
Abstract
High levels of correlation among financial assets and extreme losses are typical during crises. In such situations, investing in few assets might be a better choice than holding diversified portfolios. We show that constraining the sparse \(\ell _q\)-norm of portfolio weights automatically controls diversification and selects portfolios with a small number of active weights and low risk, in presence of high correlation and volatility. We highlight the diversification relationships between the minimum variance portfolio, risk budgeting strategies and diversification-constrained portfolios. Finally, we show empirically that the \(\ell _q\)-strategy can successfully cope with bear markets by shrinking portfolio weights and total amount of shorting.








Similar content being viewed by others

Notes
By active weights and positions, we refer henceforth to non-zero weights and not active weights w.r.t. a benchmark as defined within some streams of financial research (Grinold and Kahn 1999).
The \(\ell _q\)-norm of a vector \(\varvec{w}\) of n elements is defined here, for \(0<q<\infty \), as \(\ell _q = \Vert \varvec{w}\Vert _q^q\ = \sum _{i=1}^{n}|w_i|^q\), with slight abuse of terminology. In fact, the \(\ell _q\)-norm would be \(\Vert \varvec{w}\Vert _q\ = \left( \sum _{i=1}^{n}|w_i|^q\right) ^{1/q}\). Note that for \(0<q<1\), the q-norm \(\Vert \varvec{w}\Vert _q\) is a pseudo-norm.
Given a vector \(\varvec{w}\) of n elements, \(\ell _\infty = \Vert \varvec{w}\Vert _\infty \ = \max (|w_1|,\dots , |w_n|)\) and \(\ell _0 = \Vert \varvec{w}\Vert _0 = \sum _{i=1}^{n} \mathbb {1} (w_i \ne 0)\).
Imposing an upper bound on the 0-norm, such that \(\Vert \varvec{w}\Vert _0 \le k\), results in the so-called cardinality constraint, which limits the number of active weights in the portfolio.
Given a vector \(\varvec{w}\) of n elements, we define the standardized vector \(\varvec{w}^\star \) as \(w^{\star }_i = w_i/\sum _{i=1}^n |w_i|\), with \(i = 1,\dots n\).
See Bauer and Zanjani (2016) for a discussion about risk exposures based on different risk measures.
In the two-asset case, the ERC strategy selects the assets weight according to their volatilities. As the difference \(\sigma _1-\sigma _2\) is not large in our examples, \(w_1\simeq w_2\).
References
Bauer D, Zanjani G (2016) The marginal cost of risk, risk measures, and capital allocation. Manag Sci 62:1431–1457
Behr P, Guettler A, Miebs F (2013) On portfolio optimization: imposing the right constraint. J Bank Finance 37:1232–1242
Benoit S, Colletaz G, Hurlin C, Perignon C (2013) A theoretical and empirical comparison of systemic risk measures. HEC Paris Research Paper (FIN-2014-1030)
Bodie Z, Kane A, Marcus A (1999) Investments, 4th edn. Irwin/McGraw-Hill, Boston
Boyle P, Garlappi L, Uppal R, Wang T (2012) Keynes meets Markowitz: the trade-off between familiarity and diversification. Manag Sci 58:253–272
Brands S, Brown S, Gallagher D (2005) Portfolio concentration and investment manager performance. Int Rev Finance 5:149–174
Brodie J, Daubechies I, De Mol C, Giannone D, Loris I (2009) Sparse and stable Markowitz portfolios. Proc Natl Acad Sci 106:12267–12272
Bruder B, Roncalli T (2012) Managing risk exposures using the risk budgeting approach. Working paper
Buffett W (1979) Chairman’s Letter. http://www.berkshirehathaway.com/letters/1979.html
Carrasco M, Noumon N (2012) Optimal portfolio selection using regularization. Working paper, University of Montreal
Cazalet Z, Grison P, Roncalli T (2014) The smart beta indexing puzzle. J Index Invest 5:97–119
