
Abstract
One-class classification aims at constructing a distinctive classifier based on one class of examples. Most of the existing one-class classification methods are proposed based on the assumptions that: (1) there are a large number of training examples available for learning the classifier; (2) the training examples can be explicitly collected and hence do not contain any uncertain information. However, in real-world applications, these assumptions are not always satisfied. In this paper, we propose a novel approach called uncertain one-class transfer learning with support vector machine (UOCT-SVM), which is capable of constructing an accurate classifier on the target task by transferring knowledge from multiple source tasks whose data may contain uncertain information. In UOCT-SVM, the optimization function is formulated to deal with uncertain data and transfer learning based on one-class SVM. Then, an iterative framework is proposed to solve the optimization function. Extensive experiments have showed that UOCT-SVM can mitigate the effect of uncertain data on the decision boundary and transfer knowledge from source tasks to help build an accurate classifier on the target task, compared with state-of-the-art one-class classification methods.





Similar content being viewed by others

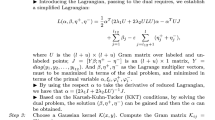
Notes
In the experiments, we initialize \(\Delta \overline{\mathbf{x }}_{1i}=0\) and \(\Delta \overline{\mathbf{x }}_{2j}=0\).
Available at http://www.daviddlewis.com/resources/testcollections/.
Available at http://people.csail.mit.edu/jrennie/20Newsgroups/.
Available at http://archive.ics.uci.edu/ml/datasets/Mushroom.
Available from http://archive.ics.uci.edu/ml/datasets/ISOLET.
Available from http://dis.ijs.si/confidence/dataset.html.
References
Schölkopf B, Williamson RC, Smola A, Shawe-Taylor J (1999) Support vector method for novelty detection. In: Proceedings of neural information processing systems 1999, pp 582–588
Manevitz LM, Yousef M (2002) One-class SVMs for document classiffication. J Mach Learn Res 2:139–154
Ma J, Perkins S (2003) Time-series novelty detection using one-class support vector machines. In: Proceedings of international joint conference on neural networks 2003, pp 1741–1745
Li J, Su L, Cheng C (2011) Finding pre-images via evolution strategies. Appl Soft Comput 11(6):4183–4194
Takruri M, Rajasegarar S, Challa S, Leckie C, Palaniswami M (2011) Spatio-temporal modelling-based drift-aware wireless sensor networks. Wirel Sens Syst 1(2):110–122
Münoz-Marí J, Bovolo F, Gomez-Chova L, Bruzzone L, Camp-Valls G (2010) Semisupervised one-class support vector machines for classification of remote sensing data. IEEE Trans Geosci Remote Sens 48(8):3188–3197
Yu H, Han J, Chang KCC (2004) Pebl: web page classification without negative examples. IEEE Trans Knowl Data Eng 16(1):70–81
Fung GPC, Yu JX, Lu H, Yu PS (2006) Text classification without negative examples revisit. IEEE Trans Knowl Data Eng 18:6–20
Liu B, Xiao Y, Cao L, Yu PS (1995) One-class-based uncertain data stream learning. In: Proceedings of SIAM international conference on data mining 2011, pp 992–1003
Pan SJ, Tsand IW, Kwok JT, Yang Q (2011) Domain adaptation via transfer component analysis. IEEE Trans Neural Netw 22(2):199–210
Aggarwal CC, Yu PS (2009) A survey of uncertain data algorithms and applications. IEEE Trans Knowl Data Eng 21(5):609–623
Kriegel HP, Pfeifle M (2005) Hierarchical density based clustering of uncertain data. In: Proceedings of international conference on data engineering 2005, pp 689–692
Ngai W, Kao B, Chui C, Cheng R, Chau M, Yip KY (2006) Efficient clustering of uncertain data. In: Proceedings of international conference on data mining 2006, pp 436–445
Aggarwal CC (2007) On density based transforms for uncertain data mining. In: Proceedings of international conference on data engineering 2007, pp 866–875
Bi J, Zhang T (2004) Support vector classification with input data uncertainty. In: Proceedings of neural information processing systems, 2004
Gao C, Wang J (2010) Direct mining of discriminative patterns for classifying uncertain data. In: Proceedings of ACM SIGKDD conference on knowledge discovery and data mining 2010, pp 861–870
Tsang S, Kao B, Yip KY, Ho WS, Lee SD (2011) Decision trees for uncertain data. IEEE Trans Knowl Data Eng 23(1):64–78
