vivid applications of FL in different spheres like in edge computing (Hard et al. 2018; Leroy et al. 2019; Yang et al. 2018; Hartmann et al. 2019; Feng et al. 2020; Woubie and Bäckström 2021; Jiang et al. 2022; Lu et al. 2020), medical sector (Xu et al. 2021; Lee and Shin 2020; Silva et al. 2019; Li et al. 2019; Chen et al. 2020; Lim et al. 2020; Gao et al. 2019; Ali et al. 2022), IoT (Zhang et al. 2015; Imteaj et al. 2019; Wang et al. 2017; Rasha et al. 2023), recommendation systems (Malle et al. 2017; Ammad-Ud-Din et al. 2019; Jalalirad et al. 2019; Tan et al. 2020) and miscellaneous applications including but not limited to smart transportation, trading, drug discovery, social networking, advertisement, computer vision and NLP.
Future FL research directions are diverse and can necessitate collaborative efforts involving diverse computer science research fields, as mentioned below:
-
1.
FL offers several advantages that make it an excellent solution for privacy-preserving and decentralized ML collaborations. However, it is a relatively new field of research, and there are a number of obstacles that need to be overcome, such as scalability, security, and regulatory compliance.
-
2.
In FL, the challenges associated with communication rounds, customization, absence of labels, resilience, continuity, etc. are not studied in very detail. This is especially true from an algorithmic point of view. In addition, the issues of resource limitations at the edge nodes, security, and privacy are broadly open topics from the perspective of system architecture.
-
3.
Due to the noise that the sharing process introduces, SS-based FL systems have a few drawbacks, including increased complexity and decreased accuracy. Nonetheless, it is still a productive topic of research, and ongoing efforts are being made to improve the efficiency and scalability of SS-based FL.
-
4.
Sometimes classical encryption-based methods fail to meet the standard security requirements due to the advent of quantum computers. However, it is interesting to witness the advances in the integration of classical and quantum methods. Taking into account the challenges prevailing in quantum schemes, it is a valid open research question if the classical methods can be improved by integrating them with quantum techniques.
-
5.
QFL is an emerging field that necessitates proficiency across various academic domains. It brings together the concepts of QC and FL, with the intention of utilizing quantum technology to improve the learning process in terms of privacy, security, and overall effectiveness.
-
6.
Privacy-preservation in QFL is an open opportunity for research in the field of FL. Primary goal with Privacy-preserving QFL is to create Quantum FL methods that are highly resilient and safe from threats like adversarial attacks, quantum attacks, and unauthorized access. While using quantum-secured mechanisms for the FL process, the major focus is to guarantee the confidentiality of the data and the integrity of the model.
-
7.
The cost of implementing post-quantum security methods is significantly higher than that of classical computers. Deploying it on edge-level devices is a significant challenge considering the current cost. It is important to investigate methods that could potentially answer if the cost can be lowered by employing technologies in the coming years to make them applicable at the industry level.
-
8.
Quantum techniques are highly probabilistic. The growth rate of research in this area paves the way to a world where quantum technology will completely dominate over classical mechanisms in the future. However, it’s a debatable question that calls for scientific research.
-
9.
The scalability of QFL when applied to low-powered edge devices, considering the current implementation and cost-associated challenges, is still doubtful. The parameters for determining the threshold for the trade-off between cost and scalability are not properly defined.
-
10.
It is expected that IoT devices will be in the billions by 2030, however, it requires constant effort from the researchers to make the statement hold good for quantum-safe IoT devices.
It would be a great adventure to answer these questions through further scientific research and experiments.
13 Conclusion
Federated Learning (FL) is a machine learning technique that facilitates multiple devices or participants to cooperatively train an ML model without sharing their data with others. Instead, each participant trains the model using data that is local to them, and only the model updates are sent to the centralized server. The server compiles all of the individual models it receives into one global model. This paper presents a concise survey of the existing literature on FL. We have presented a comprehensive review of the essential topics by providing a clear and precise introduction to the concept of FL, its architectural and framework aspects, the categorization of FL, the research challenges associated with FL, the classification of major attacks on FL, the techniques employed for privacy preservation in FL, and lastly, the various applications of FL. According to a number of studies, the use of SS as an effective strategy may aid in the development of safe and efficient FL frameworks. Nevertheless, the discipline of FL is still at its nascent stage of development, exhibiting potential for growth and serving as a promising avenue for future research endeavors. In order to alleviate some challenges posed by the federated system, it is important to rectify certain vulnerabilities within the security system. Our objective is to develop security schemes in the future to safeguard FL against a wide range of attacks.
We limit the scope of our discussion to the detailed and systematic review of security protocols put forth by various researchers in the field of secret sharing-based secure and privacy-preserving FL. For the sake of completion, we briefly discussed the schemes based on differential privacy, secure multi-party computation, and homomorphic encryption. The various other issues pertaining to delay, heterogeneity, fairness, resource constraint, etc. are also defined and presented at a satisfactory depth for readers to acquaint themselves with the current state of research that is being carried out in this realm. We do not confine this review work to any specific application of interest.
Notes
Figures are indicative and may differ by 5–6 in count.
References
Abreha HG, Hayajneh M, Serhani MA (2022) Federated learning in edge computing: a systematic survey. Sensors 22(2):450
Agrawal S, Sarkar S, Aouedi O, Yenduri G, Piamrat K, Alazab M, Bhattacharya S, Maddikunta PKR, Gadekallu TR (2022) Federated learning for intrusion detection system: concepts, challenges and future directions, Comput Commun