Chen C, Li X, Tolman C, Wang S, Ye Y (2013) Sparse portfolio selection via quasi-norm regularization, preprint. arXiv:1312.6350
Chopra VK, Ziemba WT (1993) The effect of errors in means, variances, and covariances on optimal portfolio choice. J Portf Manag 19:6–11
Choueifaty Y, Coignard Y (2008) Toward maximum diversification. J Portf Manag 34:40–51
Daniel K, Grinblatt M, Titman S, Werme R (1997) Measuring mutual fund performance with characteristic-based benchmarks. J Finance 52:1035–1058
De Miguel V, Nogales FJ (2009) Portfolio selection with robust estimation. Oper Res 57:560–577
De Miguel V, Garlappi L, Nogales F, Uppal R (2009a) A generalized approach to portfolio optimization: improving performance by constraining portfolio norm. Manag Sci 55:798–812
De Miguel V, Garlappi L, Uppal R (2009b) Optimal versus naive diversification: how inefficient is the 1/n portfolio strategy? Rev Financ Stud 22(5):1915–1953
Doganoglu T, Hartz C, Mittnik S (2007) Portfolio optimization when risk factors are conditionally varying and heavy tailed. Comput Econ 29:333–354
Fan J, Li R (2001) Variable selection via nonconcave penalized likelihood and its oracle properties. J Am Stat Assoc 96:1348–1360
Fan J, Zhang J, Yu K (2012) Vast portfolio selection with gross-exposure constraints. J Am Stat Assoc 107:592–606
Fastrich B, Paterlini S, Winker P (2014) Cardinality versus q-norm constraints for index tracking. Quant Finance 14:2019–2032
Fastrich B, Paterlini S, Winker P (2015) Constructing optimal sparse portfolios using regularization methods. Comput Manag Sci 12:417–434
Figueiredo M, Nowak R, Wright S (2007) Gradient projection for sparse reconstruction: application to compressed sensing and other inverse problems. IEEE J Sel Top Signal Process 1:586–597
Frank I, Friedman J (1993) A statistical view of some chemometrics regression tools. Technometrics 35:109–135
Gasso G, Rakotomamonjy A, Canu S (2009) Recovering sparse signals with a certain family of nonconvex penalties and DC programming. IEEE Trans Signal Process 57:4686–4698
Giuzio M (2017) Genetic algorithm versus classical methods in sparse index tracking. Decis Econ Finance 40:243–256
Goto S, Xu Y (2015) Improving mean variance optimization through sparse hedging restrictions. J Financ Quant Anal 50:1415–1441
Grinold RC, Kahn R (1999) Active portfolio management, 2nd edn. McGraw-Hill, New York
Guidolin M, Rinaldi F (2013) Ambiguity in asset pricing and portfolio choice: a review of the literature. Theory Decis 74:183–217
Huang J, Horowitz J, Ma S (2008) Asymptotic properties of bridge estimators in sparse high-dimensional regression models. Ann Stat 30:587–613
Jagannathan R, Ma T (2003) Risk reduction in large portfolios: why imposing the wrong constraints helps. J Finance 58:1651–1684
Kacperczyk M, Sialm C, Zheng L (2005) On the industry concentration of actively managed equity mutual funds. J Finance 60:1983–2011
Knight K, Fu W (2000) Asymptotics for lasso-type estimators. Ann Stat 28:1356–1378
Kolm PN, Tütüncü R, Fabozzi F (2014) 60 years following Harry Markowitz’s contribution to portfolio theory and operations research. Eur J Oper Res 234:343–582
Kotkatvuori-Örnberg J, Nikkinen J, Äijö J (2013) Stock market correlations during the financial crisis in 2008–2009: evidence from 50 equity markets. Int Rev Financ Anal 28:70–78
Ledoit O, Wolf M (2004) A well-conditioned estimator for large-dimensional covariance matrices. J Multivar Anal 88:365–411
Ledoit O, Wolf M (2012) Nonlinear shrinkage estimation of large-dimensional covariance matrices. Ann Stat 40:1024–1060