Murthy R, Ikeda R, Widom J (2011) Making aggregation work in uncertain and probabilistic databases. IEEE Trans Knowl Data Eng 22(8):1261–1273
Yuen SM, Tao Y, Xiao X, Pei J, Zhang D (2010) Superseding nearest neighbor search on uncertain spatial databases. IEEE Trans Knowl Data Eng 22(7):1041–1055
Sun L, Cheng R, Cheung DW, Cheng J (2010) Mining uncertain data with probabilistic guarantees. In: Proceedings of the ACM SIGKDD conference on knowledge discovery and data mining 2010, pp 273–282
Dai W, Xue G, Yang Q, Yu Y (2007) Transferring naive bayes classifiers for text classification. In: Proceedings of the AAAI conference on artificial intelligence 2007, pp 540–545
Jiang J, Zhai C (2007) Instance weighting for domain adaptation in NLP. In: Proceedings of the association for computational linguistics 2007, pp 264–271
Liao X, Xue Y, Carin L (2005) Logistic regression with an auxiliary data source. In: Proceedings of the international conference on machine learning 2005, pp 505–512
Huang J, Smola A, Gretton A, Borgwardt KM, Schölkopf B (2007) Correcting sample selection bias by unlabeled data. In: Proceedings of the neural information processing systems 2007, pp 601–608
Zheng VW, Yang Q, Xiang W, Shen D (2008) Transferring localization models over time. In: Proceedings of the AAAI conference on artificial intelligence 2008, pp 1421–1426
Pan SJ, Shen D, Yang Q, Kwok JT (2008) Transferring localization models across space. In: Proceedings of the AAAI conference on artificial Intelligence 2008, pp 1383–1388
Raykar VC, Krishnapuram B, Bi J, Dundar M, Rao RB (2008) Bayesian multiple instance learning: automatic feature selection and inductive transfer. In: Proceedings of the international conference on machine learning 2008, pp 808–815
Pan SJ, Qiang Y (2010) A survey on transfer learning. IEEE Trans Knowl Data Eng 22(10):1345–1359
Dai W, Yang Q, Xue G, Yu Y (2007) Boosting for transfer learning. In: Proceedings of the international conference on machine learning 2007, pp 193–200
Raina R, Battle A, Lee H, Packer B, Ng AY (2007) Self-taught learning: transfer learning from unlabeled data. In: Proceedings of the international conference on machine learning 2007, pp 759–766
Dai W, Xue G, Yang Q, Yu Y (2007) Co-clustering based classification for out-of-domain documents. In: Proceedings of the ACM SIGKDD conference on knowledge discovery and data mining 2007, pp 432–444
Ando RK, Zhang T (2005) A high-performance semi-supervised learning method for text chunking. In: Proceedings of the association for computational linguistics 2005, pp 1–9
Lawrence ND, Platt JC (2004) Learning to learn with the informative vector machine. In: Proceedings of the international conference on machine learning 2004, pp 432–444
Schwaighofer A, Tresp V, Yu K (2005) Learning gaussian process kernels via hierarchical bayes. In: Proceedings of the neural information processing systems 2005, pp 1209–1216
Gao J, Fan W, Jiang J, Han J (2008) Knowledge transfer via multiple model local structure mapping. In: Proceedings of the ACM SIGKDD conference on knowledge discovery and data mining 2008, pp 283–291
Mihalkova L, Huynh T, Mooney RJ (2007) Mapping and revising markov logic networks for transfer learning. In: Proceedings of the AAAI conference on artificial intelligence 2007, pp 608–614
Mihalkova L, Mooney RJ (2008) Transfer learning by mapping with minimal target data. In: Proceedings of workshop transfer learning for complex tasks with AAAI, 2008
Davis J, Domingos P (2008) Deep transfer via second-order markov logic. In: Proceedings of workshop transfer learning for complex tasks with AAAI, 2008
Bonilla EV, Agakov F, Williams C (2007) Kernel multi-task learning using task-specific features. In: Proceedings of the international conference on artificial intelligence and statistics 2007, pp 43–50
Yu K, Tresp V, Schwaighofer A (2005) Learning gaussian processes from multiple tasks. In: Proceedings of the international conference on machine learning 2005, pp 1012–1019
Bakker B, Heskes T (2003) Task clustering and gating for bayesian multitask learning. J Mach Learn Res 4:83–99
Huffel SV, Vandewalle J (1991) The total least squares problem: computational aspects and analysis. Frontiers in applied mathematics. SIAM Press, Philadelphia
Vapnik V (1998) Statistical learning theory. Frontiers in applied mathematics. Springer, London
Wang F, Zhao B, Zhang CS (2010) Linear time maximum margin clustering. IEEE Trans Neural Netw 21(2):319–332