Alam KM, Saini M, El Saddik A (2015) Toward social internet of vehicles: concept, architecture, and applications. IEEE access 3:343–357
Albaseer A, Ciftler BS, Abdallah M, Al-Fuqaha A (2020) Exploiting unlabeled data in smart cities using federated edge learning. Int Wirel Commun Mob Comput IEEE 2020:1666–1671
Ali W, Kumar R, Deng Z, Wang Y, Shao J (2021) A federated learning approach for privacy protection in context-aware recommender systems. Comput J 64(7):1016–1027
Ali M, Naeem F, Tariq M, Kaddoum G (2022) Federated learning for privacy preservation in smart healthcare systems: acomprehensive survey. arXiv:2203.09702
Ammad-Ud-Din M, Ivannikova E, Khan SA, Oyomno W, Fu Q, Tan KE, Flanagan A (2019) Federated collaborative filtering for privacy-preserving personalized recommendation system. arXiv:1901.09888
Aono Y, Hayashi T, Wang L, Moriai S et al (2017) Privacy-preserving deep learning via additively homomorphic encryption. IEEE Trans Inf Forensics Secur 13(5):1333–1345
Asad M, Moustafa A, Ito T (2020) Fedopt: Towards communication efficiency and privacy preservation in federated learning. Appl Sci 10(8):2864
Asmuth C, Bloom J (1983) A modular approach to key safeguarding. IEEE Trans Inf Theory 29(2):208–210
Awan S, Li F, Luo B, Liu M (2019) Poster: A reliable and accountable privacy-preserving federated learning framework using the blockchain, in: Proceedings of the 2019 ACM SIGSAC Conference on Computer and Communications Security, pp 2561–2563
Bagdasaryan E, Veit A, Hua Y, Estrin D, Shmatikov V (2020) How to backdoor federated learning, in: International Conference on Artificial Intelligence and Statistics, PMLR, pp 2938–2948
Bakopoulou E, Tillman B, Markopoulou A (2019) A federated learning approach for mobile packet classification. arXiv:1907.13113
Banabilah S, Aloqaily M, Alsayed E, Malik N, Jararweh Y (2022) Federated learning review: Fundamentals, enabling technologies, and future applications. Information processing & management 59(6):103061
Bao X, Su C, Xiong Y, Huang W, Hu Y (2019) Flchain: A blockchain for auditable federated learning with trust and incentive, in: 2019 5th International Conference on Big Data Computing and Communications (BIGCOM), IEEE, pp 151–159
Beguier C, Tramel EW (2020) Safer: Sparse secure aggregation for federated learning. arXiv:2007.14861
Bell JH, Bonawitz KA, Gascón A, Lepoint T, Raykova M (2020) Secure single-server aggregation with (poly) logarithmic overhead, in: Proceedings of the 2020 ACM SIGSAC Conference on Computer and Communications Security, pp 1253–1269
Bhagoji AN, Chakraborty S, Mittal P, Calo S (2019) Analyzing federated learning through an adversarial lens, in: International Conference on Machine Learning, PMLR, pp 634–643
Bhowmick A, Duchi J, Freudiger J, Kapoor G, Rogers R (2018) Protection against reconstruction and its applications in private federated learning. arXiv:1812.00984
Blakley GR, Safeguarding cryptographic keys, in, (1979) International Workshop on Managing Requirements Knowledge (MARK). IEEE 1979:313–318
Bobadilla J, Ortega F, Hernando A, Gutiérrez A (2013) Recommender systems survey. Knowledge-based systems 46:109–132
Bonawitz K, Eichner H, Grieskamp W, Huba D, Ingerman A, Ivanov V, Kiddon C (2019) J. Konečnỳ, S. Mazzocchi, H. B. McMahan, et al., Towards federated learning at scale: System design. arXiv:1902.01046
Bonawitz K, Ivanov V, Kreuter B, Marcedone A, McMahan HB, Patel S, Ramage D, Segal A, Seth K (2017) Practical secure aggregation for privacy-preserving machine learning, in: proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security, pp 1175–1191
Brisimi TS, Chen R, Mela T, Olshevsky A, Paschalidis IC, Shi W (2018) Federated learning of predictive models from federated electronic health records. Int J Med Informatics 112:59–67
Caldas S, Konečny J, McMahan HB, Talwalkar A (2018) Expanding the reach of federated learning by reducing client resource requirements. arXiv:1812.07210
Cao H, Liu S, Zhao R, Xiong X (2020) Ifed: A novel federated learning framework for local differential privacy in power internet of things. Int J Distrib Sens Netw 16(5):1550147720919698
Catarinucci L, De Donno D, Mainetti L, Palano L, Patrono L, Stefanizzi ML, Tarricone L (2015) An iot-aware architecture for smart healthcare systems. IEEE Internet Things J 2(6):515–526
Chai H, Leng S, Chen Y, Zhang K (2020) A hierarchical blockchain-enabled federated learning algorithm for knowledge sharing in internet of vehicles. IEEE Trans Intell Transp Syst 22(7):3975–3986
Chamikara MAP, Bertok P, Khalil I, Liu D, Camtepe S (2021) Privacy preserving distributed machine learning with federated learning. Comput Commun 171:112–125
Chattopadhyay AK, Maitra P, Saha HN, Nag A, A verifiable multi-secret sharing scheme with elliptic curve cryptography, in, (2018) IEEE 9th Annual Information Technology, Electronics and Mobile Communication Conference (IEMCON). IEEE 2018:1374–1379
Chehimi M, Chen SY-C, Saad W, Towsley D, Debbah M (2023) Foundations of quantum federated learning over classical and quantum networks, IEEE Network
Chehimi M, Saad W (2021) Quantum federated learning with quantum data. arXiv:2106.00005
Chen SY-C, Yoo S (2021) Federated quantum machine learning. Entropy 23(4):460
Chen Y, Qin X, Wang J, Yu C, Gao W (2020) Fedhealth: A federated transfer learning framework for wearable healthcare. IEEE Intell Syst 35(4):83–93
Chen S, Xue D, Chuai G, Yang Q, Liu Q (2021) Fl-qsar: a federated learning-based qsar prototype for collaborative drug discovery. Bioinformatics 36(22–23):5492–5498
Cheng K, Fan T, Jin Y, Liu Y, Chen T, Papadopoulos D, Yang Q (2021) Secureboost: A lossless federated learning framework. IEEE Intell Syst 36(6):87–98
Chen F, Luo M, Dong Z, Li Z, He X (2018) Federated meta-learning with fast convergence and efficient communication. arXiv:1802.07876
Chen H, Zhu T, Zhang T, Zhou W, Yu PS (2023) Privacy and fairness in federated learning: on the perspective of trade-off, ACM Computing Surveys
Cho YJ, Wang J, Chiruvolu T, Joshi G (2021) Personalized federated learning for heterogeneous clients with clustered knowledge transfer. arXiv:2109.08119
Choi B, Sohn J-y, Han D-J, Moon J (2020) Communication-computation efficient secure aggregation for federated learning. arXiv:2012.05433
Choquette-Choo CA, Dullerud N, Dziedzic A, Zhang Y, Jha S, Papernot N, Wang X (2021) Capc learning: Confidential and private collaborative learning. arXiv:2102.05188
Choudhury O, Gkoulalas-Divanis A, Salonidis T, Sylla I, Park Y, Hsu G, Das A (2020) A syntactic approach for privacy-preserving federated learning, in: ECAI 2020, IOS Press, pp 1762–1769
Choudhury O, Gkoulalas-Divanis A, Salonidis T, Sylla I, Park Y, Hsu G, Das A (2020) Anonymizing data for privacy-preserving federated learning. arXiv:2002.09096