Maillard S, Roncalli T, Teïletche J (2010) The properties of equally weighted risk contribution portfolios. J Portf Manag 36:60–70
Mainik G, Mitov G, Rüschendorf L (2015) Portfolio optimization for heavy-tailed assets: extreme risk index vs. Markowitz. J Empir Finance 32:115–134
Markowitz H (1952) Portfolio selection. J Finance 7:77–91
Merton R (1980) On estimating the expected return on the market: an exploratory investigation. J Financ Econ 8:323–361
Michaud R (1989) The Markowitz optimization enigma: is optimized optimal? Financ Anal J 45:31–45
Murphy KP (2012) Machine learning: a probabilistic perspective. MIT Press, Cambridge
Statman M (1987) How many stocks make a diversified portfolio? J Financ Quant Anal 22:353–363
Tibshirani R, Saunders M, Rosset S, Zhu J, Knight K (2005) Sparsity and smoothness via the fused lasso. J R Stat Soc Ser B 67:91–108
Tütüncü R, Koenig M (2004) Robust asset allocation. Ann Oper Res 132:157–187
Weston J, Elisseeff A, Schölkopf B (2003) Use of the zero-norm with linear models and kernel methods. J Mach Learn Res 3:1439–1461
Xing X, Hub J, Yang Y (2014) Robust minimum variance portfolio with L-infinity constraints. J Bank Finance 46:107–117
Yen Y, Yen T (2014) Solving norm constrained portfolio optimization via coordinate-wise descent algorithms. Comput Stat Data Anal 76:737–759
You L, Daigler R (2010) Is international diversification really beneficial? J Bank Finance 34:163–173
Zou H (2006) The adaptive lasso and its oracle properties. J Am Stat Assoc 101:1418–1429
Zou H, Hastie T (2005) Regularization and variable selection via the elastic net. J R Stat Soc 67:301–320
Acknowledgements
We would like to thank the two anonymous referees and the Associate Editor for providing us with constructive and detailed comments that have improved the quality of our paper. Sandra Paterlini gratefully acknowledges financial support from ICT COST Action IC1408 “Computationally-intensive methods for the robust analysis of non-standard data”.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
Appendix A: Risk decomposition
In risk management, it is important to quantify the contribution of each asset to the overall portfolio risk. One common indicator is given by the sensitivity of portfolio risk to a small change in asset allocation. In this section, we derive this measure for the portfolio standard deviation and Expected Shortfall.
Let \(\varvec{w}\) be the \(n \times 1\) vector of portfolio weights and \(\varvec{\varSigma } \) be the \(n \times n\) covariance matrix of n asset returns. The risk of the portfolio, typically measured by the standard deviation of portfolio returns \(\sigma _p\), can then be expressed as follows:
In order to measure the contribution of each asset to the overall portfolio risk, we can compute the Marginal Risk Contribution of asset i as the partial derivative of \(\sigma _p\) with respect to \(w_i\)
\({ MRC}_i\) can be also expressed as a function of \((\varvec{\varSigma } \varvec{w})\), the product of the covariance matrix and the weights vector, as follows:
where \((\varSigma w)_i = \sum _{j=1}^{n}\sigma _{ij}w_j\) represents the i-th component of the column vector \((\varvec{\varSigma } \varvec{w})\). The risk contribution of asset i is then defined as the weighted \({ MRC}_i\) and represents the share of portfolio risk corresponding to the i-asset:
The sum of all \(RC_i\) is the total portfolio risk, quantified by the standard deviation of the portfolio returns. The relative risk contribution of asset i is defined as
By construction, the risk-parity portfolio has a RC\(_i=\sigma _p/n\), which implies an RRC\(_i= 1/n\).