Chen J, Liu X (2014) Transfer learning with one-class data. Pattern Recognit Lett 37(1):32–40
Schölkopf B, Herbrich R, Smola AJ, Williamson RC (2001) A generalized representer theorem. In: Proceedings of the annual conference on learning theory 2001, pp 416–426
Chang C-C, Lin C-J (2011) LIBSVM: a library for support vector machines. ACM Trans Intell Syst Technol 2(3):1–27
William J, Shaw M (1986) On the foundation of evaluation. Am Soc Inf Sci 37(5):346–348
Tax DMJ, Duin RPW (2004) Support vector data description. Mach Learn 54(1):45–66
Cao B, Pan J, Zhang Y, Yeung DY, Yang Q (2010) Adaptive transfer learning. In: Proceedings of the AAAI conference on artificial intelligence, 2010
Aggarwal CC, Yu PS (2008) A framework for clustering uncertain data streams. In: Proceedings of the international conference on data engineering 2008, pp 150–159
Cole R, Fanty MA (1990) Spoken letter recognition. In: Proceedings of the workshop on speech and natural language 1990, pp 385–390
Yin J, Yang Q, Pan JJ (2008) Sensor-based abnormal human-activity detection. IEEE Trans Knowl Data Eng 20(8):1082–1090
Tsang IW, Kwok JT, Cheung PM (2005) Core vector machines: Fast SVM training on very large data sets. J Mach Learn Res 6:363–392
Dong JX, Devroye L, Suen CY (2005) Core vector machines: fast SVM training algorithm with decomposition on very large data sets. IEEE Trans Pattern Anal Mach Intell 27(4):603–618
Tresp V (2000) A Bayesian committee machine. Neural Comput 12(11):2719–2741
Shalev-Shwartz S, Singer Y, Srebro N (2007) Pegasos: primal estimated sub-gradient solver for SVM. In: Proceedings of the international conference on machine learning 2007, pp 807–814
Kivinen J, Smola AJ, Williamson RC (2004) Online learning with kernels. IEEE Trans Signal Process 52(8):1–12
Dragomir SS (2003) A survey on cauchy-bunyakovsky-schwarz type discrete inequalities. J Inequal Pure Appl Math 4(3):1–142
Acknowledgments
This work is supported by Natural Science Foundation of China (61070033, 61203280, 61202270), Guangdong Natural Science Funds for Distinguished Young Scholar (S2013050014133), Natural Science Foundation of Guangdong province (9251009001000005, S2012040007078), Specialized Research Fund for the Doctoral Program of Higher Education (20124420120004), Science and Technology Plan Project of Guangzhou City(12C42111607, 201200000031,2012J5100054), Science and Technology Plan Project of Panyu District Guangzhou (2012-Z-03-67), Scientific Research Foundation for the Returned Overseas Chinese Scholars, State Education Ministry, GDUT Overseas Outstanding Doctoral Fund (405120095), US NSF through Grants IIS-0905215, CNS-1115234, IIS-0914934, DBI-0960443, and OISE-1129076, US Department of Army through Grant W911NF-12-1-0066, Google Mobile 2014 Program and KAU grant.
Author information
Authors and Affiliations
Corresponding author
Appendix
Appendix
1.1 Proof for Theorem 1
Assume that \(\alpha _{1i} \ge 0,\alpha _{2j} \ge 0,\beta _{1i} \ge 0\) and \(\beta _{2j} \ge 0\) are Lagrange multipliers. The Lagrange function of problem (8) can be given as
where it has \(\overline{\mathbf{x }}_{1i} = \mathbf x _{1i} + \Delta \overline{\mathbf{x }}_{1i}\) and \(\overline{\mathbf{x }}_{2j} = \mathbf x _{2j} + \Delta \overline{\mathbf{x }}_{2j}\).
By differentiating the Lagrange function (37) with \(\mathbf w _0,\mathbf v _1,\mathbf v _2,\rho _1,\rho _2,\xi _{1i}\) and \(\xi _{2j}\), respectively, the following equations can be obtained.
From Eqs. (38)–(44), it is easy to deduce that
Since it has \(\beta _{1i} \ge 0\) and \(\beta _{2j} \ge 0\), from (50) and (51), we can obtain
By substituting (38)–(53) into the Lagrange function (37), the dual form of problem (8) can be written as
\(\square \)
1.2 Proof for Theorem 2
In Theorem 2, we fix \(\mathbf w _0,\mathbf v _1,\mathbf v _2,\rho _1\) and \(\rho _2\) to be \(\overline{\mathbf{w }}_0,\overline{\mathbf{v }}_1,\overline{\mathbf{v }}_2,\overline{\rho }_1\) and \(\overline{\rho }_2\), respectively, and attempt to minimize the value of the objective function (7) by optimizing \(\Delta \mathbf x _{1i}\) and \(\Delta \mathbf x _{2j}\). From (7), the objective function’s value is determined by \(\sum _{t=1}^{2} \sum _{i=1}^{|S_t|} \xi _{ti}\) since \(\mathbf w _0,\mathbf v _1,\mathbf v _2,\rho _1\) and \(\rho _2\) are fixed. Hence, we need to optimize \(\Delta \mathbf x _{1i}\) and \(\Delta \mathbf x _{2j}\) to minimize \(\sum _{t=1}^{2} \sum _{ i=1}^{|S_t|} \xi _{ti}\).