Ciftler BS, Albaseer A, Lasla N, Abdallah M (2020) Federated learning for localization: A privacy-preserving crowdsourcing method. arXiv:2001.01911
Dehkordi MH, Mashhadi S (2008) Verifiable secret sharing schemes based on non-homogeneous linear recursions and elliptic curves. Comput Commun 31(9):1777–1784
Deng Y, Kamani MM, Mahdavi M (2020) Adaptive personalized federated learning. arXiv:2003.13461
Deshmukh M, Nain N, Ahmed M (2018) Efficient and secure multi secret sharing schemes based on Boolean XOR and arithmetic modulo. Multimedia Tools and Applications 77(1):89–107
Ding J, Tramel E, Sahu AK, Wu S, Avestimehr S, Zhang T (2022) Federated learning challenges and opportunities: An outlook. ICASSP 2022–2022 IEEE International Conference on Acoustics. Speech and Signal Processing (ICASSP), IEEE, pp 8752–8756
Dinh C N, Quoc-Viet P, Pathirana PN, Ming D, Seneviratne A, Zihuai L, Dobre O, Won-Joo H, et al (2023) Federated learning for smart healthcare: A survey, ACM Computing Surveys. 1937–01
Dinh CT, Tran N, Nguyen J (2020) Personalized federated learning with moreau envelopes. Adv Neural Inf Process Syst 33:21394–21405
Doku R, Rawat DB, Liu C (2019) Towards federated learning approach to determine data relevance in big data, in: 2019 IEEE 20th International Conference on Information Reuse and Integration for Data Science (IRI), IEEE, pp 184–192
Dong Y, Chen X, Shen L, Wang D (2020) Eastfly: Efficient and secure ternary federated learning. Computers & Security 94:101824
Dong Y, Chen X, Shen L, Wang D (2019) Privacy-preserving distributed machine learning based on secret sharing, in: Information and Communications Security: 21st International Conference, ICICS 2019, Beijing, China, December 15–17, Revised Selected Papers 21, Springer, 2020, pp 684–702
Dulek Y, Grilo AB, Jeffery S, Majenz C, Schaffner C (2020) Secure multi-party quantum computation with a dishonest majority, in: Annual International Conference on the Theory and Applications of Cryptographic Techniques, Springer, pp 729–758
Eichner H, Koren T, McMahan B, Srebro N, Talwar K (2019) Semi-cyclic stochastic gradient descent, in: International Conference on Machine Learning, PMLR, pp 1764–1773
Endurthi A, Tentu AN, Venkaiah VC (2014) Reusable multi-stage multi-secret sharing scheme based on Asmuth-Bloom sequence. International Journal of Computer Applications 975:8887
Fallah A, Mokhtari A, Ozdaglar A (2020) Personalized federated learning with theoretical guarantees: A model-agnostic meta-learning approach. Adv Neural Inf Process Syst 33:3557–3568
Feki I, Ammar S, Kessentini Y, Muhammad K (2021) Federated learning for covid-19 screening from chest x-ray images. Appl Soft Comput 106:107330
Feng J, Rong C, Sun F, Guo D, Li Y (2020) Pmf: A privacy-preserving human mobility prediction framework via federated learning. Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies 4(1):1–21
Feng Y, Yang X, Fang W, Xia S-T, Tang X (2020) Practical and bilateral privacy-preserving federated learning. arXiv:2002.09843
Fitzsimons JF (2017) Private quantum computation: an introduction to blind quantum computing and related protocols, npj Quantum Information 3 (1), 23
Fung C, Yoon CJ, Beschastnikh I (2018) Mitigating sybils in federated learning poisoning. arXiv:1808.04866
Gao D, Ju C, Wei X, Liu Y, Chen T, Yang Q (2019) Hhhfl: Hierarchical heterogeneous horizontal federated learning for electroencephalography. arXiv:1909.05784
Gao D, Liu Y, Huang A, Ju C, Yu H, Yang Q (2019) Privacy-preserving heterogeneous federated transfer learning, in: 2019 IEEE International Conference on Big Data (Big Data), IEEE, pp 2552–2559
Garg A, Saha AK, Dutta D (2020) Direct federated neural architecture search. arXiv:2010.06223
Ge N, Li G, Zhang L, Liu Y (2021) Failure prediction in production line based on federated learning: An empirical study, Journal of Intelligent Manufacturing. 1–18
Geyer RC, Klein T, Nabi M (2017) Differentially private federated learning: A client level perspective. arXiv:1712.07557
Ghahramani Z, Griffiths T (2005) Infinite latent feature models and the indian buffet process, Advances in neural information processing systems 18
Goetz J, Malik K, Bui D, Moon S, Liu H, Kumar A (2019) Active federated learning. arXiv:1909.12641
Gu T, Dolan-Gavitt B, Garg S (2017) Badnets: Identifying vulnerabilities in the machine learning model supply chain. arXiv:1708.06733
Guo X, Liu Z, Li J, Gao J, Hou B, Dong C, Baker T (2020) V eri fl: Communication-efficient and fast verifiable aggregation for federated learning. IEEE Trans Inf Forensics Secur 16:1736–1751
Gurung D, Pokhrel SR, Li G (2023) Quantum federated learning: Analysis, design and implementation challenges. arXiv:2306.15708
Han Y, Zhang X (2020) Robust federated learning via collaborative machine teaching. Proceedings of the AAAI Conference on Artificial Intelligence 34:4075–4082
Han G, Zhang T, Zhang Y, Xu G, Sun J, Cao J (2022) Verifiable and privacy preserving federated learning without fully trusted centers, Journal of Ambient Intelligence and Humanized Computing. 1–11
Hao M, Li H, Luo X, Xu G, Yang H, Liu S (2019) Efficient and privacy-enhanced federated learning for industrial artificial intelligence. IEEE Trans Industr Inf 16(10):6532–6542
Hao W, Mehta N, Liang KJ, Cheng P, El-Khamy M, Carin L (2022) Waffle: Weight anonymized factorization for federated learning. IEEE Access 10:49207–49218
Hao M, Li H, Xu G, Liu S, Yang H (2019) Towards efficient and privacy-preserving federated deep learning, in: ICC 2019-2019 IEEE international conference on communications (ICC), IEEE, pp 1–6
Hard A, Rao K, Mathews R, Ramaswamy S, Beaufays F, Augenstein S, Eichner H, Kiddon C, Ramage D (2018) Federated learning for mobile keyboard prediction. arXiv:1811.03604
Hardy S, Henecka W, Ivey-Law H, Nock R, Patrini G, Smith G, Thorne B (2017) Private federated learning on vertically partitioned data via entity resolution and additively homomorphic encryption. arXiv:1711.10677
Hartmann F, Suh S, Komarzewski A, Smith TD, Segall I (2019) Federated learning for ranking browser history suggestions. arXiv:1911.11807
He J, Dawson E (1995) Multisecret-sharing scheme based on one-way function. Electron Lett 31(2):93–95
Hieu NQ, Anh TT, Luong NC, Niyato D, Kim DI, Elmroth E (2020) Resource management for blockchain-enabled federated learning: A deep reinforcement learning approach. arXiv:2004.04104
Hineman A, Blaum M (2022) A modified shamir secret sharing scheme with efficient encoding. IEEE Commun Lett 26(4):758–762
Hirche C, Rouzé C, França DS (2023) Quantum differential privacy: An information theory perspective, IEEE Transactions on Information Theory
Hu C, Liao X, Cheng X (2012) Verifiable multi-secret sharing based on LFSR sequences. Theoret Comput Sci 445:52–62
Hu R, Guo Y, Li H, Pei Q, Gong Y (2020) Personalized federated learning with differential privacy. IEEE Internet Things J 7(10):9530–9539