From a risk budgeting perspective, it may be useful to know the composition of a portfolio also in terms of extreme risk. Let us denote by \(\mu _i\) the expected return on asset i (with \(i = 1, \dots , n\)) and by \(\mu _p\) the expected return on the portfolio obtained as the weighted sum of its constituents’ expected returns:
Given a constant \(0 \le \alpha \le 1\), we define the Value-at-Risk of a portfolio, \({ VaR}_{p,\alpha }\), as the maximum expected loss of the portfolio at a \(\alpha \%\) confidence level. We measure the extreme risk of a portfolio by the Expected Shortfall \(ES_{p,\alpha }\), which represents the expected return of the portfolio in the worst \((1-\alpha )\%\) of cases. \(ES_{p,\alpha }\) can be written equivalently as the expected loss of the portfolio conditional on this loss being greater than \(C={ VaR}_{p,\alpha }\):
To compute the contribution of each asset to the overall portfolio \(ES_{p,\alpha }\), we first calculate the Marginal Expected Shortfall of asset i as the partial derivative of \(ES_{p,\alpha }\) with respect to \(w_i\):
\({ MES}_{i,\alpha }\) represents the increase in portfolio extreme risk caused by a marginal increase in the weight on asset i. As suggested by Benoit et al. (2013), the extreme risk contribution of each asset \({ CES}_{i,\alpha }\) can be then defined as the weighted \({ MES}_{i,\alpha }\) and indicates the share of \(ES_{p,\alpha }\) due to the i-asset:
The sum of all the Contributions to Expected Shortfall \({ CES}_{i,\alpha }\) is the total portfolio Expected Shortfall.
Appendix B: \(\ell _q\) properties
Let’s consider the risk minimization problem
where \(0 < q \le 1\) and \(c^q>0\) is the threshold of the \(\ell _{q}\)-norm. This optimization could be solved as the following penalized problem (although convergence to the global optimum is not guaranteed as the \(\ell _q\)-penalty is non-convex).
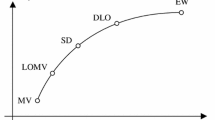
with \(\lambda >0\) as a scalar controlling the intensity of the penalty. If \(c\rightarrow n^{1-q}\), then the solution to problem (B-1) converges to the EW portfolio, while if \(c\rightarrow 1\), it converges to the most concentrated portfolio with just one active weight, as \(q\rightarrow 0^+\).
Proof
Proposition 1. Let the amount of shorting of a portfolio \(\varvec{w}\) be the sum of the absolute value of its negative weights
Due to the budget constraint, the amount of null and long positions can then be written as
Since \(\Vert \varvec{w}\Vert _1 = S+L\), we also have that \(\Vert \varvec{w}\Vert _1 = 2S +1\). Therefore, adding the \(\ell _1\)-norm to the objective function constrains the level of shorting of the portfolio. The \(\ell _q\)-norm represents a stricter constraint on shorting, as, for any value of q, we have
and, given that \(\left( \sum _{i=1}^n |w_i| \right) = 2S+1\),
Furthermore, as \(0 \le q < 1\) and \((2S+1)\ge 1\), it follows that \(2S+1\ge (2S+1)^q\). Thus, constraining the \(\ell _q\)-norm of portfolio weights, i.e., \(\Vert \varvec{w}\Vert _q^q \le c\), imposes a stronger bound on the amount of shorting than the one applied by constraining the \(\ell _1\)-norm, i.e., \(\Vert \varvec{w}\Vert _1 \le c^q\). \(\square \)
Proof
Proposition 2. To prove that the \(\ell _{q}\)-norm, with \(0 < q \le 1\), is bounded by 1 and \(n^{1-q}\) under the no-short-selling and budget constraints, i.e., \(0 \le w_i \le 1\), \(\sum _{i=1}^{n} w_1 =1\), we compute its extreme values corresponding to the most concentrated (i.e., totally invested in one asset) and the EW portfolios. Let us assume that the absolute values of the weights are sorted in descending order, from the largest to the smallest such that \(|w_{(1)}| \ge |w_{(2)}| \ge \dots |w_{(n)}|\). Then, let \(w_{(1)}\) be equal to 1 and therefore \(w_{(j)}=0\), \(j=2,\dots n\). It follows that for the most concentrated portfolio
The other limit case is for the EW portfolio, when \(w_1=w_2=\dots =w_n=1/n\). Then,
As \(\ell _1= \Vert \varvec{w}\Vert _1 = \sum _{i=1}^{n} |w_i| =1\), \(i=1,\dots ,n\), the following relationship between norms holds then true:
In fact, from norm inequalities, if \(0< q < p\), we know
Then, if \(p=1\) and \(0<q \le 1\)
or, equivalently
as we have that \(\Vert \varvec{w}\Vert _1 =1\) when \(0 \le w_i \le 1\) and \(\sum _{i=1}^{n} w_1 =1\). \(\square \)
Let \(R(\varvec{w})=\varvec{w}'\varvec{\varSigma } \varvec{w}\), and \(\varvec{w}\) and \(\varvec{w}_{opt}\) be the theoretical and empirical optimal allocation vectors that solve the optimization problems
\(\varvec{w}= \hbox {argmin}_{\mathbf{1'}{\varvec{w}} = 1, \Vert \varvec{w}\Vert _q^q\ \le c^q} \varvec{w}'\varvec{\varSigma } \varvec{w}\) and \(\varvec{w}_{opt} = \hbox {argmin}_{\mathbf{1'}{\varvec{w}} = 1, \Vert \varvec{w}\Vert _q^q\ \le c^q} \varvec{w}'\widehat{\varvec{\varSigma } }\varvec{w}\), where \(\varvec{\varSigma } \) and \(\hat{\varvec{\varSigma } }\) are the theoretical covariance matrix and its estimate, respectively.