Each training example \(\mathbf x _{ti}\) (\(i=1, \ldots , |S_t|, t=1, 2\)) is associated with an error term \(\xi _{ti}\) and the minimization of \(\sum _{t=1}^{2} \sum _{ i=1}^{|S_t|} \xi _{ti}\) can be decomposed into subproblems of minimizing each error term \(\xi _{ti}\):
From Eq. (54), it is seen that we can minimize \(\xi _{ti}\) by maximizing \((\overline{\mathbf{w }}_0 + \overline{\mathbf{v }}_t)^T \Delta \mathbf x _{ti}\). According to the Cauchy–Schwarz inequality [59], it has
In Eq. (55) becomes equation if and only if \(\Delta \mathbf x _{ti} = c (\overline{\mathbf{w }}_0 + \overline{\mathbf{v }}_t)\), where \(c\) is a constant number. Since \(\Delta \mathbf x _{ti}\) is bounded by \(\delta _{ti}\), the optimal value of \(\Delta \mathbf x _{ti}\) is
\(\square \)
1.3 Proof for Theorem 3
We fix \(\overline{\mathbf{w }}_0,\overline{\mathbf{v }}_1,\overline{\mathbf{v }}_2,\overline{\rho }_1\) and \(\overline{\rho }_2\), and focus on minimizing each \(\xi =\max \{ 0, \overline{\rho }_t - \frac{1}{2} \sum _{h=1}^{2} \sum _{j=1}^{|S_h|} \alpha _{hj} K(\mathbf x _{hj}+\Delta \overline{\mathbf{x }}_{hj}, \mathbf x + \Delta \mathbf x ) - \frac{1}{2 C_t}\sum _{j=1}^{|S_t|} \alpha _{tj} K(\mathbf x _{tj}+\Delta \overline{\mathbf{x }}_{tj}, \mathbf x + \Delta \mathbf x )\) (\(\mathbf x \in S_t, t=1, 2\)) over \(\Delta \mathbf x \). According to the first order Taylor expansion of \(K(\cdot )\) in Eq. (21), it is easy to deduce
Similar to Sect. 8.2, by using the Cauchy–Schwarz inequality, the optimal value of \(\Delta \mathbf x _{ti}\) is as follows
where it has
\(\square \)
1.4 Proof for Theorem 4
Let \(\alpha _{ti}\ge 0\) and \(\beta _{ti} \ge 0\) be Lagrange multipliers. Based on the Lagrange multipliers, the Lagrange function of problem (29) can be given as
Differentiating the Lagrange function (58) with \(\mathbf w ,{\mathbb {\rho }},\xi _{ti}\) leads to
According to Eqs. (59)–(61), we can obtain
By substituting (62)–(64) to problem (29), the dual form can be given as
\(\square \)
1.5 Proof for Theorem 6
We fix \( \mathbf w ^{\phi }\) and \(\rho \) to be \(\overline{\mathbf{w }}^{\phi }\) and \(\overline{\rho }\), respectively, and minimize each \(\xi _{hj} =\max \{ 0, \overline{\rho }_h^T \mathbf e _h - (\mathbf w ^{\phi })^T \phi (\overline{\mathbf{z }}(\mathbf x _{hj}, h)) \}\) (\(\mathbf x _{hj} \in S_h, h=1, \ldots , K\)) over \(\Delta \mathbf x _{hj}\). Since \(\overline{\rho }_h^T \mathbf e _h\) is known, we minimize \(\xi _{hj} \) by maximizing \((\mathbf w ^{\phi })^T \phi (\overline{\mathbf{z }}(\mathbf x _{hj}, h))\). Replacing \(\overline{\mathbf{z }}(\mathbf x _{hj}, h)\) with \(\phi (\overline{\mathbf{z }}(\mathbf x _{hj}, h))\) in Eq. (31) leads to
By employing the first order Taylor expansion of \(K(\cdot )\) in Eq. (21) and substituting Eq. (66) into \((\mathbf w ^{\phi })^T \phi (\overline{\mathbf{z }}(\mathbf x _{hj}, h))\), it has
By utilizing the Cauchy–Schwarz inequality, the optimal value of \(\Delta \mathbf x _{hj}\) is
where it has
\(\square \)
Rights and permissions
About this article

Cite this article
Xiao, Y., Liu, B., Yu, P.S. et al. A robust one-class transfer learning method with uncertain data. Knowl Inf Syst 44, 407–438 (2015). https://doi.org/10.1007/s10115-014-0765-8
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10115-014-0765-8