Huang L, Shea AL, Qian H, Masurkar A, Deng H, Liu D (2019) Patient clustering improves efficiency of federated machine learning to predict mortality and hospital stay time using distributed electronic medical records. J Biomed Inform 99:103291
Huang L, Yin Y, Fu Z, Zhang S, Deng H, Liu D (2020) Loadaboost: Loss-based adaboost federated machine learning with reduced computational complexity on iid and non-iid intensive care data. PLoS ONE 15(4):e0230706
Huang W, Li T, Wang D, Du S, Zhang J, Huang T (2022) Fairness and accuracy in horizontal federated learning. Inf Sci 589:170–185
Huang R, Tan X, Xu Q (2022) Quantum federated learning with decentralized data, IEEE Journal of Selected Topics in Quantum Electronics 28 (4: Mach. Learn. in Photon. Commun. and Meas. Syst.) 1–10
Ilias C, Georgios S (2019) Machine learning for all: A more robust federated learning framework, in: Proc. 5th Int. Conf. Inf. Syst. Secur. Privacy, pp 544–551
Imteaj A, Amini MH, Distributed sensing using smart end-user devices: Pathway to federated learning for autonomous iot, in, (2019) International conference on computational science and computational intelligence (CSCI). IEEE 2019:1156–1161
Jalalirad A, Scavuzzo M, Capota C, Sprague M (2019) A simple and efficient federated recommender system, in: Proceedings of the 6th IEEE/ACM International Conference on Big Data Computing, Applications and Technologies, pp 53–58
Jeong E, Oh S, Kim H, Park J, Bennis M, Kim SL (2018) Communication-efficient on-device machine learning: Federated distillation and augmentation under non-iid private data. arXiv:1811.11479
Jiang JC, Kantarci B, Oktug S, Soyata T (2020) Federated learning in smart city sensing: Challenges and opportunities. Sensors 20(21):6230
Jiang C, Xu C, Zhang Y (2021) Pflm: Privacy-preserving federated learning with membership proof. Inf Sci 576:288–311
Jiang Y, Wang S, Valls V, Ko BJ, Lee W-H, Leung KK, Tassiulas L (2022) Model pruning enables efficient federated learning on edge devices, IEEE Transactions on Neural Networks and Learning Systems
Jiang P, Ying L (2020) An optimal stopping approach for iterative training in federated learning, in: 2020 54th Annual Conference on Information Sciences and Systems (CISS), IEEE, pp 1–6
Kadhe S, Rajaraman N, Koyluoglu OO, Ramchandran K (2020) Fastsecagg: Scalable secure aggregation for privacy-preserving federated learning. arXiv:2009.11248
Kairouz P, McMahan HB, Avent B, Bellet A, Bennis M, Bhagoji AN, Bonawitz K, Charles Z, Cormode G, Cummings R, et al (2021) Advances and open problems in federated learning, Foundations and Trends® in Machine Learning 14 (1–2), 1–210
Kandar S, Dhara BC (2020) A verifiable secret sharing scheme with combiner verification and cheater identification. Journal of Information Security and Applications 51:102430
Kang Y, Liu Y, Niu B, Tong X, Zhang L, Wang W (2020) Input perturbation: A new paradigm between central and local differential privacy. arXiv:2002.08570
Kang J, Xiong Z, Niyato D, Yu H, Liang Y-C, Kim DI, Incentive design for efficient federated learning in mobile networks: A contract theory approach, in, (2019) IEEE VTS Asia Pacific Wireless Communications Symposium (APWCS). IEEE 2019:1–5
Kim YJ, Hong CS (2019) Blockchain-based node-aware dynamic weighting methods for improving federated learning performance, in: 2019 20th Asia-Pacific Network Operations and Management Symposium (APNOMS), IEEE, 2019, pp 1–4
Kim H, Park J, Bennis M, Kim S-L (2019) Blockchained on-device federated learning. IEEE Commun Lett 24(6):1279–1283
Konečnỳ J, McMahan HB, Yu FX, Richtárik P, Suresh AT, Bacon D (2016) Federated learning: Strategies for improving communication efficiency. arXiv:1610.05492
Kumar R, Khan AA, Kumar J, Golilarz NA, Zhang S, Ting Y, Zheng C, Wang W et al (2021) Blockchain-federated-learning and deep learning models for covid-19 detection using ct imaging. IEEE Sens J 21(14):16301–16314
Lee GH, Shin S-Y (2020) Federated learning on clinical benchmark data: Performance assessment. J Med Internet Res 22(10):e20891
Leroy D, Coucke A, Lavril T, Gisselbrecht T, Dureau J (2019) rated learning for keyword spotting. ICASSP 2019–2019 IEEE International Conference on Acoustics. Speech and Signal Processing (ICASSP), IEEE, pp 6341–6345
Li H-X, Cheng C-T, Pang L-J (2005) An improved multi-stage (t, n)-threshold secret sharing scheme, in: International Conference on Web-Age Information Management, Springer, pp 267–274
Li X, Gu Y, Dvornek N, Staib LH, Ventola P, Duncan JS (2020) Multi-site fmri analysis using privacy-preserving federated learning and domain adaptation: Abide results. Med Image Anal 65:101765
Li L, Fan Y, Tse M, Lin K-Y (2020) A review of applications in federated learning. Computers & Industrial Engineering 149:106854
Li T, Sahu AK, Zaheer M, Sanjabi M, Talwalkar A, Smith V (2020) Federated optimization in heterogeneous networks. Proceedings of Machine learning and systems 2:429–450
Li W, Lu S, Deng D-L (2021) Quantum federated learning through blind quantum computing. Science China Physics. Mechanics & Astronomy 64(10):100312
Li L, Wang Y, Lin K-Y (2021) Preventive maintenance scheduling optimization based on opportunistic production-maintenance synchronization. J Intell Manuf 32(2):545–558
Li D, Han D, Weng T-H, Zheng Z, Li H, Liu H, Castiglione A, Li K-C (2022) Blockchain for federated learning toward secure distributed machine learning systems: a systemic survey. Soft Comput 26(9):4423–4440
Li X, Zhao S, Chen C, Zheng Z (2023) Heterogeneity-aware fair federated learning. Inf Sci 619:968–986
Li X, Huang K, Yang W, Wang S, Zhang Z (2019) On the convergence of fedavg on non-iid data. arXiv:1907.02189
Li J, Khodak M, Caldas S, Talwalkar A (2019) Differentially-private gradient-based meta-learning, J. Technical Report
Lim WYB, Garg S, Xiong Z, Niyato D, Leung C, Miao C, Guizani M (2020) Dynamic contract design for federated learning in smart healthcare applications. IEEE Internet Things J 8(23):16853–16862
Li W, Milletarì F, Xu D, Rieke N, Hancox J, Zhu W, Baust M, Cheng Y, Ourselin S, Cardoso MJ, et al (2019) Privacy-preserving federated brain tumour segmentation, in: International workshop on machine learning in medical imaging, Springer, pp 133–141
Li T, Sanjabi M, Beirami A, Smith V (2019) Fair resource allocation in federated learning. arXiv:1905.10497
Liu Y, James J, Kang J, Niyato D, Zhang S (2020) Privacy-preserving traffic flow prediction: A federated learning approach. IEEE Internet Things J 7(8):7751–7763
Liu Y, Garg S, Nie J, Zhang Y, Xiong Z, Kang J, Hossain MS (2020) Deep anomaly detection for time-series data in industrial iot: A communication-efficient on-device federated learning approach. IEEE Internet Things J 8(8):6348–6358