Proposition 3
Let \(a_n\) represent the maximum component-wise estimation error, i.e., \(a_n = \Vert \hat{\varvec{\varSigma } } - \varvec{\varSigma } \Vert _{\infty }\). Then, under the assumptions in Fan et al. (2012), we can write the oracle, empirical and actual risks as
These inequalities hold without any condition on the weights and show that the differences between oracle, empirical and actual risks are very small as long as c is not too large and the covariance estimate is precise.
Proof
Proof of Proposition 3 First, let us recall Theorem 1 in Fan et al. (2012), which states the following relationships between oracle, empirical and actual risk of a constrained minimum variance portfolio \(\varvec{w}\), with \(\Vert \varvec{w}\Vert _q \ \le c \) (i.e., \(\root q \of {\ell _q}\ \le c \))
From Eq. (B-3), if \(p=1\) and \(0<q \le 1\), we know
or, equivalently
As we solve the optimization problem (B-1) for \( \Vert \varvec{w}\Vert _q^q \le c^q\), \( \Vert \varvec{w}\Vert _1 \le c\). The bounds on the differences between oracle, empirical, and actual risks, reported in Theorem 1 in Fan et al. (2012), still hold. \(\square \)
Appendix C: Optimization methods and computational time
In this section, we compare the performance of two state-of-art methods in non-convex optimization in solving Problem 8: the gradient projection (GP) algorithm, developed by Figueiredo et al. (2007), and the cycling coordinate descent (CD) algorithm, implemented by Yen and Yen (2014). The corresponding pseudo-codes are described in Algorithms 1 and 2. We run the two methods for the \(\ell _q\) and Log-penalties in both dataset over the whole sample period, using a vector of 10 \(\lambda \)s, as specified in Sect. 3.2. Table 6 reports the average penalized minimum variance obtained by the two algorithms, as in Eq. (4) (Columns 2 and 3), and the corresponding computational time (Columns 5 and 6). The comparison is implemented in Matlab R2016.a on a Lenovo ThinkPad X1 Yoga laptop with 2.50 GHz, Intel Core i7-6500U processor in Windows 10. We confirm empirically the results of Gasso et al. (2009) and find that the gradient projection outperforms the cycling coordinate descent, achieving lower or equal values of penalized variance for any value of \(\lambda \) (Column 4), and is more efficient in terms of time, especially when the dimensionality of the data increases. For a comparison between the performance of state-of-art methods in non-convex optimization, we refer to Giuzio (2017) and references therein.

Appendix D: Transaction costs
As the magnitude of portfolio weights is a proxy for transaction costs (Brodie et al. 2009), we model these costs as a payment proportional to the transaction volume (i.e., turnover) by the factor v. Results do not change qualitatively when considering \(v = 0.10\) and \(v = 0.25\), as Tables 7 and 8 show.
Rights and permissions
About this article

Cite this article
Giuzio, M., Paterlini, S. Un-diversifying during crises: Is it a good idea?. Comput Manag Sci 16, 401–432 (2019). https://doi.org/10.1007/s10287-018-0340-y
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10287-018-0340-y