Liu Y, Huang A, Luo Y, Huang H, Liu Y, Chen Y, Feng L, Chen T, Yu H, Yang Q (2020) Fedvision: An online visual object detection platform powered by federated learning. Proceedings of the AAAI Conference on Artificial Intelligence 34:13172–13179
Liu Y, Kang Y, Xing C, Chen T, Yang Q (2020) A secure federated transfer learning framework. IEEE Intell Syst 35(4):70–82
Liu Y, Ma Z, Yan Z, Wang Z, Liu X, Ma J (2020) Privacy-preserving federated k-means for proactive caching in next generation cellular networks. Inf Sci 521:14–31
Liu P, Xu X, Wang W (2022) Threats, attacks and defenses to federated learning: issues, taxonomy and perspectives. Cybersecurity 5(1):1–19
Liu Y, Ai Z, Sun S, Zhang S, Liu Z, Yu H (2020) Fedcoin: A peer-to-peer payment system for federated learning, in: Federated Learning, Springer, pp 125–138
Liu D, Dligach D, Miller T (2019) Two-stage federated phenotyping and patient representation learning, in: Proceedings of the conference. Association for Computational Linguistics. Meeting, Vol. 2019, NIH Public Access, p. 283
Liu C, Fan Z, Zhou Z, Shi Y, Pei J, Chu L, Zhang Y (2021) Achieving model fairness in vertical federated learning. arXiv:2109.08344
Liu B, Wang L, Liu M, Xu C-Z (2019) Federated imitation learning: A privacy considered imitation learning framework for cloud robotic systems with heterogeneous sensor data. arXiv:1909.00895
Liu B, Yan B, Zhou Y, Yang Y, Zhang Y (2020) Experiments of federated learning for covid-19 chest x-ray images. arXiv:2007.05592
Li Q, Wen Z, Wu Z, Hu S, Wang N, Li Y, Liu X, He B (2021) A survey on federated learning systems: vision, hype and reality for data privacy and protection, IEEE Transactions on Knowledge and Data Engineering
Li R, Xiao Y, Zhang C, Song T, Hu C (2018) Cryptographic algorithms for privacy-preserving online applications., Math. Found. Comput. 1 (4), 311–330
Long G, Tan Y, Jiang J, Zhang C (2020) Federated learning for open banking, in: Federated learning, Springer, pp 240–254
Lu Y, Huang X, Dai Y, Maharjan S, Zhang Y (2019) Differentially private asynchronous federated learning for mobile edge computing in urban informatics. IEEE Trans Industr Inf 16(3):2134–2143
Lu Y, Huang X, Dai Y, Maharjan S, Zhang Y (2019) Blockchain and federated learning for privacy-preserved data sharing in industrial iot. IEEE Trans Industr Inf 16(6):4177–4186
Lu Y, Huang X, Zhang K, Maharjan S, Zhang Y (2020) Blockchain empowered asynchronous federated learning for secure data sharing in internet of vehicles. IEEE Trans Veh Technol 69(4):4298–4311
Lu X, Liao Y, Lio P, Hui P (2020) Privacy-preserving asynchronous federated learning mechanism for edge network computing. IEEE Access 8:48970–48981
Lyu L, Yu H, Yang Q (2020) Threats to federated learning: A survey. arXiv:2003.02133
Ma S, Cao Y, Xiong L (2021) Transparent contribution evaluation for secure federated learning on blockchain, in: 2021 IEEE 37th International Conference on Data Engineering Workshops (ICDEW), IEEE, pp 88–91
Majeed A, Lee S (2020) Attribute susceptibility and entropy based data anonymization to improve users community privacy and utility in publishing data. Appl Intell 50(8):2555–2574
Majeed A, Zhang X, Hwang SO (2022) Applications and challenges of federated learning paradigm in the big data era with special emphasis on covid-19. Big Data and Cognitive Computing 6(4):127
Majeed U, Hong CS, Flchain: Federated learning via mec-enabled blockchain network, in, (2019) 20th Asia-Pacific Network Operations and Management Symposium (APNOMS). IEEE 2019:1–4
Maji HK, Nguyen HH, Paskin-Cherniavsky A, Suad T, Wang M (2021) Leakage-resilience of the shamir secret-sharing scheme against physical-bit leakages, in: Advances in Cryptology–EUROCRYPT 2021: 40th Annual International Conference on the Theory and Applications of Cryptographic Techniques, Zagreb, Croatia, October 17–21, 2021, Proceedings, Part II, Springer, pp 344–374
Malle B, Giuliani N, Kieseberg P, Holzinger A (2017) The more the merrier-federated learning from local sphere recommendations, in: International Cross-Domain Conference for Machine Learning and Knowledge Extraction, Springer, pp 367–373
Mansour Y, Mohri M, Ro J, Suresh AT (2020) Three approaches for personalization with applications to federated learning. arXiv:2002.10619
Martinez I, Francis S, Hafid AS, Record and reward federated learning contributions with blockchain, in, (2019) International conference on cyber-enabled distributed computing and knowledge discovery (CyberC). IEEE 2019:50–57
McMahan HB, Moore E, Ramage D, y Arcas BA (2016) Federated learning of deep networks using model averaging. arXiv:1602.05629 2, 2
McMahan HB, Ramage D, Talwar K, Zhang L (2017) Learning differentially private recurrent language models. arXiv:1710.06963
McMahan B, Moore E, Ramage D, Hampson S, y Arcas BA (2017) Communication-efficient learning of deep networks from decentralized data, in: Artificial intelligence and statistics, PMLR, pp 1273–1282
Melis L, Song C, De Cristofaro E, Shmatikov V, Exploiting unintended feature leakage in collaborative learning, in, (2019) IEEE Symposium on Security and Privacy (SP). IEEE 2019:691–706
Mignotte (1982) How to share a secret, in: Workshop on Cryptography, Springer. pp 371–375
Mohri M, Sivek G, Suresh AT (2019) Agnostic federated learning, in: International Conference on Machine Learning, PMLR. pp 4615–4625
Mothukuri V, Parizi RM, Pouriyeh S, Huang Y, Dehghantanha A, Srivastava G (2021) A survey on security and privacy of federated learning. Futur Gener Comput Syst 115:619–640
Mugunthan V, Polychroniadou A, Byrd D, Balch TH (2019) Smpai: Secure multi-party computation for federated learning, in: Proceedings of the NeurIPS 2019 Workshop on Robust AI in Financial Services, MIT Press Cambridge, MA, USA, pp 1–9
Mun H, Lee Y (2020) Internet traffic classification with federated learning. electronics 2021, 10, 27
Myrzashova R, Alsamhi SH, Shvetsov AV, Hawbani A, Wei X (2023) Blockchain meets federated learning in healthcare: A systematic review with challenges and opportunities, IEEE Internet of Things Journal
Naseri M, Hayes J, De Cristofaro E (2020) Toward robustness and privacy in federated learning: Experimenting with local and central differential privacy. arXiv:2009.03561
Nasr M, Shokri R, Houmansadr A, Comprehensive privacy analysis of deep learning: Passive and active white-box inference attacks against centralized and federated learning, in, (2019) IEEE symposium on security and privacy (SP). IEEE 2019:739–753
Ng D, Lan X, Yao MM-S, Chan WP, Feng M (2021) Federated learning: a collaborative effort to achieve better medical imaging models for individual sites that have small labelled datasets. Quant Imaging Med Surg 11(2):852
Nguyen TD, Marchal S, Miettinen M, Fereidooni H, Asokan N, Sadeghi A-R, Dïot (2019) A federated self-learning anomaly detection system for iot, in: 2019 IEEE 39th International Conference on Distributed Computing Systems (ICDCS), IEEE, pp 756–767
Nguyen DC, Pham Q-V, Pathirana PN, Ding M, Seneviratne A, Lin Z, Dobre O, Hwang W-J (2022) Federated learning for smart healthcare: A survey. ACM Computing Surveys (CSUR) 55(3):1–37
Niknam S, Dhillon HS, Reed JH (2020) Federated learning for wireless communications: Motivation, opportunities, and challenges. IEEE Commun Mag 58(6):46–51
Nishio T, Yonetani R (2019) Client selection for federated learning with heterogeneous resources in mobile edge, in: ICC 2019-2019 IEEE international conference on communications (ICC), IEEE, pp 1–7
Orekondy T, Oh SJ, Zhang Y, Schiele B, Fritz M (2018) Gradient-leaks: Understanding and controlling deanonymization in federated learning. arXiv:1805.05838
Pang L-J, Wang Y-M (2005) A new (t, n) multi-secret sharing scheme based on shamir’s secret sharing. Appl Math Comput 167(2):840–848
Pang J, Huang Y, Xie Z, Han Q, Cai Z (2020) Realizing the heterogeneity: A self-organized federated learning framework for iot. IEEE Internet of Things Journal 8(5):3088–3098
Pokhrel SR, Choi J (2020) Federated learning with blockchain for autonomous vehicles: Analysis and design challenges. IEEE Trans Commun 68(8):4734–4746
Preskill J (2018) Quantum computing in the nisq era and beyond. Quantum 2:79
Preuveneers D, Rimmer V, Tsingenopoulos I, Spooren J, Joosen W, Ilie-Zudor E (2018) Chained anomaly detection models for federated learning: An intrusion detection case study. Appl Sci 8(12):2663
Pujahari R, Tanwar A (2022) Quantum federated learning for wireless communications, in: Federated Learning for IoT Applications, Springer, pp 215–230
Qayyum A, Ahmad K, Ahsan MA, Al-Fuqaha A, Qadir J (2021) Collaborative federated learning for healthcare: Multi-modal covid-19 diagnosis at the edge. arXiv:2101.07511
Qian Y, Hu L, Chen J, Guan X, Hassan MM, Alelaiwi A (2019) Privacy-aware service placement for mobile edge computing via federated learning. Inf Sci 505:562–570
Qin J, Liu B, Qian J (2021) A novel privacy-preserved recommender system framework based on federated learning, in: 2021 The 4th International Conference on Software Engineering and Information Management, pp 82–88
Qu G-J, Wang M-M (2021) Secure multi-party quantum computation based on blind quantum computation. Int J Theor Phys 60:3003–3012
Qu Y, Gao L, Luan TH, Xiang Y, Yu S, Li B, Zheng G (2020) Decentralized privacy using blockchain-enabled federated learning in fog computing. IEEE Internet Things J 7(6):5171–5183
Qu Z, Li Y, Liu B, Gupta D, Tiwari P (2023) Dtqfl: A digital twin-assisted quantum federated learning algorithm for intelligent diagnosis in 5g mobile network, IEEE journal of biomedical and health informatics
Rahman MA, Hossain MS, Islam MS, Alrajeh NA, Muhammad G (2020) Secure and provenance enhanced internet of health things framework: A blockchain managed federated learning approach, Ieee. Access 8:205071–205087
Ramaswamy S, Mathews R, Rao K, Beaufays F (2019) Federated learning for emoji prediction in a mobile keyboard. arXiv:1906.04329
Rasha A-H, Li T, Huang W, Gu J, Li C (2023) Federated learning in smart cities: Privacy and security survey, Information Sciences
Ray Chaudhury B, Li L, Kang M, Li B, Mehta R (2022) Fairness in federated learning via core-stability. Adv Neural Inf Process Syst 35:5738–5750
Reisizadeh A, Farnia F, Pedarsani R, Jadbabaie A (2020) Robust federated learning: The case of affine distribution shifts. Adv Neural Inf Process Syst 33:21554–21565
Ren C, Yan R, Xu M, Yu H, Xu Y, Niyato D, Dong ZY (2023) Qfdsa: A quantum-secured federated learning system for smart grid dynamic security assessment, IEEE Internet of Things Journal
Rivest RL, Adleman L, Dertouzos ML et al (1978) On data banks and privacy homomorphisms. Foundations of secure computation 4(11):169–180
Rodríguez-Barroso N, Jiménez-López D, Luzón MV, Herrera F, Martínez-Cámara E (2023) Survey on federated learning threats: Concepts, taxonomy on attacks and defences, experimental study and challenges. Information Fusion 90:148–173
Roy AG, Siddiqui S, Pölsterl S, Navab N, Wachinger C (2019) Braintorrent: A peer-to-peer environment for decentralized federated learning. arXiv:1905.06731
Roy Chowdhury A, Guo C, Jha S, van der Maaten L (2022) Eiffel: Ensuring integrity for federated learning, in: Proceedings of the 2022 ACM SIGSAC Conference on Computer and Communications Security, pp 2535–2549
Samarakoon S, Bennis M, Saad W, Debbah M (2019) Distributed federated learning for ultra-reliable low-latency vehicular communications. IEEE Trans Commun 68(2):1146–1159
Samarakoon S, Bennis M, Saad W, Debbah M, Federated learning for ultra-reliable low-latency v2v communications, in, (2018) IEEE Global Communications Conference (GLOBECOM). IEEE 2018:1–7
Saputra YM, Hoang DT, Nguyen DN, Dutkiewicz E, Mueck MD, Srikanteswara S, Energy demand prediction with federated learning for electric vehicle networks, in, (2019) IEEE Global Communications Conference (GLOBECOM). IEEE 2019:1–6
Sattler F, Wiedemann S, Müller K-R, Samek W (2019) Robust and communication-efficient federated learning from non-iid data. IEEE transactions on neural networks and learning systems 31(9):3400–3413
Shamir A (1979) How to share a secret. Commun ACM 22(11):612–613
Sharghi H, Ma W, Sartipi K, Federated service-based authentication provisioning for distributed diagnostic imaging systems, in, (2015) IEEE 28th International Symposium on Computer-Based Medical Systems. IEEE 2015:344–347
Sharma S, Xing C, Liu Y, Kang Y (2019) Secure and efficient federated transfer learning, in: 2019 IEEE International Conference on Big Data (Big Data), IEEE, pp 2569–2576
Shi Y, Yu H, Leung C (2023) Towards fairness-aware federated learning, IEEE Transactions on Neural Networks and Learning Systems
Shokri R, Shmatikov V (2015) Privacy-preserving deep learning, in: Proceedings of the 22nd ACM SIGSAC conference on computer and communications security, pp 1310–1321
Silva S, Gutman BA, Romero E, Thompson PM, Altmann A, Lorenzi M, Federated learning in distributed medical databases: Meta-analysis of large-scale subcortical brain data, in, (2019) IEEE 16th international symposium on biomedical imaging (ISBI 2019). IEEE 2019:270–274
Smith V, Chiang CK, Sanjabi M, Talwalkar A (2017) Federated multi-task learning. arXiv:1705.10467
So J, Güler B, Avestimehr AS (2021) Turbo-aggregate: Breaking the quadratic aggregation barrier in secure federated learning. IEEE Journal on Selected Areas in Information Theory 2(1):479–489
So J, He C, Yang C-S, Li S, Yu Q, Ali RE, Guler B, Avestimehr S (2022) Lightsecagg: a lightweight and versatile design for secure aggregation in federated learning. Proceedings of Machine Learning and Systems 4:694–720
Song M, Wang Z, Zhang Z, Song Y, Wang Q, Ren J, Qi H (2020) Analyzing user-level privacy attack against federated learning. IEEE J Sel Areas Commun 38(10):2430–2444
Song Y, Wu Y, Wu S, Li D, Wen Q, Qin S, Gao F (2023) A quantum federated learning framework for classical clients. arXiv:2312.11672
Sozinov K, Vlassov V, Girdzijauskas S, Human activity recognition using federated learning, in, (2018) IEEE Intl Conf on Parallel & Distributed Processing with Applications, Ubiquitous Computing & Communications, Big Data & Cloud Computing, Social Computing & Networking, Sustainable Computing & Communications (ISPA/IUCC/BDCloud/SocialCom/SustainCom). IEEE 2018:1103–1111
Sprague MR, Jalalirad A, Scavuzzo M, Capota C, Neun M, Do L, Kopp M (2018) Asynchronous federated learning for geospatial applications, in: Joint European Conference on Machine Learning and Knowledge Discovery in Databases, Springer, pp 21–28
Steinfeld R, Pieprzyk J, Wang H (2007) Lattice-based threshold changeability for standard shamir secret-sharing schemes. IEEE Trans Inf Theory 53(7):2542–2559
Stinson DR, Paterson M (2018) Cryptography: theory and practice. CRC Press
STROLL A The growth and diversification in data collection techniques has led to tremendous changes in machine learning systems. since the breakthrough of variance-reduced stochastic methods (saga, miso [4, 12]), several research directions in optimization for learning have recently proven to be able to scale up to current challenges. among them, let us focus on two promising trends
Sun W, Lei S, Wang L, Liu Z, Zhang Y (2020) Adaptive federated learning and digital twin for industrial internet of things. IEEE Trans Industr Inf 17(8):5605–5614
Szatmari T-I, Petersen MK, Korzepa MJ, Giannetsos T (2020) Modelling audiological preferences using federated learning, in: Adjunct Publication of the 28th ACM Conference on User Modeling, Adaptation and Personalization. pp 187–190
Szegedi G, Kiss P, Horváth T (2019) Evolutionary federated learning on eeg-data., in: ITAT, pp 71–78
Tan B, Liu B, Zheng V, Yang Q (2020) A federated recommender system for online services, in: Fourteenth ACM Conference on Recommender Systems, pp 579–581
Toyoda K, Zhang AN (2019) Mechanism design for an incentive-aware blockchain-enabled federated learning platform, in: 2019 IEEE International Conference on Big Data (Big Data), IEEE, pp 395–403
Tran NH, Bao W, Zomaya A, Nguyen MN, Hong CS (2019) Federated learning over wireless networks: Optimization model design and analysis, in: IEEE INFOCOM 2019-IEEE Conference on Computer Communications, IEEE, pp 1387–1395
Truex S, Baracaldo N, Anwar A, Steinke T, Ludwig H, Zhang R, Zhou Y (2019) A hybrid approach to privacy-preserving federated learning, in: Proceedings of the 12th ACM workshop on artificial intelligence and security, pp 1–11
Truex S, Liu L, Chow K-H, Gursoy ME, Wei W (2020) Ldp-fed: Federated learning with local differential privacy, in: Proceedings of the Third ACM International Workshop on Edge Systems, Analytics and Networking, pp 61–66
Ulhaq A, Burmeister O (2020) Covid-19 imaging data privacy by federated learning design: A theoretical framework. arXiv:2010.06177
ur Rehman MH, Salah K, Damiani E, Svetinovic D (2020) Towards blockchain-based reputation-aware federated learning, in: IEEE INFOCOM 2020-IEEE Conference on Computer Communications Workshops (INFOCOM WKSHPS), IEEE, pp 183–188
Vatsalan D, Sehili Z, Christen P, Rahm E (2017) Privacy-preserving record linkage for big data: Current approaches and research challenges, in: Handbook of big data technologies, Springer, pp 851–895
Vucinich S, Zhu Q (2023) The current state and challenges of fairness in federated learning, IEEE Access
Wang S, Tuor T, Salonidis T, Leung KK, Makaya C, He T, Chan K (2019) Adaptive federated learning in resource constrained edge computing systems. IEEE J Sel Areas Commun 37(6):1205–1221
Wang Y, Tong Y, Shi D (2020) Federated latent dirichlet allocation: A local differential privacy based framework. Proceedings of the AAAI Conference on Artificial Intelligence 34:6283–6290
Wang Z, Fan X, Qi J, Wen C, Wang C, Yu R (2021) Federated learning with fair averaging. arXiv:2104.14937
Wang J, Jiang C, Zhang K, Quek TQ, Ren Y, Hanzo L (2017) Vehicular sensing networks in a smart city: Principles, technologies and applications. IEEE Wireless Communications 25(1):122–132
Wang T, Li P, Wu Y, Qian L, Su Z, Lu R (2023) Quantum-empowered federated learning in space-air-ground integrated networks, IEEE Network
Wang K, Mathews R, Kiddon C, Eichner H, Beaufays F, Ramage D (2019) Federated evaluation of on-device personalization. arXiv:1910.10252
Wang Z, Song M, Zhang Z, Song Y, Wang Q, Qi H (2019) Beyond inferring class representatives: User-level privacy leakage from federated learning, in: IEEE INFOCOM 2019-IEEE Conference on Computer Communications, IEEE. pp 2512–2520
Wei K, Li J, Ding M, Ma C, Yang HH, Farokhi F, Jin S, Quek TQ, Poor HV (2020) Federated learning with differential privacy: Algorithms and performance analysis. IEEE Trans Inf Forensics Secur 15:3454–3469
Wen W, Xu C, Yan F, Wu C, Wang Y, Chen Y, Li H (2017) Terngrad: Ternary gradients to reduce communication in distributed deep learning, Advances in neural information processing systems 30
Woubie A, Bäckström T (2021) Federated learning for privacy-preserving speaker recognition. IEEE Access 9:149477–149485
Wu Y, Cai S, Xiao X, Chen G, Ooi BC (2020) Privacy preserving vertical federated learning for tree-based models. arXiv:2008.06170
Xia Q, Ye W, Tao Z, Wu J, Li Q (2021) A survey of federated learning for edge computing: Research problems and solutions. High-Confidence Computing 1(1):100008
Xie C, Koyejo O, Gupta I (2019) Slsgd: Secure and efficient distributed on-device machine learning, in: Joint European Conference on Machine Learning and Knowledge Discovery in Databases, Springer, pp 213–228
Xiong Z, Cheng Z, Xu C, Lin X, Liu X, Wang D, Luo X, Zhang Y, Qiao N, Zheng M, et al (2020) Facing small and biased data dilemma in drug discovery with federated learning, BioRxiv
Xu G, Li H, Liu S, Yang K, Lin X (2019) Verifynet: Secure and verifiable federated learning. IEEE Trans Inf Forensics Secur 15:911–926
Xu J, Glicksberg BS, Su C, Walker P, Bian J, Wang F (2021) Federated learning for healthcare informatics. Journal of Healthcare Informatics Research 5(1):1–19
Xu R, Baracaldo N, Zhou Y, Anwar A, Ludwig H (2019) Hybridalpha: An efficient approach for privacy-preserving federated learning, in: Proceedings of the 12th ACM workshop on artificial intelligence and security. pp 13–23
Xu Q, Zhao L, Su Z, Fang D, Li R (2023) Secure federated learning in quantum autonomous vehicular networks, IEEE Network
Yamany W, Moustafa N, Turnbull B (2021) Oqfl: An optimized quantum-based federated learning framework for defending against adversarial attacks in intelligent transportation systems, IEEE Transactions on Intelligent Transportation Systems
Yang C-C, Chang T-Y, Hwang M-S (2004) A (t, n) multi-secret sharing scheme. Appl Math Comput 151(2):483–490
Yang Q, Liu Y, Cheng Y, Kang Y, Chen T, Yu H (2019) Federated learning, Synthesis Lectures on Artificial Intelligence and Machine. Learning 13(3):1–207
Yang T, Andrew G, Eichner H, Sun H, Li W, Kong N, Ramage D, Beaufays F (2018) Applied federated learning: Improving google keyboard query suggestions. arXiv:1812.02903
Yang Q, Zhang J, Hao W, Spell GP, Carin L (2021) Flop: Federated learning on medical datasets using partial networks, in: Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining, pp 3845–3853
Yin X, Zhu Y, Hu J (2021) A comprehensive survey of privacy-preserving federated learning: A taxonomy, review, and future directions. ACM Computing Surveys (CSUR) 54(6):1–36
Yu T, Li T, Sun Y, Nanda S, Smith V, Sekar V, Seshan S (2020) Learning context-aware policies from multiple smart homes via federated multi-task learning, in: 2020 IEEE/ACM Fifth International Conference on Internet-of-Things Design and Implementation (IoTDI), IEEE, pp 104–115
Yurochkin M, Agarwal M, Ghosh S, Greenewald K, Hoang N, Khazaeni Y (2019) Bayesian () nonparametric federated learning of neural networks, in: International Conference on Machine Learning, PMLR, pp 7252–7261
Zhang X, Yang Z, Sun W, Liu Y, Tang S, Xing K, Mao X (2015) Incentives for mobile crowd sensing: A survey. IEEE Communications Surveys & Tutorials 18(1):54–67
Zhang C, Liu Y, Wang L, Liu Y, Li L, Zheng N (2020) Joint intelligence ranking by federated multiplicative update. IEEE Intell Syst 35(4):15–24
Zhang W, Lu Q, Yu Q, Li Z, Liu Y, Lo SK, Chen S, Xu X, Zhu L (2020) Blockchain-based federated learning for device failure detection in industrial iot. IEEE Internet Things J 8(7):5926–5937
Zhang W, Li X, Ma H, Luo Z, Li X (2021) Federated learning for machinery fault diagnosis with dynamic validation and self-supervision. Knowl-Based Syst 213:106679
Zhang W, Zhou T, Lu Q, Wang X, Zhu C, Sun H, Wang Z, Lo SK, Wang F-Y (2021) Dynamic-fusion-based federated learning for covid-19 detection. IEEE Internet Things J 8(21):15884–15891
Zhang C, Zhang S, James J, Yu S (2021) Fastgnn: A topological information protected federated learning approach for traffic speed forecasting. IEEE Trans Industr Inf 17(12):8464–8474
Zhang C, Xie Y, Bai H, Yu B, Li W, Gao Y (2021) A survey on federated learning. Knowl-Based Syst 216:106775
Zhang J, Chen J, Wu D, Chen B, Yu S, Poisoning attack in federated learning using generative adversarial nets, in, (2019) 18th IEEE International Conference On Trust, Security And Privacy In Computing And Communications/13th IEEE International Conference On Big Data Science And Engineering (TrustCom/BigDataSE). IEEE 2019:374–380
Zhang X, Fu A, Wang H, Zhou C, Chen Z (2020) A privacy-preserving and verifiable federated learning scheme, in: ICC 2020-2020 IEEE International Conference on Communications (ICC), IEEE, pp 1–6
Zhang X, Ji S, Wang H, Wang T (2017) Private, yet practical, multiparty deep learning, in: 2017 IEEE 37th International Conference on Distributed Computing Systems (ICDCS), IEEE, pp 1442–1452
Zhang C, Li S, Xia J, Wang W, Yan F, Liu Y (2020) \(\{\)BatchCrypt\(\}\): Efficient homomorphic encryption for \(\{\)Cross-Silo\(\}\) federated learning, in: 2020 USENIX annual technical conference (USENIX ATC 20), pp 493–506
Zhang M, Sapra K, Fidler S, Yeung S, Alvarez JM (2020) Personalized federated learning with first order model optimization. arXiv:2012.08565
Zhang L, Xu J, Vijayakumar P, Sharma PK, Ghosh U (2022) Homomorphic encryption-based privacy-preserving federated learning in iot-enabled healthcare system, IEEE Transactions on Network Science and Engineering
Zhao H (2023) Non-iid quantum federated learning with one-shot communication complexity. Quantum Machine Intelligence 5(1):3
Zhao J, Zhang J, Zhao R (2007) A practical verifiable multi-secret sharing scheme. Computer Standards & Interfaces 29(1):138–141
Zhao Z, Feng C, Yang HH, Luo X (2020) Federated-learning-enabled intelligent fog radio access networks: fundamental theory, key techniques, and future trends. IEEE Wirel Commun 27(2):22–28
Zhao Y, Zhao J, Jiang L, Tan R, Niyato D, Li Z, Lyu L, Liu Y (2020) Privacy-preserving blockchain-based federated learning for iot devices. IEEE Internet Things J 8(3):1817–1829
Zhao K, Xi W, Wang Z, Zhao J, Wang R, Jiang Z (2020) Smss: Secure member selection strategy in federated learning. IEEE Intell Syst 35(4):37–49
Zhao B, Fan K, Yang K, Wang Z, Li H, Yang Y (2021) Anonymous and privacy-preserving federated learning with industrial big data. IEEE Trans Industr Inf 17(9):6314–6323
Zhao Y, Li M, Lai L, Suda N, Civin D, Chandra V (2018) Federated learning with non-iid data. arXiv:1806.00582
Zhou X, Ye X, Kevin I, Wang K, Liang W, Nair NKC, Shimizu S, Yan Z, Jin Q (2023) Hierarchical federated learning with social context clustering-based participant selection for internet of medical things applications, IEEE Transactions on Computational Social Systems
Zhou J, Zhang S, Lu Q, Dai W, Chen M, Liu X, Pirttikangas S, Shi Y, Zhang W, Herrera-Viedma E (2021) A survey on federated learning and its applications for accelerating industrial internet of things. arXiv:2104.10501
Zhu H, Jin Y (2019) Multi-objective evolutionary federated learning. IEEE transactions on neural networks and learning systems 31(4):1310–1322
Zhu H, Goh RSM, Ng W-K (2020) Privacy-preserving weighted federated learning within the secret sharing framework. IEEE Access 8:198275–198284
Zhu H, Li Z, Cheah M, Goh RSM (2020) Privacy-preserving weighted federated learning within oracle-aided mpc framework. arXiv:2003.07630
Zhu L, Liu Z, Han S (2019) Deep leakage from gradients, Advances in Neural Information Processing Systems 32
Zhu W, White A, Luo J (2021) Federated learning of molecular properties with graph neural networks in a heterogeneous setting, Available at SSRN 4002763
Author information
Authors and Affiliations
Contributions
Anchita Saha is responsible for Conceptualization; Methodology; Writing—original draft; Writing—review & Editing; Formal analysis; Ashlesha Hota is responsible for Conceptualization; Writing—original draft; Writing—review & Editing; Formal analysis; Arup Kumar Chattopadhyay is responsible for Writing—review & Editing; Formal analysis; Amitava Nag is responsible for Conceptualization; Supervision; Investigation; Review & Editing; Validation; Sukumar Nandi is responsible for Supervision; Investigation; Review & Editing; Validation;
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Saha, S., Hota, A., Chattopadhyay, A.K. et al. A multifaceted survey on privacy preservation of federated learning: progress, challenges, and opportunities. Artif Intell Rev 57, 184 (2024). https://doi.org/10.1007/s10462-024-10766-7
Accepted:
Published:
DOI: https://doi.org/10.1007/s10462-024-10766-7